



文章目录
- 图解机器学习算法笔记
- 一、机器学习概要
- 二、有监督学习
- 三、无监督学习
- 四、评估方法和各种数据的处理
图解机器学习算法笔记
一、机器学习概要
1.什么是机器学习
机器学习指的是计算机根据给定的问题、课题或环境进行学习,并利用学习结果解决问题或课题等的一整套机制.
对结果的验证通常应使用另外准备的一些不用于学习的数据来进行,否则会产生过拟合(overfitting)问题。
2.机器学习的种类
机器学习包含不同的种类。根据不同的输入数据,分类如下:
- 有监督学习
- 无监督学习
- 强化学习
(1)有监督学习(回归和分类)
有监督学习是将问题的答案告知计算机,使计算机进行学习并给出机器学习模型的方法。这种方法要求数据中包含表示特征的数据和作为答案的目标数据。
答案变量不是连续值,而是作为类别数据的离散值的问题就是分类问题。

有监督学习算法与分类和回归的应用范围:
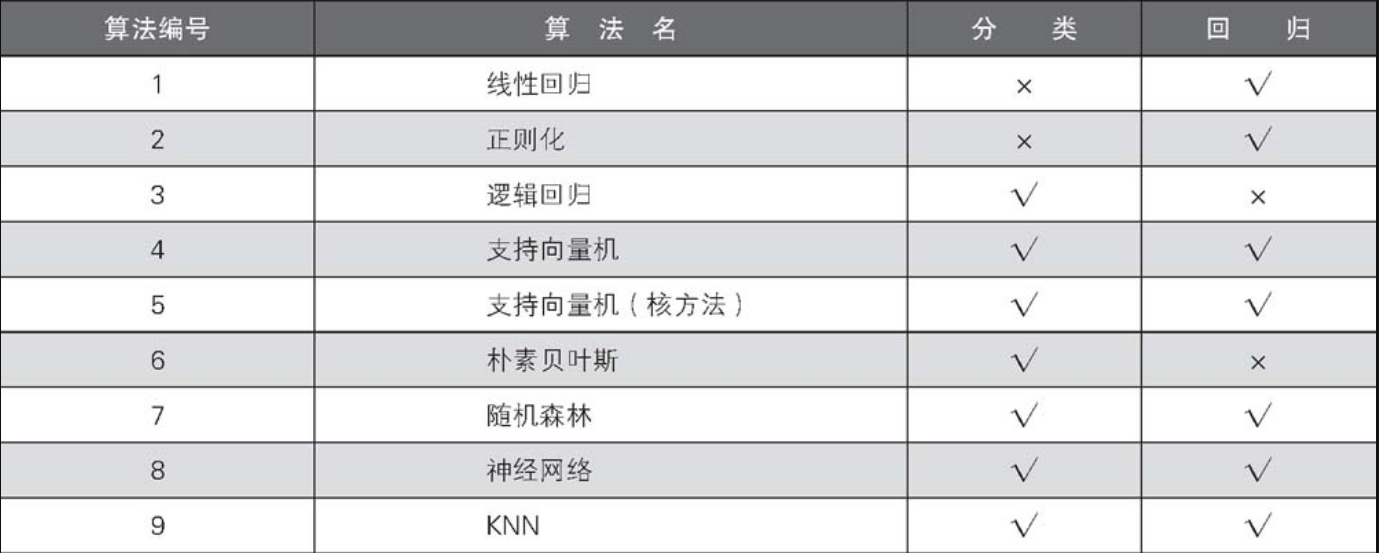
(2)无监督学习(降维和聚类)
有监督学习是将特征值和目标变量(答案)作为一套数据进行学习的方法,而无监督学习的数据中没有作为答案的目标变量。
无监督学习的降维和聚类的关系:
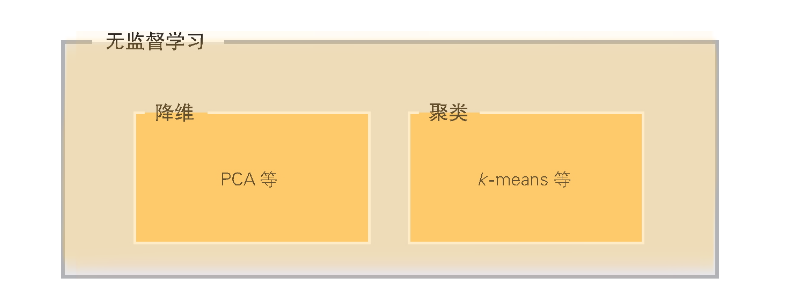
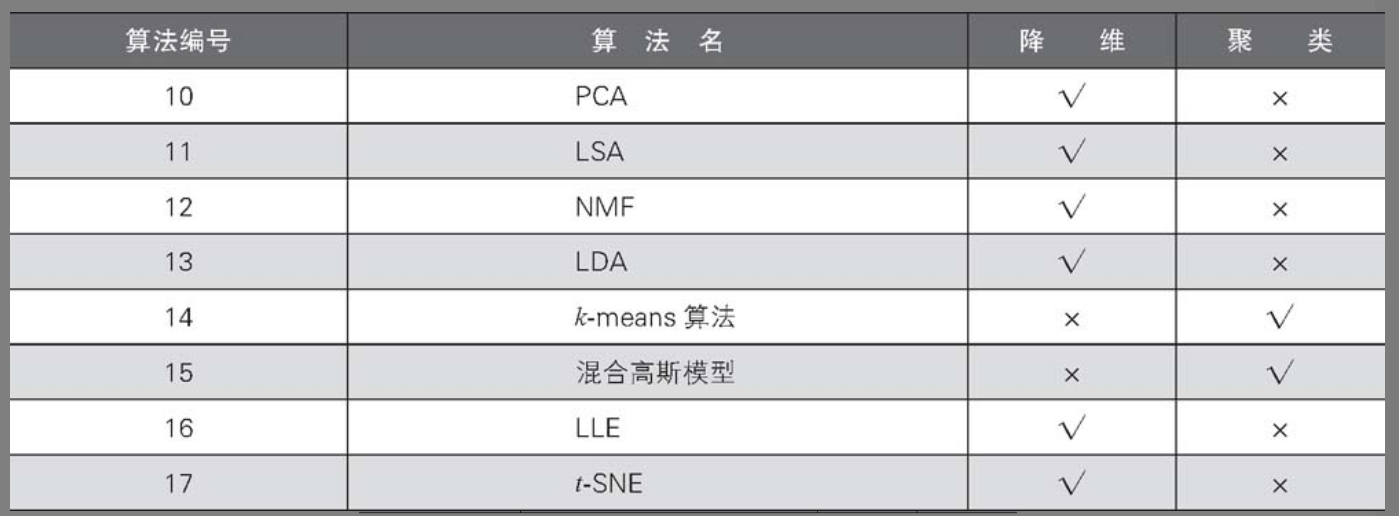
无监督学习与降维和聚类的应用范围
(3)强化学习
强化学习是以在某个环境下行动的智能体获得的奖励最大化为目标而进行学习的方法。
也可以把强化学习看作有监督学习的目标变量被作为奖励提供的情况。
3.可视化
可视化是利用图形等把握数据的整体情况的方法。在机器学习领域中,许多场景下需要进行可视化。有时用于了解数据的概况,有时用于以图形展示机器学习的结果。
Python 可视化工具 Matplotlib。Python 的可视化工具不只有 Matplotlib,还有以下几种:
- pandas:pandas 是处理数组数据的库,也具有可视化功能。
- seaborn:seaborn 在 Matplotlib 的基础上强化了表现力,用起来更简单。
- Bokeh:Bokeh 使用了 JavaScript,可用于显示动态图形。
(1)使用 Matplotlib 显示图形
在 Jupyter Notebook 页面上可显示图形。在 Code 单元格内,运行 %matplotlib inline 这个以 % 开始的“魔法”命令后,即使不运行后面将介绍的 show方法,页面上也会输出图形
在本地自己的编译器中则不需要那个魔法指令,直接show就可以了
- 可以自己画各种图,也可如下中方法
- 使用 scatter 方法绘制散点图
- 使用 hist 方法绘制直方图
- 使用 bar 方法绘制柱状图
- 使用 plot 方法绘制折线图
- 使用 boxplot 方法绘制箱形图
(2)使用 pandas 理解和处理数据
在进行机器学习时,有时会查看特征值、对数据进行取舍选择或再加工等。
二、有监督学习

1.线性回归
拿到数据之后,首先应该进行可视化,再考虑是否进行线性回归。
线性回归(linear regression)是用于预测回归问题的算法。该算法根据训练数据计算使损失最小的参数的做法是有监督学习算法的共同之处。
斜率和截距是由有监督学习的算法学到的参数,我们称之为学习参数。是否为线性回归不是从特征变量来看的。而是从学习参数的角度来看的。
线性回归算法一般使用一个以上的特征变量创建模型,其中只有一个独立的特征变量的情况叫作一元回归。还有多元回归和多项式回归。
表示误差和学习参数之间关系的函数叫作误差函数(或损失函数)。
对于计算出的两条直线中的哪一条更好地表示了数据的关联性呢?
