






一、 视频学习
绪论
一、 卷积神经网络的应用
可以进行一些诸如分类、检索、检测等的基本功能,也可以进行一些基于人脸的识别功能,还可以将音频之类的文件转化为图像,甚至一些其他领域的东西也可以用图像的方式表达出来,在人工驾驶领域也有所运用。
二、 传统神经网络vs卷积神经网络
1、 深度学习的三部曲
搭建神经网络三部曲
建立损失函数
建立优化函数
2、卷积神经网络是个多层结构,包含了由若干卷积层和子采样层(池化层)构成的特征抽取器,以及连接层。卷积层中,一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征图(featureMap),每个特征图由一些矩形排列的的神经元组成,同一特征图的神经元共享权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数。
CNN的基本组成结构
卷积
一维卷积
一维卷积经常用在信号处理中,用于计算信号的延迟累积。 例子: 假设一个信号发生器在时刻t发出一个信号x~t~,其信息的衰减率为f~k~,即在k-1个时间步长后,信息衰减为原来的fk倍。 设f1~ = 1,f2=1/2,f3=1/4,在时刻t收到的信号y~t~为当前时刻产生的信息和以前时刻延迟信息的叠加。
yt=1*x1+1/2*xt-1+1/4*xt-2
=f1*xt+f2*xt-1+f3*xt-2
=fk*xt-k+1
此处的f = [f1, f2, f3]被称为滤波器(filter)或卷积核(concoluntional kernel)。 设滤波器f长度为m,它和一个信号序列x = [x1, x2, x3...]的卷积记为
yt=fk*xt-k+1
卷积的定义
卷积是对两个实变函数的一种数学操作。 在图像处理中,图像是以二维矩阵的形式输入到神经网络的,因此我们需要二维卷积。 例子: 大小不匹配时进行零填充
大小不匹配时进行零填充  未加padding时输出的特征图大小: (N - F) / stride + 1 有padding时输出的特征图大小: (N + padding * 2 - F) / stride + 1
未加padding时输出的特征图大小: (N - F) / stride + 1 有padding时输出的特征图大小: (N + padding * 2 - F) / stride + 1
池化

pooling
保留了主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力。 它一般处于卷积层与卷积层之间,全连接层与全连接层之间。
pooling的类型
Max pooling:最大值池化 Average pooling:平均池化 例子: 
全连接

