






首先需要安装openvino、paddlepaddle、labelimg等模块,python版本需要小于3.8(可以通过虚拟环境创建),
classes.txt:
dog
cat
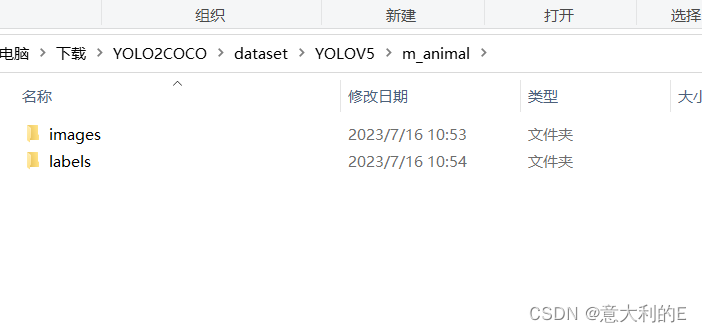
在这个位置运行gen.py
gen.py:
import os
def train_val(labels_path, data_path, ratio=0.3):
nomask_num = 0
mask_num = 0
image_dir = "\\".join(data_path.split("\\")[-3:]) + "\\images"
txt_files = os.listdir(labels_path)
f_train = open("train.txt", "w")
f_val = open("val.txt", "w")
m = 0
n = 0
for txt in txt_files:
f_txt = open(os.path.join(labels_path, txt), 'r')
if f_txt.read()[0] == "0":
nomask_num += 1
else:
mask_num += 1
f_txt.close()
for txt in txt_files:
f_txt = open(os.path.join(labels_path, txt), 'r')
if f_txt.read()[0] == "0":
n += 1
if n >= int(nomask_num * ratio):
f_train.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")
else:
f_val.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")
else:
m += 1
if m >= int(mask_num * ratio):
f_train.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")
else:
f_val.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")
f_txt.close()
f_train.close()
f_val.close()
if __name__ == "__main__":
data_path = os.path.join(os.getcwd(), "m_animal")
labels_path = os.path.join(data_path, "labels")
train_val(labels_path=labels_path, data_path=data_path, ratio=0.3)
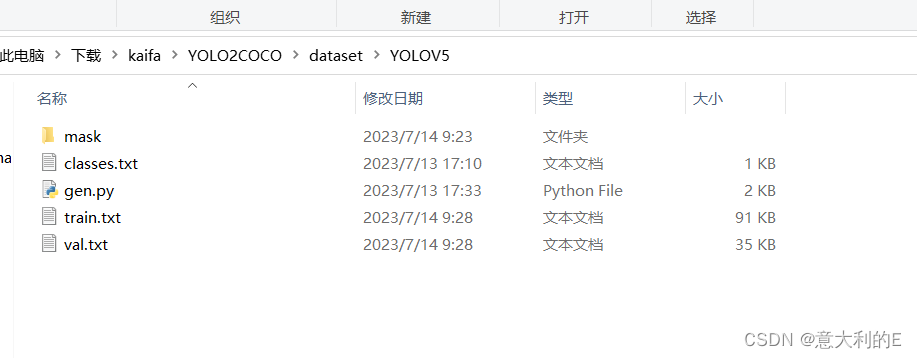
运行后产生train.txt、val.txt,在yolo2coco目录用控制台运行
python yolov5_2_coco.py --dir_path dataset/YOLOV5
yolov5_2_coco.py:
import argparse
from pathlib import Path
import json
import shutil
import cv2
def read_txt(txt_path):
with open(str(txt_path), 'r', encoding='utf-8') as f:
data = f.readlines()
data = list(map(lambda x: x.rstrip('\n'), data))
return data
def mkdir(dir_path):
Path(dir_path).mkdir(parents=True, exist_ok=True)
class YOLOV5ToCOCO(object):
def __init__(self, dir_path):
self.src_data = Path(dir_path)
self.src = self.src_data.parent
self.train_txt_path = self.src_data / 'train.txt'
self.val_txt_path = self.src_data / 'val.txt'
# 构建COCO格式目录
self.dst = Path(self.src) / f"{Path(self.src_data).name}_COCO_format"
self.coco_train = "train2017"
self.coco_val = "val2017"
self.coco_annotation = "annotations"
self.coco_train_json = self.dst / self.coco_annotation \
/ f'instances_{self.coco_train}.json'
self.coco_val_json = self.dst / self.coco_annotation \
/ f'instances_{self.coco_val}.json'
mkdir(self.dst)
mkdir(self.dst / self.coco_train)
mkdir(self.dst / self.coco_val)
mkdir(self.dst / self.coco_annotation)
# 构建json内容结构
self.type = 'instances'
