







 本文介绍基于扩散的盲超分辨模型SR3+,结合参数化退化和噪声调节增强进行自监督训练。实验表明,SR3+在多个数据集上优于SR3和Real - ESRGAN,在更大数据集训练可进一步提升性能,但使用噪声调节增强时存在故障模式,需更多训练步骤收敛。
本文介绍基于扩散的盲超分辨模型SR3+,结合参数化退化和噪声调节增强进行自监督训练。实验表明,SR3+在多个数据集上优于SR3和Real - ESRGAN,在更大数据集训练可进一步提升性能,但使用噪声调节增强时存在故障模式,需更多训练步骤收敛。
深度学习论文分享(七)Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild
前言
论文原文:https://arxiv.org/abs/2302.07864
论文代码:
Title:Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild
Authors:Hshmat Sahak, Daniel Watson, Chitwan Saharia, David Fleet
在此仅做翻译
Abstract
扩散模型在单幅图像的超分辨率和其他图像到图像的转换任务中显示出很好的结果。尽管取得了成功,但它们在更具挑战性的盲超分辨率任务上的表现并没有超过最先进的GAN模型,在盲超分辨率任务中,输入图像没有分布,并且存在未知的退化。
本文介绍了一种基于扩散的盲超分辨模型SR3+,建立了一种新的技术。为此,我们提倡将自监督训练的复合、参数化退化和训练和测试过程中的噪声调节增强相结合进行自监督训练。通过这些创新,大规模卷积架构和大规模数据集,SR3+大大优于SR3。在相同的数据上训练时,它优于RealESRGAN, DRealSR的FID得分为36.82和37.22,在更大的模型上进一步提高到32.37的FID,在更大的训练集上进一步提高。
1. Introduction
扩散模型((Sohl-Dickstein et al., 2015; Song& Ermon, 2019; Ho et al., 2020; Song et al., 2020)已经迅速成为一类强大的生成模型,推进了文本到图像合成和图像到图像翻译任务的最新技术 (Dhariwal& Nichol, 2021; Rombach et al., 2022; Saharia et al.,2022a;c; Li et al., 2022).。对于单幅超分辨率图像,撒哈拉等人(2022c)利用自监督扩散模型捕捉复杂的多模态分布的能力,在具有大放大系数的超分辨率任务中表现出很强的性能。虽然令人印象深刻,但SR3在非分布(OOD)数据(即未知退化的野外图像)上存在不足。因此,gan仍然是盲超分辨的首选方法(Wang et al ., 2021b)。

图1所示。盲超分辨率测试结果(64×64->256×256)用于SR3+, SR3和Real-ESRGAN。
本文介绍了一种新的基于扩散的超分辨率模型SR3+,它既灵活又鲁棒,可以在OOD数据上获得最先进的结果(图1)。为此,SR3+结合了简单的卷积架构和具有两个关键创新的新颖训练过程。受Wang等人(2021b)的启发,我们在数据增强训练管道中使用参数化退化,与(撒哈拉等人,2022c)相比,在生成低分辨率(LR)训练输入时明显更复杂。我们将这些退化与噪声调节增强相结合,首先用于提高级联扩散模型(Ho等人(2022))的鲁棒性。我们发现噪声调节增强在测试时对于零射击应用也是有效的。当在相同的数据上训练时,使用类似大小的模型,SR3+在fid10k上优于SR3和Real-ESRGAN,并应用于RealSR (Cai et al ., 2019)和DRealSR (Wei et al ., 2020)数据集上的零射击测试。我们还通过增加模型容量和训练集大小来进一步改进。
