






C++ Primer Plus
第1章 预备知识
1.面向对象编程(OOP);Object Oriented Programming
2.cin.get()可以读取下一次键盘的输入
第2章 开始学习C++
1.通常模板
#include <iostream>
int main()
{
using namespace std;
return 0;
}
2.关于using namespace std;
详解可见:C++命名空间<转> - Li Qian - 博客园 (cnblogs.com)
//以下三种方式等价
//①using编译指令
using namespace std;
cout << "你好";
cin >> temp;
cout<<endl;
//②用多条指令
using std::cout;
using std::cin;
using std:endl;
cout << "你好";
cin >> temp;
cout<<endl;
//③直接用
std::cout << "你好";
std::cin >> temp;
std::cout<<std::endl;
3.关于换行符
\n和endl都能换行,区别是endl确保程序继续运行前刷新输出(将其立即显示在屏幕上),而\n不能提供这样的保证。建议在大多数情况下用endl比较好。
第3章 处理数据
1.变量名
以两个下划线开头或以下划线和大写字母开头的名称被保留给实现(编译器及其使用的资源)使用。
用一个下划线开头的名称被保留给实现,用作全局变量。
2.sizeof
#include <iostream>
int main()
{
using namespace std;
int n_int = INT_MAX;//INT_MAX为int的最大取值
int char_bit = CHAR_BIT;//CHAR_BIT为字节的位数
cout<<sizeof(int);//4
cout<<char_bit;//8
cout<<sizeof n_int;//4
cout<<n_int;//2147483647
return 0;
}
3.初始化
int a=10;
int b(10);
cout<<a;//10
cout<<b;//10
4.无符号类型
有符号short:-32768~+32767
无符号short:0~65535
5.进制数
#include <iostream>
using namespace std;
int main()
{
int a=42;
cout<<dec<<a<<endl;//十进制,42
cout<<oct<<a<<endl;//八进制,52
cout<<hex<<a<<endl;//十六进制,2a
}
6.内存地址是没有符号的,所以用unsigned int比long更为合适来表示16位的地址。
7.cout.put()函数显示一个字符
8.define和const
#define MAX 100 //全字母大写
const int Max=100;//首字母大写
第4章 复合类型
1.数组的初始化
#include <iostream>
using namespace std;
int main()
{
int a[]={1,2,3,4};
int b[5]={1,2,3};
int c[] {1,5,9,3};//可省略等号
int d[4] {1,5,9,3};
}
2.字符串
性质:必须以空字符(\0)结尾
char dog[3]={'a','s','j'};//不是字符串
char cat[3]={'t','c','\0'};//是字符串
在确定存储字符串所需的最短数组时,要把结尾的空字符计算在内(占一个位置)。
3.单引号’'对应字符,双引号""对应字符串
4.字符串长度
sizeof运算符指出的是整个数组的长度
strlen()返回的是存储在数组内的字符串的长度,且只计算可见的字符(忽略最后的’\0’)
.size()方法是用于计算字符串的长度
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char dog[3]={'a','s','\0'};
cout<<sizeof dog<<endl;//3
cout<<strlen(dog)<<endl;//2
cout<<dog;//as
string cat="miao";
cout<<cat.size()<<endl;//4
}
5.get()和getline()
这两个函数都是cin的成员函数,都是读取一行输入,直到到达换行符。不过,getline()会丢弃换行符,get()将换行符保存在输入序列中。
-
cin.getline(A,B):A指的是存储输入行的数组的名称,B指的是要读取的字符数。如果B=20,那么最多读取19个字符,余下的空间用于存储自动在结尾处添加的空字符。
-
cin.get(A,B):get()并不读取最后的换行符,如果我们连续两次用get(),那么留在输入队列的那个换行符会被第二个get()直接吸收,导致第二个get()我们输入不了内容。为了避免这种情况,我们可以使用cin.get(A,B).get(),前一个get是获取我们的输入,后一个get自动吸收最后的换行符,这样的情况下我们就可以连续用get进行输入了。
#include <iostream> int main() { using namespace std; const int ArSize = 20; char name[ArSize]; char dessert[ArSize]; cout << "Enter your name:\n"; cin.get(name, ArSize).get(); //吸收换行符 cout << "Enter your favorite dessert:\n"; cin.get(dessert, ArSize).get(); cout << "I have some delicious " << dessert; cout << " for you, " << name << ".\n"; return 0; } -
cin和get结合使用
#include <iostream> int main() { using namespace std; cout << "What year was your house built?\n"; int year; //cin >> year;当cin读取年份时,将回车键生成的换行符留在了输入队列,导致后面的getline看到换行符就直接读入结束了 (cin >> year).get(); cout << "What is its street address?\n"; char address[80]; cin.getline(address, 80); cout << "Year built: " << year << endl; cout << "Address: " << address << endl; cout << "Done!\n"; return 0; } -
用cin<<和cin.get()进行输入的时候都会把换行符残留在输入队列,导致下面的get和getline出错,所以连续使用输入时,需要在最后加上get()吸收最后输入的换行符。
6.共用体
- 共用体结构和结构体类似,但是只能同时存储其中的一种类型。
- 里面的数据项不能同时使用。
- 可以节约空间。
- 同一个共用体内的数据项的地址相同。
- 指针用->,结构体用.
7.指针
-
int *p创建指针的时候,这时候p是一个地址。可以利用p=&a给p改变地址(赋地址)。
char * name="111"; cout << name << " at " << (int *) name << "\n"; //name指针的内存地址。 //(int *) name将name指针强制转换为整数指针,以便输出指针的内存地址。 cout << name << " at " << &name << "\n"; //name指针变量自身的内存地址。 //&name获取的是name指针变量本身的地址,而不是它所指向的字符串的地址。&name的类型是char **,因为它是一个指向指针的指针。 delete [] name; -
指针是一个变量,其存储的是值的地址,而不是值本身。
-
如何实现将指针指向内存中一个地址?
