







Linux系统中进程的通信与同步实验
实验二 Linux系统中进程的通信与同步实验
一、实验目的和要求
1.理解进程间通信的概念和方法。
2.掌握常用的Linux 进程间通信的方法。
3.加强对进程同步和互斥的理解,学会使用信号蜇解决资源共享问题。
4.熟悉Linux 进程同步原语。
5. 掌握信号量wait/signal 原语的使用方法,理解信号量的定义、赋初值及w扣t/signal操作。
##二、实验设备和环境
硬件环境:HuaWei MateBook 14
软件环境:RedHat CentOS 7.0操作系统与g++编译环境
三、进程通信实验:实验内容
编写C 程序,使用Linux 中的IPC 机制完成“石头、剪刀、布“游戏。
修改上述C 程序,使之能够在网络上运行。
四、进程通信实验:实验步骤
针对实验内容 ,可以创建三个进程,其中一个进程为裁判进程,另外两个进程为选手进程。可将“石头” “剪刀” “布“这三招定义为三个整型值,胜负关系为:石头> 剪刀>布>石头。
选手进程按照随机产生出招,然后交给裁判进程判断大小。裁判进程将对手的出招和胜负结果通知选手。比赛采取多轮定胜负机制,并由裁判宣布最后结果。每次出招由裁判限定时间,超时则判负。
每一轮的胜负结果可以存放在文件或其他数据结构中。比赛结束后,打印每一轮的胜负情况利总的结果。
具体的实验步骤如下。
(1) 设计表示“石头” “剪刀”, 0——石头,1——剪刀,2——布
(2) 设计比赛结果的存放方式——字符数组
(3) 选择 IPC 方法。
(4) 根据所选择的 IPC 方法,创建对应的 IPC 资源。
(5) 完成选手进程。
(6) 完成裁判进程。
程序使用 fork()函数创建了两个选手进程,当前进程为裁判进程。裁判进程创建了两个消息队列,且两个选手进程会发送出拳信息至不同的消息队列,最后由裁判进程从消息队列取得出拳信息并判断结果。
五、进程通信实验:代码及注释
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <errno.h>
#include <stdlib.h>
#include <string.h>
#define FIFO1 "/tmp/myfifo1"
#define FIFO2 "/tmp/myfifo2"
#define SIZE 5
#define COUNT 100
int judge(char a, char b);
int main(void)
{
int fp, fp1, fp2, i = 1;
int status;
int nread;
printf("请输入进行的轮数:\n");
int lun=0;
scanf("%d",&lun);
char buf[SIZE] = {0};
char c1[COUNT] = {0}; //用来存放p1发送的消息
char c2[COUNT] = {0}; //用来存放p2发送的消息
pid_t p1 = fork(); //产生子进程p1
/*********************************/
if (p1 == 0)
{
srand(time(NULL));
while ((fp = open(FIFO1, O_WRONLY | O_NONBLOCK)) == -1)
; //只写打开管道1,不断尝试直到成功
for (; i <= lun; i++)
{
sprintf(buf, "%d", rand() % 3); //随机产生0-2的数字写入管道
while (write(fp, buf, SIZE) == -1)
; //不断尝试写直至成功
}
close(fp);
return 0;
}
/*********************************/