我们的主要贡献如下:
-
我们引入了SR3+,一种用于盲图像超分辨率的扩散模型,在不同模型和训练集大小的RealSR和DRealSR基准测试中优于SR3和以前的SOTA。
-
通过仔细的消融实验,我们证明了参数退化和噪声调节增强技术的互补优势(后者也在测试时使用)。
-
我们证明了随着模型尺寸的增加和数据集的增加(在我们的实验中有多达61M的图像),SR3+性能有了显著的改善。
2. Background on Diffusion Models
生成扩散模型被训练以一种允许从模型本身计算样本的方式来学习数据分布。这是通过首先训练去噪模型来实现的。在实践中,给定一个(可能是有条件的)数据分布
q
(
x
∣
c
)
q(x|c)
q(x∣c),构造一个高斯前向过程。
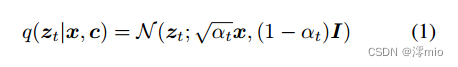
式中
α
t
α_t
αt是单调递减函数,
t
∈
[
0
;
1
]
t\in[0;1]
t∈[0;1],通常固定在
α
0
≈
1
α_0≈1
α0≈1和
α
1
≈
0
α_1≈0
α1≈0。在每个训练步骤中,给定一个随机的
t
∼
U
n
i
f
o
r
m
(
0
;
1
)
t \sim Uniform(0;1)
t∼Uniform(0;1),神经网络
x
θ
(
z
t
,
t
,
c
)
x_θ(z_t,t,c)
xθ(zt,t,c)必须学会将有噪声信号
z
t
z_t
zt映射到原始(无噪声)
x
x
x。Ho等人(2020)表明,在实践中效果良好的损失函数是重新加权的证据下界(Kingma & Welling, 2013):
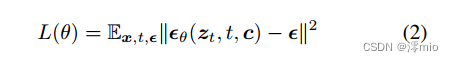
神经网络学习推断附加噪声
ϵ
\epsilon
ϵ,而不是图像本身。然后恢复图像是微不足道的,因为我们可以使用Eqn. 1的重新参数化技巧(Kingma & Welling, 2013)来获得
x
θ
=
1
α
t
(
z
t
−
1
−
α
t
ϵ
θ
)
x_θ = \frac{1}{\sqrt{\alpha_t}}(z_t-\sqrt{1-\alpha_t}\epsilon_\theta)
xθ=αt1(zt−1−αtϵθ)
训练后,我们从最大噪声水平
t
=
1
t = 1
t=1的高斯噪声开始,即
z
1
N
(
0
,
I
)
z_1 ~ N (0,I)
z1 N(0,I),然后对噪声信号进行迭代细化,通过反复计算,逐步衰减噪声,放大信号
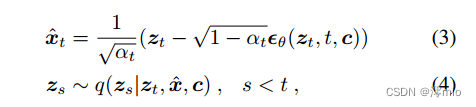
Ho et al .(2020)表明
q
(
z
s
∣
z
t
,
x
,
c
)
q(z_s|z_t,x,c)
q(zs∣zt,x,c)可以在
s
<
t
s < t
s<t时以封闭形式得到。为了进行
t
t
t次去噪采样,我们通常选择
s
s
s为
T
−
1
T
\frac{T - 1}{T}
TT−1,然后为
T
−
2
T
\frac{T - 2}{T}
TT−2,以此类推,直到s = 0。在最后一个去噪步骤中,我们省略了再次添加噪声的步骤,并简单地将最终的
x
^
\hat{x}
x^作为我们的样本。
对于单幅图像的超分辨率,我们使用条件扩散模型。数据分布
q
(
x
;
c
)
q(x;c)
q(x;c)由高分辨率(HR)图像x和相应的低分辨率(LR)图像c组成.
