







在写这篇博客前,我使用yolov5+deepstream完成了在jetson nano上的部署,部署完成后检测帧率很低,然后查阅各种资料和论文,发现直接使用pytorch模型转化并不会优化jetson nano底层算法,然后我使用各种转化方法,把能用的算法几乎都用了,还是做不到实时检测(可能还是模型的问题),也尝试了yolov3 ,yolov4 ,最终效果都不是很好。
然后我看到一篇博主分享的博客(https://blog.csdn.net/ZeyiRTangent),使用yolov4-tiny+tensorRT可以做到实时检测(目前yolov4-tiny+tensorRT是效果最好的组合),我写下这篇博客只是记录我使用yolov4-tiny+tensorRT检测时遇到的一些问题。感谢这位博主的分享(https://blog.csdn.net/weixin_54603153)
文章目录
前言
这篇博客并不是我的原创,只是记录我的一些学习经历,并在其他博主的博客上做了一些补充。希望可以帮到大家。在使用deepstream部署时检测帧率大概只有5帧左右,使用yolov4-tiny+tensorRT可以做到40~50帧(在这里我只做到了25帧左右),做到实时检测时没有问题的,下面我们进入正文。
一、环境
具体所需的硬件环境和软件环境可以看我上一篇博客,里面详细记录了部署前的准备,在这里我不做过多赘述。
基本环境准备好后
还需要:
1.pycuda =2019.1.2
2.numpy=1.19.5
3.onnx=1.4.1
二、安装步骤
1.安装pycuda
在此我附上百度网盘链接:
链接:https://pan.baidu.com/s/1DL5sre_HhU9P9bSUPDRAKw
提取码:uwc4
下载之后执行一下命令进行安装
cd pycuda-2019.1.2/
python3 configure.py --cuda-root=/usr/local/cuda-10.2
sudo python3 setup.py install
2.安装numpy
首先我们先安装pip3
sudo apt-get install python3-pip
然后安装Cython
pip3 install Cython
接下来我们安装numpy
pip3 install numpy
3.安装onnx=1.4.1
首先在nano上安装依赖
sudo apt-get install protobuf-compiler libprotoc-dev
然后就可以安装onnx了(不要换源,我换源安装之后环境出错了)
pip3 install onnx==1.4.1
三、具体步骤
1.下载tensorrt_demos代码
(感谢这位博主的分享:https://blog.csdn.net/ZeyiRTangent)
https://github.com/jkjung-avt/tensorrt_demos
下载之后进入yolo文件夹下
在yolo文件夹下有一个download_yolo.sh 文件,里面包含了yolov3 和yolov4的各种模型和模型生成文件
运行downloda_yolo.sh文件
sh download_yolo.sh
然后就会下载相应的模型和生成模型文件(这里我使用的是yolov4-tiny和其模型生成文件)
下载完成后在yolo文件夹下会出现模型文件和模型生成文件
2.编译
此时不要直接生成运行yolo_toTonnx.py文件,会出现错误提示你没有进行编译
接下来我们回到上一级目录
cd ..
进入plugins文件夹进行编译
cd plugins
make
编译完成后就可以进行模型生成
3.生成onnx文件
执行yolo_to_onnx.py文件,我选用的是yolov4-tiny-416
python3 yolo_to_onnx.py -m yolov4-tiny-416
执行之后在yolo文件夹下就会生成一个.onnx文件
4.生成经过tensorRT优化后的模型文件(.trt文件)
执行
python3 onnx_to_tensorrt.py -m yolov4-tiny-416
执行之后在yolo文件夹下你可以看到.trt文件
5.调用usb摄像头进行目标检测
这里便是我要补充的地方,一些博主的博客里提到在utils/camera.py文件中有相应的声明
调用usb摄像头需要修改camera.py文件的某个部分
修改前

修改后

这里为什么要修改为False,在注释第二句话可以看到,如果设置False,我们打开使用cv2.VideoCapture()
机制的摄像头,修改后保存。
执行
python3 trt_yolo.py --usb 0 -m yolov4_tiny-416
接下来就可以看到检测结果了
基本上可以做到实时检测。
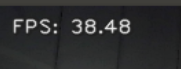
下面是一个博主检测的结果,检测帧率达到了38(我只做到了25)
需要配置好的tensorrt_demo文件可以在下面留下邮箱,我看到后会发到相应邮箱里。
总结
这里对文章进行总结:
这篇文章是我在部署yolov5后为了提升帧率写的一篇博客,在调用USB摄像头时,出现了一点小插曲,所以我写下这篇文章记录下来,后续我会在对yolov5进行优化。感谢这些博主的分享,在此附上链接
(https://blog.csdn.net/ZeyiRTangent)
(https://blog.csdn.net/weixin_54603153)















 3971
3971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