self.categories = []
self.annotation_id = 1
# 读取类别数
self._get_category()
self.info = {
'year': 2021,
'version': '1.0',
'description': 'For object detection',
'date_created': '2021',
}
self.licenses = [{
'id': 1,
'name': 'GNU General Public License v3.0',
'url': 'https://github.com/zhiqwang/yolov5-rt-stack/blob/master/LICENSE',
}]
def _get_category(self):
class_list = read_txt(self.src_data / 'classes.txt')
for i, category in enumerate(class_list, 1):
self.categories.append({
'supercategory': category,
'id': i,
'name': category,
})
def generate(self):
self.train_files = read_txt(self.train_txt_path)
if Path(self.val_txt_path).exists():
self.valid_files = read_txt(self.val_txt_path)
train_dest_dir = Path(self.dst) / self.coco_train
self.gen_dataset(self.train_files, train_dest_dir,
self.coco_train_json)
val_dest_dir = Path(self.dst) / self.coco_val
if Path(self.val_txt_path).exists():
self.gen_dataset(self.valid_files, val_dest_dir,
self.coco_val_json)
print(f"The output directory is: {str(self.dst)}")
def gen_dataset(self, img_paths, target_img_path, target_json):
"""
https://cocodataset.org/#format-data
"""
images = []
annotations = []
for img_id, img_path in enumerate(img_paths, 1):
img_path = Path(img_path)
if not img_path.exists():
continue
label_path = str(img_path.parent.parent
/ 'labels' / f'{img_path.stem}.txt')
imgsrc = cv2.imread(str(img_path))
height, width = imgsrc.shape[:2]
dest_file_name = f'{img_id:012d}.jpg'
save_img_path = target_img_path / dest_file_name
if img_path.suffix.lower() == ".jpg":
shutil.copyfile(img_path, save_img_path)
else:
cv2.imwrite(str(save_img_path), imgsrc)
images.append({
'date_captured': '2021',
'file_name': dest_file_name,
'id': img_id,
'height': height,
'width': width,
})
if Path(label_path).exists():
new_anno = self.read_annotation(label_path, img_id,
height, width)
if len(new_anno) > 0:
annotations.extend(new_anno)
else:
raise ValueError(f'{label_path} is empty')
else:
raise FileExistsError(f'{label_path} not exists')
json_data = {
'info': self.info,
'images': images,
'licenses': self.licenses,
'type': self.type,
'annotations': annotations,
'categories': self.categories,
}
with open(target_json, 'w', encoding='utf-8') as f:
json.dump(json_data, f, ensure_ascii=False)
def read_annotation(self, txtfile, img_id,
height, width):
annotation = []
allinfo = read_txt(txtfile)
for label_info in allinfo:
# 遍历一张图中不同标注对象
label_info = label_info.split(" ")
