







1.简单随机抽样
抽取的样本满足两点:
(1)样本X1,X2...Xn是相互独立的随机变量。
(2)样本X1,X2...Xn与总体X同分布。
联合分布函数:
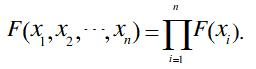
联合概率密度:![]()
2.似然函数:
给定联合样本值x关于参数θ的函数:
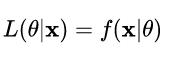
其中x是随机变量X取得的值,θ是未知的参数。
![]() 是密度函数,表示给定θ下的联合密度函数。
是密度函数,表示给定θ下的联合密度函数。
似然函数是关于θ的函数而密度函数是关于x的函数。
离散情况下 :
概率密度函数:
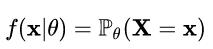
表示在参数θ的下随机变量X取到x的可能性
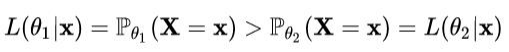
如果有上式成立,则在参数θ1下随机变量X取到x值的可能性大于θ2
连续情况下 :
如果X是连续随机变量给定足够小的ε>0,那么其在(x-ε,x+ε)内的概率为:
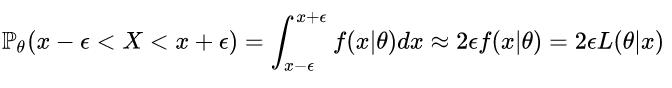
得到的结果与离散型一致!概率表达了在给定参数θ时X=x的可能性而似然表示的是在给定样本X=x时,参数的可能性!
3.极大似然估计
在一次吃鸡比赛中,有两位选手,一个是职业选手,一个是菜鸟路人。 比赛结束后,公布结果有一位选手完成20杀,请问是哪个选手呢?
估计我们都选职业选手, 因为我们会普遍认为概率最大的事件最有可能发生!
极大似然估计:在一次抽样中,得到观测值x1,x2...xn。 选取θ'(x1,x2...xn)作为θ的估计值,使得θ=θ'(x1,x2...xn)时样本出现的概率最大
极大似然估计 :
离散型样本:
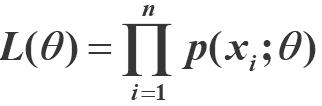
连续型样本:![]()
极大似然估计:![]()
极大似然估计求解
构造似然函数:
对似然函数取对数: ![]()
求偏导:![]()
求解得到θ值
例题:

