







1.岭回归的介绍:
岭回归也是回归分析中常用的线性模型,它实际上是一种改良的最小二乘法。
2.岭回归的原理:
岭回归实际上是一种能够避免过拟合的线性模型。在岭回归中,模型会保留所有的特征变了,但是会减小特征变量的系数值,让特征变量对预测结果的影响变小,在岭回归中是通过改变其alpha参数来控制减小特征变量系数的程度。而这种通过保留全部特征变量,只是降低特征变量的系数值来避免过拟合的方法,我们称之为L2正则化。
3.岭回归的实战:
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
#载入糖尿病情数据集
X,y=load_diabetes().data,load_diabetes().target
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=1)
#导入岭回归
from sklearn.linear_model import Ridge
#使用岭回归对数据进行拟合
ridge=Ridge().fit(X_train,y_train)
print('训练集得分:{}'.format(ridge.score(X_train,y_train)))
print('测试集得分:{}'.format(ridge.score(X_test,y_test)))
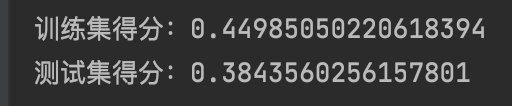
结果分析:
使用岭回归后,训练数据集的得分比线性回归中的要稍微低调一些,而测试数据集的得分却高了一些,这和我们的预期基本是一致的。在线性回归中,我们的模型出现了轻微的过拟合,但是由于岭回归是一个相对受限的模型,所以我们发生过拟合的可能性大大降低了。可以说,复杂度越低的模型,在训练数据集上的表现越差,但是其泛化能力会更好。如果我们更在意模型在泛化方面的表现,那么我们就应该选择岭回归模型,而不是线性回归模型。
4.岭回归的参数调节:
岭回归是在模型的简单性(使系数趋近于0)和它在训练集上的性能之间取得平衡的一种模型。用户可以使用alpha参数控制模型更加简单性还是在训练集上的性能更高。在刚刚的案例中,我们使用的alpha为默认参数——1.
ps:alpha的取值并没有一定之规。alpha的最佳设置取决于我们使用的特定数据集。增加alpha的值会降低特征变量的系数,使其趋近于0,从而降低在训练集的性能,但更有助于泛化。
下面我们再看一个例子:
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
#载入糖尿病情数据集
X,y=load_diabetes().data,load_diabetes().target
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=1)
#导入岭回归
from sklearn.linear_model import Ridge
#使用岭回归对数据进行拟合
ridge=Ridge(alpha=10).fit(X_train,y_train)
print('训练集得分:{}'.format(ridge.score(X_train,y_train)))
print('测试集得分:{}'.format(ridge.score(X_test,y_test)))

结果分析:
在刚刚的例子中,我们提高了alpha参数的值为10,发现模型的得分大大的降低了,然而有意思是,测试集与训练集得分的差异变小了。这说明,如果我们的模型出现了过拟合,那么我们可以通过提高alpha的值来降低过拟合的程度。
同样,降低alpha的值会让系数的限制变得不那么严格,如果我们用一个非常小的alpha值,那么系统的限制几乎可以忽略不计,得到的结果也会非常的接近线性回归。
ps:随着数据量的增加,线性回归在训练数据集上的得分是下降的,这说明随着数据增加,线性回归模型就越不容易产生过拟合的现象,或者说越难记住这些数据。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









