






ADABOOST 核心思想:融合一些弱分类器获得强分类器
核心流程:先用一部分特征训练一些较弱的分类器,然后再将这些较弱的分类器逐步提升为强的分类器。ADABOOST的核心是调整训练样本的分布,使得先前分类器做错的训练样本在后续学习中获得更多的关注,然后基于调整后的样本分布来训练下一个分类器。
算法流程:假定一个二类分类问题


输出:最终分类器G(x)
步骤一:初始化每个样本的权值分布

每个样本以等概率被采样

注:这里em表示的是用每个样本权重分布wmi加权平均后的错误率
接着计算第m个弱分类器的加权系数:

结论1:由于这是一个二分类问题,所以加权后错误了em<1/2,因此根据上面公式可以得出am>0;
结论2:em越小,am越大,换句话说,第m个弱分类器的加权错误率越小,意味着这个分类器越准确,那么这个分类器对最好识别结果影响的权重就应该越大。
步骤三:更新训练集的权值分布

从以上可以看出


步骤三经过M次循环后,最终进入步骤四
首先构建基本的分类面
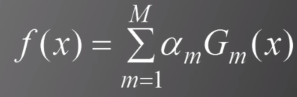
然后根据f(x)我们可以得到最终分类器:

每个分类器的权值系数am越大,那么它对最终集成的分类器G(x)的影响也就越大
随着弱分类器个数M的增加,ADABOOST获得的强分类器在训练集上的错误率会减小最终趋近于0
基于ADABOOST的学习器不容易过拟合,在测试集上也能获得很好的性能。
应用:
基于类哈尔特征构建四种弱分类器

以上20w个类哈尔图像可以用积分图来简化计算

积分图可以通过从左到右从上到下一次性遍历图像获得

对每一个类哈尔特征,构建一个人脸检测的弱分类器


以上每一个弱分类器,都只是基于一个类哈尔特征构建的,可以想见,每一个弱分类器的识别率都不高,它们的识别率大概都只比1/2瞎猜概率多一点点。
利用ADABOOST算法选择4000个左右的弱分类器,集成获得的识别率可以满足使用需求
训练结束后,整个人脸检测流程如下:
1、在图像中,对每一个24*24的格子遍历使用分类器,如果是人脸,则输出。
2、将图像缩小,长宽同时除以1.2,在用分类器遍历每一个24*24的格子。如果是人脸,将该处位置坐标乘以1.2,等比例放大到原图。
3、重复2,直到图像长和宽小于24个像素为止















 1075
1075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









