






-
摘要
-
问题:基于物品属性的语义物品关系(在推荐中对衡量物品相似性至关重要)在序列化推荐模型中没有被好好利用。
-
解决方法:提出了通用的表征平滑框架。
-
怎么做:第一步:将序列化物品关系和语义物品关系融合起来构成混合物品图(涉及多个物品关系)。第二步:在混合物品图上执行图卷积生成平滑表征物品。第三步:将平滑物品表征用在序列化推荐模型中作为输入来提高性能。
-
-
引言
-
para1:如何准确捕捉用户的偏好是推荐中的核心问题,为了给用户偏好建模,已经提出了各种各样的序列化架构(RNN,CNN等等)
-
para2:现有挑战:在不同的推荐场景中,用户交互的顺序性可能会有很大的差异,这可能会严重影响序列化推荐模型的适用性。
-
para3:我们采取序列化关联规则去证实在不同的推荐场景中用户交互的顺序性。
-
para4:讲了基于物品属性的语义物品关系为什么没有被好好利用,但是又很重要。
-
para5:本论文主要思想:用物品关系图平滑物品表征,以维护全局物品相似结构。在使用图卷积时,我们需要去除冗余非线性,实现一个简单的图卷积,最后,平滑物品表征作为序列化推荐模型的输入。以这样的方式,当预测下一个物品时,序列化模型包含了用户交互物品和他们的关系物品,放宽模型中的序列化假设,增强模型的泛化能力。
-
para6:我们用SASRec在三个数据集上评估所提出的表征平滑方法,大量的实验表明改进的SASRec在高/中序列化数据集上超过所有基线方法,在低序列化数据集上也获得了好的结果;我们还进行了实验,以展示在打乱用户交互顺序的情况下SASRec的性能,以及所提出的方法在缓解性能下降方面的效果。最后,对不同类别的序列化推荐模型进行了实验,验证了该方法的有效性。
-
-
准备工作
-
问题形式化
-
U:用户集、 I:物品集 S(U):用户U的交互序列
-
-
SASRec
-
简介一下骨干模型SASREc,在Transformer中通过自注意力体系结构以序列化依赖性建模,他通过表征查找,将用户交互序列转换为向量序列,然后将可训练的位置表征注入到输入表征中,并使用具有两个前馈层的自注意层对序列进行编码。将具有残差连接的自注意块叠加后,将时间步长t处的最终表示向量作为序列表示。最后利用点积计算序列表示与候选物品表征的相似度得分,采用交叉熵损失进行模型训练。
-
-
图卷积
-
图卷积是我们所提出方法的一个重要组成部分,早期的研究通过计算归一化图的特征分解来定义傅里叶域的图卷积。然后,图卷积可以定义为信号与参数滤波器的乘积。为了避免计算归一化图的拉普拉斯特征分解,切比雪夫多项式用Chebyshev多项式逼近滤波器。广泛使用的图卷积网络通过引入一阶近似简化了ChebNet,其矩阵形式
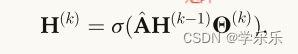 通过堆叠多个这样的层,GCN可以将来自多跳邻居的信息聚合到中心节点。
通过堆叠多个这样的层,GCN可以将来自多跳邻居的信息聚合到中心节点。
-
-
-
方法
-
框架
-
将序列化物品关系和语义物品关系融合起来构成混合物品图(涉及多个物品关系)。在混合物品图上执行图卷积生成平滑表征物品。将平滑物品表征用在序列化推荐模型中来提高性能。
-
-
物品图的生成
-
序列化物品图
-
我们聚合所有用户交互序列,以构建一个全局的序列化物品图,该图反映了根据用户行为的物品之间的关系。
-
-
语义物品图
-
从用户-物品交互构建的序列化物品图反映了用户行为方面的物品转换模式。
-
-
图融合
-
为了结合序列化物品图和语义物品图以实现表征平滑,一个简单的方法是在每个图中传播物品表征,然后融合输出以获得最终的物品表征。
-
-
用于表征平滑的图卷积
-
在混合物品图上进行图卷积,得到平滑的物品表征。物品在推荐模型中由可训练的ID表征表示。因此,执行多层非线性转换可能会影响ID表征的学习,从而导致较差的推荐性能。所以我们考虑去除GCN层中的非线性转换,并执行一个简单的图形卷积来平滑序列化推荐模型中的表征。我们还可以采用层聚合策略来缓解深度图卷积网络的过平滑问题。