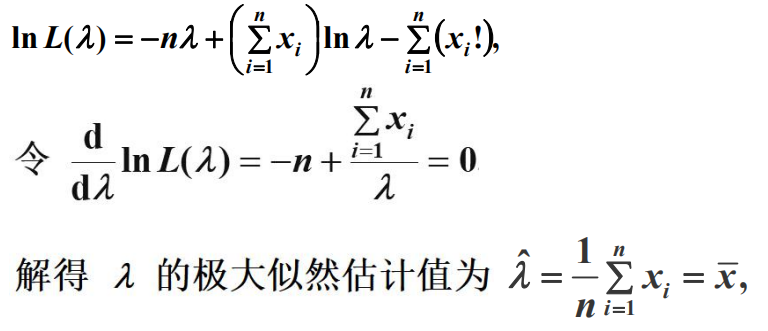
3.二维随机变量
以前我们只关心一个指标,现在要更操心了,例如根据学生的身高(X) 和体重(Y)来观察学生的身体状况。
这就不仅仅是X和Y各自的情况,还需要了解其相互的关系。
二维随机变量的联合函数:若(X,Y)是随机变量,对于任意的实数x,y
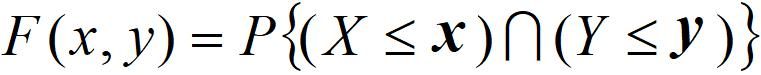
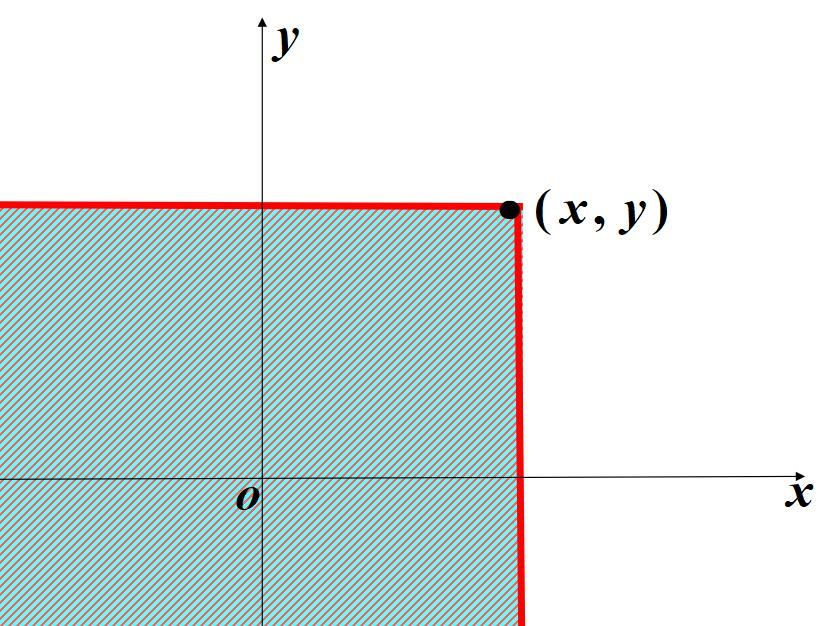
F(x,y)表示随机点(X,Y)在以(x,y)为顶点且位于该点左下方无穷矩形内的概率。
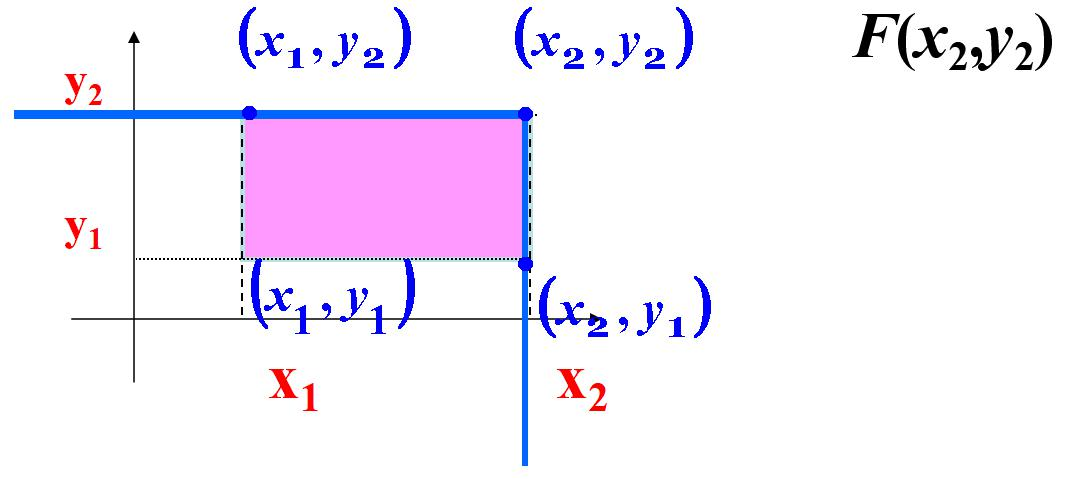
用联合分布函数F(x,y)表示矩形域概率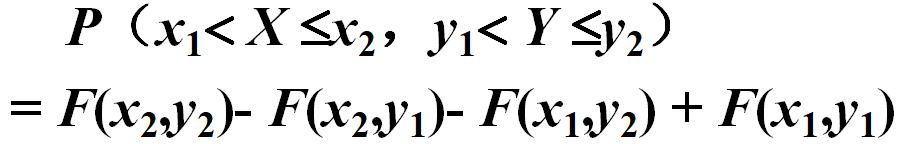
二维随机变量

