



labelme 数据标注使用流程
Labelme 安装 - windows
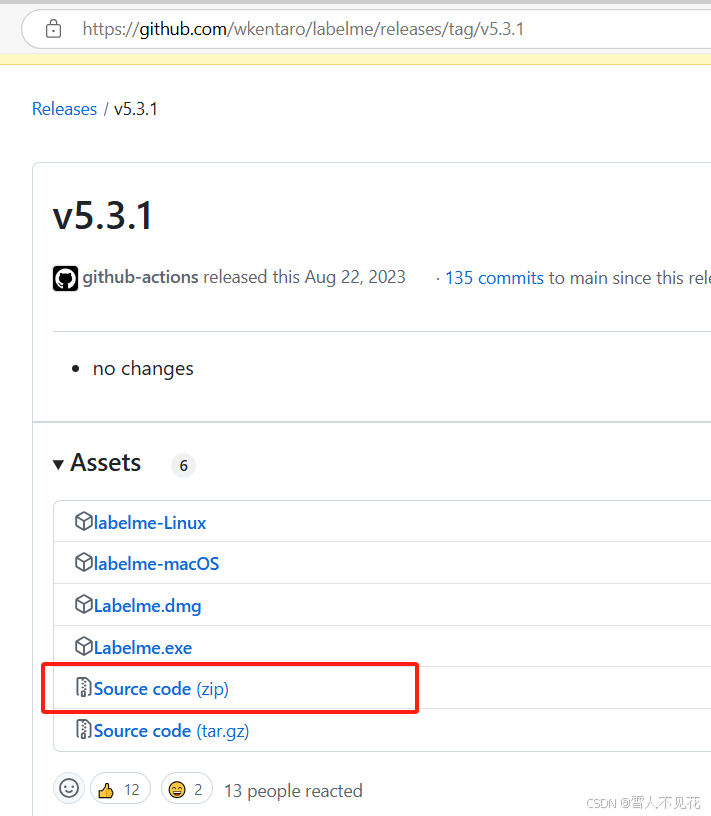
1.下载labelme
下载labelme(github.com)
下载压缩包,下载完成后解压至自定义的目录
2. 安装anaconda
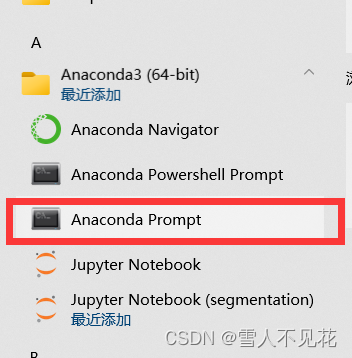
3.创建labelme环境
打开anaconda,在控制台分别输入以下三条命令
conda create -n labelme python=3.8.0
conda activate labelme
pip install opencv-python==4.2.0.34
使用labelme标注
1.打开anaconda环境
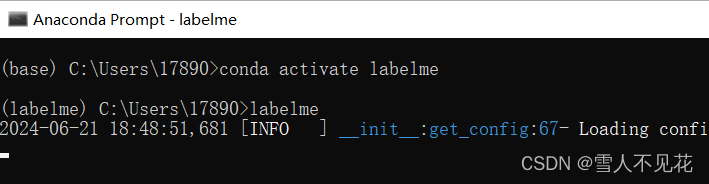
2.打开labelme工具
输入下列两条命令,打开labelme工具
(前提是本机anaconda中已经安装了labelme工具)
conda activate labelme
labelme
输入完成后,此窗口不可关闭
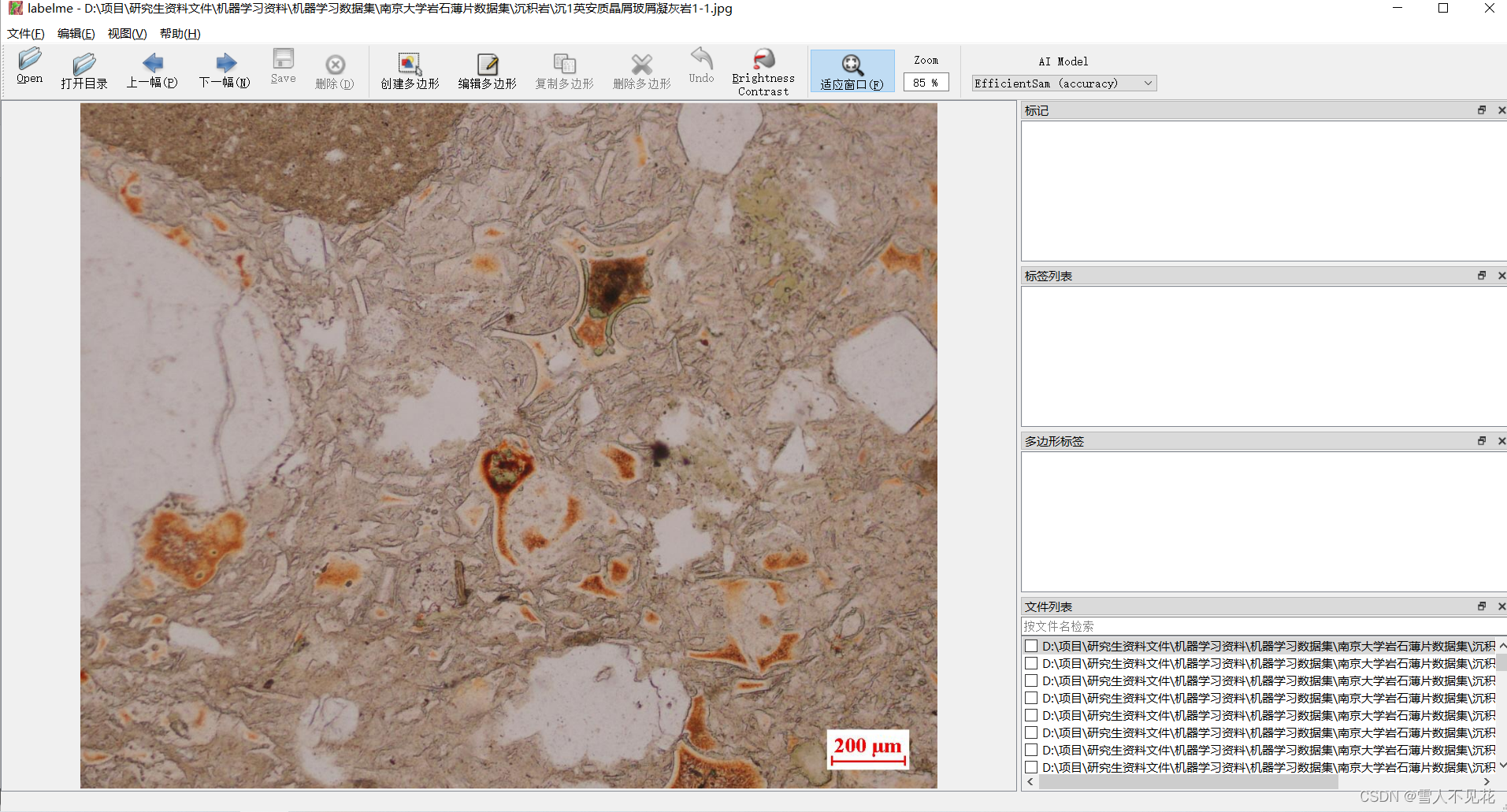
3.打开数据集文件夹
注意:打开一个文件夹后,要将本文件夹中的所有图片全部标注完成后,再可以关闭labelme图形界面(防止文件混乱)
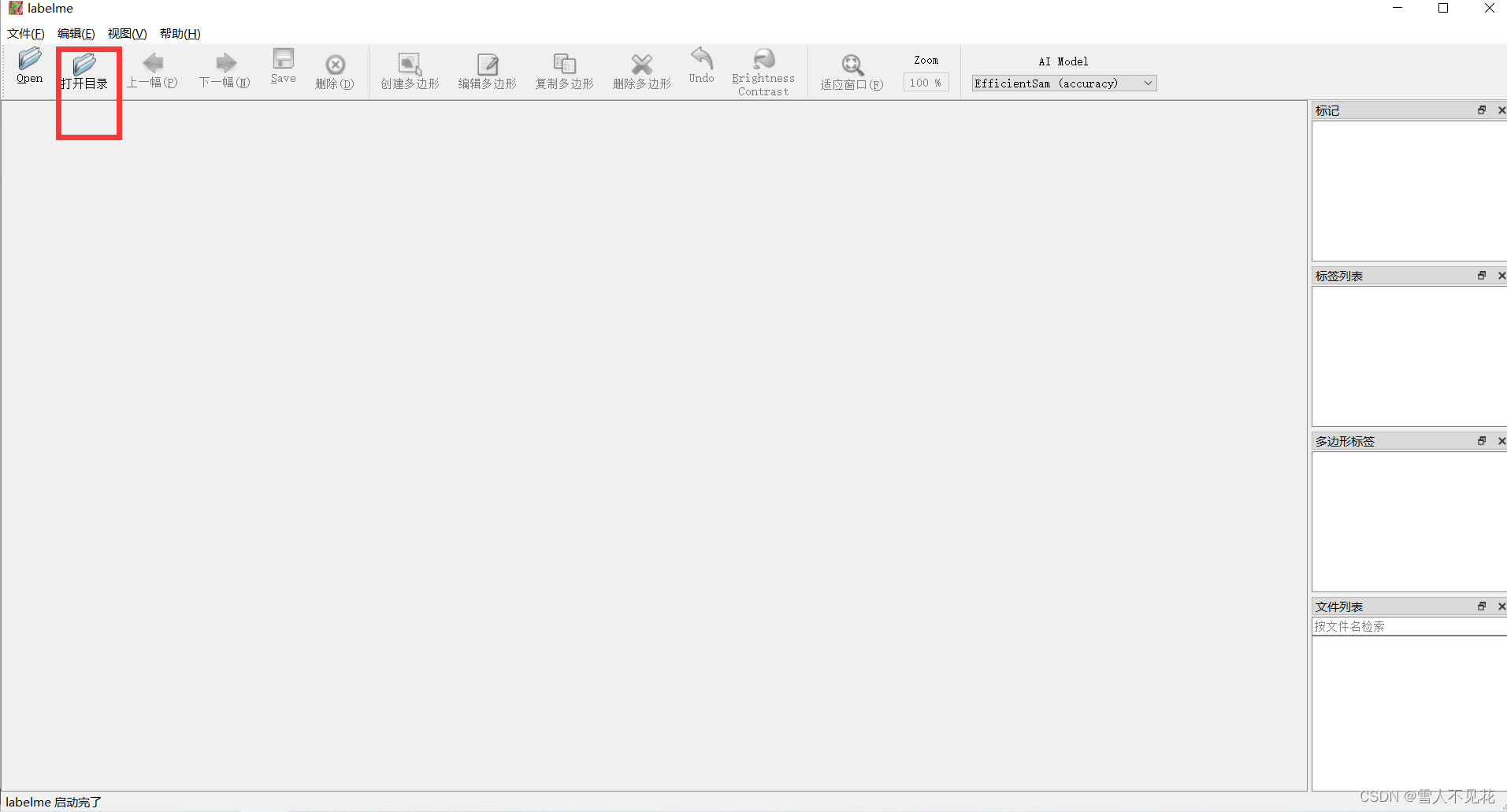
打开完成后界面如下:
4.开始标注
4.1 点击编辑按钮,选择创建标注的类型
这里选择create-AI-Polygon,采用ai辅助标注
