









sklearn的基本建模流程:
1. 实例化,建立评估模型对象
2. 通过模型接口训练模型
3. 通过模型接口提取需要的信息
from sklearn import tree
clf = tree.DecisionTreeClassifier() #实例化
clf = clf.fit(X_train,y_train) #用训练集数据训练模型
result = clf.score(X_test,y_test) #导入测试集,从接口调用需要的信息决策树
1. 分类树
class sklearn.tree. DecisionTreeClassifier ( criterion=’gini’ , splitter=’best’ , max_depth=None ,min_samples_split=2 , min_samples_leaf=1 , min_weight_fraction_leaf=0.0 , max_features=None , random_state=None , max_leaf_nodes=None , min_impurity_decrease=0.0 , min_impurity_split=None ,class_weight=None , presort=False )
1.1. 模块:sklearn.tree
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split1.2. 决策树的建立(以load_wine数据集为例)
x_train,x_test,y_train,y_test=train_test_split(wine.data,wine.target,test_size=0.3)
##实例化
clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=30
,splitter="random")
clf = clf.fit(x_train,y_train)
score = clf.score(x_test,y_test)
##可视化
import graphviz
dot_data = tree.export_graphviz(clf
,feature_names=wine.feature_names
,class_names=["琴酒","雪莉","贝尔莫德"]
,filled=True,rounded=True)
graph = graphviz.Source(dot_data)
graph
##查看特征的贡献
clf.feature_importances_
##把特征进行匹配
[*zip(feature_name,clf.feature_importances_)]1.3. 重要参数
1.3.1 criterion
用来决定决策树的不纯度的衡量指标,有两种取值
entropy:信息熵 / 信息增益
gini :基尼系数
默认情况下会选择基尼系数
信息熵计算会慢一点,对不纯度更敏感,用信息熵为标准时生成的决策树会更精细,更贴近训练集,也更容易过拟合。主要取决于数据。数据噪音很大的时候用gini系数。
1.3.2 random_state
决策树内部实际上自带有随机化的过程,在建立决策树的时候,并不会选择全部的特征进行建树,而是会选择其中的一部分,因此需要通过random_state规定这个随机过程的方式。
可以通过设置random_state的参数进行多次测试,选出score最大的树。
1.3.3 splitter
也是用来控制决策树中的随机选项的,有两个值
"best":选择更重要的特征进行分枝
"random":随机进行分枝
用random的时候树会更深,更加随机,也是对抗过拟合的一种方式。
1.3.4 剪枝参数---核心问题
1. max_depth : 限制树的最大深度,建议从3开始尝试
2. min_samples_leaf & min_samples_split
min_samples_leaf: 规定每个叶子节点必须含有的最少样本数,那么如果分出来的节点达不到最小样本数要求,就不会进行划分。

例: **如在此树中,从上一个节点(49个样本)到下面分节点(左:46个样本,右:3个样本)的过程中,如果设置min_samples_leaf为5,则右边的分枝无法满足条件。
min_samples_split: 规定所有训练数据的最少样本数,即中间节点包含的最少样本的数量。
3. max_features & min_impurity_decrease
max_features:强制减少可以使用的特征数量,但这样的方法会限制决策树对数据的学习,因为强行减少了数据的信息量。
min_impurity_decrease:限制信息熵增益,即如果分层后的信息熵增益不够大,就放弃分类,也是提前结束分类的方法。
1.3.5 目标权重参数
用来解决样本不平衡的问题:class_weight & min_weight_fraction_leaf
1.3.6 如何确定最优的剪枝参数?
