







 本文介绍了Java中常用的集合类如List、Set、Map及其具体实现,接口与抽象类的概念和区别,HashMap的数据存储、扩容机制和hashcode、equals的作用。接着探讨了ConcurrentHashMap在JDK1.7和1.8中的线程安全实现。此外,还讲解了Spring的IOC和AOP机制,以及SpringBean的生命周期。最后,涉及JVM内存划分、事务特性、数据库索引和Redis的持久化策略。
本文介绍了Java中常用的集合类如List、Set、Map及其具体实现,接口与抽象类的概念和区别,HashMap的数据存储、扩容机制和hashcode、equals的作用。接着探讨了ConcurrentHashMap在JDK1.7和1.8中的线程安全实现。此外,还讲解了Spring的IOC和AOP机制,以及SpringBean的生命周期。最后,涉及JVM内存划分、事务特性、数据库索引和Redis的持久化策略。
1. java中常用的集合有哪些
java中常用的集合类有List,Set,Map,其中List和Set继承了Collection。
List的实现类有:ArrayList,LinkedList,Vector,Stack
Set的实现类有:TreeSet,HashSet
Map的实现类有:TreeMap,HashMap
注意:Queue是一个接口,继承Collection,由LinkedList实现。而Stack是一个实现类。
2. 接口和抽象类的定义,以及他们的区别
抽象类是对根源的抽象,而接口是对动作的抽象。
如果你要表示这个对象是什么,那就用抽象类,比如:男人和女人,他们的共性就是“人”,即可以抽象出来一个“人”的抽象类,然后让“男人”和“女人”继承他们就行。