int *p; p=(int *)0xB8000000;//使用了类型转换(int *)来确保编译器知道我们正在将一个地址值赋给一个整数指针。 //p=&0xB8000000; //为什么这种是错误的? //因为&运算符用于获取变量的地址,但在这里它试图获取一个整数常量0xB8000000的地址。在C和C++中,你不能获取一个常量的地址,因为常量通常存储在程序的只读段中,并没有一个固定的内存地址。因此,这行代码会导致编译错误。 //p=0xB8000000; //为什么这种是错误的? //因为在计算机内,系统会认为我们输入的0xB8000000是一个数字,而不是直接识别成地址 -
&运算符用于获取变量的地址
-
指针的地址问题
假设nights的地址是A,pt的地址是B(为new创建出来的)
而执行*pt = 1001; 之后,只相当于将pt指的地址的值赋为1001,对nights和pt本身的地址不会改变。
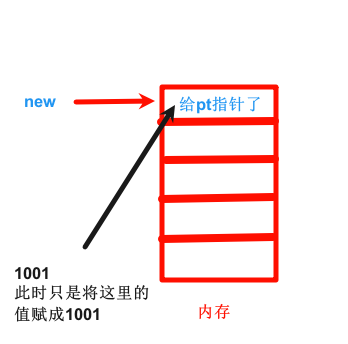
#include <iostream> int main() { using namespace std; int nights = 1001; int * pt = new int; *pt = 1001; cout << "nights value = " << nights << ": location " << &nights << endl; //nights value = 1001: location 0x61fe14 cout << "int value = " << *pt << ": location = " << pt << endl; //int value = 1001: location = 0xe26120 cout << "size of pt = " << sizeof(pt) << ": size of *pt = " << sizeof(*pt) << endl; //size of pt = 8: size of *pt = 4 return 0; }
8.使用new来创建动态数组
-
用new创建的数组,需要使用delete来释放。
-
通用格式如下:type *name=new type[num_elements];
-
new运算符返回未命名的内存地址。
-
可以用new实现根据用户输入的数值而创建对应长度的数组。
int size; cin>>size; int *p=new int[size]; .... delete [] p;
9.指针加减
将指针变量加1后,增加的量等于它指向的类型的字节数。将指向double的指针加1后,则数值将增加8;将short指针加1后,数值加2。如果是减,同理。
#include <iostream>
int main()
{
using namespace std;
double * p3 = new double [3];
p3[0] = 0.2;p3[1] = 0.5;p3[2] = 0.8;
cout << "p3[1] is " << p3[1] << ".\n"; //0.5
p3 = p3 + 1;
cout << "Now p3[0] is " << p3[0] << " and ";//0.5
cout << "p3[1] is " << p3[1] << ".\n"; //0.8
p3 = p3 - 1;
delete [] p3;
return 0;
}
注:
- C++将数组名解释为地址。*(a+1)=a[1]是等价的。
- 对数组用sizeof运算符得到的是数组的长度,对指针应用sizeof得到的是指针的长度。
- 数组名被解释为其第一个元素的地址,而对数组名应用地址运算符时,得到的是整个数组的地址。
10.数组的替代品
vector(动态数组):使用vector对象必须包含vector头文件。vector vt(n_elem)。n_elem可以是整型常量或者常数。
array(静态数组):与普通数组相比,更方便更安全。需包含头文件array。array<type,n_elem> arr;n_elem只能是常数。
第5章 循环和关系表达式
1.优先级
#include <iostream>
using namespace std;
int main()
{
int a=1;
int b(1);
cout<<(a==b);
//cout<<a==b;会报错,<<运算符的优先级比表达式中使用的运算符高,在cout和cin中使用条件时需要加()。
}
2.阶乘
0!=1;1!=1×0!=1×1=1。
3.类型别名
-
用预处理器,#define BYTE char
-
用typedef,typedef char byte; 注typedef不会创建新类型,只是为已有的类型建立一个新名称,可以同时用。
typedef char byte; char a; byte b;using namespace std; int main() { int a=1; int b(1); cout<<(a==b); //cout<<a==b;会报错,<<运算符的优先级比表达式中使用的运算符高,在cout和cin中使用条件时需要加()。 }
2.阶乘
0!=1;1!=1×0!=1×1=1。
3.类型别名
-
用预处理器,#define BYTE char
-
用typedef,typedef char byte; 注typedef不会创建新类型,只是为已有的类型建立一个新名称,可以同时用。
typedef char byte; char a; byte b;
第6章 分支语句和逻辑运算符
1.枚举变量
enum {red, orange, yellow, green, blue, violet, indigo};
//此时,red即为0,orange为1,yellow为2.....
cout<<(red==0);//true
2.跳出循环
break:使程序跳出当前循环,结束循环。
continue:使程序跳出当下的循环下部分的代码,开始本循环的新一轮循环。
3.保留小数点后两位
// 将浮点数格式化为保留两位小数
#include <iostream>
#include <iomanip> // 包含用于设置输出格式的头文件
int main() {
double number = 123.456789;
// 设置输出流以固定的小数点格式,并保留两位小数
std::cout << std::fixed << std::setprecision(2);
// std::fixed告诉std::cout以固定的小数点格式输出,而std::setprecision(2)设置了小数点后保留两位数字。
// 运行这段代码将输出123.46。
// 输出浮点数,保留两位小数
std::cout << number << std::endl;
return 0;
}
// 将数字四舍五入到两位小数,并保留为一个字符串
#include <iostream>
#include <iomanip>
#include <sstream>
#include <cmath> // 包含用于四舍五入的头文件
int main() {
double number = 123.456789;
std::stringstream ss;
// 设置输出流以固定的小数点格式,并保留两位小数
ss << std::fixed << std::setprecision(2) << std::round(number * 100) / 100;
// 在这行代码中,std::stringstream 对象 ss 被用来构建一个格式化的字符串,该字符串表示一个浮点数,该浮点数已被四舍五入到两位小数。
// 首先将数字乘以100(移动到小数点后两位),然后使用std::round进行四舍五入,接着再除以100将其移回原位。
// 这样我们就得到了一个四舍五入到两位小数的数字,并且将其转换为了一个字符串。输出将是123.46。
// 提取格式化后的字符串
std::string formattedNumber = ss.str();
// 输出字符串
std::cout << formattedNumber << std::endl;
return 0;
}
4.写入到文本文件中
文件输出(输出指的是电脑中的内容输出到文件中去)
- 必须包含头文件fstream
- 头文件fstream定义了一个用于输出的ofstream类
- 需要声明一个或多个ofstream变量(对象),并用自己喜欢的方式对其进行命名
- 必须指明名称空间std(这个和cout操作类似)
- 需要将ofstream对象与文件关联起来。方法之一是使用open()方法
- 使用完文件时,需要使用close()方法将其关闭
- 可结合使用ofstream对象和运算符<<来输出各种类型的数据
- 主要步骤:
- 包含头文件fstream
- 创建一个ofstream对象
- 将该ofstream对象同一个文件关联起来
- 就像使用cout那样使用ofstream
// 简单版
#include <iostream>
#include <fstream>
using namespace std;
int main() {
ofstream outFile;
ofstream fout;
//打开一个名为a.txt的文件
//若不存在,则创建一个名为"open函数括号内部字符串"的文件
//若存在,则将原来文件所有内容丢弃
outFile.open("a.txt");
double wt=125.8;
outFile<<wt;//将文件写入a.txt文件中
// 根据输入的文件名,创建一个文件
char filename[50];
cin>>filename;
fout.open(filename);
}
// 复杂版
#include <iostream>
#include <fstream> // for file I/O
int main()
{
using namespace std;
char automobile[50];
int year;
double a_price;
double d_price;
ofstream outFile; // create object for output
outFile.open("carinfo.txt"); // associate with a file
cout << "Enter the make and model of automobile: ";
cin.getline(automobile, 50);
cout << "Enter the model year: ";
cin >> year;
cout << "Enter the original asking price: ";
cin >> a_price;
d_price = 0.913 * a_price;
// display information on screen with cout
cout << fixed;
cout.precision(2);
cout.setf(ios_base::showpoint);
cout << "Make and model: " << automobile << endl;
cout << "Year: " << year << endl;
cout << "Was asking $" << a_price << endl;
cout << "Now asking $" << d_price << endl;
// now do exact same things using outFile instead of cout
outFile << fixed;
outFile.precision(2);
outFile.setf(ios_base::showpoint);
outFile << "Make and model: " << automobile << endl;
outFile << "Year: " << year << endl;
outFile << "Was asking $" << a_price << endl;
outFile << "Now asking $" << d_price << endl;
outFile.close();//close()不需要使用文件名作为参数,因为outFile已经同特定的文件关联起来。
return 0;
}
部分代码注意:
cout << fixed;
// 设置了cout的浮点数输出格式为固定点表示法,这意味着浮点数将始终显示小数点,即使小数部分为零或可以省略也不会显示为科学记数法。