if len(label_info) < 5:
continue
category_id, vertex_info = label_info[0], label_info[1:]
segmentation, bbox, area = self._get_annotation(vertex_info,
height, width)
annotation.append({
'segmentation': segmentation,
'area': area,
'iscrowd': 0,
'image_id': img_id,
'bbox': bbox,
'category_id': int(category_id)+1,
'id': self.annotation_id,
})
self.annotation_id += 1
return annotation
@staticmethod
def _get_annotation(vertex_info, height, width):
cx, cy, w, h = [float(i) for i in vertex_info]
cx = cx * width
cy = cy * height
box_w = w * width
box_h = h * height
# left top
x0 = max(cx - box_w / 2, 0)
y0 = max(cy - box_h / 2, 0)
# right bottomt
x1 = min(x0 + box_w, width)
y1 = min(y0 + box_h, height)
segmentation = [[x0, y0, x1, y0, x1, y1, x0, y1]]
bbox = [x0, y0, box_w, box_h]
area = box_w * box_h
return segmentation, bbox, area
if __name__ == "__main__":
parser = argparse.ArgumentParser('Datasets converter from YOLOV5 to COCO')
parser.add_argument('--dir_path', type=str,
default='.\\',
help='Dataset root path')
args = parser.parse_args()
converter = YOLOV5ToCOCO(args.dir_path)
converter.generate()
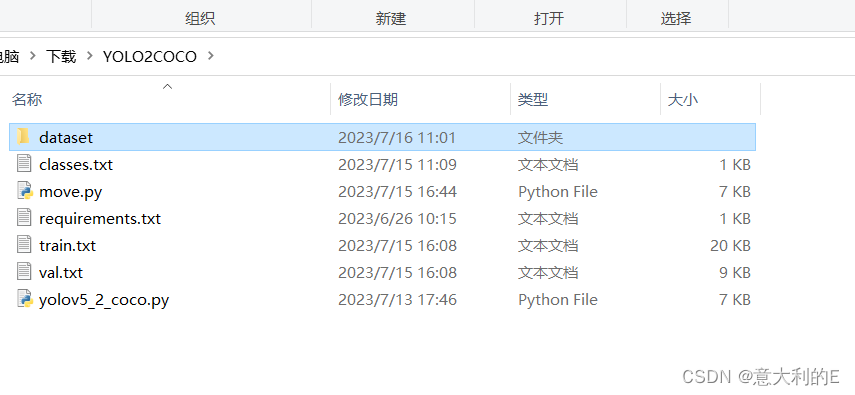
在YOLOV5_COCO_format就会产生3个文件夹,一起打包:
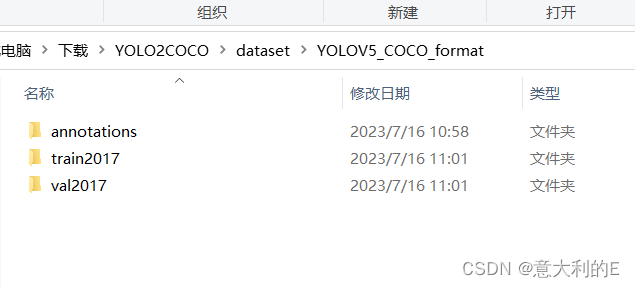
把打包文件上传到飞桨平台:
然后新建ppyoloe.ipynb
cd /home/aistudio/work
!git clone https://github.com/PaddlePaddle/PaddleYOLO.git
等待下载
下载完成后修改coco_detection.yml:
metric: COCO
num_classes: 2
TrainDataset:
name: COCODataSet
image_dir: train2017
anno_path: annotations/instances_train2017.json
dataset_dir: dataset/m_animal
data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']
EvalDataset:
name: COCODataSet
image_dir: val2017
anno_path: annotations/instances_val2017.json
dataset_dir: dataset/m_animal
TestDataset:
name: ImageFolder
anno_path: annotations/instances_val2017.json # also support txt (like VOC's label_list.txt)
dataset_dir: dataset/m_animal # if set, anno_path will be 'dataset_dir/anno_path'
压缩包解压到这个目录
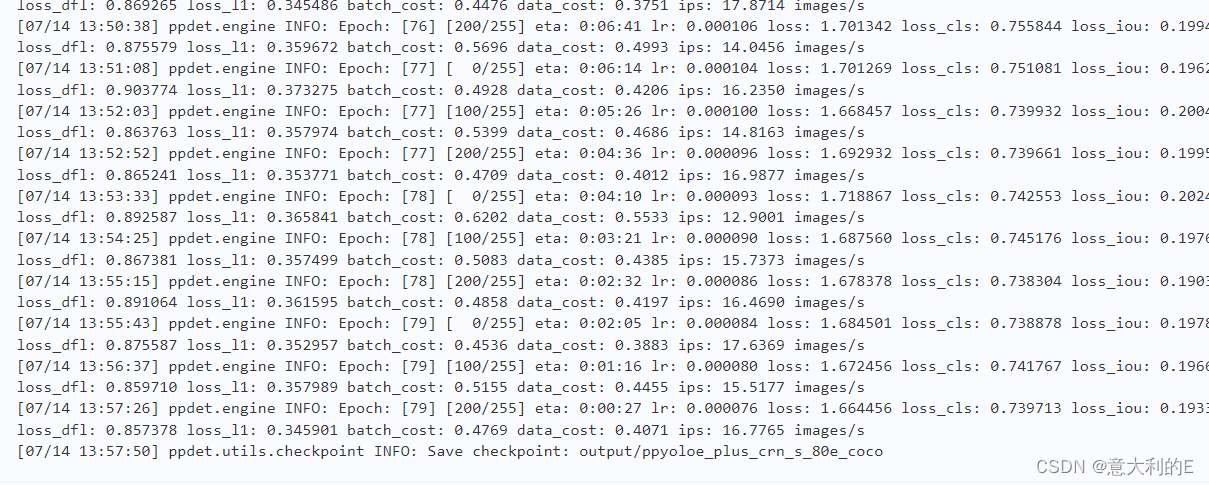
执行!python tools/train.py -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml 开始训练,训练时间因数据集大小和使用环境而异
然后执行:
!python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml -o weights=/home/aistudio/work/PaddleYOLO/output/ppyoloe_plus_crn_s_80e_coco/model_final.pdparams
导出模型会放置output文件夹下,把它们一起打包下载。
下面使用prune_paddle_model.py剪裁数据
prune_paddle_model.py:
import argparse
import paddle.fluid as fluid
def new_prepend_feed_ops(inference_program,
feed_target_names,