pid_t p2 = fork(); //产生子进程p2,程序结构同p1
/*********************************/
if (p2 == 0)
{
srand(time(NULL) + 100);
while ((fp = open(FIFO2, O_WRONLY | O_NONBLOCK)) == -1)
;
for (; i <= lun; i++)
{
sprintf(buf, "%d", rand() % 3);
while (write(fp, buf, SIZE) == -1)
;
}
close(fp);
exit(0);
}
/**************************************/
//创建2个管道
if ((mkfifo(FIFO1, 0777) < 0) && (errno != EEXIST))
{
printf("cannot create fifo.\n");
exit(1);
}
if ((mkfifo(FIFO2, 0777) < 0) && (errno != EEXIST))
{
printf("cannot create fifo.\n");
exit(2);
}
memset(buf, 0, sizeof(buf)); //清空缓冲区
//只读方式打开两个命名管道
while ((fp1 = open(FIFO1, O_RDONLY | O_NONBLOCK, 0)) == -1)
;
while ((fp2 = open(FIFO2, O_RDONLY | O_NONBLOCK, 0)) == -1)
;
sleep(3); //等待两个子进程中打开管道写端并输入数据,必要
for (; i <= lun; i++) //连续读取lun个数据
{
nread = read(fp1, buf, SIZE);
if (nread != -1 && nread != 0)
{
c1[i] = buf[0]; //结果存放至c1
}
}
i = 1;
for (; i <= lun; i++)
{
nread = read(fp2, buf, SIZE);
if (nread != -1 && nread != 0)
{
c2[i] = buf[0]; //结果存放至c2
}
}
int j = 1;
int p1w = 0, p2w = 0, pd = 0;
for (; j <= lun; j++)
{
int tmp = judge(c1[j], c2[j]);
printf("round %d:", j);
if (tmp == 0)
{
printf("in a draw!\n");
pd++; //平局
}
else
{
printf("%s wins!\n", (tmp > 0) ? "p1" : "p2");
if (tmp > 0)
p1w++; // p1胜
else
p2w++; // p2胜
}
}
//打印最终统计结果
printf("In summary:\n");
printf("p1 wins %d rounds.\n", p1w);
printf("p2 wins %d rounds.\n", p2w);
printf("%d rounds end in a draw.\n", pd);
printf("%s wins in the game!\n", (p1w > p2w) ? "p1" : "p2");
//等待两个子进程结束
if (waitpid(p1, &status, 0) < 0)
{
perror("waitpid");
exit(5);
}
if (waitpid(p2, &status, 0) < 0)
{
perror("waitpid");
exit(6);
}
exit(0);
}
