







Datawhale打卡活动 Kaggle Spaceship Titanic
尝试了一个coggle科学的打卡活动(Coggle 30 Days of ML(22年10月)),记录一下学习过程!
Day7 多折训练与集成
步骤1:使用KFold完成数据划分;
KFold在原来的博客中也有相关的介绍,不清楚的可以查阅网上的相关资料(推荐),或者翻一下笔者写的博客(也是网上copy下来的)。直接进入实战部分。
def cv_model(clf, train_x, train_y, test_x):
folds = 5
seed = 42
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
train = np.zeros(train_x.shape[0])
test = np.zeros(test_x.shape[0])
cv_scores = []
test_pre = []
Feass = pd.DataFrame()
for i, (train_index, valid_index) in enumerate(kf.split(train_x)):
print('********************* {} *********************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
fea = pd.DataFrame()
params = {
'objective': 'binary',
'boosting_type': 'gbdt',
'metric': 'auc',
'n_jobs': 30,
'learning_rate': 0.05,
'num_leaves': 2 ** 6,
'max_depth': 8,
'tree_learner': 'serial',
'colsample_bytree': 0.8,
'subsample_freq': 1,
'subsample': 0.8,
'num_boost_round': 5000,
'max_bin': 255,
'verbose': -1,
'seed': 2021,
'bagging_seed': 2021,
'feature_fraction_seed': 2021,
'early_stopping_rounds': 200,
}
model = clf.train(params, train_matrix, num_boost_round=2000, valid_sets=[train_matrix, valid_matrix],categorical_feature =[] ,verbose_eval=200,early_stopping_rounds=400)
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
test_pre.append(test_pred)
fea['feas'] = train_x.columns.tolist()
fea['sorce'] = model.feature_importance()
Feass = pd.concat([Feass,fea],axis = 0)
print(list(sorted(zip(train_x.columns.tolist(), model.feature_importance()), key=lambda x: x[1], reverse=True))[:20])
train[valid_index] = val_pred
test = test_pred
cv_scores.append(roc_auc_score(val_y, val_pred))
print(cv_scores)
test = sum(test_pre) / folds
print("scotrainre_list:" , cv_scores)
print("score_mean:" ,np.mean(cv_scores))
print("score_std:" ,np.std(cv_scores))
return train, test, Feass
步骤2:使用StratifiedKFold完成数据划分;
def cv_model(clf, train_x, train_y, test_x):
folds = 5
seed = 42
#kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
kf = StratifiedKFold(n_splits=folds, shuffle=True, random_state=seed)
train = np.zeros(train_x.shape[0])
test = np.zeros(test_x.shape[0])
cv_scores = []
test_pre = []
Feass = pd.DataFrame()
for i, (train_index, valid_index) in enumerate(kf.split(train_x,train_y)):
print('********************* {} *********************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
fea = pd.DataFrame()
params = {
'objective': 'binary',
'boosting_type': 'gbdt',
'metric': 'auc',
'n_jobs': 30,
'learning_rate': 0.05,
'num_leaves': 2 ** 6,
'max_depth': 8,
'tree_learner': 'serial',
'colsample_bytree': 0.8,
'subsample_freq': 1,
'subsample': 0.8,
'num_boost_round': 5000,
'max_bin': 255,
'verbose': -1,
'seed': 2021,
'bagging_seed': 2021,
'feature_fraction_seed': 2021,
'early_stopping_rounds': 200,
}
model = clf.train(params, train_matrix, num_boost_round=2000, valid_sets=[train_matrix, valid_matrix],categorical_feature =[] ,verbose_eval=200,early_stopping_rounds=400)
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
test_pre.append(test_pred)
fea['feas'] = train_x.columns.tolist()
fea['sorce'] = model.feature_importance()
Feass = pd.concat([Feass,fea],axis = 0)
print(list(sorted(zip(train_x.columns.tolist(), model.feature_importance()), key=lambda x: x[1], reverse=True))[:20])
train[valid_index] = val_pred
test = test_pred
cv_scores.append(roc_auc_score(val_y, val_pred))
print(cv_scores)
test = sum(test_pre) / folds
print("scotrainre_list:" , cv_scores)
print("score_mean:" ,np.mean(cv_scores))
print("score_std:" ,np.std(cv_scores))
return train, test, Feass
步骤3:使用StratifiedKFold配合LightGBM完成模型的训练和预测
训练结果如下:

步骤4:在步骤3训练得到了多少个模型,对测试集多次预测,将最新预测的结果文件提交到比赛,截图分数;
在步骤3中,我们使用了5折交叉验证,也就是得到了5个模型,对测试集进行了5次预测,然后求均值作为最后的结果。
线上分数如下:
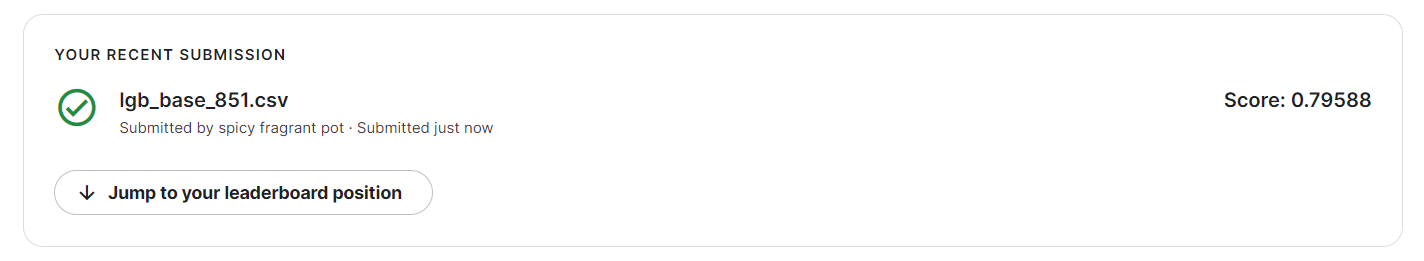
步骤5:使用交叉验证训练5个机器学习模型(svm、lr等),使用stacking完成集成,将最新预测的结果文件提交到比赛,截图分数;
写一个五折交叉验证的函数,方便训练:
def model_train(model, model_name, kfold=5):
oof_preds = np.zeros((train.shape[0]))
test_preds = np.zeros(test.shape[0])
skf = StratifiedKFold(n_splits=kfold)
print(f"Model = {model_name}")
for k, (train_index, test_index) in enumerate(skf.split(train, label)):
x_train, x_test = train.iloc[train_index, :], train.iloc[test_index, :]
y_train, y_test = label.iloc[train_index], label.iloc[test_index]
model.fit(x_train,y_train)
y_pred = model.predict_proba(x_test)[:,1]
oof_preds[test_index] = y_pred.ravel()
auc = roc_auc_score(y_test,y_pred)
print("- KFold = %d, val_auc = %.4f" % (k, auc))
test_fold_preds = model.predict_proba(test)[:, 1]
test_preds += test_fold_preds.ravel()
print("Overall Model = %s, AUC = %.4f" % (model_name, roc_auc_score(label, oof_preds)))
return test_preds / kfold
stacking部分:
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import StackingClassifier
from sklearn.model_selection import StratifiedKFold, KFold
lr = LogisticRegression(random_state=2022,tol=1e-6) # 逻辑回归模型
tree = DecisionTreeClassifier(random_state=2022) #决策树模型
svm = SVC(probability=True,random_state=2022,tol=1e-6) # SVM模型
forest=RandomForestClassifier(n_estimators=100,random_state=2022) # 随机森林
Gbdt=GradientBoostingClassifier(random_state=2022) #GBDT
estimators = [
('lr', lr),
('hgbc', tree),
('xgbc', svm),
('gbm', forest),
('cbc', Gbdt)
]
clf = StackingClassifier(
estimators=estimators,
final_estimator=LogisticRegression()
)
线上分数:
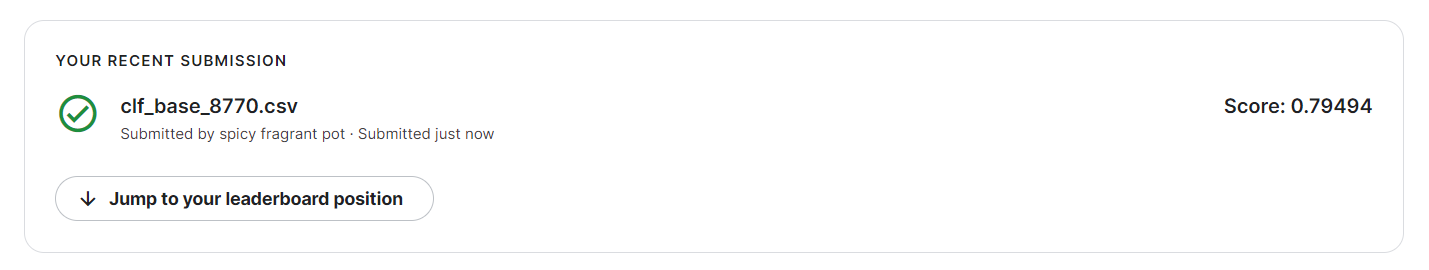















 1028
1028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









