






代码随想录学习笔记
一.程序的性能分析
1.O(logn)中的log是以什么为底?
平时说这个算法的时间复杂度是logn的,那么一定是log 以2为底n的对数么?
其实不然,也可以是以10为底n的对数,也可以是以20为底n的对数,但我们统一说 logn,也就是忽略底数的描述。
因为,可以通过换底公式得到任意数为底的对数。
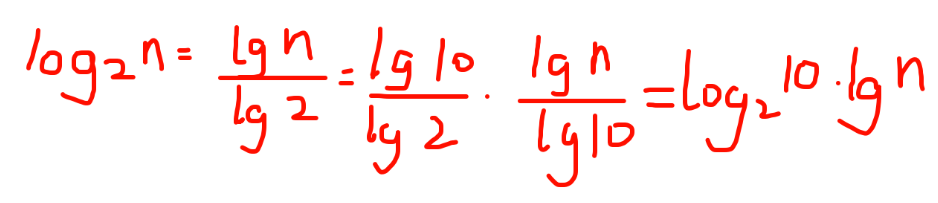
2.递归的时间复杂度
面试题:求x的n次方
**法一:**直接for循环,O(n)
int function1(int x,int n){
int result=1;
for(int i=0;i<n;i++){
result*=x;
}
return result;
}
**法二:**直接递归,O(n)
int function2(int x,int n){
if(n==0) return 1;
else return x* function2(x,n-1);
}
**法三:**分两部分(奇次幂和偶次幂)进行递归,O(n)
int function3(int x,int n){
if(n==0) return 1;
else if (n%2==0) return function3(x,n/2) * function3(x,n/2);//偶次幂
else return x* function3(x,n/2) * function3(x,n/2);//奇次幂
}
我们来分析一下,首先看递归了多少次呢,可以把递归抽象出一棵满二叉树。刚刚同学写的这个算法,可以用一棵满二叉树来表示(为了方便表示,选择n为偶数16),如图:
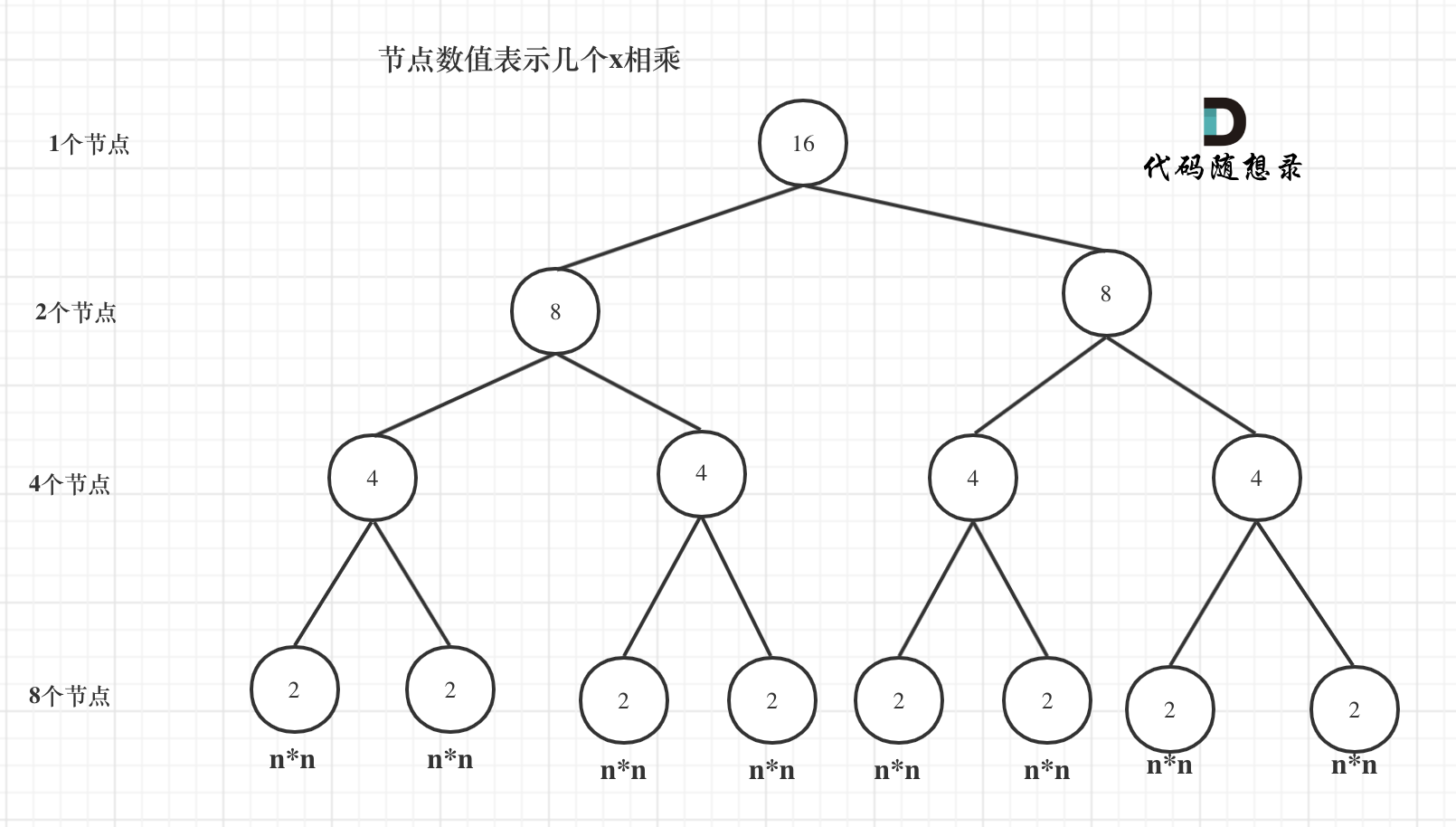
当前这棵二叉树就是求x的n次方,n为16的情况,n为16的时候,进行了多少次乘法运算呢?
这棵树上每一个节点就代表着一次递归并进行了一次相乘操作,所以进行了多少次递归的话,就是看这棵树上有多少个节点。
熟悉二叉树话应该知道如何求满二叉树节点数量,这棵满二叉树的节点数量就是2^3 + 2^2 + 2^1 + 2^0 = 15,可以发现:这其实是等比数列的求和公式,这个结论在二叉树相关的面试题里也经常出现。
这么如果是求x的n次方,这个递归树有多少个节点呢,如下图所示:(m为深度,从0开始)
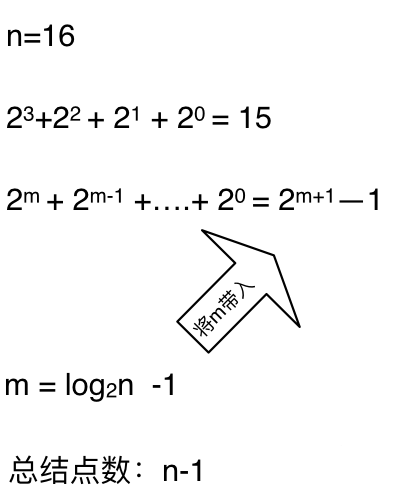
时间复杂度忽略掉常数项-1之后,这个递归算法的时间复杂度依然是O(n)。
法四:采用了分治法的思想,每次递归保证会处理两次数据,奇数和偶数,时间复杂度是O(logn)
int function4(int x, int n) {
//采用了分治法的思想
if (n == 0) return 1;
if (n == 1) return x;
int t = function4(x, n / 2);// 这里相对于function3,是把这个递归操作抽取出来
if (n % 2 == 1) {
return t * t * x;
}
return t * t;
}
3.空间复杂度
空间复杂度是考虑程序运行时占用内存的大小,而不是可执行文件的大小。
递归算法的空间复杂度=每次递归的空间复杂度×递归深度
为什么要求递归深度?因为每次递归所需的空间都被压到调用栈里(这里内存管理中的数据结构,和算法中的栈的原理是一样的),一次递归结束,这个栈九八本次递归的数据“弹出去”。所以这个栈的最大长度就是递归的深度。
在C/C++中函数传递数组参数,不是整个数组拷贝一份传入函数而是传入的数组首元素地址。也就是说每一层递归都是公用一块数组地址空间的,所以 每次递归的空间复杂度是常数即:O(1)。
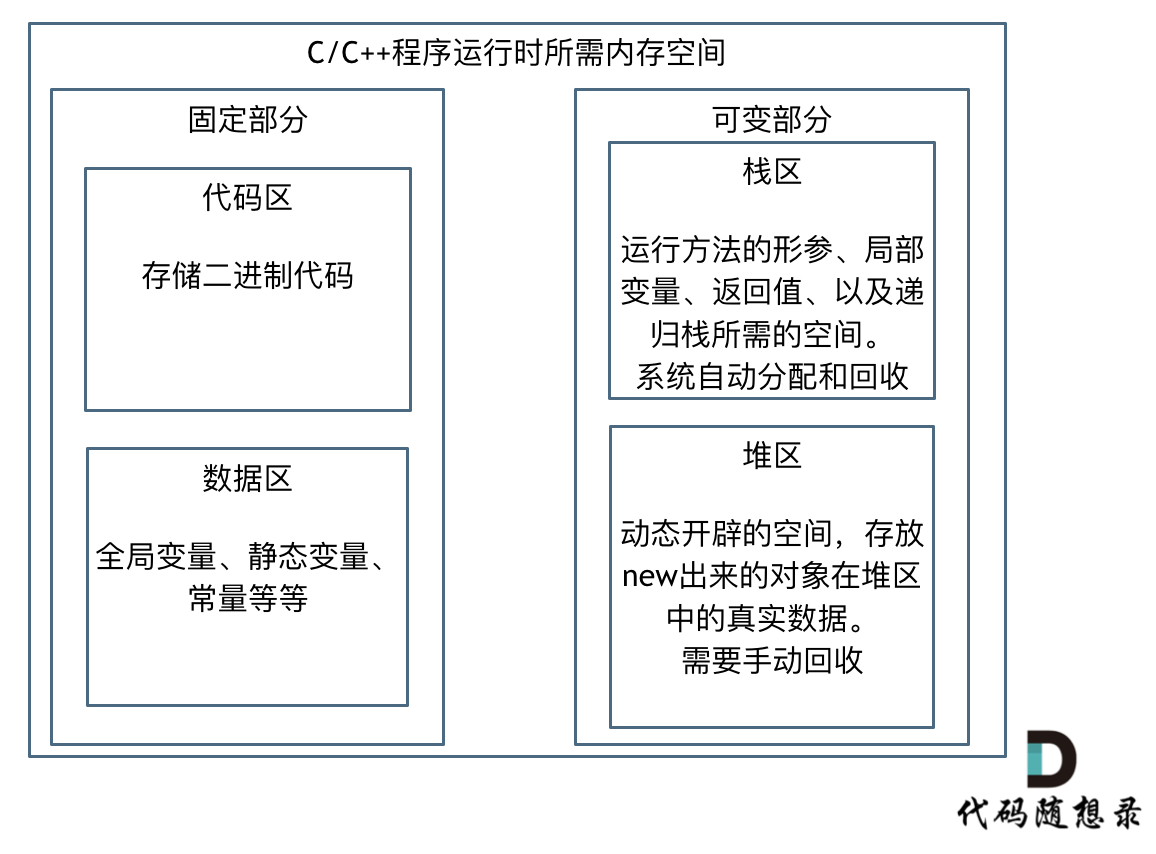
4.C++的内存管理
一个由C/C++编译的程序占用的内存分为以下几个部分:
- 栈区(Stack) :由编译器自动分配释放,存放函数的参数值,局部变量的值等,其操作方式类似于数据结构中的栈。
- 堆区(Heap) :一般由程序员分配释放,若程序员不释放,程序结束时可能由OS收回
- 未初始化数据区(Uninitialized Data): 存放未初始化的全局变量和静态变量
- 初始化数据区(Initialized Data):存放已经初始化的全局变量和静态变量
- 程序代码区(Text):存放函数体的二进制代码
代码区和数据区所占空间都是固定的,而且占用的空间非常小,那么看运行时消耗的内存主要看可变部分。
在可变部分中,栈区间的数据在代码块执行结束之后,系统会自动回收,而堆区间数据是需要程序员自己回收,所以也就是造成内存泄漏的发源地。
5.内存对齐
内存对齐是计算机系统中的一个概念,指的是数据存储在内存中时按照某种规则排列的方式。在大多数计算机系统中,数据通常按照其大小的倍数进行对齐,以提高内存访问的效率。
内存对齐的概念有两个重要方面:
-
数据对齐:数据类型在内存中的起始地址必须是其大小的整数倍。例如,一个 4 字节大小的整数通常会被要求存储在内存地址是 4 的倍数的位置上。如果数据没有正确对齐,处理器可能需要进行多次内存访问才能读取完整的数据,降低了访问效率。
-
结构对齐:结构体中的成员变量也需要进行对齐,通常会按照结构体中最大成员变量的大小进行对齐,以确保结构体的整体对齐。这样做是为了减少内存访问的次数和提高访问速度。
内存对齐在许多情况下是由编译器自动处理的,开发者通常无需手动进行操作。但在某些情况下,为了优化内存使用或与外部系统进行交互,可能需要手动控制内存对齐。在 C/C++ 中,可以使用一些特殊的语法或编译器指令来实现对齐操作。
6.为什么需要内存对齐
内存对齐的存在主要是为了提高计算机系统的性能和可靠性。以下是内存对齐的几个主要原因:
-
硬件要求:许多计算机体系结构对内存访问的性能有严格的要求。某些处理器甚至要求数据必须按照其大小的倍数对齐,否则可能会导致性能下降或异常行为。例如,一些处理器可能只能从偶地址读取双字节数据,从四字节边界读取四字节数据,从八字节边界读取八字节数据等。
-
提高访问效率:内存对齐可以减少处理器在读取和写入内存时所需的操作次数。如果数据没有正确对齐,处理器可能需要多次访问内存来读取完整的数据,而内存对齐可以减少这种额外的访问次数,从而提高访问效率。
-
简化硬件设计:内存对齐可以简化硬件设计,使得硬件能够更加高效地访问内存。例如,对齐的数据可以更容易地通过总线传输,而无需进行额外的操作。
-
提高可靠性:内存对齐可以减少内存访问中可能出现的错误和异常情况。例如,未对齐的数据可能会导致内存访问异常,甚至在某些情况下可能导致系统崩溃。
综上所述,内存对齐是为了满足硬件要求、提高访问效率、简化硬件设计以及提高系统可靠性而存在的重要概念。
7.以空间换时间
例子:给出n个字母(小写字母从a到z),找出出现次数最多的字母并输出该字母。
法一:暴力枚举,时间O(n²),空间O(1)
void function1(const vector<char> &a){
char result;
int max_count=0;
for (int i=0;i<a.size();i++){
int num=0;//统计a[i]字符出现的次数
for(int j=0;j<a.size();j++){
if (a[i]==a[j]) num++;
}
if(num>max_count) {
result=a[i];
max_count=num;
}
}
cout<<"出现次数最多的字符是"<<result<<"出现了"<<max_count<<"次"<<endl;
}
法二:考虑到字母个数只有26个,所以建立一个字母数组,下标表示字母的次序,元素表示该字母出现的次数。以空间换时间。
时间O(n),空间O(26)=O(1)
void function2(const vector<char> &a){
int record[26]={0};//字母数组
for(int i=0;i<a.size();i++){//计算出各字母出现的次数
record[a[i]-'a']++;
}
char result;
int max_count=0;
for(int i=0;i<26;i++){//找到出现次数最多的字母
if(record[i]>max_count){
result='a'+i;
max_count=record[i];
}
}
cout<<"出现次数最多的字符是"<<result<<"出现了"<<max_count<<"次"<<endl;
}
注:哈希法就是基于空间换时间的思路实现的。在哈希法中,使用数组、set、map等容器无一例外都是基于空间换时间的思路。先将集合中的数据放入容器中,然后通过哈希索引的方式快速找到某个元素是否出现在这个集合中。在哈希法中,时间复杂度一般都是O(1)级别,就是因为使用了“空间”将集合中的数据进行了预处理,节约了“时间”,从而达到快速查找的目的。
二.数组
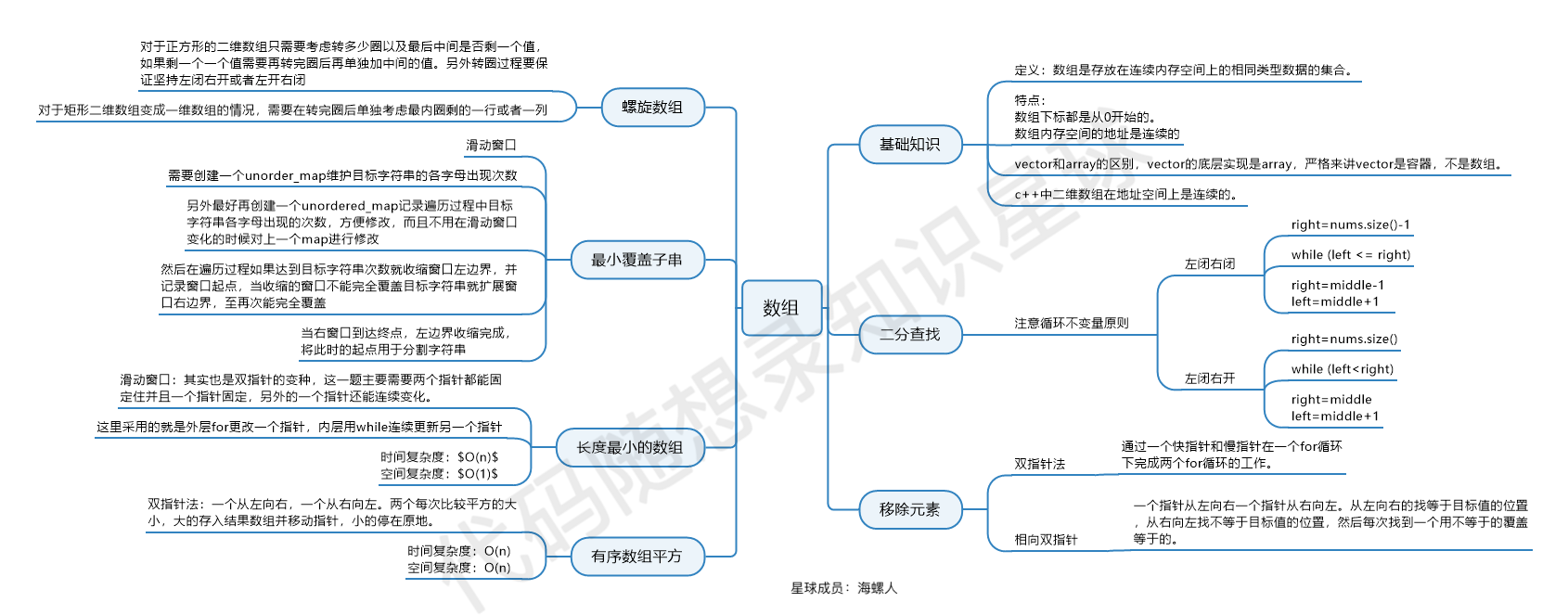
1.基础理论
数组是存放在连续内存空间上的相同类型数据的集合。
数组下标都是从0开始的。
数组内存空间的地址是连续的。
在C++中二维数组的地址空间是连续分布的。
2.二分查找(循环不变量原则)
题目链接:https://leetcode.cn/problems/binary-search/description/
my_code:暴力求解,循环一遍。时间O(n)
缺点是我没有用到这个数组有序且无重复元素的条件。
class Solution {
public:
int search(vector<int>& nums, int target) {
for (int i = 0; i < nums.size(); i++) {//依次查找一遍
if (nums[i] == target)
return i;
}
return -1;
}
};
