







相关定义
AI:计算机科学下的一个学科,旨在让计算机系统模拟人类的智能从而解决问题和完成任务。
机器学习:AI的一个子集,核心在于不需要人类做显示编程,而是让计算机通过算法自行学习和改进,去识别模式、做出预测和决策
深度学习:机器学习的一个方法,核心在于使用人工神经网络模仿人脑处理信息的方式,通过层次化方法,提取和表示数据的特征。神经网络由许多基本的计算和存储单元组成,就是神经元,神经元通过层层连接来处理数据,有输入层、隐藏层(多层)、输出层。可以用于监督学习、无监督学习、强化学习。(AlexNET,用GPU代替CPU进行AI训练和推理,降低硬件成本)
ps: 在地理上,通过空间深度学习,可以①对影响空间目标的识别,二元分类提取道路、建筑物轮廓,对象提取光伏板对象等,②对时空数据进行挖掘分析,如分析犯罪数据(预测犯罪概率、判断犯罪类型、识别犯罪热点),③进行变化监测
深度学习
- ( 1-31 https://www.bilibili.com/video/BV1K94y1Z7wn?p=3&spm_id_from=pageDriver&vd_source=8afdf2d9fefd0cf019fbf34e67125765)
基础知识
解决的问题:如何提取特征
算法:k近临,,,
✔ 前向传播:
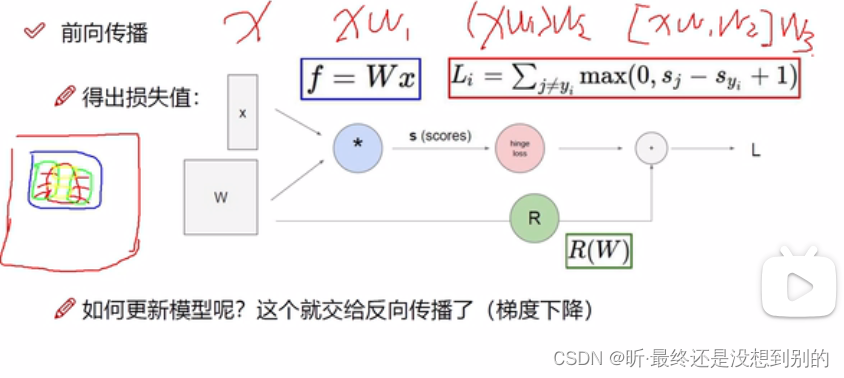
得分任务:
先随机生成,在迭代过程中哪个w好就用哪个
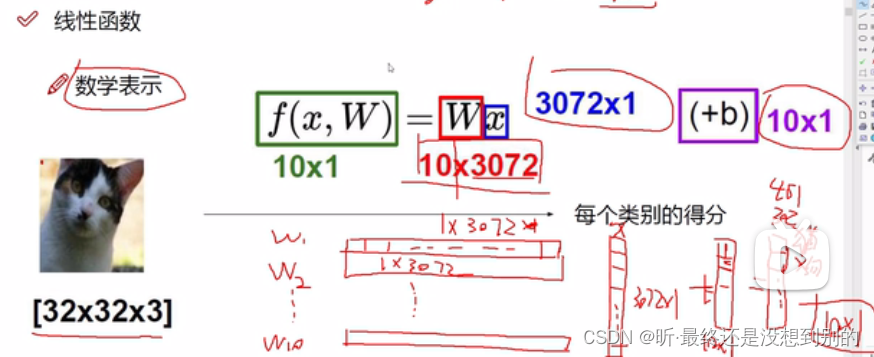
分类任务:
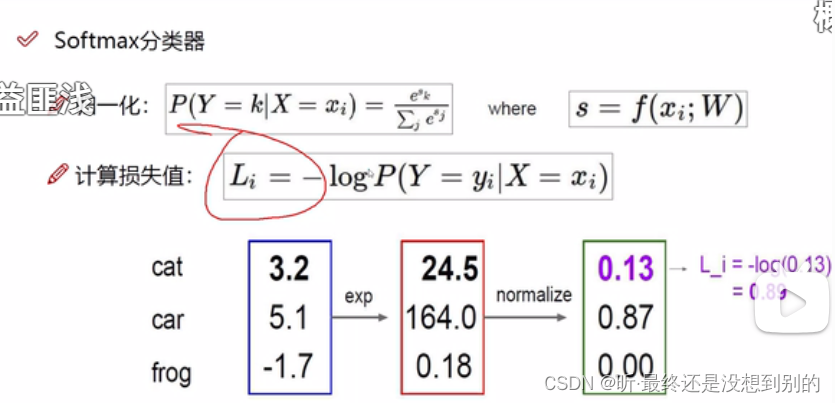
ps:

✔ 反向传播:链式法则

梯度下降法
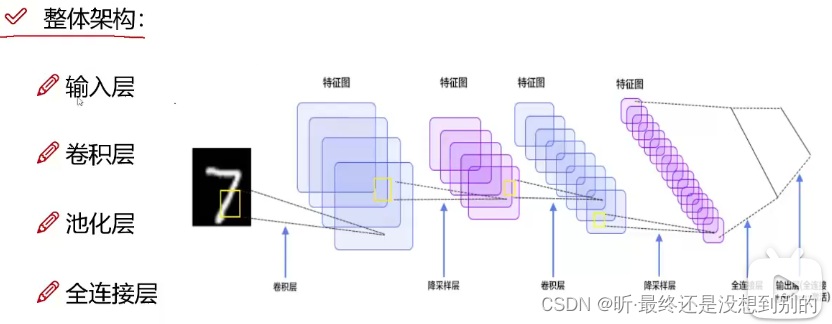
✔ 整体架构:
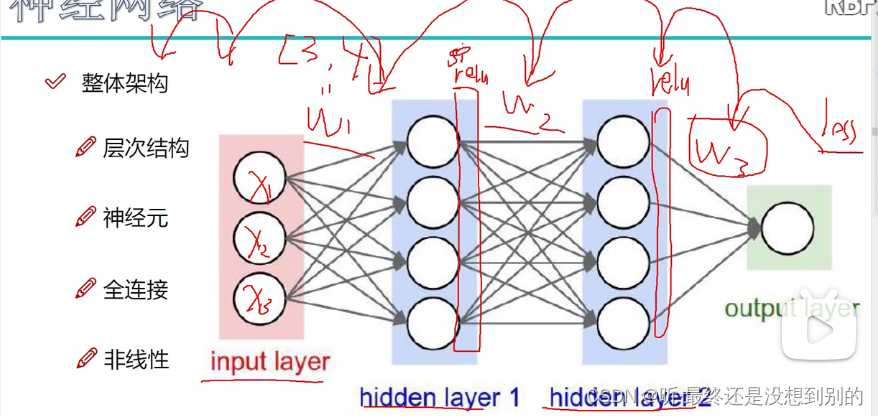
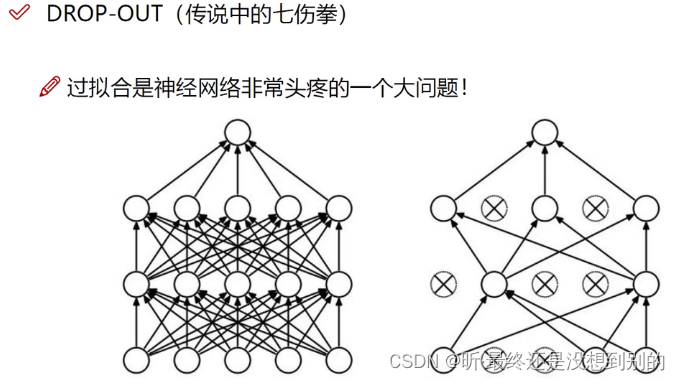
神经元个数越多(特征越多)分类效果越好
但可能产生过拟合(可以用正则化、dropout消减):
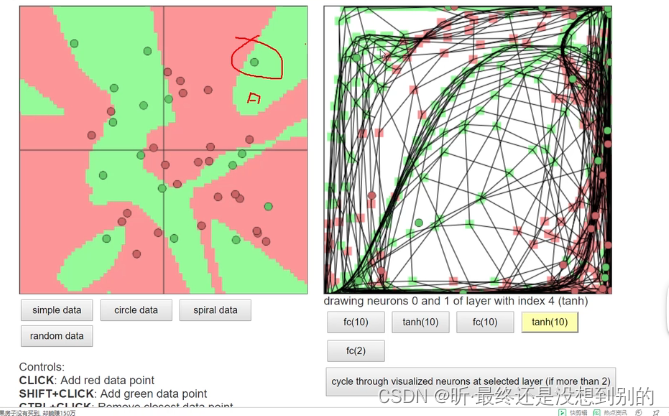
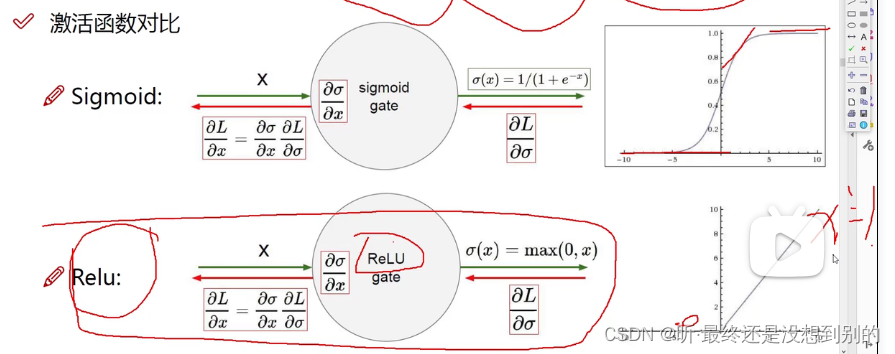
✔ 激活函数:
✔ 数据预处理:
训练阶段可以
卷积神经网络(CNN)
- 传统应用(计算机视觉):检测任务、分类与检索、超分辨率重构、医学任务、无人驾驶、人脸识别
- 与传统网络区别:二维到三维,保留空间信息,像素点-图像(乘1是做了灰度处理)
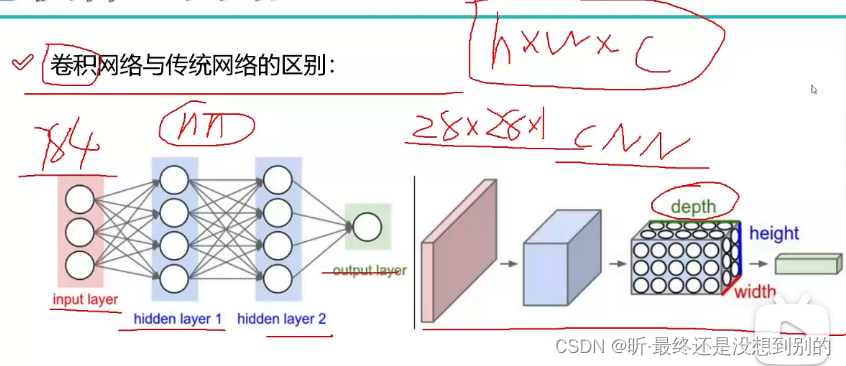
- 整体架构:
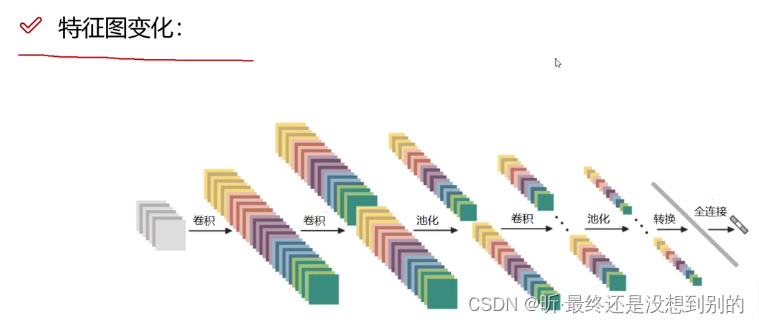
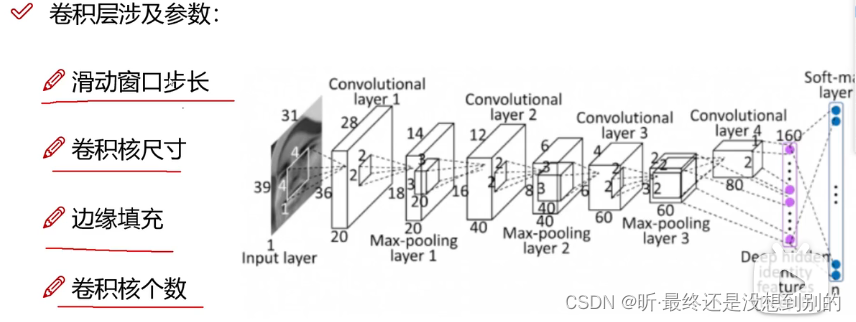
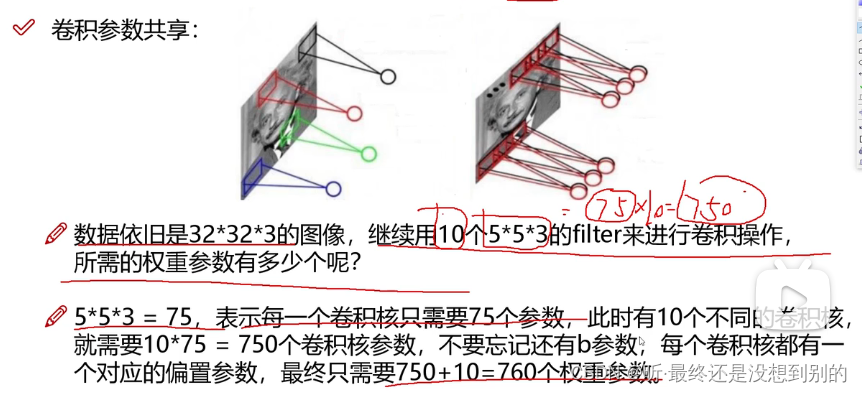