4.二维随机变量的概率分布
若二维随机变量(
X,Y
)
全部可能取到的不同值是有限对或可列无限对, 则称(
X,Y
)
是离散型随机变量。

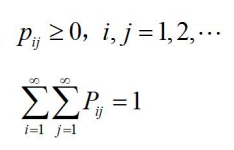
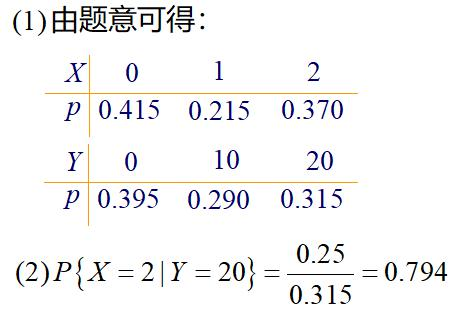
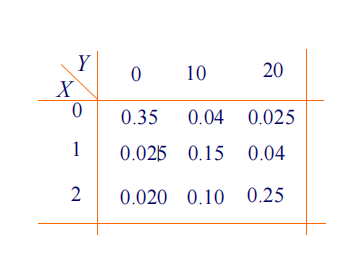
设随机变量X在1、2、3、4四个整数中等可能地取 一个值,另一个随机变量 Y在1~X中等可能地取一整数值,试求(X,Y)的联合概率分布。

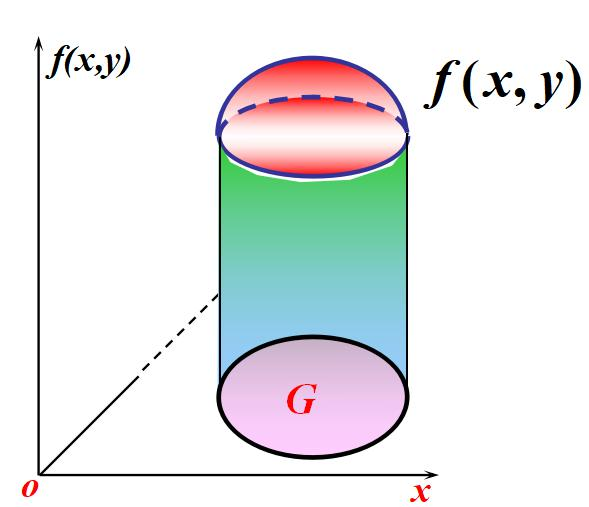
5.二维连续型随机变量
二维随机变量(X,Y)的分布函数 如果存在非负函数
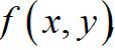
对于任意x,y有:![]()
称(X,Y)为连续型的二维随机变量, 为其概率密度。
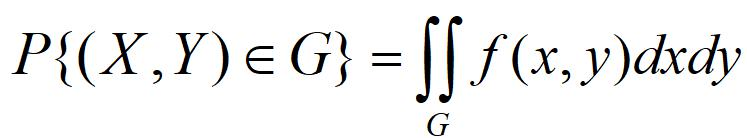

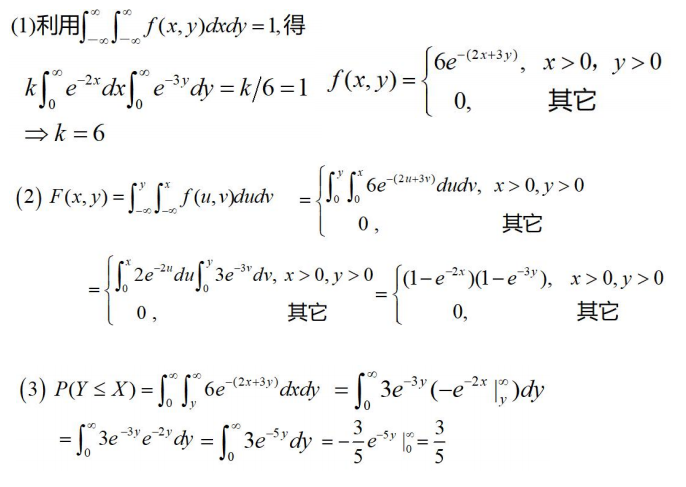
6.边缘分布
边缘分布函数:二维随机变量
(
X,Y)作为整体,有分布函数
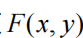
其中, X和Y都是随机变量,它们的分布函数记为:![]()
称为边缘分布函数。
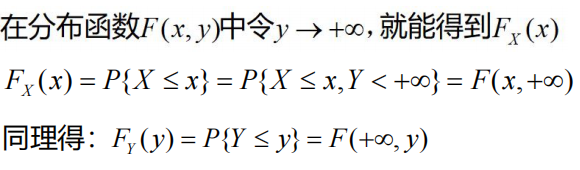
由联合分布函数可以得到边缘分布函数:

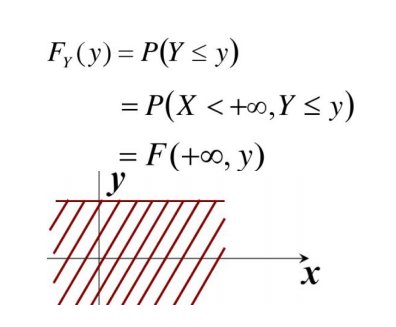
离散型的边缘分布
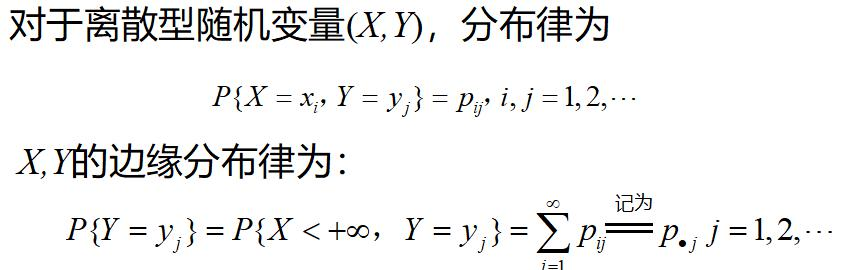
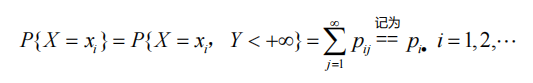

连续型的边缘概率密度:



7.期望
很多时候我们需要掌握的是一个具体的指标,比如粮食的平均产量, 一个地区家庭的平均年收入,贫富差距等。
离散型随机变量X的分布律为:
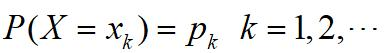


随机变量X满足于均匀分布,求其期望。
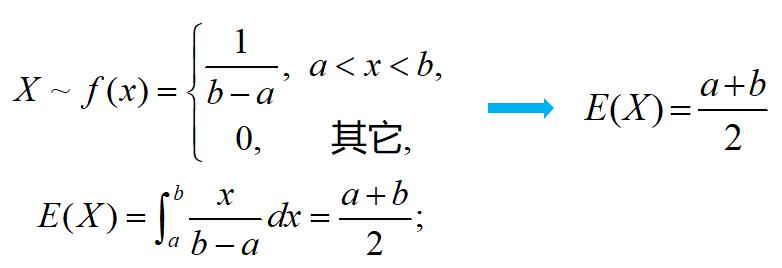
二维情况



数学期望的性质


8.方差
数学期望反映了随机变量的取值水平,衡量随机变量相对于数学期望的分散程度则的另一个数字特征。
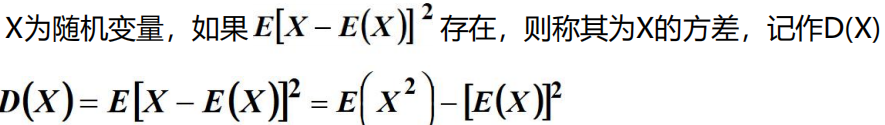
大数定理:
在试验不变的条件下,重复试验多次,随机事件的频率近似于它的概率。
9.马尔科夫不等式