因为是有序且无重复元素的数组,可以考虑用二分法查找,能找到就返回该下标,找不到就返回-1。时间O(logn)
写二分法,区间的定义一般为两种,左闭右闭即[left, right],或者左闭右开即[left, right)。
法一:左闭右闭即[left, right]
- 时间复杂度:O(log n)
- 空间复杂度:O(1)
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0;// 下限
int right = nums.size() - 1;// 上限
while (left <= right) {// [left, right]
int mid = (left + right) / 2;
// 防止溢出,可以这样写
// mid = left + (right - left) / 2;
if (nums[mid] < target) left = mid + 1;
else if (nums[mid] > target) right = mid - 1;
else return mid;
}
return -1;
}
};
法二:左闭右开即[left, right)。实现方法就是上限取不到,所以就给大点。
- 时间复杂度:O(log n)
- 空间复杂度:O(1)
注意:
int right = nums.size();
int mid = left + ((right - left) >> 1);
// 版本二
class Solution {
public:
int search(vector<int>& nums, int target) {
int left = 0;
int right = nums.size(); // 定义target在左闭右开的区间里,即:[left, right)
while (left < right) { // 因为left == right的时候,在[left, right)是无效的空间,所以使用 <
int mid = left + ((right - left) >> 1);
// 用 >> 1进行右移一位的操作,实际上就是除以2并向下取整
if (nums[mid] > target) {
right = mid; // target 在左区间,在[left, mid)中
} else if (nums[mid] < target) {
left = mid + 1; // target 在右区间,在[mid + 1, right)中
} else { // nums[mid] == target
return mid; // 数组中找到目标值,直接返回下标
}
}
// 未找到目标值
return -1;
}
};
(1)搜索插入位置
题目链接:https://leetcode.cn/problems/search-insert-position/description/
my_code
法一:暴力解法
- 时间复杂度:O(n)
- 空间复杂度:O(1)
class Solution {
public:
int searchInsert(vector<int>& nums, int target) {
for(int i=0;i<nums.size();i++){
//如果target小于当前值,i就没有再往后的必要了,因为后面的值都比target大,故插入在下标为i的位置
if(target<nums[i]) return i;
else if(nums[i]==target) return i;
}
//意味着target比nums中所有元素都要大,故插入在下标为nums.size()的位置
return nums.size();
}
};
法二:二分法
- 时间复杂度:O(logn)
- 空间复杂度:O(1)
class Solution {//左闭右闭即[left, right]
public:
int searchInsert(vector<int>& nums, int target) {
int left=0;
int right=nums.size()-1;
int mid=left+(right-left)/2;
while(left<=right){
if(nums[mid]<target) left=mid+1;
else if(nums[mid]>target) right=mid-1;
else return mid;
mid=left+(right-left)/2;
//保证mid始终是right和left更新后计算的值,而不受while循环的条件直接跳出去导致mid还是前一个值
}
return mid;
}
};
class Solution {//左闭右开即[left, right)
public:
int searchInsert(vector<int>& nums, int target) {
int left=0;
int right = nums.size()-1;
if(target<nums[left]) return 0;
if(target>nums[right]) return right+1;
int mid=left+(right-left)>>1;
while(left<right){
if(nums[mid]<target) left=mid+1;
else if(nums[mid]>target) right=mid;
else return mid;
mid=left+((right-left)>>1);
}
return mid;
}
};
官方题解
- 时间复杂度:O(logn)
- 空间复杂度:O(1)
class Solution {
public:
int searchInsert(vector<int>& nums, int target) {
int n = nums.size();
int left = 0, right = n - 1, ans = n;
while (left <= right) {
int mid = ((right - left) >> 1) + left;//防溢出
if (target <= nums[mid]) {
ans = mid;
right = mid - 1;
} else {
left = mid + 1;
}
}
return ans;
}
};
(2)在排序数组中查找元素的第一个和最后一个位置
题目链接:https://leetcode.cn/problems/search-insert-position/description/
my_code:
主要是findLeft函数的理解,因为是有序的,所以,如果在右半部分mid找到了,那么下面肯定是左边继续计算,右边肯定一点都不会计算了,所以最后会在左边找到合适的最小的(因为如果有一样的重复数据的话,右边的mid会继续往左边去,直到最后一个重复的target)。
时间复杂度:O(logn),其中 n 为数组的长度。二分查找所需的时间复杂度为 O(logn)。
空间复杂度:O(1)。我们只需要常数空间存放若干变量。
class Solution {
public:
//先找到左边界
int findLeft(vector<int>& nums, int target) {
//用二分法去查找,一直从左边找到答案,而从右边找的却不管
int left = 0;
int right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;//防溢出
if (nums[mid] < target)
left = mid + 1;
else
right = mid - 1;
}
if(left==nums.size()||nums[left]!=target) return -1;
//因为left最终指向的位置,如果长度为0,那么left指向0,如果有长度,但不包含target,会直到最后一个,即size()的长度
//或者到最后仍然没找到target,那么返回-1
else return left;//如果不是长度为0,那就返回左边界的值
}
vector<int> searchRange(vector<int>& nums, int target) {
int left = findLeft(nums, target);
if (left == -1) return vector<int>{-1, -1};//nums长度为0的话,直接返回-1
int right = left;
while (right < nums.size() - 1 && nums[right + 1] == target) {
//保证下一个值和target一样,同时right下标不会越界
right++;
}
return vector<int>{left, right};
//下面这样写也可以,一样的,多加的,最后在返回值的时候减去1就好了
//while(right<nums.size()&&nums[right]==target){
// right++;
//}
//return vector<int>{left,--right};
}
};
题解:
想法是分别找数的上界和下界,两次二分查找
时间复杂度:O(logn),其中 n 为数组的长度。二分查找所需的时间复杂度为 O(logn)。
空间复杂度:O(1)。我们只需要常数空间存放若干变量。
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
int leftBorder = getLeftBorder(nums, target);
int rightBorder = getRightBorder(nums, target);
// 情况一
if (leftBorder == -2 || rightBorder == -2) return {-1, -1};
// 情况三
