






深度学习算法在目标识别分类任务上取得了飞快的进展,也取得了优异的效果,本文将重点介绍如何运用YOLOv8模型进行目标分类检测任务,以口罩的分类为例。
0.环境准备:首先需要安装配置好深度学习相关的环境。
1.模型的搭建:模型框架源于Github网站,模型的代码层次如图所示。
2.数据集的准备(标注):为了制作合适的口罩分类识别的数据集,先从网上寻找一部分开源的数据集,并根据程序需要进行部分修改,然后通过自己爬虫采取的方式寻找到一部分合适的图片,使用 Labelimg工具对其进行标注,标注完成后会生成与图片对应的txt文档,这里要保证图片与txt文档一 一对应,标注过程如图所示。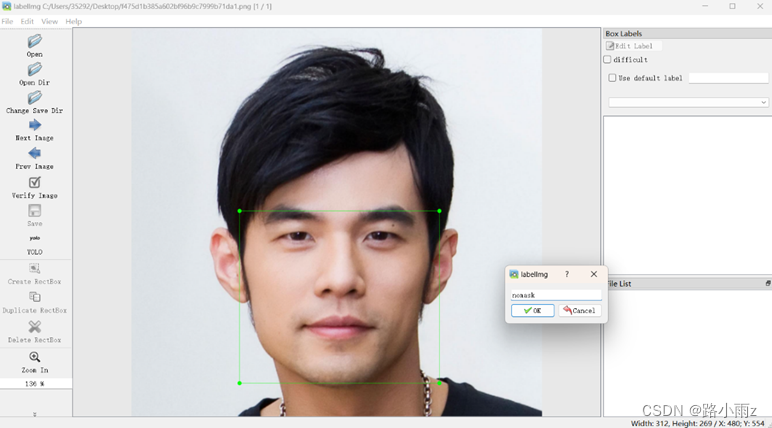
数据集中各类别图片数量:
| 图片种类 | 数量 |
| all cloth(布口罩) kn95 n95 surgical nomask | 2606 740 422 422 422 600 |
3.启动训练:YOLOv8模型搭建好后,将整理好的数据集文件放入datasets文件夹,在入口程序中编写好启动YOLO训练的代码,指定好训练集中的data.yaml文件所在路径。
在data.yaml文件中指定训练集、验证集以及测试集中图片所在的路径,指定好口罩识别的标注种类(kn95、n95、cloth、surgical、Nomask)。调配好训练参数后便可以进行模型训练。本实验进行200轮的模型训练,入口程序代码如下:
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('yolov8n.yaml').load('yolov8n.pt') #加载模型和预训练权重
model.train(data=r'D:\ultralytics-main\datasets\mask\data.yaml', epochs=200, imgsz=640, workers=1, amp=True) #训练数据集路径data.yaml文档中的内容如下:
【train: ../train/images
val: ../valid/images
test: ../test/images
nc: 5
names: ['Nomask', 'cloth', 'kn95', 'n95', 'surgical']
】
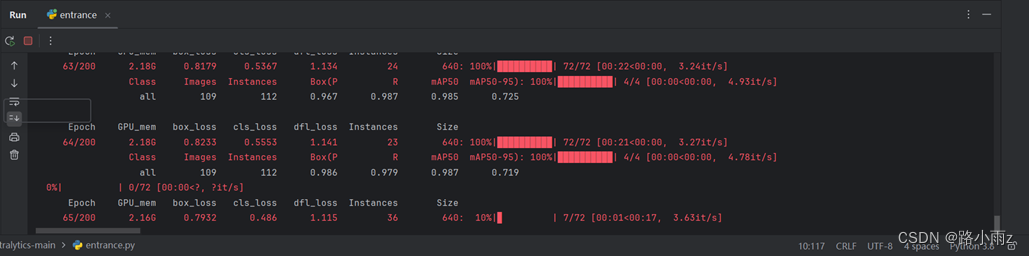
训练过程图:
4.最后,为了进一步对训练结果进行验证,可以编写一个可以进行图片上传并给出验证结果的可视化界面。
可视化界面的编写采用Python中的PyQT5库来实现,运行程序后出现一个可以上传图片并且给出相应结果的可视化界面。通过指定路径将程序与YOLOv8项目中200轮训练生成的的文件夹中的best.pt相连。这样就可以通过识别上传图片来验证模型的训练效果,这也是整个可视化界面编写过程中核心的一步。可视化界面编写的代码如下:
from PyQt5.QtWidgets import QApplication, QMainWindow, QFileDialog
import sys
from PyQt5 import QtCore, QtGui, QtWidgets
import torch
import torchvision
from ultralytics import YOLO
class Ui_MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setupUi(self)
self.retranslateUi(self)
def setupUi(self, MainWindow): # 设置界面的组件,包括主窗口、按钮、标签等
MainWindow.setObjectName("MainWindow")
MainWindow.resize(1128, 1009)
self.centralwidget = QtWidgets.QWidget(MainWindow)
self.centralwidget.setObjectName("centralwidget")
self.pushButton = QtWidgets.QPushButton(self.centralwidget)
self.pushButton.setGeometry(QtCore.QRect(20, 10, 93, 28))
self.pushButton.setObjectName("pushButton")
self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget)
self.pushButton_2.setGeometry(QtCore.QRect(160, 10, 93, 28))
self.pushButton_2.setObjectName("pushButton_2")
self.pushButton_3 = QtWidgets.QPushButton(self.centralwidget)
self.pushButton_3.setGeometry(QtCore.QRect(290, 10, 93, 28))
self.pushButton_3.setObjectName("pushButton_3")
self.label1 = QtWidgets.QTextBrowser(self.centralwidget)
self.label1.setGeometry(QtCore.QRect(20, 60, 1071, 71))
self.label1.setObjectName("label1")
self.label2 = QtWidgets.QLabel(self.centralwidget)
self.label2.setGeometry(QtCore.QRect(40, 190, 481, 421))
self.label2.setObjectName("label2")
self.label3 = QtWidgets.QLabel(self.centralwidget)