// cout << fixed是一个流控制操作符,用于设置浮点数的输出格式。具体来说,fixed会告诉cout以固定点表示法(fixed-point notation)来输出浮点数,而不是科学记数法(scientific notation)。
// 默认情况下,当浮点数的绝对值小于或等于 1e-4 或大于或等于 1e+20 时,cout 会使用科学记数法来输出浮点数。使用 fixed 之后,浮点数将始终使用固定点表示法输出,即总是显示小数点及其后面的数字。
cout.precision(2);
// 设置了cout的浮点数精度为小数点后两位。这意味着无论浮点数的实际值有多少位小数,输出时都只会显示小数点后两位。如果原始值的小数部分少于两位,则会在其后补零以达到两位小数的效果。
cout.setf(ios_base::showpoint);
// 确保了即使浮点数的小数部分为零,也会显示小数点。默认情况下,如果浮点数的小数部分为零,cout可能会省略小数点和小数部分。使用showpoint标志后,即使小数部分为零,也会显示小数点。
下面是一个完整的例子:
这段代码会输出123.46,即使原始值的小数部分有更多位数,输出也只会显示小数点后两位,并且因为设置了showpoint,小数点始终会显示出来。
#include <iostream>
using namespace std;
int main() {
double num = 123.456789;
cout << fixed; // 设置固定点表示法
cout.precision(2); // 设置精度为小数点后两位
cout.setf(ios_base::showpoint); // 即使小数部分为零也显示小数点
std::cout << num << std::endl; // 输出 num
return 0;
}
5.读取文本文件
输出
- 必须包含头文件fstream
- 头文件fstream定义了一个用于处理输入的ifstream类
- 需要声明一个或多个ifstream变量(对象),并以自己喜欢的方式对其进行命名
- 必须指明名称空间std::
- 需要将ifstream对象与文件关联起来。方法之一是使用open()
- 使用完文件,需要使用close()进行关闭
- 可结合使用ifstream对象和运算符>>来读取各种类型的数据
- 可以使用ifstream对象和get()方法来读取一个字符,使用ifstream对象和getline()来读取一行字符
- 可以结合ifstream对象和eof()、fail()等方法来判断输入是否成功
- ifstream对象本身被用作测试条件时,如果最后一个读取操作成功,它将会被转换为布尔值true,否则被转换为false
- 检查一个文件是否被打开,可以用is_open()方法
- 程序必须能够找到这个文件。通常,除非在输入的文件名中包含路径,否则程序将在可执行文件所属的文件夹中查找
//需准备一个都是数字的文件
#include <iostream>
#include <fstream> // file I/O support
#include <cstdlib> // support for exit()
const int SIZE = 60;
int main()
{
using namespace std;
char filename[SIZE];
ifstream inFile; // object for handling file input
cout << "Enter name of data file: ";
cin.getline(filename, SIZE);//输入想打开的文件的路径名
inFile.open(filename); // associate inFile with a file
if (!inFile.is_open()){
// 如果文件打不开
cout << "Could not open the file " << filename << endl;
cout << "Program terminating.\n";
exit(EXIT_FAILURE);
//程序会立即停止执行,并返回给操作系统一个退出状态码。
}
double value;
double sum = 0.0;
int count = 0; // number of items read
inFile >> value;//获取第一个值
while (inFile.good()){
// while input good and not at EOF
// 在C++中,inFile.good() 是一个成员函数,用于检查输入流 inFile 的状态。它返回一个布尔值,如果流处于有效状态(即没有遇到错误或文件结束),则返回 true;否则返回 false。
// 当你从文件或其他输入流中读取数据时,可能会发生各种错误,如文件不存在、文件无法打开、读取过程中遇到非预期的字符等。
// inFile.good() 函数允许你在尝试读取数据之前或之后检查流是否处于良好状态。
++count; // one more item read
sum += value; // calculate running total
inFile >> value; // 获取下一个值
}
if (inFile.eof()) cout << "End of file reached.\n"; //文件正常读完的话,到EOF
else if (inFile.fail()) cout << "Input terminated by data mismatch.\n";//文件读异常,到fail
else cout << "Input terminated for unknown reason.\n";
if (count == 0) cout << "No data processed.\n";
else{
cout << "Items read: " << count << endl;
cout << "Sum: " << sum << endl;
cout << "Average: " << sum / count << endl;
}
inFile.close(); // finished with the file
return 0;
}
第7章 函数–C++的编程模块
1.函数参数
- 不写默认为空:void say_hi()
- 如果有多个,用省略号:void say_byte(…)
2.恒等式
arr[i] == *(arr+i);
&arr[i] == arr+ i
3.const和*
#include <iostream>
using namespace std;
int main()
{
int num = 20;
//const int *p =num;
//&num 是 num 变量的地址,p 是一个指向 const int 的指针,它指向 num 的地址。由于 p 是一个指向 const int 的指针,所以您不能通过 p 来修改 num 的值。
const int *p = #
// 因为 num 没有被明确定义。如果 num 是一个 int 类型的变量,那么直接赋值给 const int* 类型的 p 是不合法的,
// 因为 const int* 类型的指针要求指向一个 const int,而不是一个普通的 int。
cout<<p<<endl;//0x61fe14
cout<<*p<<endl;//20
int a=80;
p=&a;
cout<<p<<endl;//0x61fe10
cout<<*p<<endl;//80
}
4.函数和array
#include <iostream>
#include <array>
#include <string>
const int Seasons = 4;
const std::array<std::string, Seasons> Snames = {"Spring", "Summer", "Fall", "Winter"};
void fill(std::array<double, Seasons> * pa);
void show(std::array<double, Seasons> da);
int main()
{
std::array<double, 4> expenses;
fill(&expenses);
show(expenses);
// std::cin.get();
// std::cin.get();
return 0;
}
void fill(std::array<double, Seasons> * pa){
// 需要修改原数据,需要在创建函数时使用指针,调用函数时用传地址符
for (int i = 0; i < Seasons; i++)
{
std::cout << "Enter " << Snames[i] << " expenses: ";//季节字符串
std::cin >> (*pa)[i];//输入
}
}
void show(std::array<double, Seasons> da){
double total = 0.0;
std::cout << "\nEXPENSES\n";
for (int i = 0; i < Seasons; i++){
std::cout << Snames[i] << ": $" << da[i] << '\n';
total += da[i];
}
std::cout << "Total: $" << total << '\n';
}
5.函数指针的基础知识
获取函数的地址:如果think()是函数话,think就是函数的地址
声明函数指针:double *think(int a)。
使用指针调用函数:*think和think是等价的。
double pam(int);
double (*pf)(int);
pf=pam;
double x=pam(4);
double y=(*pf)(5);//等价pam(5)
double z=pf(5);//等价pf(5)
// 以下三个等价
const double * f1(const double ar[],int n);
const double * f2(const double [],int);
const double * f3(const double *,int);
#include <iostream>
// various notations, same signatures
const double * f1(const double ar[], int n);
const double * f2(const double [], int);
const double * f3(const double *, int);
int main()
{
using namespace std;
double av[3] = {1112.3, 1542.6, 2227.9};
// pointer to a function
const double *(*p1)(const double *, int) = f1;
auto p2 = f2; // C++0x automatic type deduction
// 等价于const double *(*p2)(const double *, int) = f2;
cout << "Using pointers to functions:\n";
cout << " Address Value\n";
cout << (*p1)(av,3) << ": " << *(*p1)(av,3) << endl;
cout << p2(av,3) << ": " << *p2(av,3) << endl;
// pa an array of pointers
// auto doesn't work with list initialization
const double *(*pa[3])(const double *, int) = {f1,f2,f3};
// but it does work for initializing to a single value
// pb a pointer to first element of pa
auto pb = pa;
// 等价于const double *(**pb)(const double *, int) = pa;
cout << "\nUsing an array of pointers to functions:\n";