全连接层 / FC layer
1.两层之间所有神经元都有权重链接 2.通常全连接层在卷积神经网络尾部 3.全连接层参数量通常最大
卷积神经网络典型结构
1.AlexNet
AlexNet是2012年ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军网络,分类准确率由传统的 70%+提升到 80%+。 它是由Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,深 度学习开始迅速发展。
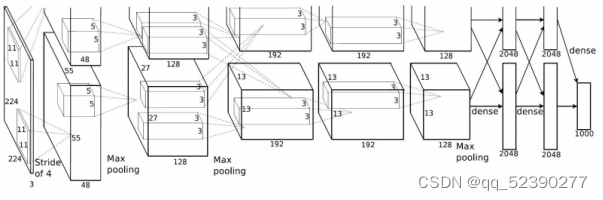
该网络的亮点在于:
(1)首次利用 GPU 进行网络加速训练。
(2)使用了 ReLU 激活函数,而不是传统的 Sigmoid 激活函数以及 Tanh 激活函数。
(3)使用了 LRN 局部响应归一化。
(4)在全连接层的前两层中使用了 Dropout 随机失活神经元操作,以减少过拟合。
2.ZFNet
ZFNet 仅仅是在 AlexNet 上做了一些调参:
改变了 AlexNet 的第一层,即将滤波器的大小 11x11 变成 7x7,并且将步长 4 变成了 2
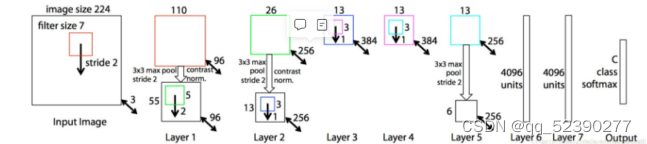
ZFNet网络结构和AlexNet保持一致,但是卷积核的大小和步长发生了变化。 主要改进:
将第一个卷积层的卷积核大小改为了7×7。 将第二、第三个卷积层的卷积步长都设置为2。 增加了第三、第四个卷积层的卷积核个数。
3.VGG
VGG网络结构输入为224224的RGB图像,经过卷积、池化与全连接操作后输出1000个分类结果,其中卷积池化部分共五段卷积组,每一段卷积组后接一个最大池化层,最后由3层全连接层输出分类结果,卷积层全部为33的卷积核。
卷积池化部分的结构如下:
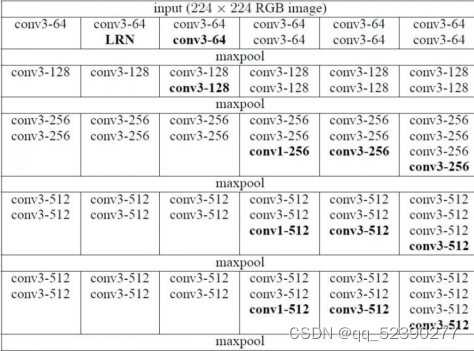
4.GoogleNet
VGG等一些经典的神经网络模型,其整个网络是不同神经模块的串联构建,随着神经网络深度不断加深会造成过拟合和模型参数巨大的问题为解决此问题,GoogleNet采用了串并联网络结构,使用了1x1 卷积和全局平均池化的方法改善网络结构,经过不断的迭代优化,发展出了Inception-v1、Inception-v2、Inception-v3、Inception-v4、Inception-ResNet共5个版本。
v2、v3大致结构如图所示:

5.ResNet
ResNet的提出是为了解决随着网络的加深造成的梯度爆炸和梯度消失问题以及解决深层网络中的退化问题。为了解决梯度消失或梯度爆炸问题,ResNet
通过数据的预处理以及在网络中使用BN层来解决。
为了解决深层网络中的退化问题,ResNet人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系,即残差网络。
ResNet的结构图如图所示:
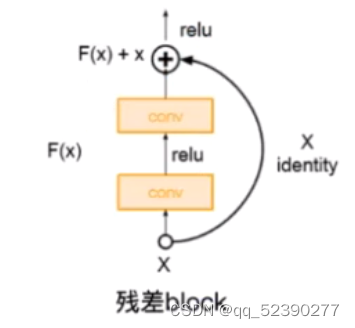
二、代码练习
MNIST 数据集分类
本段定义了一个函数get_n_params用于计算模型中的参数,同时设置使用GPU实验。
1. 加载数据 (MNIST)
本段代码调用torchvision.datasets下载了PyTorch中的常用数据集MNIST,另外值得注意的是,DataLoader是一个比较重要的类,提供的常用操作有:batch_size(每个batch的大小), shuffle(是否进行随机打乱顺序的操作), num_workers(加载数据的时候使用几个子进程)。
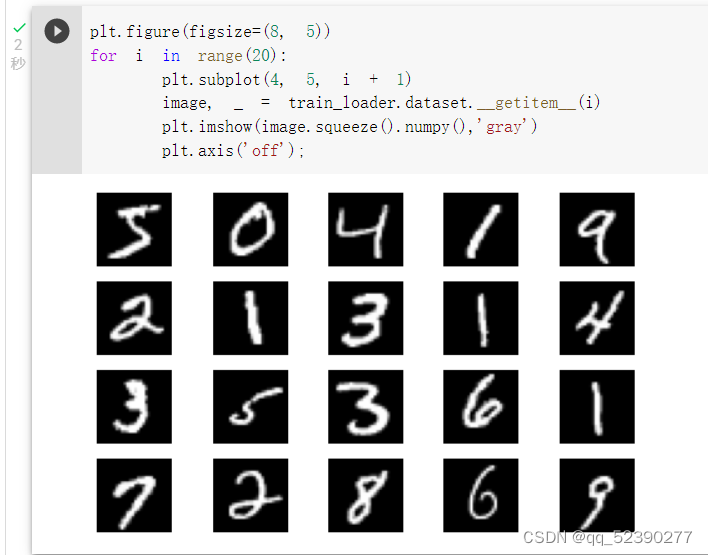
显示数据集中的部分图像。
2. 创建网络
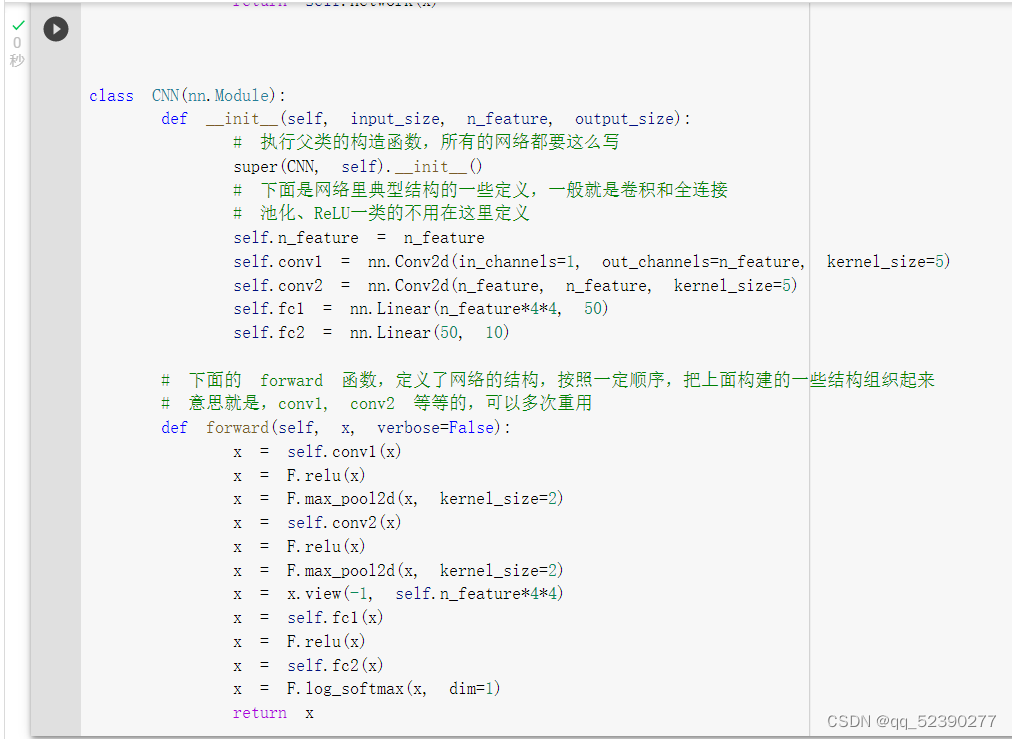

定义网络时,需要继承nn.Module,并实现它的forward方法,把网络中具有可学习参数的层放在构造函数init中。
只要在nn.Module的子类中定义了forward函数,backward函数就会自动被实现(利用autograd)。FC2Layer和CNN两个类均继承了nn.Module类。并重写了父类的继承函数和forward函数,定义了网络的结构,按照一定顺序,把上面构建的一些结构组织起来。

