







一、概述
1. 监督学习
定义:“ 从正确答案中学习 ”
input(x) \rightarrow output \space label(y)
-
回归算法:
预测数字 (eg. 房价)
-
分类算法:
对类型做出预测 (eg. 是否癌症)
2. 非监督学习
-
聚类算法:
将相似的数据点组合在一起 / 未标记的数据放入不同集群中 (eg. googlenews)
-
异常检测:
检测异常事件
-
降维:
将大数据集压缩成小数据集,且丢失尽可能少的数据
二、线性回归模型
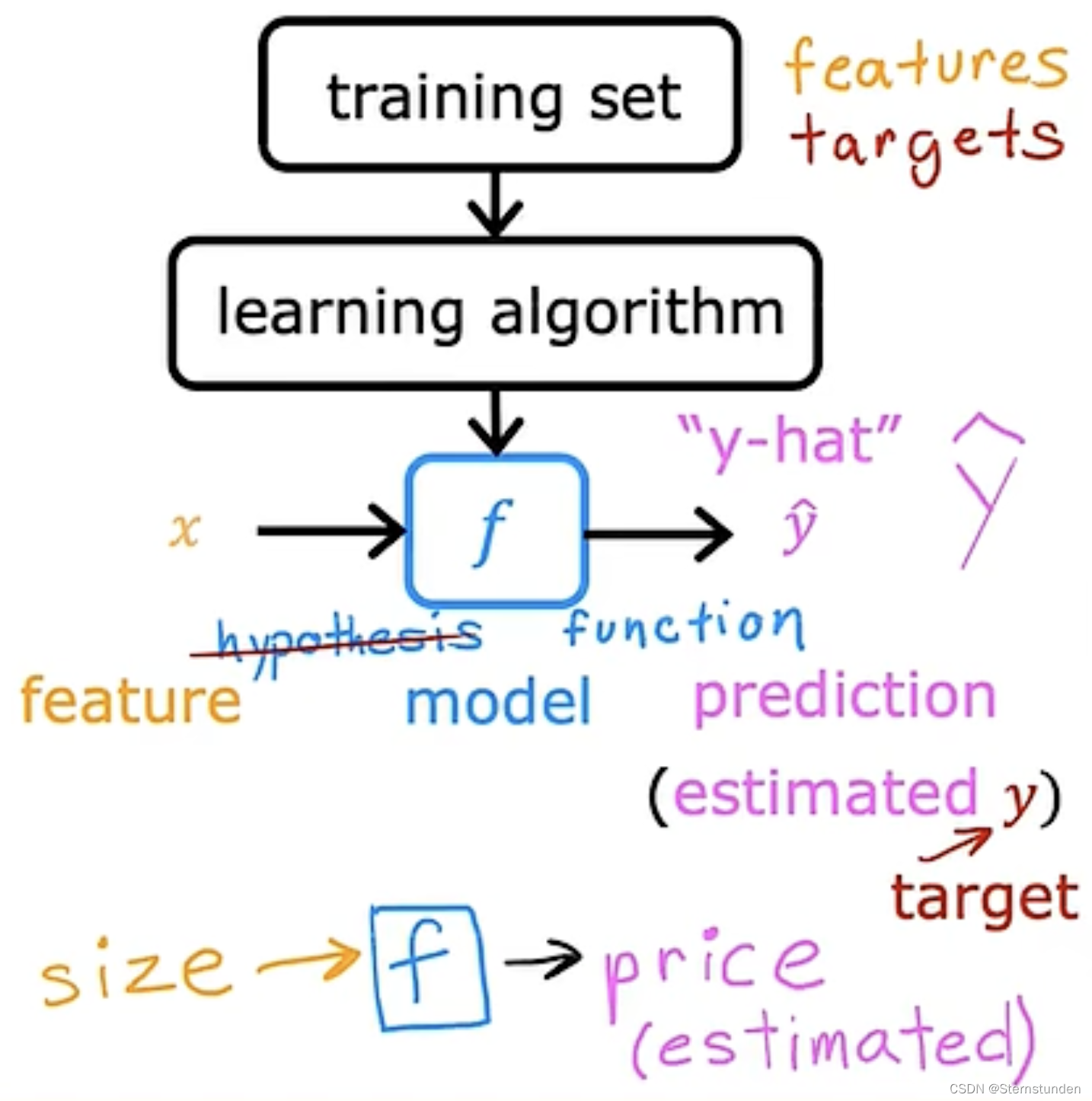
1. 机器学习符号

2. 过程
三、损失函数
