







相较于Deeplab v1改进措施就是将VGG16改为resnet 101,并且引入了ASPP层
1 INTRODUCTION
挑战1:
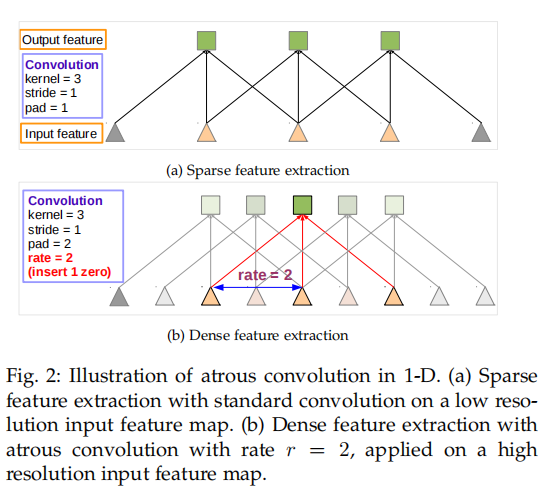
DCNN最初是为图像分类设计的,进行了不断的下采样。当DCNN以完全卷积方式[14]使用时,这导致特征图的空间分辨率显著降低。为了克服这一障碍并有效地生成更密集的特征图,从dcnn的最后几个最大池化层中删除了降采样算子,而是在随后的卷积层中对滤波器进行上采样,从而以更高的采样率计算特征图。在实施过程中,首先使用空洞卷积对特征图进行处理,在不增大参数数量的情况下,增大感受野,然后进行上采样。而不直接使用反转卷积
挑战2:
第二个挑战是由存在多个尺度的物体造成的。处理这一问题的一个标准方法是将同一图像的重新缩放版本呈现给DCNN,然后聚合特征或评分地图。这种方法确实提高了性能,但代价是以为输入图像的多个缩放版本计算所有DCNN层的特征响应为代价的。论文提出的替代方案为ASPP,即在卷积之前以多个空洞率的空洞卷积重采样给定的特征层。这相当于使用具有互补的感受野的多个滤波器来探测原始图像,从而在多个尺度上捕获目标和有用的图像上下文。
挑战3:
目标中心分类器需要对空间转换的不变性,这固有地限制了DCNN的空间准确性。论文使用全连通条件随机场(CRF)[22]来提高模型捕获细节的能力。CRFs被广泛应用于语义分割,将多路分类器计算的类分数与像素与边缘[23]、[24]或超像素[25]的局部交互所捕获的低水平信息结合起来。
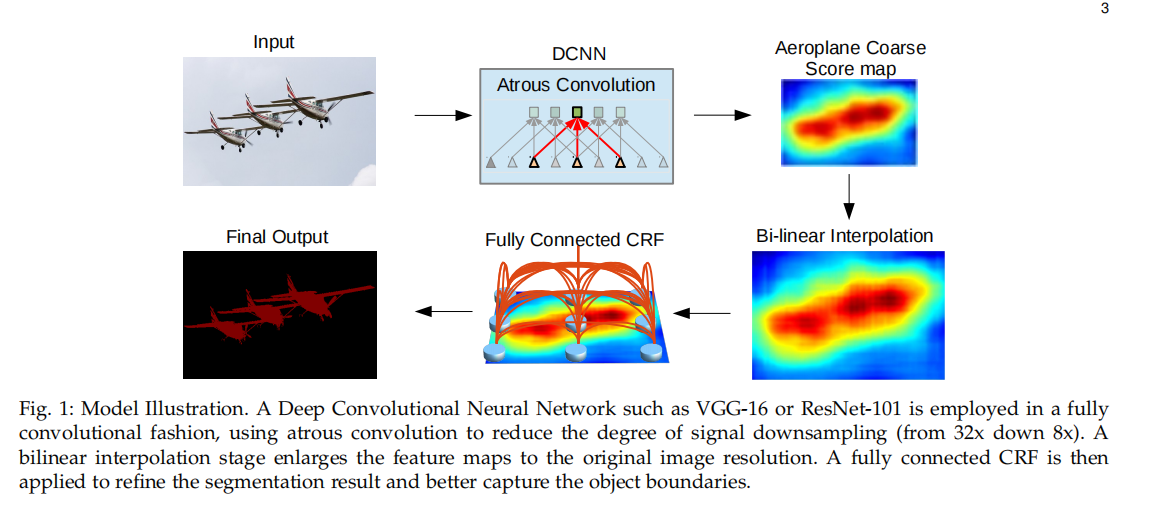
DeepLab模型如图1所示。深度卷积神经网络(VGG-16 [4]或ResNet-101[11])进行特征提取,需要注意的是在这个模型中,网络对原始图像下采样8倍而不是32倍。然后,使用双线性插值对分数图进行8倍的上采样,以达到原始图像的分辨率,产生输入到一个完全连接的CRF [22],从而细化分割结果。
与以前DCNN和CRF的结合的区别:
DCNN和CRF的结合并不是作者初创,但以前的工作只尝试了本地连接的CRF模型。具体来说,[53]使用CRFs作为基于DCNN的重新排序系统的建议机制,而[39]将超像素视为局部成对CRF的节点,并使用图剪切进行离散推理。因此,他们的模型受到超像素计算误差的限制或忽略了长期依赖的限制。