本段定义了训练函数和测试函数,训练函数从train_loader里,64个样本一个batch为单位提取样本进行训练,test函数把数据送到GPU中,把数据送入模型,得到预测结果,并计算本次batch的损失,并加到 test_loss 中。
3. 在小型全连接网络上训练(Fully-connected network)
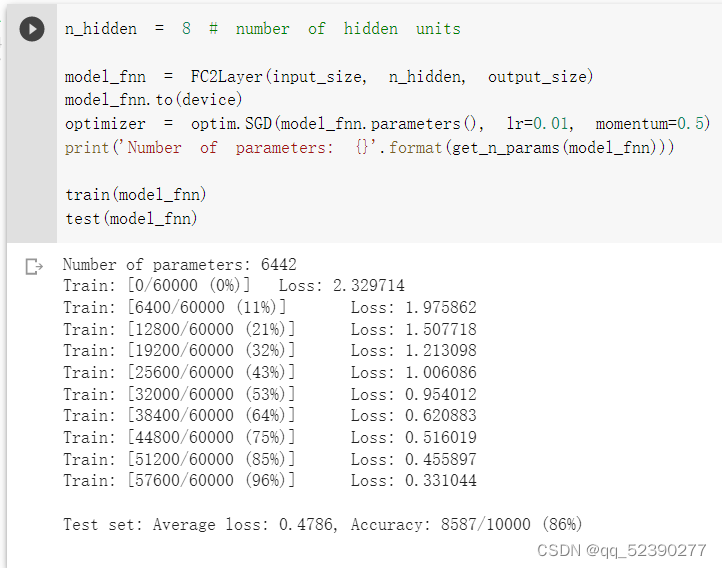
可以看出,全连接网络的平均损失值是0.4786,精确度是86%。
4. 在卷积神经网络上训练
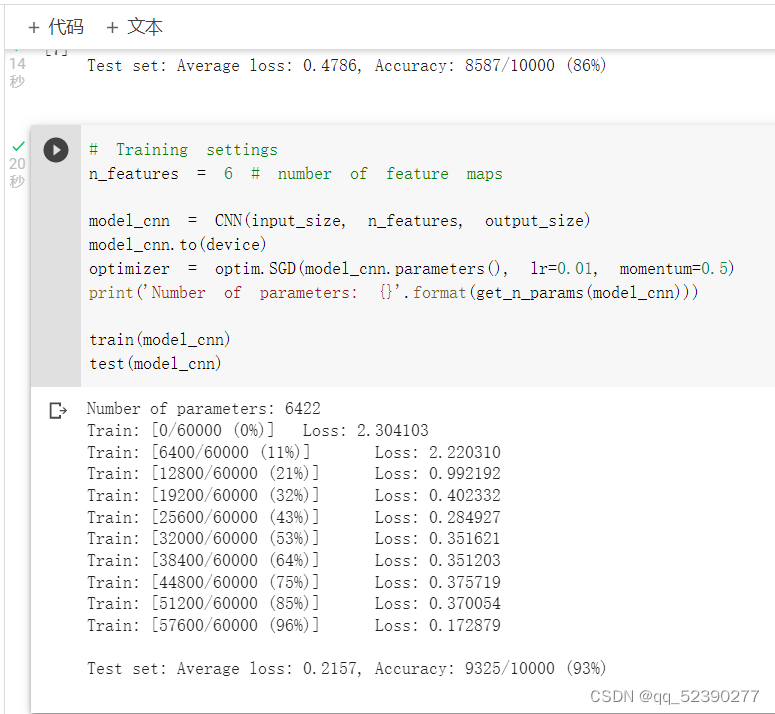
使用卷积神经网络对相同数据进行训练时,使用相同参数时平均损失为0.2157,精确度为93%,明显优于全连接网络。这是因为卷积神经网络利用卷积和池化更好地挖掘了图像中的信息。
5. 打乱像素顺序再次在两个网络上训练与测试

打乱顺序后图像的形态。

重新定义训练与测试函数,我们写了两个函数 train_perm 和 test_perm,分别对应着加入像素打乱顺序的训练函数与测试函数。
与之前的训练与测试函数基本上完全相同,只是对 data 加入了打乱顺序操作。