model: f_{w,b} (x) = wx + b
w, b: 参数/系数/权重
1. 平方误差成本函数
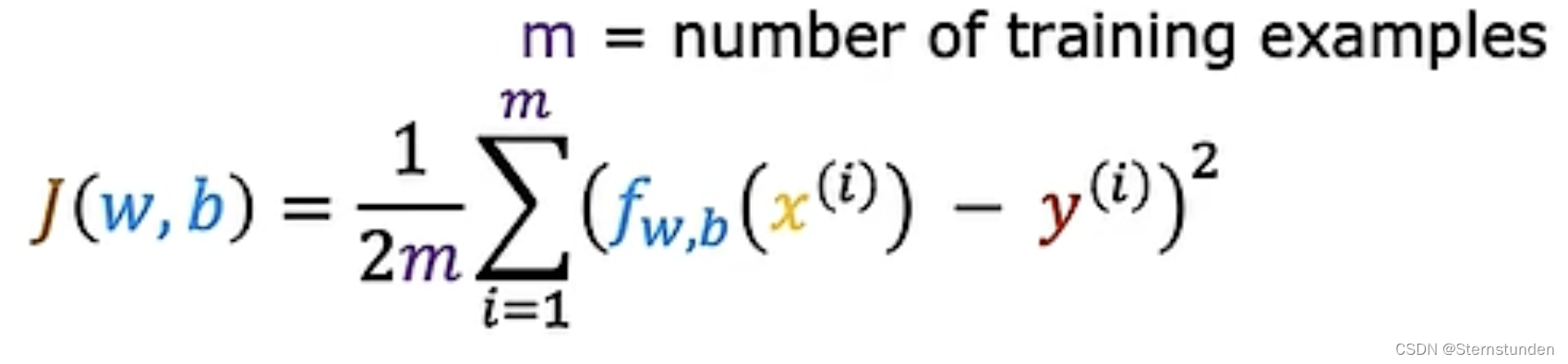
额外除以 2 : 使后面计算更简洁 (无论是否除,都有效)
2. 代价函数的直观理解
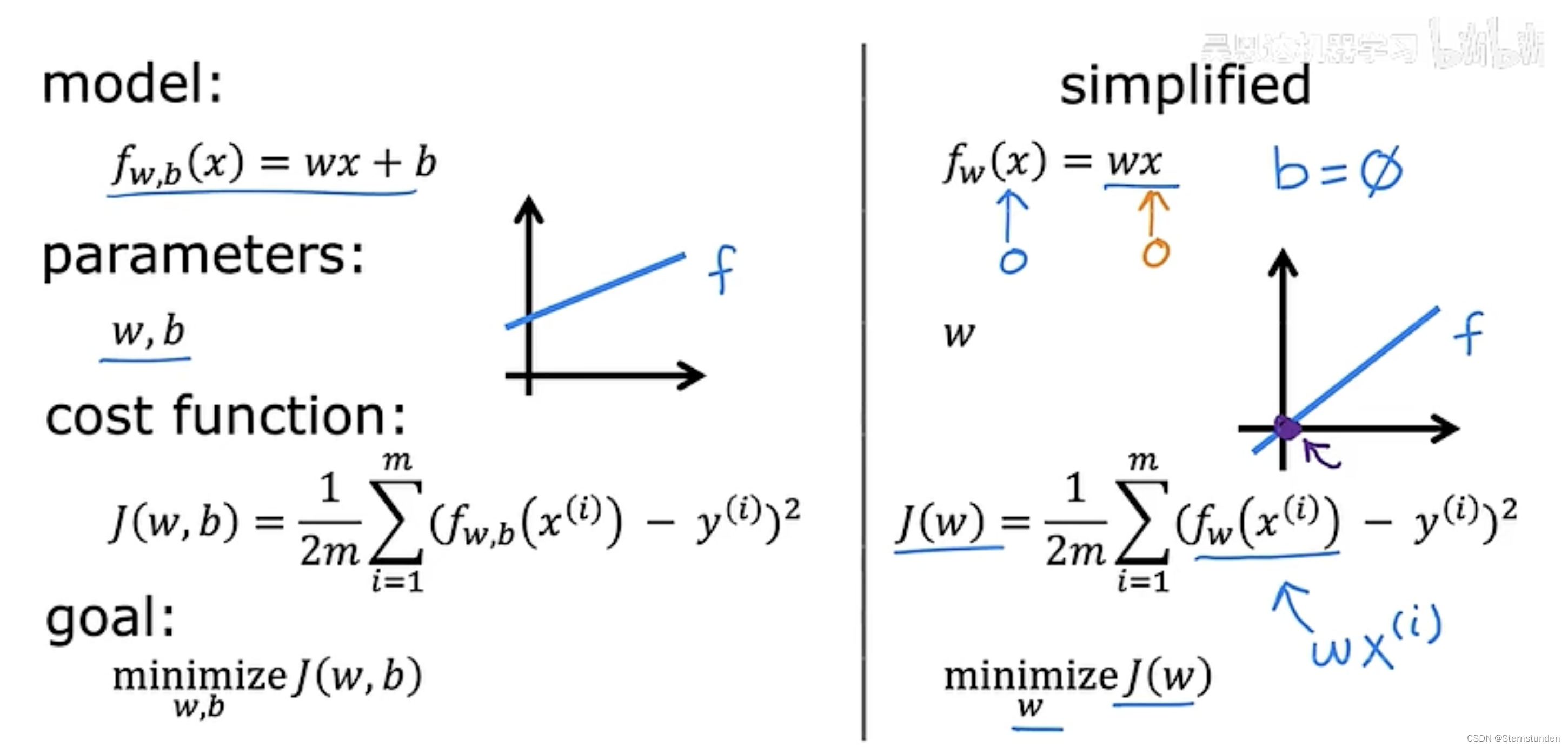