作者方法将每个像素视为一个接收DCNN一元势的CRF节点。采用的[22]全连接CRF模型中的高斯CRF势可以捕获长期依赖关系,同时该模型易于快速平均场推断。平均场推理已经在传统的图像分割任务[54],[55],[56]中得到了广泛的研究,但这些较老的模型通常仅限于短接连接。在独立的工作中,[57]使用一个非常相似的紧密连接的CRF模型来细化DCNN的材料分类问题的结果。然而,[57]的DCNN模块只通过稀疏点监督进行训练,而不是对每个像素进行密集监督。
3 METHODS
3.1 Atrous Convolution for Dense Feature Extraction and Field-of-View Enlargement
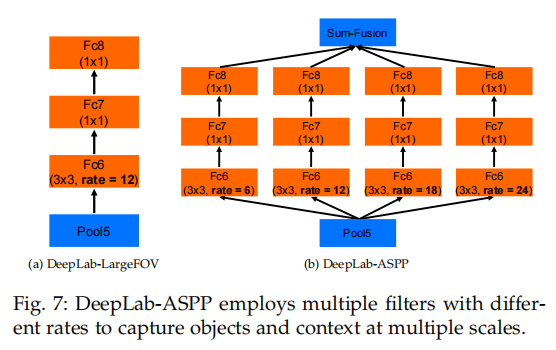
空洞卷积可以增大DCNN的感受野,dcnn通常使用空间小的卷积核(通常是3×3),以保持较小计算和参数的数量。在使用空洞率为r的空洞卷积后,在卷积核中填充r−1个0,在不增加参数数量或计算量的情况下,有效地扩大了感受野至k×k +(k−1,k−1)(r−1)。作者在DeepLab-LargeFOV模型变体[38]在VGG-16 ‘fc6’层中采用了与空洞率r = 12的空洞卷积,具有显著的性能提高

3.2 Multiscale Image Representations using Atrous Spatial Pyramid Pooling
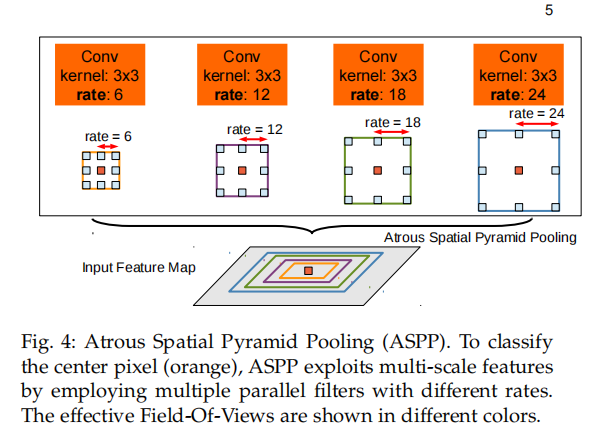
ASPP方法的灵感来自于[20]的R-CNN空间金字塔池方法的成功,该方法表明,通过对单尺度上提取的卷积特征进行重采样,可以准确有效地分类任意尺度的区域。论文实现了他们方案的一个变体,它使用多个不同采样率的并行卷积层。对每个采样率提取的特征在不同的分支中进行进一步处理,并进行融合,生成最终结果。所提出的“空洞空间金字塔池”(DeepLabASPP)方法应用于DeepLab-LargeFOV变体,如图4所示。
3.3 Structured Prediction with Fully-Connected Conditional Random Fields for Accurate Boundary Recovery