如果要表示这个对象能干什么,那就用接口,比如:“吃饭”这个动作,人可以吃饭,狗也可以吃饭,所以就可以将"吃饭"作为一个接口,然后让其他的类去实现它就行。
抽象类的使用成本是比接口要大,因为抽象类要定义出子类的所有共性。而接口可以单独的定义一个动作。
其他具体的区别: 接口和抽象类的区别
3. HashMap数据的存储和扩容机制
3.1 存储过程:
- 先判断可以是否已经存在,如果存在就进行更行,如果不存在就进行下一步
- 将数据先进行存储
- 判断是否超过负载因子,超过的话就进行扩容,然后重新hash。
- 如果链表长度大于8并且桶的容量超过64,那就将链表进行树化,变成红黑树。
3.2 扩容机制
在Java当中,HashMap底层是由数组+链表+红黑树实现的。
桶的默认大下是16,负载因子是0.75,树化条件是:链表长度大于8并且桶的容量超过64。
即:
- 当初始化一个HashMap时,它的容量初始为0,当第一次插入元素时,他才会进行内存的分配,数组容量就变成16。
- 随着元素的插入,如果usedSize*1.0/ array.length>=DEFAULT_LOAD_FACTOR,那就进行扩容,即桶的个数变为原来的2倍。
3.3 扩展内容——hashMap当中的hashcode和equals的作用
HashMap确定下标位置
euuals判断key是否一样
在向HashMap中插入对象元素的时候,要对对象元素的hashcode和equals方法进行重写。
链接: HashMap原码分析
4. ConcurrentHashMap如何保证线程的(1.7和1.8)
4.1 jdk1.7中的ConcurrentHashMap
jdk1.7中的ConcurrentHashMap数据结构模型如下:
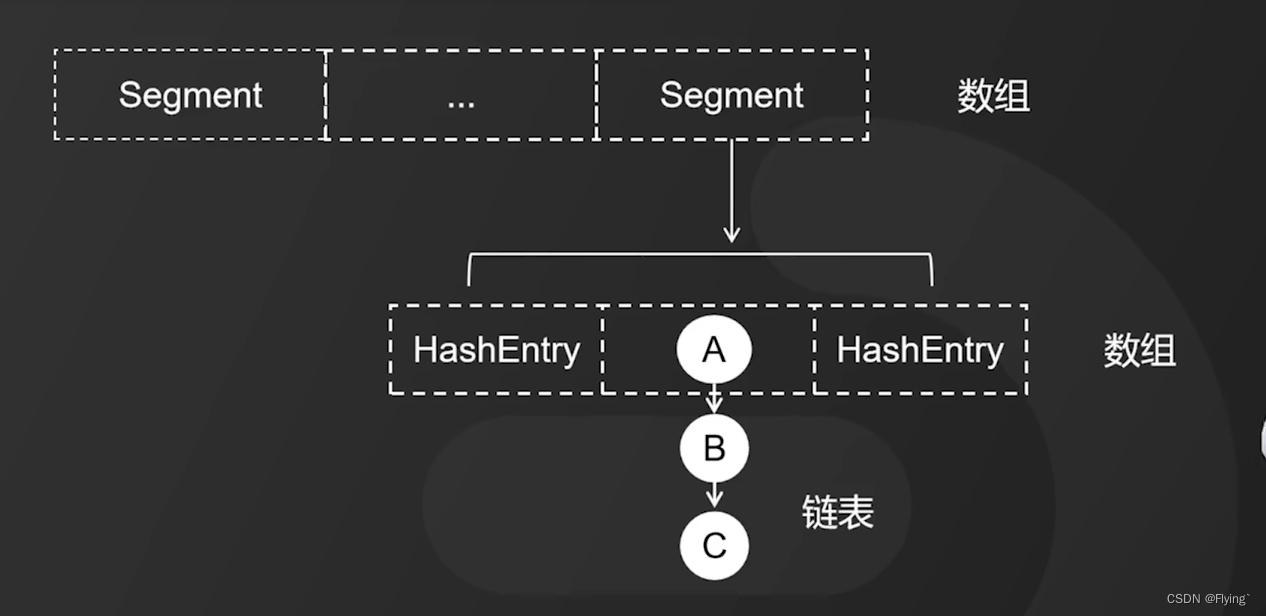