if (rightBorder - leftBorder > 1) return {leftBorder + 1, rightBorder - 1};
// 情况二
return {-1, -1};
}
private:
int getRightBorder(vector<int>& nums, int target) {//找右边界,所以从左边界找到也不会变,只看右边界动去找
int left = 0;
int right = nums.size() - 1;
int rightBorder = -2; // 记录一下rightBorder没有被赋值的情况
while (left <= right) {
int middle = left + ((right - left) / 2);
if (nums[middle] > target) {
right = middle - 1;
} else { // 寻找右边界,nums[middle] == target的时候更新left
left = middle + 1;
rightBorder = left;
}
}
return rightBorder;
}
int getLeftBorder(vector<int>& nums, int target) {//找左边界,所以从右边界找到也不会变,只看左边界动去找
int left = 0;
int right = nums.size() - 1;
int leftBorder = -2; // 记录一下leftBorder没有被赋值的情况
while (left <= right) {
int middle = left + ((right - left) / 2);
if (nums[middle] < target) { // 寻找左边界,nums[middle] == target的时候更新right
left = middle + 1;
} else {
right = middle - 1;
leftBorder = right;
}
}
return leftBorder;
}
};
(3)x的平方根
题目链接:https://leetcode.cn/problems/sqrtx/description/
my_code:
法一:暴力求解
- 时间复杂度:O(x)。
- 空间复杂度:O(1)。
class Solution {
public:
int mySqrt(int x) {
for(long i=0;;i++){
if(i*i<=x && x<(i+1)*(i+1)){
return i;
}
}
}
};
法二:二分法
- 时间复杂度:O(logx),即为二分查找需要的次数。
- 空间复杂度:O(1)。
class Solution {
public:
int mySqrt(int x) {
int left=0;
int right=x;
while(left<right){
int mid=left+(right-left)/2;
//int ans =mid*mid;
//因为输入的数可能非常大,所以相乘之后结果更大了,建议用long
long ans = (long)mid*mid;
if(ans>x) right=mid-1;
else left=mid+1;
}
return right;
}
};
题解:牛顿迭代法
https://zhuanlan.zhihu.com/p/240077462
http://t.csdnimg.cn/imHd3
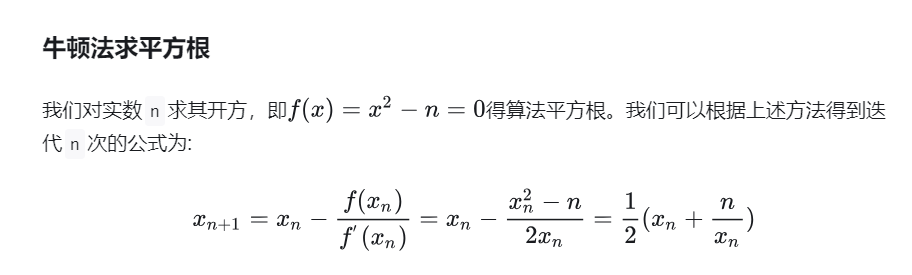
- 时间复杂度:O(logx),此方法是二次收敛的,相较于二分查找更快。
- 空间复杂度:O(1)。
class Solution {
public:
int mySqrt(int x) {
if (x == 0) {
return 0;
}
double C = x, x0 = x;
while (true) {
double xi = 0.5 * (x0 + C / x0);
if (fabs(x0 - xi) < 1e-7) {
break;
}
x0 = xi;
}
return int(x0);
}
};
(4)有效的完全平方数
题目链接:https://leetcode.cn/problems/valid-perfect-square/description/
my_code:
二分法
- 时间复杂度:O(logn),其中 nnn 为正整数 num 的最大值。
- 空间复杂度:O(1)。
class Solution {
public:
bool isPerfectSquare(int num) {
int left=0;
int right=num;
while(left<=right){
int mid=left+(right-left)/2;
long ans=(long)mid*mid;
//long ans=mid*mid;这样写会报错,因为这里默认mid是int型,两个int相乘,仍然是int,所以我们需要将其中一个强转成long型,这样右边相乘的结果就是long型
if(ans<num) left=mid+1;
else if(ans>num) right=mid-1;
else return true;
}
return false;
}
};
题解:
法一:牛顿迭代法:
- 时间复杂度:O(log num),此方法是二次收敛的,相较于二分查找更快。
- 空间复杂度:O(1)。
class Solution {
public:
bool isPerfectSquare(int num) {
double x0=num,x1;
while(true){
x1=(x0+num/x0)/2;
if((x0-x1)< 1e-6) break;
//我们将截至条件设置为1e-6精度,这样保证继续迭代的数值和上一次的数值差别不大(只在1e-6精度内),故可停止迭代
else x0=x1;
}
int x =int(x0);//取迭代结束后的整数部分
return x*x==num;//如果整数部分的平方等于num,即num为完全平方数
}
};
法二:从数的性质来看:
1=1 4=1+3 9=1+3+5 16=1+3+5+7以此类推,模仿它可以使用一个while循环,不断减去一个从1开始不断增大的奇数,若最终减成了0,说明是完全平方数,否则,不是。
-
时间复杂度:
O ( n ) O(\sqrt{n}) O(n) -
空间复杂度:O(1)。
class Solution {
public:
bool isPerfectSquare(int num) {
int x=1;
while(num>0){
num-=x;
x+=2;
}
return num==0;
}
};
3.双指针法
通过一个快指针和慢指针在一个for循环下完成两个for循环的工作。
(1)移除元素
https://leetcode.cn/problems/remove-element/description/
my_code
暴力法
- 时间复杂度:O(n^2)
- 空间复杂度:O(1)
class Solution {
public:
int removeElement(vector<int>& nums, int val) {
int size=nums.size();
for(int i=0;i<size;i++){
if(nums[i]==val){//如果相等就开始移动
for(int j=i;j<size-1;j++){
//因为将后一个移动到前一个,所以j循环的上限应该是size-1
nums[j]=nums[j+1];
}
size--;//因为移动之后,少了一个元素,需要将size总长度减1
i--;//移动之后,现在i位置的元素是之前i+1位置的元素,为了防止for循环中再进行i++,这时候应该将i-1,以确保不漏一个元素
}
}
return size;
}
};
题解
双指针法
- 时间复杂度:O(n)
- 空间复杂度:O(1)
class Solution {
public:
int removeElement(vector<int>& nums, int val) {//双指针法
int size = nums.size();
int left=0,right=0;
//right指针始终往右走
//left指针保留最终的数组元素
while(left<size){
if(nums[right]!=val){
//不是val,即可保存
nums[left++]=nums[right++];
}else{
//是val,left不保存,size减,right继续遍历
right++;
size--;
}
}
return size;
}
};
双指针的优化
如果要移除的元素恰好在数组的开头,例如序列「1,2,3,4,5」,当 val为1时,我们需要把每一个元素都左移一位。注意到题目中说:「元素的顺序可以改变」。实际上我们可以直接将最后一个元素5 移动到序列开头,取代元素 1,得到序列「5,2,3,4」,同样满足题目要求。这个优化在序列中 val元素的数量较少时非常有效。
实现方面,我们依然使用双指针,两个指针初始时分别位于数组的首尾,向中间移动遍历该序列。
- 时间复杂度:O(n),其中 n为序列的长度。我们只需要遍历该序列至多一次。
- 空间复杂度:O(1)。我们只需要常数的空间保存若干变量。
class Solution {
public:
int removeElement(vector<int>& nums, int val) {//双指针法
int left=0;//从头开始的首指针
int right=nums.size()-1;//尾指针
while(left<=right){
if(nums[left]==val) nums[left]=nums[right--];
else left++;
}