-
-
理论分析
-
深入了解图形卷积是如何导致表征平滑的。这里以单层简单图卷积为例,图卷积后两个物品之间的相似度主要取决于邻居-邻居的相似度。通过图卷积的表征平滑主要基于二阶近似。从图信号处理的角度来看证明了带有自回路的简单图卷积缩小了图谱域,得到了一个捕获低频信号的低通滤波器,对应于图的平滑特征。因此,在进行简单的图卷积后,附近的节点倾向于共享相似的表示。将基于图卷积的表征平滑应用于序列化推荐模型,可以认为是同时使用过去的物品和序列或语义相关的物品来预测下一个物品
-
-
-
-
讨论
-
与图拉普拉斯正则化的关系
-
执行图拉普拉斯正则化也可以根据物品关系平滑物品表征,但与图卷积相比有以下缺点:
-
图拉普拉斯正则化建立在一阶近似上,在真实数据集中观察到的物品关系通常是稀疏的,许多类似的物品可能没有显式地链接到,考虑邻域结构的相似性(即二阶邻近性)可以极大地丰富物品间的关系,且表征平滑效率更高。所以要用图卷积。
-
图拉普拉斯正则化基于半监督学习框架,其性能对权值高度敏感,而图卷积使用归一化的传播矩阵,它的性能对平衡节点本身及其邻居信息的权重不那么敏感。
-
-
-
与SR-GNN的关系
-
SR-GNN使用了Gated GraphNeural Network (GGNN)对基于会话推荐中的本地依赖关系进行建模,通过收集会话序列来构造全局图,并将每个会话序列建模为从全局图中提取的子图。SR-GNN只考虑会话中的物品如何根据全局图彼此通信。而我们提出的方法对全局图进行表征平滑。对于用户的交互序列,我们的方法还考虑用户没有交互但其他用户有交互的相关物品。
-
我们提出的方法是一个总体框架。它可以利用不同的物品图来提高推荐性能,更重要的是,该框架可以应用于各种序列化模型中以提高其性能。
-
-
时间复杂度分析
-
本文提出的表征平滑法是一个序列化推荐模型的插件模块,在这里分析其中的图卷积的时间复杂度,我们也可以采用邻域抽样策略来进一步降低图卷积的时间成本。
-
-
-
实验
-
数据集 Amazon Books 、Yelp、 Google Local
-
实验设置
-
评估协议:我们采用了留一方案来评价模型在序列化推荐下的性能,最后一物品用于测试,倒数第二物品用于验证,其余物品用于训练。
-
评价指标:HR、NDCG、MRR
-
为了验证GES-SASRec的有效性,与5组基线进行比较,第一组包含一般推荐方法,只使用用户-物品交互数据进行物品推荐;第二组包括捕捉用户动态偏好的序列化推荐模型;第三组包含使用语义物品关系来提高推荐性能:关系感知推荐模型;第四组包括同时对推荐的序列化和语义的物品关系进行编码;超参数设置
-
对于提出的5个问题所做的实验
-
Can the proposed embedding smoothing method improve the performance of SASRec?
-
方法:我们在表2中报告了1-3个图卷积层的SASRec和GES-SASRec在序列化/语义的/混合的物品图上的性能。我们在图3中进一步绘制了它们的学习曲线(NDCG@10的测试性能),以展示所提出的表征平滑方法的好处。
-
结论:1.对于高序列性数据集(Amazon Books),在序列化物品图中表征平滑可能会导致过度平滑,损害SASRec的性能。而对于中、低序列性数据集(Yelp和Google Local),则可以提高推荐性能。2.语义物品图的表征平滑Amazon Books 和Yelp上更有效。3.混合物品图进行表征平滑在所有数据集上取得最好的结果。4.太多的图形卷积层会导致对物品表征的过度平滑,图卷积的层数为1-2层更合适。
-
-
Can the proposed GES-SASRec outperform the state- of-the-art recommendation methods?