3. Related Work
盲超分辨率的两种一般方法包括显式(Shocher等人,2018;Liang等,2021;Yoo等人,2022)和隐式(Patel等人,2021;Yan et al ., 2021)退化建模。隐式退化建模需要学习退化过程;然而,这需要大型数据集才能很好地推广(Liu et al ., 2021)。文献中最好的结果采用显式退化建模,其中退化直接作为训练期间的数据增强。Luo et al . (2021);Wang等人(2021a)在对原始HR图像进行降采样之前先应用模糊,然后对降采样结果添加噪声并应用JPEG压缩,从而产生增强条件反射图像c。RealESRGAN模型(Wang等人,2021b)表明,多次应用这种退化方案会导致LR分布更接近于野外图像的LR分布。这些降解方案对于基于gan的方法实现最先进的结果至关重要。
除gan之外的其他超分辨率方法包括扩散模型,甚至更简单的非生成模型。SRCNN (Dong et al ., 2015)的初步工作表明,深度卷积神经网络优于简单的双三次或双线性上采样。Dong et al . (2016);Shi等人(2016)通过学习本身执行图像上采样的CNN,提高了这些结果的效率。此后,进一步的架构和训练创新被发现通过残差连接加深神经网络(Kim等人,2016a;Lim等人,2017;Ahn et al, 2018)和其他架构(Fan et al, 2017;Kim et al ., 2016b;Tai等,2017;Lai et al ., 2017)。对比学习也被应用于超分辨率(Wang et al ., 2021a;Yin et al, 2021)。基于注意力的网络已经被提出(Choi & Kim, 2017;Zhang et al, 2018);然而,我们仍然选择探索一个全卷积模型,因为它可以更好地推广到未知的分辨率(Whang et al, 2022)。
最近在超分辨率方面的工作已经证明了图像条件扩散模型的潜力(撒哈拉等人,2022c;Li et al, 2022),这些模型被证明优于基于回归的模型,后者不能生成尖锐和多样化的样本(Ho et al, 2022;撒哈拉等人,2022b)。扩散模型的一个优点是它们能够捕捉视觉世界的复杂统计数据,因为它们可以推断出远远超出LR输入范围的结构。在放大倍率较大的情况下,这一点尤其重要,因为许多不同的HR图像可能与单个LR图像一致。相比之下,GAN模型经常与模式崩溃作斗争,从而减少了多样性(Thanh-Tung & Tran, 2020)。
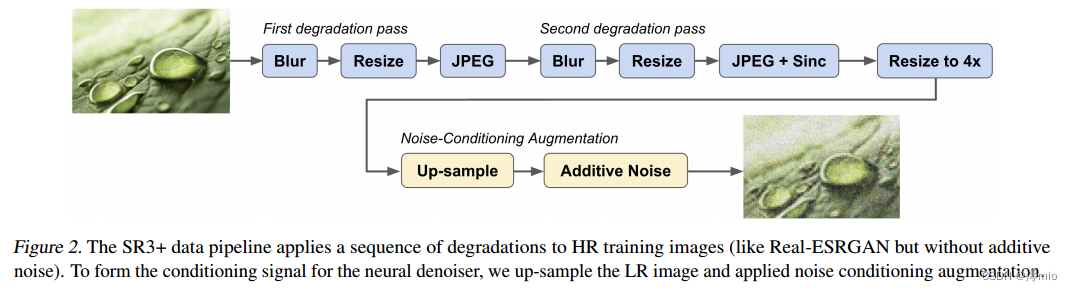
图2。SR3+数据管道对HR训练图像应用一系列退化(类似于Real-ESRGAN,但没有附加噪声)。为了形成神经去噪的调节信号,我们对LR图像进行上采样并进行噪声调节增强。
4. Methodology
SR3+是一种盲、单图像超分辨率的自监督扩散模型。它的架构是SR3中使用的卷积变体,因此在图像分辨率和宽高比方面更加灵活。在训练过程中,通过对高分辨率图像进行降采样,得到LR-HR图像对,生成相应的低分辨率输入。鲁棒性是通过两个关键增强来实现的,即训练期间的复合参数退化(Wang et al, 2021b;a)和噪声调节增强(Ho et al, 2022),这两个增强都是在训练和测试时进行的,如下所述。
4.1. Architecture
遵循撒哈拉等人(2022c), SR3+使用UNet架构,但没有SR3使用的自关注层。虽然自我关注对图像质量有积极的影响,但它使得对不同图像分辨率和长宽比的推广非常困难(Whang et al, 2022)。我们还采用了撒哈拉等人使用的修改(2022b),以提高训练速度。下面我们将缩小架构的大小,展示更大模型的性能优势。
4.2. Higher-order degradations