✔ 卷积层(卷积核filter和原图选取大小一样,做内积,加偏置项b,得到特征值,特征值组成特征图)
ps:filter可以有多个,决定有几张特征图
pps:每次滑动的距离是步长,可以自己设置
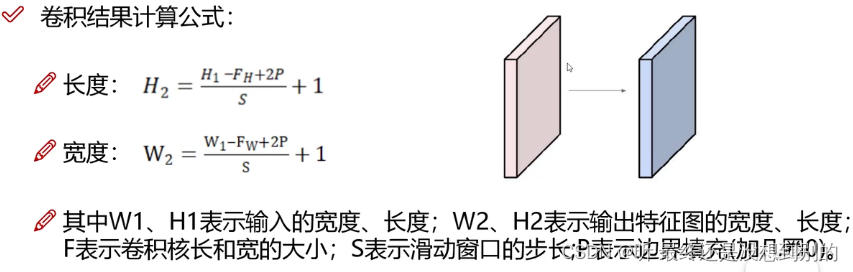
ppps:越边界的点对最终结果影响越小,为了提高边界的利用率,可边缘填充。只能用0填充 +pad1就是加1圈
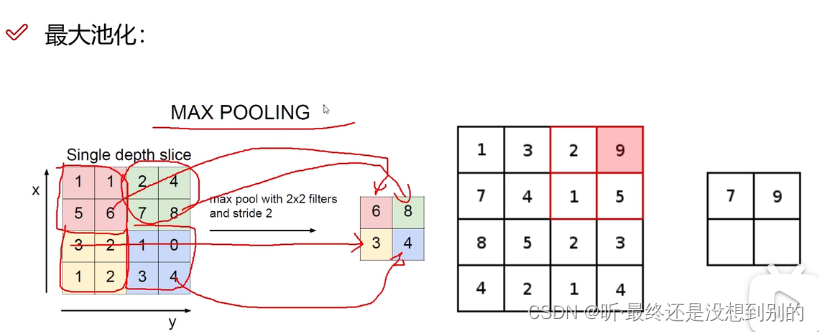
✔ 池化层(起压缩的作用)
ps:是一个筛选的过程,不涉及矩阵计算,有最大池化(基本上都用这个)、平均池化(淘汰)
✔ 全连接层(把三维特征图的拉长成一维特征向量)
ps:带参数的才能称之为一层
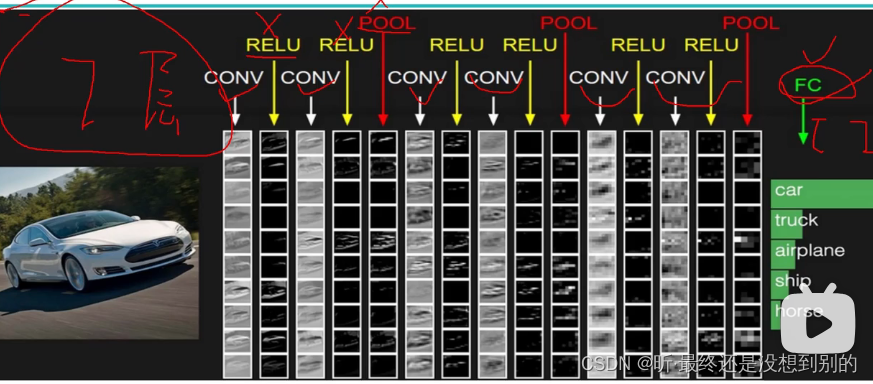
- 经典网络:
Alexnet:12年,8层,问题:卷积核、步长大
VGG:14年,16/19层,3*3,由于池化损失的信息在下一层中使特征图翻倍弥补回来,问题:训练时间长,16层比30层效果好
Resnet残差网络(何凯明):同等映射
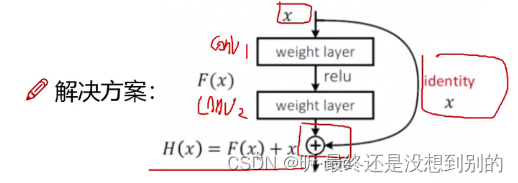
ps:感受野:由最后的值推测原始数据的窗口大小(越大越好)