return right+1;//因为right指向最后一个元素的下标,而返回值为长度,故需加1
}
};
(2)删除排序数组中的重复项
https://leetcode.cn/problems/remove-duplicates-from-sorted-array/description/
my_code
- 时间复杂度:O(n)
- 空间复杂度:O(1)
class Solution {
public:
int removeDuplicates(vector<int>& nums){
int size=nums.size();
int left=0,right=1;
while(right < nums.size()){
if(nums[left]==nums[right]) {//如果相同,left不动,right动
right++;
size--;
}
else nums[++left]=nums[right++];//如果不同,left。right都动
}
return size;
}
};
(3)移动零
https://leetcode.cn/problems/move-zeroes/description/
my_code
- 时间复杂度:O(n)
- 空间复杂度:O(1)
class Solution {
public:
void moveZeroes(vector<int>& nums) {
int left=0,right=0;
while(right < nums.size()){
//快指针走一遍,遇到不是0的就放在慢指针的位置
if(nums[right]==0) right++;
else nums[left++]=nums[right++];
}
for(int i=left;i<nums.size();i++)//将后面的元素刷成0
nums[i]=0;
}
};
(4)比较含退格的字符串
https://leetcode.cn/problems/backspace-string-compare/description/
my_code
- 时间复杂度:O(n)
- 空间复杂度:O(1)
class Solution {
public:
bool backspaceCompare(string s, string t) {
//利用双指针进行查#,如果找到退格符,那么就往前退
//最后left指向的是处理后的字符串的最后一位的下标
int left_s=0,right_s=0;
while(right_s < s.size()){
if(s[right_s] != '#') s[left_s++]=s[right_s++];
else {
left_s= left_s > 0 ? left_s - 1 : left_s;//保证当#比字符多的时,left不会变负数
right_s++;
}
}
int left_t=0,right_t=0;
while(right_t < t.size()){
if(t[right_t] != '#') t[left_t++]=t[right_t++];
else {
left_t= left_t > 0 ? left_t - 1 : left_t;
right_t++;
}
}
//如果处理后两个字符串一样长,才可能相等
if(left_s == left_t){
for(int i=0; i < left_s; i++)
if(s[i]!=t[i]) return false;//如果处理后的字符串有不一样的字符,那么返回false
return true;
}
else return false;//如果处理后两个字符串不一样长,不可能相等
}
};
题解
利用栈来重构字符串,非常简单
- 时间复杂度:O(n)
- 空间复杂度:O(1)
class Solution {
public:
bool backspaceCompare(string S, string T) {
return build(S) == build(T);
}
string build(string str) {
string ret;
for (char ch : str) {
//for (char ch : str) 是一种 C++ 中的范围基于范围的循环语法,用于遍历字符串 str 中的每个字符,并将每个字符赋值给变量 ch。
//这种循环语法可以用于遍历支持迭代器的容器,包括字符串。在每次迭代中,循环将执行指定的代码块,并将当前迭代的元素赋值给变量 ch,使您可以对每个字符执行特定的操作或逻辑。
if (ch != '#') ret.push_back(ch);//如果不是#就压进去
else if (!ret.empty()) ret.pop_back();//else首先保证这边情况是遇到了#,而且此时ret不是空的,就退出一个字符串
}
return ret;
}
};
(5)有序数组的平方
https://leetcode.cn/problems/squares-of-a-sorted-array/description/
my_code
利用双指针,分别指向头部和尾部,如果遇到绝对值大的,就将其求平方,放在新数组的最后,保证是升序排列
- 时间复杂度:O(n)
- 空间复杂度:O(n)
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
int left=0;
int right=nums.size()-1;
vector<int> ans(nums.size());//因为题目没有限制空间复杂度,我们可以创建一个容器放整理后的数组
int i=1;
while(left <= right){
if(abs(nums[left]) > abs(nums[right])){
//因为是大的放在最后,所以这样操作nums.size()-i++
ans[nums.size()-i++]=nums[left]*nums[left];
left++;
}
else{
ans[nums.size()-i++]=nums[right]*nums[right];
right--;
}
}
return ans;
}
};
题解
法一:用堆栈,双指针一个从头一个从尾,如果绝对值大就先压栈里面,然后再对栈的结果进行逆序就好了,跟上面那种方法有点类似
- 时间复杂度:O(n)
- 空间复杂度:O(n)
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
vector <int> ans;
//vector <int> ans(nums.size());是不对的(ans[0]~ans[nums.size()]都是0)
//需要注意的是,在使用push_back时会自动在尾部创建空间,就会在nums.size()后面入栈,导致错误
//同理,使用pop_back时,也会自动在尾部销毁空间。
int left=0,right=nums.size()-1;
while(left <= right){
if(abs(nums[left]) > abs(nums[right])){
ans.push_back(nums[left]*nums[left]);
left++;
}
else {
ans.push_back(nums[right]*nums[right]);
right--;
}
}
for(int i=0;i<nums.size();i++){
//因为ans里面是逆序排列的,就把ans内元素反转过来赋值给nums
nums[i]=ans[nums.size()-1-i];
}
return nums;
}
};
法二:先找到负数和正数的分界线,然后对两部分进行归并排序
- 时间复杂度:O(n)
- 空间复杂度:O(n)
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
int gap = 0;
for (int num : nums) {
if (num < 0) gap++;
else break;
}
vector<int> ans(nums.size());
int count = 0;
//先比小的,把小的放前面,所以i应该从gap-1开始,j从gap开始
int i = gap - 1; // 将 i 指向最后一个负数的索引,绝对值最小
int j = gap; // 将 j 指向第一个非负数的索引,绝对值最小
while (i >= 0 && j < nums.size()) { // 注意边界情况处理
if (abs(nums[i]) <= abs(nums[j])) {
ans[count++] = nums[i] * nums[i];
i--;
} else {
ans[count++] = nums[j] * nums[j];
j++;
}
}
// 剩余未处理的数,放在数组的最后
while (i >= 0) {
ans[count++] = nums[i] * nums[i];
i--;
}
while (j < nums.size()) {
ans[count++] = nums[j] * nums[j];
j++;
}
return ans;
}
};
4.滑动窗口–双指针的变形
滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将O(n^2)的暴力解法降为O(n)。
滑动窗口,就是不断的调节子序列的起始位置和终止位置,从而得出我们要想的结果。
在暴力解法中,是一个for循环滑动窗口的起始位置,一个for循环为滑动窗口的终止位置,用两个for循环 完成了一个不断搜索区间的过程。
那么滑动窗口如何用一个for循环来完成这个操作呢。
首先要思考 如果用一个for循环,那么应该表示 滑动窗口的起始位置,还是终止位置。
如果只用一个for循环来表示 滑动窗口的起始位置,那么如何遍历剩下的终止位置?