我们可以通过均方误差进行定量判断。均方误差指的是目标变量和直线的差。注意一些均方误差的最小化方法
2.正则化
正则化是防止过拟合的一种方法,与线性回归等算法配合使用。通过向损失函数增加惩罚项的方式对模型施加制约,有望提高模型的泛化能力。
正则化是防止过拟合的方法,用于机器学习模型的训练阶段。过拟合是模型在验证数据上产生的误差比在训练数据上产生的误差(训练误差)大得多的现象。过拟合的一个原因是机器学习模型过于复杂。正则化可以降低模型的复杂度,有助于提高模型的泛化能力。
正则化可以通过向损失函数增加惩罚项的方式防止过拟合。
一般来说,惩罚项中不包含截距。
(1)岭回归(ridge regression)
岭回归(Ridge Regression)是一种用于回归分析的技术,它是线性回归的一种改进方法,特别适用于处理数据的共线性问题,即特征之间高度相关的情况。岭回归通过引入L2正则化项来降低模型的复杂度,从而减少过拟合的风险。
在线性回归模型中,我们尝试最小化损失函数,该函数是观测值和模型预测值之间差异的度量。在岭回归中,损失函数被修改为原始损失函数加上一个与模型参数大小相关的惩罚项,即:
J
(
β
)
=
MSE
(
y
,
X
β
)
+
λ
∑
j
=
1
p
β
j
2
J(\beta) = \text{MSE}(y, X\beta) + \lambda \sum_{j=1}^{p} \beta_j^2
J(β)=MSE(y,Xβ)+λj=1∑pβj2
其中:
-
J ( β ) 是要最小化的目标函数。 J(\beta) 是要最小化的目标函数。 J(β)是要最小化的目标函数。
-
MSE ( y , X β ) 是均方误差,衡量模型预测值和实际观测值之间的差异。 \text{MSE}(y, X\beta) 是均方误差,衡量模型预测值和实际观测值之间的差异。 MSE(y,Xβ)是均方误差,衡量模型预测值和实际观测值之间的差异。
-
λ 是正则化参数,控制惩罚项的强度。 \lambda 是正则化参数,控制惩罚项的强度。 λ是正则化参数,控制惩罚项的强度。
-
β j 是模型的参数。 \beta_j 是模型的参数。 βj是模型的参数。
-
p 是特征的数量。 p 是特征的数量。 p是特征的数量。
通过引入正则化项,岭回归在训练模型时会考虑使模型参数尽可能小,从而防止模型过于复杂。正则化参数 λ 的选择很重要,较大的λ 值会导致模型更加简单,但可能欠拟合;较小的λ 值可能导致模型复杂,容易过拟合。
岭回归的一个优点是它总是有一个解(只要 ( λ > 0 )),这在线性回归中特征矩阵 ( X ) 的列线性相关时是一个问题。因此,岭回归在处理多重共线性问题时特别有用。
在实际应用中,岭回归可以通过各种统计软件和机器学习库来实现,如Python的scikit-learn库。
(2)Lasso 回归
Lasso 回归的惩罚项是学习参数的绝对值之和
Lasso回归(Least Absolute Shrinkage and Selection Operator Regression),也是一种线性回归的改进方法,它通过在损失函数中引入L1正则化项来解决过拟合问题,并且在具有大量特征的数据集中进行特征选择。Lasso回归的损失函数可以表示为:
J
(
β
)
=
MSE
(
y
,
X
β
)
+
λ
∑
j
=
1
p
∣
β
j
∣
J(\beta) = \text{MSE}(y, X\beta) + \lambda \sum_{j=1}^{p} |\beta_j|
J(β)=MSE(y,Xβ)+λj=1∑p∣βj∣
其中:
J
(
β
)
是要最小化的目标函数。MSE
(
y
,
X
β
)
是均方误差,衡量模型预测值和实际观测值之间的差异。
λ
是正则化参数,控制惩罚项的强度。
β
j
是模型的参数。
p
是特征的数量。
J(\beta) 是要最小化的目标函数。 \text{MSE}(y, X\beta) 是均方误差,衡量模型预测值和实际观测值之间的差异。 \lambda是正则化参数,控制惩罚项的强度。 \beta_j 是模型的参数。 p 是特征的数量。
J(β)是要最小化的目标函数。MSE(y,Xβ)是均方误差,衡量模型预测值和实际观测值之间的差异。λ是正则化参数,控制惩罚项的强度。βj是模型的参数。p是特征的数量。
Lasso回归中的L1正则化项
λ
∑
j
=
1
p
∣
β
j
∣
\lambda \sum_{j=1}^{p} |\beta_j|
λj=1∑p∣βj∣
使得一部分不重要的特征对应的系数恰好为零,从而实现了特征选择的效果。这种特性使得Lasso回归特别适合于高维数据,因为它不仅可以减少过拟合的风险,还可以帮助识别出对预测目标有重要影响的特征。
与岭回归相比,Lasso回归更可能选择出一个稀疏的模型(即只有少数特征的系数非零),而岭回归则倾向于使所有特征的系数都较小但不为零。选择Lasso回归还是岭回归取决于具体的数据特性和模型需求。
Lasso回归的一个挑战是它的解可能不是唯一的,特别是在多个特征高度相关的情况下。此外,选择合适的正则化参数 λ 也是关键,通常需要通过交叉验证等技术来确定。
Lasso 回归计算的是函数与这种四边形函数的交点,因此具有学习参数容易变为 0 的特点。利用这个特点,我们可以使用学习参数不为 0 的特征来构建模型,从而达到利用 Lasso 回归选择特征的效果。这样不仅能提高模型的泛化能力,还能使模型的解释变容易。
3.逻辑回归
逻辑回归是一种用于有监督学习的分类任务的简单算法。虽然算法的名字中包含“回归”二字,但其实它是用于分类问题的算法。逻辑回归通过计算数据属于各类别的概率来进行分类。
逻辑回归是一种学习某个事件发生概率的算法。利用这个概率,可以对某个事件发生或不发生进行二元分类。
逻辑损失作为误差函数进行最小化。与其他误差函数一样,逻辑损失是在分类失败时返回大值,在分类成功时返回小值的函数。
import numpy as np
from sklearn.linear_model import LogisticRegression
X_train = np.r_[np.random.normal(3, 1, size=50), np.random.normal(-1, 1, size=50)].reshape((100, -1))
y_train = np.r_[np.ones(50), np.zeros(50)]
model = LogisticRegression()
model.fit(X_train, y_train)
var = model.predict_proba([[0], [1], [2]])[:, 1]
print(var)
[0.06811025 0.47787441 0.91975084]
(1)决策边界
在解决分类问题时,如果让学习后的模型对未知数据分类,模型就会以某个地方为边界来区分分类结果,这个边界就叫作决策边界。逻辑回归的决策边界是计算出的概率正好为 50% 的地方。
4.支持向量机
支持向量机(Support Vector Machine,SVM)是一种应用范围非常广泛的算法,既可以用于分类,也可以用于回归。
(1)线性支持向量机
线性支持向量机(Linear Support Vector Machine,LSVM)处理二元分类。线性支持向量机是以间隔最大化为基准,来学习得到尽可能地远离数据的决策边界的算法。虽然该算法的决策边界与逻辑回归一样是线性的,但有时线性支持向量机得到的结果更好。
线性支持向量机的学习方式是:以间隔最大化为基准,让决策边界尽可能地远离数据。
训练数据中最接近决策边界的数据与决策边界之间的距离就称为间隔。
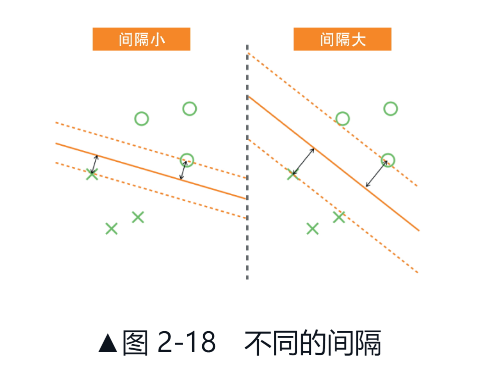
from sklearn.svm import LinearSVC
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 数据生成
centers = [(-1, -0.125), (0.5, 0.5)]
X, y = make_blobs(n_samples=50, n_features=2, centers=centers, cluster_std=0.3)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
model = LinearSVC()
model.fit(X_train, y_train) # 训练
y_pred = model.predict(X_test)
accuracy_score(y_pred, y_test) # 评估
print(accuracy_score(y_pred, y_test))
1.0
(2)软间隔和支持向量
不允许数据进入间隔内侧的情况称为硬间隔。但一般来说,数据并不是完全可以线性分离的,所以要允许一部分数据进入间隔内侧,这种情况叫作软间隔。
基于线性支持向量机的学习结果,我们可以将训练数据分为以下 3 种。
- 与决策边界之间的距离比间隔还要远的数据:间隔外侧的数据。
- 与决策边界之间的距离和间隔相同的数据:间隔上的数据。
- 与决策边界之间的距离比间隔近,或者误分类的数据:间隔内侧的数据。
间隔上的数据和间隔内侧的数据特殊对待,称为支持向量。支持向量是确定决策边界的重要数据。间隔外侧的数据则不会影响决策边界的形状
由于间隔内侧的数据包含被误分类的数据,所以乍看起来通过调整间隔,使间隔内侧不存在数据的做法更好。但对于线性可分的数据,如果强制训练数据不进入间隔内侧,可能会导致学习结果对数据过拟合。
在使用软间隔时,允许间隔内侧进入多少数据由超参数决定。与其他算法一样,在决定超参数时,需要使用网格搜索(grid search)和随机搜索(random search)等方法反复验证后再做决定。
5.支持向量机(核方法)
核方法的一个常见解释是“将数据移动到另一个特征空间,然后进行线性回归”。
构建线性分离的高维空间非常困难,但通过一个叫作核函数的函数,核方法就可以使用在高维空间中学习到的决策边界,而无须构建具体的线性分离的高维空间。
from sklearn.svm import SVC
from sklearn.datasets import make_gaussian_quantiles
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 数据生成
X, y = make_gaussian_quantiles(n_features=2, n_classes=2, n_samples=300)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
model = SVC()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy_score(y_pred, y_test)
print(accuracy_score(y_pred, y_test))
0.9555555555555556
学习结果因核函数而异:核方法中可以使用的核函数多种多样。使用不同的核函数,得到的决策边界的形状也不同。常见的核函数如,线性核函数、Sigmoid 核函数、多项式核函数和 RBF 核函数。
**注意:**在使用支持向量机时,不宜立即使用非线性核函数,在此之前,应先使用线性核函数进行分析,以了解数据。
(1)核方法(kernel methods)
核方法是一类用于机器学习和统计学中的算法,它们依赖于一种称为核技巧(kernel trick)的技术,这种技术允许算法在原始输入空间(可能非常高维或无限维)中不容易处理的数据上进行操作,而是在一个通常更低维或更容易处理的特征空间(称为“核空间”)中处理数据。
核方法中最著名的例子是支持向量机(SVM),它是一种用于分类、回归和异常检测的强大工具。核技巧允许SVM有效地处理非线性问题,即使原始输入空间中的数据不是线性可分的。.
