







编程工具:jupyter notebook
一、基本认识
1. 导入库
import pandas as pd
import warnings2. 屏蔽警告提示
warnings.filterwarnings('ignore')3.读取Excel
df = pd.read_excel('./data/demo_01.xlsx', engine='openpyxl') # 相对路径,engine='openpyxl' 引擎可以不加,但是旧版本需要加
df = pd.read_excel('./data/demo_01.xlsx') 4.预览前5行
df.head(5)
5.列名对齐
- display.unicode.ambiguous_as_wide
- display.unicode.east_asian_width
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)6.禁止换行
pd.set_option('expand_frame_repr', False)7.显示所有行
pd.set_option('display.max_rows', None)8.最多显示10行
pd.set_option('display.max_rows', 10)9.显示所有列
pd.set_option('display.max_columns', None)10.最多显示10列
pd.set_option('display.max_columns', 10)11.设置内容的显示宽度
pd.set_option('display.width', 100)12.设置数值的显示精度
pd.set_option('display.precision', 2)13.设置小数的显示格式
pd.set_option('display.float_format', lambda x: '%.2f' % x)
# '{:.2f}'.format(x),小数点
# '{:.2%}'.format(x),百分比14.设置计算引擎
pd.set_option('compute.use_numba', True) # 当数据处理量较大速度较慢时可以设置为此计算引擎15.获取指定选项的设置情况
pd.get_option('compute.use_numba')16.条件格式
# pandas.io.formats.style.Styler
df.style.highlight_max() #高亮显示最大值
二、Scries对象
import pandas as pd1.创建Series对象
pd.Series([80,90,88]) #pd.Series(data=None,index=None,dtype=None,name=None,copy=False,fastpath=False,)
2.设置Series索引
2.1 数字索引
pd.Series(data=[80,90,88],index=[1,2,3])
2.2字符串索引
pd.Series(data=[80,90,88],index=['张三','李四','王五'])
3.Series的索引操作
s4 = pd.Series(data=[80,90,88,96],index=['张三','李四','王五','赵六'])
s4
# 取第一个同学的成绩
s4[0],s4['张三']![]()
3.1通过索引号获取值
s4[0]80
3.2通过索引名获取值
s4['张三']80
3.3通过多个索引名获取值
s4[ ['张三','赵六'] ]张三 80 赵六 96 dtype: int64
3.4通过索引名切片获取值
s4张三 80 李四 90 王五 88 赵六 96 dtype: int64
s4['张三':'王五'] # 通过索引名切片,左右都包含;通过索引号切片左闭右开张三 80 李四 90 王五 88 dtype: int64
3.5通过索引号切片获取值
s4[:3] #通过索引号切片左闭右开张三 80 李四 90 王五 88 dtype: int64
3.6获取Series的索引
s4.index # 获取s4的索引Index(['张三', '李四', '王五', '赵六'], dtype='object')
3.7获取Series的值
s4.values # 获取s4的值array([80, 90, 88, 96], dtype=int64)
type(s4.values)numpy.ndarray
3.8判断Series是否包含空值
s4.hasnansFalse
三、DataFrame对象
import pandas as pd1.创建DataFrame对象
data = [[110, 105, 99],
[105, 88, 115],
[109, 120, 130]]
index = [0, 1, 2]
columns = ['语文', '数学', '英语']
#pd.DataFrame(data=None,index:'Optional[Axes]'=None,columns:'Optional[Axes]'=None,dtype:'Optional[Dtype]'= None,copy:'bool'=False)
df = pd.DataFrame(data=data,index=index,columns=columns)
df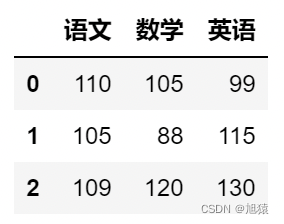
2.遍历DataFrame每列
df['语文']0 110 1 105 2 109 Name: 语文, dtype: int64
type(df['语文'])pandas.core.series.Series
for col in df.columns:
print(type(df[col]))<class 'pandas.core.series.Series'> <class 'pandas.core.series.Series'> <class 'pandas.core.series.Series'>
3.通过字典创建DataFrame
- value为多个元素
dct = {
'语文': [110, 105, 99],
'数学': [105, 88, 115],
'英语': [109, 120, 130]}
df = pd.DataFrame(data=dct,index=[1,2,3])
df 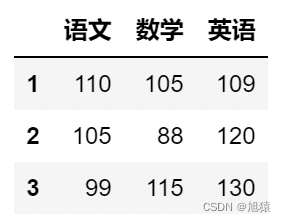
4.通过字典创建DataFrame
- value为一个元素
dct = {
'语文': 110,
'数学': 105,
'英语': 109}
df = pd.DataFrame(data=dct,index=[0]) # 一行数据 index 也要传入列表格式
df 
dct = {'语文': [110],
'数学': [105],
'英语': [109]}
pd.DataFrame(data=dct) 
5.DataFrame的重要属性
5.1查看所有元素的值