此时难免再次陷入 暴力解法的怪圈。
所以 只用一个for循环,那么这个循环的索引,一定是表示 滑动窗口的终止位置。
那么问题来了, 滑动窗口的起始位置如何移动呢?
这里还是以题目中的示例来举例,s=7, 数组是 2,3,1,2,4,3,来看一下查找的过程:
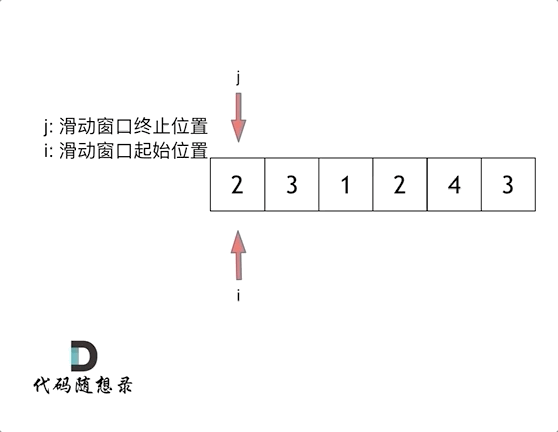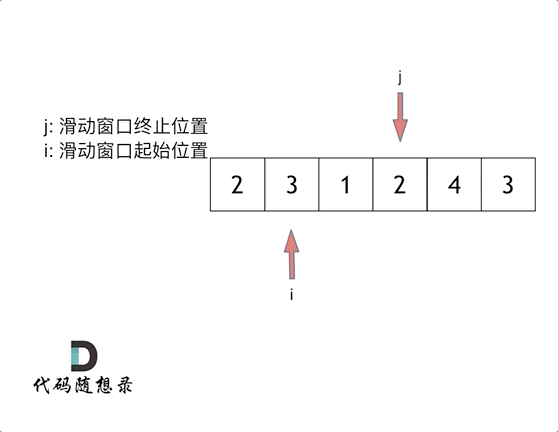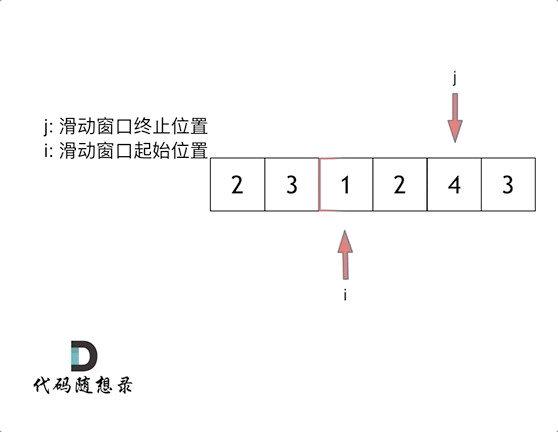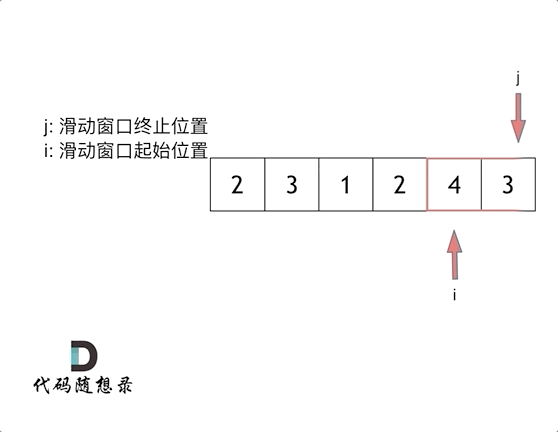
最后找到 4,3 是最短距离。
其实从动画中可以发现滑动窗口也可以理解为双指针法的一种!只不过这种解法更像是一个窗口的移动,所以叫做滑动窗口更适合一些。
(1)长度最小的子数组
https://leetcode.cn/problems/minimum-size-subarray-sum/description/
my_code
暴力求解,两层循环(会超时)
- 时间复杂度:O(n²)
- 空间复杂度:O(1)
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int n = nums.size();
int min_length = INT_MAX;//先将最小的长度赋值成一个特殊值
for (int i = 0; i < n; ++i) {
int sum = 0;
for (int j = i; j < n; ++j) {
sum += nums[j];
if (sum >= target) {
min_length = min(min_length, j - i + 1);
//如果有满足条件的,需要将其长度和min_length进行对比,找出最小的
break;
}
}
}
return (min_length == INT_MAX) ? 0 : min_length;
//如果min_length == INT_MAX,就是数组内没有满足的子数组。返回0
}
};
题解
滑动窗口
- 时间复杂度:O(n)
- 空间复杂度:O(1)
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int min_length=INT_MAX;
int left=0,right=0;
int n=nums.size();
int sum=0;
while(right < n){
sum+=nums[right];
right++;//右边窗口往前移动,
while(sum>=target){
//因为可能从左边减1个后sum仍大于等于target,故需滑动左边边缘直到满足sum<target时,才能进行加新的值
//所以我们在每次调整数据后,需要改变min_length的值,以获取最小的值
min_length=(min_length > (right-left)) ? (right-left) : min_length;
sum-=nums[left++];
}
}
return (min_length==INT_MAX) ? 0 :min_length;
}
};
(2)水果成篮
https://leetcode.cn/problems/fruit-into-baskets/description/
my_code
滑动窗口,但是最终没成功,执行报错。不过我也不知道哪里有问题。我的想法是先写一个exit函数,可以判断在数组内是否存在该种元素。接着到整体部分,快慢指针都先指向0。然后水果种类able数组就都是fruits[0]。开始循环,如果右指针指向的水果种类在able数组中,右指针就继续往右走。如果右指针指向的水果种类不在able数组中,先判断able数组内是不是两个一样的水果种类,如果是两个一样的,那就把此时右指针指向的水果种类添加到able数组内,随便替换一个。如果able数组内不是两个一样的水果种类,此时把left指针指向的水果种类的水果全部移除。
改了好久发现还是错误,我还是老老实实地用滑动窗口加哈希表吧。
class Solution {
public:
bool exit(int *a[], int x, int &index) {
// 判断在a数组内是否存在x元素,如果存在那么返回下标+1,如果不存在返回0
for (int i = 0; i < 2; i++) {
if (a[i][0] == x) {
index = i;
// num=a[i][1];
return true;
}
}
index = -1;
return false;
}
int totalFruit(vector<int>& fruits) {
int left = 0, right = 0;
int** able = new int*[2]; // 创建一个指针数组,包含两个指针
able[0] = new int[2]; // 第一个指针指向一个长度为2的整数数组
able[1] = new int[2]; // 第二个指针指向一个长度为2的整数数组
able[0][0] = fruits[left];
able[0][1] = 1;
able[1][0] = fruits[right];
able[1][1] = 1;
int max_length = 0;
while (right < fruits.size()) {
// 当右边界的类型存在于able数组内或者able内是两种一样的
int index = 0;
// int num_right=0;
while (right < fruits.size() && exit(able, fruits[right], index)) {
// 找到右边界指向而不在able种类数组内水果
// if(right > fruits.size()) return max_length;
able[index][1]++;
++right;
max_length = max(max_length, right - left);
}
if (right >= fruits.size()) break;
// 右边界类型不在able数组内
if (able[0][0] == able[1][0]) {
// 当able数组内只有一种类型的元素时,改一下就可以了
able[0][0] = fruits[right];
} else {
// 如果此时右边界的水果种类不在able数组内,
// 如果able数组内已经有两种别的类型的元素时,需要完全消去其中一种元素
int now_left;
exit(able, fruits[left], now_left);
int temp = 0; // 找到左边界水果的种类在able数组内的下标
do {
// 将左边界移动到不含该种类型水果的时刻
++left;
--able[now_left][1];
if (able[now_left][1] == 0) break;
} while (exit(able, fruits[left], now_left) && temp == now_left);
able[now_left][0] = fruits[right];
able[now_left][1] = 1;
}
}
delete[] able[0]; // 释放第一个数组的内存
delete[] able[1]; // 释放第二个数组的内存
delete[] able; // 释放指针数组的内存
return max_length;
}
};
题解:
class Solution {
public:
int totalFruit(vector<int>& fruits) {
int n = fruits.size(); // 获取水果数组的长度
unordered_map<int, int> cnt;// 创建一个哈希表,用于记录每种水果的计数
//左边为键,右边是该键对应的值
int left = 0; // 左边界的起始位置
int max_length = 0;
for (int right = 0; right < n; ++right) {
// 根据右边界的移动,统计出滑动窗口中有几种种类水果的树
++cnt[fruits[right]];//将键为fruits[right]的值加1
while (cnt.size() > 2) {// 当哈希表中的水果种类超过两种时,需要调整左边界,直到窗口内只有两种类型的水果
//cnt.size()返回键值对的数量(这里即为种类即该种类有的果树的数量)
auto temp = cnt.find(fruits[left]); // 找到左边界对应的水果的种类
// find()函数用于查找指定键是否存在于容器中,并返回指向该键的迭代器。
// 如果找到了键,则返回指向该键值对的迭代器;如果没有找到,则返回指向容器末尾的迭代器,即end()。
--temp->second; // 减少该种水果的计数
//temp->second表示获取迭代器指向的键值对的值
++left; // 减少一个,左边界需向右移动一个
if (temp->second == 0) cnt.erase(temp);// 如果该水果的计数减少到了0,则从哈希表中删除该键值对
}
max_length = max(max_length, right - left + 1);
}
return max_length; // 返回最大水果数
}
};
自己手码
class Solution {
public:
int totalFruit(vector<int>& fruits) {
unordered_map<int,int> cnt;//创建hash表
int left=0,right=0;
int max_length=0;
while(right<fruits.size()){
++cnt[fruits[right]];//直接根据水果种类录入哈希表内,若表内不存在,那么创建,后值加1;若存在,则直接加1。
while(cnt.size()>2){//若水果种类超过两种,则需从左边进行删去,直到完全去除一种水果才停止
cnt[fruits[left]]--;
if(cnt[fruits[left]]==0)
//若此时left指针指向的水果种类减少到0,即消除该水果种类的键值对
cnt.erase(fruits[left]);
left++;//指向下一个元素
}
max_length=max(max_length,right-left+1);
right++;
}
return max_length;
}
};
(3)最小覆盖子串
https://leetcode.cn/problems/minimum-window-substring/description/
my_code:暴力求解
class Solution {
public:
string minWindow(string s, string t) {
if (t.size() > s.size() || s.size() == 0) return "";