self.label3.setGeometry(QtCore.QRect(600, 200, 461, 381))
self.label3.setObjectName("label3")
MainWindow.setCentralWidget(self.centralwidget)
self.menubar = QtWidgets.QMenuBar(MainWindow)
self.menubar.setGeometry(QtCore.QRect(0, 0, 1128, 26))
self.menubar.setObjectName("menubar")
MainWindow.setMenuBar(self.menubar)
self.statusbar = QtWidgets.QStatusBar(MainWindow)
self.statusbar.setObjectName("statusbar")
MainWindow.setStatusBar(self.statusbar)
self.retranslateUi(MainWindow)
QtCore.QMetaObject.connectSlotsByName(MainWindow)
# 点击响应函数
self.pushButton.clicked.connect(self.uploadImage)
self.pushButton_2.clicked.connect(self.showEnvironment)
self.pushButton_3.clicked.connect(self.startProgram)
# self.image_path = ''
def retranslateUi(self, MainWindow): # 设置界面各个组件的文本内容。
_translate = QtCore.QCoreApplication.translate
MainWindow.setWindowTitle(_translate("MainWindow", "MainWindow"))
self.pushButton.setText(_translate("MainWindow", "上传图片"))
self.pushButton_2.setText(_translate("MainWindow", "显示环境"))
self.pushButton_3.setText(_translate("MainWindow", "启动程序"))
self.label2.setText(_translate("MainWindow", "TextLabel"))
self.label3.setText(_translate("MainWindow", "TextLabel"))
def uploadImage(self):
file_dialog = QFileDialog()
image_path, _ = file_dialog.getOpenFileName(self, '选择图片', '', 'Images (*.png *.xpm *.jpg *.bmp)')
self.image_path = image_path
if image_path:
# 在这里添加加载图片的逻辑,例如显示图片到label2
pixmap = QtGui.QPixmap(image_path)
self.label2.setPixmap(pixmap)
self.label2.setScaledContents(True)
def showEnvironment(self):
pytorch_version = torch.__version__
torchvision_version = torchvision.__version__
self.label1.setText(f"PyTorch Version: {pytorch_version}\n"
f"Torchvision Version: {torchvision_version}")
def startProgram(self):
self.label1.setText(self.image_path)
model = YOLO('../runs/detect/train20/weights/best.pt')
results = model(self.image_path)
annotated_frame = results[0].plot()
height, width, channel = annotated_frame.shape
bytes_per_line = 3 * width
qimage = QtGui.QImage(annotated_frame.data, width, height, bytes_per_line, QtGui.QImage.Format_RGB888)
# 将QImage转换为QPixmap
pixmap = QtGui.QPixmap.fromImage(qimage)
# 都执行:
self.label3.setPixmap(pixmap)
self.label3.setScaledContents(True)
if __name__ == '__main__':
app = QApplication(sys.argv)
MainWindow1 = QMainWindow() # MainWindow1随便改
ui = Ui_MainWindow() # 随便改
ui.setupUi(MainWindow1)
MainWindow1.show()
sys.exit(app.exec_())可视化界面效果展示:

最后是效果验证,上传本地图片后便可验证目标分类的训练效果:
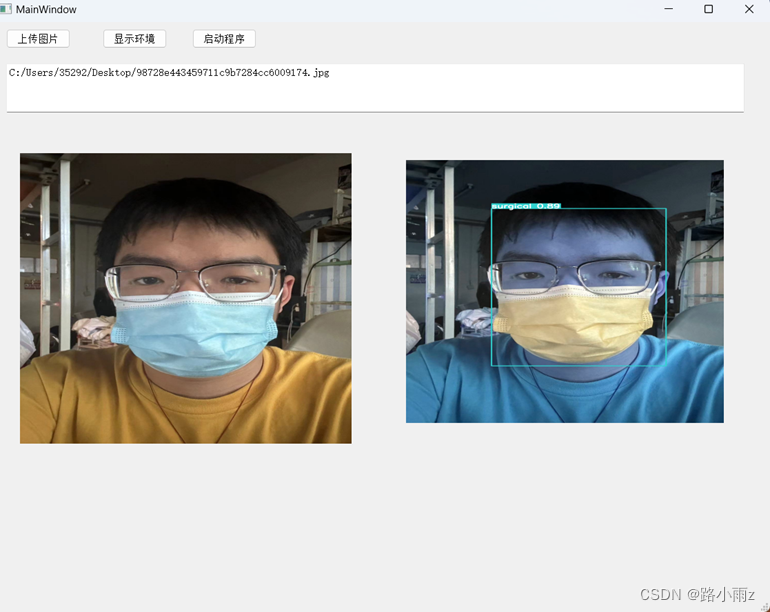
至此,口罩分类精准识别系统的雏形基本实现,但也存在着相当的不足,有待进一步改善和优化。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