dct = {
'语文': [110, 105, 99],
'数学': [105, 88, 115],
'英语': [109, 120, 130]}
df = pd.DataFrame(data=dct,index=[1,2,3])
df
df.valuesarray([[110, 105, 109],
[105, 88, 120],
[ 99, 115, 130]], dtype=int64)
5.2查看某列的唯一值
df['语文'].unique() # 查看 语文 列中去重后的数据array([110, 105, 99], dtype=int64)
5.3查看所有元素的类型
df.dtypes # 查看每个字段的数据类型语文 int64 数学 int64 英语 int64 dtype: object
5.4查看所有行名
# index ——> 行索引,索引
# column ——> 列索引,字段,列名
df.indexInt64Index([1, 2, 3], dtype='int64')
5.5重命名行名
df.index = ['a1','a2','a3']
df
5.6查看所有列名
df.columnsIndex(['语文', '数学', '英语'], dtype='object')
5.7重命名列名
df.columns = ['语','数','外']
df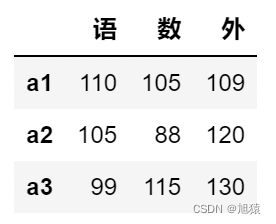
5.8行列转置
df.T
5.9查看前n条数据
- 默认5条
df.head() 
5.10查看前10条数据
df.head(10)
5.11查看后n条数据
- 默认5条
df.tail()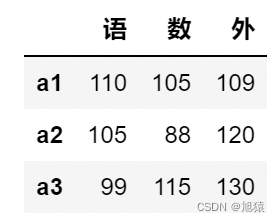
5.12查看后10条数据
df.tail(10)
5.13查看行数
- 0表示行
df.shape[0]3
5.14查看列数
- 1表示列
df.shape[1]3
5.15查看基本信息
- 索引、数据类型、非空值数量和内存信息
df.info()<class 'pandas.core.frame.DataFrame'> Index: 3 entries, a1 to a3 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 语 3 non-null int64 1 数 3 non-null int64 2 外 3 non-null int64 dtypes: int64(3) memory usage: 204.0+ bytes
6.DataFrame的重要函数
6.1查看每列的描述统计信息
- 返回DataFrame类型
df.describe() 
type(df.describe())pandas.core.frame.DataFrame
df.describe().round(2) # 保留两位小数
6.2返回每列非空值数量
df.count()语 3 数 3 外 3 dtype: int64
6.3返回每列的合计
- 无法计算返回空值
df.sum()语 314 数 308 外 359 dtype: int64
6.4返回每列的最大值
df.max()语 110 数 115 外 130 dtype: int64
6.5返回每列的最小值
df.min()语 99 数 88 外 109 dtype: int64
6.6返回最大值的索引号
- 原始的数字索引
df
# 原始索引:从0开始递增
df['语'].argmax() # 语文中最大的原始索引0
6.7返回最小值的索引号
- 原始的数字索引
df['语'].argmin()2
6.8 返回最大值的索引名
- 自定义的索引
df['语'].idxmax()'a1'
6.9返回最小值的索引名
- 自定义的索引
df['语'].idxmin()'a3'
6.10返回每列的平均值
df.mean()语 104.666667 数 102.666667 外 119.666667 dtype: float64
6.11返回每列的中位数
- 中位数又称中值,按顺序排列后处于中间位置的数值
df.median()语 105.0 数 105.0 外 120.0 dtype: float64
6.12返回每列的方差
- 用于衡量一组数据的离散程度
df.var()语 30.333333 数 186.333333 外 110.333333 dtype: float64
6.13返回每列的标准差
- 标准差是方差的算术平方根
- 也用于衡量一组数据的离散程度
df.std()语 5.507571 数 13.650397 外 10.503968 dtype: float64
6.14检查df中的空值
- 空值为True,否则为False,返回布尔型数组
df.isnull() 
6.15检查df中的非空值
- 非空值为True,否则为False,返回布尔型数组
df.notnull() 
四、数据导入
import pandas as pd1.导入Excel
df1 = pd.read_excel('./data/demo_04.xlsx') # 默认读取第一个工作表
df1.head(5)
2.导入Excel的指定Sheet
pd.read_excel('./data/demo_04.xlsx', sheet_name='工作表2') # 参数 sheet_name 设为想要读取的工作表名称 
3.设置第2行为列索引
pd.read_excel('./data/demo_04.xlsx', sheet_name='工作表3') # 默认第一行作为表头
pd.read_excel('./data/demo_04.xlsx', sheet_name='工作表3',header=1) 
4.通过指定的列索引来导入第1列
pd.read_excel('./data/demo_04.xlsx', sheet_name='工作表1',usecols=[0]) 
5.通过指定的列索引来导入第1列、第4列
pd.read_excel('./data/demo_04.xlsx', sheet_name='工作表1',usecols=[0,3])
6.通过指定的列名来导入指定列
pd.read_excel('./data/demo_04.xlsx', sheet_name='工作表1',usecols=['name','sex'])
7.导入csv,并指定编码格式
pd.read_csv('./data/demo_04.csv',encoding='utf-8')
8.导入txt,并指定编码格式
pd.read_csv('./data/demo_04.txt',encoding='utf-8',sep='\t') # 参数 sep 设置分隔符,默认是逗号
9.导入json,并指定数据结构
- split, records, index, table, values
(1)index结构