在打乱的数据上进行全连接网络的测试,观察结果发现数据打乱前后平均损失和精确度基本没有变化,说明全连接网络没有使用卷积和池化,其性能基本没有变化。
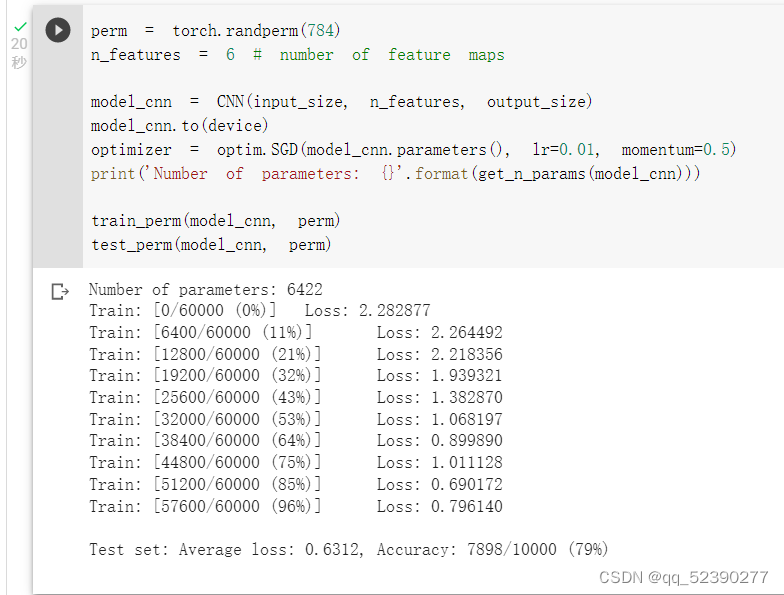
在打乱的数据上进行卷积神经网络的测试,打乱数据后卷积神经网络的平均损失明显上升,而精确度明显下降,甚至低于全连接网络。这是因为对于卷积神经网络,会利用像素的局部关系,但是打乱顺序以后,这些像素间的关系将无法得到利用。
CIFAR10 数据集分类
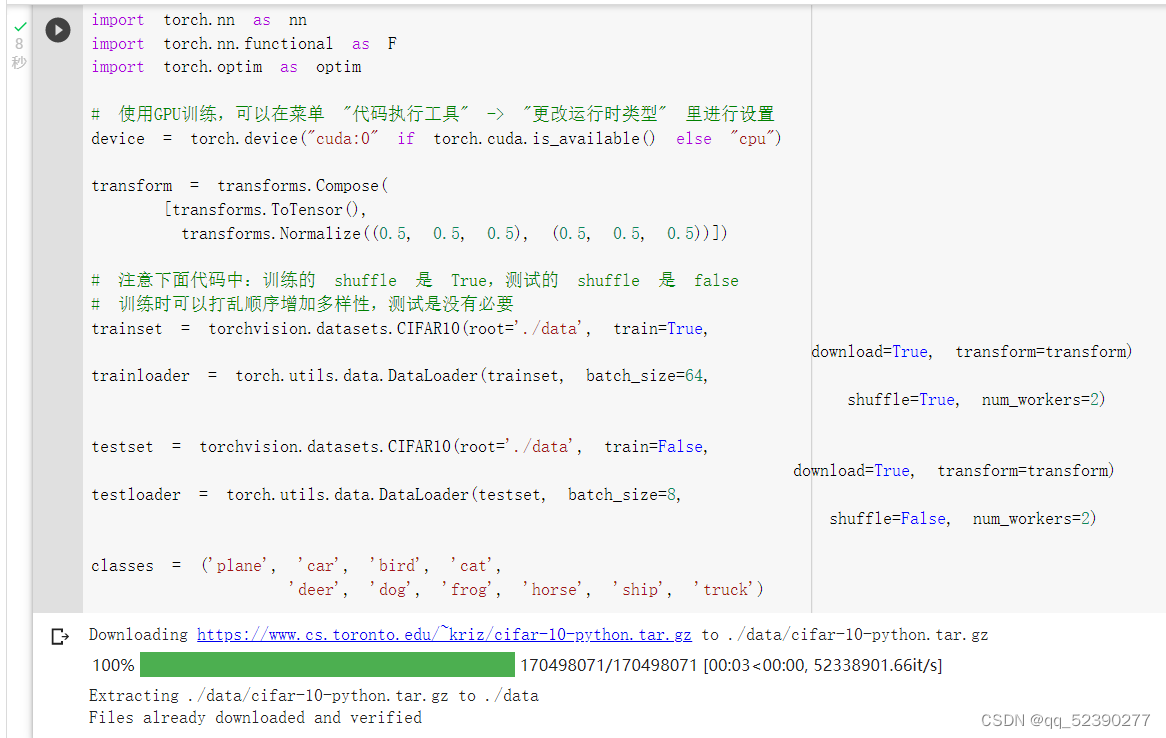
首先,加载并归一化 CIFAR10 使用 torchvision 。torchvision 数据集的输出是范围在[0,1]之间的 PILImage,我们将他们转换成归一化范围为[-1,1]之间的张量 Tensors。