feed_holder_name='feed'):
import paddle.fluid.core as core
if len(feed_target_names) == 0:
return
global_block = inference_program.global_block()
feed_var = global_block.create_var(
name=feed_holder_name,
type=core.VarDesc.VarType.FEED_MINIBATCH,
persistable=True)
for i, name in enumerate(feed_target_names):
if not global_block.has_var(name):
print("The input[{i}]: '{name}' doesn't exist in pruned inference program, which will be ignored in new saved model.".format(i=i, name=name))
continue
out = global_block.var(name)
global_block._prepend_op(
type='feed',
inputs={'X': [feed_var]},
outputs={'Out': [out]},
attrs={'col': i})
def append_fetch_ops(program, fetch_target_names, fetch_holder_name='fetch'):
"""
In this palce, we will add the fetch op
"""
import paddle.fluid.core as core
global_block = program.global_block()
fetch_var = global_block.create_var(
name=fetch_holder_name,
type=core.VarDesc.VarType.FETCH_LIST,
persistable=True)
print("the len of fetch_target_names:%d" % (len(fetch_target_names)))
for i, name in enumerate(fetch_target_names):
global_block.append_op(
type='fetch',
inputs={'X': [name]},
outputs={'Out': [fetch_var]},
attrs={'col': i})
def insert_fetch(program, fetchs, fetch_holder_name="fetch"):
global_block = program.global_block()
need_to_remove_op_index = list()
for i, op in enumerate(global_block.ops):
if op.type == 'fetch':
need_to_remove_op_index.append(i)
for index in need_to_remove_op_index[::-1]:
global_block._remove_op(index)
program.desc.flush()
append_fetch_ops(program, fetchs, fetch_holder_name)
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('--model_dir', required=True, help='Path of directory saved the input model.')
parser.add_argument('--model_filename', required=True, help='The input model file name.')
parser.add_argument('--params_filename', required=True, help='The parameters file name.')
parser.add_argument('--output_names', required=True, nargs='+', help='The outputs of pruned model.')
parser.add_argument('--save_dir', required=True,
help='Path of directory to save the new exported model.')
return parser.parse_args()
if __name__ == '__main__':
args = parse_arguments()
if len(set(args.output_names)) < len(args.output_names):
print("[ERROR] There's dumplicate name in --output_names, which is not allowed.")
sys.exit(-1)
import paddle
#paddle.enable_static()
paddle.fluid.io.prepend_feed_ops = new_prepend_feed_ops
print("Start to load paddle model...")