-
目标:
找到参数 w / w和b,使代价函数最小
-
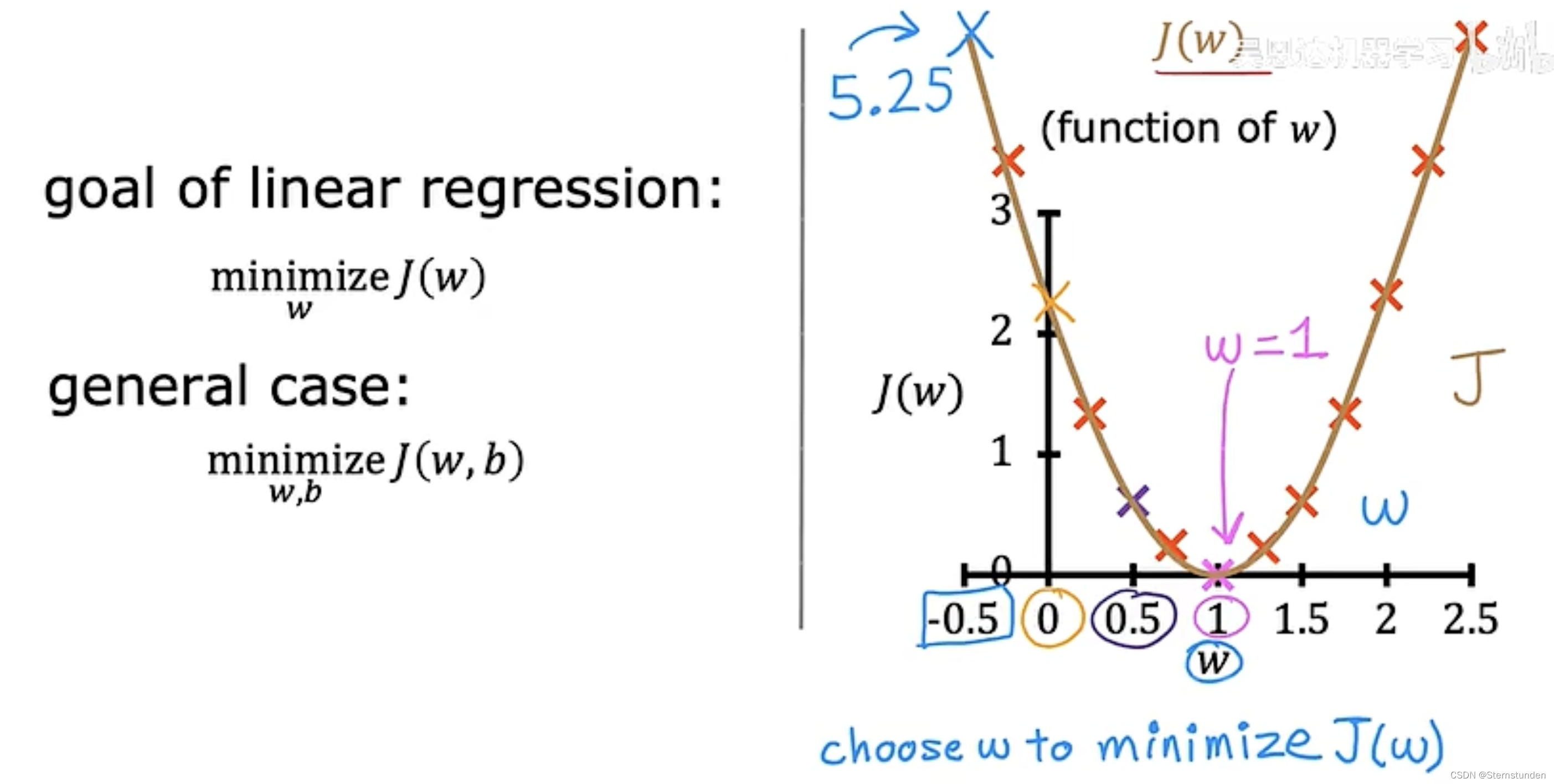
2. 可视化代价函数
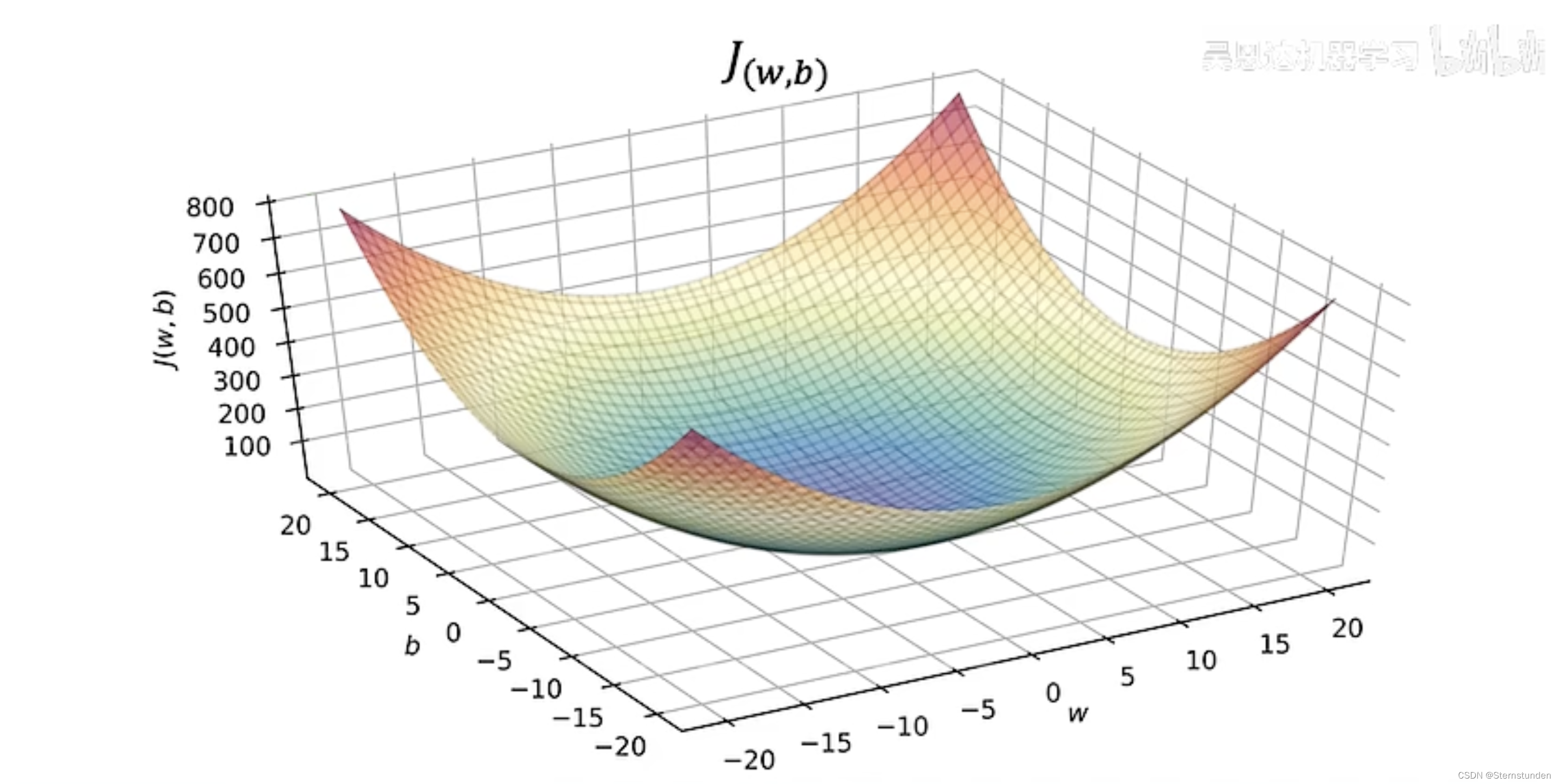
四、梯度函数
