







离散特征处理
1 离散特征
离散特征(Discrete Feature)是指在数据集中表现为离散值的特征,通常这些特征是分类数据,可以是数字也可以是非数字的标识符。
离散特征可以是二元的(如性别:男/女),也可以是多类别的(如血型:A型、B型、AB型、O型),或者是有序的(如教育水平:小学、中学、大学等)。
2 离散特征处理
-
建立字典:把类别映射成序号。
中国 → 1
美国 → 2
印度 → 3 -
向量化:把序号映射成向量。
One-hot编码:把序号映射成高维稀疏向量。
Embedding:把序号映射成低维稠密向量。
3 One-Hot 编码
One-Hot 编码是一种将类别变量转换为机器学习算法可以更好处理的形式的方法。在这种编码方式中,每个类别值都会被转换成一个二进制向量,除了表示该类别的一个位置是1之外,其余位置都是0。
例1:性别特征

例2:国籍特征

One-Hot 编码的局限
-
例1:自然语言处理中,对单词做编码。
-
英文有几万个常见单词。
-
那么 one-hot 向量的维度是几万。
-
-
例2:推荐系统中,对物品ID做编码。
-
小红书有几亿篇笔记。
-
那么 one-hot 向量的维度是几亿。
-
类别数量太大时,通常不用 one-hot 编码。
更常见的做法是 Embedding,即把每一个类别映射成一个低维的稠密向量。
4 Embedding(嵌入)
Embedding 是一种将离散特征映射到连续向量空间的技术。Embedding 可以捕捉特征之间的复杂关系,并在低维空间中表示高维数据,从而使得机器学习模型能够更好地处理和理解这些数据。
例1:国籍的 Embedding
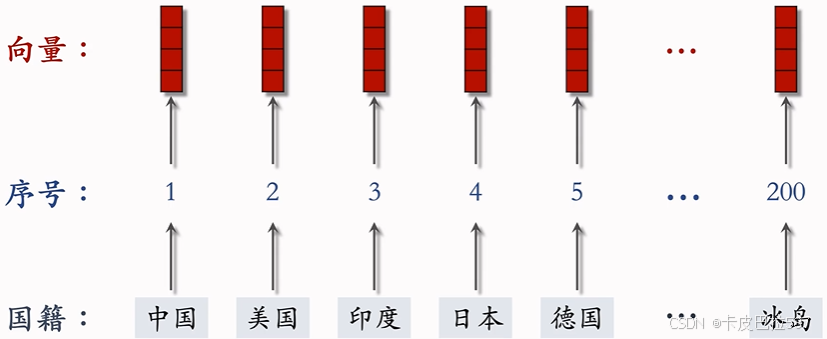
-
参数数量:向量维度 × 类别数量。
-
设 embedding 得到的向量都是 4 维的。
-
一共有 200 个国籍。
-
参数数量 = 4 × 200 = 800。
-
-
编程实现:TensorFlow、PyTorch 提供 embedding 层。
-
参数以矩阵的形式保存,矩阵大小是向量维度 × 类别数量。
-
输入是序号,比如“美国”的序号是 2。
-
输出是向量,比如“美国”对应参数矩阵的第 2 列。
-
例2:物品ID的 Embedding

如果类别的数量不大,只有几百万,那么 Embedding 层的实现是比较容易的,TensorFlow 和 PyTorch 都可以处理的很好。
但如果类别数量特别大,比如推荐系统中的物品数量有几十亿,那么 Embedding 层会特别大,一个神经网络绝大多数的参数都在 Embedding 层。所以工业界深度学习系统都会对 Embedding 层做很多优化。这是存储和计算效率的关键所在。
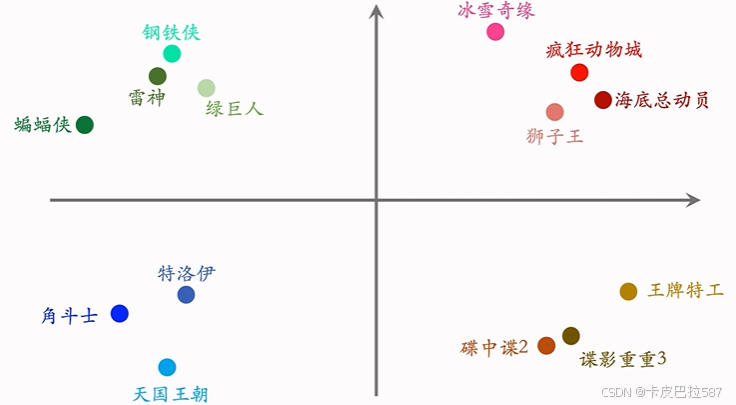
用示意图来说明 Embedding 得到的向量的物理意义。
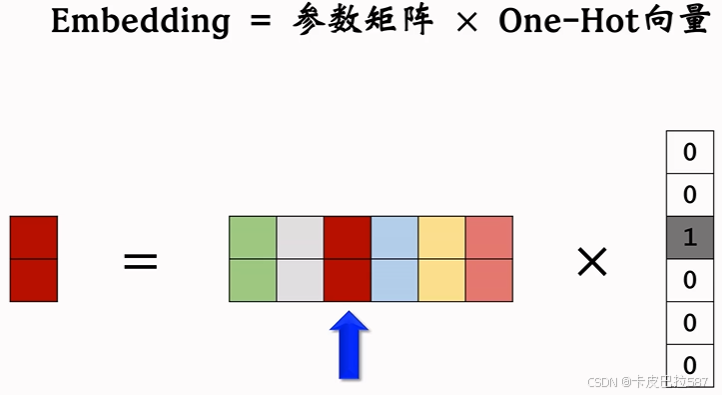
Embedding 和 One-Hot 编码之间的关系
5 总结
-
离散特征处理:one-hot 编码、embedding。
-
类别数量很大时,用 embedding。
-
Word embedding。
-
用户 ID embedding。
-
物品 ID embedding。
-

















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