exe = fluid.Executor(fluid.CPUPlace())
[prog, ipts, outs] = fluid.io.load_inference_model(args.model_dir, exe, model_filename=args.model_filename, params_filename=args.params_filename)
new_outputs = list()
insert_fetch(prog, args.output_names)
for out_name in args.output_names:
new_outputs.append(prog.global_block().var(out_name))
fluid.io.save_inference_model(args.save_dir, ipts, new_outputs, exe, prog, model_filename=args.model_filename, params_filename=args.params_filename)
执行命令:python prune_paddle_model.py --model_dir ppyoloe_crn_s_80 --model_filename model.pdmodel --params_filename model.pdiparams --output_names tmp_16 concat_14.tmp_0 --save_dir export_model
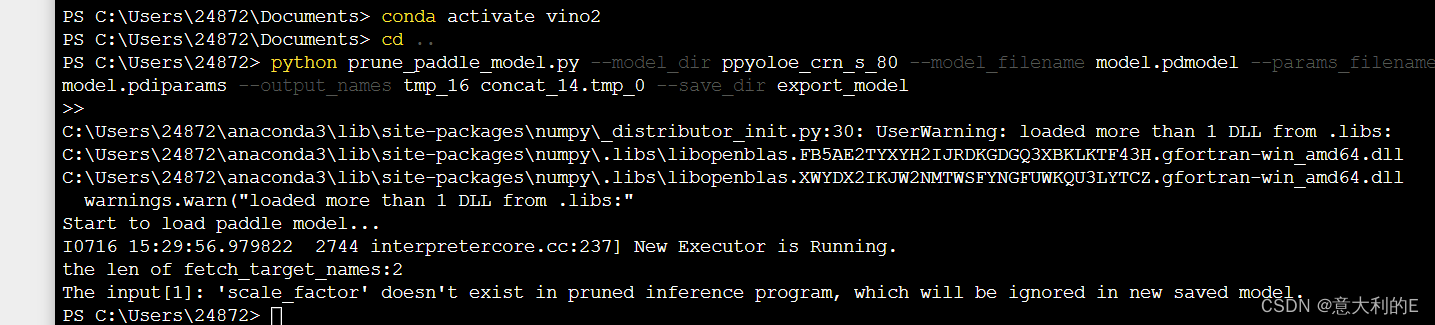
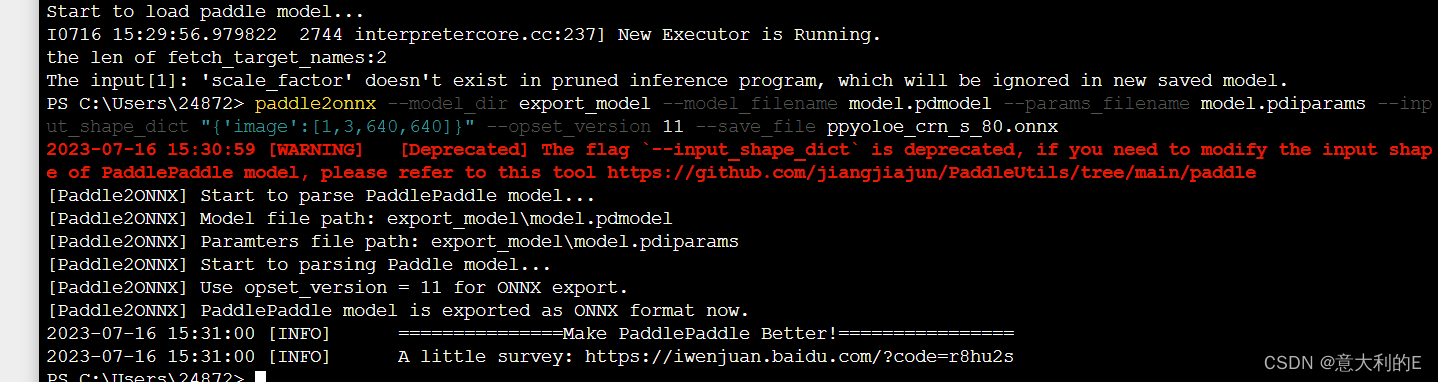
把paddle模型转换为onnx,需要提前安装paddle2onnx。执行以下命令:
paddle2onnx --model_dir export_model --model_filename model.pdmodel --params_filename model.pdiparams --input_shape_dict “{‘image’:[1,3,640,640]}” --opset_version 11 --save_file ppyoloe_crn_s_80.onnx
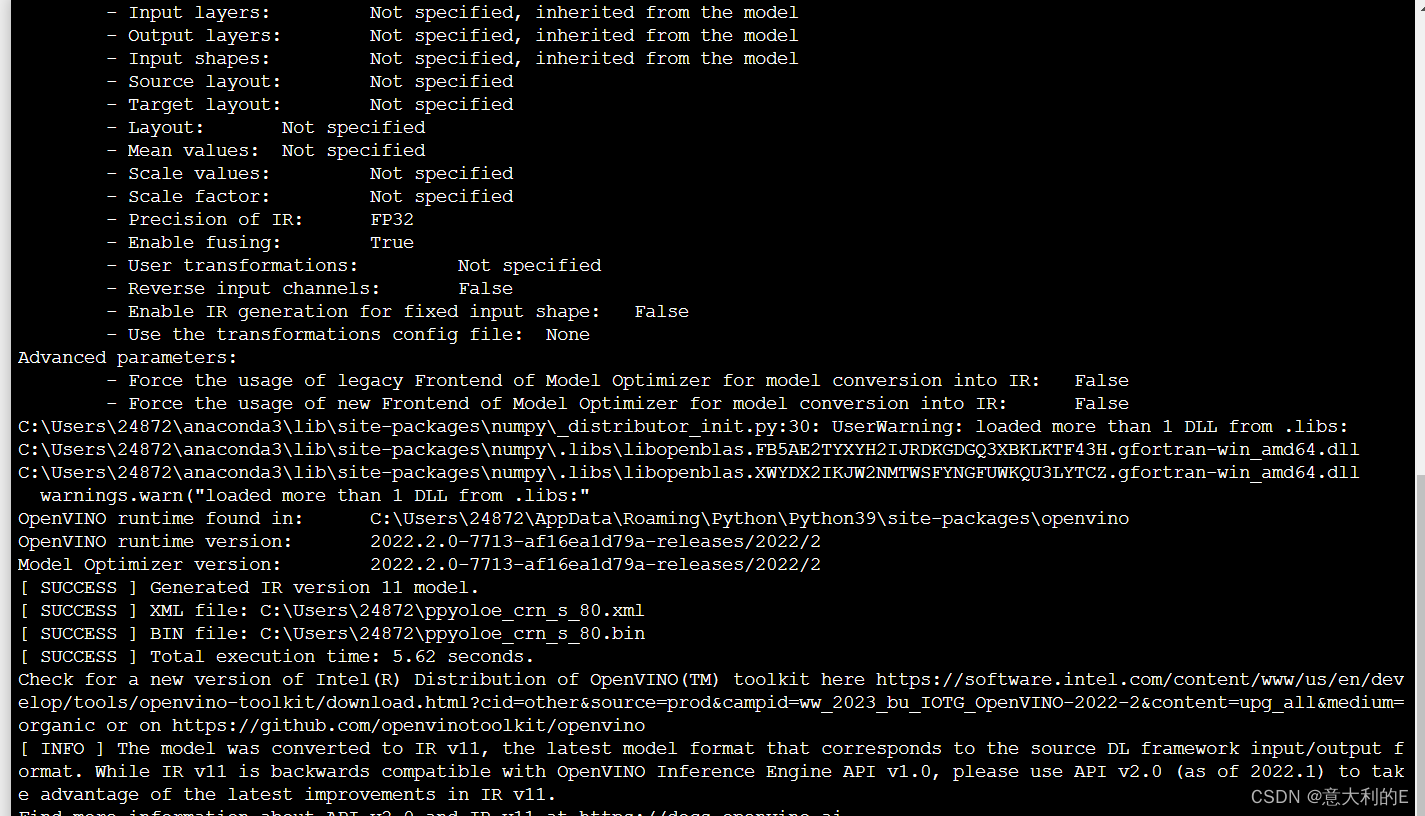
然后使用openvino进行处理,python运行环境应小于3.8
mo --input_model ppyoloe_crn_s_80.onnx
在当前目录加入labels.txt
dog
cat
运行dection.py:
from openvino.runtime import Core
import openvino.runtime as ov
import cv2 as cv
import numpy as np
import tensorflow as tf
class Predictor:
def __init__(self, model_path):
ie_core = Core()
model = ie_core.read_model(model=model_path)
self.compiled_model = ie_core.compile_model(model=model, device_name="CPU")
def get_inputs_name(self, num):
return self.compiled_model.input(num)