-
方法:我们在表3显示了与基线方法的性能比较。
-
结论:1.对于高序列性数据集(Amazon Books),最好的序列化推荐模型SASRec显著优于最好的一般推荐模型Mult-DAE。而对于低序列性数据集(Yelp), SASRec的性能要比Mult-DAE差得多。对于中序列性数据集(Google Local), SASRec和mult - dae的性能是相当的。2.对于基于mf的方法,MCF显著优于BPR。对于基于图卷积的方法,LightGCN+比LightGCN获得更好的结果。3.GES-SASRec在Amazon Books和Google Local上的表现优于其他基线,但在Yelp上表现不佳。也就是说,GES-SASRec在高序列性数据集上显示了更强的推荐性能。
-
-
How do the hyperparameters and setups affect the performance of GES-SASRec?
-
方法:我们对GES-SASRec进行了详细的分析,以展示关键超参数和层聚合策略对其性能的影响。我们也研究了不同表征平滑方法下SASRec的性能。
-
结论:
-
1.表征大小的效率
-
从宏观角度看,随着表征尺寸的增大,各模型的表达性增强,性能均有所提高。过度拟合可能发生在一些模型的大表征尺寸。在不同的表征尺寸下,GES-SASRec比SASRec在所有数据集上获得更好的结果。
-
-
关系系数的影响
-
方法:我们在图5给出了GES-SASRec序列化/语义关系系数a/β的结果。
-
结论:对于Amazon Books来说,a与β的最优比约为0.5,即语义关系的最优权重是序列化的两倍。而Yelp和Google Local的最优比例约为2,即序列化的最优权重是语义关系的两倍。
-
-
层聚合的影响
-
方法:我们在图6显示了具有不同层聚合功能的GES-SASRec的性能。
-
结论:当层数从1-2增加到3时,没有层聚合的GES-SASRec性能下降,说明存在过平滑问题。而使用层聚合可以有效地避免这一问题,因为在大多数情况下,模型性能会随着层数的增加而略有提高,使用1-2个没有层聚合的图卷积层,对于推荐中的物品表征可能会获得更合适的平滑度。
-
-
表征平滑方法的影响
-
方法:我们在表4给出了不同表征平滑方法下SASRec在混合物品图上的性能。
-
结论:在大多数情况下,所有的表征平滑方法都可以提高SASRec的性能。与图拉普拉斯正则化相比,图卷积似乎更有效。此外,在大多数情况下,GES-SASRec的性能优于GCN-SASRec,这表明图卷积层中转换的冗余复杂性可能会影响推荐性能。
-
-
-
-
How do SASRec and GES-SASRec perform under the shuffled user interaction orders?
-
方法:实验展示了SASRec在用户交互序列被打乱时的执行情况,以及所提出的表征平滑方法是否能够缓解性能下降的问题。如图7所示,在测试过程中,SASRec、GES-SASRec、LightGCN和LightGCN+在不同混合率下的性能。
-
结论:1.SASRec和GES-SASRec的性能对用户交互的顺序都很敏感,推荐准确度随交互混合率的增加而下降。2.表征平滑可以帮助SASRec在高序列性数据集的推荐性能上超越LightGCN。3.表征平滑可以缩小SASRec和LightGCN在低序列性数据集上的性能差距。4.表征平滑可以帮助SASRec在中等序列数据集上胜过LightGCN。
-
-
Can the proposed embedding smoothing method apply to other categories of sequential recommenda- tion models?
-
方法:我们尝试将所提出的方法应用于其他四种序列化模型,包括基于马尔可夫链的模型(TransRec),基于cnn的模型(Caser),基于RNN-based的模型(GRU4Rec),以及基于注意力的RNN模型(NARM)。我们用所提出的混合物品图平滑这些模型中的物品表征,并在表5中显示结果。
-
结论:所提出的表征平滑方法可以显著提高所有这些序列化推荐模型的性能,特别是对于基于物品的方法(GRU4Rec 和NARM).