超分辨率的自我监督需要对HR图像进行下采样,以获得相应的LR输入。理想情况下,我们可以将下采样核与我们期望在实践中看到的其他退化结合起来。否则,在训练和测试之间可能会发生域转移,因此对野外图像的零概率泛化很差。可以说,这是SR3失效的关键点,其结果在图1所示的ODD测试数据中是显而易见的。
SR3+使用数据增强管道进行训练,该管道包括多种类型的退化,包括图像模糊,附加噪声,JPEG压缩和下采样。而在超分辨率训练管道中使用多参数变形是很常见的(Zhang等人,2021;Wang et al ., 2021a), Wang et al . (2021b)发现,应用重复的变形序列(称为高阶变形)对OOD泛化有实质性的影响。为了简单性和与RealESRGAN的可比性,SR3+使用了相同的降解管道,但没有附加噪声(见图2)。从经验上看,我们在初步实验中发现,噪声调节增强(稍后解释)比在降解管道中包含噪声更好。在与Real-ESRGAN相同的数据集上训练400M参数模型,但使用降噪而不是噪声调节增强,我们获得了42.58的FID(10k)分数(vs。36.28,见表1)。为了完整起见,我们现在记录所有的退化超参数。这些数据应该与Wang等人(2021b)使用的数据相匹配。
模糊。使用了四种模糊滤波器,即高斯滤波器、广义高斯滤波器、基于平台的核滤波器和sinc滤波器(选择概率分别为0.63、0.135、0.135和0.1)。高斯分布有可能是各向同性的,否则是各向异性的。高原核是各向同性的,概率为0:8。当各向异性时,核在(−π)内旋转任意角度;π)。对于各向同性核,σ 2 [0:2;握)。对于各向异性核,σx;σy 2 [0:2;握)。内核半径r在3到11像素之间是随机的(只有奇数值)。对于自滤波模糊,wc随机从[π=3;当r <6时,从[π=5];否则π)。对于广义高斯函数,形状参数β从[0:5;4:0];它是从[1:0;2:0]用于平台滤波器。第二模糊以0.2的概率被省略;σ 2 [0:2;1:5)。
调整。图像以三种(等概率)方式之一调整大小,即区域调整大小,双三次插值或双线性插值。比例因子在[00:15]中是随机的;1:5]为第一阶段调整尺寸,在[0:3;[1:2]第二个。
JPEG压缩。JPEG质量因子随机抽取[30;95]。在第二阶段,我们还应用了一个sinc过滤器(如上所述),在JPEG压缩之前或之后(概率相等)
经过两个阶段的退化,如图2所示,使用双三次插值将图像调整到原始HR图像和LR退化图像之间所需的放大倍数。SR3+被训练为4倍放大。
4.3. Noise Conditioning Augmentation
噪声调节首先用于级联扩散模型(Ho et al, 2022;撒哈拉等人,2022b)。它的引入是为了使级联中的超分辨率模型可以进行下采样的自监督,而在测试时它将接收来自级联中前一个模型的输入。噪声调节增强为前一阶段的输入分布提供了鲁棒性,即使每个阶段都是独立训练的。虽然退化管道应该已经提高了鲁棒性,但很自然地要问,是否还可以通过包括这种技术来实现进一步的鲁棒性。
本质上,噪声调节增强需要在上采样LR输入中添加噪声,但也为神经去噪器提供噪声水平。在训练时,对于小批量中的每个LR图像,它需要
-
样品τ ~均匀(0;τmax)。 Sample τ ∼ Uniform(0; τmax).
-
重新利用扩散正演过程的边际分布,加入噪声得到$cτ ~ q(zτ jc)。Add noise to get cτ ∼ q(zτ jc), reusing the marginal
distribution of the diffusion forward process. -
将模型条件化为cτ而不是c,并且我们还将模型条件化为(位置嵌入)τ。Condition the model on cτ instead of c, and we also
condition the model on (a positional embedding of) τ .