注意:ai辅助标注速度块,但是精度或许不够,要注意附加手动调整来确保标注具有较高精度
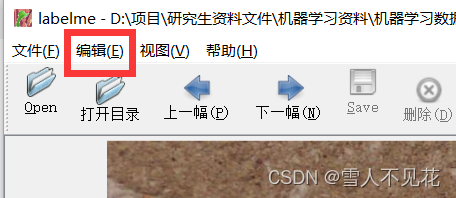
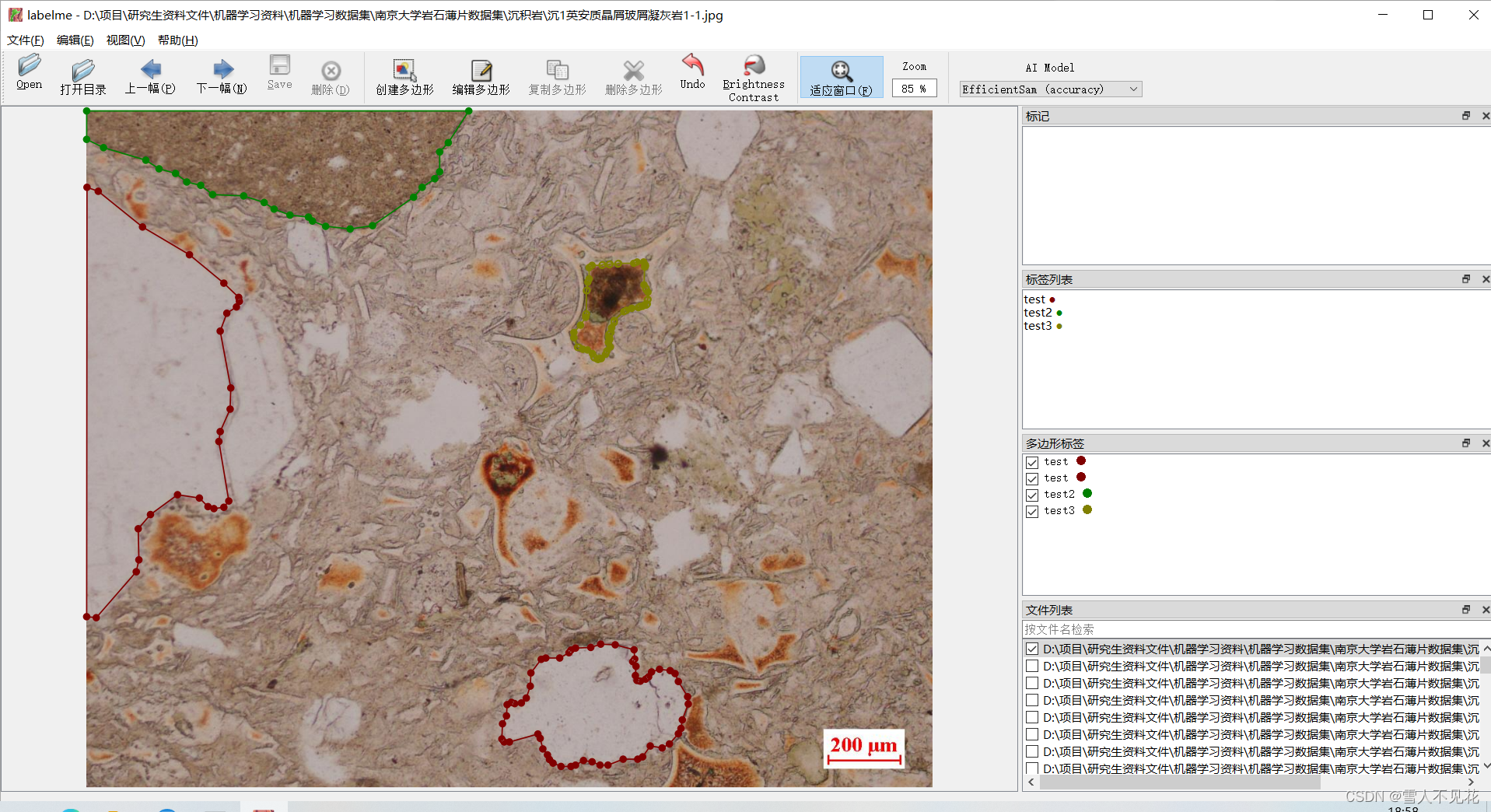
4.2 在区域中间打上关键点来调整标注内容
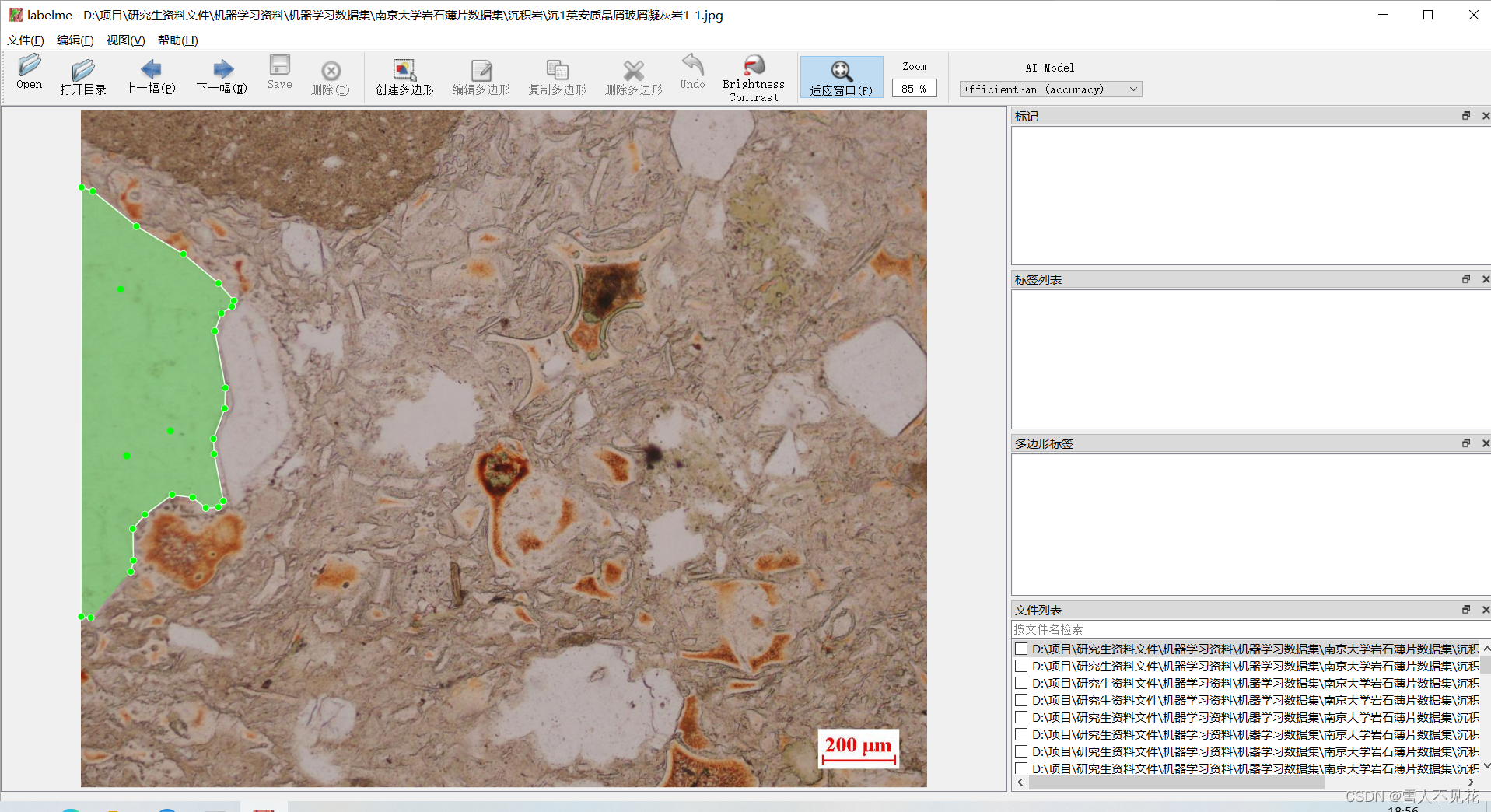
4.3 调整完成后,左键双击完成本区域标注
完成本区域标注,,然后键入岩石类型,这里以test为例
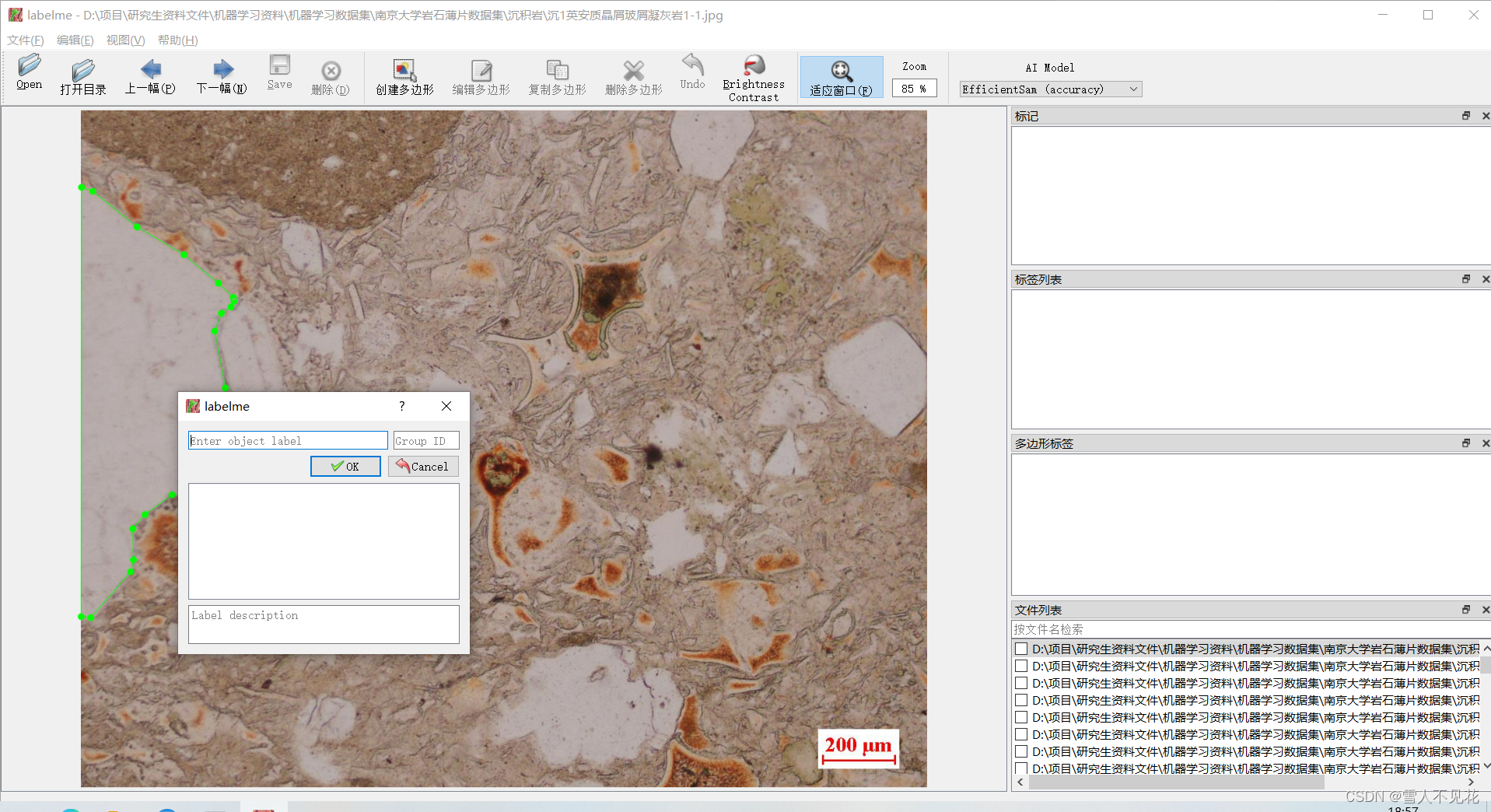
4.4 键入标签后,右侧会显示标签列表
4.5 撤销标注点
若标注点打错,则可以选择单击右键,选择撤销最后的控制点,来撤销上一个操作
4.6 若ai辅助标注不合理,也可以选择"创建多边形"来进行数据标注
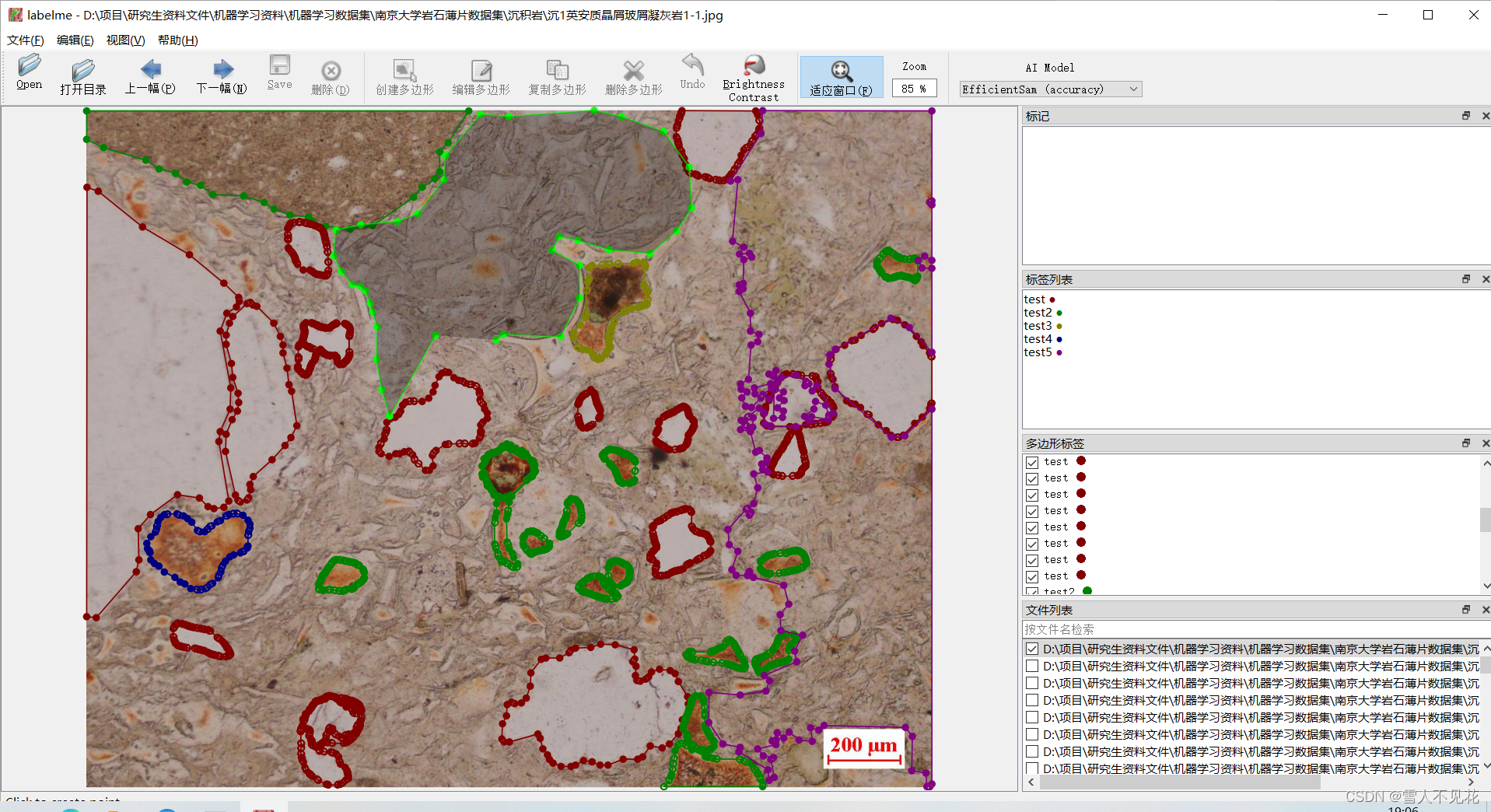
4.7 注意
1.若ai标注区域不合理,则需要人工手动调整,确保标注的准确性
2.一定要确保标注内容覆盖全图,不可以有漏标区域
5. 标注完成
本图片标注完成后,ctrl+s进行保存,之后进行下一幅图片的标注,
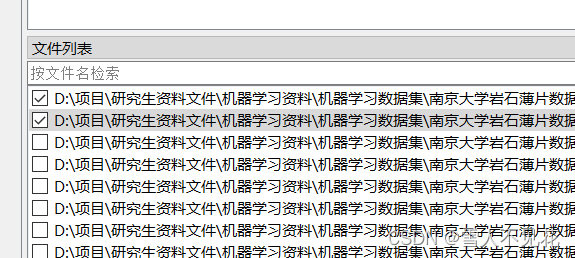
直到本文件夹的图片全部标注完成
图片被标注后,文件前会存在对勾。图片全部标注完成后,关闭labelme图形界面。
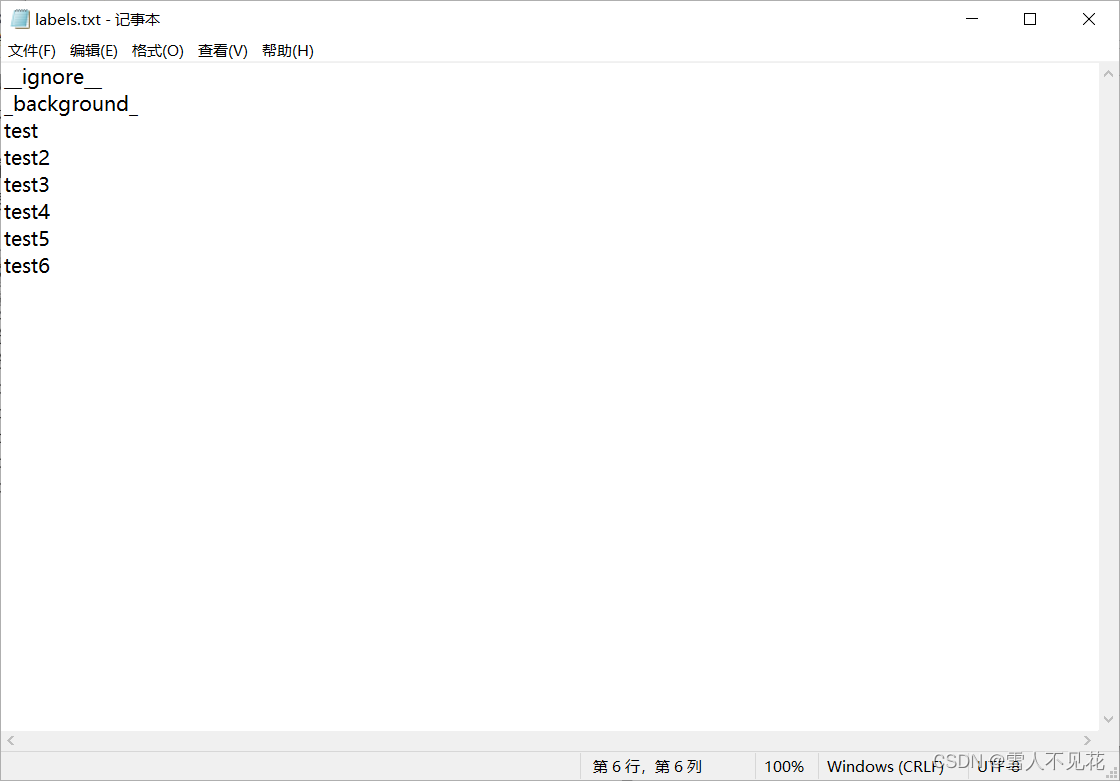
6. 修改labels.txt文件
在标注过程中,若是新加入的标签,则应该将其添加到labels.txt文件中
