






本篇博客主要针对C++面向对象编程技术做详细讲解,探讨C++中的核心和精髓。主要是讲C++特有的一些特点。C++的核心编程主要有五个方面:
- 内存分区模型
- 引用
- 函数提高
- 类和对象
- 文件操作
后续将会在本账号全部更新
1,内存分区模型
C++程序在执行时,将内存大方向划分为4个区域:
- 代码区:存放函数体的二进制代码,由操作系统进行管理的
- 全局区:存放全局变量和静态变量以及常量
- 栈区:由编译器自动分配释放,存放函数的参数值,局部变量等
- 堆区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
内存四区的意义:
不同区域存放的数据,赋予不同的生命周期,给我们更大的灵活编程。其中,代码区和全局区是在程序运行前划分的区域,栈区和堆区则是程序运行后划分的区域
1.1 程序运行前
在程序编译后,生成了exe可执行程序,未执行该程序前分为两个区域
代码区:
存放CPU执行的机器指令
代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可
代码区是只读的,使其只读的原因是防止程序意外地修改了它的指令。
全局区:
全局变量和静态变量存放在此
全局区还包含了常量区,字符串常量和其他常量(const修饰的一些变量)也存放在此。
该区域的数据在程序结束后由操作系统释放。
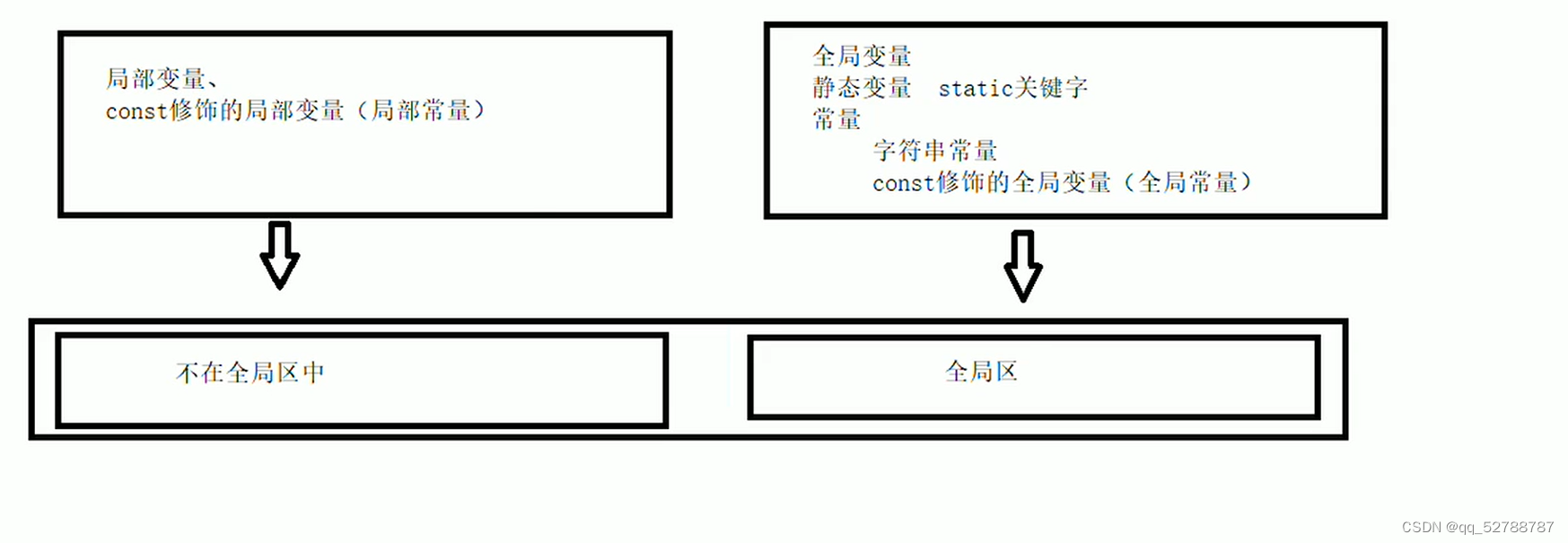
代码展现:
#include<bits/stdc++.h>
using namespace std;
int g_a=10;
int g_b=20;
const int c_g_a=10;
const int c_g_b=10;
int main(){
int a=10;
int b=20;
const int c_l_a=10;
const int c_l_b=20;
cout<<"局部变量a的地址 "<<&a<<endl;
cout<<"局部变量b的地址 "<<&b<<endl;
cout<<"全局变量a的地址 "<<&g_a<<endl;
cout<<"全局变量b的地址 "<<&g_b<<endl;
//静态变量 在普通变量的前面加static,属于静态变量
static int s_a=10;
static int s_b=10;
cout<<"静态变量a的地址 "<<&s_a<<endl;
cout<<"静态变量b的地址 "<<&s_b<<endl;
//常量
//字符串常量
cout<<"字符串常量地址"<<&("hello,world")<<endl;
//const修饰的变量
//const修饰的全局变量,const修饰的局部变量
cout<<"const修饰的全局变量c_g_a地址"<<&c_g_a<<endl;
cout<<"const修饰的全局变量c_g_b地址"<<&c_g_b<<endl;
cout<<"const修饰的局部变量c_l_a地址"<<&c_l_a<<endl;
cout<<"const修饰的局部变量c_l_b地址"<<&c_l_b<<endl;
} 
1.2 程序运行后
栈区:
由编译器自动分配释放,存放函数的参数值,局部变量等
注意事项:不要返回局部变量的地址,栈区开辟的数据由编译器自动释放
示例:
#include<bits/stdc++.h>