该模型学习处理不同噪声水平 τ τ τ下的输入信号。在实践中,我们设 τ m a x = 0 : 5 τ_{max} = 0:5 τmax=0:5;超过这个值,输入信噪比过低,无法有效训练。
在测试时,噪声调节增强中的噪声级超参数teval提供了与LR输入对齐和生成模型产生幻觉之间的权衡。随着时间的增加,更多的高频细节丢失,因此模型被迫更多地依赖于其对自然图像的了解,而不是条件反射信号本身。我们发现,这使逼真的纹理和视觉细节的幻觉。
5. Experiments
SR3+在多个数据集上使用退化和噪声调节增强相结合的方法进行训练,并对测试数据应用零射击。我们使用消融来确定不同形式的增强、模型大小和数据集大小的影响。在这里,我们关注的是具有4倍放大系数的盲超分辨率任务。对于基线,我们使用SR3(撒哈拉等人,2022c)和以前最先进的盲超分辨率,即RealESRGAN (Wang等人,2021b)。
与SR3一样,LR输入采用双三次插值上采样4倍。SR3和SR3+的输出样本使用DDPM祖先采样(Ho et al, 2020), 256步去噪。为了简单和连续时间步长训练,我们使用Ho & Salimans(2022)引入的余弦对数信噪比调度。
训练。为了与Real-ESRGAN进行公平的比较,我们首先在用于训练Real-ESRGAN的数据集上训练SR3+ (Wang et al ., 2021b);即DF2K+OST (Agustsson & Timofte, 2017), Div2K(800张图片)、Flick2K(2650张图片)和OST300(300张图片)的组合。为了探索缩放的影响,我们还在61M图像的大型数据集上进行训练,将内部图像集合与DF2K+OST相结合
在训练期间,遵循Real-ESRGAN,我们为每个图像提取随机400×400裁剪,然后应用退化管道(图2)。然后将退化图像调整为100×100(用于4倍放大)。然后使用双三次插值将LR图像上采样到400× 400,从中中心作物产生256×256图像,用于训练64×64 !256×256的任务。由于模型是卷积的,我们可以在测试时将其应用于任意分辨率和长宽比
对于下面的结果,SR3+和所有烧蚀都是在具有相同超参数的相同数据上进行训练的。注意,当去除退化和噪声调节增强时,SR3+减少到SR3。所有模型训练1.5M步,在DF2K+OST上训练的模型使用256个批次,在其他情况下使用512个批次。我们还考虑了两种型号尺寸,重量分别为40M和400M。较小的可以直接与Real-ESRGAN进行比较,Real-ESRGAN也有大约40M个参数。更大的模型揭示了模型缩放的影响。

图3。Real-ESRGAN与各种SR3+模型(我们的)的样本比较。我们观察到Real-ESRGAN经常遭受过度平滑和过度对比度的困扰,而SR3+能够生成高保真度,逼真的纹理。
测试。对于测试,如上所述,我们专注于zero - shot应用程序来测试与用于训练的数据集不相交的数据集。在所有实验和消融中,我们使用RealSR (Cai et al ., 2019) v3和DRealSR (Wei et al ., 2020)数据集进行评估。RealSR有400张配对的低分辨率和高分辨率图像,从中我们计算每对图像25个随机但对齐的64×64和256×256作物。这将产生一个固定的10,000个图像对的测试集。DRealSR包含超过10,000对图像,因此我们转而为10,000张随机图像提取64×64和256×256中心作物。
结合PSNR、SSIM (Wang et al ., 2004)和FID (10k) (Heusel et al ., 2017)对模型性能进行评估。虽然基于参考的指标(如PSNR和SSIM)对于较小的放大因子很有用,但在放大倍数为4倍或更大的情况下,特别是在测试中使用生成模型和噪声调节增强时,后验分布是复杂的,与回归模型相比,人们期望输出具有显着的多样性。