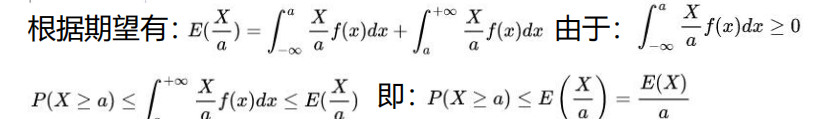
10.切比雪夫不等式
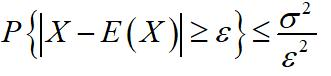


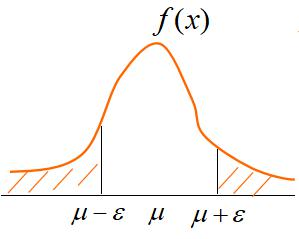
在n重贝努里试验中,若已知每次试验事件A出现的概率为0.75,试利用契比雪夫不等式估计n,使A出现的频率在0.74至0.76之间的概率不小于0.90。

11.中心极限定理

12.后验概率估计
最大似然估计:
找到最合适的参数使其满足数据:
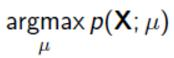
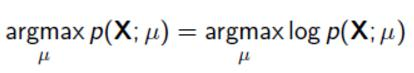
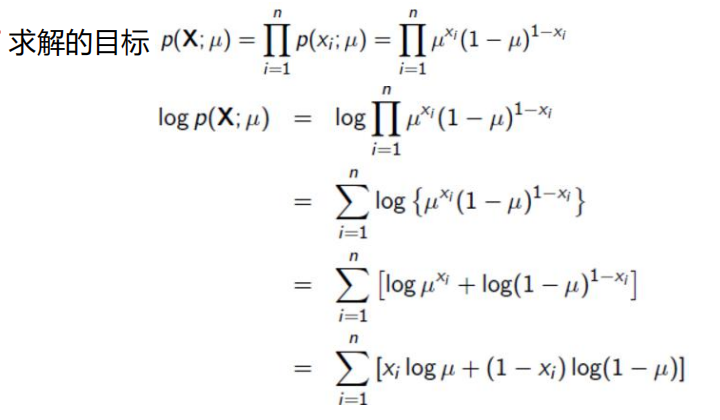
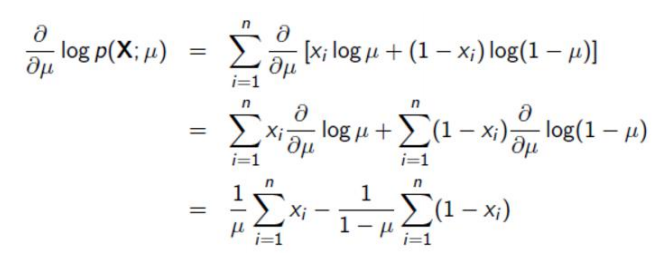
最大后验概率
问题变得复杂一点了,现在多了一个先验知识。
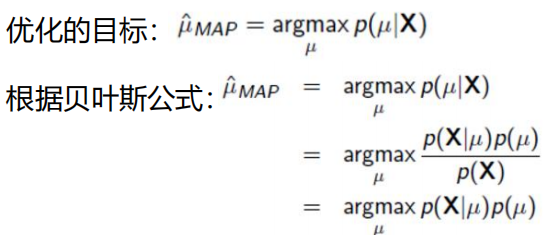
![]() 就是似然,
就是似然,![]() 这就是先验知识了。
这就是先验知识了。
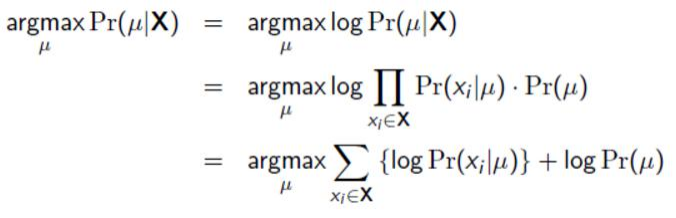


















 991
991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