cout << " Address Value\n";
for (int i = 0; i < 3; i++)
cout << pa[i](av,3) << ": " << *pa[i](av,3) << endl;
cout << "\nUsing a pointer to a pointer to a function:\n";
cout << " Address Value\n";
for (int i = 0; i < 3; i++)
cout << pb[i](av,3) << ": " << *pb[i](av,3) << endl;
// what about a pointer to an array of function pointers
cout << "\nUsing pointers to an array of pointers:\n";
cout << " Address Value\n";
// easy way to declare pc
auto pc = &pa;
// pre-C++0x can use the following code instead
// const double *(*(*pc)[3])(const double *, int) = &pa;
cout << (*pc)[0](av,3) << ": " << *(*pc)[0](av,3) << endl;
// hard way to declare pd
const double *(*(*pd)[3])(const double *, int) = &pa;
// store return value in pdb
const double * pdb = (*pd)[1](av,3);
cout << pdb << ": " << *pdb << endl;
// alternative notation
cout << (*(*pd)[2])(av,3) << ": " << *(*(*pd)[2])(av,3) << endl;
// cin.get();
return 0;
}
// some rather dull functions
const double * f1(const double * ar, int n)
{
return ar;
}
const double * f2(const double ar[], int n)
{
return ar+1;
}
const double * f3(const double ar[], int n)
{
return ar+2;
}
第8章 函数探幽
1.内联函数
-
必须采取以下措施之一:
- 在函数声明前加上关键字inline
- 在函数定义前加上关键字inline
-
内敛函数不能递归
-
内敛和宏:
- C语言的#define和C++的inline实现的本质一样
- #define SQUARE(X) ((X)*(X))
- inline double square(double x) { return x*x; }
2.引用变量
int rat;
int &rodent=rat;
// &不是地址运算符,而是类型标识符的一种
// int &表示的是指向int的引用
// 上述声明允许将rat和rodent互换,它们指向相同的值和内存单元
引用和指针的区别:
int rat = 101;
int &rodent = rat;
int *prat = &rat;
// 表达式rodent和prat都可以同rat互换,而表达式&rodent和*prat都可以同&rat互换
引用和指针还是不同的,例如引用必须在声明引用时将其初始化,而不能像指针那样,先声明,再赋值。引用更接近const指针,必须在创建时进行初始化,一旦与某个变量关联起来,就将一直效忠它。
3.引用参数
int a(int &at,int &bt)
使用引用参数的原因:
- 能够修改调用函数中的数据对象
- 通过传递引用而不是整个数据对象,可以提高程序的运行速度
指导原则:
-
对于使用传递的值而不作修改的函数:
- 如果数据对象很小,如内置数据类型或小型结构,则按值传递。
- 如果数据对象是数组,则使用指针,因为这是唯一的选择,并将指针声明为指向const的指针
- 如果数据对象是较大的结构,则使用const指针或const引用,以提高程序的效率。这样可以节省复制结构所需的时间和空间。
- 如果数据对象是类对象,则使用const引用。类设计的语义常常要求使用引用,这是C++新增这项特性的主要原因。因此,传递类对象参数的标准方式是按引用传递。
-
对于修改调用函数中数据的函数:
- 如果数据对象是内置数据类型,则使用指针,如果看到诸如fixit(&x)这样的代码(其中x是int),则很明显,该函数将修改x。
- 如果数据对象是数组,则只能使用指针。
- 如果数据对象是结构,则使用引用或指针。
- 如果数据对象是类对象,则使用引用。
4.函数模板
C++中的模板函数是一种特殊的函数,其类型可以被参数化,因此可以用不同类型进行调用。这实际上是建立了一个通用函数,其内部的类型和函数的形参类型不具体指定,而是用一个虚拟的类型来代表。这种通用的方式称为模板,是泛型编程的基础。
具体来说,模板函数的主要目的是为了解决同一类参数类型不同函数多次写入重复函数体代码的问题。通过模板函数,我们可以为所有数据类型实现同一个函数,而无需为每种数据类型都编写一个函数。
模板函数的语法规则包括使用template关键字来声明开始进行泛型编程,以及使用typename(也可以使用class)关键字来声明泛指类型。在模板函数中,凡希望根据实参数据类型来确定数据类型的变量,都可以用数据类型参数标识符来说明,从而使这个变量可以适应不同的数据类型。
模板函数本身只是一个声明,并不是一个可以直接执行的函数。只有当我们用实参的数据类型代替类型参数标识符之后,才能产生真正的函数。如果模板函数没有显示的实例化,编译器会根据推演参数列表得到合适的实例化函数。
总的来说,模板函数是C++中一种重要的代码复用方式,它提高了代码的灵活性和可重用性。
template <typename T>
// 通常在每个函数的前面都写一遍这句话
void Swap(T *a, T *b, int n);
这段代码定义了一个模板函数 Swap,该函数用于交换两个数组的内容。这里的模板参数 T 表示这个 Swap 函数可以用于任何类型的数组,只要该类型支持赋值操作。
解释如下:
template <typename T>: 这是一个模板声明,表示这个函数是一个模板函数,可以接受任何类型T。void Swap(T *a, T *b, int n): 这是函数的定义。void表示这个函数没有返回值。T *a, T *b是两个指向类型T的指针,分别代表两个要交换的数组。int n表示数组的长度或要交换的元素数量。
5.显示具体化
- 对于给定的函数名,可以有非模板函数、模板函数和显式具体化模板函数以及它们的重载版本。
- 显式具体化的原型和定义应以template<>打头,并通过名称来指出类型。
- 具体化优先于常规模板,而非模板函数优先于具体化和常规模板。
- 如果有多个原型,则编译器在选择原型时,非模板版本优先于显式具体化,显式具体化优先于模板版本。
//非模板函数
void swap(job &,job &);
//模板函数
template <typename T>
void swap(T &,T &);
//具体化
template <> void swap<job>(job &,job &);
#include <iostream>
template <typename T>
void Swap(T &a, T &b);
struct job
{
char name[40];
double salary;
int floor;
};
// explicit specialization
template <> void Swap<job>(job &j1, job &j2);
void Show(job &j);
int main()
{
using namespace std;
//这两行代码通常一起使用,以确保浮点数以固定点形式输出,并且小数点后有两位数字。
cout.precision(2);
//这行代码设置了输出流中浮点数的精度为2位。对于浮点数,这通常意味着小数点后只显示两位数字。
//注意,这并不意味着浮点数会被四舍五入到两位小数,而是输出时将只显示两位小数。原始浮点数的值保持不变。
cout.setf(ios::fixed, ios::floatfield);
//这行代码设置了浮点数的输出格式为固定点表示法(fixed-point notation)。
//在C++中,浮点数可以以固定点或科学记数法(scientific notation)输出。ios::fixed标志确保浮点数以固定点形式输出,即不包含指数部分。ios::floatfield是一个掩码,用于选择浮点数的表示法。通过设置ios::fixed,我们告诉输出流使用固定点表示法,而不是科学记数法。
int i = 10, j = 20;
cout << "i, j = " << i << ", " << j << ".\n";
cout << "Using compiler-generated int swapper:\n";
Swap(i,j); // generates void Swap(int &, int &)
cout << "Now i, j = " << i << ", " << j << ".\n";
job sue = {"Susan Yaffee", 73000.60, 7};
job sidney = {"Sidney Taffee", 78060.72, 9};
cout << "Before job swapping:\n";
Show(sue);
Show(sidney);
Swap(sue, sidney); // uses void Swap(job &, job &)
cout << "After job swapping:\n";
Show(sue);
Show(sidney);
// cin.get();
return 0;
}
// 模板函数版本
template <typename T>
void Swap(T &a, T &b) // general version
{
T temp;
temp = a;
a = b;
b = temp;
}
// swaps just the salary and floor fields of a job structure
// 具体化版本
template <> void Swap<job>(job &j1, job &j2) // specialization
{
double t1;
int t2;
t1 = j1.salary;
j1.salary = j2.salary;
j2.salary = t1;
t2 = j1.floor;
j1.floor = j2.floor;
j2.floor = t2;
}
void Show(job &j)
{
using namespace std;
cout << j.name << ": $" << j.salary
<< " on floor " << j.floor << endl;
}
第9章 内存模型和名称空间
1.头文件管理
#ifndef COORDIN_H_
#define COORDIN_H_
#endif
在C和C++编程中,#ifndef、#define 和 #endif 是预处理指令,通常用于防止头文件(header file)的内容在一个编译单元中被多次包含。这被称为包含保护(include guard)或头文件保护。
具体来说:
#ifndef:这是一个条件编译指令,它检查一个宏(在这里是COORDIN_H_)是否已经定义。如果宏没有定义,那么后面的代码(直到遇到配对的#endif)将会被编译器处理。#define:这个指令用于定义一个宏。在这里,它定义了COORDIN_H_这个宏。一旦这个宏被定义,后续的#ifndef COORDIN_H_检查就会失败,从而避免再次包含这个头文件的内容。#endif:这个指令标志着#ifndef条件块的结束。
这样做的目的是确保即使头文件在多个地方被包含,其内容也只会被编译一次。这可以避免因重复定义引发的各种编译错误,如变量或函数的重复定义。
在你提供的代码片段中:
#ifndef COORDIN_H_
#define COORDIN_H_
// ... 头文件内容 ...