# {
# "0": {
# "姓名": "王晨",
# "电话": 13807990096
# },
# "1": {
# "姓名": "刘英",
# "电话": 15317068630
# },
# "2": {
# "姓名": "王婷",
# "电话": 15069162098
# },
# "3": {
# "姓名": "余颖",
# "电话": 15110247460
# },
# "4": {
# "姓名": "程秀珍",
# "电话": 15052126982
# },
# "5": {
# "姓名": "孙飞",
# "电话": 15187633436
# },
# "6": {
# "姓名": "戚阳",
# "电话": 15749935938
# },
# "7": {
# "姓名": "李璐",
# "电话": 18712343795
# },
# "8": {
# "姓名": "秦静",
# "电话": 15800229061
# },
# "9": {
# "姓名": "张莹",
# "电话": 13718317243
# }
# }
pd.read_json('./data/index.json',orient='index') # 通过 orient 参数修改 json 的数据结构格式 
(2)records结构
# [
# {
# "姓名": "王晨",
# "电话": 13807990096
# },
# {
# "姓名": "刘英",
# "电话": 15317068630
# },
# {
# "姓名": "王婷",
# "电话": 15069162098
# },
# {
# "姓名": "余颖",
# "电话": 15110247460
# },
# {
# "姓名": "程秀珍",
# "电话": 15052126982
# },
# {
# "姓名": "孙飞",
# "电话": 15187633436
# },
# {
# "姓名": "戚阳",
# "电话": 15749935938
# },
# {
# "姓名": "李璐",
# "电话": 18712343795
# },
# {
# "姓名": "秦静",
# "电话": 15800229061
# },
# {
# "姓名": "张莹",
# "电话": 13718317243
# }
# ]
pd.read_json('./data/records.json',orient='records')
(3)split结构
# {
# "columns": [
# "姓名",
# "电话"
# ],
# "index": [
# 0,
# 1,
# 2,
# 3,
# 4,
# 5,
# 6,
# 7,
# 8,
# 9
# ],
# "data": [
# [
# "王晨",
# 13807990096
# ],
# [
# "刘英",
# 15317068630
# ],
# [
# "王婷",
# 15069162098
# ],
# [
# "余颖",
# 15110247460
# ],
# [
# "程秀珍",
# 15052126982
# ],
# [
# "孙飞",
# 15187633436
# ],
# [
# "戚阳",
# 15749935938
# ],
# [
# "李璐",
# 18712343795
# ],
# [
# "秦静",
# 15800229061
# ],
# [
# "张莹",
# 13718317243
# ]
# ]
# }
pd.read_json('./data/split.json',orient='split')
(4)table结构
# {
# "schema": {
# "fields": [
# {
# "name": "index",
# "type": "integer"
# },
# {
# "name": "姓名",
# "type": "string"
# },
# {
# "name": "电话",
# "type": "integer"
# }
# ],
# "primaryKey": [
# "index"
# ],
# "pandas_version": "0.20.0"
# },
# "data": [
# {
# "index": 0,
# "姓名": "王晨",
# "电话": 13807990096
# },
# {
# "index": 1,
# "姓名": "刘英",
# "电话": 15317068630
# },
# {
# "index": 2,
# "姓名": "王婷",
# "电话": 15069162098
# },
# {
# "index": 3,
# "姓名": "余颖",
# "电话": 15110247460
# },
# {
# "index": 4,
# "姓名": "程秀珍",
# "电话": 15052126982
# },
# {
# "index": 5,
# "姓名": "孙飞",
# "电话": 15187633436
# },
# {
# "index": 6,
# "姓名": "戚阳",
# "电话": 15749935938
# },
# {
# "index": 7,
# "姓名": "李璐",
# "电话": 18712343795
# },
# {
# "index": 8,
# "姓名": "秦静",
# "电话": 15800229061
# },
# {
# "index": 9,
# "姓名": "张莹",
# "电话": 13718317243
# }
# ]
# }
pd.read_json('./data/table.json',orient='table')
(5)values结构
# [
# [
# "王晨",
# 13807990096
# ],
# [
# "刘英",
# 15317068630
# ],
# [
# "王婷",
# 15069162098
# ],
# [
# "余颖",
# 15110247460
# ],
# [
# "程秀珍",
# 15052126982
# ],
# [
# "孙飞",
# 15187633436
# ],
# [
# "戚阳",
# 15749935938
# ],
# [
# "李璐",
# 18712343795
# ],
# [
# "秦静",
# 15800229061
# ],
# [
# "张莹",
# 13718317243
# ]
# ]
df = pd.read_json('./data/values.json',orient='values')
df.columns = ['姓名','电话'] # values 需要自己定义字段名称
df
五、数据抽取
import pandas as pd1.创建DataFrame对象
data = [[109, 107, 100],
[105, 114, 135],
[98, 88, 120],
[145, 150, 130]]
name = ['刘备', '关羽', '张飞', '诸葛亮']
columns = ['语文', '数学', '英语']
df = pd.DataFrame(