// 0——石头,1——剪刀,2——布
int judge(char a, char b) //规定游戏判定规则
{
int r = 0;
if (a == b)
r = 0;
else
{
if (a == '0' && b == '1')
r = 1;
if (a == '0' && b == '2')
r = -1;
if (a == '1' && b == '2')
r = 1;
if (a == '1' && b == '0')
r = -1;
if (a == '2' && b == '0')
r = 1;
if (a == '2' && b == '1')
r = -1;
}
return r;
}
##六、进程通信实验:实验结果
第一道题:
当输入的比赛轮数是10时
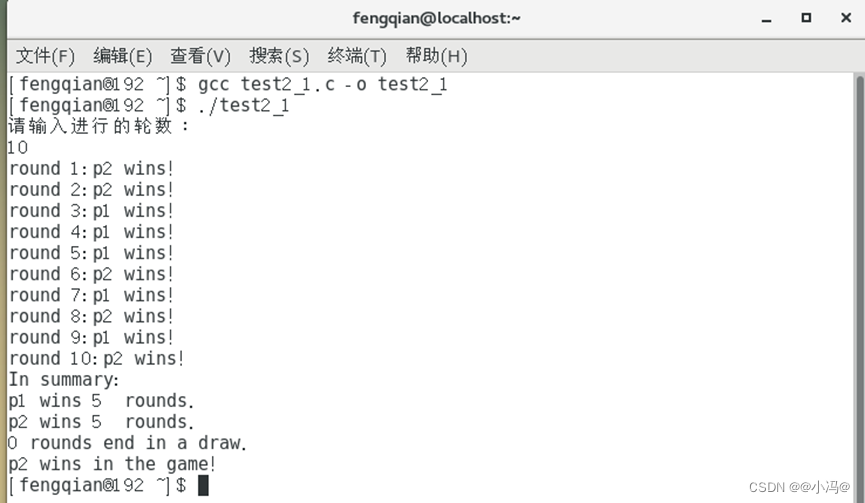
图2.1进程通信的运行结果_1
当输入的比赛轮数为20
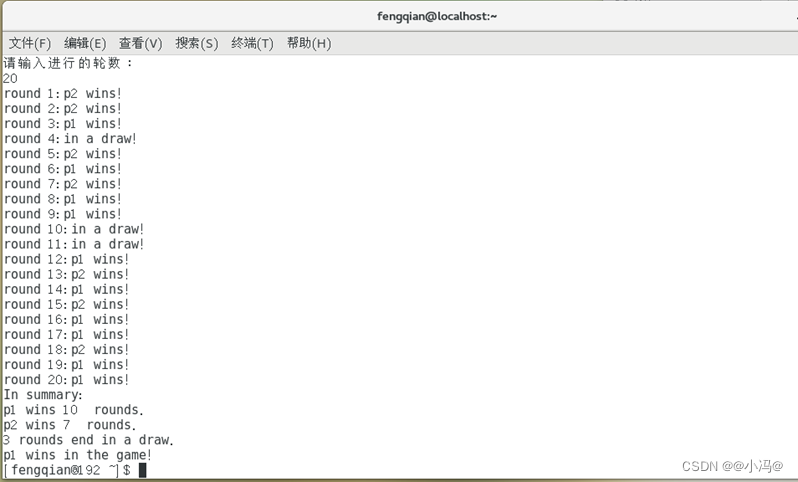
图2.1进程通信的运行结_2
七、进程同步实验:实验内容
编写C 程序,使用Linux 操作系统中的信号量机制模拟解决经典的进程同步问题:生产者-消费者问题。假设有一个生产者和一个消费者,缓冲区可以存放产品,生产者不断生产产品并存入缓冲区,消费者不断从缓冲区中取出产品并消费。
八、进程同步实验:实验步骤
定义同步信号量empty
定义同步信号量full
定义互斥信号量mutex
定义信号量的PV操作
给缓冲区分配内存空间
使用pthread_create创建生产者消费者进程
运行程序后,提示下用户输入内容到缓冲区中,输入完成后消费者读出缓冲区的内容输出到屏幕上
九、进程同步实验:代码及注释
#include <semaphore.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <pthread.h>
#define MAX 256
char *buffer;
sem_t empty; //定义同步信号量empty
sem_t full; //定义同步信号量full
sem_t mutex; //定义互斥信号量mutex
//生产者
void * producer()
{
sem_wait(&empty); //empty的P操作
sem_wait(&mutex); //mutex的P操作
printf("input something to buffer:");
buffer=(char *)malloc(MAX); //给缓冲区分配内存空间
fgets(buffer,MAX,stdin); //输入产品至缓冲区
sem_post(&mutex); //mutex的V操作
sem_post(&full); //full的V操作
}
//消费者
void * consumer()
{
sem_wait(&full); //full的P操作
sem_wait(&mutex); //mutex的P操作
printf("read product from buffer:%s",buffer); //给缓冲区中读出产品
memset(buffer,0,MAX); //清空缓冲区
sem_post(&mutex); //mutex的V操作
sem_post(&empty); //empty的V操作
}
int main()
{
pthread_t id_producer;
pthread_t id_consumer;
int i;
sem_init(&empty,0,10); //设置empty的初值为10
sem_init(&full,0,0); //设置full的初值为0
sem_init(&mutex,0,1); //设置mutex的初值为1