#endif
如果 COORDIN_H_ 还没有被定义,那么整个头文件的内容会被包含在编译中。一旦这个头文件被包含一次并且 COORDIN_H_ 被定义,后续的包含请求就会因 #ifndef COORDIN_H_ 检查失败而被忽略。
这是一种常见的头文件保护技术,用于确保头文件的唯一性和一致性。
2.extern double warming;
在C或C++编程中,extern double warming; 是一个声明,它告诉编译器warming是一个double类型的变量,但这个变量的定义(即分配内存空间的部分)是在别的文件中。extern关键字用于指明变量或函数在其他地方有定义,因此编译器在当前文件中不会为其分配内存。
具体来说,extern double warming;通常出现在头文件中,用来告诉包含这个头文件的源文件:warming这个变量在别的地方(可能是另一个源文件或库)有定义,所以你可以在这里引用它,但不要在这里重新定义它。
例如,假设你有两个源文件:main.c和data.c,以及一个头文件data.h。
在data.c中,你定义了warming变量:
// data.c
#include "data.h"
double warming = 0.5; // 定义并初始化warming变量
在data.h中,你声明了warming变量:
// data.h
extern double warming; // 声明warming变量,告诉编译器它在其他地方有定义
然后,在main.c中,你可以通过包含data.h来引用warming变量:
// main.c
#include <stdio.h>
#include "data.h"
int main() {
printf("The warming value is: %f\n", warming);
return 0;
}
在编译时,链接器会查找warming变量的定义(在这个例子中是data.c中的定义),并将其与main.c中的引用关联起来。这样,main.c中的代码就可以访问和修改warming变量的值了。
需要注意的是,如果warming变量在任何地方都没有定义,链接器会报错,因为它找不到这个变量的实际内存位置。
3.作用域解释符(::)
在编程中,:: 是一个作用域解析运算符(Scope Resolution Operator),主要用于C++语言中。它有两个主要用途:
- 指定类中的成员:当你想访问一个类的静态成员(包括静态变量、静态函数、枚举值等)或者嵌套类型(比如类内部的另一个类)时,你可以使用
::运算符。
class MyClass {
public:
static int myStaticVar;
void myFunction();
class NestedClass {
// ...
};
};
int MyClass::myStaticVar = 0; // 使用 :: 访问和定义静态成员变量
void MyClass::myFunction() {
// 函数实现
}
int main() {
MyClass::myStaticVar = 42; // 访问静态成员变量
MyClass::NestedClass nestedObj; // 创建嵌套类的实例
return 0;
}
- 指定命名空间中的实体:在C++中,命名空间用于封装相关的代码实体(如变量、函数、类等),以避免命名冲突。
::运算符可以用来指定命名空间中的特定实体。
namespace MyNamespace {
int myVariable = 10;
void myFunction() {
// 函数实现
}
}
int main() {
int x = MyNamespace::myVariable; // 使用 :: 访问命名空间中的变量
MyNamespace::myFunction(); // 调用命名空间中的函数
return 0;
}
此外,在全局作用域中使用 :: 运算符表示的是全局作用域本身,这在某些上下文中(如模板编程)可能很有用。
4.static
在C++中,static关键字具有多种用途,每种用途都赋予变量或函数不同的特性。以下是static关键字在C++中的几种主要用法及其解释:
- 局部静态变量:
当在函数内部声明一个静态变量时,该变量的生命周期会持续到程序结束,而不是在函数返回时结束。这意味着,每次函数调用时,该变量的值都会被保留,而不是被重新初始化。
void count() {
static int calls = 0; // 静态局部变量
calls++;
std::cout << "Function has been called " << calls << " times." << std::endl;
}
- 类静态成员:
静态成员变量属于类本身,而不是类的任何特定对象。所有对象共享同一个静态成员变量的实例。静态成员函数只能访问静态成员变量或其他静态成员函数,不能访问类的非静态成员。
class MyClass {
public:
static int count; // 静态成员变量
static void incrementCount() { count++; } // 静态成员函数
};
int MyClass::count = 0; // 静态成员变量的定义
- 静态类内部对象:
在类中,可以使用static来声明一个静态的对象。这样的对象在类的第一次使用之前就被创建,并在程序的整个生命周期中保持存在。
class MyClass {
public:
static MyClass staticObject; // 静态对象
// ... 其他成员 ...
};
MyClass MyClass::staticObject; // 静态对象的定义
- 静态函数:
在文件作用域(即全局作用域)中,static函数只能在声明它的文件中被调用。它对于其他文件是不可见的,因此可以提供一定程度的封装,避免名称冲突。
// file1.cpp
static void myFunction() {
// ...