data=data,
index=name,
columns=columns)
df
2.使用loc方法抽取
# 通过名称筛选
df.loc['刘备']语文 109 数学 107 英语 100 Name: 刘备, dtype: int64
type(df.loc['刘备'])pandas.core.series.Series
3.使用iloc方法抽取
# 通过索引号筛选
df.iloc[0]语文 109 数学 107 英语 100 Name: 刘备, dtype: int64
df.iloc[[0,3]] # 读取下表为 0 ,3 的行
4.抽取指定行的数据
- 使用loc和iloc
4.1从“刘备”到“诸葛亮”
df.loc['刘备':'诸葛亮'] # 通过切片方式,左闭右闭
4.2第1行到“关羽”
df.loc[:'关羽']
4.3第1行到第4行
df.iloc[:4]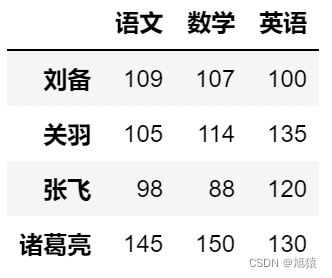
4.4第2行到最后1行
df.iloc[1:]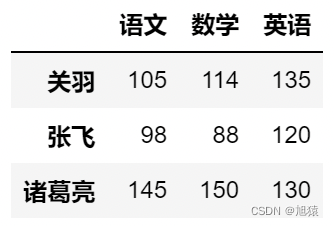
5.抽取指定列的数据
df
5.1直接使用列名
df['语文']刘备 109 关羽 105 张飞 98 诸葛亮 145 Name: 语文, dtype: int64
df[['语文']]
df[['语文','数学']]
5.2使用loc和iloc
5.2.1抽取“语文”和“数学”
df.loc[:,['语文','数学']]
5.2.2抽取第1列和第2列
df.iloc[:,[0,1]]
5.2.3抽取从“语文”开始到最后1列
df.loc[:,'语文':]
5.2.4抽取从第1列开始到第3列
df.iloc[:,:3]
6.抽取指定行列的数据
- 使用loc和iloc
6.1 “英语”成绩
df.loc[:,'英语']刘备 100 关羽 135 张飞 120 诸葛亮 130 Name: 英语, dtype: int64
6.2“关羽”的“英语”成绩
df.loc['关羽','英语']135
df.loc[['关羽'],['英语']]
6.3“关羽”的“数学”和“英语”成绩
df.loc[['关羽'],['英语','数学']]
6.4第2行第3列
df.iloc[1,2]135
df.iloc[[1],[2]]
6.5第2行到最后1行,第3列
df.iloc[1:,[2]]
6.6第2行到最后1行,第1列和第3列
df.iloc[1:,[0,2]]
6.7所有行,第3列
df.iloc[:,[2]]
7.按指定条件抽取数据
df
7.1 语文大于105且数学大于88
df.loc[ (df['语文'] > 105) & (df['数学'] > 88) ] # 注意加括号
cod1 = df['语文'] > 105
cod2 = df['数学'] > 88
df.loc[ cod1 & cod2]
7.2 语文大于105或数学大于88
df.loc[ (df['语文'] > 105) | (df['数学'] > 88) ] # 注意加括号
cod1 = df['语文'] > 105
cod2 = df['数学'] > 88
df.loc[ cod1 | cod2]
7.3 语文不等于105
- !=
df.loc[ df['语文'] != 105 ] 
7.4 语文不等于105
- ~
df.loc[~(df['语文'] == 105)] # 注意括号 
六、数据新增修改删除
import pandas as pd1. 创建DataFrame对象
data = [[109, 107, 100],
[105, 114, 135],
[98, 88, 120],
[145, 150, 130]]
name = ['刘备', '关羽', '张飞', '诸葛亮']
columns = ['语文', '数学', '英语']
df = pd.DataFrame(
data=data,
index=name,
columns=columns)
df
2 .新增数据
2.1 按列新增数据
2.1.1 直接赋值
- 在最后插入“物理”一列
df['物理'] = [88,77,66,55]
df 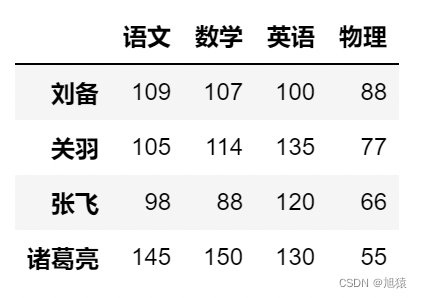
2.1.2 loc方法
- 在最后插入“物理”一列
df.loc[:,'物理'] = [99,89,79,69]
df
2.1.3 insert方法
- 在第1列后面插入“物理”列名
del df['物理'] # 删除 ‘物理’ 列
df 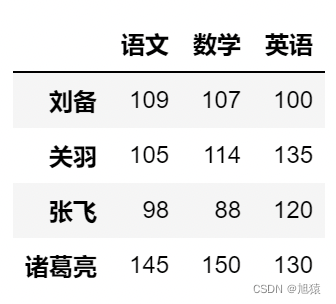
df.insert(1,'物理',[89,79,69,66])
df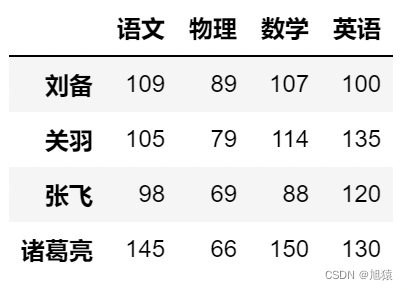
2.2 按行新增数据
2.2.1 新增一行数据
df.loc['赵云'] = [100,70,120,110]
df 
2.2.2 新增多行数据
df2 = pd.DataFrame(
{'语文': [100, 123, 138],
'数学': [120, 142, 60],
'英语': [99, 139, 99],
'物理': [105, 110, 96]},
index=['马超', '黄忠', '姜维'])
df2
df3 = df.append(df2) # 必须重新赋值
df,df3( 语文 物理 数学 英语
刘备 109 89 107 100
关羽 105 79 114 135
张飞 98 69 88 120
诸葛亮 145 66 150 130
赵云 100 70 120 110,
语文 物理 数学 英语
刘备 109 89 107 100
关羽 105 79 114 135
张飞 98 69 88 120
诸葛亮 145 66 150 130
赵云 100 70 120 110
马超 100 105 120 99
黄忠 123 110 142 139
姜维 138 96 60 99)
3.修改行列索引
3.1 修改列索引
3.1.1 通过属性赋值
columns = df.columns # 备份列索引
df.columns = ['语文(上)','物理','数学','英语']
df
df.columns = columns # 还原
df
3.1.2 通过rename方法
dct = {'语文':'语文(上)','物理':'物理(上)'} # 定义字典,键为修改前的字段名称,值为修改后的字段名称
df4 = df.rename(dct,axis=1) # 不会修改原始数据,需要重新赋值
df,df4( 语文 物理 数学 英语
刘备 109 89 107 100
关羽 105 79 114 135
张飞 98 69 88 120
诸葛亮 145 66 150 130
赵云 100 70 120 110,
语文(上) 物理(上) 数学 英语
刘备 109 89 107 100
关羽 105 79 114 135
张飞 98 69 88 120
诸葛亮 145 66 150 130