递归神经网络(RNN)
- (常用于自然语言处理)可以处理时间序列。会把前一层中间结果保存下来参与下一层运
- 缺点:误差累积
ps: LSTM是对RNN的改进,加入参数C控制模型复杂度 - 自然语言处理-词向量模型-Word2Vec
✔ 过程
分词:jieba
构建词向量:想快一点用50维,想精确一点用300维
构建训练数据:

进行训练:
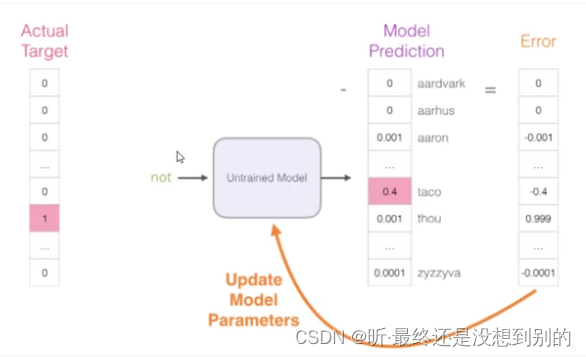
ps:反向传播不仅要更新权重w,还要更新输入数据
问题:语料库大的时候计算耗时
✔ 不同模型对比 工具包Gensim
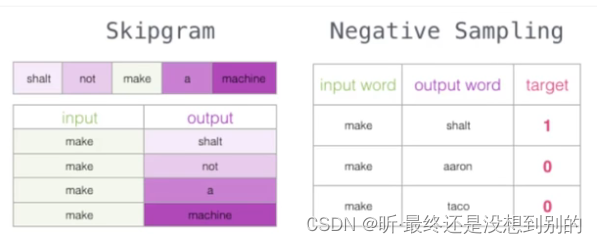
CBOW:输入上下文预测中间词

Skipgram:输入中间词预测上下文
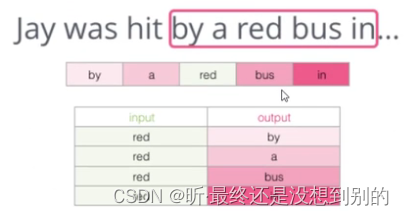
✔ 问题解决
初始方案:改 输入一个词预测一个词 为 输入两个词预测相关性 target:1
但此时训练集构建出来的标签全为1,无法进行较好的训练
优化方案:加入一些负样本(负采样模型)推荐参数5个
python(面向对象解释型程序设计语言)
- (1-19 https://www.bilibili.com/video/BV11x4y1E7aQ/?p=4&spm_id_from=pageDriver&vd_source=8afdf2d9fefd0cf019fbf34e67125765)
- 环境配置(python解释器+pycharm IDE)
win+R 运行窗口 – 输入cmd调出DOS窗口(python编程、cd改变路径、d:D盘、cd…退出当前路径、exit退出cmd)
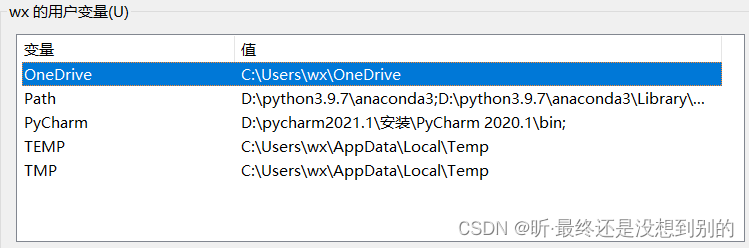
系统属性-高级设置-环境变量
程序编写
- 运行方法
✔交互模式:(1)IDLE(2)CMD用DOS窗口
✔其他:(1)pycharm 项目-文件夹-文件-运行(右键run)(2)新建文本,改后缀为.py,在dos窗口(cd修改路径或加python环境直接拖文件)或pycharm运行

ps:主题字体设置-settings - bug、debug、注释、输出
✔bug:(1)拼写错误:name error(2)语法错误syntax error:多个print写在一行(3)缩进错误indentation error(4)标点符号错误
✔debug:(1)打断点 在代码框左侧点击(2)调试 右键debug、左下角、右上角
ps:

✔注释:(1)单行注释:#(3)多行注释:三对双/三对单
ps:三引号用在变量定义里用来定义多行字符串的内容
一次性单行注释ctrl+/
✔输出:
- 变量、数值类型、字符串、格式化输出
✔变量的定义:变量 = 值(包含变量名称、变量保存的数据、存储的数据类型、变量地址)

ps:=是赋值、==才是等于
标识符(自己命名的变量名):
关键字:

✔数值类型


ps:指数形式3.1E5是3.1乘以10的5次,输出为浮点型 可使用type查看

pps:数据类型(1)Number数值类型(2)String字符串(3)list列表(4)元组(5)集合(6)字典
✔字符串

单双引号都可以
三引号用在变量定义里用来定义多行字符串的内容

字符串内部使用单或双引号,使用转义符


✔格式化输出:定义模板照模板输出 【蛇蛇文件test】
(1)模板 % 变量名

(2)format()
不带编号,即{}
带数字编号,可调换顺序,即{1} {2}
设置参数

(3)f’{表达式}’ # 不需要考虑数据类型


- 转义字符、算数运算符、输入
✔转义字符
\n 换行 print默认自带换行符
\t 制表符,一个tab键(4个空格)的距离 用于排版
\ 反斜杠
’ 单引号 字符串内用引号需要转义
✔算数运算符




ps:eval返回的是值
✔输入input()
一般存储到变量方便使用
输入的数据当做字符串处理,但可以做类型转换 - if判断、比较运算符、逻辑运算符、三元表达式
✔if判断
true和false界定:1.任何非零和非空对象都为真,解释为true 2.数字0、空对象、none对象都为假,解释为false 3.判断的返回值为true或false
ps:要大写!!!!记得if和else后面的冒号
✔比较运算符