该txt文件为手动创建,文件存放在与标注图像文件夹同级的目录下,详见7.1
7. 将标注结果可视化
标注完成后,可以将标注结果的json文件批量转换为图像,用来作为图像标签
注意:以下命令需要根据自己的实际文件路径进行修改
7.1 首先,将python代码文件、标签名称与标注的图像文件夹放入同一级目录
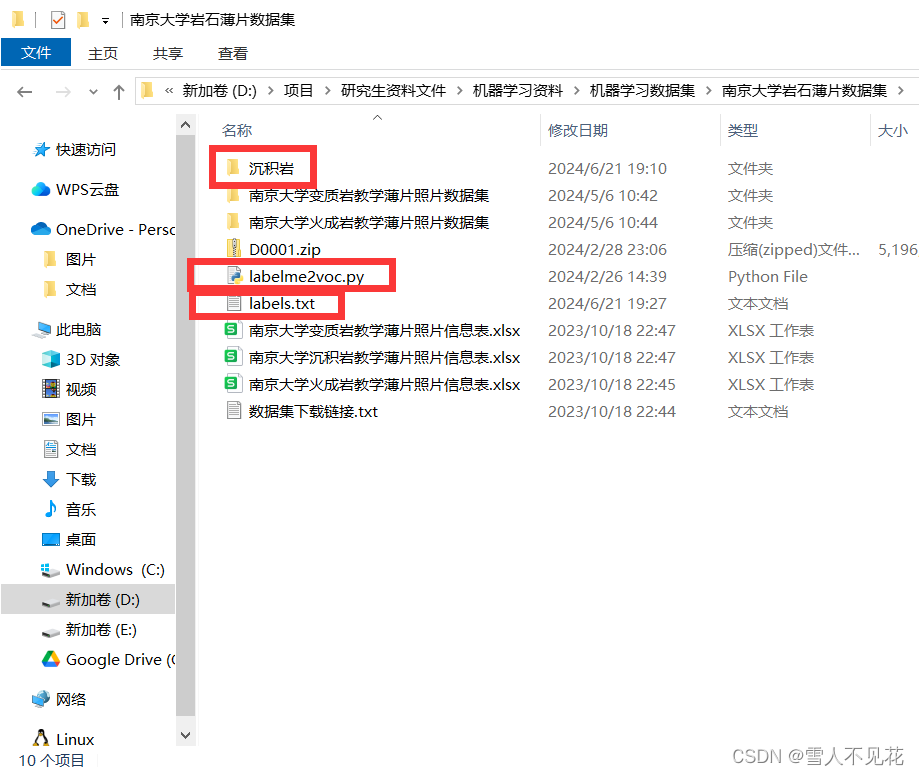
7.2 在命令行窗口进入到标注文件夹下
进入文件夹后执行转换
python labelme2voc.py images_name target_name --labels labels.txt
其中 :
images_name 是标注图片路径,即原始图片与json所在文件夹
target_name 是要将结果保存的文件夹的名称
labels.txt 是存储标签名称
此处的命令需要根据自己实际的文件路径进行修
比如我的命令是
cd D:\项目\研究生资料文件\机器学习资料\机器学习数据集\南京大学岩石薄片数据集
D:
python labelme2voc.py 沉积岩 target_name --labels labels.txt
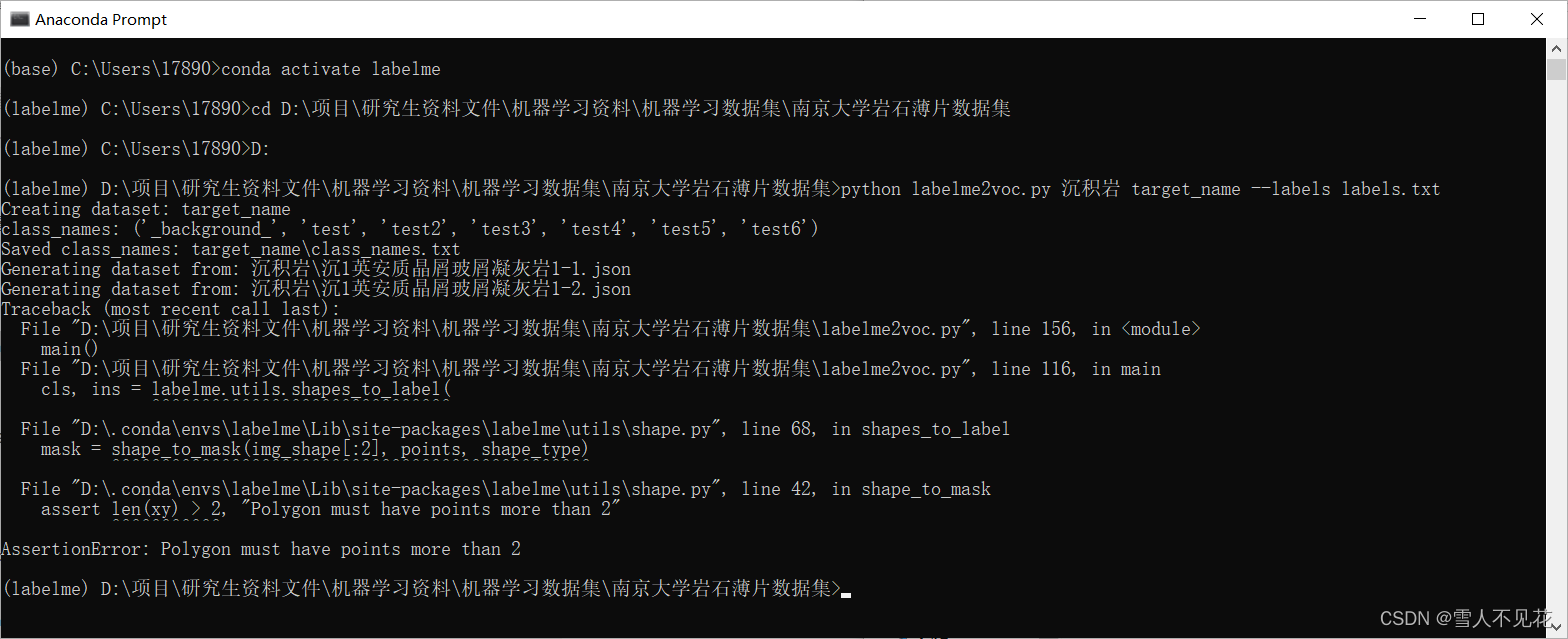
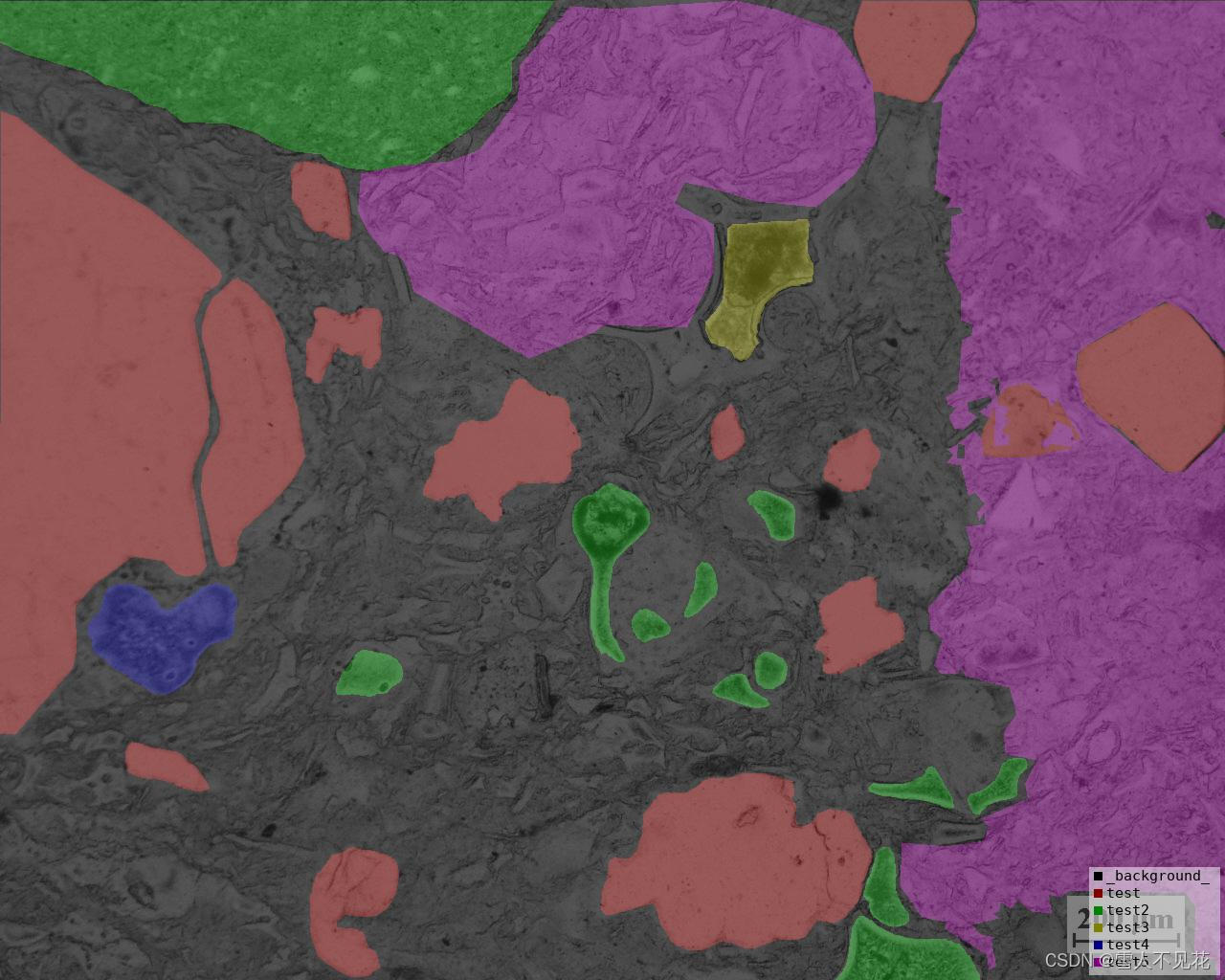
8. 完成json转图片
注意,下面这个例子中,标签并没有全部覆盖,说明这是一个不好的标签。
语义分割标签文件:

标签与原始图像展示
9. labelme2voc.py代码
#!/usr/bin/env python
from __future__ import print_function