}
// file2.cpp
// myFunction() 在这里是不可见的
- 静态全局变量:
全局作用域中的静态变量具有内部链接性,这意味着它们只在定义它们的文件内可见。这与没有static关键字的全局变量形成对比,后者具有外部链接性,可以在其他文件中通过extern关键字访问。
// file1.cpp
static int myGlobalVariable = 42; // 静态全局变量,只在file1.cpp中可见
// file2.cpp
extern int myGlobalVariable; // 错误:myGlobalVariable在file2.cpp中不可见
使用static关键字时,需要清楚其上下文,因为不同的上下文会赋予static不同的意义。在编写代码时,合理地使用static可以帮助你管理变量的生命周期和可见性,从而提高代码的可读性和可维护性。
5.const
在C++中,const是一个类型修饰符,用于指定一个变量、对象或函数返回值为常量,这意味着它们的值在初始化后不能被修改。const关键字可以用于多种上下文,提供不同级别的保护。
以下是const在C++中的一些常见用法:
- 常量变量:
使用const声明的变量必须在声明时初始化,并且之后不能再被修改。
const int x = 10; // x是一个常量,其值为10,且不能被修改
- 常量指针和指针常量:
const可以用于指针的声明,以指定指针本身是否可变,或指针指向的值是否可变。
const int* p1 = &x; // p1指向一个常量整数,不能通过p1来修改x的值
int const* p2 = &x; // 与p1相同,也是指向一个常量整数的指针
int* const p3 = &y; // p3是一个常量指针,指向一个整数,p3的值(即它指向的地址)不能改变
const int* const p4 = &z; // p4是一个指向常量整数的常量指针,都不能被修改
- 常量引用:
引用本质上是一个已存在变量的别名,而const引用则指向一个不能被修改的值。
const int& ref = x; // ref是x的引用,但不能通过ref来修改x的值
- 常量成员函数:
在类的成员函数中,const可以表明这个函数不会修改它所属对象的任何成员变量(除了声明为mutable的成员变量)。
class MyClass {
public:
int value;
int GetValue() const { return value; } // 不会修改value的值
};
- 常量对象:
类也可以被声明为const,这意味着该类的所有成员函数(除非它们被声明为mutable)和成员变量都必须是const的。
const MyClass obj; // obj是一个常量对象,它的所有成员函数都必须是const的
- 常量表达式:
constexpr关键字(从C++11开始引入)用于指定一个表达式或变量的值在编译时是已知的,且不可改变。
constexpr int limit = 100; // limit是一个常量表达式,其值在编译时已知
使用const的好处包括:
- 提高代码可读性:
const变量和函数的使用可以清晰地表明哪些值是不应该被修改的。 - 防止错误:通过使用
const,可以防止程序员意外地修改不应该被修改的值。 - 优化:编译器通常可以对
const变量和constexpr表达式进行更高级的优化。
总的来说,const是C++中用于实现常量性和保护数据不被意外修改的重要工具。
6.new
在C++中,new是一个操作符,用于在动态内存分配中创建对象。当你使用new操作符时,它会在堆上分配足够的内存来存储所请求类型的对象,并返回指向该新创建对象的指针。与在栈上分配对象(例如通过声明局部变量)不同,new创建的对象将一直存在,直到使用delete操作符显式释放它们,或者程序结束时才会被自动释放。
以下是new操作符的基本用法:
int* p = new int; // 分配一个int大小的内存,并返回指向它的指针
double* dp = new double; // 分配一个double大小的内存
// 对于对象,同样适用
std::string* strPtr = new std::string("Hello, World!");
你也可以使用new来分配对象数组:
int* arr = new int[10]; // 分配一个包含10个int的数组
使用new时,如果内存分配失败(例如,由于内存不足),它将抛出std::bad_alloc异常。因此,在实际使用中,你通常会希望将new操作放在try/catch块中,以处理可能的异常。
请注意,当你使用new分配内存后,有责任在不再需要这些内存时使用delete或delete[]来释放它们,以避免内存泄漏。
delete p; // 释放之前由new int分配的内存
delete[] arr; // 释放之前由new int[10]分配的内存数组
delete strPtr; // 释放之前由new std::string分配的内存和销毁对象
在C++11及更高版本中,new还可以与初始化列表一起使用,以便在对象创建时初始化其成员:
MyClass* obj = new MyClass{param1, param2, param3}; // 使用初始化列表
此外,C++11还引入了智能指针(如std::unique_ptr和std::shared_ptr),它们可以自动管理动态分配的内存的生命周期,从而减少了手动管理内存的需要和内存泄漏的风险。
std::unique_ptr<int> smartPtr(new int(5)); // 使用unique_ptr来自动管理int的生命周期
使用智能指针通常是比直接使用new和delete更好的做法,因为它们提供了更强的类型安全性和内存安全性。
7.名称空间
名称空间(Namespace)是许多编程语言中用于组织代码的一种形式。其主要目的是通过分类和区分不同的代码功能,以避免不同代码片段(通常由不同的人协同工作或调用已有的代码片段)同时使用时由于不同代码间变量名相同而造成冲突。
在编程中,名称空间可以看作是一个容器,它包含了各种标识符(如变量名、函数名、类名等)。通过使用名称空间,我们可以将这些标识符组织起来,使得它们在不同的名称空间中具有唯一的标识,从而避免命名冲突。
以C++为例,名称空间可以有以下几种类型:
- 用户定义的有名字的名称空间:用户可以创建自己的名称空间,用于组织自己的代码。在名称空间中声明的名称的链接性为外部的,这意味着它们可以被其他代码片段访问。此外,名称空间是开放的,即可以把名称加入到已有的名称空间中。
- 全局名称空间:对应于文件级声明区域。全局变量位于全局名称空间中。全局名称空间中的标识符在整个程序范围内都是可见的。
- 局部名称空间:在函数调用时产生,并在函数调用完毕后回收。它包含了在函数体内定义的变量和函数等。
名称空间的加载顺序和回收顺序通常是:内置名称空间首先加载和最后回收,全局名称空间次之,局部名称空间最后加载和最先回收。在查找标识符时,编译器会按照从当前位置向内置名称空间、全局名称空间、局部名称空间的顺序进行查找。
使用名称空间的好处包括提高代码的可读性和可维护性,减少命名冲突的可能性,以及更好地组织和管理代码。同时,通过使用智能指针等现代C++特性,我们还可以更有效地管理内存,避免内存泄漏等问题。
当涉及到名称空间(Namespace)的代码示例时,我们可以使用C++语言来展示其用法。下面是一个简单的示例,演示了如何在C++中使用名称空间。
假设我们有两个名称空间:NamespaceA 和 NamespaceB,它们各自包含一些函数和变量。
// NamespaceA.h
#ifndef NAMESPACEA_H
#define NAMESPACEA_H
namespace NamespaceA {
int variableA = 10;
void functionA() {
std::cout << "Function A from NamespaceA" << std::endl;
}
}
#endif // NAMESPACEA_H
// NamespaceB.h
#ifndef NAMESPACEB_H
#define NAMESPACEB_H
#include <iostream>
namespace NamespaceB {
int variableB = 20;
void functionB() {
std::cout << "Function B from NamespaceB" << std::endl;
}
}
#endif // NAMESPACEB_H
现在,我们有一个主程序,它使用这两个名称空间中的函数和变量。
// main.cpp
#include <iostream>
#include "NamespaceA.h"
#include "NamespaceB.h"
int main() {
// 使用完整限定名访问名称空间中的函数和变量
std::cout << "Variable A from NamespaceA: " << NamespaceA::variableA << std::endl;
NamespaceA::functionA();
std::cout << "Variable B from NamespaceB: " << NamespaceB::variableB << std::endl;
NamespaceB::functionB();
// 使用using声明引入特定名称到当前作用域
using NamespaceA::variableA;
std::cout << "Variable A (using declaration): " << variableA << std::endl;
// 使用using编译指令引入整个名称空间到当前作用域(注意:这可能会导致命名冲突)
using namespace NamespaceB;
std::cout << "Variable B (using directive): " << variableB << std::endl;
functionB();
return 0;
}