✔if、elif、else组合
满足多个条件时只会执行第一个
同层级的if和else同缩进
✔if嵌套

这布尔咋输入?????
✔逻辑运算符


ps:判断true的时候不用写==1
✔三元表达式 是if判断的另一种写法
# 猜拳题答案
import random # 引用库写在最前面
ni = int(input('你要输入的拳是(石头0、剪刀1、布2):')) # 变量的命名简单易懂
com = random.randint(0,2) # 注意random的使用
print (f'电脑的出拳是{com}') # f‘{}’的格式化输出你忘了?
if (ni==0 and com==1) or (ni==1 and com==2) or (ni==2 and com==0): # 逻辑判断符的应用,为了看清楚可以加括号
print('你赢了')
elif ni==com:
print('平局')
else:
print('电脑赢了')
# random扩展
import random
com = random.choice(['剪刀','石头','布']) # 用[]括起来,用于传递一个list
print (f'电脑的出拳是{com}')
- 程序的三大流程、while循环、for循环、break和continue
✔三大流程(顺序、分支、循环)
✔while循环
i = 1
while i<=10:
print('i love you!')
i+=1
# 1-100累加
a = 1
sum =0
while a<=100:
b=a+1
sum=sum+a+b
a+=2
print(sum)
## 答案
a = 1
sum = 0
while a<=100:
sum=sum+a
a += 1
print(f'1-100的累计和为:{sum}')
#1-100偶数累加
a = 2
sum = 0
while a<=100:
b=a+2
sum=sum+a+b
a+=4
print(sum)
## 答案1
a = 1
sum = 0
while a<=100:
if a % 2 ==0: #判断是否为偶数
sum =sum+a
a += 1
print(f'1-100的偶数累计和为:{sum}')
## 答案2 只判断5次,更好
a = 2
sum = 0
while a<=100:
sum =sum+a
a += 2
print(f'1-100的偶数累计和为:{sum}')
#一天说3遍说3天
day =0
while day<3:
say = 0
while say<3:
print('好好学习天天向上')
say = say+1
day=day+1
print('再坚持一分钟')
print('*******学不了一点*******')
# 打印星星
i=0
while i<=5:
print((' * ')*i)
i+=1
## 法二 循环嵌套
row =1
while row <=5:
col = 1
while col<=row:
print('*',end=' ')
col+=1
print() # 手动换行
row+=1
# 打印乘法表
row =1
while row <=9:
col = 1
while col<=row:
# 格式化输出,法一 %:
# print('%d*%d =%d' %(col,row,row*col),end='\t')
# 法二
# print(f'{col}*{row}={col*row}',end='\t')
# 法三
print('{}*{}={}'.format(col,row,col*row),end='\t') # 中间是点点
col+=1
print() # 手动换行
row+=1
✔for循环

可迭代对象:能通过for循环一个个把数取出来的对象
range()函数:左闭右开,可创建一个整数列表,一般用在for循环中
range(start,end,step)
start默认从0开始
step默认为1
# 1-100求和
sum = 0
for i in range(1,101):
sum = sum + i
print(f'求和结果是{sum}')
# 打印乘法表
for row in range(1,10):
for col in range(1,row+1):
print(f'{col}*{row}={col*row}',end='\t')
print()
✔break和continue 只能在循环体内部使用

ps:break跳出的是当前循环,continue结束的是当前循环的本轮循环
# break
## while
a = 0
while a<5:
a+=1
if a==3:
break
print(a)
else:
print('结束') # while和else可以配对使用
## for
for i in range(3):
print(i)
break
## 嵌套循环
for i in range(5):
print('haha')
for i in range(3):
if i == 2:
break
else:
print(i)
# continue
## while
a = 0
while a<5:
a+=1
if a==3:
continue
print(a)
else:
print('结束') # 不输出3
## for
for i in range(5):
if i== 3:
continue
print(i)
- 字符串、字符串常见操作
✔字符串
字符编码:本质是二进制数据与语言文字的一一对应关系。字符–翻译–二进制
ASCII编码 英文 单字节
GBK 中文 双字节
unicode 兼容万国语言
utf-8 对不同的字符用不同的长度表示 中文用3个字节
✔编码和解码
# 编码 encode:字符转换为字节流
a = 'hello'
print(type(a))
al = a.encode() # 给a编码
print(al)
print(type(al))
b = b'hello' # 在字符串前面加b就是字节码的形式
print(b)
print(type(b))
# 解码 decode:字节流转换为字符
a1 = b'hello'
a2 = a1.decode() # 还原成字符串
print(a2)
✔下标/索引、切片
下标/索引:左闭右开
# 通过索引取值 正数从0开始,倒数从-1开始
name = 'abcde'
print(name[0]) #a
print(name[1]) #b !从5开始就报错
name2 = 'abcdsssfghjktrrdytyere'
print(name2[-1]) #e
切片:[起始:结束:步长]
name = 'class_name_hahah'
a= name[6]
b= name[7]
c= name[8]
d= name[9]
print(a+b+c+d) # 逐个取然后拼接name 麻烦
print(name[6:10:1])
print(name[6:10:2])
print(name[:]) # 没有限制就是取到所有
print(name[-1:3:-1]) # 倒序输出
ps:切片超出范围不报错,截止到最后一位
pps:方向和步长要一致,否则输出为空白
✔字符串常见操作

(1)find() 字符串序列.find(str,开始下标,结束下标)
检测子串str是否包含在原字符串内,如果在返回第一次找到的索引值,否则返回-1
a = 'hello world'
print(a.find('h')) #0
print(a.find('hello')) #0
print(a.find('hello',1,5)) #-1
(2)index() 字符串序列.index(str,开始下标,结束下标)
与find语法一样,但找不到会报错
a = 'hello world'
print(a.index('hello',1,5)) #报错
(3)count() 字符串序列.count(str,开始下标,结束下标)
查找子串在原串出现次数
mystr = 'hello world'
print(mystr.count('l')) #3
print(mystr.count('l',3)) #2
修改:
(4)replace() 字符串序列.replace(旧子串,新子串,替换次数)
mystr = 'hello world'
print(mystr.replace('l','a'))
print(mystr.replace('l','a',2))
(5)split() 字符串序列.split(用什么切,切的次数)
mystr = 'hello world'
print(mystr.split('l',3)) #['he', '', 'o wor', 'd']
print(mystr.split(' ',3)) #['hello', 'world']
其他修改方式:

(6)capitalize()
mystr = 'hello world'
print(mystr.capitalize()) #第一个字母变成大写
(7)lower()
mystr = 'HELLO'
print(mystr.lower()) #所有变成小写
(8)upper()
mystr = 'hello'
print(mystr.upper()) #所有变成大写
(9)title()
mystr = 'hello world'
print(mystr.title()) #首字母大写
判断:
(10)islower()
检测字符串是否都有由小写字母组成(True/False)
mystr = 'hello world'
print(mystr.islower()) #True
(11)isupper() 是否大写
mystr = 'hello world'
print(mystr.isupper()) #False
(12)isdigit() 是否数字
j =0
mystr = 'hello123'
for i in mystr:
if i.isdigit():
j+=1
print(j) #3 有几个数字
(13)startswith() 是否以什么开头
mystr = 'hello123'
print(mystr.startswith('h')) #True
(14)endswith() 是否以什么结尾
mystr = 'hello123'
print(mystr.endswith('3')) #True
增:
(15)+
name = 'six'
name2 = 'xinxin'
info = name+name2
print(info) #sixxinxin
(16)join
a = 'hello'
print('*'.join(a)) #h*e*l*l*o 每一个字符后加*
删:
(17)lstrip
a = ' hello'
print(a)
print(a.lstrip('h')) #删除左边的h 结果没变化说明只能删最左边的东西
print(a.lstrip()) #删除左边的空白
(18)rstrip 删除右边的空白
(19)strip 删除两边的空白
a ='\n\t itcast \t\n'
print(a) # itcast
print(a.strip()) #itcast !删的不是换行符
✔列表 是有序的集合,可以一次性存储多个数据,元素可是不同类型
name ='TOM'
li = ['a','b','c'] #用中括号包围所有元素,每个元素用逗号隔开
list =[1,1.5,'a','b',]
print(li[0])
print(li[-1])
#循环读取
##for
for i in li: #可迭代对象,可通过for in方式把元素一个个取出来
print(i)
##while
li_len = len(li) # len求列表元素个数
i=0
while i < li_len:
print(li[i]) # 通过下标取值
i +=1
相关操作