-
-
-
-
-
相关工作
-
序列化推荐模型
-
对序列化推荐问题的研究重点是如何捕获用户的动态偏好。并讲述了一些相关工作
-
-
基于GNN推荐模型
-
图神经网络(gnn)被广泛用于处理推荐模型[中的图结构数据。这些图可以分为四类:1用户-物品二部图,2.用户-用户社交网络 3.物品-物品图 4.异构信息网络/知识图。
-
-
推荐模型中的正则化
-
推荐模型往往存在数据稀疏性问题,难以捕捉用户的偏好和物品特征,导致性能不理想。为了解决这些问题,最近的一些努力试图利用图数据,通过使图中接近的用户/物品具有类似的表示,从而对这些模型进行规范化。这些策略有两种思路:1)使用从用户-物品交互中生成的图形。2)使用从侧面信息构建的图。
-
-
-
结论
-
在本研究中,我们指出,在不同的推荐场景中,用户交互的顺序性可能会有很大的差异,这可能会严重影响序列化推荐模型的性能。此外,序列化模型只考虑用户行为方面的序列化物品关系,而忽略了对度量推荐中的物品相似性至关重要的语义物品关系。针对这些问题,提出了一种有效的提高序列化推荐模型性能的框架。我们的主要思想是用物品图平滑序列化模型中的物品表征,这包括两个基本步骤:生成混合物品关系图和执行图卷积。为了构造一个混合的物品关系图,我们将用户-物品交互产生的序列化物品关系与基于物品属性的语义物品关系融合在一起。然后对混合物品图进行图卷积,生成平滑物品表征作为序列化推荐模型的输入。我们用最先进的序列化推荐模型SASRec在三个公共数据集上评估了提议的表征平滑方法。实验结果表明,改进后的SASRec模型在高/中序列性数据集上优于所有基线,在低序列性数据集上取得了较好的结果。我们也进行了实验来验证所提出的表征平滑方法在不同类别的序列化推荐模型上的有效性。
-
对于未来的工作,一种可能的努力是探索物品之间的异构语义关系(例如,具有相同类型/导演/演员的电影),从而用这些关系去设计表征平滑策略。
问题:图卷积被定义为 信号与参数滤波器的乘积 信号是指什么?
在这里,"signal" 指的是输入的信号或数据,通常用于图形卷积神经网络(Graph Convolutional Networks,GCN)中。这个信号可以是节点特征矩阵、边缘权重矩阵等,用于表示图结构中的信息。通过与参数化滤波器(即图卷积操作)的乘积,可以对信号进行处理和分析,从而学习图结构中的特征和关系。
-
文献总结:
问题:基于物品属性的语义物品关系(在推荐中对衡量物品相似性至关重要)在序列化推荐模型中没有被好好利用。
解决方法:提出了通用的表征平滑框架,对物品-物品之间的关系进行建模。
怎么做:第一步:将序列化物品关系和语义物品关系融合起来构成混合物品图(涉及多个物品关系)。第二步:在混合物品图上执行图卷积生成平滑表征物品。第三步:将平滑物品表征用在序列化推荐模型中作为输入来提高性能。
文献在方法部分讲述了为什么要用简单图卷积(执行多层非线性转换可能会影响ID表征的学习,从而导致较差的推荐性能。所以我们考虑去除GCN层中的非线性转换,并执行一个简单的图形卷积来平滑序列化推荐模型中的表征)。
讲述了为什么要用图卷积生成平滑物品表征(因为执行图拉普拉斯正则化也可以根据物品关系平滑物品表征,但与图卷积相比有缺点)
也了解图卷积是如何导致表征平滑的(图卷积后两个物品之间的相似度主要取决于邻居-邻居的相似度。通过图卷积的表征平滑主要基于二阶近似。从图信号处理的角度来看证明了带有自回路的简单图卷积缩小了图谱域,得到了一个捕获低频信号的低通滤波器,对应于图的平滑特征。因此,在进行简单的图卷积后,附近的节点倾向于共享相似的表示。将基于图卷积的表征平滑应用于序列化推荐模型,可以认为是同时使用过去的物品和序列或语义相关的物品来预测下一个物品)
实验部分:我们用最先进的序列化推荐模型SASRec在三个公共数据集上评估了提议的表征平滑方法。在实验部分,该文献提出了5个问题,分别从这5个问题进行展开实验,每个实验都对方法、结论进行了介绍总结,图表结合让实验部分更直观、更清晰。实验结果表明,改进后的SASRec模型在高/中序列性数据集上优于所有基线,在低序列性数据集上取得了较好的结果。我们也进行了实验来验证所提出的表征平滑方法在不同类别的序列化推荐模型上的有效性。
疑问点:
1:序列化模型为什么只考虑序列化物品关系,而忽略语义物品关系呢?此处也讲述了语义物品关系的重要性,那为什么会忽略呢?这里讲序列化模型不容易捕捉这种关系,不容易捕捉,就忽略了?