使用超参数曲线的方法。
可以使用matplotlib通过循环的方法画曲线。
1.4 重要属性和接口
主要用的有四个:fit score apply predict
fit: 模型训练接口
score: 分类效果的评判指标
apply:输入为x_test,即clf.apply(x_test),返回每个样本对应的叶节点的索引
predict: 输入为x_test,即clf.predict(x_test),返回对于每个样本的预测结果
2. 回归树
class sklearn.tree.DecisionTreeRegressor ( criterion=’mse’ , splitter=’best’ , max_depth=None , min_samples_split=2 , min_samples_leaf=1 , min_weight_fraction_leaf=0.0 , max_features=None , random_state=None , max_leaf_nodes=None , min_impurity_decrease=0.0 , min_impurity_split=None , presort=False )
回归树是怎么工作的
2.1 交叉验证
交叉验证是观察模型稳定性的一种方法,我们将数据划分为n份,依次使用其中一份作为测试集,其他n-1份作为训练集,多次计算模型的精确度来评估模型的平均准确程度。
2.1 重要参数
2.1.1 criterion
支持的标准有三种:mse、friedman_mse、mae
mse:均方误差,父节点和叶子节点之间的均方误差的差额将作为特征选择的标准,通过使用叶子节点的均值来最小化L2损失。
friedman_mse:费尔德曼均方误差。
mae:绝对平均误差,使用叶节点的中值来最小化L1损失。
要注意回归树的score接口返回的是,而不是MSE。
u是残差平方和,v是总平方和,N是样本量,i是每一个数据样本。可见,可以为正或为负,而均方误差永远为正。sklearn中使用的是负均方误差。
回归树案例:正弦曲线
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegression
##创建带有噪点的正弦数据
rng = np.random.RandomState(1) ##创建随机数种子
x = np.sort(5 * rng.rand(80,1),axis=0) ##生成0~5之间的80个随机数,并从小到大排序
y = np.sin(x).ravel() ##生成正弦数据
y[::5] += 3*(0.5-rng.rand(16)) ##在y上加入噪声数据
##创建回归模型
regression1 = DecisionTreeRegression(max_depth=3) ##3层回归
regression2 = DecisionTreeRegression(max_depth=5) ##5层回归
regression1.fit(x,y)
regression2.fit(x,y) ##模型训练
##模型结果测试
x_test = rng.rand(0,5,0.01)[:,np.newaxis] ##创建测试数据集,要进行升维操作
y_1 = regression1.predict(x_test)
y_2 = regression2.predict(x_test)
##画图展示结果
plt.figure(figsize=(20,8),dpi=80)
plt.scatter(x,y,s=20,edgecolors='black',c='darkorange',label='raw data')
plt.plot(x_test,y_1,color="cornflowerblue",label="max_depth=2", linewidth=2)
plt.plot(x_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
实例:泰坦尼克幸存者预测
1. 数据预处理过程:
数据导入----->数据清洗------>数据分割
数据和包的导入:
import numpy as np
from sklearn.tree import DecisionTreeClassifier,DecisionTreeRegressor
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import pandas as pd
from sklearn.model_selection import GridSearchCV
##数据导入
data = pd.read_csv("F:\\拜师培训\\sklearn\\决策树\\Taitanic data\\data.csv")
数据的预处理(重点):
##数据清洗
##特征筛选
data.drop(["Name","Cabin","Ticket"],inplace=True,axis=1) ##把无关的特征删掉
##处理缺省值