在上面的示例中,我们使用了完整限定名来访问名称空间中的函数和变量。然后,我们使用using声明将NamespaceA中的variableA引入到当前作用域,这样我们就可以直接使用variableA而不需要前缀。最后,我们使用using编译指令将整个NamespaceB引入到当前作用域,这使得我们可以直接使用NamespaceB中的variableB和functionB,而不需要前缀。
请注意,在实际编程中,过度使用using编译指令可能会导致命名冲突,特别是在大型项目中。因此,建议谨慎使用,并尽量使用完整限定名或using声明来引入特定的名称。
8.using声明和using编译指令,以及比较
在C++中,using声明和using编译指令(也被称为using指令)是两个不同的概念,它们各自在命名空间(Namespace)的使用中扮演着不同的角色。下面我将对它们进行解释和比较。
using声明(Using Declaration)
using声明用于将特定命名空间中的名称引入到当前的命名空间中,使得我们可以不必通过命名空间的限定符(例如std::)来访问这些名称。
示例:
#include <iostream>
using std::cout; // using声明,引入cout到当前命名空间
using std::endl; // 引入endl到当前命名空间
int main() {
cout << "Hello, world!" << endl; // 不需要std::前缀
return 0;
}
在这个例子中,我们使用了using声明来引入std命名空间中的cout和endl。因此,在main函数中我们可以直接使用cout和endl,而不需要加上std::前缀。
using编译指令(Using Directive)
using编译指令(通常称为using指令)则是将整个命名空间的内容引入到当前的命名空间中。
示例:
#include <iostream>
using namespace std; // using指令,引入整个std命名空间
int main() {
cout << "Hello, world!" << endl; // 不需要std::前缀
return 0;
}
在这个例子中,using namespace std;使得std命名空间中的所有名称(例如cout、endl、vector等)在当前文件中都是可见的,不需要加上std::前缀。
比较
-
范围:
using声明仅引入命名空间中的特定名称。using指令引入整个命名空间中的所有名称。
-
可控性:
using声明更加可控,因为它只引入你需要的名称。using指令可能引入不必要的名称,增加了命名冲突的风险。
-
命名冲突风险:
using声明不太可能引入与当前命名空间中的名称冲突的名称,因为它只引入一个或几个特定的名称。using指令如果在一个包含多个命名空间的文件中使用,可能会引入与当前命名空间或其他命名空间中已有的名称冲突的名称。
-
推荐用法:
- 在头文件中,通常不建议使用
using指令,因为它可能会引入命名冲突。 - 在源文件中,如果确信不会引入命名冲突,可以使用
using指令来简化代码。 - 在任何情况下,
using声明都是安全的,因为它只引入你明确需要的名称。
- 在头文件中,通常不建议使用
总结
using声明和using指令都是用来简化代码书写、避免重复输入命名空间前缀的方法。然而,它们的使用应该谨慎,特别是在大型项目中,以避免引入不必要的命名冲突。通常建议在源文件而不是头文件中使用using指令,并且尽可能使用using声明来只引入需要的名称。
第10章 对象和类
1.类
在面向对象的编程中,类(Class)是一个非常重要的概念。类是创建对象的蓝图或模板,它定义了一组属性和方法,用于描述具有相同特性和行为的对象。通过类,我们可以创建多个具有相同结构和行为的对象实例。
下面是一个简单的C++类的示例:
// 定义一个名为Person的类
class Person {
public: // 公有成员,可以在类的外部访问
// 构造函数,用于初始化对象
Person(std::string name, int age) : name_(name), age_(age) {}
// 成员函数,用于获取名字
std::string getName() const {
return name_;
}
// 成员函数,用于获取年龄
int getAge() const {
return age_;
}
// 成员函数,用于设置年龄
void setAge(int age) {
age_ = age;
}
// 成员函数,用于打印个人信息
void printInfo() const {
std::cout << "Name: " << name_ << ", Age: " << age_ << std::endl;
}
private: // 私有成员,只能在类的内部访问
std::string name_; // 名字属性
int age_; // 年龄属性
};
// 主函数,用于演示类的使用
int main() {
// 创建Person类的对象实例
Person person1("Alice", 25);
Person person2("Bob", 30);
// 访问对象的公有成员
std::cout << "Person 1: " << std::endl;
person1.printInfo();
std::cout << "Person 2: " << std::endl;
person2.printInfo();
// 修改person2的年龄
person2.setAge(31);
std::cout << "Updated info for Person 2: " << std::endl;
person2.printInfo();
return 0;
}
在这个示例中,我们定义了一个名为Person的类,它有两个私有成员变量name_和age_,以及几个公有成员函数,如getName(), getAge(), setAge(), 和printInfo()。类的构造函数用于初始化对象的name_和age_属性。
在main()函数中,我们创建了两个Person类的对象实例person1和person2,并通过调用它们的公有成员函数来访问和修改它们的属性。
类还可以包含静态成员变量和静态成员函数,它们与类的所有实例共享相同的值或行为。类还可以继承自其他类,从而复用和扩展代码。
类是面向对象编程的基石,它允许我们创建具有复杂行为和数据结构的对象,并通过这些对象来模拟现实世界中的实体和它们之间的交互。
2.构造函数
构造函数是类的一种特殊成员函数,它的主要任务是初始化类对象的数据成员。在创建类的对象时,构造函数会被自动调用,以确保对象的数据成员被正确地初始化。
构造函数的特点包括:
- 函数名和类名必须一样,没有返回值,即使是
void类型也不行。 - 构造函数可以有多个,它们可以通过参数的数量或类型来区分,这被称为构造函数的重载。
- 如果没有显式地定义构造函数,编译器会自动生成一个默认的构造函数。
- 构造函数可以在创建对象时通过初始化列表为成员变量设置初始值。
根据参数的不同,构造函数可以分为以下几类:
- 无参构造函数:没有参数的构造函数,如
Test();。 - 带参数的构造函数:有一个或多个参数的构造函数,如
Test(int x, int y);,它可以在创建对象时初始化类内的数据成员。 - 默认构造函数:当没有显式地定义任何构造函数时,编译器会生成一个默认的构造函数,它不执行任何操作。
- 复制(拷贝)构造函数:它接受一个同类型的常量引用作为参数,并用于初始化新创建的对象作为现有对象的副本。
构造函数的主要作用是确保对象在创建时处于有效的状态。当对象被创建时,构造函数会被自动调用,并执行其中的初始化代码。这样,对象的成员变量就会被赋予正确的初始值,从而避免未定义的行为或错误。
下面是一个简单的C++构造函数的示例:
class MyClass {
public:
int value;
// 无参构造函数
MyClass() : value(0) {
// 构造函数体,可以在这里添加其他初始化代码
}
// 带参数的构造函数
MyClass(int initialValue) : value_(initialValue) {
// 使用初始化列表设置value的初始值
}
// 复制构造函数
MyClass(const MyClass& other) : value_(other.value) {
// 使用另一个对象来初始化当前对象
}
};
int main() {
MyClass obj1; // 调用无参构造函数,obj1.value被初始化为0
MyClass obj2(42); // 调用带参数的构造函数,obj2.value被初始化为42
MyClass obj3(obj2); // 调用复制构造函数,obj3是obj2的一个副本,obj3.value也被初始化为42
return 0;
}
在这个示例中,MyClass类定义了三个构造函数:一个无参构造函数,一个带参数的构造函数,和一个复制构造函数。在main()函数中,我们展示了如何使用这些构造函数来创建和初始化MyClass的对象。
3.隐式和显式调用构造函数的区别
在C++中,构造函数可以通过两种方式调用:隐式调用和显式调用。这两种调用方式有一些区别,主要取决于调用方式和情境。
-
隐式调用构造函数:
- 隐式调用发生在对象声明或定义时,而不需要显式地调用构造函数。
- 当你声明对象时,如果提供了构造函数的参数(在括号中),编译器会自动调用相应的构造函数来初始化对象。
- 如果没有提供参数,则会调用默认构造函数(如果定义了的话)。
-
显式调用构造函数:
- 显式调用发生在通过构造函数调用语法明确指定要调用构造函数的情况下。
- 这意味着在创建对象时,你可以使用构造函数调用语法,并提供适当的参数列表来调用构造函数。
- 这种情况下,你可以选择调用任何一个构造函数,包括默认构造函数和带参数的构造函数。
以下是一个简单的示例,说明了隐式和显式调用构造函数的区别:
#include <iostream>
#include <string>
class Person {
private:
std::string name;
int age;
public:
// 带参数的构造函数