i=pthread_create(&id_producer,NULL,producer,NULL); //创建生产者进程
i=pthread_create(&id_consumer,NULL,consumer,NULL); //创建消费者进程
pthread_join(id_producer,NULL); //等待生产者进程结束
pthread_join(id_consumer,NULL); //等待消费者进程结束
//删除信号量
sem_destroy(&empty);
sem_destroy(&full);
sem_destroy(&mutex);
printf("The End\n");
}
十、进程同步实验:实验结果
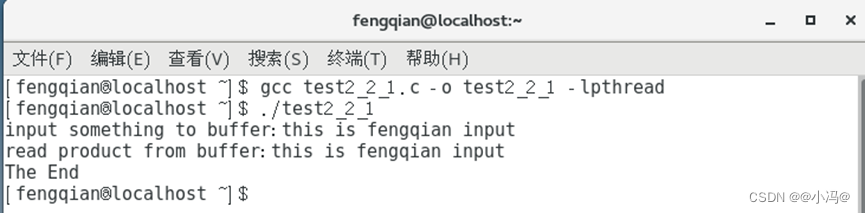 图2.2进程同步代码的运行结果
图2.2进程同步代码的运行结果
十一、实验思考
1、 代码中随机数的取值对于模拟“石头、剪刀、布“游戏很重要,如果取值不当,就可能出现大量平局的情况,故请思考Linux 随机数的合理取值方法。
生成随机数的方法有7种
1.通过时间获取随机数
1)date +%s (随机生成10位数字)
用于获得时间戳。
如果用它做随机数,相同一秒的数据是一样的。在做循环处理,多线程里面基本不能满足要求了。

2)date +%N (随机生成9位数字)
获得当前时间的纳秒数据,精确到亿分之一秒。
这个在同一秒里面,也很难出现相同结果,不过不同时间里面还会有大量重复碰撞
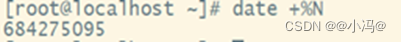
额外扩展:date +%s%N (随机生成19位数字)
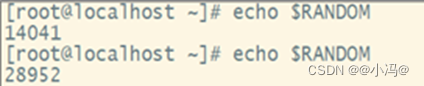
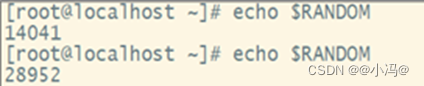
2.通过系统环境变量($RANDOM)
echo $RANDOM (随机生成5位数字)(范围0~32767)
echo “$RANDOM”|md5sum|cut -c 5-14(随机生成10个字符的字符串)

3.通过系统内部唯一数据生成随机数(/dev/urandom)
head /dev/urandom|cksum (9位,4位,如果用cat或more则虚拟机会自动打开打印机,cksum是用来解决乱码的)。
cksum 将读取文件内容,生成唯一的表示整型数据,只有文件内容不变,生成结果就不会变化,与php crc函数。

4.通过opensssl产生随机数
rand -base64 10(表示10位字符串)。

只有当位数为3的倍数时,后面才会没有等号。
5.通过UUID生成随机数
cat /proc/sys/kernel/random/uuid 或 uuidgen。
UUID码全称是通用唯一识别码(Universally Unique Identifier,UUID)它是一个软件建构的标准,亦为自由软件基金会的组织在分布式计算环境领域的一部分;
UUID的目的是让分布式系统中的所有元素都能有唯一的辨别信息,而不需要通过中央控制端来做辨别信息的指定,如此一来,每个人都可以创建不与其他人发生冲突的UUID,在这种情况下,就不需要考虑数据库创建时的名称重复问题了,它会让网络中任何一台计算机所生成的UUID码都是互联网整个服务器网路中唯一的编码。它的原信息会加入硬件、时间、机器当期那运行信息等。

指定长度:uuidgen|md5sum|cut -c 2-10(8位长的字符串)
6.mkpaswd
mkpasswd(默认产生9位的字符串,其中数字固定位2位,特殊字符固定位1位,其余都是字母)。
相关参数:
-l (length of password, default = 9) :指定密码长度;
-d (min # of digits, default = 2) :指定密码中数字的数量;