using namespace std;
//栈区数据注意事项——不要返回局部变量的地址
//栈区的数据由编译器管理开辟和释放
int *func(){
int a=10;
return &a;
}
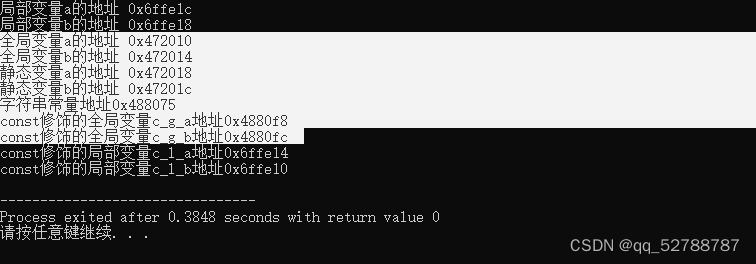
int main(){
int *p=func();
cout<<*p<<endl;//
cout<<*p<<endl;//
}
由上述运行结果可以看出,第一次访问正确,可以打印出正确的数字是因为编译器做了保留,而第二次访问则是因为此时内存已经被释放,访问该指针的内容将导致不确定的结果,也可能是崩溃。
堆区:
由程序员分配释放,若程序员不释放,程序结束时由操作系统回收
在C++中主要利用new在堆区开辟内存,因此,new关键字返回的值就是变量的地址,可以新建指针接收目标地址。
示例:
#include<bits/stdc++.h>
using namespace std;
int *func(){
//利用new关键字,可以将数据开辟到堆区
//指针 本质也是局部变量,放在栈上,指针保存的数据是放在堆区
int *p=new int(10);
return p;
}
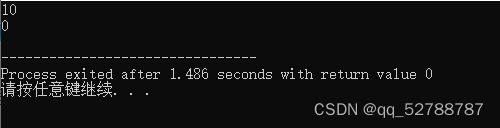
int main(){
//在堆区开辟数据
int *p=func();
cout<<*p<<endl;
cout<<*p<<endl;
}
注意与上面代码的区别,堆区中的数据,只要程序员不手动关闭,就可以一直存活。
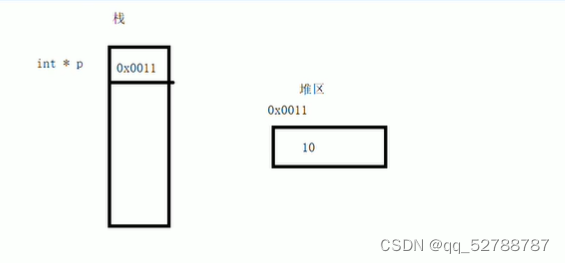
总结:
堆区数据由程序员管理开辟和释放
堆区数据利用new关键字进行开辟内存
堆区和栈区二者区别:
1.3 new操作符
C++中利用new操作符在堆区开辟数据
堆区开辟的数据,由程序员手动开辟,手动释放,释放利用操作符delete
语法:new 数据类型
利用new创建的数据,会返回该数据对应的类型的指针
示例:基本语法
##include<bits/stdc++.h>
using namespace std;
int *func(){
//在堆区创建整型数据
//new返回是 该数据类型的指针
int *p=new int(10);
return p;
}
void test01(){
int *p=func();
cout<<*p<<endl;
cout<<*p<<endl;
cout<<*p<<endl;
//堆区的数据,由程序员管理开辟,程序员管理释放
//如果想释放堆区的数据,利用关键字delete
delete p;
}
//2,在堆区利用new开辟数组
void test02(){
//创建10整型数据的数组,在堆区
int *arr=new int[10];//10代表数组有十个元素
for(int i=0;i<10;i++){
arr[i]=100+i;//给十个元素赋值 100~109
cout<<arr[i]<<endl;
}
//释放堆区数组的时候 要加[]
delete[] arr;
}
int main(){
//test01();
test02();
} 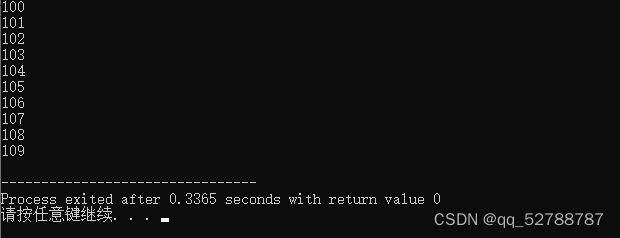
堆区数组在释放时,要加 [] , delete[] arr
2,引用
2.1 引用的基本使用
作用:给变量起别名
