






Pytorch模块和基础实战
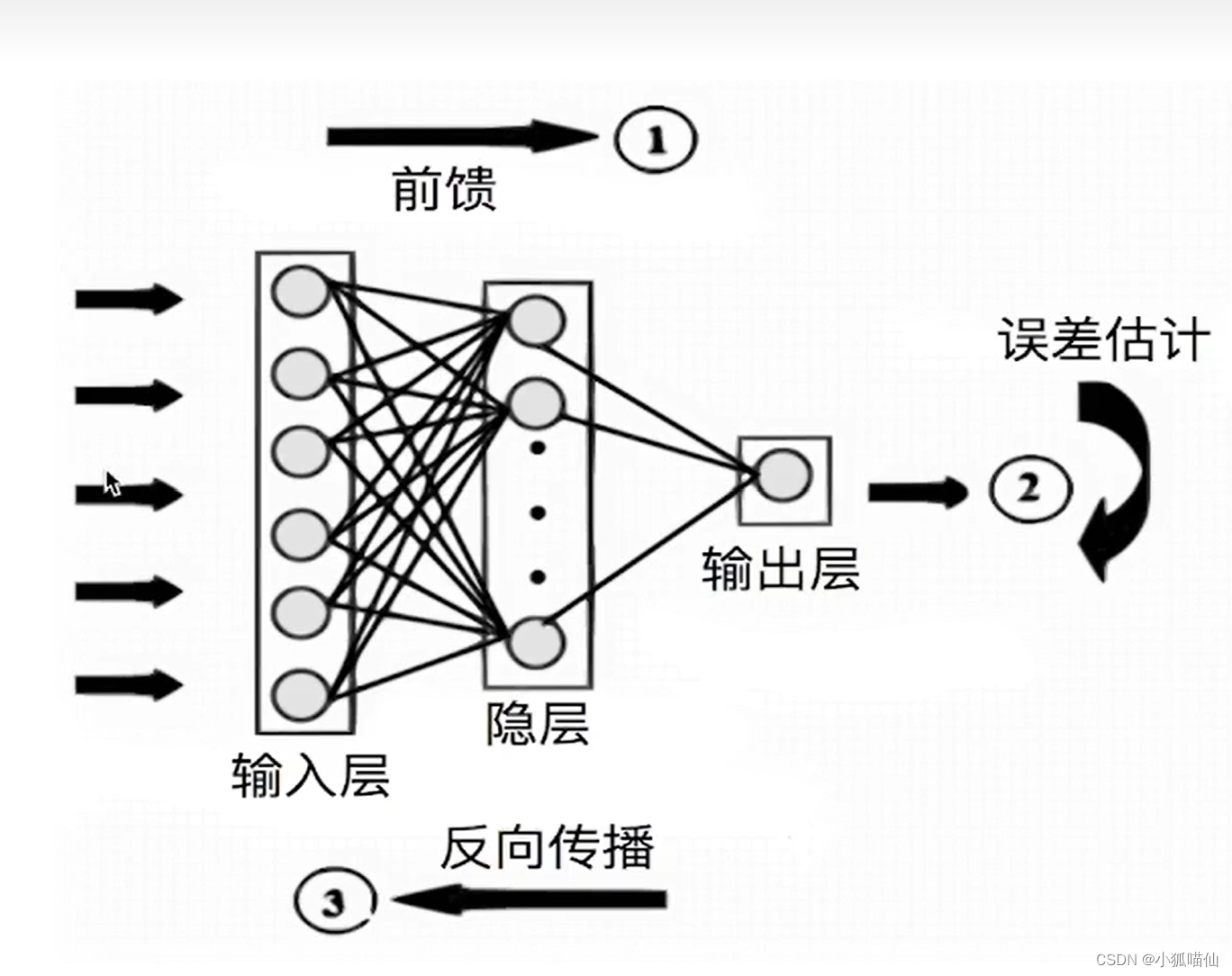
一、神经网络学习机制:
数据预处理
模型设计
损失函数和优化方案
前向传播
反向传播
更新参数
二、深度学习实现(特殊性)
样本量大,通常需要分批(batch)加载
逐层,模块化搭建网络(卷积层,全连接层,LSTM等)
多样化的损失函数和优化器设计
GPU的使用
以上各模块间的配合
3、PyTorch深度学习模块
3.1基本配置
导包
常见的包有
os | operate system |
|---|---|
numpy | 科学计算 |
等,此外还需要调用PyTorch自身一些模块便于灵活使用,比如
pandas | 表格操作,数据存储文件交互 |
|---|---|
torch | pytorch |
torch.nn | net work |
torch.utils.data.Dataset | 数据读取,数据预处理方式 |
torch.utils.data.DataLoader | 数据加载器(可快速迭代数据) |
torch.optimizer | 优化器 |
matplotlib、seaborn | 可视化 |
sklearn | 下游分析和指标计算 |
等等。
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim as optimizer3.2配置训练过程的超参数
-
batch size
-
初始学习率(初始)(learning rate)
-
训练次数(max_epochs)
-
读入数据线程(num_workers)
batch_size = 256 num_workers=4 # 批次的大小 lr = 1e-4 # 优化器的学习率 max_epochs = 100 -
GPU配置
# 方案一:使用os.environ,这种情况如果使用GPU不需要设置 os.environ['CUDA_VISIBLE_DEVICES'] = '0,1' # 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可 device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
3.3数据读入
定义自己的Dataset类来实现灵活的数据读取,主要包含三个函数:
-
__init__: 传入外部参数,定义样本集 -
__getitem__: 逐个读取样本集,可进行一定变换,并返回所需的数据 -
__len__: 返回数据集样本数
使用DataLoader来按批次读入数据:
-
batch_size:每次读入的样本数
-
num_workers:有多少个进程用于读取数据
-
shuffle:是否将读入的数据打乱
-
drop_last:对于样本最后一部分没有达到批次数的样本,使其不再参与训练
-
pin_memory:表示要将load进来的数据是否要拷贝到pin_memory区中,其表示生成的Tensor数据是属于内存中的锁页内存区,这样将Tensor数据转移到GPU中速度就会快一些,默认为False。
下载并使用PyTorch提供的内置数据集(适合常见的数据集,适用于快速测试的方法)
从网站下载csv格式存储的数据,读入并转成预期的格式(需自己构建Dataset,对数据进行必要变换,eg:统一图片大小,数据格式转为tensor类等
可用torchvision---官方图像处理工具库
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
from torchvision import datasets
os.environ['CUDA_VISIBLE_DEVICES']='0'
# device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
batch_size=256
num_workers=0
lr=1e-4
epochs=20
#设置数据变换
"""与模型匹配"""
image_size=28
data_transform=transforms.Compose([
"""内置PL库,取决于后续数据读取方式,如果使用内置数据集则不需要"""
transforms.ToPILImage(),
"""设置大小"""
transforms.Resize(image_size),
"""变为tensor的形式"""
transforms.ToTensor()
])
# #读取方式一:使用torchvision自带数据集,train=False代表测试集
# tran_data=datasets.FashionMNIST(root='./',train=True,download=True,transform=data_transform)
# test_data=datasets.FashionMNIST(root='./',train=False,download=True,transform=data_transform)
#读取方式二:读入csv格式的数据,自行构建Dataset类
#继承Dataset子类
class FMDataset(Dataset):
def __init__(self,df,transform=None):
#初始化
self.df=df
self.transform=transform
#读图,从第二列开始--第一列是标签label,提取为uint8
self.images=df.iloc[:,1:].values.astype(np.uint8)