参数初始值并不重要,通常将它们设置为 0 \rightarrow 不同方向下坡、找局部最小值
1. 算法

\alpha:学习率 \rightarrow 控制下坡的步幅
2. 梯度下降算法的直观理解:找最小值
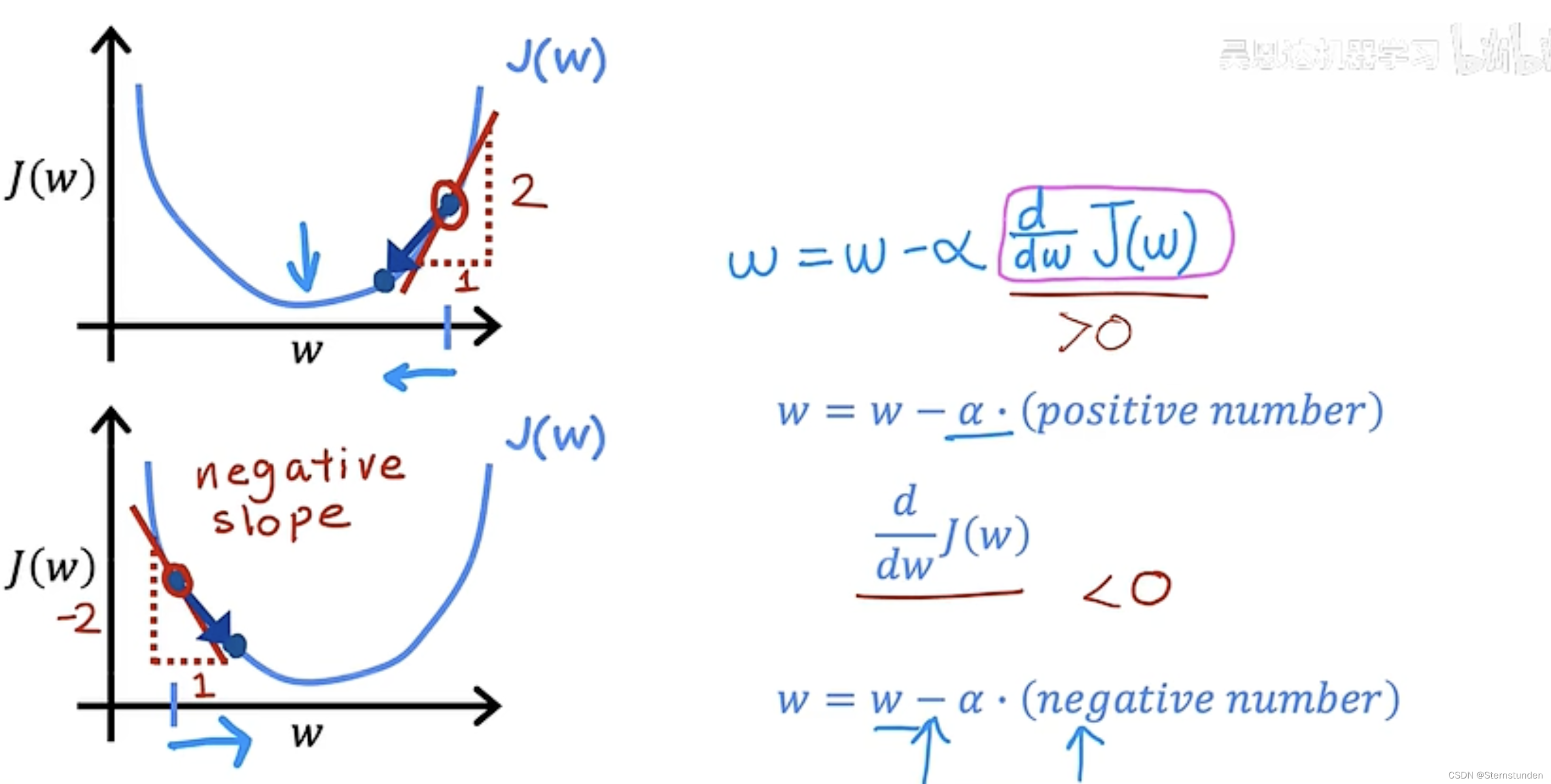
3. 学习率 \alpha