赵云 100 70 120 110)
3.2 修改行索引
3.2.1 通过属性赋值
#备份行索引
index = df.index
indexIndex(['刘备', '关羽', '张飞', '诸葛亮', '赵云'], dtype='object')
df.index = [1,2,3,4,5]
df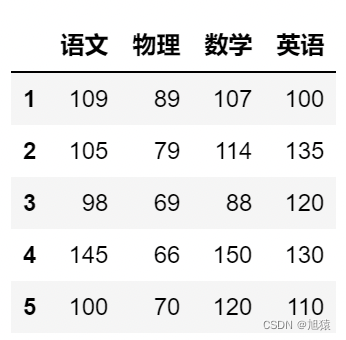
df.index = index # 还原
df
3.2.2 通过rename方法
dct = {'刘备':'101',
'关羽':'102',
'张飞':'103',
'诸葛亮':'104',
'赵云':'105'} # 定义字典,键为修改前的索引名称,值为修改后的索引名称
df.rename(dct,axis=0)
df
df.rename(index=dct,inplace=True) # inplace = True 表示将修改后的数据在原来变量修改
df
4.修改数据
4.1 修改整行数据
df.index = index
df
df.loc['张飞'] = [100,95,90,85]
df
4.2 修改整列数据
df.loc[:,'英语'] = [95,94,93,92,91]
df 
4.3 修改张飞的各科成绩
- 各科均加10分
df.loc['张飞'] = df.loc['张飞'] + 10
df 
4.4 修改张飞的语文成绩
df.loc['张飞','语文'] = 102
df
4.5 修改第1行第1列数据
- 使用iloc方法
df.iloc[0,0] = 120
df 
4.6 修改整列数据,第1列
- 使用iloc方法
df.iloc[:,0] = [130,110,105,130,110]
df 
4.7 修改整行数据,第1行
- 使用iloc方法
df.iloc[0,:] = [120,80,100,90]
df 
df.iloc[0] = [100,100,100,100]
df 
5.删除数据
5.1 删除列数据
- 传输列表,则删除多列
df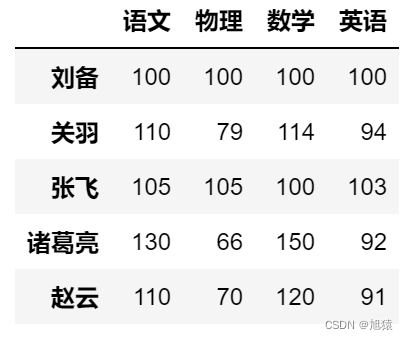
df.drop(columns='数学') # 默认不会修改原数据,设置inplace=True则修改原数据
df.drop(labels='数学',axis=1)
5.2 删除行数据
- 传输列表,则删除多行
df.drop(index='张飞') 
df.drop(labels='张飞',axis=0)
5.3 删除指定条件的行
5.3.1 删除“物理”等于70或79的行
df['物理'].isin([70,79]) # 值判断刘备 False 关羽 True 张飞 False 诸葛亮 False 赵云 True Name: 物理, dtype: bool
df[df['物理'].isin([70,79])] # 筛选符合的
df[df['物理'].isin([70,79])].index # 获取行索引Index(['关羽', '赵云'], dtype='object')
df.drop(index=df[df['物理'].isin([70,79])].index) # 根据获取的行索引删除行
5.3.2 删除“语文”小于120的行
df['语文'] < 120刘备 True 关羽 True 张飞 True 诸葛亮 False 赵云 True Name: 语文, dtype: bool
df[df['语文'] < 120].indexIndex(['刘备', '关羽', '张飞', '赵云'], dtype='object')
df.drop(index=df[df['语文'] < 120].index)
七、数据清洗
import pandas as pd1.导入数据
df = pd.read_excel('./data/demo_07.xlsx', sheet_name='Sheet1')
df
2. 查看是否缺失
2.1 查看字段信息
df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 14 entries, 0 to 13 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 用户ID 14 non-null object 1 付款金额 14 non-null float64 2 产品数量 11 non-null float64 3 产品名称 12 non-null object 4 类别 9 non-null object 5 订单付款时间 14 non-null datetime64[ns] dtypes: datetime64[ns](1), float64(2), object(3) memory usage: 800.0+ bytes
2.2 查看每列的空值数量
df.isnull().sum()用户ID 0 付款金额 0 产品数量 3 产品名称 2 类别 5 订单付款时间 0 dtype: int64
2.3 查看每列是否存在空值
df.isnull().any() # 返回值是True表示存在空值用户ID False 付款金额 False 产品数量 True 产品名称 True 类别 True 订单付款时间 False dtype: bool
2.4 判断每个元素是否非空
df.notnull()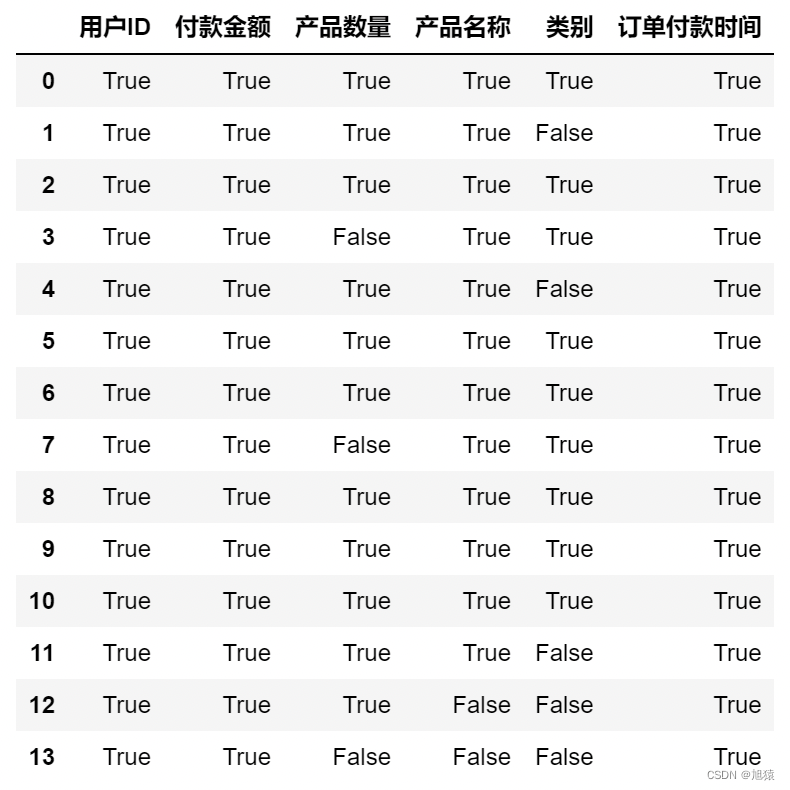
#查看每列是否都不存在空值
df.notnull().all() # 值为True表示该列无空值用户ID True 付款金额 True 产品数量 False 产品名称 False 类别 False 订单付款时间 True dtype: bool
3. 处理缺失值
3.1 填充缺失值方法
- 均值(mean)
- 众数(mode)
- 中位数(median)
3.2 众数填充
df
df['产品数量'].mode() # 返回值为一个数据结构0 5.0 dtype: float64
df['产品数量'].mode()[0] # 获得第一个众数5.0
df['产品数量'].mode()[0].mean() # 获得多个众数的均值5.0
# 用第一个众数填充
mode = df['产品数量'].mode()[0]
df['产品数量'].fillna(mode) # 不修改原表数据,需要重新赋值0 3.0 1 5.0 2 4.0 3 5.0 4 5.0 5 6.0 6 7.0 7 5.0 8 5.0 9 6.0 10 3.0 11 5.0 12 5.0 13 5.0 Name: 产品数量, dtype: float64
3.3 频数最高的“类别”填充
most = df['类别'].mode()[0]
df['类别'].fillna(most)0 优选 1 优选 2 优选 3 优选 4 优选 5 普通 6 普通 7 优选 8 优选 9 优选 10 优选 11 优选 12 优选 13 优选 Name: 类别, dtype: object