传统上,条件随机域CRF已经用来平滑噪声分割图。经典的一些模型包含耦合相邻结点的能量术语,有利于将相同标签分配给空间上邻近的像素。定性的说,这些短程CRF的主要功能是清除建立在局部手工设计特征之上的弱分类器的虚假预测。
但对于CNN来说,short-range CRFs可能会起到反作用,因为我们的目标是恢复局部信息,而不是进一步平滑图像。
E(x)模型能量函数:
公式表明只有具有不同标签的节点才会被惩罚。第二个表达式表示在不同的特征空间中使用两个高斯核;第一个,“双边”核同时依赖于像素位置(记为p)和RGB颜色(记为I),第二个核只依赖于像素位置。超参数σα、σβ和σγ控制了高斯核的尺度。第一个核强制具有相似颜色和位置的像素具有相似的标签,而第二个核在强制平滑时只考虑空间邻近性。
至关重要的是,该模型适合于有效的近似概率推理[22]。在一个完全可分解的平均场近似![]() 下的消息传递更新可以表示为双边空间中的高斯卷积。高维过滤算法[84]显著加快了计算速度,导致该算法在实践中非常快
下的消息传递更新可以表示为双边空间中的高斯卷积。高维过滤算法[84]显著加快了计算速度,导致该算法在实践中非常快
4 EXPERIMENTAL RESULTS
调整预先训练的VGG-16或ResNet-101网络的模型权重,以直接的方式使它们适应语义分割任务。我们将最后一层的1000类Imagenet分类器替换为一个21类分类器,损失函数是CNN输出图中每个空间位置的交叉熵项的和(与原始图像相比,下采样8倍)。所有的位置和标签在整体损失函数中的权重相等(除了未标记的像素被忽略)。目标是真实标签(下采样8倍)。通过[2]的标准SGD程序对所有网络层的权值进行优化目标函数。在DCNN和CRF训练阶段,假设在设置CRF参数时DCNN一元项是固定的。
在 PASCAL VOC 2012, PASCAL-Context, PASCAL Person-Part, and Cityscapes.都进行了实验
使用了在Imagenet上预先训练过的VGG-16网络,batch=20,初始学习率为0.001(最终的分类器层为0.01),每2000次迭代将学习率乘以0.1。动量为0.9,权重衰减为0.0005。