它是用 数组(Segment)+数组(HashEntry)+链表 的形式进行存储数据,在发送冲突时,他将用ReentrantLock锁对Segment数组元素进行上锁。
源码如下:
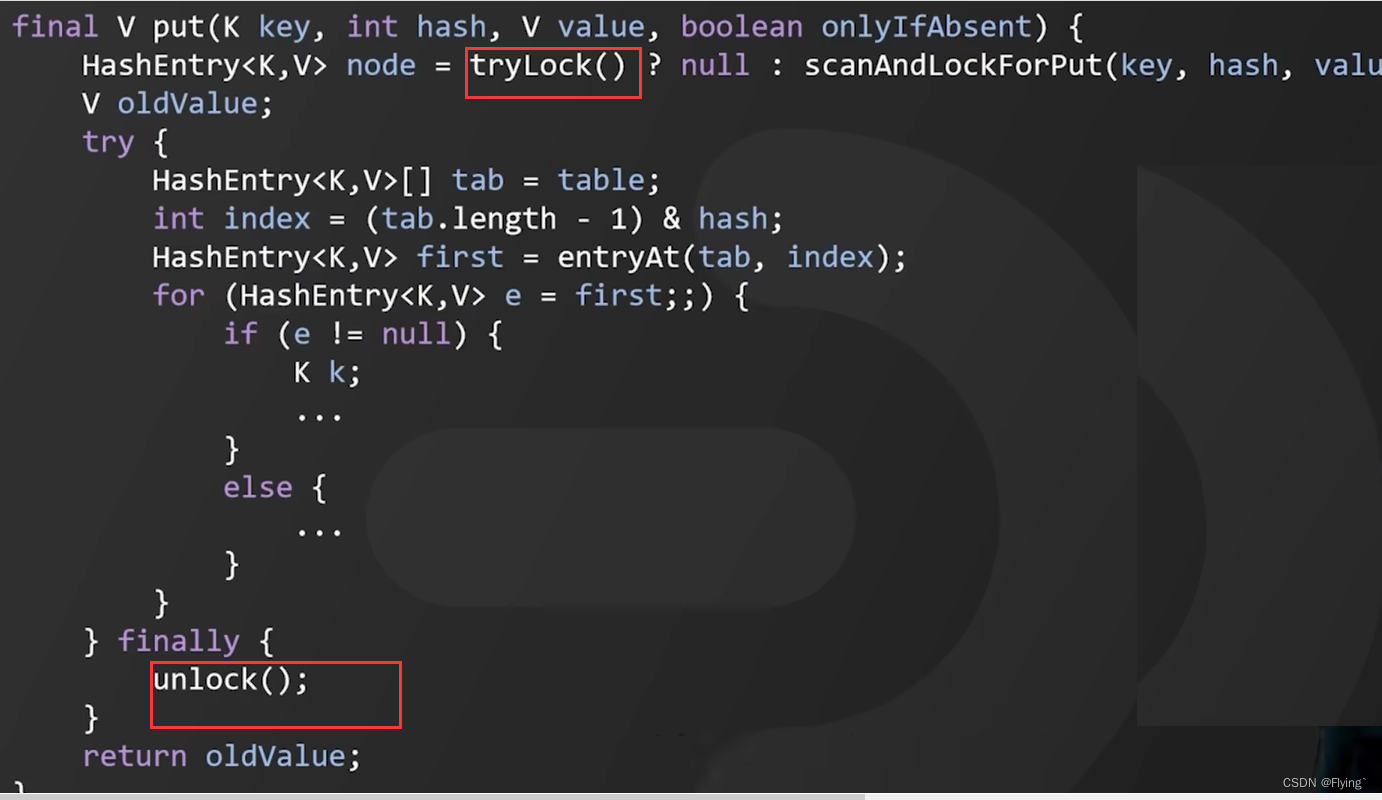
4.2 jdk1.8中的ConcurrentHashMap
jdk1.8中的ConcurrentHashMap数据结构模型如下:
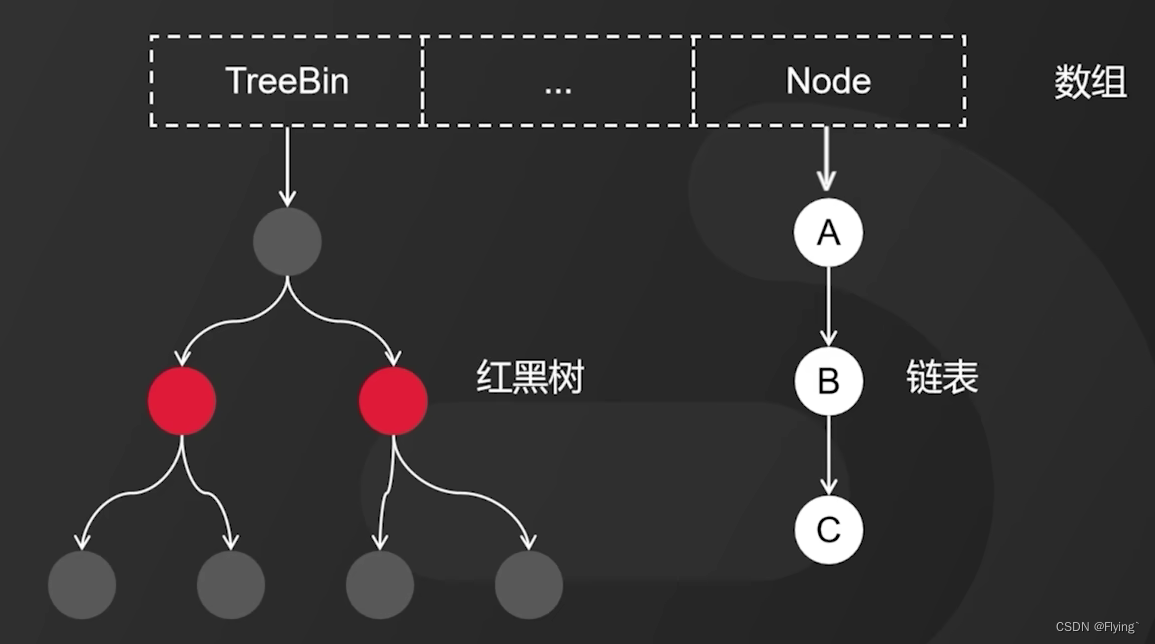
它采用数组+链表+红黑树的形式进行数据的存储。
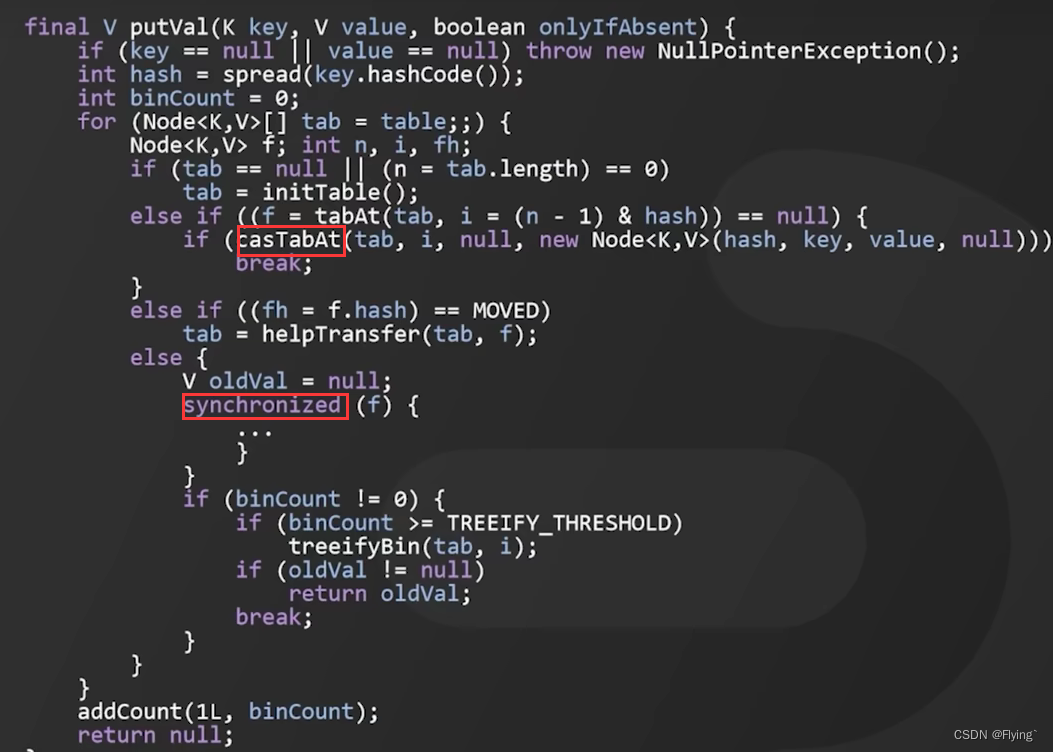
- 首先他会判断容器是否为空,为空的化,他就会采用CAS+volatile来进行初始化
- 当容器不为空,就根据存储的元素计算该位置是否为空。如果为空,就用CAS来设计该节点;如果不为空,就用synchronsized进行加锁
源码如下:
4.3 区别总结
- jdk1.7当中对Segment加锁是一种锁分段技术,而jdk1.8当中是对头节点进行加锁,它的粒度更小,发生冲突的概率也就更小。
- jdk1.7 用ReentrantLock锁对Segment来实现线程安全
- jdk1.8 用CAS和synchronsized来实现线程安全
5. Spring IOC 和 AOP
5.1 Spring IOC
- IOC就是控制反转,是指创建对象的控制权的转移。在Spring当中,可以将创建对象的控制权交给Spring容器,然后由容器根据配置文件去创建和管理各个实例之间的依赖关系。实现的手段有:DI依赖注入。
- 给人最直观的感觉就是:IOC让对象的创建不再需要去new,可以由Spring自动产生,使用Java反射机制,根据配置文件在Java运行时动态的去创建对象以及管理对象,并调用对象的方法。