对于具有多模态后验的SR任务,例如,在更大的放大倍数下,基于参考的指标与人类的偏好不太一致。虽然模糊图像往往会使真实的RMSE最小化,但人类观察者对它们的评分更低(Chen等人,2018;Dahl等人,2017;Menon et al, 2020;撒哈拉等人,2022c)。特别是PSNR和SSIM倾向于过度惩罚可信但推断出的高频细节,这些细节可能与地面真实图像不完全一致。然而,我们认为重建指标对于评估SR模型仍然很重要,因为它们奖励对齐,这是一个理想的属性(特别是在高频细节较少的区域)。
除了PSNR和SSIM,我们还报告了FID,它在足够大的数据集上提供了与地面真实图像数据类似的汇总统计度量。这与人类素质评估有更好的相关性。由于生成模型被应用于更困难的输入,或者有大量的NCA或更大的放大,我们将需要更多地依赖FID和类似的措施。因为在这种情况下,我们将依靠模型推理来捕获自然图像的状态,这需要一个更大的模型,因为生成模型很难学习。所以人们会期望更大的数据和更大的模型会表现得更好。
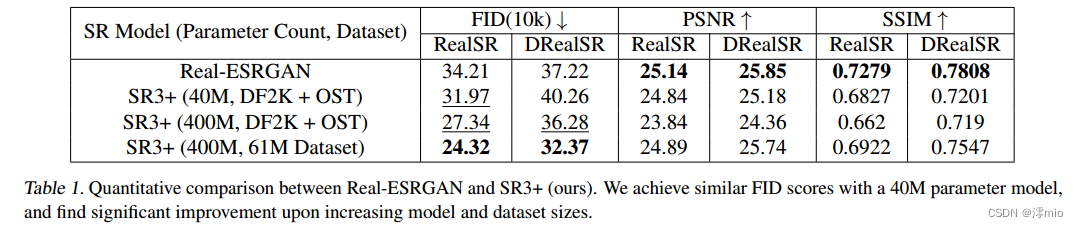
表1。Real-ESRGAN与SR3+的定量比较。我们使用40M参数模型获得了类似的FID分数,并在增加模型和数据集大小时发现了显着的改进。

表2。RealSR和DRealSR试验装置上SR3+的烧蚀研究。请注意,将这两个组件都剔除将产生SR3模型。
5.1. Comparison with Real-ESRGAN and SR3
如前所述,我们将不同尺寸的SR3+模型与Real-ESRGAN模型进行了比较,Real-ESRGAN是之前最先进的盲超分辨率模型,它们都是在相同的数据上训练的。此外,为了在一般情况下获得最好的结果,我们将在上述数据上训练的最佳SR3+模型与在更大的61m图像数据集上训练的相同模型进行比较(并且批处理大小是前者的两倍)。为了进行评估,我们对从0到0.4的teval执行网格扫描,增量为0.05,并报告teval = 0:1的结果,我们始终认为这是最佳值。我们在图3中提供了并排比较,并在表1中显示了定量结果。
我们发现,在40m参数的网络中,SR3+达到了与Real-ESRGAN竞争的FID分数,在RealSR上取得了更好的分数,但在DRealSR上略差。从质量上讲,它创造了更逼真的纹理,没有明显的过度平滑或饱和,但对于某些类型的图像,我们关心的是准确的高频细节,比如带有文本的图像,它做得更差。使用400m参数的SR3+模型,结果和图像的真实感显著提高,在相同的数据集上训练时,在FID分数上优于Real-ESRGAN,并且通过在更大的数据集上训练,这种差距进一步扩大。在后一种情况下,早期模型(例如文本情况)的一些失效模式也得到了缓解,并且粗糙的纹理在图像中更加连贯。我们在补充材料中提供了额外的样品。
SR3+在基于参考的指标(PSNR, SSIM)上的表现并不好,稍微差一些,但这是由具有更大放大因子或更大噪声调节增强(其中生成模型被迫推断更多细节)的强生成模型所期望的。之前的研究也表明了这一点(Chen et al ., 2018;Dahl等人,2017;Menon et al, 2020;撒哈拉等人,2022c)。我们在图4和表2所示的样本中进行了经验验证,其中值得注意的是,SR3获得了更好的PSNR和SSIM分数,但该模型在盲任务中产生了模糊的结果。在从64x64开始的4倍放大任务中,p(xjc)可能是非常多模态的(特别是在高频细节上),这些指标过度惩罚了看似合理但令人产生幻觉的高频细节。

图4。消融样本(teval = 0:1),说明了高阶退化和噪声调理增强的重要性。
5.2. Ablation studies
我们现在通过经验证明了我们的主要贡献的重要性,我们记得:(1)高阶退化方案和(2)噪声调节增强。我们使用我们最强的模型进行消融研究,即在61m图像数据集上训练的400m参数SR3+模型,因为较差的模型在去除上述组件后会更严重地破坏。我们训练了与我们最强的SR3+模型相似的模型:一个没有噪声调节增强,一个没有高阶退化,另一个两者都没有(这相当于SR3模型,尽管使用的是UNetv3架构(撒哈拉等人,2022b),并且数据集比原始作品更大)。然后,我们比较盲SR任务上的FID、PSNR和SSIM。每当使用噪声条件增强时,我们设置teval = 0:1。结果见表2,样本比较见图4。