self.labels=df.iloc[:,0].values
#数据集长度
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
#所有image第index(个)行---变化形状,28*28,1---单色通道
image=self.images[idx].reshape(28,28,1)
#将标签变为整型
label=int(self.labels[idx])
if self.transform is not None:
image=self.transform(image)
else:
#image变为tensor的形式,图像每一个数是0-255除法后变为0-1方便模型处理
image=torch.tensor(image/255.,dtype=torch.float)
label=torch.tensor(label,dtype=torch.long)
return image,label
#实例化
train_df=pd.read_csv("./FashionMNIST/fashion-mnist_train.csv")
test_df=pd.read_csv("./FashionMNIST/fashion-mnist_test.csv")
train_data=FMDataset(train_df,data_transform)
test_data=FMDataset(test_df,data_transform)
#定义DataLoader类,以便在训练和测试时加载数据
#从哪个dataset load data数据,每批加载的数据,是否打乱顺序,用多少线程读数据,是否将最后没达到批次样本继续参与训练
train_loader=DataLoader(train_data,batch_size=batch_size,shuffle=True,num_workers=num_workers,drop_last=True)
test_load=DataLoader(test_data,batch_size=batch_size,shuffle=False,num_workers=num_workers)
#next表迭代(1次),shape形状,matplotlib进行可视化,展示第0个数据
image,label=next(iter(train_loader))
print(image.shape,label.shape)
plt.imshow(image[100][0],cmap="gray")
torch.Size([256, 1, 28, 28]) torch.Size([256])#batchsize为256,通道为1,28为图片大小3.4模型构建
PyTorch中神经网络构造一般是基于 Module 类的模型来完成的(nn.Module)
-
重载
__init__和forward函数
-
“层定义+层顺序”方式构建
-
神经网络常见层nn.Conv2d,nn.MaxPool2d,nn.Linear,nn.ReLU,……
3.5模型设计
import torch
from torch import nn
#继承nn.Module类
class Net(nn.Module):
#完成关于层的定义
def __int__(self):
#supper初始化,层定义
super(Net,self).__init__()
#序贯模型
self.conv=nn.Sequential(
#二维卷积
# in_channels: int,
# out_channels: int,
# kernel_size: _size_2_t,
nn.Conv2d(1,32,5),
#激活函数
nn.ReLU(),
#池化
nn.MaxPool2d(2,stride=2),
nn.Dropout(0.3),
nn.Conv2d(32,64,5),
nn.ReLU(),
nn.MaxPool2d(2,stride=2),
nn.Dropout(0.3)
)
#全连接层,从64*4*4神经元变成512,再从512变为结果10(类)
self.fc=nn.Sequential(
nn.Linear(64*4*4,512),
nn.ReLU(),
nn.Linear(512,10)
)
#层顺序的排列(前馈)
def forward(self, x):
#数据x走conv卷积流程
x=self.conv(x)
#数据拉平,便于全连接层的操作
x=x.view(-1,64*4*4)
#变换数据维度
x=self.fc(x)
return x
#实例化
model=Net()
model=model.cuda()4、损失函数
BCELoss 二分类损失函数
BCEWithLogitsLoss
负对数似然损失函数 NLLLoss
交叉熵损失函数 CrossEntropyLoss
L1损失函数
L2 损失函数
SmoothL1Loss 损失函数
一般通过torch.nn调用, 损失函数常用操作:backward()
5、设定损失函数
-
使用torch.nn模块自带的CrosssEtropy损失
-
Pytorch会自动把整数型的label转为one-hot型,用于计算CE loss
-
确保label是从0开始的,同时模型不加softmax层(使用logits计算)---pytorch训练中各个部分不是独立的,需要通盘考虑
criterion=nn.CrossEntropyLoss()
criterion=nn.CrossEntropyLoss(weight=[1,1,3,1,1,1,1,])#加大某一个的训练权重6、优化器
常用操作:
step(),zero_grad,load_state_dict()……
优化器是根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数计算值,使得模型输出更加接近真实标签。
torch.optim.ASGD
torch.optim.Adadelta
torch.optim.Adagrad
torch.optim.Adam
torch.optim.AdamW
torch.optim.Adamax
torch.optim.LBFGS
torch.optim.RMSprop
torch.optim.Rprop
torch.optim.SGD
torch.optim.SparseAdam
而以上这些优化算法均继承于Optimizer,下面我们先来看下所有优化器的基类Optimizer。定义如下:
class Optimizer(object):
def __init__(self, params, defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []Optimizer有三个属性:
defaults:存储的是优化器的超参数,例子如下:
state:参数的缓存:
param_groups:管理的参数组,是一个list,其中每个元素是一个字典,顺序是params,lr,momentum,dampening,weight_decay,nesterov,例子如下:
Optimizer还有以下的方法:
zero_grad():清空所管理参数的梯度,PyTorch的特性是张量的梯度不自动清零,因此每次反向传播后都需要清空梯度。
step():执行一步梯度更新,参数更新
add_param_group():添加参数组
load_state_dict():加载状态参数字典,可以用来进行模型的断点续训练,继续上次的参数进行训练
state_dict():获取优化器当前状态信息字典
7、训练和测试(验证)
-
模型状态设置:model.train(),model.eval
是否需要初始化优化器
是否需要将loss传回到网络
是否需要每步更新optimizer
-
训练流程:读取、转换、梯度清零、输入、计算损失、反向传播、参数更新
-
验证流程:读取、转换、输入、计算损失、计算指标
时装分类:
FashionMNIST数据集中包含已经预先划分好的训练集和测试集,其中训练集共60,000张图像,测试集共10,000张图像。每张图像均为单通道黑白图像,大小为28*28pixel,分属10个类别。
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
from torchvision import datasets
import matplotlib.pyplot as plt
# os.environ['CUDA_VISIBLE_DEVICES']='0'
## 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
# device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
# device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
batch_size=256
num_workers=0
lr=1e-4
epochs=20
#设置数据变换
"""与模型匹配"""
image_size=28
data_transform=transforms.Compose([
#"""内置PL库,取决于后续数据读取方式,如果使用内置数据集则不需要"""
transforms.ToPILImage(),
# """设置大小"""
transforms.Resize(image_size),
#"""变为tensor的形式"""
transforms.ToTensor()
])
# #读取方式一:使用torchvision自带数据集,train=False代表测试集
# tran_data=datasets.FashionMNIST(root='./',train=True,download=True,transform=data_transform)
# test_data=datasets.FashionMNIST(root='./',train=False,download=True,transform=data_transform)
# 读取方式二:读入csv格式的数据,自行构建Dataset类
# 继承Dataset子类
class FMDataset(Dataset):
def __init__(self,df,transform=None):
#初始化
self.df=df
self.transform=transform
#读图,从第二列开始--第一列是标签label,提取为uint8
self.images=df.iloc[:,1:].values.astype(np.uint8)
self.labels=df.iloc[:,0].values
#数据集长度
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
#所有image第index(个)行---变化形状,28*28,1---单色通道
image=self.images[idx].reshape(28,28,1)
#将标签变为整型
label=int(self.labels[idx])
if self.transform is not None:
image=self.transform(image)
else:
#image变为tensor的形式,图像每一个数是0-255除法后变为0-1方便模型处理
image=torch.tensor(image/255.,dtype=torch.float)
label=torch.tensor(label,dtype=torch.long)
return image,label
#实例化
train_df=pd.read_csv("./FashionMNIST/fashion-mnist_train.csv")
test_df=pd.read_csv("./FashionMNIST/fashion-mnist_test.csv")
train_data=FMDataset(train_df,data_transform)
test_data=FMDataset(test_df,data_transform)
#定义DataLoader类,以便在训练和测试时加载数据
#从哪个dataset load data数据,每批加载的数据,是否打乱顺序,用多少线程读数据,是否将最后没达到批次样本继续参与训练
train_loader=DataLoader(train_data,batch_size=batch_size,shuffle=True,num_workers=num_workers,drop_last=True)
test_loader=DataLoader(test_data,batch_size=batch_size,shuffle=False,num_workers=num_workers)
image, label = next(iter(train_loader))
print(image.shape, label.shape)
plt.imshow(image[0][0], cmap="gray")
class Net(nn.Module):
#完成关于层的定义
def __init__(self):
#supper初始化,层定义
super(Net, self).__init__()
#序贯模型
self.conv = nn.Sequential(
#二维卷积
# in_channels: int,
# out_channels: int,
# kernel_size: _size_2_t,
nn.Conv2d(1, 32, 5),
#激活函数
nn.ReLU(),
#池化
nn.MaxPool2d(2, stride=2),
nn.Dropout(0.3),
nn.Conv2d(32, 64, 5),
nn.ReLU(),
nn.MaxPool2d(2, stride=2),
nn.Dropout(0.3)
)
#全连接层,从64*4*4神经元变成512,再从512变为结果10(类)
self.fc = nn.Sequential(
nn.Linear(64 * 4 * 4, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
#层顺序的排列(前馈)
def forward(self, x):
#数据x走conv卷积流程
x=self.conv(x)
#数据拉平,便于全连接层的操作
x=x.view(-1,64*4*4)
#变换数据维度
x=self.fc(x)
return x
#实例化
model=Net()
# model=model.cuda()
criterion = nn.CrossEntropyLoss()
# criterion=nn.CrossEntropyLoss(weight=[1,1,3,1,1,1,1,])
#定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
#训练
def train(epoch):
model.train()
train_loss=0
# for data,label=data.cuda(),label.cuda()
#返回batch的编号和batch对应数据
# for i,(data,label)in enumerate(train_loader):
for data,label in train_loader:
# data,label=data.cuda(),label.cuda()
#梯度回传0,不进行累加
optimizer.zero_grad()
#前向传播
output=model(data)
#计算损失函数
loss=criterion(output,label)
#反向传播
loss.backward()
#优化器更新权重
optimizer.step()
#训练损失叠加
train_loss += loss.item()*data.size(0)
train_loss=train_loss/len(train_loader.dataset)
print('EPOCH:{} \tTraining Loss: {:.6f}'.format(epoch,train_loss))
#验证
def val(epoch):
model.eval()
val_loss=0
gt_labels=[]
pred_labels=[]
#不做梯度的计算
with torch.no_grad():
for data,label in test_loader:
# data,label=data.cuda(),label.cuda()
output=model(data)
#取最大
preds=torch.argmax(output,1)
#真实label,预测label