-c (min # of lowercase chars, default = 2) :指定密码中小写字母的数量;
-C (min # of uppercase chars, default = 2) :指定密码中大写字母的数量;
-s (min # of special chars, default = 1) :指定密码中特殊字符的数量;
-p prog (program to set password, default = /bin/passwd) :程序设置密码,默认是passwd;

7.mktemp
/tmp/tmp.**********(10位长的字符串)。
这是一个比较特殊的随机数,它有指定的目录/tmp。

如果在创建文件时引用此命令,那么它会自动在/tmp目录下产生文件。

2、 比较Linux 操作系统中的几种IPC 机制,并说明它们各自适用于哪些场合。
- UNIX早期IPC:管道、FIFO、信号;
- system V IPC:System V消息队列、System V信号灯、System V共享内存区;
- Posix IPC: Posix消息队列、Posix信号灯、Posix共享内存区;
- 基于socket的IPC;
1.socket
a、使用socket通信的方式实现起来简单,可以使用因特网域和UNIX域来实现,使用因特网域可以实现不同主机之间的进出通信。
b、该方式自身携带同步机制,不需要额外的方式来辅助实现同步。
c、随进程持续。
2.共享内存
a、最快的一种通信方式,多个进程可同时访问同一片内存空间,相对其他方式来说具有更少的数据拷贝,效率较高。
b、需要结合信号灯或其他方式来实现多个进程间同步,自身不具备同步机制。
c、随内核持续,相比于随进程持续生命力更强。
3.管道
a、较早的一种通信方式,缺点明显:只能用于有亲缘关系进程之间的通信;只支持单向数据流,如果要双向通信需要多创建一个管道来实现。
b、自身具备同步机制。
c、随进程持续。
4.FIFO
a、是有名管道,所以支持没有亲缘关系的进程通信。和共享内存类似,提供一个路径名字将各个无亲缘关系的进程关联起来。但是也需要创建两个描述符来实现双向通信。
b、自身具备同步机制。
c、随进程持续。
5.信号
a、这种通信可携带的信息极少。不适合需要经常携带数据的通信。
b、不具备同步机制,类似于中断,什么时候产生信号,进程是不知道的。
6.消息队列
a、与共享内存和FIFO类似,使用一个路径名来实现各个无亲缘关系进程之间的通信。消息队列相比于其他方式有很多优点:它提供有格式的字节流,减少了开发人员的工作量;消息具有类型(system V)或优先级(posix)。其他方式都没有这些优点。
b、具备同步机制。
c、随内核持续。
3、本实验只模拟实现了一个产品的放入与取出,请修改代码,以模拟实现多个产品的放入与取出。
适用
-
管道:只能用于具有亲缘关系的进行通信,使用面相对较窄,实际开发中较少使用;
-
FIFO(命名管道):可以用于任意进程间的通信,对于大块数据的传输效率较高,可应用于单进程大量数据传递,和多个进程向一个进程传递数据;
-
信号:无法传递数据,而且信号的种类有限,只适用于完成一些简单的事件通知任务,如配置跟新信号通知,一个服务通过信号告知另一个服务自身状态;
-
共享内存:最为高效的进程间通信方式,进程可以直接读写内存,不需要任何数据拷贝,适用于多个进程共享数据,或进程间频繁的进行大量的数据交互;–建议使用mmap方式;
-
消息队列:进程间传递简单的命令和控制消息,如配置更新通知,多进程对多进程的通信等,可以简化代码逻辑;–建议使用全双工管道替代;
-
信号量:某种资源数为N,多个进程都在使用该资源,为了进行进程间的互斥,可以使用初始值为N的信号量;–建议使用记录锁替代;
-
多线程并发与多进程并发有何不同与相同之处?