3.4 向前/向后填充
# ffill:向前填充
df['类别'].fillna(method='ffill')0 优选 1 优选 2 优选 3 优选 4 优选 5 普通 6 普通 7 优选 8 优选 9 优选 10 优选 11 优选 12 优选 13 优选 Name: 类别, dtype: object
# bfill:向后填充
df['类别'].fillna(method='bfill')0 优选 1 优选 2 优选 3 优选 4 普通 5 普通 6 普通 7 优选 8 优选 9 优选 10 优选 11 NaN 12 NaN 13 NaN Name: 类别, dtype: object
3.5 删除缺失值
# 删除存在空值的行,整表判断
df.dropna() # 不修改原数据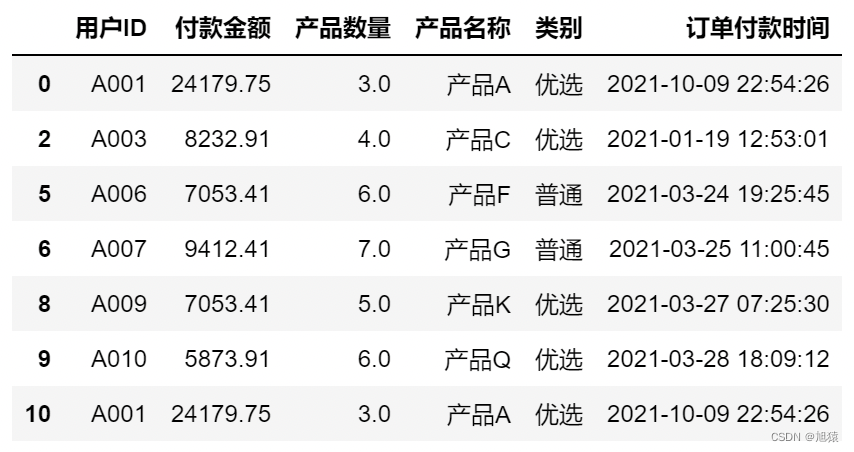
# 删除指定列存在空值的行,其中一列存在空值则删除整行
df.dropna(how='any',subset=['产品数量','产品名称'])
# 删除指定列均为空值的行
df.dropna(how='all',subset=['产品数量','类别'])
# 删除小于4个非空值的行
df.dropna(thresh=4)
4.处理重复值
df = pd.read_excel('./data/demo_07.xlsx', sheet_name='Sheet1')
df
4.1 判断每行是否完全重复
df.duplicated() # 返回值为True表示改行与前面行的其中一行的所有值完全重复0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 True 11 False 12 False 13 False dtype: bool
4.2 删除整行完全重复的数据
df.drop_duplicates(keep='last') # 保留最后一条,默认keep='first'保留第一条
4.3 删除指定列的重复数据
- 保留第1条
df.drop_duplicates(subset='用户ID') # 按照‘用户ID’判断重复,有重复整行删除,保留重复中的第一条数据 
- 保留最后1条
df.drop_duplicates(subset='用户ID',keep='last') 
4.4 删除指定多列的重复数据
- 保留最后1条
df.drop_duplicates(subset=['用户ID','产品名称'],keep='last') 
5. 数据筛选
df = pd.read_excel('./data/demo_07.xlsx', sheet_name='Sheet1')5.1 query方法筛选
- and、or、not,&、|、~
df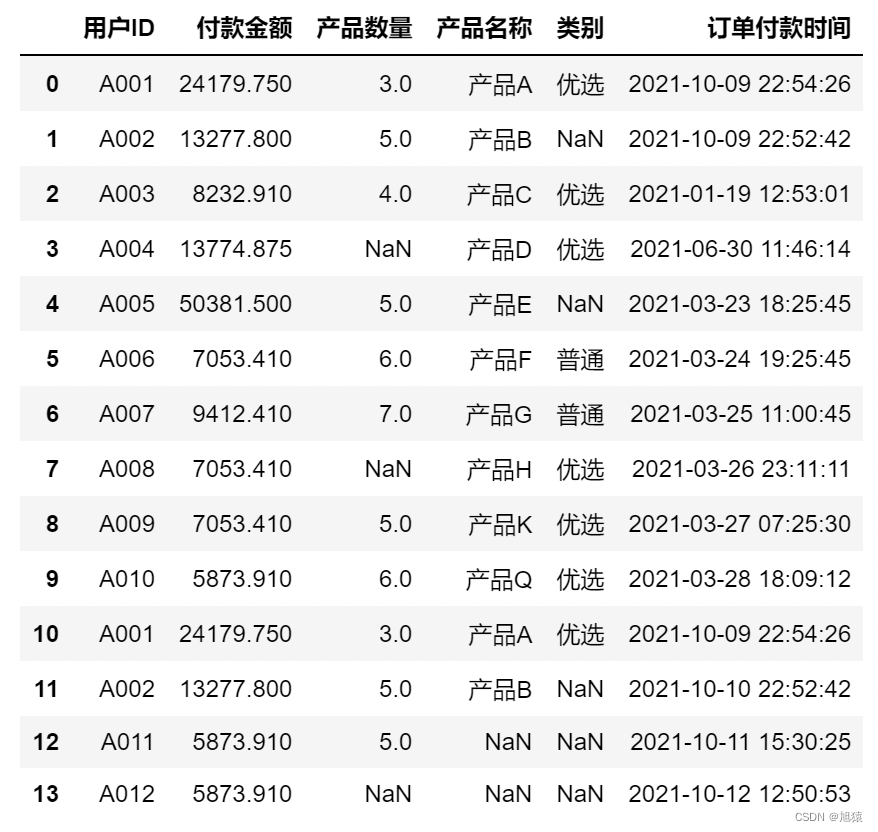
df.query('产品数量 >=2 ') # 获取产品数量大于等于2的数据 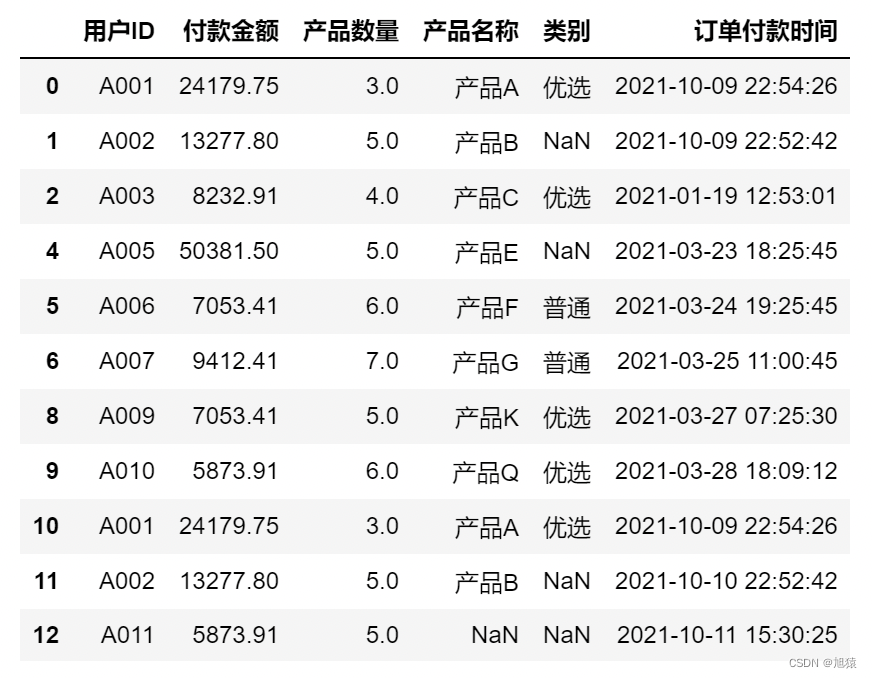
#文本筛选
df.query('类别 == "优选"') # 获取类别为优选的数据,文本筛选,筛选的值需要加引号
#组合筛选
df.query('类别=="优选" and 产品数量 >= 2 ')
5.2 数值范围筛选
# pd.Series.between(self, left, right, inclusive=True)
df['产品数量'].between(3,5)0 True 1 True 2 True 3 False 4 True 5 False 6 False 7 False 8 True 9 False 10 True 11 True 12 True 13 False Name: 产品数量, dtype: bool
df[df['产品数量'].between(3,5)] # 包含开始结束值
5.3 时间段筛选
- 12:00:00-23:00:00
# 将时间字段设置为索引
tb = df.set_index('订单付款时间')
tb 
# pd.Series.between_time(
# self: 'FrameOrSeries',
# start_time,
# end_time,
# include_start: 'bool_t' = True,
# include_end: 'bool_t' = True,
# axis=None,
# )
tb.between_time('12:00:00','23:00:00') # between_time函数筛选必须设置日期时间索引
5.4 时间点筛选
- 22:54:26
# .at_time(time, asof: 'bool_t' = False, axis=None)
tb = df.set_index('订单付款时间')
tb.at_time('22:54:26')
6. 数据清洗
- str,dt
6.1 导入数据
df = pd.read_excel('./data/demo_07.xlsx', sheet_name='Sheet2')
df 
6.2 普通方法筛选
# .filter(
# items=None,
# like: 'Optional[str]' = None,
# regex: 'Optional[str]' = None,
# axis=None,
# )
df.filter(items=['用户ID','第1次交易金额']) 
6.3 正则方法筛选
df.filter(regex='用户ID|第\d+次交易金额')
df.filter(regex='用户ID|第[1-8]次交易金额') 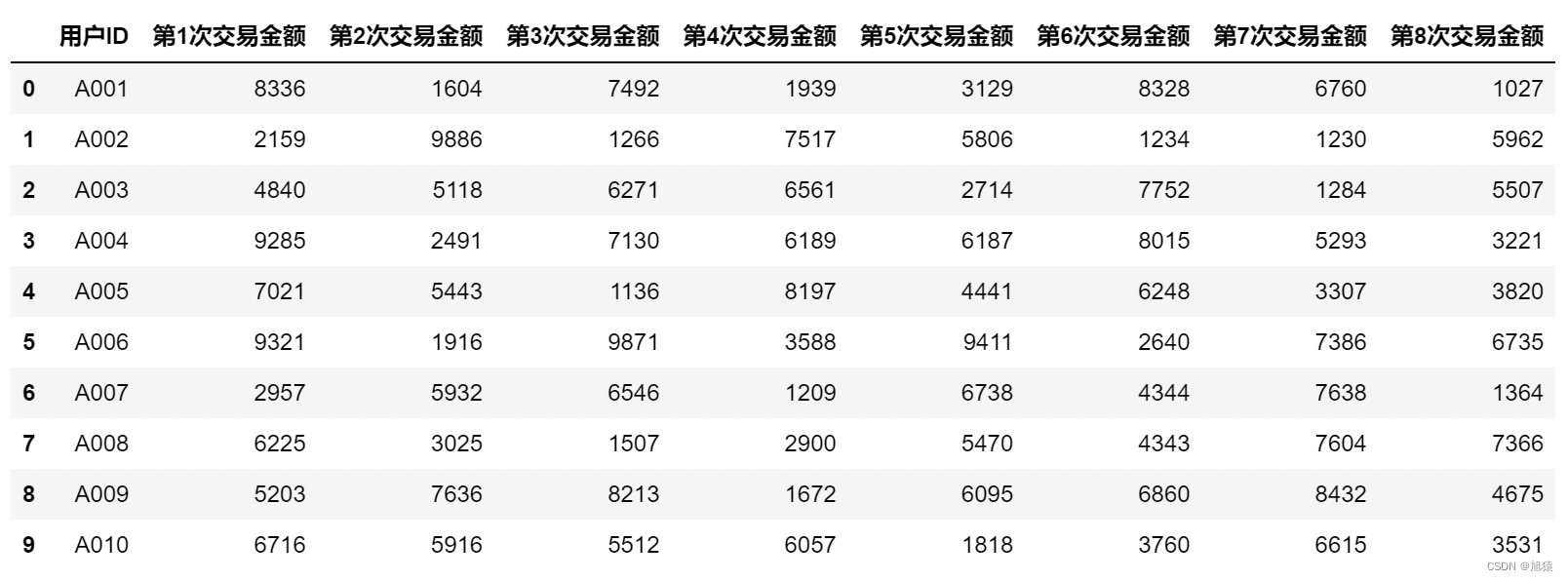
6.4 字段分列
- pd.Series.str.split()
# pd.Series.str.split(self, pat=None, n=-1, expand=False)
df['用户信息'].str.split(',',expand=True) # 设置分隔符时要确定是中文还是英文符号,默认不加入原表 
#将分裂好的字段插入到表中
df[['性别','年龄']] = df['用户信息'].str.split(',',expand=True)
df
6.5 字段合并
- pd.Series.str.cat()
#pd.Series.str.cat(self, others=None, sep=None, na_rep=None, join='left')
df['性别'].str.cat(df['年龄'],',')0 女,34 1 男,22 2 女,24 3 男,48 4 男,32 5 男,38 6 女,24 7 女,43 8 女,41 9 男,26 Name: 性别, dtype: object
df['性别'] + ',' + df['年龄']0 女,34 1 男,22 2 女,24 3 男,48 4 男,32 5 男,38 6 女,24 7 女,43 8 女,41 9 男,26 dtype: object