unordered_map<char, int> cnt;
for (char i: t) ++cnt[i];//先将t中的内容录进哈希表内
int min_length = INT_MAX;
string ans;
int left = 0;//从s字符串左边开始找
while (left < s.size()) {
if (cnt.count(s[left]) == 0) ++left;
//count()可用来盘对岸该键是否存在于哈希表中
//如果键存在于哈希表中,则返回 1,表示该键出现了一次。
//如果键不存在于哈希表中,则返回 0,表示该键没有出现。
else {
//如果在t字符串内有该字符,那就可以从该处开始试一试
unordered_map<char, int> temp = cnt;
int right = left;
while (right < s.size()) {
if (temp.count(s[right])) {
if (--temp[s[right]] == 0) temp.erase(s[right]);
if (temp.empty()) {//如果找到的话
if (right - left + 1 < min_length) {
min_length = right - left + 1;
ans = s.substr(left, min_length);
// substr从一个字符串中提取子字符串。它接受两个参数:起始索引和子字符串的长度(可选)。
// 如果省略第二个参数,则提取从起始索引到字符串的末尾的子字符串。
break;
}
}
}
++right;
}
++left;//这个不满足,故需继续往前走
}
}
return ans;
}
};
题解:
滑动窗口
class Solution {
public:
string minWindow(string s, string t) {
if (s.size() < t.size() || s.empty()) return "";
// 存储 t 中每个字符出现的次数
unordered_map<char, int> tMap;
for (char i : t) tMap[i]++;
int left = 0, right = 0;
int minWindowLength = INT_MAX;
int minWindowStart = 0;
int tNum = t.size(); // 需要的字符数
unordered_map<char, int> nowWindowMap; // 当前窗口中各字符的出现次数
while (right < s.size()) {
// 左边固定移动右边,扩展窗口(移动右指针)
char c = s[right];
nowWindowMap[c]++;//将所有的字符都先加入当前窗口内,再进行下面的操作
// 只有当 当前字符是 t 中的字符,并且在当前窗口中出现次数不超过 t 中的次数(保证是缺少的字符)
if (tMap.find(c) != tMap.end() && nowWindowMap[c] <= tMap[c]) {
tNum--;
}
//直到right指针移动到,当前窗口完全包含t后,才开始缩小窗口
// 缩小窗口(移动左指针)
while (left <= right && tNum == 0) {
// 更新最小窗口的信息
if (right - left + 1 < minWindowLength) {
minWindowLength = right - left + 1;
minWindowStart = left;
}
// 收缩窗口
char leftChar = s[left];
nowWindowMap[leftChar]--;//nowWindowMap的该字符串数量减少
//只有当移除的字符串(leftChar)是属于t的,才进行下面操作,释放一个空间
//当left指向的的字符在t内,且当前窗口该字符的数量小于t中该字符的数量时才把空间释放
if (tMap.find(leftChar) != tMap.end() && nowWindowMap[leftChar] < tMap[leftChar]) {
tNum++;
}
left++;// 缩小窗口(移动左指针)
}
right++;//扩展窗口(移动右指针)
}
return minWindowLength == INT_MAX ? "" : s.substr(minWindowStart, minWindowLength);
}
};
5.螺旋数组(循环不变量原则)
坚持循环不变量原则
模拟顺时针画矩阵的过程:
- 填充上行从左到右
- 填充右列从上到下
- 填充下行从右到左
- 填充左列从下到上
画一条边都要坚持一致的左闭右开,或者左开右闭的原则,这样这一圈才能按照统一的规则画下来。
那么我按照左闭右开的原则,来画一圈,大家看一下:

这里每一种颜色,代表一条边,我们遍历的长度,可以看出每一个拐角处的处理规则,拐角处让给新的一条边来继续画。
这也是坚持了每条边左闭右开的原则。
(1)螺旋数组Ⅱ
https://leetcode.cn/problems/spiral-matrix-ii/description/
my_code:
class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
vector<vector<int>> ans(n, vector<int>(n, 0));
int loop = n / 2;//循环次数,就是走几圈
//n为偶数时,走n/2圈;n为奇数时,走(n-1)/2圈,最后只用看中心点就可以了
if(n%2==1){//n为奇数时,中心点单看,中心点值最大
ans[loop][loop]=n*n;
}
int width=0,hight=0;//更新当前起始位置
int count=0;//计数
//坚持一个原则,左闭右开
while(loop){
int i=width,j=hight;
while(i == width && j<n-1){//右
ans[i][j]=++count;
j++;
}
while(i < n-1 && j == n-1){//下
ans[i][j]=++count;
i++;
}
while(i == n-1 && j > hight){//左
ans[i][j]=++count;
j--;
}
while(i > width && j == hight){//上
ans[i][j]=++count;
i--;
}
width++;hight++;//改变下一轮的起始位置
loop--;
n--;//外面一层以及走完,n减1
}
return ans;
}
};
(2)螺旋数组
https://leetcode.cn/problems/spiral-matrix/description/
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
// 处理特殊情况,空矩阵
if (matrix.size() == 0) return {};
int row = matrix.size();//行
int col = matrix[0].size();//列
vector<int> ans(row * col);
int index = -1;//ans数组的下标
int left = 0, right = col - 1; // 定义左右边界
int top = 0, bottom = row - 1; // 定义上下边界
//保持左闭右开的原则
while(left <= right && top <= bottom){
for(int i =left ; i <= right ;++i){//右,top不变
ans[++index]=matrix[top][i];
}
for(int i = top+1 ; i <= bottom ;++i){//下,right不变
ans[++index]=matrix[i][right];
}
//因为行和列不相等,所以可能会出现最终独行和独列,如果是独行或独列的话下面两个循环代码就不用运行了
if(top < bottom){//判断是否需要第二行
for(int i =right-1 ; i >= left ;--i){//左,bottom不变
ans[++index]=matrix[bottom][i];
}
}
if(left < right){//判断是否需要第二列
for(int i = bottom-1 ; i > top ;--i){//上,left不变
//这里之所以不是i>=top,为了保证转一圈没有覆盖开始的位置
ans[++index]=matrix[i][left];
}
}
left++;right--;
top++;bottom--;
}
return ans;
}
};
补充:
(1)vector和array的区别
在C++中,vector 和 array 是两种不同的容器,它们各自有不同的特性和用途。
- 动态性与静态性:
vector是一个动态数组,它的长度可以在运行时改变,可以随意地添加或删除元素,它会自动处理内存的分配和释放。array是一个固定大小的数组,其长度在编译时就已经确定,且在运行时不能改变其大小。
- 内存分配:
vector的内存通常是在堆上分配的,这意味着当vector的空间不足以容纳更多元素时,它会重新分配一块更大的内存,并将原有元素复制过去。array可以在栈上分配,也可以在堆上分配,但其大小固定,不会像vector那样自动重新分配内存。
- 性能:
- 由于
vector需要处理内存的动态分配,它的某些操作(如添加元素时可能触发的重新分配)可能比array慢。 array的访问速度通常比vector快,因为没有动态内存管理的开销。
- 由于
- 接口:
vector提供了丰富的接口,如push_back,pop_back,insert,erase等,用于动态修改其内容。array的接口相对较少,它主要提供对固定大小数组的访问和迭代器支持。
- 类型安全:
array的尺寸是类型的一部分,这意味着array<int, 5>和array<int, 10>是不同的类型,这有助于防止一些类型错误。vector不将尺寸作为类型的一部分,所有的vector<int>都是同一类型,无论它们的大小如何。
- 标准库支持:
vector是标准模板库(STL)的一部分,自C++98以来就有了。array是在C++11中引入的,它提供了类似STL容器的接口,但具有固定大小。
选择vector还是array取决于你的具体需求。如果你需要一个可以动态改变大小的数组,那么vector是更好的选择。如果你知道数组的大小在编译时就已经确定,并且永远不会改变,那么array可能是更有效、更安全的选择。
vector的底层实现是array,严格来讲vector是容器,不是数组。
数组的元素是不能删的,只能覆盖。
(2)二维数组在内存的空间地址是连续的么?