- 实现方式有:构造器注入,setter注入,注解注入(Autowried,Resource)
作用:IOC的使用使得代码的耦合度降低
5.2 Spring AOP
- AOP即面向切面编程。与业务模块无关,但是为业务模块所共同调用的逻辑和责任提供统一的处理(事务处理,日志管理,权限控制 ),减少了系统的重复代码,降低了代码的耦合度。比如:事务处理,日志管理,权限控制
- SpringAOP是基于动态代理的,他有两种代理方式:JDK和CGlib。如果代理的对象实现了某个接口,那它就是用JDK动态的去创建对象,如果代理的对象没有实现某个接口,那它就是用CGlib动态的去创建对象。
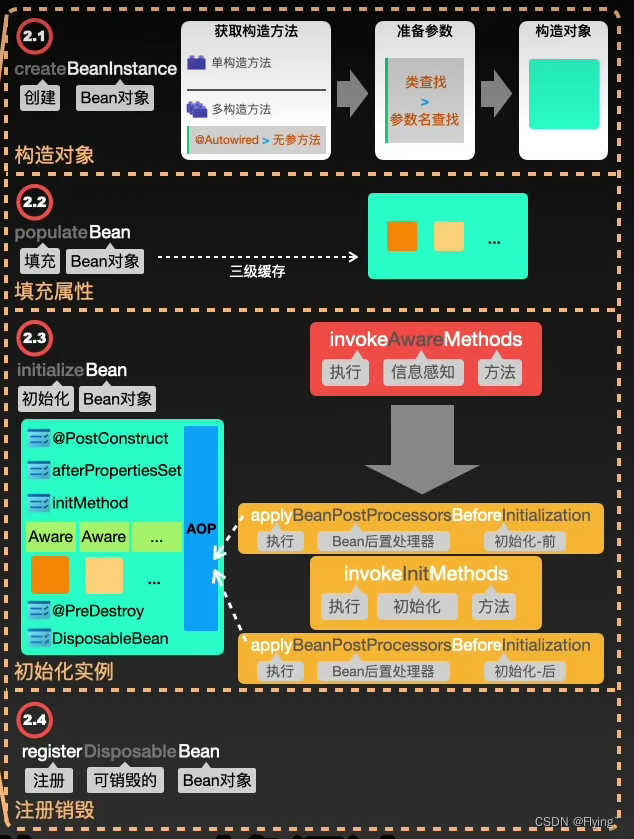
6. Spring Bean的生命周期
- 产生
- 启动,准备容器
- 加载bean定义——扫描xml、注解,将定义的bean一个个先找到,然后放入Spring的一个容器集合当中
- createBean——构造对象,填充属性,初始化实例,注册销毁
初始化则是将程序的执行权,从系统级别转换到用户级别,并开始执行用户添加的业务代码。- 用addSingleton方法将加载完的bean对象放入单例池,就可以被获取和使用了。
-
使用
-
销毁
- 执行@PreDestory注解的方法
- 执行destoryBeans注意销毁所有的bean
- 执行自定义的destoryMethod方法
7. JVM内存划分
JVM内存可划分为4个部分:分别是堆区,栈区,方法区和程序计数器。
堆区:存放new的对象
栈区:存放方法之间的调用关系,以及局部变量
方法区:存放类对象
程序计数器:相当于书签,存放下一条要执行的指令
8. 堆内存的老年代和新生代,以及分代算法的各个区的算法
