






后向传播算法
几个编导数之间是相互关联的
利用链式求导法

先计算这三个点
接着  可得
可得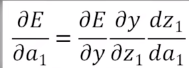


综合我们可得
同理我们可以得到


同理

因为其从输出往输入推,从后往前传递,所以叫后向传播算法
总结后向传播算法的步骤:
(1)对神经网络每一层的各个神经元,随机选取相应的w,b的值
(2)设置目标函数E,例如E=1/2(y-Y)^2,用后向传播算法对每一个w和b,计算
(3)利用如下迭代公式,更新w和b的值

(4)回到(2),不断循环,直到所有
很小为止,推出循环
更普通的神经网络

神经网络的矩阵方式

说明:

设对于一个输入的向量X,其标签为Y

先推到E对“枢纽变量”的偏导数
设枢纽变量为
最后一层:
通过第m+1层推导第m层

这里Sm+1是第m+1层的神经元个数
推导
如图

最终:
易求得
总结一般情况下的后向传播算法流程
(1)对神经网络每一层的各个神经元,随机选取相应的w,b值
(2)前向计算,对于输入,计算并保留每一层的输出值,直到计算出最后一层的输出y
(3)设置目标函数E,如: ,用后向传播算法对每一个w和b计算
,用后向传播算法对每一个w和b计算
(4)利用如下迭代公式,更新w和b的值

(5)回到(2),不断循环,直到所有 很小为止,退出循环。
很小为止,退出循环。
后向传播算法的应用
为了算法的顺利完成要对基本框架进行一系列改进
非线性函数的改进
层与层之间的非线性函数是阶跃函数
但是后向传播算法需要对φ求导数,所以要对非线性函数加以改造
例如
sigmoid函数

x是负无穷处为0,在正无穷为1
双曲正切tanh函数


求导等于1-原函数的平方
在分类问题中基于SOFTMAX函数和交叉熵的目标函数
例如二分类问题
在神经网络中标签Y是一个二维变量
![]() 表示一类,
表示一类,![]() 表示另一类
表示另一类
将这种向量叫做独热向量
之所以使用这种向量,我们需要充分利用神经网络类别的相关信息才能产生更好的分类结果
在分类问题中我们经常使用基于SOFTMAX函数和交叉熵的目标函数

SOFTMAX函数的形式为:

EXP(x)表示e的x次方
这是做了一个归一化,因此
基于交叉熵的目标函数:

此放映了两个概率分布Y与y之间的相似程度
根据信息论,可得E(y)>=0,当Y确定时,当且仅当y=Y是,E(y)取最小值
采用SOFTMAX函数加交叉熵的目标函数
可以证明一个非常简介的偏导公式
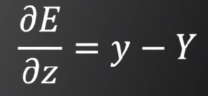
第三个重要改进:随机梯度下降法
在参数更新部分
如果每输入一个测试样本,就要更新所有参数,这样训练非常慢,其次如果梯度的更新只依赖一个训练数据,则这个数据的训练误差将传导到每一个参数上去,这样会让算法收敛变得非常缓慢
随机梯度下降算法的要点:
(1)不用没输入一个样本就去更新参数,而是输入一批样本(叫做一个BATCH或一个MINI-BATCH)求出这些样本的梯度平均值后,根据这个平均值改变参数。在神经网络训练中,BATCH的样本数大致设置为50到200不等
对于所有训练数据,根据BATCH SIZE 分割为各个不同的BATCH
注:按照BATCH遍历所有训练样本一次,我们称为一个EPOCH
对于每一个EPOCH,我们需要随机打乱所有训练样本的次序,来增加BATCH中训练样本的随机性















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