核函数是核方法中的核心概念。核函数是一个函数,它能够计算两个向量在隐式定义的核空间中的内积。这意味着,不需要显式地将数据映射到高维空间,核函数可以直接在高维空间中计算内积。这种能力使得核方法在处理非线性问题时非常高效。
常用的核函数包括:
- 线性核(Linear Kernel):适用于特征和标签是线性关系的情况。
- 多项式核(Polynomial Kernel):适用于特征之间具有多项式关系的情况。
- 径向基函数核(Radial Basis Function Kernel,也称为RBF核或高斯核):适用于无限维空间中的数据,能够捕捉到复杂的非线性关系。
- Sigmoid核:灵感来自于神经网络,适用于具有复杂结构的数据。
核方法的优势在于它们能够处理非线性问题,而不需要显式地定义映射到高维空间的函数。这使得核方法在许多领域,如图像识别、文本分类和生物信息学中非常有用。然而,选择合适的核函数和调整参数可能需要领域知识和实验经验。
6.朴素贝叶斯
朴素贝叶斯(Naive Bayes)是常用于自然语言分类问题的算法。它在垃圾邮件过滤上的应用非常有名。
朴素贝叶斯是一个基于概率进行预测的算法,在实践中被用于分类问题。具体来说,就是计算数据为某个标签的概率,并将其分类为概率值最大的标签。朴素贝叶斯主要用于文本分类和垃圾邮件判定等自然语言处理中的分类问题。
朴素贝叶斯基于文本中包含的单词推测未知数据的类别。
朴素贝叶斯不仅使用了单词在文本中出现的比例,还使用了每个单词的条件概率,通过文本中单词的信息提高了计算精度。
朴素贝叶斯使用训练数据来学习与各标签对应的单词的出现概率。在分类时求出每个标签对应的概率,将概率最高的标签作为分类结果。
from sklearn.naive_bayes import MultinomialNB
# 数据生成
X_train = [[1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0],
[0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 1]]
y_train = [1, 1, 1, 0, 0, 0]
model = MultinomialNB()
model.fit(X_train, y_train) # 训练
model.predict([[1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0]]) # 评估
print(model.predict([[1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0]]))
[1]
注意:
朴素贝叶斯是自然语言分类的基础算法,但是不适合预测天气预报中的降水概率那种预测值是概率本身的情况。
朴素贝叶斯基于“每个单词的概率可以独立计算”的假设,这是为了使概率的计算方法尽量简单。这个假设忽略了文本中单词之间的关联性。如果要计算的概率值很重要,则应该避免直接将由朴素贝叶斯算出的值用作概率。
7.随机森林
随机森林(random forest)是将多个模型综合起来创建更高性能模型的方法,既可用于回归,也可用于分类。
随机森林的目标是利用多个决策树模型,获得比单个决策树更高的预测精度。
随机森林分类算法的示意图。该算法从每个决策树收集输出,通过多数表决得到最终的分类结果。
随机森林的多数表决就像找别人商量事情一样,不只听一个人的意见,而是在听取许多人的意见之后综合判断。
随机森林尝试对每棵决策树的数据应用下述方法来进行训练,以使分类结果尽可能地不同。首先采用Bootstrap 方法,根据训练数据生成多个不同内容的训练数据。所谓 Bootstrap 方法,即通过对单个训练数据进行多次随机的抽样放回,“虚增”训练数据,这样就可以为每棵决策树输入不同的训练数据。
from sklearn.datasets import load_wine
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 数据生成
data = load_wine()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)
model = RandomForestClassifier()
model.fit(X_train, y_train) # 训练
y_pred = model.predict(X_test)
accuracy_score(y_pred, y_test) # 评估
print(accuracy_score(y_pred, y_test))
0.9814814814814815
(1)决策树
决策树概述:
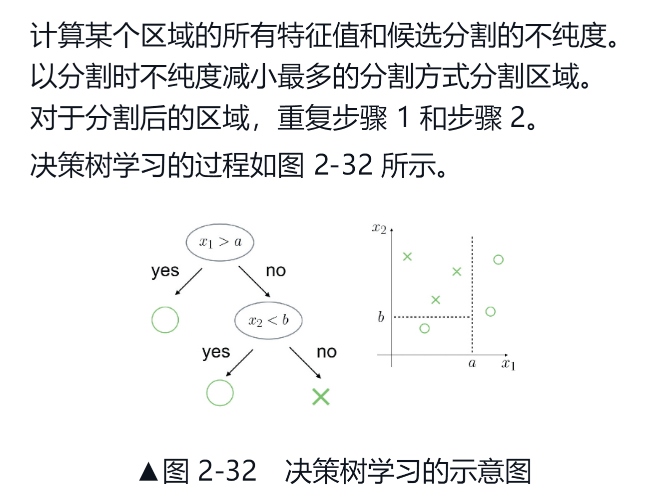
决策树是通过将训练数据按条件分支进行划分来解决分类问题的方法,在分割时利用了表示数据杂乱程度(或者不均衡程度)的不纯度的数值。
决策树是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。程序设计中的条件分支结构就是if-then-else结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。
如何进行更高效的决策?就要适当的调整特征的先后顺序。比如说银行对不同人的贷款数:
对这15个不同的人,我们对他们的特征选取不同的先后评判顺序对应得到是否银行贷款给他的所需判断时间也不同,比如我们先看年龄和先看是否有房子对应得到是否贷款的效率也是不一样的。假如现在有一个新的人要来银行贷款,我们如果先衡量他是否有房子和是否有工作或者是信贷情况的效率是不一样的。基本上所有的人,如果他有房子,那么银行都会贷款给他,而如果没有房子的话,还要继续衡量其是否有工作和年龄以及信贷情况来继续判断。所以对于决策树的第一步应该要找出最高效、最好的决策顺序。
决策树基于树结构,从顶往下,依次对样本的(一个或多个)属性进行判断,直到决策树的叶节点并导出最终结果。下图是我们如何去判断一个瓜是好瓜还是怀瓜的步骤,我们根据瓜的特征的先后顺序而对应得出一种最高效的选瓜方式:
西瓜决策树
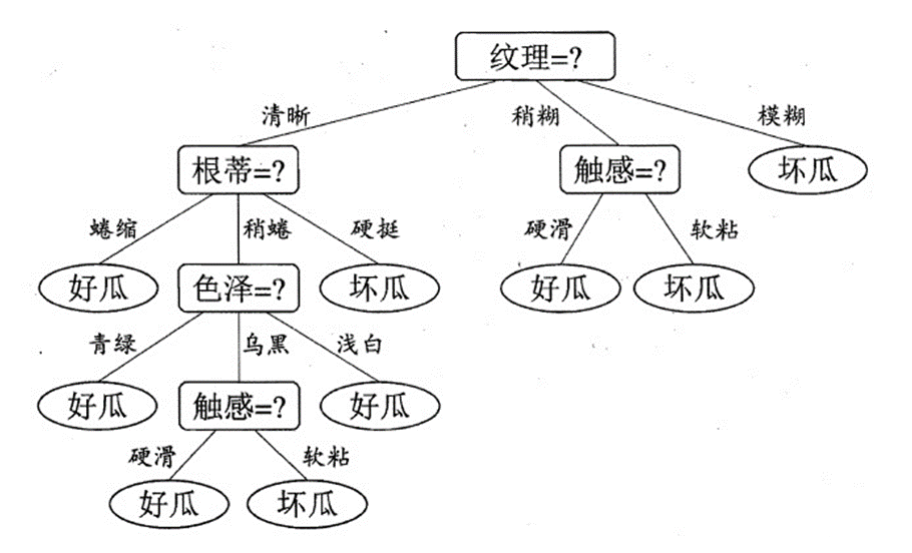
决策树的原理:
决策树是一种十分常用的分类方法,需要监督学习(有教师的Supervised Learning),监督学习就是给出一堆样本,每个样本都有一组属性和一个分类结果,也就是分类结果已知,那么通过学习这些样本得到一个决策树,这个决策树能够对新的数据给出正确的分类。
决策树的生成:
选择好特征后,就从根节点触发,对节点计算所有特征的信息增益,选择信息增益最大的特征作为节点特征,根据该特征的不同取值建立子节点;对每个子节点使用相同的方式生成新的子节点,直到信息增益很小或者没有特征可以选择为止。
决策树通过层次递进的属性判断,对样本进行划分。那么生成决策树的过程,就是确定树上的每一层(节点)应该选择什么属性来进行判断,即如何选择(每个节点的)最优划分属性?
基本思想:一般而言,我们遵循这样一个思想来选择属性。每一次划分,同类样本尽量走相同分支,不同类样本尽量走不同分支。即:随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度” (purity) 越来越高。
决策树剪枝:
剪枝的主要目的是对抗「过拟合」,通过主动去掉部分分支来降低过拟合的风险。
想象一下,如果树足够大,每一个数据就都可以分配到每个叶子节点上了(理论上可以完全分得开数据)。但是这样的决策树过拟合(在训练集上表现很好,但在测试集上表现很差)风险很大,泛化能力弱。
剪枝策略有预剪枝,后剪枝两种
①预剪枝:边建立决策树边进行剪枝的操作(很实用,易实现),限制深度(特征数),叶子节点个数,叶子节点样本数,信息增益量等抑制树结构的伸展。
②后剪枝:当建立完决策树后来进行剪枝操作,通过一定的衡量标准(叶子节点越多,损失C越大)。
优缺点:
优点:简单的理解和解释,树木可视化。
缺点:决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
改进:减枝cart算法(决策树API当中已经实现,随机森林参数调优有相关介绍)。随机森林
注:企业重要决策,由于决策树很好的分析能力,在决策过程应用较多, 可以选择特征
8.神经网络
神经网络在输入数据和输出结果之间插入了叫作中间层的层,能够学习复杂的决策边界。它既可以用于回归,也可以用于分类,但主要还是应用于分类问题。
中间层使用 Sigmoid 等非线性函数计算输入层传来的数据。中间层的维度是超参数。使维度变大可以学习更加复杂的边界,但是容易发生过拟合。
通过叠加简单感知机,神经网络得以表示复杂的决策边界。
神经网络通过这种设置中间层的方式,可以利用单一算法学习各种决策边界。通过调节中间层的数量及层的深度,神经网络可以学习更复杂的边界。
from sklearn.datasets import load_digits
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 数据生成
data = load_digits()
X = data.images.reshape(len(data.images), -1)
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
model = MLPClassifier(hidden_layer_sizes=(16, ))
model.fit(X_train, y_train) # 训练
y_pred = model.predict(X_test)
accuracy_score(y_pred, y_test) # 评估
print(accuracy_score(y_pred, y_test))
0.9462962962962963
(1)感知机
感知机(Perceptron)是由美国心理学家弗兰克·罗森布拉特(Frank Rosenblatt)在1957年提出的一种简单的线性二分类模型。它是神经网络和支持向量机等现代机器学习算法的早期形式。感知机模型模拟了人类神经元的工作方式,能够学习输入数据并将其分为两个类别。
感知机模型的基本结构包括一个或多个输入节点(输入特征),一个输出节点(预测结果),以及连接输入和输出的权重。每个输入节点都有一个相应的权重,代表着该特征对输出结果的影响程度。感知机通过计算输入特征的加权和,然后应用一个激活函数(通常是阶跃函数)来生成输出。
感知机的学习过程是通过训练数据集来调整权重,使得模型能够正确地分类样本。在每次迭代中,感知机会检查训练样本的预测结果是否正确。如果预测错误,它会根据错误的大小来调整相关特征的权重。这个过程会一直重复,直到模型在训练数据集上的错误率足够低或者达到预设的迭代次数。
尽管感知机在理论上能够学习线性可分的数据集,但它无法处理非线性问题。此外,感知机对于初始权重值非常敏感,可能会因为不同的初始化而导致不同的结果。尽管如此,感知机的历史意义在于它为后来的学习算法奠定了基础,特别是在神经网络和机器学习领域。
(2)激活函数
激活函数是神经网络中的一个关键概念,它被用于引入非线性因素,使得神经网络能够学习和模拟更复杂的数据关系和模式。激活函数作用于神经元的输出,决定了神经元是否应该被激活,即是否应该向下一层网络传递信息。
在神经网络中,每个神经元接收来自前一层神经元的输入信号,计算这些信号的加权和,然后通过激活函数来决定输出。激活函数的选择对神经网络的性能和能够学习的数据类型有重要影响。
常见的激活函数包括:
- 阶跃函数(Step Function):是最简单的激活函数,如果输入大于某个阈值,输出为1,否则为0。但它对于梯度下降算法来说是不连续的,因此在训练深度网络时不太实用。
- Sigmoid函数:也称为逻辑函数,其输出范围在0到1之间,适合用于二分类问题。Sigmoid函数具有平滑的输出,但是容易导致梯度消失问题,特别是在输入值远离0的时候。
- 双曲正切函数(Tanh):类似于Sigmoid函数,但是其输出范围在-1到1之间,解决了Sigmoid函数的输出不以0为中心的问题。Tanh函数在深度学习中的应用不如ReLU广泛。
- 线性整流函数(ReLU,Rectified Linear Unit):是目前最流行的激活函数之一,它的公式为 ( f(x) = max(0, x) )。ReLU函数简单、计算效率高,并且在大多数情况下都能提供良好的性能。但是它可能会遇到“死神经元”问题,即某些神经元可能永远不会激活。
- Softmax函数:通常用于神经网络的输出层,用于多分类问题。它将输入转换为概率分布,确保所有输出的和为1。
- leaky ReLU、parametric ReLU(PReLU)和exponential linear unit(ELU)等:这些是ReLU的变体,旨在解决“死神经元”问题,通过允许函数在负值域内有一定的非零输出。
选择合适的激活函数取决于具体的应用场景和问题类型。例如,对于分类问题,Sigmoid和Softmax函数可能是合适的选择,而对于大多数深度神经网络,ReLU及其变体通常是首选。激活函数的正确选择可以显著提高神经网络的性能和训练效率。
(3)早停法
Early Stopping 是指在进入过拟合状态前停止训练的防止过拟合的方法。