展示 CIFAR10 里面的一些图片。

定义网络,损失函数和优化器,将网络放到GPU上。
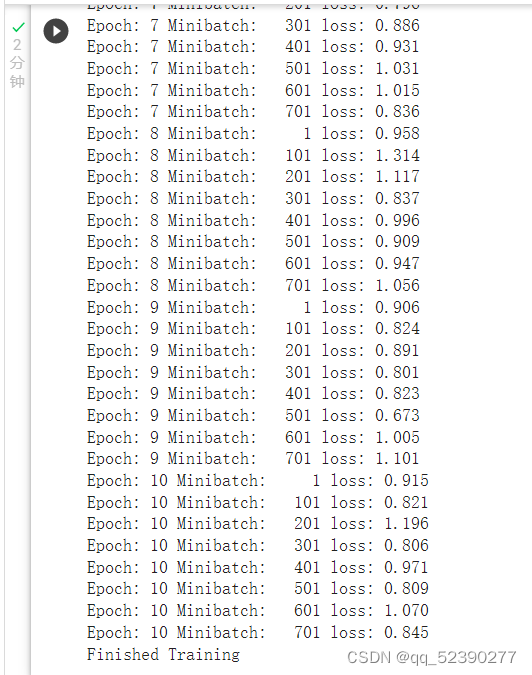
训练网络的过程。

从测试集中取出8张图片,把图片输入模型进行识别,观察输出结果发现有4个图片识别错了,准确率为50%。

在整个网络上进行训练,训练准确率为63%,性能一般。
使用 VGG16 对 CIFAR10 分类
1. 定义 dataloader
加载并归一化 CIFAR10 使用 torchvision 。
2. VGG 网络定义