C++中:
在C++中,二维数组在内存中的存储有两种常见的方式:行优先(row-major)和列优先(column-major)。C++标准没有明确规定使用哪一种方式,这取决于具体的编译器和实现。
行优先(Row-major):如果数组是行优先的,那么在内存中,二维数组的元素是按行存储的,即第一行的所有元素先存储,然后是第二行,依此类推。这意味着在同一行内的元素地址是连续的。
列优先(Column-major):如果数组是列优先的,那么在内存中,二维数组的元素是按列存储的,即第一列的所有元素先存储,然后是第二列,依此类推。
无论采用哪种方式,整个二维数组的所有元素在内存中都是连续存储的,只是连续的方式不同。这意味着你可以像处理一维数组一样遍历二维数组的元素,而不需要担心内存中存在间隙。
Java中:
在Java中,二维数组实际上是一维数组的数组。这意味着一个二维数组是由多个一维数组组成的,每个一维数组都可以包含多个元素。在内存中,这些一维数组是连续存储的,但是它们之间的连接可能不是连续的。
当你创建一个二维数组时,例如:
int[][] matrix = new int[3][4];
你实际上创建了三个一维数组,每个一维数组包含4个整数。在内存中,这三个一维数组是连续存储的,但是每个一维数组之间的连接可能不是连续的。这是因为每个一维数组都是一个对象,而对象在Java中是通过指针(或者引用)来访问的。因此,即使一维数组在内存中是连续的,二维数组的行之间的连接是由这些指针提供的,而不是直接的内存地址。
在Java中,二维数组的存储可以看作是一个“数组的数组”,其中每一行都是一个独立的一维数组。这意味着如果你访问一个二维数组的元素 matrix[i][j],Java会首先通过第一级索引 i 找到对应的一维数组,然后再通过第二级索引 j 访问该一维数组中的元素。
由于二维数组是由一维数组组成的,所以如果你更改了其中一个一维数组的引用(例如,将一行赋值给另一行),那么你实际上是在更改引用,而不是复制数组的数据。这可能会导致意外的行为,因为两个不同的行引用可能最终指向同一个一维数组。
总之,Java中的二维数组在内存中是由一维数组组成的,这些一维数组是连续存储的,但是二维数组的行之间的连接是由引用(指针)提供的,而不是直接的内存地址。
三.链表(虚拟头节点)
1.链表理论基础
循环链表可以用来解决约瑟夫环问题。
链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
(1)链表的定义
// 单链表
struct ListNode {
int val; // 节点上存储的元素
ListNode *next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数
};
如果不定义构造函数也是可以的,C++默认生成一个构造函数。但是这个构造函数不会初始化任何成员变量,下面两个例子:
- 通过自己定义构造函数初始化节点:
ListNode* head = new ListNode(5);
- 使用默认构造函数初始化节点:
ListNode* head = new ListNode();
head->val = 5;
所以如果不定义构造函数使用默认构造函数的话,在初始化的时候就不能直接给变量赋值!
(2)链表的操作
**删除节点:**将被删除节点的前一个节点指向,被删除节点的下一个节点,然后手动释放当前被删除节点。(是这样的,所以在C++里最好是再手动释放这个D节点,释放这块内存。其他语言例如Java、Python,就有自己的内存回收机制,就不用自己手动释放了。)
(3)性能分析
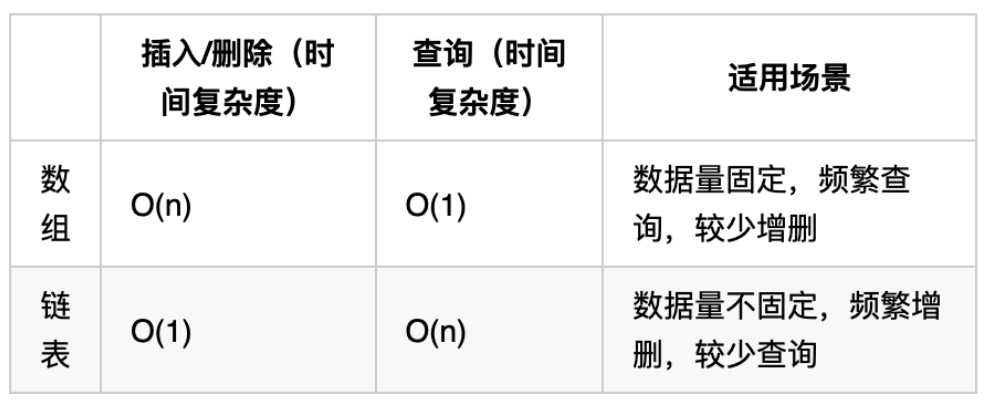
数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删, 适合数据量不固定,频繁增删,较少查询的场景。
2.移除链表元素
https://leetcode.cn/problems/remove-linked-list-elements/submissions/516239608/
法一:直接使用原来的链表来进行移除节点操作
- 时间复杂度: O(n)
- 空间复杂度: O(1)
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
// 删除头节点
// 从头开始看,如果前面有一样的,就删除,保证head始终指向链表的头部,且结束时head的val肯定不为val
while (head != nullptr && head->val == val) {
ListNode* tmp = head;
head = head->next;
delete tmp;
}
//删除后续节点
ListNode *temp=head;
while(temp!= nullptr && temp->next != nullptr){
if(temp->next->val==val){
ListNode* tmp = temp->next;
temp->next=temp->next->next;
delete tmp;
}
else temp=temp->next;
}
return head;
}
};
法二:设置一个虚拟头结点在进行移除节点操作:
- 时间复杂度: O(n)
- 空间复杂度: O(1)
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
dummyHead->next = head; // 将虚拟头结点指向head,这样方便后面做删除操作
ListNode* cur = dummyHead; // 虚拟头指针不动,让一个指针指向虚拟指针动
while (cur->next != NULL) {
if(cur->next->val == val) {
ListNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
}
else cur = cur->next;
}
head = dummyHead->next;
delete dummyHead;
return head;
}
};
3.设计链表
https://leetcode.cn/problems/design-linked-list/description/
- 时间复杂度: 涉及
index的相关操作为 O(index), 其余为 O(1) - 空间复杂度: O(n)
class MyLinkedList {
public:
// 定义链表节点结构体
struct LinkedNode {
int val;
LinkedNode* next;
// 构造函数初始化列表,作用是在对象构造时直接初始化成员变量,而不是在构造函数的函数体内部进行赋值。
// 这样可以提高效率,特别是对于成员变量是常量或者引用类型的情况,因为这样可以避免了两次赋值。
// val(val)表示将参数val的值赋给结构体的val成员变量
LinkedNode(int val):val(val), next(nullptr){}
};
// 初始化链表
MyLinkedList() {
_dummyHead = new LinkedNode(0); // 这里定义的头结点 是一个虚拟头结点,而不是真正的链表头结点
_size = 0; // 链表的长度
}
// 获取到第index个节点数值,如果index是非法数值直接返回-1, 注意index是从0开始的,第0个节点就是头结点
int get(int index) {
if (index >= _size || index < 0) return -1;// 下标超过index或者比0还小
LinkedNode* cur = _dummyHead->next; // cur指向head
while(index--) cur = cur->next; // 找到第index个元素
return cur->val;
}
// 在链表最前面插入一个节点,插入完成后,新插入的节点为链表的新的头结点
void addAtHead(int val) {
LinkedNode* newNode = new LinkedNode(val);
newNode->next = _dummyHead->next;
_dummyHead->next = newNode;
_size++;
}
// 在链表最后面添加一个节点
void addAtTail(int val) {
LinkedNode* newNode = new LinkedNode(val);
LinkedNode* cur = _dummyHead;
while(cur->next != nullptr) cur = cur->next;//找到最后一个元素的位置
cur->next = newNode;
_size++;
}
// 在第index个节点之前插入一个新节点,例如index为0,那么新插入的节点为链表的新头节点。
void addAtIndex(int index, int val) {
if(index > _size) return; // 如果index大于链表的长度,则返回空
if(index < 0) index = 0; // 如果index小于0,则在头部插入节点
LinkedNode* newNode = new LinkedNode(val);
LinkedNode* cur = _dummyHead;
while(index--) cur = cur->next;//找到该节点的位置
//插入
newNode->next = cur->next;
cur->next = newNode;
_size++;
}
// 删除第index个节点,如果index 大于等于链表的长度,直接return,注意index是从0开始的
void deleteAtIndex(int index) {
if (index >= _size || index < 0) return;
LinkedNode* cur = _dummyHead;
while(index--) cur = cur ->next;//找到第index节点的前一个节点的位置
//将目标节点删除(cur->next)
LinkedNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
//delete命令指示释放了tmp指针原本所指的那部分内存,
//被delete后的指针tmp的值(地址)并非就是NULL,而是随机值。也就是被delete后,
//如果不再加上一句tmp=nullptr,tmp会成为乱指的野指针
//如果之后的程序不小心使用了tmp,会指向难以预想的内存空间
tmp=nullptr;
_size--;
}
// 打印链表
void printLinkedList() {
LinkedNode* cur = _dummyHead;
while (cur->next != nullptr) {
cout << cur->next->val << " ";
cur = cur->next;
}
cout << endl;
}
private:
int _size;
LinkedNode* _dummyHead;
};
(1)class中public和private的用法和区别
在C++中,public和private是两个访问修饰符,它们用于定义类成员(属性和方法)的访问权限。这两个关键字的作用是实施封装,即隐藏对象的内部细节,仅暴露出必要的接口与外界交互。
1.public(公有)
public成员在类的内部和外部都可以被访问。- 公有成员通常是类的接口部分,用于允许外部代码与类的对象进行交互。
- 例如,一个银行的账户类可能会提供一个公有的
deposit方法,允许用户存款。
2.private(私有)
private成员仅在类的内部可以被访问,外部代码无法直接访问私有成员。- 私有成员通常包含类的实现细节,如数据成员和仅用于类内部的方法。
- 例如,账户类可能会将账户余额作为一个私有成员,以防止外部代码直接修改它。
3.用法示例
class Account {
private:
double balance; // 私有属性,外部不能直接访问
public:
void deposit(double amount) { // 公有方法,外部可以调用
balance += amount;
}
double getBalance() const { // 公有方法,外部可以调用