data["Age"] = data["Age"].fillna(data["Age"].mean()) ##用平均值对缺损进行填补
data = data.dropna() ##剩下缺损少的行直接删掉
##处理非数值数据 数据中的 "Sex","Embarked"为非数值型数据
data.loc[:,"Sex"] = (data.loc[:,"Sex"]=="male").astype("int") ##处理sex数据
type_list = data.loc[:,"Embarked"].unique().tolist()
data.loc[:,"Embarked"] = data.loc[:,"Embarked"].apply(lambda x: type_list.index(x))
##数据分割
x = data.loc[:,data.columns != "Survived"]
y = data.loc[:,data.columns == "Survived"]
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3)
for i in [x_train,x_test,y_train,y_test]: ##纠正乱序索引
i.index = range(i.shape[0])模型建立与参数优化:
1. max_depth参数的影响
score_tr = [] ##存放打分数据
score_te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25
,max_depth=i+1)
clf.fit(x_train,y_train)
score_train = clf.score(x_train,y_train)
score_test = cross_val_score(clf,x,y,cv=10).mean()
score_tr.append(score_train)
score_te.append(score_test)
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(1,11),score_te,color='red',label='test')
plt.plot(range(1,11),score_tr,color='blue',label='train')
plt.xticks(range(1,11))
plt.legend()
plt.show()
2. 改变模型评价方式为entropy
for i in range(10):
clf = DecisionTreeClassifier(random_state=25
,max_depth=i+1
,criterion='entropy'
)
clf.fit(x_train,y_train)
score_train = clf.score(x_train,y_train)
score_test = cross_val_score(clf,x,y,cv=10).mean()
score_tr.append(score_train)
score_te.append(score_test)
3. 用网格搜索的方法对多个参数进行优化
3.1 网格搜索是一种能够同时优化多个参数的方法,属于一种枚举方法
计算量大,耗时长
网格搜索的实现方法:
要给定需要搜索的参数范围
###通过网格搜索对多个参数进行优化
##首先要实例化模型
clf = DecisionTreeClassifier(random_state=25)
##通过np.linspace()来定义min_impurity_decrease的取值范围
gini_thresholds = np.linspace(0,0.5,20)
#entropy_thresholds = np.linspace(0,1,50)
##parameters是一串参数和这些参数对应的,我们希望网格搜索来搜索的参数的取值范围
##parameters是一个字典
parameters = {"criterion":("gini","entropy")
,"splitter":("best","random")
,"max_depth":[*range(1,10)]
,"min_samples_leaf":[*range(1,50,5)]
,"min_impurity_decrease":gini_thresholds}
GS = GridSearchCV(clf,parameters,cv=10)
GS.fit(x_train,y_train)
GS.best_params_##从我们输入的参数和参数值的列表中返回最优结果
GS.best_score_##网格搜索后模型的评判标准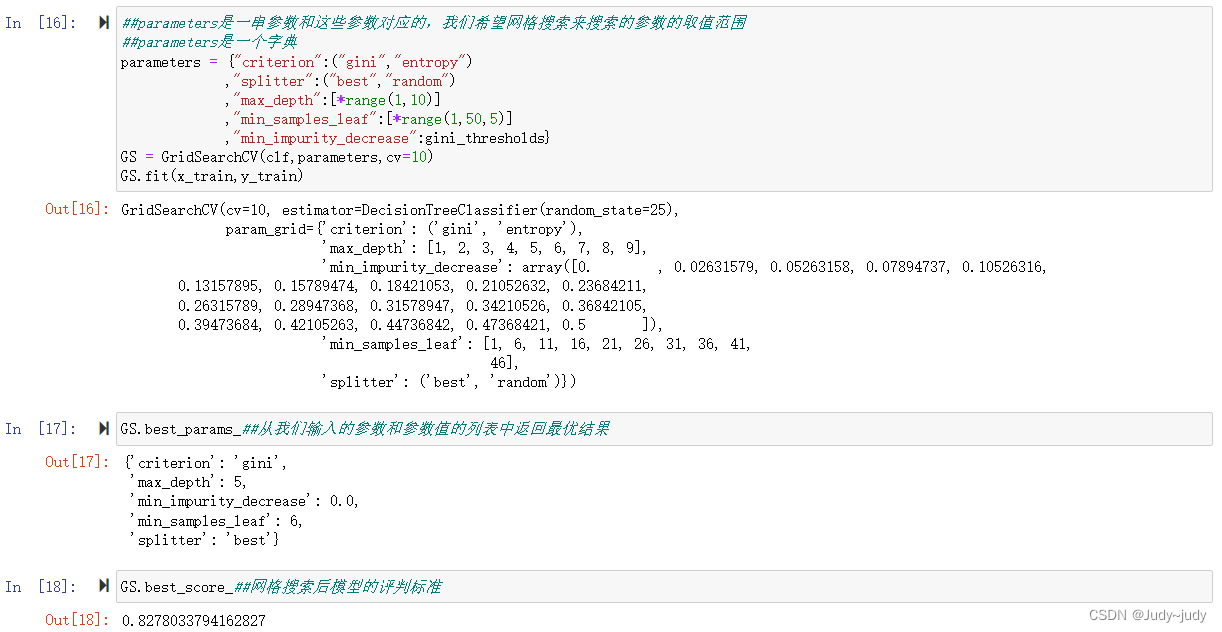














 1278
1278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