语法:数据类型 &别名=原名
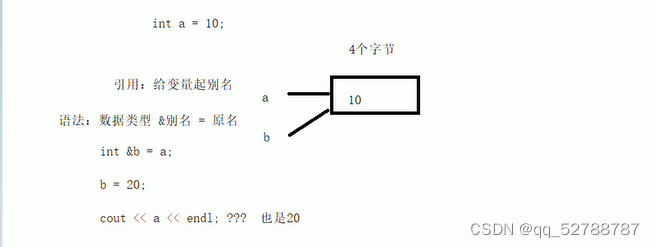
注意:此处别名的数据类型要与原名的数据类型保持一致。如果是int型,两者都要是int型。
如:int &b=a 就是创建了一个简单的引用b。
示例:
#include<bits/stdc++.h>
using namespace std;
int main(){
//引用基本语法
//数据类型 &别名= 原名
int a=10;
//创建引用
int &b=a;
cout<<"a= "<<a<<endl;
cout<<"b= "<<b<<endl;
b=100;
cout<<"a= "<<a<<endl;
cout<<"b= "<<b<<endl;
} 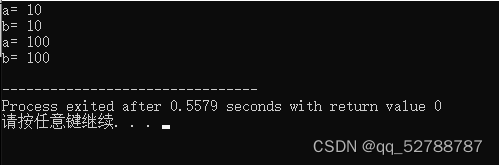
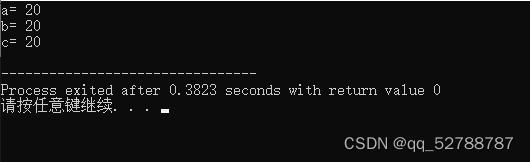
由运行的结果可以看出,引用的本质就是起别名,不同名字对应一个内存地址,数据也必然相同。
2.2 引用注意事项
- 引用必须初始化
- 引用在初始化后,不可以改变
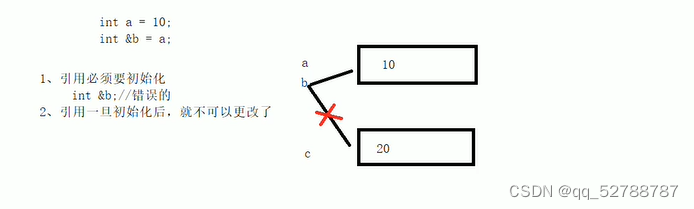
示例:
#include<bits/stdc++.h>
using namespace std;
int main(){
int a=10;
int &b=a;
int c=20;
b=c;//赋值操作,而不是更改引用
cout<<"a= "<<a<<endl;
cout<<"b= "<<b<<endl;
cout<<"c= "<<c<<endl;
} 
2.3 引用做函数参数
作用:函数传参时,可以利用引用的技术让形参修饰实参
优点:可以简化指针修改实参
在以往的学习中我们知道了函数传参只有两种方式:值传递和地址传递,其中值传递不能利用形参修饰实参,只有地址传递可以。而在学过引用之后,我们可以知道还可以用引用的技术让形参修饰实参。
#include<bits/stdc++.h>
using namespace std;
//交换函数
//1,值传递
void swap1(int a,int b ){
int temp=a;
a=b;
b=temp;
}
//2,地址传递
void swap2(int *a,int *b){
int temp=*a;//a,b中装的地址
*a=*b;
*b=temp;
}
//3,引用传递
void swap3(int &a,int &b){
int temp=a;
a=b;
b=temp;
}
int main(){
int a=10;
int b=20;
swap1(a,b); //值传递,形参不会修饰实参
cout<<"a= "<<a<<"b= "<<b<<endl;
swap2(&a,&b);//地址传递,形参会修饰实参
cout<<"a= "<<a<<"b= "<<b<<endl;
swap3(a,b);//引用作参数,形参会修饰实参
cout<<"a= "<<b<<"b= "<<a<<endl;
} 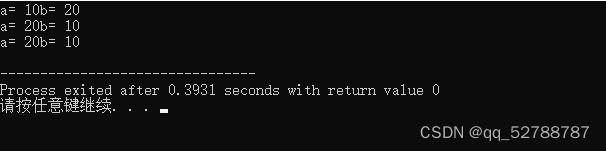
上述我们说过,引用的本质就是通过别名控制一块内存区域,既然是通过别名也可以控制内存内容,则函数对变量别名所作的操作与实际改变变量本身是一样的效果。
2.4 引用做函数返回值