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
loss=criterion(output,label)
val_loss += loss.item()*data.size(0)
val_loss=val_loss/len(test_loader.dataset)
gt_labels,pred_labels=np.concatenate(gt_labels),np.concatenate(pred_labels)
#拼接,把相等的值拼接并除以总数
acc=np.sum(gt_labels==pred_labels)/len(pred_labels)
print('Epoch: {} \tValidation Loss: {:.6f}, Accuracy: {:6f}'.format(epoch, val_loss, acc))
for epoch in range(1,epochs+1):
train(epoch)
val(epoch)
#训练完成后,可以使用torch.save保存模型参数或者整个模型,也可以在训练过程中保存模型
save_path = "./FahionModel.pkl"
torch.save(model, save_path)torch.Size([256, 1, 28, 28]) torch.Size([256])
EPOCH:1 Training Loss: 0.680543
Epoch: 1 Validation Loss: 0.441949, Accuracy: 0.842200
EPOCH:2 Training Loss: 0.431540
Epoch: 2 Validation Loss: 0.345487, Accuracy: 0.879300
EPOCH:3 Training Loss: 0.366046
Epoch: 3 Validation Loss: 0.316142, Accuracy: 0.887900
EPOCH:4 Training Loss: 0.336380
Epoch: 4 Validation Loss: 0.285833, Accuracy: 0.896500
EPOCH:5 Training Loss: 0.311207
Epoch: 5 Validation Loss: 0.267263, Accuracy: 0.902200
EPOCH:6 Training Loss: 0.290970
Epoch: 6 Validation Loss: 0.257569, Accuracy: 0.905200
EPOCH:7 Training Loss: 0.275216
Epoch: 7 Validation Loss: 0.257715, Accuracy: 0.905700
EPOCH:8 Training Loss: 0.263491
Epoch: 8 Validation Loss: 0.247774, Accuracy: 0.910000
EPOCH:9 Training Loss: 0.253206
Epoch: 9 Validation Loss: 0.257099, Accuracy: 0.902700
EPOCH:10 Training Loss: 0.243676
Epoch: 10 Validation Loss: 0.236460, Accuracy: 0.914600
EPOCH:11 Training Loss: 0.233477
Epoch: 11 Validation Loss: 0.227580, Accuracy: 0.917400
EPOCH:12 Training Loss: 0.227029
Epoch: 12 Validation Loss: 0.217505, Accuracy: 0.919000
EPOCH:13 Training Loss: 0.219373
Epoch: 13 Validation Loss: 0.218901, Accuracy: 0.918400
EPOCH:14 Training Loss: 0.214295
Epoch: 14 Validation Loss: 0.221296, Accuracy: 0.918900
EPOCH:15 Training Loss: 0.204996
Epoch: 15 Validation Loss: 0.217973, Accuracy: 0.920500
EPOCH:16 Training Loss: 0.197011
Epoch: 16 Validation Loss: 0.212263, Accuracy: 0.919200
EPOCH:17 Training Loss: 0.191312
Epoch: 17 Validation Loss: 0.207198, Accuracy: 0.925000
EPOCH:18 Training Loss: 0.187683
Epoch: 18 Validation Loss: 0.202116, Accuracy: 0.925500
EPOCH:19 Training Loss: 0.181617
Epoch: 19 Validation Loss: 0.199740, Accuracy: 0.926000
EPOCH:20 Training Loss: 0.179331
Epoch: 20 Validation Loss: 0.202072, Accuracy: 0.925200














 4455
4455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









