







————————————————————————————————————
⏩ 大家好哇!我是小光,嵌入式爱好者,一个想要成为系统架构师的大三学生。
⏩最近在准备秋招,一直在练习编程。
⏩本篇文章对赛码网的 Light 题目做一个详解。
⏩感谢你的阅读,不对的地方欢迎指正。
————————————————————————————————————
题目:
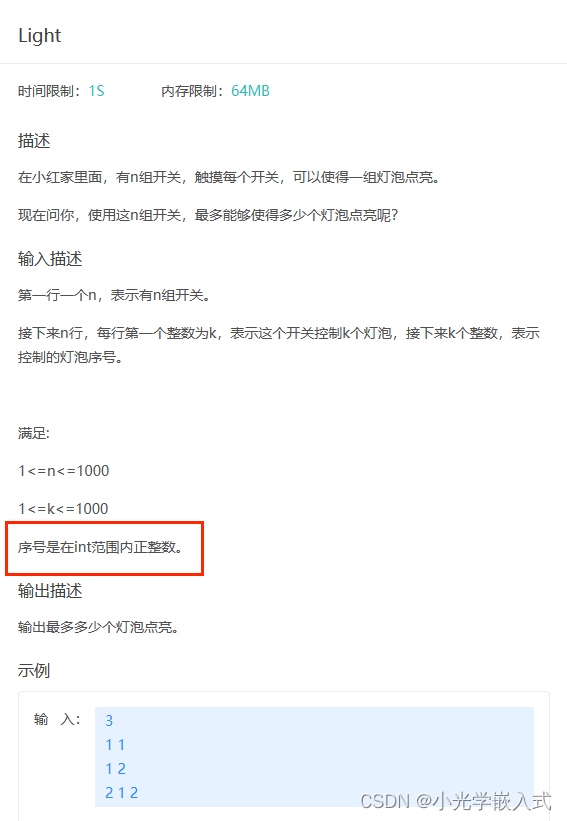
分析:其实这道题不难,只需要记录每一个序号出现的次数就可以了,第一种想法就是定义一个数组,对应的是序号出现的次数,但是题目要求序号的范围是0~2^31-1,所以我们使用哈希表来写:
这里我们使用了C++标准库中的unordered_map来实现哈希表。unordered_map提供了以键值对形式存储数据,并以O(1)的平均复杂度进行插入、查找和删除操作。
通过使用unordered_map,我们可以在遍历输入时统计每个灯泡的被控制次数,并且无需担心序号的范围限制。最后,我们遍历哈希表,计算出被控制次数大于等于1的灯泡数量。
#include <iostream>
#include <unordered_map>
using namespace std;
int main()
{
int n;
unordered_map<int,int> hash;
scanf("%d",&n);
for(int i = 0;i < n;i ++){
int k;
scanf("%d",&k);
for(int j = 0;j < k;j++){
int bot;
scanf("%d",&bot);
hash[bot]++;
}
}
printf("%d",hash.size());
return 0;
}
代码非常的简单,最后AC100%
















 201
201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