Early Stopping 进一步划分训练数据,将其中一部分作为训练中的评估数据。在训练过程中使用评估数据,依次记录损失等评估指标,以了解训练的进度。在训练过程中,如果评估数据的损失开始恶化,开始出现过拟合的趋势,就停止训练,结束学习。这种在过拟合之前停止训练的做法就叫作Early Stopping。
早停法(Early Stopping)是一种在训练机器学习模型时常用的 regularization 技术,用于防止过拟合。过拟合是指模型在训练数据上表现良好,但在未见过的数据上表现不佳,因为它学到了训练数据中的噪声和细节,而没有捕捉到数据的真实分布。
早停法的基本思想是在模型训练过程中监控模型在验证集上的性能。验证集是从原始训练集中分离出来的一部分数据,不用于模型的训练,但用于评估模型的性能。当模型在验证集上的性能开始下降时,即认为模型已经过拟合,训练过程随即停止。
具体操作步骤如下:
- 将原始训练数据集分为训练集和验证集。
- 在每次迭代或批次后,评估模型在训练集和验证集上的性能。
- 当模型在验证集上的性能开始下降时,停止训练,并回退到之前验证集性能最好的模型状态。
早停法不需要修改模型的结构或损失函数,也不需要调整学习率等超参数,是一种简单有效的正则化方法。它可以帮助找到模型复杂度和泛化能力之间的平衡点,从而提高模型在实际应用中的表现。
9.KNN(K-Nearest Neighbor,K 近邻)
KNN(K-Nearest Neighbor,K 近邻)算法是一种与众不同的机器学习算法,它只是机械地记住所有的数据。
KNN 既可用于分类,也可用于回归。
KNN 是一种在训练时机械地记住所有数据的简单算法。该算法使用训练数据对未知输入数据进行分类时的步骤如下。
- 计算输入数据与训练数据之间的距离。
- 得到距离输入数据最近的K个训练数据。
- 对训练数据的标签进行多数表决,将结果作为分类结果。
最近邻点K的数量是一个超参数。在二元分类时,通常取K为奇数,这样多数表决才能决定结果是其中的哪一个。
下面查看示例代码。我们使用呈曲线分布的样本数据进行学习,从而解决分类问题。最近邻点 [插图] 的数量采用默认值 5。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 数据生成
X, y = make_moons(noise=0.3)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
model = KNeighborsClassifier()
model.fit(X_train, y_train) # 训练
y_pred = model.predict(X_test)
accuracy_score(y_pred, y_test) # 评估
print(accuracy_score(y_pred, y_test))
0.8666666666666667
决策边界因K值而异,K为超参数。
注意:
当数据量较小或维度较小时,KNN 的效果很好,但是当数据量较大或维度较大时,我们就需要考虑其他方法。
为了高效地进行近邻搜索,人们经常借助于利用树结构存储训练数据的技术,但一般来说,KNN 不适合处理大规模的训练数据。
KNN 也无法很好地学习高维数据。KNN 起作用的前提是“只要拥有的训练数据多,就能在未知数据的附近发现训练数据”这一假设。这个假设叫作渐近假设,但对于高维数据来说,这个假设不一定成立。对于高维的音频和图像数据,我们需要考虑其他方法。
三、无监督学习
1.PCA(Principal Component Analysis,主成分分析)
PCA 可以将相关的多变量数据以主成分简洁地表现出来。PCA 是一种用于减少数据中的变量的算法。它对变量之间存在相关性的数据很有效,是一种具有代表性的降维算法。
减少数据变量的方法有两种:
- 一种是只选择重要的变量,不使用其余变量;
- 另一种是基于原来的变量构造新的变量。PCA 使用的是后一种方法。
PCA 可发现对象数据的方向和重要度。对于数据的散点图,可以画出正交的两条线,线的方向表示数据的方向,长度表示重要度。方向由构成新变量时对象数据变量的权重决定,而重要度与变量的偏差有关。
PCA 采用以下步骤来寻找主成分:
- 计算协方差矩阵。
- 对协方差矩阵求解特征值问题,求出特征向量和特征值。
- 以数据表示各主成分方向。
示例代码,下面是对 scikit-learn 内置的鸢尾花数据使用 PCA 的示例代码,用于将 4 个特征变量变换为 2 个主成分。
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
data = load_iris()
n_components = 2 # 将减少后的维度设置为2
model = PCA(n_components=n_components)
model = model.fit(data.data)
print(model.transform(data.data)) # 变换后的数据
[[-2.68420713 0.32660731]
[-2.71539062 -0.16955685]
[-2.88981954 -0.13734561]
~ 略~
[ 1.76404594 0.07851919]
[ 1.90162908 0.11587675]
[ 1.38966613 -0.28288671]]
主成分的选择方法:PCA 可以将原始数据中的变量表示为新的轴的主成分。这些主成分按照贡献率大小排序,分别为第一主成分、第二主成分……照此类推。这时通过计算累计贡献率,我们可以知道使用到第几个主成分为止可以包含原始数据多少比例的信息。
2.LSA(Latent Semantic Analysis,潜在语义分析)
LSA(Latent Semantic Analysis,潜在语义分析)是一种自然语言处理技术。作为一种降维算法,它常被用于信息搜索领域。
使用 LSA 能够从大量的文本数据中找出单词之间的潜在关联性。可以根据大量文本自动计算单词和单词的相似度,以及单词和文本的相似度。
矩阵分解是指将某个矩阵表示为多个矩阵的乘积的形式。
示例代码下面使用 Python 代码解决前面探讨的问题。假设有一个使用 8 个变量(= 单词的个数)表示的数据集,现在用 2 个潜在变量来表示它。
from sklearn.decomposition import TruncatedSVD
data = [[1, 0, 0, 0],
[1, 0, 0, 0],
[1, 1, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 1],
[0, 0, 1, 0],
[0, 0, 1, 1],
[0, 0, 0, 1]]
n_components = 2 # 潜在变量的个数
model = TruncatedSVD(n_components=n_components)
model.fit(data)
print(model.transform(data)) # 变换后的数据
print(model.explained_variance_ratio_) # 贡献率
print(sum(model.explained_variance_ratio_)) # 累计贡献率
[[ 0.00000000e+00 8.50650808e-01]
[ 0.00000000e+00 8.50650808e-01]
[ 1.08779196e-15 1.37638192e+00]
[ 1.08779196e-15 5.25731112e-01]
[ 1.41421356e+00 -8.08769049e-16]
[ 7.07106781e-01 -4.04384525e-16]
[ 1.41421356e+00 -8.08769049e-16]
[ 7.07106781e-01 -4.04384525e-16]]
[0.38596491 0.27999429]
0.6659592065833292
注意:
使用了奇异值分解的 LSA 在信息检索中的应用备受关注,它具有以新的空间表示文本等优点。但在实际使用中,需要注意一些问题。
一是变换后的矩阵有时难以解释。在通过奇异值分解降维时,各个维度可能是正交的,矩阵中的元素也可能是负值。因此,与之相比,还是后面即将介绍的 NMF 和 LDA 等算法的结果更容易解释。
二是 LSA 的计算成本有时很高。特别是在用于文本时,由于原始矩阵的维度就是单词的个数,所以LSA 必须在非常大的矩阵上进行奇异值分解。
还有一个与计算成本有关的问题:随着新词的加入,原有的矩阵必须重新创建,我们必须在此基础上重新计算,所以模型的更新难度很大。
(1)潜在语义空间
潜在语义空间(Latent Semantic Space)是指由潜在语义分析(Latent Semantic Analysis,LSA)或潜在语义索引(Latent Semantic Indexing,LSI)构建的一个多维空间,其中包含了文本数据中的潜在主题或概念。在这个空间中,文档和单词被表示为向量,使得语义上相似的文档和单词在空间中的距离较近。
潜在语义分析是一种自然语言处理技术,它通过奇异值分解(Singular Value Decomposition,SVD)来识别文本数据中的潜在模式。LSA的基本思想是,文本中的单词和文档可以被映射到一个低维空间,这个空间捕捉到了文档和单词之间的语义关系,而不仅仅是表面的词汇匹配。
在潜在语义空间中:
- 文档向量表示了文档与不同潜在主题的相关性。
- 单词向量表示了单词与不同潜在主题的关联度。
通过这种方式,LSA能够发现单词和文档之间的深层次联系,即使它们没有直接的词汇重叠。例如,单词“汽车”和“车辆”在潜在语义空间中可能会非常接近,因为它们都与“交通”这一潜在主题相关。
潜在语义分析在信息检索、文本分类、主题建模等领域有着广泛的应用。它帮助计算机更好地理解文本的语义内容,从而提高处理自然语言数据的效率和质量。
(2)奇异值分解
奇异值分解(Singular Value Decomposition,简称SVD)是一种重要的矩阵分解方法,它将一个任意矩阵分解为三个矩阵的乘积。在奇异值分解中,一个m×n的矩阵M可以被分解为三个矩阵的乘积,即:
M
=
U
Σ
V
T
M = U \Sigma V^T
M=UΣVT
其中:
U
是一个
m
×
m
的单位正交矩阵,它的列向量称为左奇异向量。
Σ
是一个
m
×
n
的对角矩阵,对角线上的非负数称为奇异值,按从大到小的顺序排列,其余位置上的元素都是
0
。奇异值的数量
r
等于
M
的秩。
V
T
是一个
n
×
n
的单位正交矩阵的转置,它的行向量称为右奇异向量。
U 是一个m×m的单位正交矩阵,它的列向量称为左奇异向量。 \Sigma 是一个m×n的对角矩阵,对角线上的非负数称为奇异值,按从大到小的顺序排列,其余位置上的元素都是0。奇异值的数量r等于M的秩。 V^T 是一个n×n的单位正交矩阵的转置,它的行向量称为右奇异向量。
U是一个m×m的单位正交矩阵,它的列向量称为左奇异向量。Σ是一个m×n的对角矩阵,对角线上的非负数称为奇异值,按从大到小的顺序排列,其余位置上的元素都是0。奇异值的数量r等于M的秩。VT是一个n×n的单位正交矩阵的转置,它的行向量称为右奇异向量。
奇异值分解在信号处理、统计学习、图像处理、推荐系统、自然语言处理等领域有着广泛的应用。例如,在潜在语义分析(Latent Semantic Analysis,LSA)中,SVD被用来发现文本数据中的潜在主题。在图像压缩中,SVD可以用来降低数据的维数,去除噪声,同时保留最重要的特征。在推荐系统中,SVD可以用来预测用户对商品的评分,从而提供个性化的推荐。
奇异值分解是线性代数中的一个基本工具,它不仅有助于理解矩阵的结构,而且在解决实际问题时也发挥着重要作用。
3.NMF(Non-negative Matrix Factorization,非负矩阵分解)
负矩阵分解)是一种降维算法,它的特点是输入数据和输出数据的值都是非负的。这个特点在处理图像等数据时有一个优点,那就是模型的可解释性强。
NMF 只适用于原始矩阵的所有元素都是非负数(即大于等于 0)的情况。NMF 具有以下特点:
- 原始矩阵的元素是非负数。
- 分解后矩阵的元素是非负数。
- 没有“潜在语义空间的每一个维度都是正交的”这一约束条件。
NMF 没有“潜在变量必须正交”的约束条件,所以各个潜在变量可能有一定程度的信息重复。
示例代码,下面是使用 scikit-learn 运行 NMF 算法的示例代码。
from sklearn.datasets import make_blobs
from sklearn.decomposition import NMF
centers = [[5, 10, 5], [10, 4, 10], [6, 8, 8]]
X, _ = make_blobs(centers=centers) # 以centers为中心生成数据
n_components = 2 # 潜在变量的个数
model = NMF(n_components=n_components)
model.fit(X)
W = model.transform(X) # 分解后的矩阵
H = model.components_
print(W)
print()
print(H)
[[0.8862986 0.24573036]
[0.90932215 0.1596284 ]
[0.14034544 1.100911 ]
[0.5907961 0.51957175]
...