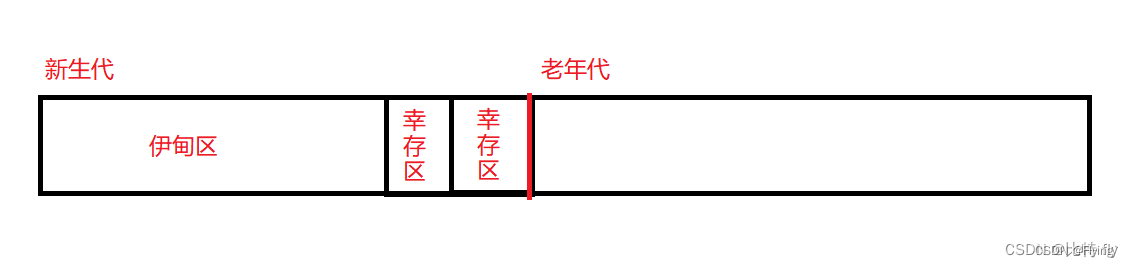
- 新创建出来的对象,先放在伊甸区。
- 伊甸区的绝大部分对象都活不过一轮GC,活过一轮的对象就被复制(复制算法)到幸存区,这里需要复制的对象不多,所以幸存区不需要很大。
- 幸存区里面的对象,又会经历第二次GC,每一轮都会淘汰一些对象,幸存的对象被复制到另一个幸存区。这个过程既保留了复制算法的高效,无内存碎片的优势,同时也没有浪费太多的内存空间。
- 幸存区里面的对象,经历过几轮的GC之后,如果然后没被淘汰,就可以放到老年区当中。
- 老年区里面的对象,仍然会接受GC的洗礼,但是频率大大降低,此时就接受用标记-整理算法带来的效率问题。
9. 索引的分类,聚簇索引和主键索引在查询数据时的区别
索引一般有主键索引,唯一性索引,普通索引和组合索引,比较常用的就是主键索引和联合索引。
当一个表中有主键时,聚簇索引和主键索引是没有区别的;但是如果一个表中没有主键时,聚簇索引和主键索引就不一样了,因为这时的聚簇索引就依靠唯一性键或者6字节的row_id生成。
10. 主键索引和非主键索引的叶子节点在存储上有什么区别
11. 事务的特性,事务的隔离级别,mvcc的原理
11.1 事务的特性
- 原子性
- 一致性
- 持久性
- 隔离性
11.2 事务的隔离级别
- 读未提交
- 读已提交
- 可重复读
- 串行化
12. 不可重复读和幻读的区别
不可重复读强调的是:两次查找,结果不同是因为修改数据
幻读强调的是:两次查找,结果不同是因为新增数据
13. rdb和aof,redis断电后缓存会丢失,所以持久化到磁盘上,重启的时候,持久化文件是如何加载的?
rdb是指将内存中某一时刻的数据快照全量写入到指定的 rdb 文件的持久化技术。RDB 持久化默认是开启的。当 Redis 启动时会自动读取 RDB 快照文件,将数据从硬盘载入到内存,以恢复 Redis 关机前的数据库状态