6.6 内容替换
- pd.Series.str.replace()
# pd.Series.str.replace(
# self,
# pat,
# repl,
# n=-1,
# case=None,
# flags=0,
# regex=None,
# )
df['交易金额'] = df['交易金额'].str.replace('元','')
df['交易金额'] = df['交易金额'].astype(int) # 修改字段类型为整型
df['交易金额']0 43154 1 40398 2 54026 3 58610 4 47180 5 64875 6 52912 7 48676 8 54220 9 50153 Name: 交易金额, dtype: int32
6.7 信息提取
- pd.Series.str.extract()
#pd.Series.str.extract(self, pat, flags=0, expand=True)
#匹配手机号
df['手机号码'] = df['联系方式'].str.extract(pat='(\d{11})',expand=True)
df['手机号码']0 15985958961 1 13551067802 2 13682396462 3 18615205809 4 13862393688 5 13717850943 6 13524312139 7 18914085419 8 15674526730 9 15676911440 Name: 手机号码, dtype: object
#匹配邮箱
df['电子邮箱'] = df['联系方式'].str.extract(pat='(\w+@[\w\.]+)')
df['电子邮箱']0 dingqiang@junliang.cn 1 mingkong@hotmail.com 2 gujuan@juan.cn 3 chaoding@yahoo.com 4 xiulangong@hotmail.com 5 wei15@hotmail.com 6 lijiang@gmail.com 7 xiulanpan@hotmail.com 8 jing70@gmail.com 9 qiangfu@zhaoren.net Name: 电子邮箱, dtype: object
6.8 爆炸序列
- 一行拆分成多行
tb = df[['用户ID','产品清单']].copy()
tb
# 先转换为列表,再爆炸序列
tb['产品清单'] = tb['产品清单'].str.split(',',expand=False)
tb['产品清单']0 [产品D, 产品C] 1 [产品E, 产品A] 2 [产品D, 产品E] 3 [产品D, 产品B] 4 [产品A, 产品C] 5 [产品A, 产品D] 6 [产品D, 产品A] 7 [产品C, 产品D] 8 [产品A, 产品B] 9 [产品B, 产品D] Name: 产品清单, dtype: object
tb = tb.explode(column='产品清单')
tb
6.9 文本聚合
- 多行合并成一行
tb = tb.groupby('用户ID').agg(lambda x: ','.join(x))
tb 
tb.reset_index() # 将索引设置为字段并生成一个新的索引
八、索引设置
import pandas as pd1. Series重置索引
1.1 创建Series对象
s1 = pd.Series(
data=[88, 60, 75],
index=[1, 2, 3])
s11 88 2 60 3 75 dtype: int64
1.2 重置索引操作
- 新索引:[1, 2, 3, 4, 5]
- 新索引的长度大于原索引,则以NaN填充
s2 = s1.reindex([1,2,3,4,5])
s21 88.0 2 60.0 3 75.0 4 NaN 5 NaN dtype: float64
2. DataFrame重置索引
2.1 创建DataFrame对象
data = [[110, 105, 99],
[105, 88, 115],
[109, 120, 130]]
index = ['A001', 'A003', 'A005']
columns = ['语文', '数学', '英语']
df = pd.DataFrame(
data=data,
index=index,
columns=columns)
df
2.2 重置行列索引
# .reindex(
# labels=None,
# index=None,
# columns=None,
# axis=None,
# method=None,
# copy=True,
# level=None,
# fill_value=nan,
# limit=None,
# tolerance=None,
# )
index = ['A001','A002','A003','A004','A005','A006']
columns = ['语文','数学','英语','物理']
tb = df.reindex(index=index, columns=columns)
tb
#reindex 对索引重新赋值
#set_index 将某字段设置为索引
#reset_index 重置索引从0开始
df = pd.read_excel('./data/demo_08.xlsx')
df
#将用户ID设置为索引
tb = df.set_index('用户ID')
tb.head()
tb = tb.reset_index()
tb.head()
九、数据排序
import pandas as pd1. 导入数据
df = pd.read_excel('./data/demo_09.xlsx')
df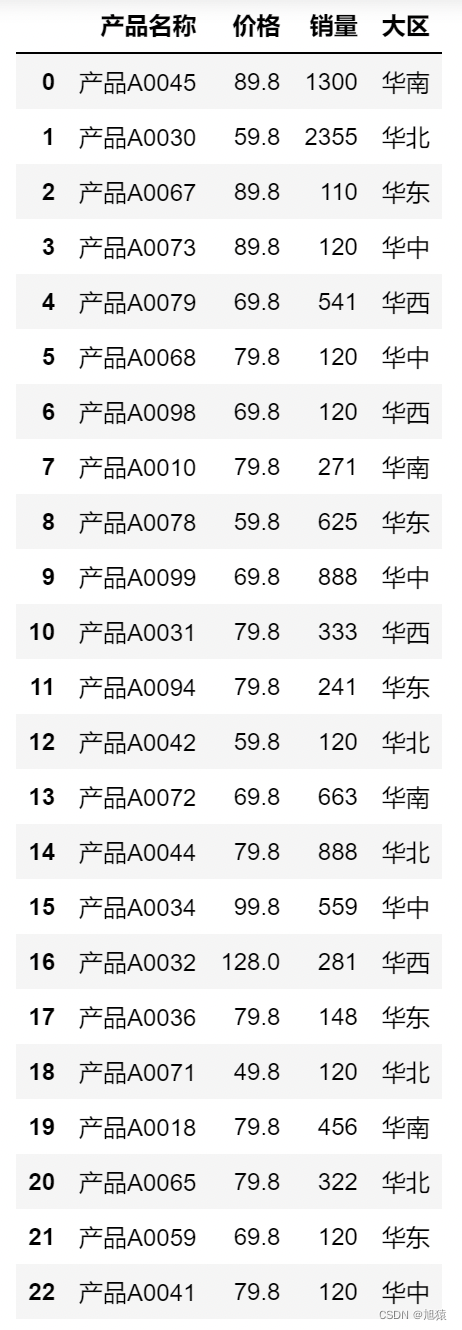
2. 按一列排序
# .sort_values(
# by,
# axis=0,
# ascending=True,
# inplace=False,
# kind='quicksort',
# na_position='last',
# ignore_index=False,
# key: 'ValueKeyFunc' = None,
# )
df.sort_values(by='销量',ascending=False)
#ascending=True 升序
#ascending=False 降序 
df.sort_values(by='销量',ascending=False,ignore_index=True) #ignore_index=True 重置索引
3. 按多列排序
- 排序方式相同,均为升序或降序
df.sort_values(by=['大区','销量'],ascending=False)
4. 按多列排序
- 排序方式不同,一列升序一列降序
df.sort_values(by=['大区','销量'],ascending=[True,False])
5. 对分组统计结果排序