[0.65389481 0.25371246]
[0.57707002 0.55395538]
[0.28578785 0.97380832]]
[[ 3.78434745 11.76179467 4.56644899]
[ 8.21590437 2.29424836 8.32539455]]
NMF 和 PCA 的比较
NMF(非负矩阵分解,Non-negative Matrix Factorization)和PCA(主成分分析,Principal Component Analysis)都是数据降维技术,但它们在方法和应用上有一些关键的区别。
- 数据表示:
- PCA:是一种线性变换技术,它寻找能够最大化数据方差的新坐标系。PCA不限制坐标必须是正的,因此可能产生负的成分。
- NMF:是一种矩阵分解技术,它将数据矩阵分解为两个非负矩阵的乘积。这意味着NMF的成分始终是非负的,这使其在表示具有自然非负性的数据(如图像、文本数据)时更加有用。
- 数学原理:
- PCA:使用协方差矩阵和特征分解来找到数据的主要方差方向。
- NMF:通常通过迭代优化方法来寻找非负的矩阵因子,使得原始矩阵与重构矩阵之间的差异最小。
- 应用领域:
- PCA:广泛应用于数据压缩、去噪、特征提取等领域。由于PCA不限制成分的非负性,它可以用于各种类型的数据。
- NMF:特别适用于具有非负特性的数据,如音频信号、图像、文本数据。在文本挖掘中,NMF常用于发现文档的主题分布。
- 成分解释性:
- PCA:主成分可能不具有直观的解释性,尤其是在它们是原始特征的线性组合时。
- NMF:由于成分是非负的,它们可以被解释为数据中的原始特征的“组合”,这在某些应用中提供了更好的可解释性。
- 算法复杂性:
- PCA:通常计算效率较高,特别是当使用谱分解方法时。
- NMF:可能需要更复杂的迭代优化过程,因此计算成本可能更高。
- 稳定性:
- PCA:对于数据的微小变化可能非常敏感,尤其是在主成分的数量接近数据的维度时。
- NMF:通常对于数据的微小变化更加稳定,因为它鼓励稀疏性。
总的来说,PCA和NMF是互补的技术,选择哪种方法取决于数据的特性和降维的目的。如果数据是非负的,或者需要具有可解释性的成分,NMF可能是更好的选择。如果数据的自然特性不要求非负性,并且主要目标是数据压缩或去噪,PCA可能更加适用。
PCA 通过将不同的脸(负的脸和正的脸。听上去是不是有些奇怪?)加在一起来恢复原始图像。NMF 则通过组合具有人脸部分特征的图像来恢复原始图像。NMF 的潜在变量的含义(在本例中就是人脸的部分特征)的可解释性更强。
4.LDA(Latent Dirichlet Allocation,隐含狄利克雷分布)
LDA(Latent Dirichlet Allocation,隐含狄利克雷分布)是一种降维算法,适用于文本建模。
LDA 是一种用于自然语言处理等的算法。该算法可以根据文本中的单词找出潜在的主题,并描述每个文本是由什么主题组成的,还可以用于说明一个文本不只有一个主题,而是有多个主题。
LDA 通过以下步骤计算主题分布和单词分布。
- 为各文本的单词随机分配主题。
- 基于为单词分配的主题,计算每个文本的主题概率。
- 基于为单词分配的主题,计算每个主题的单词概率。
- 计算步骤 2 和步骤 3 中的概率的乘积,基于得到的概率,再次为各文本的单词分配主题。
- 重复步骤 2 ~步骤 4 的计算,直到收敛。
示例代码,下面使用 scikit-learn 实现基于 LDA 的主题模型的创建。我们使用一个名为 20 Newsgroups 的数据集,这个数据集是 20 个主题的新闻组文本的集合,每个文本属于一个主题。
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
# 使用remove去除正文以外的信息
data = fetch_20newsgroups(remove=('headers', 'footers', 'quotes'))
max_features = 1000
# 将文本数据变换为向量
tf_vectorizer = CountVectorizer(max_features=max_features,stop_words='english')
tf = tf_vectorizer.fit_transform(data.data)
n_topics = 20
model = LatentDirichletAllocation(n_components=n_topics)
model.fit(tf)
print(model.components_) # 各主题包含的单词的分布
print(model.transform(tf)) # 使用主题描述的文本
[[5.00000000e-02 5.00000002e-02 5.00000001e-02 ... 1.07134735e+02
5.63861118e-02 2.41486558e+01]
[1.17770474e+03 1.61900928e+02 2.02346570e+02 ... 5.00000007e-02
1.21663522e+01 2.53286918e+01]
[5.00000007e-02 1.25761294e-01 5.00000002e-02 ... 2.25598513e+01
5.00000001e-02 5.00000010e-02]
...
[3.19399526e+00 2.67423391e+01 5.00000001e-02 ... 7.70173054e+01
9.54810188e+00 7.03503433e+01]
[5.00000005e-02 5.00000005e-02 2.75285738e+00 ... 6.34930885e+01
5.00000038e-02 1.60675445e+00]
[5.00000002e-02 5.00000006e-02 5.00000003e-02 ... 1.94769491e+02
5.00000005e-02 5.00000013e-02]]
[[0.00208333 0.00208333 0.00208333 ... 0.00208333 0.00208333 0.00208333]
[0.0025 0.0025 0.0025 ... 0.0025 0.0025 0.0025 ]
[0.00060241 0.00060241 0.00060241 ... 0.00060241 0.01601128 0.27171065]
...
[0.00454545 0.00454545 0.00454545 ... 0.00454545 0.00454545 0.31902404]
[0.35426268 0.00294118 0.00294118 ... 0.00294118 0.00294118 0.44543479]
[0.00357143 0.20147944 0.31800886 ... 0.00357143 0.00357143 0.00357143]]
如果只用单词来描述文本的特征,就很难直观地理解,但通过 LDA,我们就能够用主题来描述文本的特征。
5.k-means 算法
k-means 算法是一种有代表性的聚类算法。由于该算法简单易懂,又可以用于比较大的数据集,所以在市场分析和计算机视觉等领域得到了广泛的应用。
通过计算数据点与各重心的距离,找出离得最近的簇的重心,可以确定数据点所属的簇。求簇的重心是k-means算法中重要的计算。
k-means 算法的典型计算步骤如下:
- 从数据点中随机选择数量与簇的数量相同的数据点,作为这些簇的重心。
- 计算数据点与各重心之间的距离,并将最近的重心所在的簇作为该数据点所属的簇。
- 计算每个簇的数据点的平均值,并将其作为新的重心。
- 重复步骤 2 和步骤 3,继续计算,直到所有数据点不改变所属的簇,或者达到最大计算步数。
有时选择的重心不好可能会导致步骤 2 和步骤 3 的训练无法顺利进行。比如在随机选择的重心之间太近等的情况下,就会出现这种问题。利用k-means++等方法,选择位置尽可能远离的数据点作为重心的初始值,就可以解决这个问题。
示例代码,下面是对鸢尾花数据集应用 [插图] 算法的代码,簇的数量设置为 3。
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
data = load_iris()
n_clusters = 3 # 将簇的数量设置为3
model = KMeans(n_clusters=n_clusters)
model.fit(data.data)
print(model.labels_) # 各数据点所属的簇
print(model.cluster_centers_) # 通过fit()计算得到的重心
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 2 2 2 2 0 2 2 2 2
2 2 0 0 2 2 2 2 0 2 0 2 0 2 2 0 0 2 2 2 2 2 0 2 2 2 2 0 2 2 2 0 2 2 2 0 2
2 0]
[[5.9016129 2.7483871 4.39354839 1.43387097]
[5.006 3.428 1.462 0.246 ]
[6.85 3.07368421 5.74210526 2.07105263]]
可以使用 Elbow 方法确定簇的数量。
聚类结果的好坏可以通过计算簇内平方和(Within-Cluster Sum of Squares,WCSS)来定量评估(这个 WCSS 随着簇的数量的增加而变小,所以可以用于相同数量的簇的情况下的比较)。
WCSS 指的是对所有簇计算其所属的数据点与簇的重心之间距离的平方和,并将它们相加得到的值。这个值越小,说明聚类结果越好。
(1)Elbow 方法(肘方法)
Elbow方法,也称为“肘部法则”,是一种用于确定机器学习模型中最佳特征数量或聚类数目的直观方法。它通过绘制模型性能指标(如误差或成本函数值)与特征数量或聚类数目的关系图来工作。当增加特征数量或聚类数目时,模型的性能通常先快速提升,然后逐渐饱和,形成一条类似于人类肘部的曲线。Elbow方法就是找到这条曲线的“肘部”点,即性能提升幅度突然变缓的点,作为最佳的特征数量或聚类数目。
Elbow方法的步骤通常如下:
- 训练模型:对于不同的特征数量或聚类数目,训练多个模型。
- 评估性能:对于每个模型,评估其在验证集或训练集上的性能。
- 绘制图表:将模型性能指标(如均方误差、轮廓系数等)绘制成图表,横轴为特征数量或聚类数目,纵轴为性能指标。
- 寻找“肘部”:在图表上找到曲线开始变平缓的点,这个点通常就是最佳的特征数量或聚类数目。
Elbow方法简单直观,但有时可能需要结合领域知识和进一步的分析来确定最佳参数。此外,Elbow方法并不是总是有效,有时曲线可能没有清晰的“肘部”,或者“肘部”可能出现在数据集特定的问题中。因此,在使用Elbow方法时,需要谨慎并考虑其他可能的评估指标和方法。
(2)k-means++
k-means++ 是一种用于初始化 k-means 聚类算法的种子点选择方法。在标准的 k-means 算法中,初始中心点的选择通常是基于随机选择的,这可能导致算法收敛到局部最优解,而不是全局最优解。k-means++ 提供了一种更智能的方法来选择初始中心点,以增加找到更好解的概率。
k-means++ 算法的步骤如下:
- 随机选择第一个中心点:从数据集中随机选择一个样本点作为第一个聚类中心。
- 计算距离:对于数据集中的每个未选择的样本点,计算它与最近中心点的距离的平方。
- 选择下一个中心点:根据每个样本点与最近中心点的距离的平方,以概率权重随机选择下一个中心点。距离越远的样本点被选为下一个中心点的概率越高。
- 重复步骤 2 和 3:重复步骤 2 和 3,直到选择了 k 个中心点。
- 执行 k-means 聚类:使用这 k 个初始中心点执行标准的 k-means 算法。
k-means++ 算法的关键思想是通过选择初始中心点来改善聚类质量。通过选择距离已选中心点较远的点作为新的中心点,k-means++ 旨在获得初始中心点的良好分布,从而减少陷入局部最优解的风险,并可能更快地收敛到更好的聚类结果。
在实际应用中,k-means++ 算法通常比标准的 k-means 算法表现得更好,特别是在聚类质量方面。然而,k-means++ 仍然受到 k-means 算法的一些限制,例如对球状聚类假设的敏感性,以及需要预先指定聚类数 k。尽管如此,k-means++ 是一种流行且有效的聚类初始化方法。
6.混合高斯分布
数据集中有多组数据,可以使用混合高斯分布(即多个高斯分布的线性组合)来实现聚类。
数据的分布可以用均值和方差表示,均值描述数据的中心位置,方差描述数据的离散程度。
混合高斯分布是以多个高斯分布的线性叠加来表示数据的模型。
混合高斯分布的学习过程是从给定的数据点中找到每个高斯分布的均值和方差的过程。
示例代码,下面是对包含 3 个品种的鸢尾花数据应用混合高斯分布的示例代码。
from sklearn.datasets import load_iris
from sklearn.mixture import GaussianMixture
data = load_iris()
n_components = 3 # 高斯分布的数量
model = GaussianMixture(n_components=n_components)
model.fit(data.data)
print(model.predict(data.data)) # 预测类别
print(model.means_) # 各高斯分布的均值
print(model.covariances_) # 各高斯分布的方差
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 2 0 2 0
0 0 0 2 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
[[5.91697517 2.77803998 4.20523542 1.29841561]
[5.006 3.428 1.462 0.246 ]
[6.54632887 2.94943079 5.4834877 1.98716063]]
[[[0.27550587 0.09663458 0.18542939 0.05476915]
[0.09663458 0.09255531 0.09103836 0.04299877]
[0.18542939 0.09103836 0.20227635 0.0616792 ]
[0.05476915 0.04299877 0.0616792 0.03232217]]
[[0.121765 0.097232 0.016028 0.010124 ]
[0.097232 0.140817 0.011464 0.009112 ]
[0.016028 0.011464 0.029557 0.005948 ]
[0.010124 0.009112 0.005948 0.010885 ]]
[[0.38741443 0.09223101 0.30244612 0.06089936]
[0.09223101 0.11040631 0.08386768 0.0557538 ]
[0.30244612 0.08386768 0.32595958 0.07283247]
[0.06089936 0.0557538 0.07283247 0.08488025]]]
7.LLE(Locally Linear Embedding,局部线性嵌入)
LLE(Locally Linear Embedding,局部线性嵌入)可以将以弯曲或扭曲的状态埋藏在高维空间中的结构简单地表示在低维空间中。
LLE 是一种被称为流形学习(manifold learning)的算法,它的目标是对具有非线性结构的数据进行降维。
LLE 可以把埋藏在三维空间中的二维结构取出,将其以二维数据表示。PCA 则采取像是将原始数据压扁的方式进行降维。
PCA 适用于变量之间存在相关性的数据,所以在对瑞士卷数据集这种非线性数据降维时,更适合采用 LLE 这样的方法。
LLE 算法要求数据点由其近邻点的线性组合来表示。
LLE 的近邻点数量需要被定义为超参数。
8.t-SNE(t-Distributed Stochastic Neighbor Embedding,t分布随机邻域嵌入)
t-SNE的特点是在降维时使用了自由度为 1 的t分布。通过t-SNE分布,可以使在高维空间中原本很近的结构在低维空间中变得更近,原本较远的结构变得更远。
t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种非线性降维技术,通常用于高维数据的可视化。它由Laurens van der Maaten和Geoffrey Hinton于2008年提出。t-SNE的主要目的是将高维空间中的数据点映射到低维空间(通常是2维或3维),同时保持原始数据中相似度较高的点在低维空间中仍然相似。
t-SNE算法主要分为两个步骤:
- 高维空间中的相似度计算:在高维空间中,t-SNE使用高斯分布来表示一个数据点与其他数据点的相似度。对于每个数据点,其高斯分布的方差是根据其邻域的大小决定的,这可以确保即使在不同的密度区域中,相似度的计算也是比较鲁棒的。
- 低维空间中的相似度计算:在低维空间中,t-SNE使用“学生t分布”来表示一个数据点与其他数据点的相似度。t分布的尾部比高斯分布更重,这有助于确保即使在低维空间中,远离的点也能被有效地推开。
t-SNE的目标是最小化高维空间和低维空间中相似度分布之间的Kullback-Leibler散度(KL散度)。通过梯度下降法优化这个目标函数,最终得到低维空间中的数据点坐标。
t-SNE在可视化高维数据方面非常有效,特别是在数据具有复杂结构和非线性特征时。然而,它也有一些局限性,例如计算成本高、在某些情况下可能无法保持全局结构等。因此,在使用t-SNE之前,了解其优缺点是非常重要的。
示例代码,下面是将t-SNE应用于手写数字数据集的代码,其中设置的降维后的维度是 2。
from sklearn.manifold import TSNE
from sklearn.datasets import load_digits
data = load_digits()
n_components = 2 # 设置降维后的维度为2
model = TSNE(n_components=n_components)
print(model.fit_transform(data.data))
[[ -2.8171818 52.976727 ]
[ 10.301826 -11.549088 ]
[-13.671792 -18.572178 ]
...