我们的结果表明,在移除我们的任何一个主要贡献后,FID分数显着增加(在所有情况下都超过10分)。并且,在去除两者后,FID分数更差,因为该指标在野外应用于非分布图像时惩罚了SR3的一致性模糊。我们还观察到,特别是在没有高阶退化的情况下,我们还观察到一些模糊和重建指标的轻微改善。在SR3模型中,从质量上看,它在几代中受到模糊的影响最大,但PSNR和SSIM都得到了显著改善,而且,有趣的是,它在指标和评估数据集上的表现都足以超过Real-ESRGAN。
5.3. Noise conditioning augmentation at test time
回想一下,由于使用了噪声调节增强,我们在采样时引入了一个我们可以自由使用的自由度。直观地看,使用teval = 0似乎是最合适的,因为添加噪声会从调节低分辨率输入中删除一些信息。然而,根据经验,我们发现使用非零值通常可以获得更好的结果;特别是在图像中,高度详细的纹理是可取的。为了证明这一点,我们在图6中展示了两个400m参数SR3+模型(召回,一个在DF2K+OST上训练,另一个在61M-图像数据集上训练)在不同teval值上的FID分数的比较。我们还包括了在图5中61m图像数据集上训练的SR3+模型的样本。
对于两个模型和两个评估数据集,我们发现在测试时使用噪声调节增强后,FID分数明显下降,最佳值通常在teval = 0:1左右。使用在61m图像数据集上训练的模型,我们奇怪地发现,在测试时可以使用更积极的噪声调节增强,同时仍然获得比teval = 0更好的FID分数。在我们的样本中,我们表明使用少量测试时间噪声调节增强的效果具有微妙但有益的效果:出现更高质量的纹理,并且与没有任何噪声相比,模糊程度更低,并且与调节图像的对齐仍然很好,甚至可以改善(例如,没有噪声的花盆似乎向上移动)。
然而,当我们增加teval时,我们开始看到最初很小,但越来越明显的与条件反射图像不一致,因为更多的高频信息被越来越多的噪声破坏,应用于条件反射信号。这迫使模型依赖于它自己的知识来产生这些细节和纹理,这在大多数情况下是有益的(但对于文本等情况则不那么有益)。
 图5。来自SR3+ (400M权重,61M数据集)的样本使用不同数量的测试时间噪声调节增强,teval。
图5。来自SR3+ (400M权重,61M数据集)的样本使用不同数量的测试时间噪声调节增强,teval。
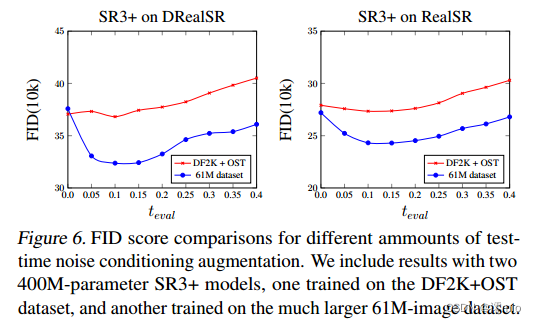
图6。不同测试时间噪声调节增强量的FID评分比较。我们包括了两个400m参数的SR3+模型的结果,一个是在DF2K+OST数据集上训练的,另一个是在更大的61m图像数据集上训练的。
6. Conclusion
在这项工作中,我们提出了SR3+,一个盲超分辨率的扩散模型。通过结合两种最新的图像增强技术,高阶退化方案和噪声调节增强,SR3+在盲超分辨率测试数据集上实现了最先进的FID分数。通过在更大的数据集上进行训练,我们进一步显著提高了定量和定性结果。与之前的工作不同,SR3+对分布外输入具有鲁棒性,并且可以以可控的方式生成逼真的纹理,因为测试时间噪声调节增强可以迫使模型更多地依赖自己的知识来推断高频细节。SR3+在自然图像上表现出色,如果有足够的数据,它在其他图像(如带有文本的图像)上也表现得相当好。我们最兴奋的是SR3+更广泛地提高了扩散模型的质量和鲁棒性,特别是那些依赖级联的模型(Ho et al, 2022),例如文本到图像模型。
然而,SR3+有一些局限性。当使用噪声调节增强时,可以观察到一些故障模式,例如乱码文本,并且可能需要更多的训练步骤来收敛,因为任务变得比使用总是干净的条件调节信号更具挑战性。我们相信具有更大容量(即参数计数)的模型,以及对神经结构的改进,可以在未来的工作中解决这些问题。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