答:序列化模型比较稀疏,加入语义关系后,物品图会更加稠密,之前的模型会忽略,所以我们要加入语义物品关系。
2:图卷积被定义为 信号与参数滤波器的乘积 信号是指什么?一阶近似,(后面有个二阶近似)不太明白

答:信号 就是传递的信息
3:这里为什么要加入I,用图的重规范化邻接矩阵?
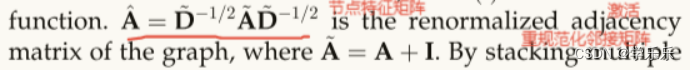
答: I:自身的连接,不仅要学习邻接矩阵,还要自身的连接,一般情况下不加这个I。
4:三跳物品 / 五跳物品是什么意思?

答: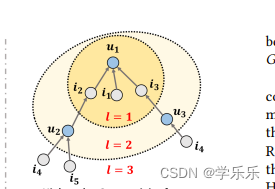 一跳 U1访问i2,i1,i3 一跳 二跳指那个层
一跳 U1访问i2,i1,i3 一跳 二跳指那个层
5:式子: K层重规范化邻接矩阵 点积 (o层)可训练的ID物品表征
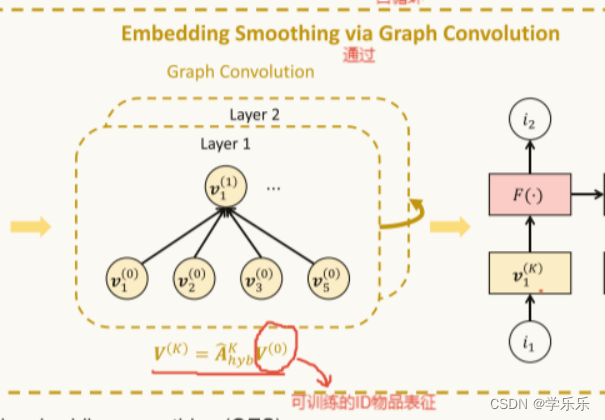
答: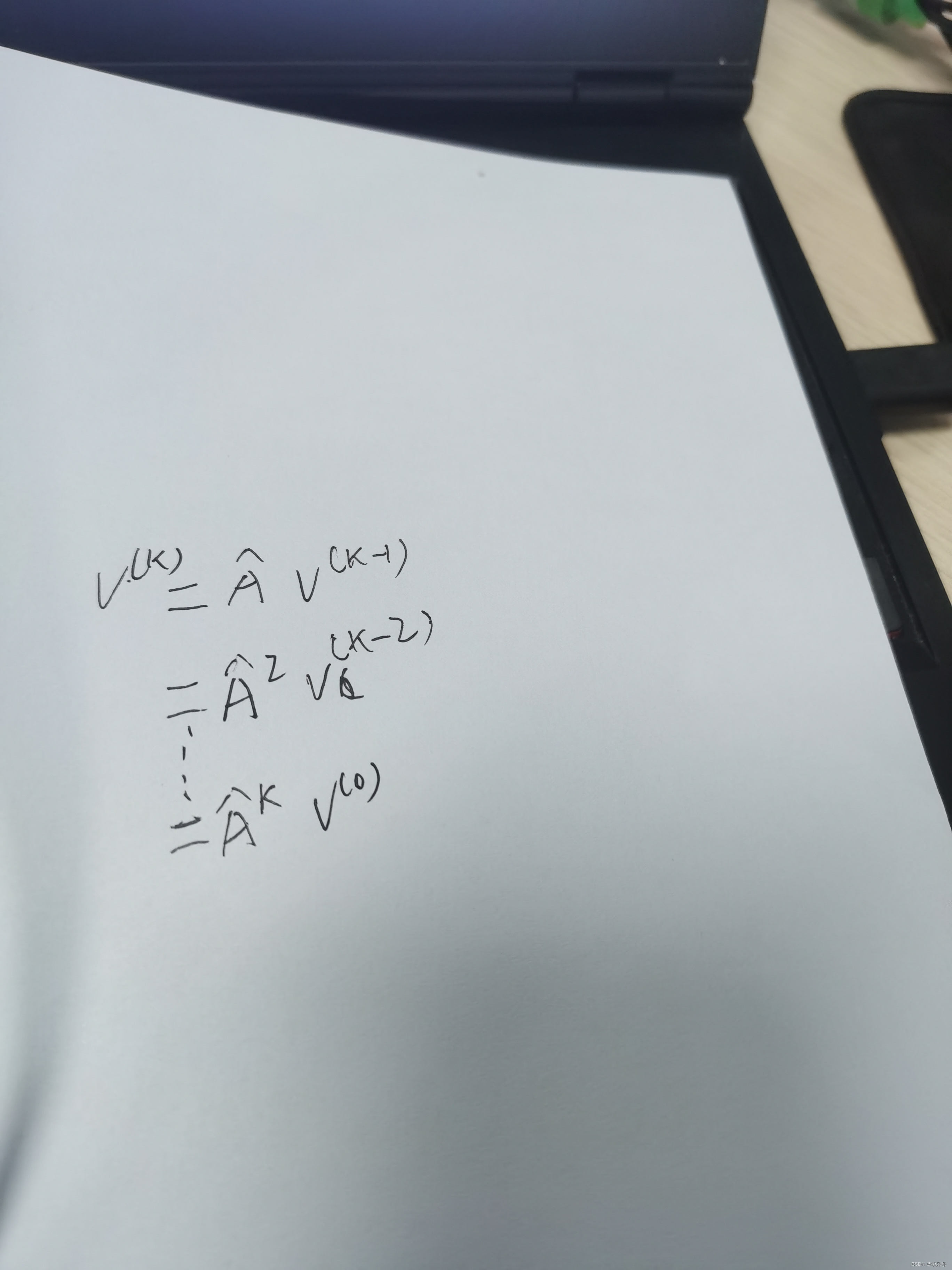

答:式子6是lightGCN里的