(1)增
#(1 +
language = ['python','c++','java']
birthday = [1991,1998,1995]
info = language+birthday
print(info)
#(2 insert 在索引前插入obj元素 listname.insert(indedx,obj) 列表名称.插入(索引,插入元素)
## 插入元素
l = ['python','c++','java']
l.insert(1,1998)
print(l)
## 插入元组 把元组当做整体插入,元组的访问比列表快
l = ['python','c++','java']
t = ('c#','go')
l.insert(2,t)
print(l)
#(3 append() 在末尾追加obj元素 listname.append(obj)
## 插入元素
l = ['python','c++','java']
l.append(1998)
print(l)
# 插入元组
l = ['python','c++','java']
t = ('c#','go')
l.append(t)
print(l)
#(4 extend() 在列表末尾添加obj,并且把obj中的元素拆分 listname.extend()
l = ['python','c++','java']
t = ('c#','go')
l.extend(t)
print(l)
(2)修改 本质是赋值
# (1 修改单个元素
nums=[1,4,3,6,10,5,8]
nums[2] = -10 # 通过下标访问指定元素并赋新值
print(nums)
# (2 修改一组元素
nums=[1,4,3,6,10,5,8]
nums[2:5] =[10,20,30] # 通过下标访问指定元素并赋新值
print(nums)
# (3 特殊情况:对空切片赋值,对应下标前插入所有元素
nums=[1,4,3,6,10,5,8]
print(nums[4:4])
nums[4:4]=[-1,-2,-3] #从下标为4的位置插入所有元素
print(nums) # [1, 4, 3, 6, -1, -2, -3, 10, 5, 8]
# (4 间隔修改
nums=[1,4,3,6,10,5,8]
nums[1:6:2]=[-2,-2,-2]
print(nums) # [1, -2, 3, -2, 10, -2, 8]
(3)删
#(1 del 删除整个列表 del listname
s = list('hello') # 把字符串转换成列表
print(s)
del s
print(s) # 删除整个列表,name 's' is not defined
#(2 del 删除单个值 del listname[index]
nums=[1,4,3,6,10,5,8]
del nums[0]
print(f'nums={nums}')
#(3 del 删除多个值
nums=[1,4,3,6,10,5,8]
del nums[2:5]
print(f'nums={nums}')
#(4 pop() listname.pop(index) 不写index默认删除最后一个元素
nums=[1,4,3,6,10,5,8]
nums.pop(3)
print(f'nums={nums}')
nums.pop()
print(f'nums={nums}')
#(5 remove() 值进行删除,无则报错;有相同值默认删除第一个
nums=[1,4,3,6,10,5,8]
nums.remove(3)
print(f'nums={nums}')
#(6 clear() 删除列表所有元素
nums=[1,4,3,6,10,5,8]
nums.clear()
print(f'nums={nums}')
#小结:根据位置索引删除,用del或pop;根据值删除,用remove;删除整个列表元素,用clear
(4)查
#(1 in/not in
list =['tom','xie','xin']
name =input('需要查找的名字是:')
if name in list:
print('找到了')
else:
print('找到了空气')
#(2 count() listname.count(obj) obj是要统计的元素,返回值为0代表不存在
nums =[1,2,3,2,4,5,2]
print(nums.count(2))
if nums.count(100): # count次数为0,0代表false,则执行false里的语句
print('100在列表里')
else:
print('100不在列表里')
#(3 index() listname.index(obj,star,end) 查找某个元素在列表中出现的位置
nums =[1,2,3,2,4,5,2]
print(nums.index(2))
(5)排序
#(1 reverse() 把原列表顺序倒置
nums =[1,2,3,2,4,5,2]
print('原列表:',nums)
nums.reverse()
print('倒置后:',nums)
#(2 sort() 默认从小到大排序
nums =[1,2,3,2,4,5,2]
nums.sort()
print(nums)
nums.sort(reverse=True) #从大到小
print(nums)
print(nums.sort()) # sort对原表进行修改,就地排序无返回值,和赋值打印一起使用,结果会返回Nine
#拓展:sort只应用于list的方法,sorted()是内建函数不仅局限于列表的操作
nums =[1,2,3,2,4,5,2]
b = sorted(nums)
print(b)
print(nums) # sorted默认从小到大排序,不对原列表进行修改
print(sorted(nums))
(6)列表推导式 [表达式 for 变量 in 列表] [表达式 for 变量 in 列表 if 条件]
li = [1,2,3,4,5,6,7,8,9]
print([i*2 for i in li]) # i的取值来自列表li
# for循环
li = [1,2,3,4,5,6,7,8,9]
li2=[]
for i in li: # i的取值来自列表li
li2.append(i*2) # 在列表末尾添加元素i*2
print(li2)
# while循环
li = [1,2,3,4,5,6,7,8,9]
li2=[]
i =0
while i <= len(li):
if i in li:
li2.append(i * 2)
i+=1
print(li2)
- 元组、字典、集合、公共操作
✔ 元组 不能被修改,不支持删除,提高了代码编写的安全性,尽量多使用
定义:由用逗号隔开,用小括号包围的元素组成,如(1,2,3)
ps:定义单个元素最后一定要加逗号
tu =(10) # 与tu =10等效
print(tu)
print(type(tu)) # <class 'int'>要定义为元组必须在最后加逗号
tu1 =(10,)
print(tu1)
print(type(tu1)) # <class 'tuple'>
#可以使用下标操作
num_list =(10,20,30)
print(num_list[0])
#赋值测试是否能修改
num_list[0] = 100
print(num_list) # TypeError: 'tuple' object does not support item assignment 类型错误:元组类型不支持项赋值