aof是指 Redis 将每一次的写操作都以日志的形式记录到一个 AOF文件中的持久化技术。当需要恢复内存数据时,将这些写操作重新执行一次,便会恢复到之前的内存数据状态
14. 类加载机制
类加载分为三个步骤:
- 记载:将java字节码文件加载到内存中
- 连接
- 验证:验证加载的文件是否符合JVM的规范
- 准备:为类变量赋予零值,类变量如果被final修饰则直接赋予定义的值
- 解析:将符号引用转化为直接引用
- 初始化:为类变量赋值,为成员变量赋零值,执行静态代码块
15. @Autowried和@Resource的区别
- 来源不同:@Autowried来源于Spring框架,而@Resource来源于java。
- 依赖的查询顺序不一样: @Autowried先按照Type再按Name查询,而@Resource先按照Name再按Type查询。
- 支持的参数不一样:@Autowired 只支持设置 1 个参数,而 @Resource 支持设置 7 个参数;
- 依赖注入的方法支持不同:@Autowried支持构造方法注入、属性注入、setter注入;而 @Resource 只支持属性注入和setter注入
默认情况下,@Autowired 按类型装配 Spring Bean。如果容器中有多个相同类型的 bean,则框架将抛出 NoUniqueBeanDefinitionException, 以提示有多个满足条件的 bean 进行自动装配。z怎么解决这个问题,可参考: Spring 注解 @Qualifier 详细解析

















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