def get_outputs_name(self, num):
return self.compiled_model.output(num)
def predict(self, input_data):
return self.compiled_model([input_data])
def get_request(self):
return self.compiled_model.create_infer_request()
def process_image(input_image, size):
max_len = max(input_image.shape)
img = np.zeros([max_len,max_len,3],np.uint8)
img[0:input_image.shape[0],0:input_image.shape[1]] = input_image
img = cv.cvtColor(img,cv.COLOR_BGR2RGB)
img = cv.resize(img, (size, size), cv.INTER_NEAREST)
img = np.transpose(img,[2, 0, 1])
img = img / 255.0
img = np.expand_dims(img,0)
return img.astype(np.float32)
def process_result(box_results, conf_results):
conf_results = np.transpose(conf_results,[0, 2, 1])
box_results =box_results.reshape(8400,4)
conf_results = conf_results.reshape(8400,2)
scores = []
classes = []
boxes = []
for i in range(8400):
conf = conf_results[i,:]
score = np.max(conf)
if score > 0.5:
classes.append(np.argmax(conf))
scores.append(score)
boxes.append(box_results[i,:])
scores = np.array(scores)
boxes = np.array(boxes)
result_box = []
result_score = []
result_class = []
if len(boxes) != 0:
indexs = tf.image.non_max_suppression(boxes,scores,len(scores),0.25,0.35)
for i, index in enumerate(indexs):
result_score.append(scores[index])
result_box.append(boxes[index,:])
result_class.append(classes[index])
return np.array(result_box),np.array(result_score),np.array(result_class)
def draw_box(image, boxes, scores, classes, labels):
colors = [(0, 0, 255), (0, 255, 0)]
scale = max(image.shape) / 640.0