#分组聚合
df.groupby('大区')['销量'].sum().reset_index()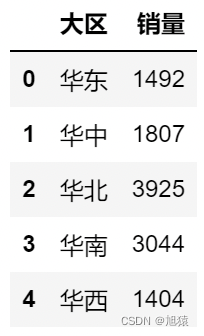
#排序
df.groupby('大区')['销量'].sum().reset_index().sort_values(by='销量',ascending=False,ignore_index=True) 
6. rank方法排序
- method : {'average', 'min', 'max', 'first', 'dense'}
# .rank(
# axis=0,
# method: 'str' = 'average',
# numeric_only: 'Optional[bool_t]' = None,
# na_option: 'str' = 'keep',
# ascending: 'bool_t' = True,
# pct: 'bool_t' = False,
# )
df['排名(average)'] = df['销量'].rank(method='average',ascending=False)
# 类似于SQL的rank
df['排名(min)'] = df['销量'].rank(method='min',ascending=False)
df['排名(max)'] = df['销量'].rank(method='max',ascending=False)
#类似于SQL的row_number
df['排名(first)'] = df['销量'].rank(method='first',ascending=False)
#类似于SQL的dense_rank
df['排名(dense)'] = df['销量'].rank(method='dense',ascending=False)
df 
#将数据导到excel文件
df.to_excel('./排名.xlsx')| 产品名称 | 价格 | 销量 | 大区 | 排名(average) | 排名(min) | 排名(max) | 排名(first) | 排名(dense) | |
| 1 | 产品A0030 | 59.8 | 2355 | 华北 | 1 | 1 | 1 | 1 | 1 |
| 0 | 产品A0045 | 89.8 | 1300 | 华南 | 2 | 2 | 2 | 2 | 2 |
| 9 | 产品A0099 | 69.8 | 888 | 华中 | 3.5 | 3 | 4 | 3 | 3 |
| 14 | 产品A0044 | 79.8 | 888 | 华北 | 3.5 | 3 | 4 | 4 | 3 |
| 13 | 产品A0072 | 69.8 | 663 | 华南 | 5 | 5 | 5 | 5 | 4 |
| 8 | 产品A0078 | 59.8 | 625 | 华东 | 6 | 6 | 6 | 6 | 5 |
| 15 | 产品A0034 | 99.8 | 559 | 华中 | 7 | 7 | 7 | 7 | 6 |
| 4 | 产品A0079 | 69.8 | 541 | 华西 | 8 | 8 | 8 | 8 | 7 |
| 19 | 产品A0018 | 79.8 | 456 | 华南 | 9 | 9 | 9 | 9 | 8 |
| 25 | 产品A0090 | 69.8 | 354 | 华南 | 10 | 10 | 10 | 10 | 9 |
| 10 | 产品A0031 | 79.8 | 333 | 华西 | 11 | 11 | 11 | 11 | 10 |
| 20 | 产品A0065 | 79.8 | 322 | 华北 | 12 | 12 | 12 | 12 | 11 |
| 16 | 产品A0032 | 128 | 281 | 华西 | 13 | 13 | 13 | 13 | 12 |
| 7 | 产品A0010 | 79.8 | 271 | 华南 | 14 | 14 | 14 | 14 | 13 |
| 26 | 产品A0026 | 79.8 | 248 | 华东 | 15 | 15 | 15 | 15 | 14 |
| 11 | 产品A0094 | 79.8 | 241 | 华东 | 16 | 16 | 16 | 16 | 15 |
| 17 | 产品A0036 | 79.8 | 148 | 华东 | 17 | 17 | 17 | 17 | 16 |
| 23 | 产品A0077 | 69.8 | 129 | 华西 | 18 | 18 | 18 | 18 | 17 |
| 3 | 产品A0073 | 89.8 | 120 | 华中 | 22.5 | 19 | 26 | 19 | 18 |
| 5 | 产品A0068 | 79.8 | 120 | 华中 | 22.5 | 19 | 26 | 20 | 18 |
| 6 | 产品A0098 | 69.8 | 120 | 华西 | 22.5 | 19 | 26 | 21 | 18 |
| 12 | 产品A0042 | 59.8 | 120 | 华北 | 22.5 | 19 | 26 | 22 | 18 |
| 18 | 产品A0071 | 49.8 | 120 | 华北 | 22.5 | 19 | 26 | 23 | 18 |
| 21 | 产品A0059 | 69.8 | 120 | 华东 | 22.5 | 19 | 26 | 24 | 18 |
| 22 | 产品A0041 | 79.8 | 120 | 华中 | 22.5 | 19 | 26 | 25 | 18 |
| 24 | 产品A0058 | 69.8 | 120 | 华北 | 22.5 | 19 | 26 | 26 | 18 |
| 2 | 产品A0067 | 89.8 | 110 | 华东 | 27 | 27 | 27 | 27 | 19 |
十、pandasql
import pandas as pd
from pandasql import sqldf
# pip install pandasql
# sqlite3数据库SQL语言
#设置全局变量
pysqldf = lambda q: sqldf(q, globals())
#读取df
df = pd.read_excel('./data/demo_09.xlsx')
df.head()
# 编写sql
sql = '''
select 大区, sum(销量) as 销量
from df
where 产品名称='产品A0045'
group by 大区
'''
#运行sql语句
pysqldf(sql)
sql = '''
select 大区, sum(销量) as 销量
from df
group by 大区
having sum(销量) > 1500
order by sum(销量) desc
'''
#where 分组前的筛选
#having 分组后的筛选
pysqldf(sql)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