作用:引用是可以作为函数的返回值存在的
注意:不要返回局部变量引用
用法:函数调用作为左值
示例:
#include<bits/stdc++.h>
using namespace std;
//1,不要返回局部变量的引用
int& test01(){
int a=10;//局部变量存放在四区中的栈区
return a;
}
int& test02(){
static int a=10;//静态变量存放在全局区,全局区上的数据在程序结束后由系统释放
return a;
}
int main(){
int &ref=test01();
cout<<"ref= "<<ref<<endl;//第一次结果正确,是因为编译器做了保留
cout<<"ref= "<<ref<<endl;//第二次结果错误,因为a的内存已经释放
int &ref2=test02();
cout<<"ref2= "<<ref2<<endl;
cout<<"ref2= "<<ref2<<endl;
test02()=1000;//2,函数的调用可以作为左值
cout<<"ref2= "<<ref2<<endl;
cout<<"ref2= "<<ref2<<endl;
} 
上述可以看出,局部变量存放在栈区,运行一次后系统将该变量的内存释放。静态变量存放在全局区,全局区上的数据在程序结束后由系统释放。
2.5 引用的本质
本质:引用的本质在C++内部实现是一个指针常量。
指针常量与常量指针,既修饰指针又修饰常量不同,指针常量是指:指针的指向不可以改,指针指向的值可以改,与常量指针正好相反。 C++学习笔记——指针-CSDN博客
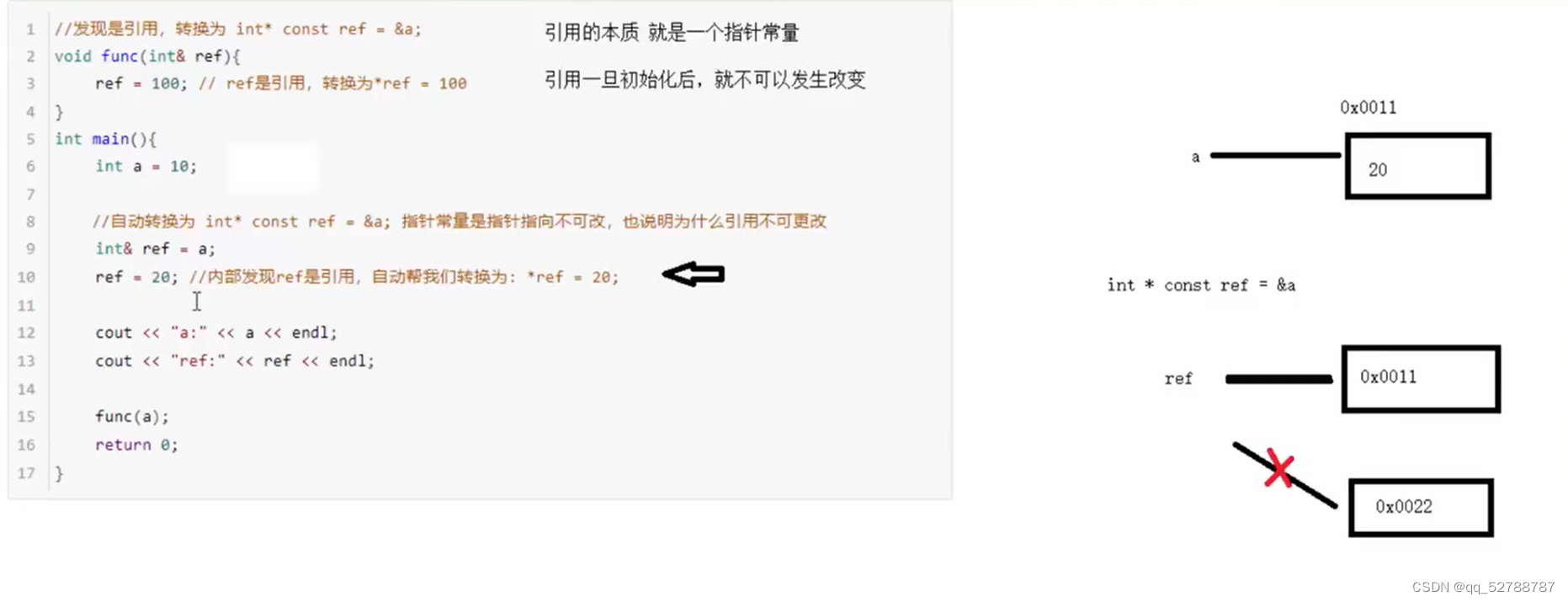
结论:C++ 推荐使用引用技术,因为语法方便,引用本质是指针常量,但是所有的指针操作编译器都帮我们做了,这部分知识如果不明白可以不用深究,只知道引用的本质是一个指针常量即可。
2.6 常量引用
作用:常量引用主要是用来修饰形参,防止误操作
在函数形参列表中,可以加const修饰形参,防止形参改变实参
示例:
const int &ref=10;//引用必须引用一块合法的内存空间
ref=20;//错误,加入const后ref为只读,不允许修改。#include<bits/stdc++.h>
using namespace std;
//常量引用防止误操作
void print(const int &a){
//a=100; 错误,防止误操作
cout<<"a= "<<a<<endl;
}
int main(){
int a=10;
const int &b=a;
print(b);
cout<<"b= "<<b<<endl;
} 
3 函数提高
在C++中,函数还会有更深的用法
3.1 函数默认参数
在C++中,函数的形参列表中的形参是可以有默认值的。
语法:返回值类型 函数名 (参数= 默认值){ }
作用:在如下代码中,如果没有说明函数参数的默认值,在其他地方调用该函数时,参数值必须要补全,否则编译器会报错,而在指定函数参数默认值之后,需要三个变量的函数调用只需要传入一个即可。
#include<bits/stdc++.h>
using namespace std;
//如果我们自己传入数据,就用自己的数据,如果没有,那么用默认值
int add(int a,int b=20,int c=30){
return a+b+c;
