







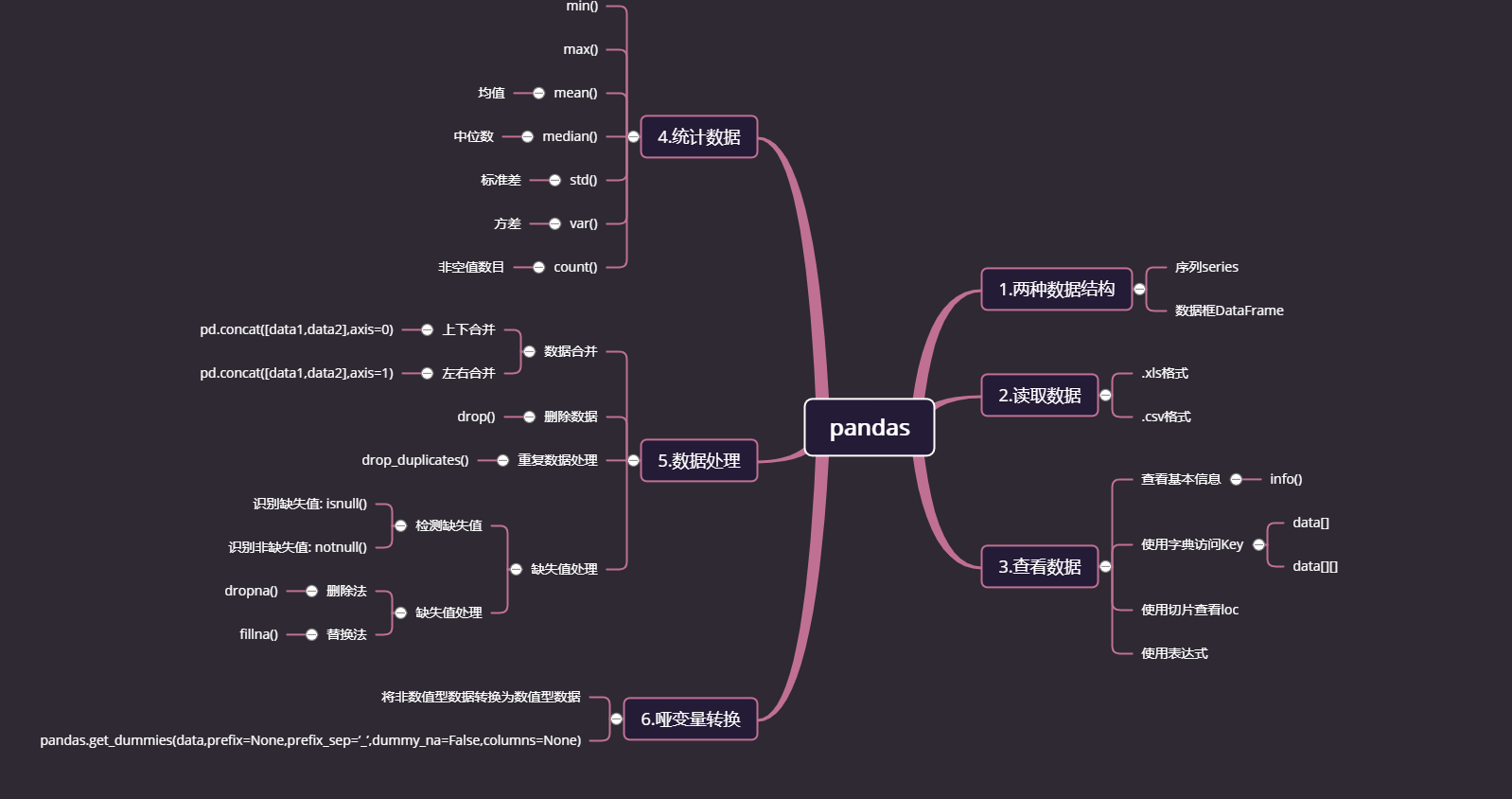
大纲:
1.pandas两种数据结构
1.1序列Series
1.1.1通过一维数组创建序列
import numpy as np
import pandas as np
arr1 = np.arange(10)
print(arr1)
s1 = pd.Series(arr1)
print(s1)
运行截图:

1.1.2通过字典创建序列
dic1 = {'a':10, 'b': 20, 'c':30, 'd':40}
s2 = pd.Series(dic1)
print(s2)
运行截图:

1.1.3通过列表创建序列
# 通过列表创建序列
lis = [1,2,3]
s3 = pd.Series(lis,index=['a','b','c'])
print(s3)
运行截图:

1.2数据框DataFrame
1.2.1通过二维数组创建
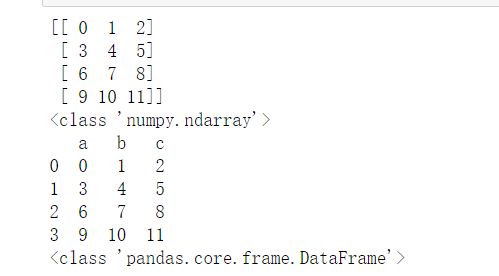
arr2 = np.arange(12).reshape(4,3)
print(arr2)
print(type(arr2))
df2 = pd.DataFrame(arr2,columns=['a','b','c'])
print(df2)
print(type(df2))
1.2.2通过字典方式创建
# 通过字典的方式创建
dic3 = {'a':[1,2,3,4], 'b':[5,6,7,8], 'c':[9,10,11,12], "d":[13,14,15,16]}
print(dic3)
df3 = pd.DataFrame(dic3)
print(df3)
运行截图:

1.2.3从已有的打他frame创建
# 从已有的打他frame中创建
df4 = df3[['b','d']]
print(df4)
运行截图:

2.读取数据
2.1读取xls数据集
import pandas as pd
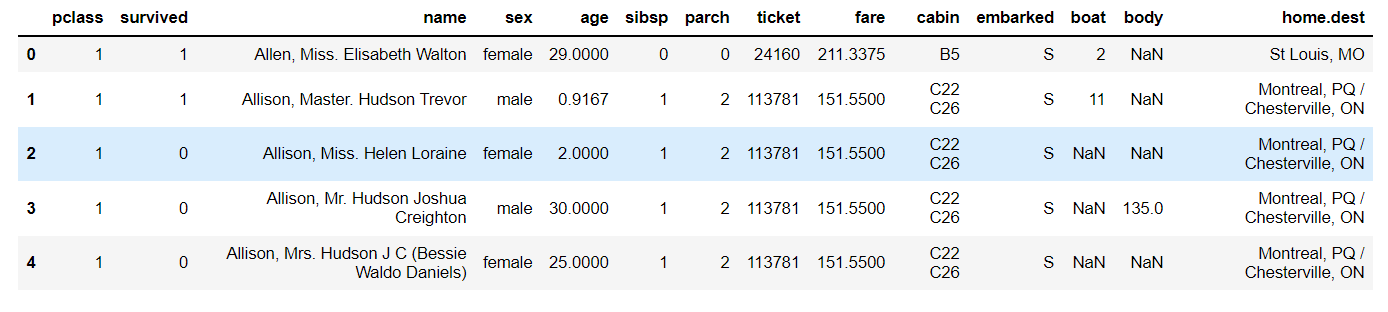
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
data.head()#显示前五行数据
运行截图:
2.2读取csv数据集
import pandas as pd
pm25 = pd.read_csv("D:\\桌面\\本学期课程\\BeijingPM2.5.csv",sep=",",encoding="utf-8")
pm25.tail()#显示最后5条数据
运行截图:

3.查看数据
3.1查看数据集基本信息
#查看基本数据信息
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
data.info()
运行截图:

3.2使用字典访问Key
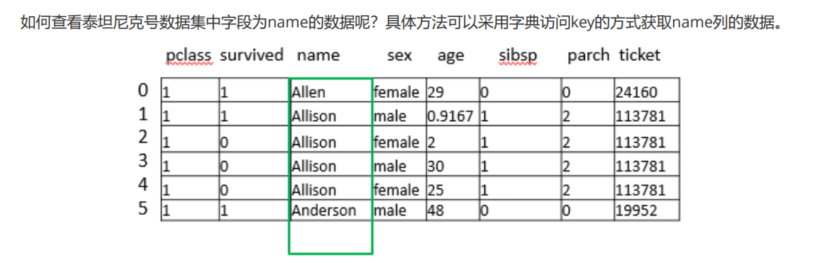
#使用字典访问key
#查看所有人的姓名
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
data1 = data['name']
print(data1)
print("*"*100)
#查看部分人的姓名
data2 = data['name'][:6]
print(data2)
运行截图:

3.3使用切片iloc
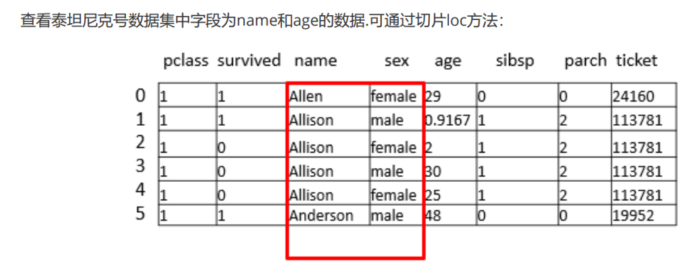
#使用切片
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
#查看泰坦尼克号数据集中的前6条的name,age,sex
#方法1,使用字典
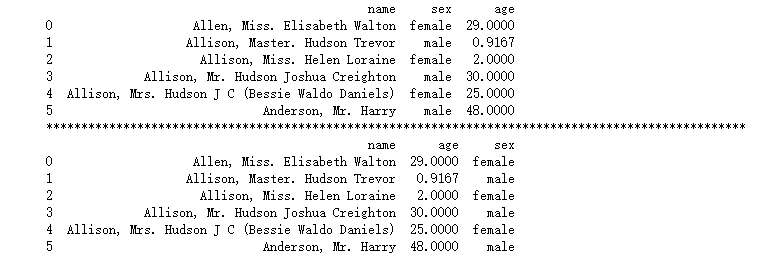
data1 = data[['name','sex','age']].head(6)
print(data1)
print("*"*100)
#方法2使用切片
data2 = data.loc[:5,['name','age','sex']]
print(data2)
运行截图:

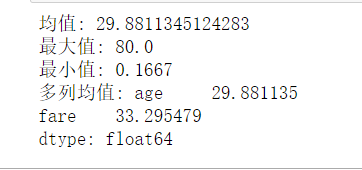
4.统计数据

import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
avg = data["age"].mean()#求平均值
max = data["age"].max()
min = data["age"].min()
m = data[['age','fare']].mean()#求多列的均值
print(avg)
print(max)
print(min)
print(m)
运行截图:
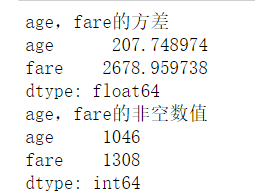
计算泰坦尼克号数据集中的age和fare的方差和非空数目
import pandas as pd
data3 = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
var = data3[["age","fare"]].var() #求方差
co = data3[["age","fare"]].count()#求非空数值
print("age,fare的方差")
print(var)
print("age,fare的非空数值")
print(co)
运行截图:
5.数据处理
5.1合并数据
5.1.1上下合并
#上下合并数据
import pandas as pd
data4 = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
data5 = data4.head()#获取前五条数据
data6 = data4.tail()#获取后五条数据
all_data = pd.concat([data5,data6],axis=0)
print(all_data)
运行截图:

5.1.2左右合并
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
data1 = data.iloc[0:5,0:3]#获取前五行前三列数据
data2 = data.iloc[:5,-3:]#获取前五行后三列数据
#使用concat纵向合并数据
data3 = pd.concat([data1,data2],axis=1)
print(data3)
print(data3.shape)
运行截图:

5.2删除数据
#删除数据
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
data.drop(labels="name",axis=1,inplace= True)
print(data)
运行截图:
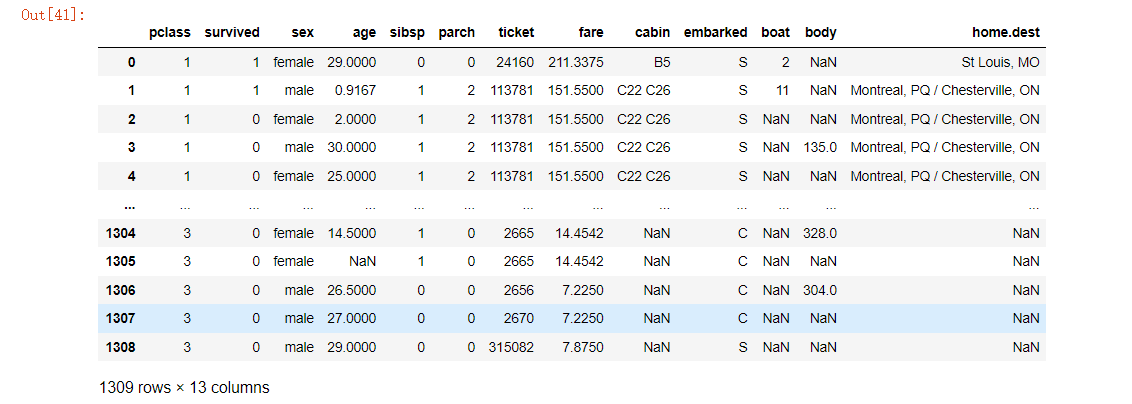
5.3重复值处理
数据重复会导致数据分布发生较大变化,因此,处理重复数据是数据分析经常面对的问题之一。我们可以采用drop_duplicates() 函数进行去重。
举例代码:
import pandas as pd
dic = {'a':[1,1,3,4],'b':[2,2,5,4],'c':[3,3,3,8],'d':[4,4,4,10]}
print("原始数据:")
df = pd.DataFrame(dic)
print(df)
print("删除重复值后:")
df1 = df.drop_duplicates()
print(df1)
运行截图:

5.4缺失值处理
5.4.1检测缺失值
①识别缺失值
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
data.isnull()
运行截图:

②识别非缺失值
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
data.notnull()
运行截图:

5.4.2删除缺失值
删除缺失值可以使用dropna()方法,具体使用参数如下

举例:在泰坦尼克号数据集中,有许多缺失值,如下表所示,age和parch中就出现了缺失值。 删除缺失值所在的那一行:
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
#删除所有缺失值的记录,按行删除
data1 = data.dropna(axis=0,how='any')
print(data1)
print("*"*100)
#删除子列‘parch’,‘age’有缺失值的记录
data2 = data.dropna(axis=0,how='any',subset=['parch','age'])
print(data2)
运行截图:
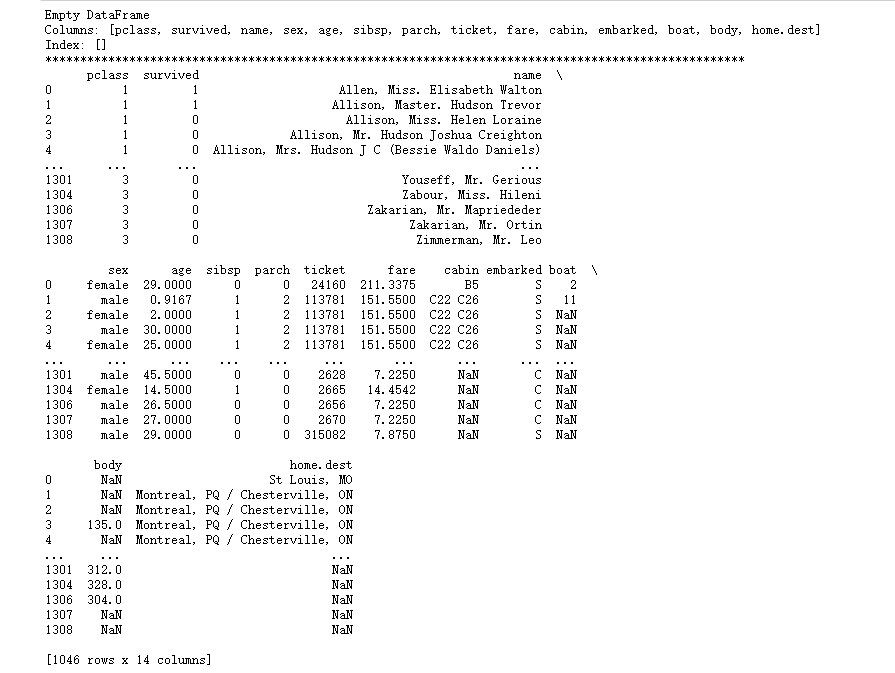
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
#删除有缺失值得那一列
data1 = data.dropna(axis=1,how='any')
print(data1)
运行截图:
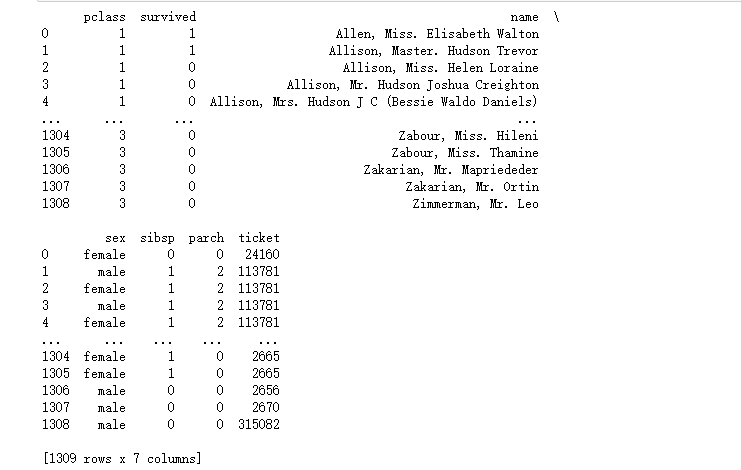
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
#删除前三列有缺失值的那一列
data2 = data.dropna(axis=1,how='any',subset=[0,1,2])
print(data2)
运行截图:
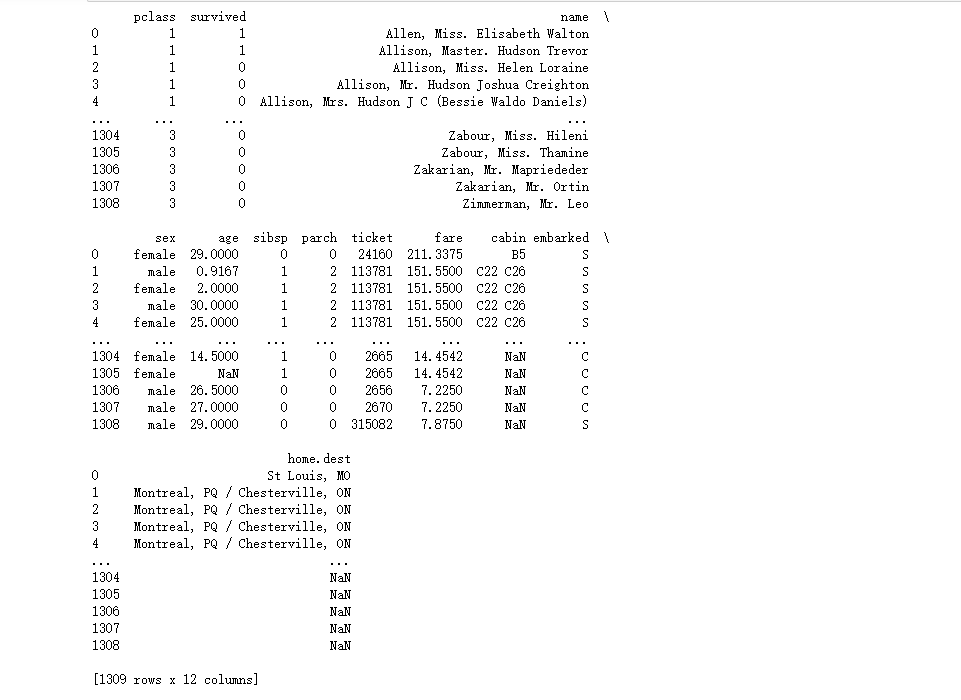
5.4.3替换缺失值
用一个特定的值替换缺失值。替换的值可以是一个固定值,使用上一个或下一个非缺失值,使用均值等。 举例: 使用如下方法替换泰坦尼克号数据集中的缺失值。
(1)使用固定值-99填充数据集中所有缺失值。
(2)使用age的均值填充age中的缺失值。
(3)使用上一个非缺失值填充age中的缺失值。
①使用固定值填充
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
#使用固定值填充缺失值
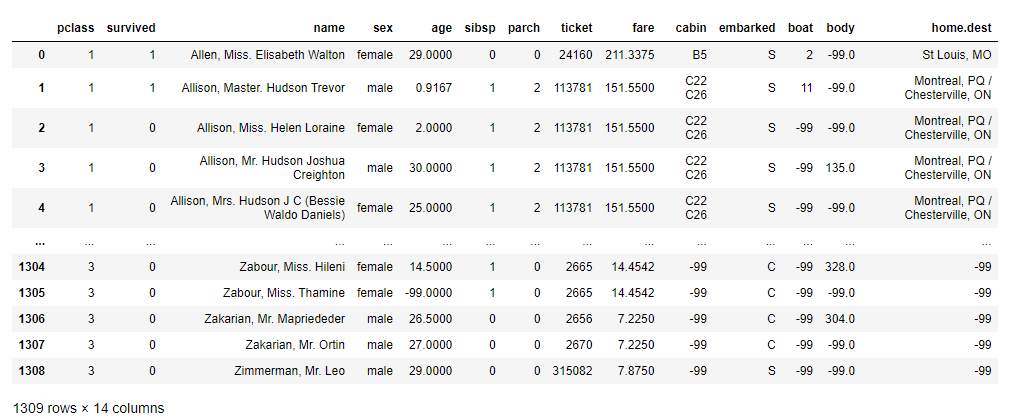
data1 = data.fillna(-99)
data1
运行截图:
②使用平均值填充
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
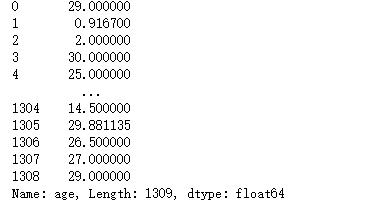
#使用均值填充age中的缺失值
data1 = data['age'].fillna(data['age'].mean())
data1
运行截图:
③使用上一个非缺失值填充
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
#使用上一个非缺失值填充age中的缺失值 ,下一个:bfill
data1 = data['age'].fillna(method='pad')
data1
运行截图:

6.哑变量转换
数据分析中有相当一部分的算法模型都要求输入的特征为数值型。但实际数据中,特征的类型不一定只有数值型, 还有很多是类别型。非数值类型数据需要经过数据转换,变为数值型,才可以放入模型中。

哑变量转换的函数:
pandas.get_dummies(data,prefix=None,prefix_sep=‘_’,dummy_na=False,columns=None)

案例:
import pandas as pd
data = pd.read_excel("D:\\桌面\\本学期课程\\titanic3.xls")
#获取前5个乘客的性别
print("获取前5个乘客的性别")
sex_data = data['sex'].head(5)
print(sex_data)
print("*"*100)
#使用哑变量转换数据
print("使用哑变量转换数据")
sex_dummies = pd.get_dummies(sex_data,prefix='sex')
print(sex_dummies)

7.综合训练
1、读取泰坦尼克号数据集
2、将字段name、cabin、ticket 、body和home.dest删除不要
3、填充数据集中的缺失值,要求如下
import pandas as pd data = pd.read_excel(“titanic3.xls”) #获取前5个乘客的性别
sex_data = data[“sex”].head(5) print(sex_data) #使用哑变量转换数据
sex_dummies = pd.get_dummies(sex_data,prefix=‘sex’) print(sex_dummies)
①字段embarked、boat使用上一个非缺失值替代 ②其余字段使用平均值替代
4、使用哑变量将所有类别型字段转换为数值型的数据
5、通过以上数据预处理后,得到一个全新的数据集,将其通过to_csv方法,保存到名为titanic_new.csv中。
答案:
"""读取excel数据集"""
import pandas as pd
# 1.读取数据集
data = pd.read_excel("titanic3.xls")
# 2.删除数据字段名
data1 = data.drop(["name", "cabin", "ticket", "body", "home.dest"], axis=1)
# 3.填充数据集的缺失值
# 字段embarked,boat使用上一个非缺失值替换
# 3.1判断embarked和boat是否为缺失值如果是则替换为上一个值method='pad'
data1["embarked"] = data1["embarked"].fillna(method='pad')
data1["boat"] = data1["boat"].fillna(method='pad')
# 其余字段使用平均值替换
data1 = data1.fillna(data1.mean)
# 4.使用哑变量字段转换为数值类型
data1 = pd.get_dummies(data1, columns=['sex', 'embarked'])
# 5.保存新数据
data1.to_csv('titanic_new.csv')
运行截图:
















 374
374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