初始化网络,根据实际需要,修改分类层。因为 tiny-imagenet 是对200类图像分类,这里把输出修改为200。并将网络放在GPU上,这里按照实验代码运行时报错显示cfg未定义,将self.features中的参数改为self.cfg可正常运行。
3. 网络训练
进行网络的训练。按照实验代码运行时运行时显示mat1 and mat2 shapes cannot be multiplied (128x512 and 2048x10),需要将self.classifier=nn.Linear(2048,10)更改为self.classifier=nn.Linear(512,10)方可正确运行。
4. 测试验证准确率:
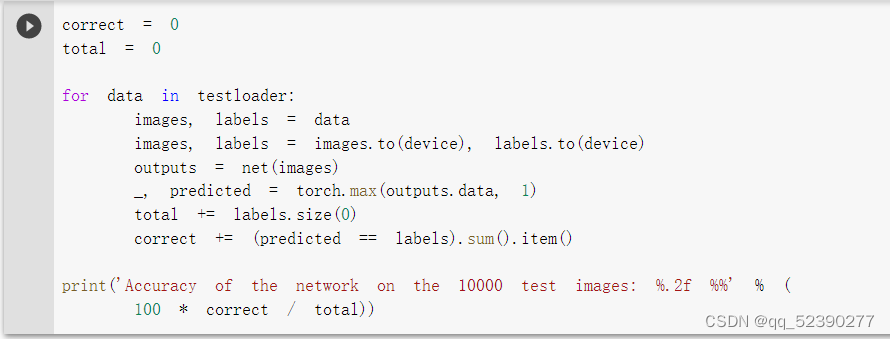
可以看到,使用一个简化版的 VGG 网络,就能够显著地将准确率由 64%,提升到 84.92%
三、问题回答
1、dataloader 里面 shuffle 取不同值有什么区别?
shuffle=true时对数据进行随机打乱,shuffle=false时则不对数据进行随机打乱。Shuffle训练时可以打乱顺序增加多样性,它可以防止训练过程中的模型抖动,有利于模型的健壮性。同时可以防止过拟合,并且使得模型学到更加正确的特征。
2、transform里,取了不同值,这个有什么区别?
一般情况下,预加载的数据集或自己构造的数据集并不能直接用于训练机器学习算法,为了将其转换为训练模型所需的最终形式,我们可以使用
transfroms对数据进行处理,以使其适合训练。transforms.Normalize()函数用于数据的归一化。其三个参数mean,类型是元组序列,表示每个通道的均值;std,类型是元组序列,表示每个通道的标准差;inplace,可选参数,类型是布尔值,表示是否以in-place执行该操作。该变换的意义是用均值和标准差对 Tensor Image 进行归一化,即给定 n 个通道的均值 (mean[1], mean[2], ..., mean[n]) 和 标准差 (std[1], std[2]), ..., std[n],那么输出图像:output[channel] = (input[channel] - mean[channel])/std[channel],返回值是 Tensor Image。
3、epoch和batch的区别?
Batch大小是在更新模型之前处理的多个样本。Epoch数是通过训练数据集的完整传递次数。批处理的大小必须大于或等于1且小于或等于训练数据集中的样本数。可以将epoch设置为1和无穷大之间的整数值。它们都是整数值,并且它们都是学习算法的超参数,例如学习过程的参数,而不是学习过程找到的内部模型参数。
4、1×1的卷积和FC有什么区别?主要起什么作用?
1*1的卷积可以用于降维(减少通道数),升维(增加通道数),代替fc成为一个分类器。其优点是权值共享,参数量较同等功能的FC层相比较少,使用了位置信息;FC层对于训练样本要求统一尺寸,但是1×1的卷积不会受此限制。
5、residual leanring 为什么能够提升准确率?
在此模型中,由于x直接连接到下一层,没有任何参数,即网络学习到的是F(x)。其不会存在梯度消失问题,且其计算速度较快,残差收敛快。
6、 代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
AlexNet采用了ReLu激活函数,也就是在卷积,池化后又增加了ReLu激活函数。ReLu在这里代替了Sigmod函数对输入的非线性进行了优化,相比较Sigmod函数,Relu的计算成本更低(Relu基本等于一个If_else的计算逻辑而Sigmod 或者 Tahn等激活函数则需要更庞大的计算陈本),同时,tanh或者sigmod在饱和区域容易产生梯度消失而减慢收敛速度,而ReLu不会。同时由于ReLu函数的构造,可以把不明显的信号替换为0,增加矩阵的稀疏性,从而防止过拟合。
7、代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
对缺失的部分进行填充。如果padding不为0的话,那么输入 feature map 的两端都要填充上 padding 大小的0。
8、有什么方法可以进一步提升准确率?
向模型中添加更多层,增强它更深入地学习数据集特性的能力。
增加训练轮次或调整模型的学习速度。
减少颜色通道。如果颜色模型中不是重要的因素,可以将彩色图像转换为灰度。
选择合适的神经网络、损失函数和激活函数。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