if len(classes) != 0:
for i in range(len(classes)):
box = boxes[i,:]
x1 = int(box[0] * scale)
y1 = int(box[1] * scale)
x2 = int(box[2] * scale)
y2 = int(box[3] * scale)
label = labels[classes[i]]
score = scores[i]
cv.rectangle(image, (x1, y1), (x2, y2), colors[classes[i]], 2, cv.LINE_8)
cv.putText(image,label+":"+str(score),(x1,y1-10),cv.FONT_HERSHEY_SIMPLEX, 0.55, colors[classes[i]], 2)
return image
def read_label(label_path):
with open(label_path, 'r') as f:
labels = f.read().split()
return labels
label_path = "labels.txt"
yoloe_model_path = "ppyoloe_crn_s_80.xml"
predictor = Predictor(model_path = yoloe_model_path)
boxes_name = predictor.get_outputs_name(0)
conf_name = predictor.get_outputs_name(1)
labels = read_label(label_path=label_path)
cap = cv.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
frame = cv.flip(frame, 180)
cv.namedWindow("AnimalDetection", 0)
cv.resizeWindow("AnimalDetection", 640, 480)
input_frame = process_image(frame, 640)
results = predictor.predict(input_data=input_frame)
print("results[boxes_name]",results[boxes_name])
print("results[conf_name]",results[conf_name])
boxes, scores, classes = process_result(box_results=results[boxes_name], conf_results=results[conf_name])
result_frame = draw_box(image=frame, boxes=boxes, scores=scores, classes=classes, labels=labels)
cv.imshow('AnimalDetection', result_frame)
key = cv.waitKey(1)
if key == 27:
break
cap.release()
cv.destroyAllWindows()
运行效果:
猫狗识别















 4041
4041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