#测试是否能删除
tuplel =('aa','bb','cc','dd')
del tuplel[2] # 测试删除下标为2的元素
print(tuplel) # TypeError: 'tuple' object doesn't support item deletion 类型错误:元组对象不支持项删除
相关操作–查找
# 下标
t1 =('aa','bb','cc','dd')
print(t1[0])
# index() 存在返回下标,否则报错
t1 =('aa','bb','cc','dd')
print(t1.index('aa')) # 0
# count() tuplel.count(obj) obj为要求统计个数的元素对象
t1 =('aa','bb','cc','dd')
print(t1.count('aa'))
# len() 统计元组中所有数据的个数
t1 =('aa','bb','cc','dd')
print(len(t1))
# 拓展:元组“可变”的情况
t2 =(10,20,['aa','bb','cc','dd'],40)
print(t2[2]) # 把列表看做一个整体元素
print(t2[2][1]) # 取列表中元素要有二维思想
t2[2][1] ='xinxin'
print(t2) # 元组中的列表是可变的
✔ 字典 键值对成对出现,键和值一一映射,绑定,和数据顺序无关,所以不支持下标
定义:dic = {key:value,key:value}
ps:符号为大括号,数据为“键值对”,键值对之间用逗号隔开
li =['TOM','男',20]
print(li[0])
dict2 ={'name':'Tom','age':20,'name':'Lucy'}
print(dict2) # {'name': 'Lucy', 'age': 20} 有重复键时覆盖写,保持键的唯一性
字典操作
# 改
dict1 ={'name':'Tom','age':20,'gender':'男'}
dict1['name']='xinxin'
print(dict1)
# 增
dict1 ={'name':'Tom','age':20,'gender':'男'}
dict1['id']=110
print(dict1)
对于key,无则添加,有则覆盖
# 删
## del
dict1 ={'name':'Tom','age':20,'gender':'男'}
del dict1['gender']
print(dict1)
## clear()
dict1.clear()
print(dict1)
# 查
## 键
dict2 ={'name':'Tom','age':20,'name':'Lucy'}
print(dict2['name'])
## len() 查看键值对个数
dict1 ={'name':'Tom','age':20,'gender':'男'}
print(len(dict1))
## keys() 查看所有键
dict1 ={'name':'Tom','age':20,'gender':'男'}
print(dict1.keys()) # dict_keys(['name', 'age', 'gender'])
## values() 查看所有值
dict1 ={'name':'Tom','age':20,'gender':'男'}
print(dict1.values()) # dict_values(['Tom', 20, '男'])
## items() 可理解为“项”,查看所有键值对
dict1 ={'name':'Tom','age':20,'gender':'男'}
print(dict1.items()) # dict_items([('name', 'Tom'), ('age', 20), ('gender', '男')])
# 循环遍历
## for ... in
dict1 ={'name':'Tom','age':20,'gender':'男'}
for value in dict1.values(): # 第一个value只代表一个变量,变量名可自定义
print(value)
for i in dict1.values():
print(i)
for key in dict1.keys():
print(key)
for item in dict1.items():
print(item)
for key,value in dict1.items():
print(f'{key}={value}') # 格式化输出
✔ 集合
定义: (1)由用逗号隔开,用大括号包围的元素组成,如s1={10,20,30} type–set
(2)用set(),如s2=set(‘abcdef’) type–set
ps:{}定义的是空字典,只有set()是定义空集合
特性:无序不重复,不支持下标操作
集合操作:
# 增
## add,追加数据是具体某个元素
s1 ={10,20}
s1.add(100)
print(s1) #{100, 10, 20}
s1.add(10) #{100, 10, 20},自动去重
## update(),追加的数据必须是可迭代对象(如列表、集合、字典、元组)
s1 ={10,20}
s1.update(100)
print(s1) #TypeError: 'int' object is not iterable 整形不是可迭代对象
s1 ={10,20}
###加列表
s1.update([100]) #[100]是列表为可迭代对象
print(s1) #{100, 10, 20}
###加元组
s1.update((22,11))
print(s1) #{10, 11, 20, 22}
###加集合
s1.update({22,11})
print(s1) #{20, 22, 10, 11}
###加字典 只添加了key(字典的键值对是一个整体,代表一个元素)
s1.update({22:11})
print(s1) #{10, 20, 22}
###实例:把x和y合并,并去重 x={'apple','banana','cherry'} y={'google','runoob','apple'}
###(1)
x={'apple','banana','cherry'}
y={'google','runoob','apple'}
x.update(y)
print(x) #{'banana', 'runoob', 'google', 'cherry', 'apple'}
###(2)
x.add(y)
print(x) #TypeError: unhashable type: 'set'
# 删
## remove() 删除集合中指定的数据,如果数据不存在则报错
s1 ={10,20}
s1.remove(10)
print(s1) #{20}
s1.remove(10)
print(s1) #KeyError: 10
## discard() 丢弃 删除集合中指定的数据,如果数据不存在则报错
s1 ={10,20}
s1.discard(10)
print(s1) #{20}
## pop() 随机删除集合中某个数据,并返回这个数据
s1={10,20,30,40,50,60}
del_num=s1.pop()
print(del_num)
# 交集 &
a ={1,2,3,4}
b ={3,4,5,6}
se =a&b
print(se) #{3, 4}
# 并集 |
se =a|b
print(se) #{1, 2, 3, 4, 5, 6}
✔ 公共操作