return balance;
}
};
在这个例子中,balance是私有成员,因此外部代码不能直接读取或修改账户余额。相反,必须通过公有的deposit和getBalance方法来操作余额。
4.区别
- 访问权限:
public成员可以在类的内部和外部访问,而private成员只能在类的内部访问。 - 封装:
private关键字用于隐藏类的实现细节,保护数据不被非法访问和修改,public关键字用于定义类的接口。 - 设计原则:合理使用
public和private可以帮助遵循面向对象编程的封装原则,使得代码更加健壮和安全。
5.设计考虑
合理地划分公有和私有成员是良好面向对象设计的关键。通常,你应该将尽可能多的成员设置为私有,仅暴露必要的接口作为公有。这样可以减少类之间的耦合,使得代码更加模块化,易于维护和扩展。同时,私有成员的改变不会影响到使用该类的其他代码,因为它们对外是不可见的。
4.反转链表
https://leetcode.cn/problems/reverse-linked-list/description/
法一:使用一个数组,将val放在数组内,然后创建一个链表,依次加
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {//使用一个数组,将val放在数组内,然后创建一个链表,依次加
if(head==nullptr) return nullptr;
int a[5000]={-10000};
ListNode* p=head;int length=0;
//遍历链表,赋值数组,求链表长度
while(p!=nullptr){
a[length++]=p->val;
p=p->next;
}
ListNode* new_head=new ListNode(a[--length]);
ListNode* cur=new_head;
int j=1;
while(length){
ListNode* temp=new ListNode(a[--length]);
cur->next=temp;
cur=cur->next;
}
return new_head;
}
};
法二:创建个虚拟头指针,指向当前头节点,然后一直使用头插法
class Solution {
public:
ListNode* reverseList(ListNode* head) {
if(head==nullptr) return nullptr;
ListNode* virtual_head=new ListNode(0);
virtual_head->next=new ListNode(head->val);
ListNode* temp=head->next;
while(temp!=nullptr){//头插
ListNode* new_head=new ListNode(temp->val);
new_head->next=virtual_head->next;
virtual_head->next=new_head;
temp=temp->next;
}
return virtual_head->next;
}
};
题解:
(1)双指针法
首先定义一个cur指针,指向头结点,再定义一个pre指针,初始化为null。
然后就要开始反转了,首先要把 cur->next 节点用tmp指针保存一下,也就是保存一下这个节点。
为什么要保存一下这个节点呢,因为接下来要改变 cur->next 的指向了,将cur->next 指向pre ,此时已经反转了第一个节点了。
接下来,就是循环走如下代码逻辑了,继续移动pre和cur指针。
最后,cur 指针已经指向了null,循环结束,链表也反转完毕了。 此时我们return pre指针就可以了,pre指针就指向了新的头结点。
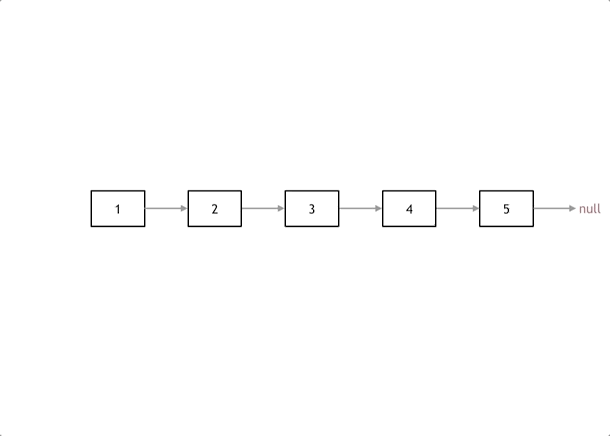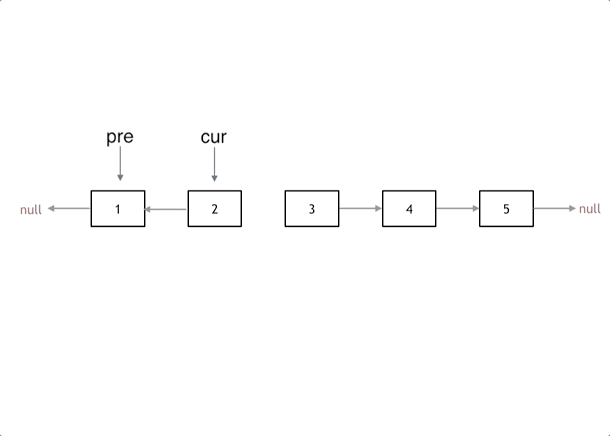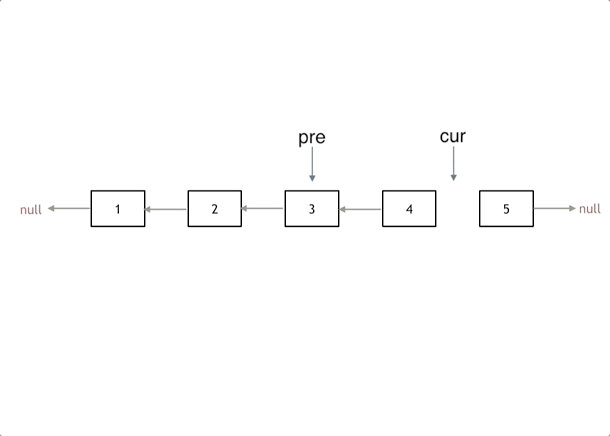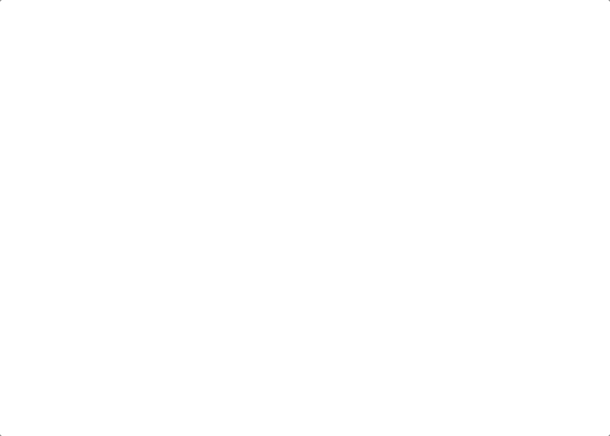
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* temp; // 保存cur的下一个节点
ListNode* cur = head;
ListNode* pre = NULL;
while(cur) {
temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
// 翻转操作
cur->next = pre;
// 更新pre 和 cur指针
pre = cur;
cur = temp;//cur继续回到cur的下一个继续操作
}
return pre;
}
};
(2)递归法
递归法相对抽象一些,但是其实和双指针法是一样的逻辑,同样是当cur为空的时候循环结束,不断将cur指向pre的过程。
关键是初始化的地方,可能有的同学会不理解, 可以看到双指针法中初始化 cur = head,pre = NULL,在递归法中可以从如下代码看出初始化的逻辑也是一样的,只不过写法变了。
class Solution {
public:
ListNode* reverse(ListNode* pre,ListNode* cur){
if(cur == NULL) return pre;
ListNode* temp = cur->next;
cur->next = pre;
// 可以和双指针法的代码进行对比,如下递归的写法,其实就是做了这两步
// pre = cur;
// cur = temp;
return reverse(cur,temp);
}
ListNode* reverseList(ListNode* head) {
// 和双指针法初始化是一样的逻辑
// ListNode* cur = head;
// ListNode* pre = NULL;
return reverse(NULL, head);
}
};
5.两两交换链表中的节点
https://leetcode.cn/problems/swap-nodes-in-pairs/description/
(1)利用虚拟头节点
利用虚拟头节点指向head,然后三个三个节点进行操作,保证cur(当前指针)指向要操作的指针的前一个位置,这样方便操作。
- 时间复杂度: O(n)
- 空间复杂度: O(1)
struct ListNode {
int val;
ListNode *next;
ListNode() : val(0), next(nullptr) {}
ListNode(int x) : val(x), next(nullptr) {}
ListNode(int x, ListNode *next) : val(x), next(next) {}
};
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
//要下面两个节点是否都存在,如果都存在才能交换,如果不存在,那么就不用交换
if(head==nullptr) return nullptr;
if(head->next== nullptr) return head;
// 设置一个虚拟头结点
ListNode* dummyHead = new ListNode(0);
dummyHead->next=head;
//当前节点
ListNode* cur=dummyHead;
while(cur->next!= nullptr&&cur->next->next!= nullptr){
//交换
ListNode* temp_left=cur->next;
ListNode* temp_right=cur->next->next;
ListNode* temp_right_right=cur->next->next->next;
cur->next=temp_right;
temp_left->next=temp_right_right;
temp_right->next=temp_left;
cur=cur->next->next;
}
ListNode* result = dummyHead->next;
delete dummyHead;
return result;
}
};
(2)递归法
- 时间复杂度: O(n)
- 空间复杂度: O(1)
class Solution {
// 定义:输入以 head 开头的单链表,将这个单链表中的每两个元素翻转,
// 返回翻转后的链表头结点
public:
ListNode* swapPairs(ListNode* head) {
if (head == nullptr || head->next == nullptr) { //递归结束条件
return head;
}
ListNode* first = head;
ListNode* second = head->next;
ListNode* others = head->next->next;
// 先把前两个元素翻转
second->next = first;
// 利用递归定义,将剩下的链表节点两两翻转,接到后面
first->next = swapPairs(others);
// 现在整个链表都成功翻转了,返回新的头结点
return second;
}
};
6.删除链表的倒数第N个节点
(1)暴力遍历法
https://leetcode.cn/problems/remove-nth-node-from-end-of-list/description/
- 时间复杂度: O(n)
- 空间复杂度: O(1)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
if(head==nullptr) return nullptr;
int length=0;//记录链表的的长度
ListNode* temp=head;
while (temp!= nullptr){
length++;
temp=temp->next;
}
//如果长度小于n返回nullptr
if(length<n) return nullptr;
//利用虚拟头节点,实现当前指针无论如何都可指向被修改指针的前面
ListNode* virtual_head=new ListNode(0);
virtual_head->next=head;
ListNode* cur=virtual_head;
//找到当前被删除指针的前一个指针
int a=n;
while (a < length){
cur=cur->next;
a++;
}
//cur指向要删元素的前一个
if(cur->next->next == nullptr) cur->next= nullptr;
else cur->next=cur->next->next;
ListNode* result=virtual_head->next;
delete virtual_head;
return result;
}
};
(2)双指针
双指针的经典应用,如果要删除倒数第n个节点,让fast移动n步,然后让fast和slow同时移动,直到fast指向链表末尾。删掉slow所指向的节点就可以了。
只用走一趟就行了
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
//用头指针是为了删除第一个
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* right=dummyHead;
ListNode* left=dummyHead;
//right != nullptr保证head为空和n大于链表长的情况
while(n>0 && right != nullptr){
right=right->next;
n--;
}
//保证left指向要删除指针的前一个位置
while(right->next!= nullptr){
right=right->next;
left=left->next;
}
left->next=left->next->next;
return dummyHead->next;
}
};















 5069
5069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