[ -5.4764643 -10.788267 ]
[-20.971333 15.351182 ]
[-14.2034445 -6.8989296]]
四、评估方法和各种数据的处理
1.分类问题
(1)混淆矩阵
混淆矩阵(Confusion Matrix),也称为错误矩阵,是一种特别适用于监督学习的评估分类模型性能的工具,特别是二分类问题。它是一种特定的表格布局,允许直观地查看模型的分类结果,包括真正(True Positives)、假正(False Positives)、真负(True Negatives)和假负(False Negatives)。
以下是混淆矩阵的基本结构:
预测结果
正类 负类
实际结果
正类 真正(TP) 假负(FN)
负类 假正(FP) 真负(TN)
- 真正(True Positive, TP):模型正确预测到的正类样本。
- 假负(False Negative, FN):实际上是正类,但模型预测为负类的样本。
- 假正(False Positive, FP):实际上是负类,但模型预测为正类的样本。
- 真负(True Negative, TN):模型正确预测到的负类样本。
基于混淆矩阵,可以计算出多种性能指标,包括:
- 准确率(Accuracy):正确预测的样本数占总样本数的比例。
- 精确率(Precision):在所有预测为正类的样本中,真正为正类的比例。
- 召回率(Recall):在所有实际为正类的样本中,被正确预测为正类的比例。
- F1分数(F1 Score):精确率和召回率的调和平均值,用于衡量模型的精确性和鲁棒性。
- 特异度(Specificity):在所有实际为负类的样本中,被正确预测为负类的比例。
混淆矩阵为评估分类模型的性能提供了一个全面的视角,特别是在不同类别样本不均衡的情况下,单纯依赖准确率可能会产生误导,而混淆矩阵则可以提供更细致的性能分析。
(2)正确率
正确率(Accuracy)是机器学习中评估分类模型性能的一个基本指标,它表示模型正确预测的样本数与总样本数之间的比例。正确率的计算公式如下:
正确率
=
正确预测的样本数
总样本数
\text{正确率} = \frac{\text{正确预测的样本数}}{\text{总样本数}}
正确率=总样本数正确预测的样本数
正确率的取值范围是0到1,或者以百分比的形式表示,其中1或100%表示模型在所有样本上的预测都是正确的。
虽然正确率是一个直观且易于理解的指标,但它也有一些局限性:
- 类别不平衡:在处理类别不平衡的数据集时,正确率可能会给出误导性的结果。例如,如果一个数据集中90%的样本属于一个类别,一个总是预测这个类别的模型也会有90%的正确率,即使它没有学习到任何有用的模式。
- 不提供细节:正确率提供了一个全局的视角,但它不告诉我们在各个类别上的表现如何。有时候,我们可能更关心模型在某个特定类别上的表现,例如在疾病筛查中,我们可能更关心真阳性(真正例)和假阴性(漏诊)。
为了克服这些局限性,通常会使用其他指标,如精确率、召回率、F1分数以及ROC曲线和AUC值等,来更全面地评估模型的性能。
(3)精确率
精确率(Precision),也称为正预测值(Positive Predictive Value,PPV),是机器学习中评估分类模型性能的一个指标,特别是在二分类问题中。精确率衡量的是在所有模型预测为正类的样本中,实际上确实是正类的比例。
精确率的计算公式如下:
精确率
=
真正类(TP)
真正类(TP)
+
假正类(FP)
\text{精确率} = \frac{\text{真正类(TP)}}{\text{真正类(TP)} + \text{假正类(FP)}}
精确率=真正类(TP)+假正类(FP)真正类(TP)
其中:
- 真正类(True Positive, TP):模型正确预测为正类的样本数量。
- 假正类(False Positive, FP):模型错误预测为正类的样本数量,即实际为负类但被预测为正类的样本数量。
精确率的取值范围是0到1,或者以百分比的形式表示,其中1或100%表示模型在预测正类时完全没有错误。
精确率在关注减少假正类错误(即避免误报)的应用场景中非常重要。例如,在医疗诊断中,我们希望尽量减少错误地告诉健康人他们有病的风险;在电子邮件过滤中,我们希望尽量减少将非垃圾邮件错误地分类为垃圾邮件的情况。
然而,精确率并不考虑模型预测为负类的样本,因此在类别不平衡的情况下,高精确率可能伴随着较低的召回率(Recall),即模型可能会错过许多真正的正类样本。因此,精确率通常与召回率一起考虑,以平衡模型的预测性能。F1分数是精确率和召回率的调和平均值,提供了一个同时考虑精确率和召回率的综合指标。
(4)召回率
召回率(Recall),也称为真正类率(True Positive Rate,TPR)或灵敏度(Sensitivity),是机器学习中评估分类模型性能的另一个重要指标,特别是在二分类问题中。召回率衡量的是在所有实际为正类的样本中,模型正确预测为正类的比例。
召回率的计算公式如下:
召回率
=
真正类(TP)
真正类(TP)
+
假负类(FN)
\text{召回率} = \frac{\text{真正类(TP)}}{\text{真正类(TP)} + \text{假负类(FN)}}
召回率=真正类(TP)+假负类(FN)真正类(TP)
其中:
- 真正类(True Positive, TP):模型正确预测为正类的样本数量。
- 假负类(False Negative, FN):模型错误预测为负类的样本数量,即实际为正类但被预测为负类的样本数量。
召回率的取值范围也是0到1,或者以百分比的形式表示,其中1或100%表示模型能够识别出所有的正类样本。
召回率在关注减少假负类错误(即避免漏报)的应用场景中非常重要。例如,在疾病筛查中,我们希望尽量减少错误地告诉患者他们没有病的风险;在欺诈检测中,我们希望尽量减少将欺诈行为错误地分类为正常行为的情况。
与精确率一样,召回率也不考虑模型预测为负类的样本。在类别不平衡的情况下,高召回率可能伴随着较低的精确率,即模型可能会包含许多错误的正类预测。因此,召回率通常与精确率一起考虑,以平衡模型的预测性能。F1分数是精确率和召回率的调和平均值,提供了一个同时考虑精确柔和召回率的综合指标。
(5)F值
F值是综合反映精确率和召回率两个趋势的指标。
F值,通常指的是F1分数(F1 Score),是机器学习中用于评估分类模型性能的一个指标,特别是在二分类问题中。F1分数是精确率(Precision)和召回率(Recall)的调和平均值,它试图在这两个指标之间取得平衡。
F1分数的计算公式如下:
F1分数
=
2
×
精确率
×
召回率
精确率
+
召回率
\text{F1分数} = 2 \times \frac{\text{精确率} \times \text{召回率}}{\text{精确率} + \text{召回率}}
F1分数=2×精确率+召回率精确率×召回率
其中:
- 精确率(Precision):衡量的是在所有模型预测为正类的样本中,实际上确实是正类的比例。
- 召回率(Recall):衡量的是在所有实际为正类的样本中,模型正确预测为正类的比例。
F1分数的取值范围也是0到1,或者以百分比的形式表示,其中1或100%表示模型在精确柔和召回方面都有完美的表现。
F1分数在需要同时考虑精确率和召回率的应用场景中非常有用。例如,在信息检索中,我们希望检索结果既相关(高召回率)又准确(高精确率);在医疗诊断中,我们希望尽量减少误诊(高精确率)的同时,也不要漏诊(高召回率)。
除了F1分数,还有F2分数和F0.5分数等,它们分别是精确柔和召回率的加权调和平均值,其中F2分数给予召回率更高的权重,而F0.5分数给予精确率更高的权重。这些指标可以根据具体的应用场景选择,以更好地满足模型的评估需求。
(6)AUC
应对数据不均衡问题的指标有AUC(Area Under the Curve,曲线下面积)。AUC指的是 ROC(Receiver Operating Characteristic,接收器操作特性)曲线下的面积。
AUC(Area Under the Curve)是机器学习中用于评估分类模型性能的一个指标,特别是在二分类问题中。AUC通常指的是ROC曲线(Receiver Operating Characteristic curve)下的面积。
ROC曲线是一种图形化表示,用于展示二元分类器随着阈值变化在不同分类标准下的性能。ROC曲线的横坐标是假正率(False Positive Rate,FPR),纵坐标是真正率(True Positive Rate,TPR),也称为召回率。假正率是指在所有实际为负类的样本中,被错误预测为正类的比例。真正率是指在所有实际为正类的样本中,被正确预测为正类的比例。
AUC的值介于0和1之间,或者以百分比的形式表示,其中1或100%表示模型具有完美的分类性能。AUC的计算方法是将ROC曲线下的面积进行积分。AUC的值越大,表示模型的分类性能越好。
AUC具有以下特点:
- 不依赖于阈值:AUC衡量的是模型在整个阈值范围内的性能,而不仅仅是在某个特定阈值下的性能。
- 对类别不平衡不敏感:AUC对正负样本的比例不敏感,因此在类别不平衡的数据集上评估模型性能时非常有用。
- 概率性解释:AUC可以被解释为随机选择一个正样本和一个负样本时,模型将正样本排在这个负样本之前的概率。
- 比较不同模型:AUC提供了一个统一的指标,可以用来比较不同模型或同一模型在不同设置下的性能。
AUC是评估二元分类器性能的一个非常强大的工具,特别是在需要考虑模型的整体性能而不是特定阈值时。然而,AUC也有其局限性,例如,它不提供关于具体错误类型的详细信息,因此在某些应用中可能需要结合其他指标一起使用。
(7)ROC
ROC(Receiver Operating Characteristic)曲线是一种图形化工具,用于评估二元分类模型的性能。它通过绘制不同分类阈值下的真正率(True Positive Rate, TPR)对阵假正率(False Positive Rate, FPR)的曲线来展示模型的判别能力。
ROC曲线的横坐标是假正率(FPR),它衡量的是在所有实际为负类的样本中,被错误预测为正类的比例。FPR的计算公式如下:
FPR
=
假正类(FP)
假正类(FP)
+
真负类(TN)
\text{FPR} = \frac{\text{假正类(FP)}}{\text{假正类(FP)} + \text{真负类(TN)}}
FPR=假正类(FP)+真负类(TN)假正类(FP)
其中:
- 假正类(False Positive, FP):模型错误预测为正类的负类样本数量。
- 真负类(True Negative, TN):模型正确预测为负类的样本数量。
ROC曲线的纵坐标是真正率(TPR),也称为召回率,它衡量的是在所有实际为正类的样本中,被正确预测为正类的比例。TPR的计算公式如下:
TPR
=
真正类(TP)
真正类(TP)
+
假负类(FN)
\text{TPR} = \frac{\text{真正类(TP)}}{\text{真正类(TP)} + \text{假负类(FN)}}
TPR=真正类(TP)+假负类(FN)真正类(TP)
其中:
- 真正类(True Positive, TP):模型正确预测为正类的样本数量。
- 假负类(False Negative, FN):模型错误预测为负类的正类样本数量。
理想情况下,一个完美的分类器会有一个TPR为1,FPR为0的点,这意味着它能够正确地识别出所有的正类样本,而不会将任何负类样本错误地分类为正类。因此,ROC曲线越靠近左上角,模型的性能越好。
ROC曲线的一个重要特性是它不依赖于类别的不平衡,因此在正负样本比例差异很大的情况下,它仍然是一个有效的评估工具。此外,ROC曲线下的面积(AUC)提供了一个单一的数值来衡量模型的性能,其中AUC值为1表示模型具有完美的判别能力,而AUC值为0.5则表示模型的判别能力与随机猜测相当
2.回归问题
(1)均方误差
平方误差是一个表示实际值和预测值之间存在多大差异的数值。
对于要评估的数据,计算所有预测值与数据之间的误差的平方,并取平方的平均值,得到的就是均方误差(Mean-Square Error,MSE)。
均方误差(Mean Squared Error,MSE)是衡量回归模型预测值与实际观测值之间差异的一种常用指标。它是每个预测值与实际值之差的平方的平均值。
均方误差的计算公式如下:
MSE
=
1
n
∑
i
=
1
n
(
Y
i
−
Y
^
i
)
2
\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (Y_i - \hat{Y}_i)^2
MSE=n1i=1∑n(Yi−Y^i)2
其中:
(
n
)
是数据点的数量。
(
Y
i
)
是第
(
i
)
个实际观测值。
(
Y
^
i
)
是第
(
i
)
个预测值。
( n ) 是数据点的数量。( Y_i ) 是第 ( i ) 个实际观测值。( \hat{Y}_i) 是第 ( i ) 个预测值。
(n)是数据点的数量。(Yi)是第(i)个实际观测值。(Y^i)是第(i)个预测值。
均方误差具有以下特点:
- 平方作用:MSE通过平方误差来放大较大的误差,从而使得较大的误差在计算过程中对总体误差的贡献更大。
- 平均值:MSE是所有样本误差的平均值,这有助于我们理解模型在整体上的表现。
- 单位平方:由于误差是平方的,因此MSE的单位是观测值单位的平方。在实际应用中,可能需要根据具体情况考虑误差的原始单位。
均方误差是回归问题中最常用的损失函数之一,因为它具有较好的数学性质,如连续性和可微性,这使得基于梯度下降的优化算法可以有效地最小化MSE。然而,MSE对异常值非常敏感,因为异常值会导致较大的平方误差,从而对整体误差产生较大的影响。在实际应用中,可能需要根据数据的特点和业务需求选择合适的损失函数。
(2)决定系数
决定系数(coefficient of determination)是使用均方误差来表示训练好的模型的预测效果的数值,也就是被称为R²的系数。
决定系数(Coefficient of Determination),通常用R²表示,是衡量回归模型拟合优度的一个统计量。它表示因变量的变异中可以被模型解释的比例。R²的值介于0和1之间,或者以百分比的形式表示,其中1或100%表示模型完美地拟合了数据,而0则表示模型没有解释能力,即模型的预测值与因变量的平均值没有区别。
决定系数R²的计算公式如下:
R
2
=
1
−
S
S
r
e
s
S
S
t
o
t
R^2 = 1 - \frac{SS_{res}}{SS_{tot}}
R2=1−SStotSSres
其中:
(
S
S
r
e
s
)
是残差平方和(
S
u
m
o
f
S
q
u
a
r
e
s
o
f
R
e
s
i
d
u
a
l
s
),表示模型未能解释的变异。
(
S
S
t
o
t
)
是总平方和(
T
o
t
a
l
S
u
m
o
f
S
q
u
a
r
e
s
),表示因变量的总变异。
( SS_{res} ) 是残差平方和(Sum of Squares of Residuals),表示模型未能解释的变异。( SS_{tot} ) 是总平方和(Total Sum of Squares),表示因变量的总变异。
(SSres)是残差平方和(SumofSquaresofResiduals),表示模型未能解释的变异。(SStot)是总平方和(TotalSumofSquares),表示因变量的总变异。
R²可以理解为模型解释的变异占总变异的比例。例如,如果一个模型的R²值为0.8,那么意味着模型解释了因变量80%的变异。
虽然R²是一个非常有用的统计量,但它也有一些局限性:
- 增加特征不一定增加R²:向模型中添加更多的特征可能会增加R²值,但这并不意味着模型的预测能力有所提高,因为可能会出现过拟合。
- R²不能说明模型的有效性:一个高R²值并不意味着模型就是有效的,它只是说明模型很好地拟合了现有的数据。
- R²对异常值敏感:由于R²是基于残差的平方计算的,因此它对异常值非常敏感,异常值可能会导致R²值显著降低。
在实际应用中,R²通常与其他指标和模型诊断工具一起使用,以全面评估回归模型的性能。
3.超参数的设置
超参数是模型参数之外的参数,它们通常在模型训练之前设置,并且不被模型训练过程直接优化。超参数的设置对模型的性能有重要影响。以下是一些常见的超参数类型和设置方法:
- 学习率(Learning Rate):
- 学习率是梯度下降优化算法中最重要的超参数之一。
- 通常开始时可以设置一个较小的值,如0.001,并根据模型在验证集上的表现进行调整。
- 使用学习率衰减策略,如在训练过程中逐渐减小学习率,可以帮助模型更好地收敛。
- 批量大小(Batch Size):
- 批量大小决定了每次迭代时用于计算梯度的样本数量。
- 较小的批量大小可能导致模型收敛较慢,但可能有助于避免局部最小值。
- 较大的批量大小可以加快训练速度,但可能需要更多的内存或显存。
- 迭代次数(Number of Epochs):
- 迭代次数是指整个数据集被遍历并用于训练模型的次数。
- 过多的迭代次数可能导致过拟合,而迭代次数过少可能导致欠拟合。
- 通常需要通过观察验证集上的性能来决定何时停止训练。
- 隐藏层大小和数量(Hidden Layer Size and Number):
- 隐藏层的大小和数量是神经网络设计中的关键超参数。
- 较多的隐藏层和神经元可以增加模型的表示能力,但也增加了过拟合的风险。
- 可以通过实验和验证集上的性能来调整这些参数。
- 正则化参数(Regularization Parameters):
- 正则化如L1和L2正则化可以帮助减少过拟合。
- 正则化参数的值需要根据数据集和模型复杂度进行调整。
- 决策树相关参数:
- 如最大深度(Max Depth)、最小分割样本数(Min Samples Split)、最小叶子节点样本数(Min Samples Leaf)等。
- 这些参数可以控制模型的复杂度和过拟合的风险。
超参数的设置通常需要经验和实验。一种常见的做法是使用交叉验证来评估不同超参数组合下的模型性能,并选择在验证集上表现最好的超参数。此外,自动化超参数优化工具,如网格搜索(Grid Search)、随机搜索(Random Search)和贝叶斯优化(Bayesian Optimization),也可以帮助找到最佳的超参数组合。
4.模型的过拟合
过拟合(Overfitting)是机器学习中常见的问题,指的是模型在训练数据上表现良好,但在未见过的数据上表现不佳。过拟合的模型捕捉到了训练数据中的噪声和细节,而没有很好地泛化到更广泛的数据分布。这通常意味着模型过于复杂,或者训练时间过长,使得模型对训练数据的学习过于精细。
过拟合的迹象包括:
- 训练误差远低于验证误差或测试误差。
- 模型在训练数据上表现近乎完美,但在验证集或测试集上表现较差。
为了避免过拟合,可以采取以下措施:
- 简化模型:选择更简单的模型,减少模型的参数数量,从而减少模型对训练数据的拟合能力。
- 正则化:应用正则化技术,如L1正则化(Lasso)、L2正则化(Ridge)或弹性网(Elastic Net),来惩罚模型的复杂度。
- 交叉验证:使用交叉验证来评估模型的泛化能力,而不仅仅是训练-验证分割。
- 数据增强:在训练过程中对数据进行变换,增加数据的多样性,从而提高模型的泛化能力。
- 提前停止:在训练过程中,一旦验证误差开始增加,就停止训练,以避免模型对训练数据过度拟合。
- 集成方法:使用集成学习方法,如随机森林或梯度提升树,结合多个模型的预测,以提高泛化能力。
- 增加数据:获取更多的训练数据可以帮助模型更好地学习数据的真实分布,减少过拟合。
- Dropout:在神经网络中使用Dropout技术,在训练过程中随机忽略一些神经元,以减少模型对特定训练样本的依赖。
- 批量归一化:在神经网络中应用批量归一化,有助于稳定训练过程,减少过拟合。
通过上述方法,可以有效地减少模型的过拟合,提高模型在未见数据上的泛化能力。
5.防止过拟合的方法
防止过拟合是机器学习中一个重要的任务,尤其是在训练复杂模型时。以下是一些常用的方法来防止过拟合:
- 数据增强:通过扩大训练集的大小来提高模型的泛化能力。对于图像数据,可以通过旋转、缩放、裁剪、颜色变换等方式来增加样本的多样性。
- 正则化:向模型的损失函数中添加惩罚项,以限制模型权重的大小。常见的正则化技术包括L1正则化(Lasso)、L2正则化(Ridge)和弹性网(Elastic Net)。
- 交叉验证:使用交叉验证来评估模型的泛化能力,而不是仅在单一的训练-验证集上评估。
- 提前停止:在训练过程中,一旦验证集上的性能不再提升,就停止训练,以避免过度的训练。
- 简化模型:选择更简单的模型,减少模型的参数数量,从而减少模型对训练数据的拟合能力。
- 集成方法:使用集成学习方法,如随机森林或梯度提升树,结合多个模型的预测,以提高泛化能力。
- Dropout:在神经网络中使用Dropout技术,在训练过程中随机忽略一些神经元,以减少模型对特定训练样本的依赖。
- 批量归一化:在神经网络中应用批量归一化,有助于稳定训练过程,减少过拟合。
- 贝叶斯方法:通过引入先验知识来约束模型的复杂性,例如使用贝叶斯神经网络。
- 数据重新采样:对于类别不平衡的数据集,可以通过过采样少数类或欠采样多数类来平衡类别分布。
- 特征选择:选择与任务最相关的特征,减少不必要的特征,以降低模型的复杂度。
- 增加训练数据:获取更多的训练数据可以帮助模型更好地学习数据的真实分布,减少过拟合。
- 使用验证集:在训练过程中定期评估模型在验证集上的性能,并根据需要在训练策略上进行调整。
通过上述方法的组合使用,可以有效地减少模型的过拟合,提高模型在未见数据上的泛化能力。
6.将数据分为训练数据和验证数据
防止过拟合的一个代表性的方法是将数据分为训练数据和验证数据。换言之,这种方法不使用事先给定的所有数据进行训练,而是留出一部分数据用于验证,不用于训练。
将数据集分为训练数据(training data)和验证数据(validation data)是机器学习中的一个常见做法,尤其是在监督学习任务中。这种划分的目的是为了评估模型在训练过程中的性能,以及调整模型参数和超参数,以防止过拟合。以下是分步说明如何进行这种划分:
- 数据集准备:
- 确保你的数据集已经清洗好,并且是随机排序的。