Person(const std::string& n, int a) : name(n), age(a) {
std::cout << "Constructor called for " << name << std::endl;
}
// 默认构造函数
Person() : name("Unknown"), age(0) {
std::cout << "Default constructor called" << std::endl;
}
// 显示个人信息
void display() {
std::cout << "Name: " << name << ", Age: " << age << std::endl;
}
};
int main() {
// 隐式调用构造函数
Person person1("Alice", 30);
Person person2; // 隐式调用默认构造函数
// 显示调用构造函数
Person person3 = Person("Bob", 25);
// 显示对象的信息
std::cout << "Person 1: ";
person1.display();
std::cout << "Person 2: ";
person2.display();
std::cout << "Person 3: ";
person3.display();
return 0;
}
在这个示例中,person1 和 person2 都是隐式调用构造函数创建的对象,而 person3 是显式调用构造函数创建的对象。
4.析构函数
在C++中,析构函数(Destructor)是一种特殊的成员函数,用于在对象被销毁时执行必要的清理工作。析构函数的名称与类名相同,前面加上一个波浪号(~),并且没有参数和返回类型(包括void)。
在对象的生命周期结束时(例如,对象超出了其作用域,或者通过delete运算符显式销毁),析构函数会被自动调用。这使得在对象销毁时可以执行一些必要的清理操作,如释放动态分配的内存、关闭打开的文件等。
下面是一个简单的示例,展示了一个类和其析构函数的定义:
#include <iostream>
class MyClass {
public:
MyClass() {
std::cout << "Constructor called" << std::endl;
}
~MyClass() {
std::cout << "Destructor called" << std::endl;
}
};
int main() {
{
MyClass obj; // 创建对象
} // 对象超出作用域,析构函数被调用
return 0;
}
在这个示例中,MyClass类具有一个析构函数。在main()函数中,创建了一个MyClass类的对象obj,并且该对象在其声明的作用域结束时被销毁。因此,当对象obj超出作用域时,析构函数会被调用,打印出"Destructor called"。
如果构造函数使用了new,则必须提供使用delete的析构函数。
5.对象数组
对象数组(Object Array)是一种特殊的数组,它的元素是对象而非基本数据类型。在面向对象编程中,对象数组允许我们存储和管理同一类对象的集合。每个数组元素都是一个对象,具有该类定义的所有属性和方法。
在C++中,定义对象数组的基本语法如下:
ClassName arrayName[arraySize];
其中,ClassName 是对象的类名,arrayName 是数组的名称,arraySize 是数组的大小(即可以容纳的对象数量)。
例如,假设我们有一个名为 Student 的类,我们可以这样定义一个包含10个 Student 对象的数组:
Student students[10];
这样,students 数组就包含了10个 Student 类型的对象,每个对象都可以调用 Student 类中定义的方法,并访问其属性。
访问对象数组中的元素与访问基本数据类型数组的元素类似,通过下标操作符 [] 来实现。例如,要访问 students 数组中的第一个 Student 对象,并调用其某个方法 printInfo(),可以这样做:
students[0].printInfo();
这里,students[0] 表示数组中的第一个元素(即第一个 Student 对象),然后通过 . 操作符调用该对象的 printInfo() 方法。
需要注意的是,当对象数组超出其作用域或被销毁时,其包含的每个对象也会自动调用其析构函数进行清理工作。因此,在定义对象数组时,需要确保类的析构函数能够正确地释放对象所占用的资源,以避免内存泄漏等问题。
6.this指针
在C++中,this 是一个指向当前对象的指针。它是一个隐式参数,可用于访问对象的成员变量和方法。this 指针在每个对象的上下文中都是唯一的,它指向正在调用成员函数的对象。
this 指针主要用于以下几种情况:
-
在成员函数中访问成员变量:在成员函数中,可以使用
this->或者省略this->直接访问对象的成员变量。例如:class MyClass { private: int x; public: void setX(int val) { this->x = val; // 使用this指针设置成员变量 } }; -
返回对象本身:可以在成员函数中使用
return *this;来返回对象本身,从而支持方法链式调用。例如:class MyClass { public: MyClass& increment() { // 增加x值,并返回对象本身 this->x++; return *this; } }; -
在构造函数和析构函数中:在构造函数和析构函数中,
this指针可以用于访问对象的成员变量和方法,就像在其他成员函数中一样。但需要小心在构造函数中使用this指针,因为对象可能还没有完全构造完成。 -
解决命名冲突:当参数名与成员变量名相同时,可以使用
this指针来区分它们。例如:class MyClass { private: int x; public: void setX(int x) { this->x = x; // 使用this指针区分成员变量和参数 } };
总之,this 指针是 C++ 中的一个重要概念,用于在成员函数中引用当前对象。
7.类作用域
在C++中,类作用域指的是类的成员(包括成员变量和成员函数)的作用域范围。类的作用域在定义类时确定,并且类的成员可以在类的任何地方被访问,只要在作用域内。
以下是关于类作用域的一些重要概念:
-
成员变量的作用域:类的成员变量的作用域从它们被声明的位置开始,一直持续到类的结束。这意味着任何类的成员函数都可以访问这些成员变量。
-
成员函数的作用域:成员函数的作用域与成员变量类似,从它们被声明的位置开始,一直持续到类的结束。成员函数可以访问类的所有成员变量,包括私有成员变量。
-
成员函数的定义位置:成员函数的定义通常在类的外部进行,这样可以使类的声明更加简洁。在定义成员函数时,需要使用作用域解析运算符
::来指定函数所属的类。例如:class MyClass { public: void myFunction(); // 声明成员函数 }; // 在类外部定义成员函数 void MyClass::myFunction() { // 函数体 } -
成员函数内部的作用域:成员函数内部可以定义局部变量和内部类,这些局部变量和内部类的作用域仅限于成员函数内部。
-
静态成员变量和静态成员函数:静态成员变量和静态成员函数的作用域与普通成员相同,但它们属于类本身而不是类的对象。因此,它们可以在类的任何地方被访问,甚至不需要创建类的对象。
总之,类作用域决定了类的成员在程序中的可见性和访问性,使得类能够组织和封装数据以及相关操作。
8.抽象数据类型
在C++中,抽象数据类型(Abstract Data Type,ADT)是指一种数学模型,它定义了一组数据和一组操作这些数据的操作。ADT 将数据的逻辑属性和操作分离开来,使得数据的实现细节对用户是不可见的,用户只能通过操作来访问和修改数据。
在 C++ 中,ADT 通常通过类来实现。类封装了数据和相关操作,将数据的表示和操作的实现细节隐藏起来,使得用户只能通过类的公共接口来访问和操作数据。下面是一个简单的示例,展示了如何在 C++ 中实现一个抽象数据类型:
#include <iostream>
// 抽象数据类型
class Stack {
private:
static const int MAX_SIZE = 100; // 栈的最大大小
int arr[MAX_SIZE]; // 存储栈元素的数组
int top; // 栈顶指针
public:
Stack() : top(-1) {} // 构造函数,初始化栈顶指针
void push(int value) { // 入栈操作
if (top < MAX_SIZE - 1) {
arr[++top] = value;
} else {
std::cerr << "Stack overflow!" << std::endl;
}
}
int pop() { // 出栈操作
if (top >= 0) {
return arr[top--];
} else {
std::cerr << "Stack underflow!" << std::endl;
return -1;
}
}
bool isEmpty() const { // 判断栈是否为空
return top == -1;
}
};
int main() {
Stack stack;
stack.push(10);
stack.push(20);
stack.push(30);
while (!stack.isEmpty()) {
std::cout << stack.pop() << std::endl;
}
return 0;
}
在这个示例中,Stack 类代表了一个简单的栈抽象数据类型。它封装了一个数组和相关的操作,包括入栈、出栈和判断栈是否为空。用户只能通过 push()、pop() 和 isEmpty() 这些公共接口来操作栈,而无需关心栈的实现细节。这种将数据的表示和操作分离的设计使得代码更加模块化、可维护和可重用。















 4527
4527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