在在训练仪上对DCNN进行微调后,对CRF参数进行交叉验证。使用w2 = 3和σγ = 3的默认值,并通过对来自val的100张图像进行交叉验证来搜索w1、σα和σβ的最佳值。采用了一种从粗到细的搜索方案。参数的初始搜索范围为w1∈[3: 6]、σα∈[30: 10: 100]和σβ∈[3: 6](MATLAB表示法),然后围绕第一轮的最佳值细化搜索步骤大小。采用了10个平均场迭代。
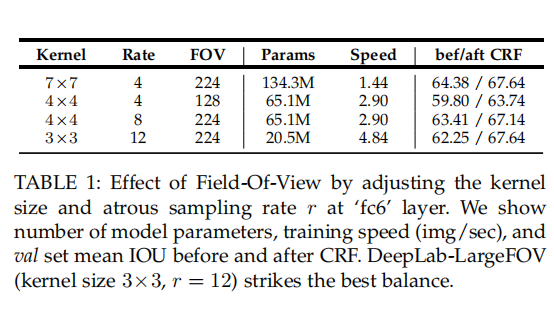
Field of View and CRF
使用的“atrous algorithm”,通过调整输入步幅来任意控制模型的感受野(FOV),如图1所示。作者在第一个全连接层上实验了几个核大小和输入步幅。该方法DeepLab-CRF-7x7是对VGG-16网络的直接修改,其中内核大小为=7×7,r=4。该模型在“val”集上产生了67.64%的性能,但它相对较慢(在训练期间每秒1.44张图像)。通过将内核大小降低到4×4,我们已经将模型速度提高到每秒2.9张图像。作者实验了两种不同FOV大小的网络变体,DeepLab-CRF和DeepLab-CRF-4x4;后者具有较大的FOV(即较大的输入步幅),并获得更好的性能。最后,作者采用内核大小为3的×3和r= 12,并进一步将最后两层的过滤器大小从4096更改为1024。生成的模型DeepLab-CRF-LargeFOV与昂贵的DeepLabCRF-7x7的性能相匹配。同时,它的运行速度快3.36倍,参数明显更少(20.5M而不是134.3M)。
Learning rate policy:
使用指数调度比使用分段调度更好。
Atrous Spatial Pyramid Pooling:



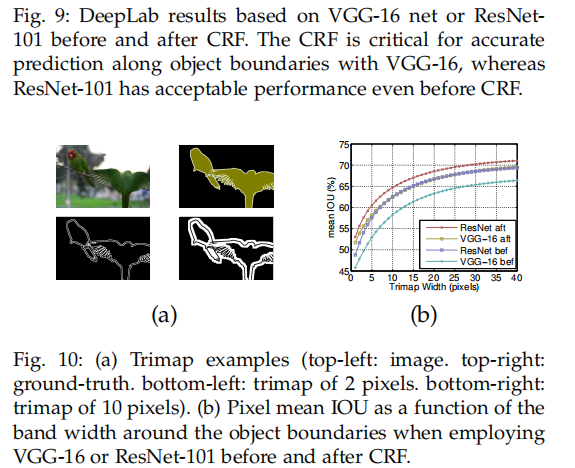
VGG-16 vs. ResNet-101:
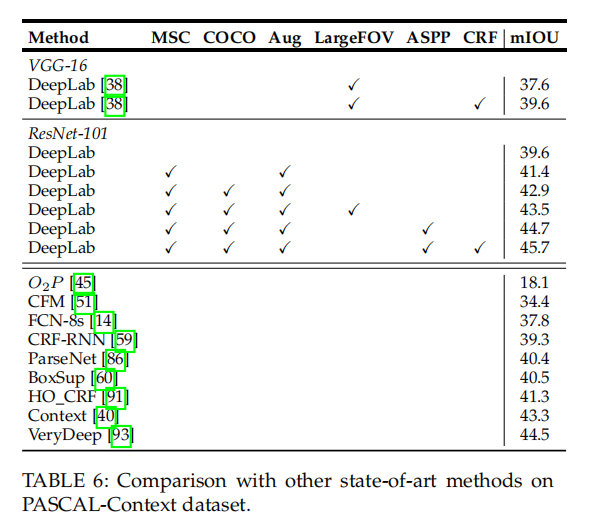
4.2 PASCAL-Context
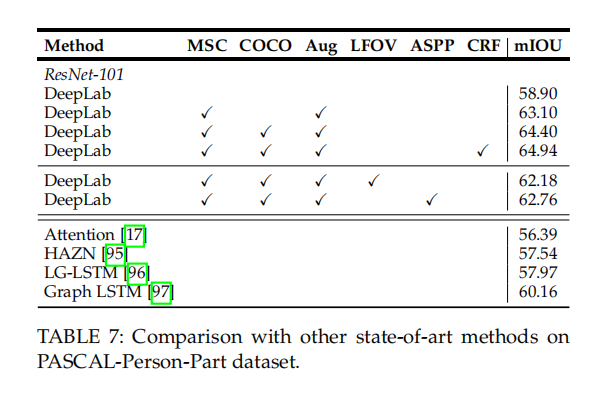

4.3 PASCAL-Person-Part

4.4 Cityscapes


















 2271
2271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