- 如果数据集很大,可能还需要进行进一步的划分,例如训练集、验证集和测试集。
- 划分比例:
- 确定训练集和验证集的比例。常见的划分比例有70%的训练集和30%的验证集,或者80%的训练集和20%的验证集。这个比例可以根据具体任务和数据集的大小进行调整。
- 随机划分:
- 使用随机方法将数据集划分为训练集和验证集。确保随机状态(random state)固定,以便结果可重复。
- 分层抽样(如果适用):
- 如果数据集中的类别不平衡,可以使用分层抽样来确保训练集和验证集中的类别比例与原始数据集相似。
- 划分数据:
- 使用编程语言中的划分函数,如Python的
train_test_split函数,来实际进行数据的划分。
下面是一个使用Python和scikit-learn库进行数据划分的示例代码:
- 使用编程语言中的划分函数,如Python的
from sklearn.model_selection import train_test_split
# 假设df是包含你所有数据的Pandas DataFrame
# features是你要用作特征的特征列名称
# target是你要预测的目标列名称
# 将数据分为特征和目标
X = df[features]
y = df[target]
# 划分数据为训练集和验证集
# test_size=0.3表示验证集占30%,训练集占70%
# random_state确保结果的可重复性
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.3, random_state=42)
# 现在你有了训练集(X_train, y_train)和验证集(X_val, y_val)
划分好数据后,你可以在训练集上训练模型,在验证集上评估模型的性能,并根据需要对模型进行调整。这种方法可以帮助你找到一组既能在训练集上表现良好,又能在未见过的数据上泛化良好的模型参数。
7.交叉验证
使用不同的分割方案进行多次验证,这就是所谓的交叉验证(cross validation)。
例如,将数据分割 5 次,其中 80% 的数据用于训练,20% 的数据用于验证的情况。如图所示,每次获取不同的 20% 的数据作为验证数据,重复 5 次。在这个例子中,20% 的数据是按分组顺序分别分割的,但在实际应用中,作为验证数据的 20% 的数据是随机抽取的。
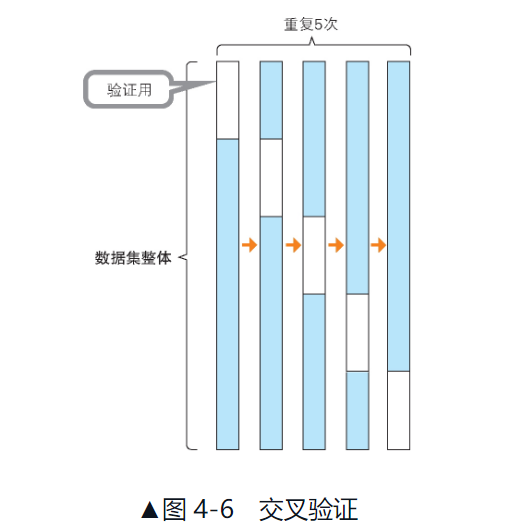
交叉验证(Cross-Validation)是一种评估机器学习模型性能的统计方法,它通过将数据集分为n个互斥的子集,轮流使用其中n-1个子集的数据训练模型,剩下的1个子集用来评估模型。这个过程重复n次,每次选择不同的子集作为测试集,最终评估结果是n次评估结果的平均值。交叉验证的主要目的是为了减少模型的过拟合风险,提高模型在未知数据上的泛化能力。
常用的交叉验证方法有:
- 留出法(Holdout Method):将数据集分为两个不相交的子集,一个作为训练集,另一个作为测试集。这种方法简单,但可能由于数据划分的随机性导致评估结果的波动。
- K-折交叉验证(K-fold Cross Validation):将数据集分为K个大小相等的互斥子集,每次用K-1个子集的数据训练模型,剩下的1个子集用来评估模型。这个过程重复K次,每次选择不同的子集作为测试集,最终评估结果是K次评估结果的平均值。
- 留一法(Leave-One-Out Cross Validation,LOOCV):这是K-折交叉验证的一种极端情况,其中K等于数据集中的样本数。每次只留下一个样本作为测试集,其余样本作为训练集。这种方法非常耗时,但提供了对模型泛化能力的非常保守的估计。
- 分层交叉验证(Stratified K-fold Cross Validation):当数据集中的类别不平衡时,这种方法非常有用。在分层交叉验证中,每次划分时都尽量保持每个折(fold)中类别比例与整个数据集中的类别比例一致。
交叉验证是机器学习模型开发过程中的一个重要步骤,它帮助研究人员和工程师选择和调整模型,以获得最佳的泛化能力。通过交叉验证,可以得到一个更加稳健的模型评估结果,因为它考虑了模型在不同数据子集上的表现。
8.搜索超参数
在机器学习中,超参数(hyperparameters)是模型参数之外的参数,它们通常在模型训练之前设置,并且不被模型训练过程直接优化。超参数的选取对模型的性能有重要影响。为了找到最佳的超参数组合,可以采用以下几种搜索策略:
- 网格搜索(Grid Search):
- 网格搜索是一种穷举搜索方法,它通过遍历指定的超参数网格来找到最佳的超参数组合。
- 网格搜索会评估每个超参数组合的性能,并选择在验证集上性能最佳的组合。
- 网格搜索的一个缺点是计算成本高,特别是当超参数空间较大时。
- 随机搜索(Random Search):
- 随机搜索不像网格搜索那样遍历所有可能的超参数组合,而是从超参数空间中随机选择组合进行评估。
- 随机搜索通常比网格搜索更快,并且有可能找到更好的超参数组合,尤其是当超参数空间较大时。
- 随机搜索允许超参数之间存在依赖关系,而网格搜索通常假设超参数是独立的。
- 贝叶斯优化(Bayesian Optimization):
- 贝叶斯优化使用贝叶斯方法来选择下一个要评估的超参数组合。
- 它基于之前的评估结果来构建一个概率模型,并使用该模型来选择最有可能提高模型性能的超参数组合。
- 贝叶斯优化特别适用于超参数空间大且计算成本高的情况。
- 基于梯度的超参数优化:
- 对于一些模型,超参数优化可以通过梯度下降方法来进行。
- 这种方法通常需要超参数是连续的,并且模型对于超参数是可微的。
- 遗传算法(Genetic Algorithms):
- 遗传算法是一种启发式搜索方法,它受到生物进化的启发。
- 遗传算法通过选择、交叉和突变操作来逐步改进超参数组合。
- 并行和分布式搜索:
- 使用多个处理器或计算机并行地搜索超参数空间可以显著减少搜索时间。
- 分布式计算框架,如Apache Spark,可以用来并行化超参数搜索过程。
在实际应用中,选择哪种搜索策略取决于问题的具体情况,包括超参数空间的复杂性、计算资源、以及模型的特点。通常,随机搜索和贝叶斯优化是首选方法,因为它们在许多情况下既高效又能找到高质量的解决方案。
9.聚类结果的评估方法
聚类结果的评估是一个挑战性的任务,因为聚类缺乏明确的标签来验证结果。以下是一些常用的聚类评估方法:
- 内部评估指标:
- 轮廓系数(Silhouette Coefficient):结合了聚类的凝聚度和分离度,取值范围在-1到1之间,接近1表示聚类效果较好。
- 戴维斯-布尔丁指数(Davies-Bouldin Index):衡量簇内相似度与簇间不相似度的比值,越小表示聚类效果越好。
- 簇内平方和(Within-Cluster Sum of Squares,WCSS):衡量簇内样本到簇中心的平均距离,越小表示聚类越紧凑。
- 外部评估指标:
- 兰德指数(Rand Index):衡量两个聚类结果的相似度,取值范围在0到1之间,1表示完全一致。
- 调整兰德指数(Adjusted Rand Index,ARI):考虑到随机性的影响,对兰德指数进行了调整。
- 互信息(Mutual Information):衡量两个聚类结果的共享信息量,值越高表示聚类结果越相似。
- 调整互信息(Adjusted Mutual Information,AMI):考虑到随机性的影响,对互信息进行了调整。
- 基于模型的评估指标:
- 似然率(Likelihood Ratio):比较实际数据和生成模型数据的相似度。
- 贝叶斯信息准则(Bayesian Information Criterion,BIC):考虑模型复杂性和拟合优度。
- 可视化评估:
- t-SNE(t-Distributed Stochastic Neighbor Embedding):将高维数据投影到二维或三维空间,用于可视化聚类结果。
- PCA(Principal Component Analysis):另一种降维技术,可以用于可视化聚类结果。
- 轮廓图(Silhouette Plot):
-
轮廓图展示了每个样本的轮廓系数,可以帮助确定最佳的聚类数。
-
这种方法通常需要超参数是连续的,并且模型对于超参数是可微的。
-
- 遗传算法(Genetic Algorithms):
- 遗传算法是一种启发式搜索方法,它受到生物进化的启发。
- 遗传算法通过选择、交叉和突变操作来逐步改进超参数组合。
- 并行和分布式搜索:
- 使用多个处理器或计算机并行地搜索超参数空间可以显著减少搜索时间。
- 分布式计算框架,如Apache Spark,可以用来并行化超参数搜索过程。
在实际应用中,选择哪种搜索策略取决于问题的具体情况,包括超参数空间的复杂性、计算资源、以及模型的特点。通常,随机搜索和贝叶斯优化是首选方法,因为它们在许多情况下既高效又能找到高质量的解决方案。
9.聚类结果的评估方法
聚类结果的评估是一个挑战性的任务,因为聚类缺乏明确的标签来验证结果。以下是一些常用的聚类评估方法:
- 内部评估指标:
- 轮廓系数(Silhouette Coefficient):结合了聚类的凝聚度和分离度,取值范围在-1到1之间,接近1表示聚类效果较好。
- 戴维斯-布尔丁指数(Davies-Bouldin Index):衡量簇内相似度与簇间不相似度的比值,越小表示聚类效果越好。
- 簇内平方和(Within-Cluster Sum of Squares,WCSS):衡量簇内样本到簇中心的平均距离,越小表示聚类越紧凑。
- 外部评估指标:
- 兰德指数(Rand Index):衡量两个聚类结果的相似度,取值范围在0到1之间,1表示完全一致。
- 调整兰德指数(Adjusted Rand Index,ARI):考虑到随机性的影响,对兰德指数进行了调整。
- 互信息(Mutual Information):衡量两个聚类结果的共享信息量,值越高表示聚类结果越相似。
- 调整互信息(Adjusted Mutual Information,AMI):考虑到随机性的影响,对互信息进行了调整。
- 基于模型的评估指标:
- 似然率(Likelihood Ratio):比较实际数据和生成模型数据的相似度。
- 贝叶斯信息准则(Bayesian Information Criterion,BIC):考虑模型复杂性和拟合优度。
- 可视化评估:
- t-SNE(t-Distributed Stochastic Neighbor Embedding):将高维数据投影到二维或三维空间,用于可视化聚类结果。
- PCA(Principal Component Analysis):另一种降维技术,可以用于可视化聚类结果。
- 轮廓图(Silhouette Plot):
- 轮廓图展示了每个样本的轮廓系数,可以帮助确定最佳的聚类数。
选择哪种评估方法取决于数据的特性和聚类的目的。通常,结合多种评估方法可以获得更全面的聚类效果评估。

















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









