






一、连续状态空间

之前的月球车的状态为离散值(1-6的位置)。连续状态空间(如卡车)的状态为一个向量(位置,速度,角度)。
二、实例:月球着陆器
1.
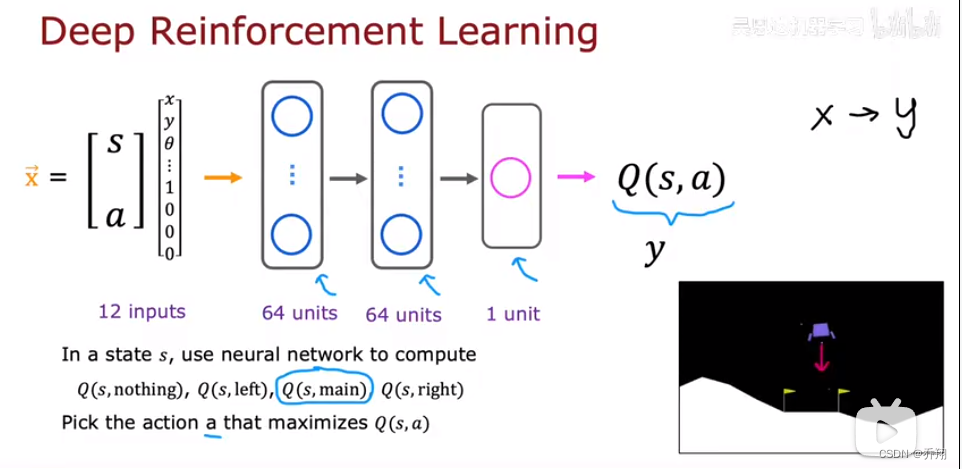
我们需要设计一个神经网络用来输入(s,a)然后输出Q。那么训练这个神经网络我们需要x-y的数据集。

数据集用贝尔曼方程得到。如图(s,a)为x,Q(x)为y,但这时候我们不知道Q的参数,那么如何求y?
只需随机之前的网络一个参数来输出y,我们得到10000个x-y。然后用它来训练网络是Q逼近y

归纳起来就是:初始一个随机的神经网络。
重复:采取行动得到![]() 。
。
保存最近的100000个四元组。
然后训练神经网络:用四元组得到训练集,开始训练。
tip:
2.算法改进:改进的神经网络架构
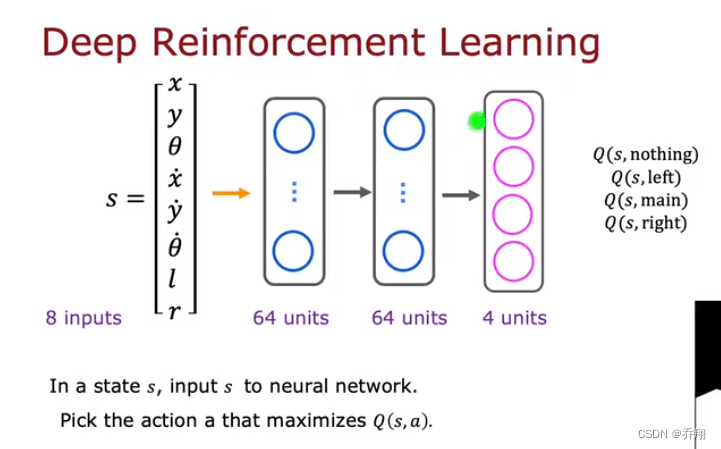
将神经网络改为输出s状态下四种行为的Q,比之前输出一个最优的效率高
3. 算法改进:ε-贪婪策略
(在采取行动时用一个3概率来选择估计的最优行动,用1-3采取随机行动,这样可以防止算法不去探索一下惩罚高的行动)
ε 表示一个小于 1 的正数,通常被称为探索率。
具体来说,ε-贪婪策略会在每个时间步中根据以下规则选择动作:
- 以概率 ε 选择一个随机动作(即探索)。
- 以概率 1-ε 选择当前估计的最佳动作(即利用)。
在实践中,通常会选择一个较小的ε值,使得在大部分时间里采取的是当前估计的最佳动作,从而最大化已知的奖励。但是偶尔地随机选择动作可以保证智能体在探索未知领域时不会陷入局部最优解,从而有机会发现更好的策略。
ε-贪婪策略的主要优点是简单易实现,并且能够在探索和利用之间找到一个良好的平衡。但是它也存在一些缺点,比如在训练的后期阶段可能会导致过多的探索,从而影响训练的效率。因此,在实践中需要仔细选择合适的 ε 值以及逐步降低 ε 的策略,以确保智能体能够在训练过程中逐渐减少探索,更多地利用已知信息。
三、月球着陆器的实现
1.初始化经验缓冲区
2.初始化预测Q,随机W
3.初始化目标Q,开始目标Q的W=预测Q的W
4.for n次
初始状态state
for m 次
用预测Q计算state状态下四种操作的Q(s,a)。
使用贪婪策略选择一个操作a。
执行a得到next_state和reward。。
设置state=next_state
构造元组(state,a,reward,next_state)并插入经验缓冲区。
when 合适时机
从经验缓冲区随机选取部分元组生成训练集,x=(state,a),y=
训练预测Q,更新W,同时使用软更新策略更新目标Q的W。
累加得分
tip:软更新:使用软更新可以防止预测Q权重更新过快出现不稳定情况。在软更新中目标Q的W一般通过将预测Q的W与他的W加权平均得到,所以W变化较平缓。
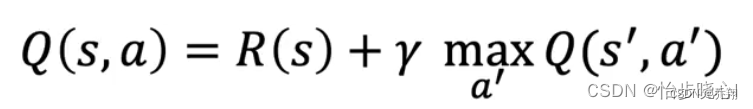















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