(1) \alpha 大小对梯度函数的影响
-
\alpha 太小:速度慢
-
\alpha 太大:无法收敛,甚至发散
-
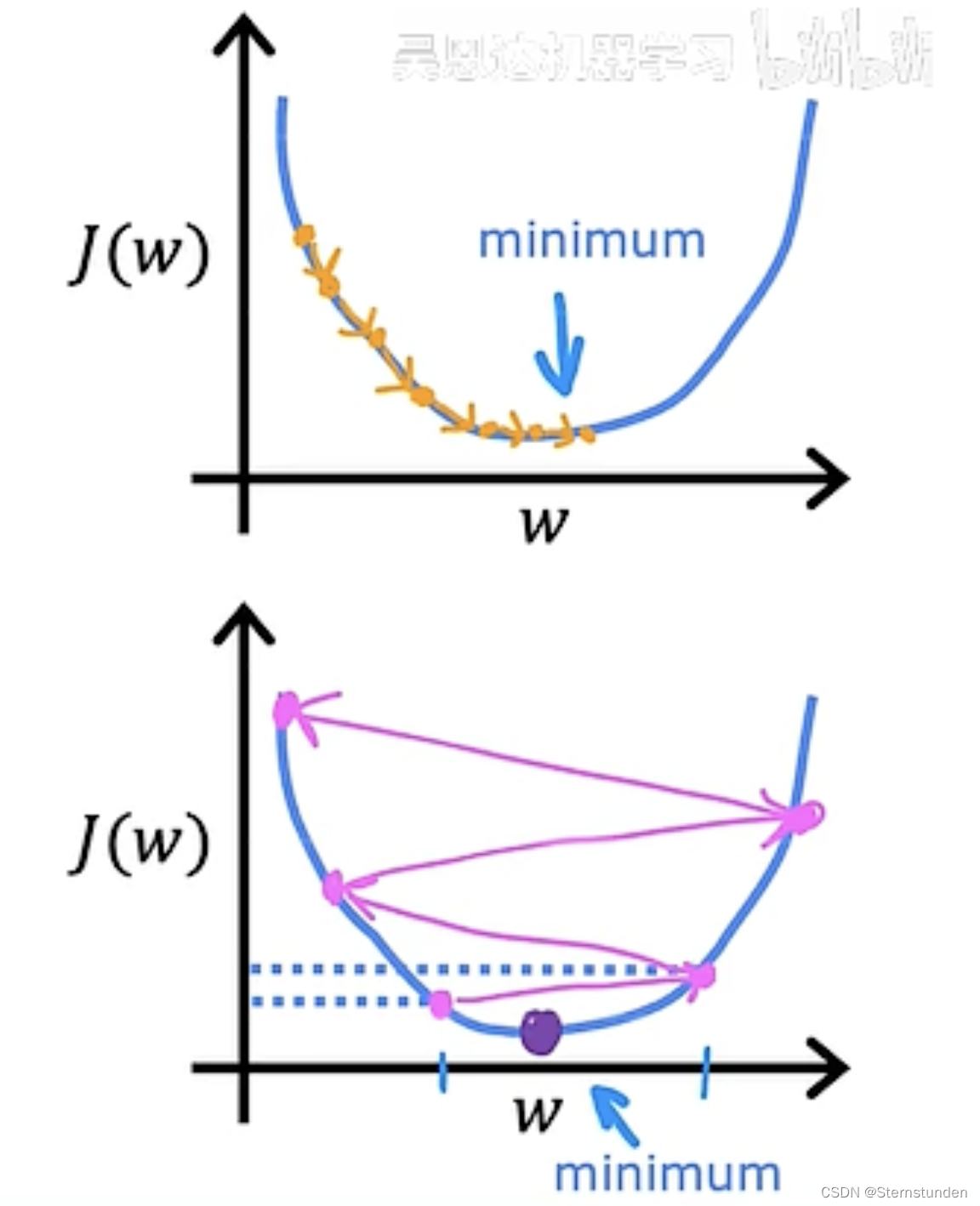
(2) 即使 \alpha保持固定值,当我们接近局部值时,导数自动变小,更新步骤也会自动变小。
五、具有梯度下降的线性回归模型