#(1)+ 拼接
#字符串
str1 ='aa'
str2 ='bb'
str3 =str1+str2
print(str3)
#列表
list1 =[1,2]
list2 =[3,4]
list3 =list1+list2
print(list3)
#元组
t1 =(1,2)
t2 =(3,4)
t3 =t1+t2
print(t3)
#(2)* 复制
#列表
list1=['hello']
print(list1*4)
#字符串
print('*'*10)
#(3)in/not in 判断结果是True或False
#列表
list1=['a','b','c','d']
print('a' in list1)
公共方法

#(1)len() 字符串、列表、元组、集合、字典都适用
##集合
s1={10,20,30}
print(len(s1))
#(2)del 字符串、列表适用
str1='abc'
del str1
print(str1)
#(3)max()/min() 统计学适用
##列表
list1=[10,20,30,40]
print(max(list1))
print(min(list1))
#(4)range() 常与for in循环搭配使用
for i in range(4):
print(i)
#(5)enumerate() (下标,数据)一一列出,通常用for来遍历
list1=['a','b','c']
for i in enumerate(list1):
print(i)
容器类型推导式:用几行表达式创建有规律的列表
# 列表推导式
##用while
list1=[]
i=0
while i <10:
list1.append(i)
i+=1
print(list1)
##用for
list1=[]
for i in range(10):
list1.append(i)
print(list1)
##用列表推导式
list1=[i for i in range(10)]
print(list1)
# 元组推导式
t1=(i for i in range(10))
print(t1) #返回的是对象地址,需要用tuple转换为元组
print(tuple(t1))
# 字典推导式
dict1={i:i**2 for i in range(1,5)}
print(dict1)
# 集合推导式
list1=[1,1,2]
set1={i**2 for i in list1}
print(set1) #去重后只剩两个元素{1, 4}
- 类型转换、深浅拷贝
✔类型转换
python3有6大标准数据类型
number数字:int,float,bool,complex
string字符串 str()
list列表 list()
tuple元组 tuple()
set集合 set()
dictionary字典 dictionary()

类型转换想获取什么类型就用相应函数
#(1)转为字符串
a=5
print(type(a)) #<class 'int'>
b=str(a)
print(b,type(b)) #5 <class 'str'>
#(2)转为元组
list1=[1,2]
print(tuple(list1)) #(1, 2)
print(type(tuple(list1))) #<class 'tuple'>
#(3)转为列表
t1=(1,2)
print(list(t1)) #[1, 2]
print(type(list(t1))) #<class 'list'>
#(4)转为字典
a=['a1','a2','a3','a4']
b=['b1','b2','b3']
c=zip(a,b) #用zip把两个列表打包绑定,然后转换成字典
print(c) #返回的是对象地址
print(dict(c)) #{'a1': 'b1', 'a2': 'b2', 'a3': 'b3'}
✔深浅拷贝
传递引用 地址相同
# 定义变量
a=10
b=10
print(id(a)) #1682112735824
print(id(b)) #1682112735824 a和b的内存地址一样,b没有重复存放10这个数据,而是引用了a的内存地址。即b=10的指针指向了a的地址
#当两个变量数值相同时共用一个存放数值的内存空间。节省内存空间
# 定义列表
a=[1,2,3,4]
print(a,id(a))
b=a
print(b,id(b)) #赋值操作时b引用了a的内存地址,没有数据重复存储
拷贝copy:在内存中开辟一个空间存储相同的值,做备份提高数据安全性 地址不同
import copy
a=[1,2,3,4,5]
a_copy=copy.copy(a) #复制a的信息
print(a_copy) #[1, 2, 3, 4, 5]
print(id(a)) #2453361473664
print(id(a_copy)) #2453360855680 内存地址不同,与引用有区别
深浅拷贝

# 深拷贝:修改原数据不会对复制后数据产生影响
import copy
a=[1,2,3,[4,5,6]] #两层的数据列表
a_deepcopy=copy.deepcopy(a)
print(a_deepcopy) #[1, 2, 3, [4, 5, 6]]
print(a,id(a)) #[1, 2, 3, [4, 5, 6]] 2536703572416
print(a_deepcopy,id(a_deepcopy)) #[1, 2, 3, [4, 5, 6]] 2536703570240
##修改原数据a第一层元素的值时,查看a_deepcopy数据的变化---不变
a[2]=100
print(a) #[1, 2, 100, [4, 5, 6]]
print(a_deepcopy) #[1, 2, 3, [4, 5, 6]]
##修改原数据a第二层元素的值时,查看a_deepcopy数据的变化---不变
a[3][1]=100
print(a) #[1, 2, 100, [4, 100, 6]]
print(a_deepcopy) #[1, 2, 3, [4, 5, 6]]
# 浅拷贝:数据半共享,复制数据会独立存放,但只拷贝成功到原数据第一层,第二层会随着原数据变
import copy
a=[1,2,3,[4,5,6]]
a_copy=copy.copy(a)
print(a,id(a)) #[1, 2, 3, [4, 5, 6]] 2011959226880
print(a_copy,id(a_copy)) #[1, 2, 3, [4, 5, 6]] 2011959226496
##修改原数据a第一层元素的值时,查看a_copy数据的变化---不变
a[2]=100
print(a) #[1, 2, 100, [4, 5, 6]]
print(a_copy) #[1, 2, 3, [4, 5, 6]]
##修改原数据a第二层元素的值时,查看a_copy数据的变化---变
a[3][1]=100
print(a) #[1, 2, 100, [4, 100, 6]]
print(a_copy) #[1, 2, 3, [4, 100, 6]]
# 小结:
# 深拷贝:完全复制,原数据发生变化,备份数据不会有任何影像---如日常备份
# 浅拷贝:半复制半数据共享,原数据第二层变化,备份数据也会变化---如给一个表链接另一个表,希望一个变的时候另一个也更新,如excel函数的使用
- 不可变对象、可变对象
✔不可变对象:存储空间保存的数据不允许被修改。是针对值(数据内容)来说的,原变量值不变,修改后的新值内容地址会变化
常见的不可变对象:数值类型、字符串、元组
意义:代码更安全,尽量多使用
#int
i=73
print(type(i)) #<class 'int'>
print(i) #73
print(id(i)) #1663269687920
i+=2
print(i) #75
print(id(i)) #1663269687984
#字符串
s1='abc'
print(id(s1)) #1910863295984
s1='abcd'
print(id(s1)) #1910863336048
✔可变对象:存储空间保存的数据允许被修改。内容可变,地址不变
常见的可变对象:列表、字典、集合
#列表
m=[5,9]
print(m) #[5, 9]
print(id(m)) #2549202434432
m+=[6]
print(m) #[5, 9, 6] 内容变化
print(id(m)) #2549202434432 地址不变
#集合
set1={1,2,'123'}
print(set1,type(set1),id(set1)) #{1, 2, '123'} <class 'set'> 2564406193056
set1.add(100)
print(set1,type(set1),id(set1)) #{1, 2, '123', 100} <class 'set'> 2564406193056















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