import argparse
import glob
import os
import os.path as osp
import sys
import imgviz
import numpy as np
import labelme
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("input_dir",default='./input_imgAndjson', help="Input annotated directory")
parser.add_argument("output_dir", default='./output_img',help="Output dataset directory")
parser.add_argument(
"--labels",default='./labels.txt', help="Labels file or comma separated text", required=True
)
parser.add_argument(
"--noobject", help="Flag not to generate object label", action="store_true"
)
parser.add_argument(
"--nonpy", help="Flag not to generate .npy files", action="store_true"
)
parser.add_argument(
"--noviz", help="Flag to disable visualization", action="store_true"
)
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
os.makedirs(osp.join(args.output_dir, "SegmentationClass"))
if not args.nonpy:
os.makedirs(osp.join(args.output_dir, "SegmentationClassNpy"))
if not args.noviz:
os.makedirs(osp.join(args.output_dir, "SegmentationClassVisualization"))
if not args.noobject:
os.makedirs(osp.join(args.output_dir, "SegmentationObject"))
if not args.nonpy:
os.makedirs(osp.join(args.output_dir, "SegmentationObjectNpy"))
if not args.noviz:
os.makedirs(osp.join(args.output_dir, "SegmentationObjectVisualization"))
print("Creating dataset:", args.output_dir)
if osp.exists(args.labels):
with open(args.labels) as f:
labels = [label.strip() for label in f if label]
else:
labels = [label.strip() for label in args.labels.split(",")]
class_names = []
class_name_to_id = {}
for i, label in enumerate(labels):
class_id = i - 1 # starts with -1
class_name = label.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__"
continue
elif class_id == 0:
assert class_name == "_background_"
class_names.append(class_name)
class_names = tuple(class_names)
print("class_names:", class_names)
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("Saved class_names:", out_class_names_file)
for filename in sorted(glob.glob(osp.join(args.input_dir, "*.json"))):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_clsp_file = osp.join(args.output_dir, "SegmentationClass", base + ".png")
if not args.nonpy:
out_cls_file = osp.join(
args.output_dir, "SegmentationClassNpy", base + ".npy"
)
if not args.noviz:
out_clsv_file = osp.join(
args.output_dir,
"SegmentationClassVisualization",
base + ".jpg",
)
if not args.noobject:
out_insp_file = osp.join(
args.output_dir, "SegmentationObject", base + ".png"
)
if not args.nonpy:
out_ins_file = osp.join(
args.output_dir, "SegmentationObjectNpy", base + ".npy"
)
if not args.noviz:
out_insv_file = osp.join(
args.output_dir,
"SegmentationObjectVisualization",
base + ".jpg",
)
img = labelme.utils.img_data_to_arr(label_file.imageData)
imgviz.io.imsave(out_img_file, img)
cls, ins = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=label_file.shapes,
label_name_to_value=class_name_to_id,
)
ins[cls == -1] = 0 # ignore it.
# class label
labelme.utils.lblsave(out_clsp_file, cls)
if not args.nonpy:
np.save(out_cls_file, cls)
if not args.noviz:
clsv = imgviz.label2rgb(
cls,
imgviz.rgb2gray(img),
label_names=class_names,
font_size=15,
loc="rb",
)
imgviz.io.imsave(out_clsv_file, clsv)
if not args.noobject:
# instance label
labelme.utils.lblsave(out_insp_file, ins)
if not args.nonpy:
np.save(out_ins_file, ins)
if not args.noviz:
instance_ids = np.unique(ins)
instance_names = [str(i) for i in range(max(instance_ids) + 1)]
insv = imgviz.label2rgb(
ins,
imgviz.rgb2gray(img),
label_names=instance_names,
font_size=15,
loc="rb",
)
imgviz.io.imsave(out_insv_file, insv)
if __name__ == "__main__":
main()


















 941
941






 到【灌水乐园】发言
到【灌水乐园】发言