多进程并发与多线程并发的区别主要在有没有共享数据,多进程间的通信较复杂且代价较大,主要的进程间通信渠道有管道、信号、文件、套接字等。
多线程并发只是表面和感觉上的并发,并不是实质上的并发。一个线程要运行,它必须占有CPU,而我们目前用的计算机大多都是单CPU的,所以一次最多只能有一个线程获取CPU并运行。多线程的实质是“最大限度地利用CPU资源”,当某一个线程的处理不需要占用CPU而只需要和I/O等资源打交道时,让其他线程有机会获得CPU资源。虽然CPU只有一个,但是它在多个线程之间频繁切换,当切换的频率高到一定程度时,我们就感觉所有的线程在同时运行,于是感觉这多个线程是并发的。
多进程并发是将应用程序分为多个、独立的、单纯和的进程,它们运行在同一时刻,就像你可以同时进行网页浏览和文字处理,这些独立的进程可以通过所有常规的进程间通信渠道互相传递信息(信号、套接字、文件、管道等)。并使用独立的进程实现并发,可以在网络连接的不同的机器上运行独立的进程,虽然这增加了通信成本,但在一个精心设计的系统上,这可能是一个提高并行可用行和提高性能的低成本方法。
5. 模拟实现读者-写者问题。
模拟读者写者问题:
利用多线程模拟读者与写者对临界区的互斥访问。读者和写者问题的读写操作限制:可以有一个或多个数量的读进程同时读这个文件;一次只有一个写进程可以写文件;若一个写进程正在写文件,则禁止任何读进程读文件;即读读允许、读写互斥、写写互斥。
在读者写者问题中,使用读者优先和写者优两种解决方案。在读者优先策略中,读进程具有优先权,也就是说,当至少有一个读进程在读时,随后的读进程就无需等待,可以直接开始读操作,此过程中写进程可能会饥饿。在写者优先策略中,写进程具有优先权,写者优先与读者优先类似。不同之处在于一旦一个写者到来,它应该尽快对文件进行写操作,如果有一个写者在等待,则新到来的读者不允许进行读操作,读者必须等到没有写者处于等待状态才能开始读操作。
算法描述:
读者优先描述
如果读者来:
-
无读者、写着,新读者可以读;
-
无写者等待,但有其他读者正在读,新读者可以读;
-
有写者等待,但有其他读者正在读,新读者可以读;
-
有写者写,新读者等
如果写者来:
-
无读者,新写者可以写;
-
有读者,新写者等待;
-
有其他写者写或等待,新写者等待
写者优先描述
如果读者来:
-
无读者、写者,新读者可以读;
-
无写者等待,但有其他读者正在读,新读者可以读;
-
有写者等待,但有其他读者正在读,新读者等;
-
有写者写,新读者等
如果写者来:
-
无读者,新写者可以写;
-
有读者,新写者等待;
-
有其他写者或等待,新写者等待
信号量和互斥锁的区别
互斥量用于线程的互斥,信号量用于线程的同步。
这是互斥量和信号量的根本区别,也就是互斥和同步之间的区别。
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源
互斥量值只能为0/1,信号量值可以为非负整数。
也就是说,一个互斥量只能用于一个资源的互斥访问,它不能实现多个资源的多线程互斥问题。信号量可以实现多个同类资源的多线程互斥和同步。当信号量为单值信号量是,也可以完成一个资源的互斥访问。
互斥量的加锁和解锁必须由同一线程分别对应使用,信号量可以由一个线程释放,另一个线程得到。
读者优先
使用互斥锁来确保同一时间只能一个进程写文件,实现互斥。使用信号量来实现访问资源的同步。
首先,写者的代码应该是这样一种形式,才能保证同一时刻只有一个写者修改数据。
考虑到写者对读者的影响是:当任何读者想读时,写者都必须被阻塞;并且,读者阻塞了写者并停止阻塞之前,后续的任何写者都会读者优先于执行。这就如同有一个读者队列,当第一个读者入队时,写者完全被阻塞,直到最后一个读者离开队列。
据此,可以用 readerCnt来统计读者的数量,而用信号量 sem_read来互斥各线程对 readerCnt的访问。


















 2272
2272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