1. 推导细节
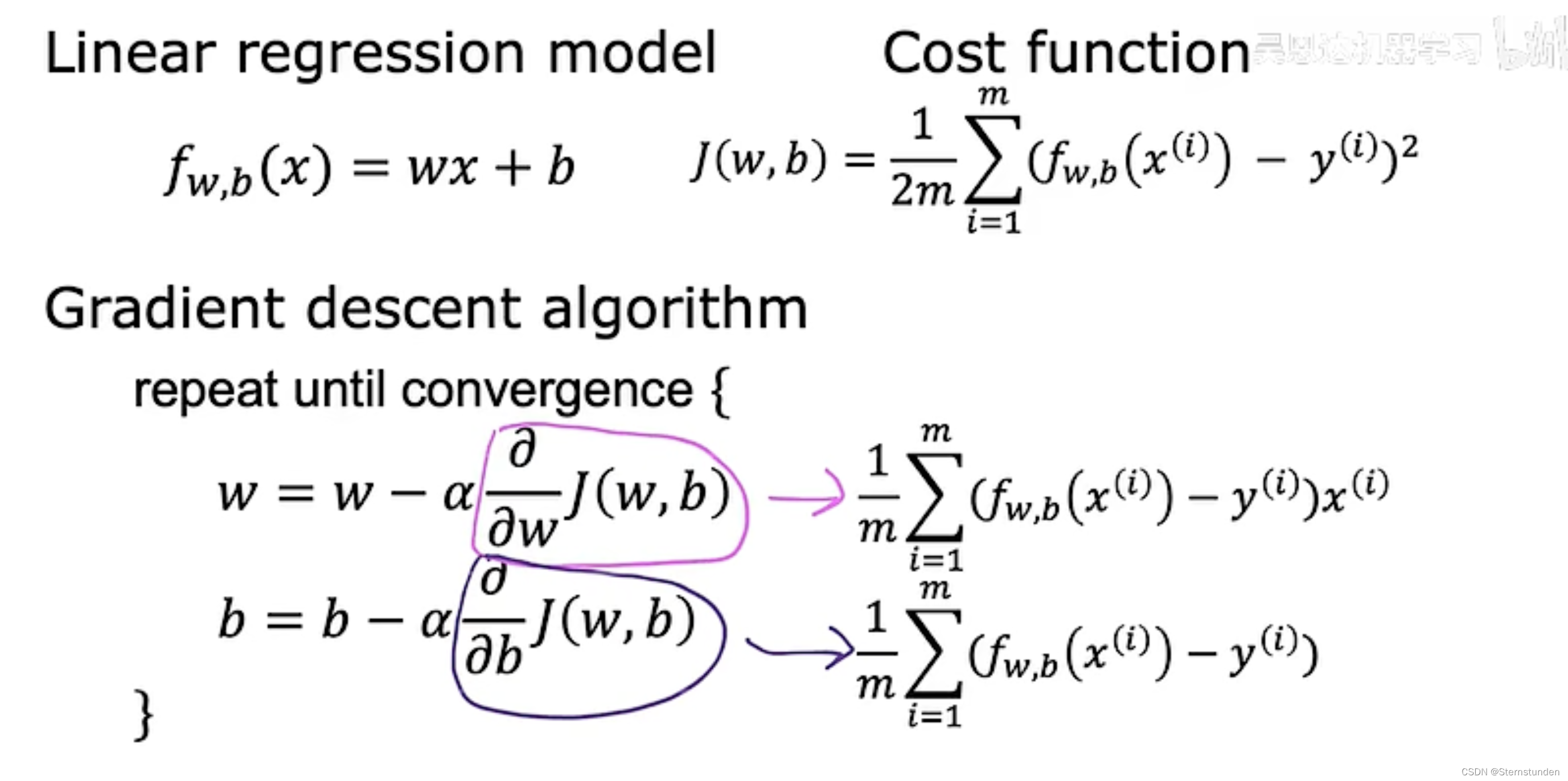
2. 算法

使用线性回归的平方误差成本函数时,成本函数不会有多个局部最小值 —— 是一个凸函数
3. 运行过程
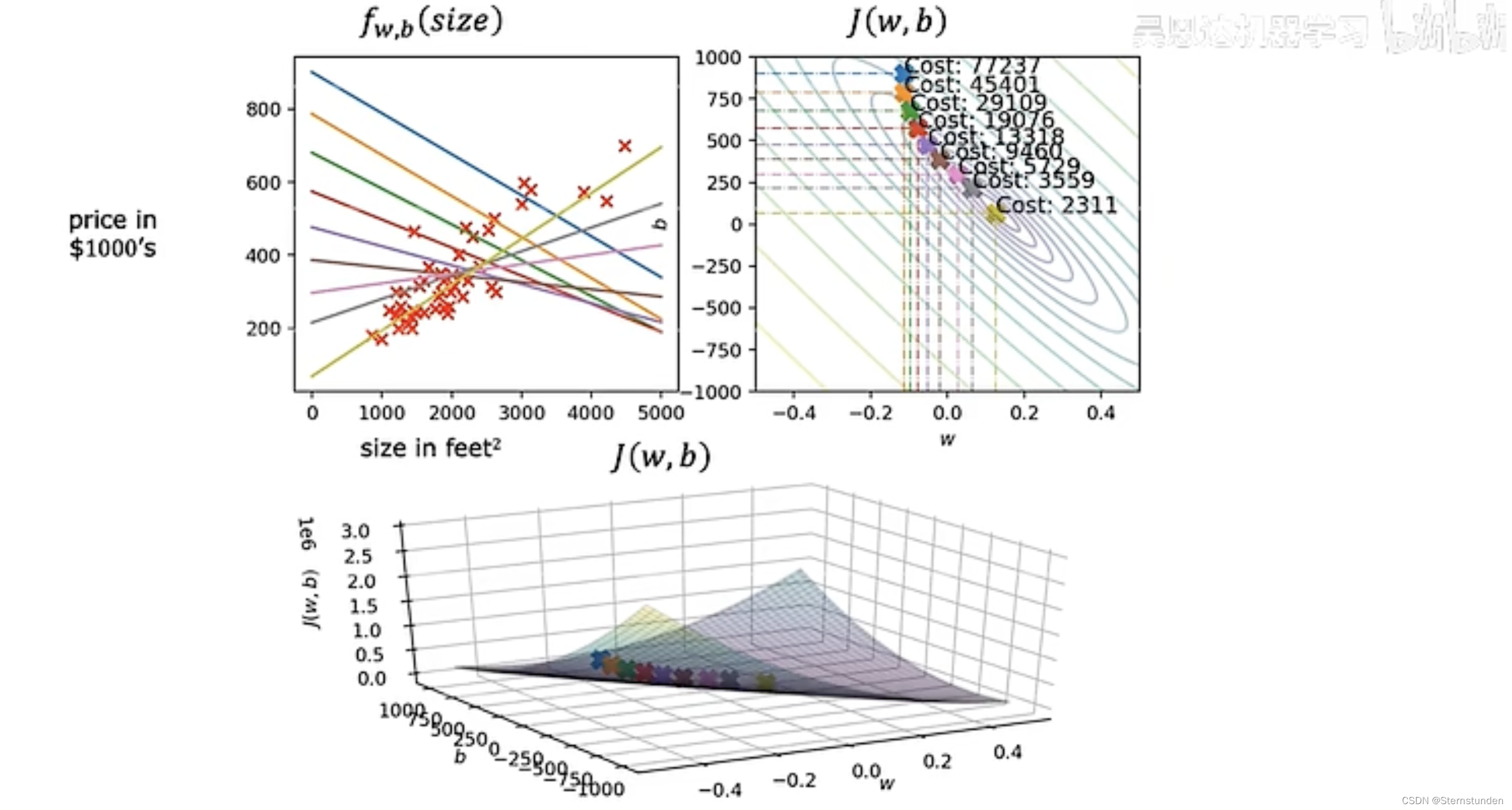
-
批梯度下降 ("Batch" gradient descent)
"Batch": 下降的每一步中,使用所有训练示例,而不仅仅是训练数据中的一个子集。















 4032
4032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