}
int main(){
int a=add(10);
cout<<a<<endl;
} 注意事项:
1,如果某个位置已经有了默认参数,那么从这个位置往后,从左到右都必须有默认值
2,如果函数声明有默认参数,函数实现就不能有默认参数,即声明和实现只能有一个默认参数
//函数声明与实现参数只能保留一个
int func(int a=10;int b=100);//函数声明
int func(int a,int b)//函数实现
{
return a+b;
}3.2 函数占位参数
C++中函数的形参列表里可以有占位参数,用来做占位,调用函数时必须填补该位置
语法:返回值类型 函数名(数据类型){}
比如:void swap(int ,int){}
void func(int ,int ){
cout<<"占位函数"<<endl;
}
int main(){
func(10,10);
}需要注意的是:实际调用函数时,上述例子中的实参是传入到了占位参数中了的,且占位参数也可以有默认参数。
在现阶段函数的占位参数存在意义不大,但是后面的学习中可能会用到该技术。
3.3 函数重载
函数重载相当于给系统提供了可以重名的函数
3.3.1 函数重载概述
作用:函数名可以相同,提高复用性
函数重载满足条件:
- 同一个作用域下
- 函数名称相同
- 函数参数类型不同或者个数不同或者顺序不同
void func();
void func(int a);
void func(double b);void func(){
cout<<"func()的调用"<<endl;
}
void func(int a){
cout<<"func(int a)的调用"<<endl;
} void func(double b){
cout<<"func(double b)的调用"<<endl;
} void func(int a,double b){
cout<<"func(int a,double b)的调用"<<endl;
} void func(double a,int b){
cout<<"func(double a,int b)的调用"<<endl;
}
int main(){
func();
func(12);
func(3.14);
func(10,3.14);
func(3.14,10);
}
注意:函数的返回值不可以作为函数重载的条件,即不允许存在像void func(double a,int b),int func(double a,int b)的重载
3.3.2 函数重载注意事项
- 引用作为重载条件
//函数定义 void func(int &a){} void func(const int &a){} //函数使用 int a=10; void (a);//调用void func(int &a){} void(10);//int &a=10不合法 void(10);//const int &a=10;合法 - 函数重载碰到函数默认参数,出现二义性,只能尽量避免
void func(int a){ } void func(int a,int b=10){ } //函数调用 func(10);//出现二义性,编译器报错















 723
723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