6:第一部分是邻居-邻居相似度,第二部分是节点对节点的相似度;第三、四部分为节点-邻居相似度。为什么直接就得到图卷积后两个物品之间的相似度主要取决于邻居-邻居相似度。

答: 根据公式得到的
7:序列化物品图的表征平滑的有效性可能依赖于用户交互中顺序性的强度,语义物品图表征平滑的有效性可能取决于语义物品关系的可靠性和数据集的稀疏性,这两句也是通过做实验得出的吗?那从图Fig. 3.上怎么没有看出来?

答: 就这样介绍的
8.边际改进是什么意思? 从图Fig. 4.上怎么看出边际改进在减少
不是边际改进,而是提升的幅度下降,此处翻译问题

9.文中讲到 当层数从1-2增加到3时,没有层聚合的GES-SASRec性能下降,说明存在过平滑问题,而使用层聚合可以有效地避免这一问题。(这个图Fig. 6没有看明白,图上哪体现了使用层聚合和没有使用层聚合的区别)
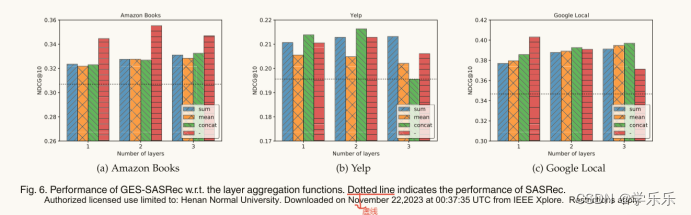
答:虚线代表SASREC即没有采用层聚合 层聚合的方式有很多,sum,mean,concat等















 741
741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









