







前言:想象一下,如果你拥有了一张能够涵盖世间万物、串联古今中外的知识网络图,只需轻轻一点,便能穿越时间与空间的壁垒,探寻那些看似不相关却实则紧密相连的信息线索,这正是知识图谱带给我们的神奇体验,知识图谱推理,正是这样一门结合了图论、人工智能和认知科学的交叉学科。它利用先进的信息抽取技术,从海量的非结构化数据中提取出实体、关系和属性,构建出一张张错综复杂却又井然有序的知识网络。然后,通过运用逻辑推理、机器学习等方法,这些网络能够自动分析、预测和解释复杂的现象和问题,为我们提供前所未有的洞察力和决策支持。
本文所涉及所有资源均在传知代码平台可获取
目录
概述
这项研究主要集中在基于图神经网络(GNN)的知识图谱推断上,尤其是对传播路径的应用和优化给予了特别的关注。目前已有大量关于传播模型构建及相关算法的文献报道,然而大多数都是针对特定场景或具体问题展开研究。在诸如智能问答和推荐系统这样的领域中,知识图谱推理扮演着至关重要的角色,然而,传统的GNN方法在执行效率和准确性上仍有其局限性,因此,如何有效地利用已有信息资源提高学习质量是当前该研究领域亟待解决的难题之一。
为了解决这些挑战,我们在这项研究中引入了AdaProp这一创新的自适应传播策略,并与传统的Red-GNN技术进行了实验性的比较。经过对AdaProp和Red-GNN两种技术的实际应用,并在多个数据集上进行了实验性的验证,研究结果揭示了AdaProp在多个性能指标上都实现了明显的进步。同时,基于此技术提出了一个面向智能问答和推荐的语义知识库构建框架。这项新发现不仅凸显了AdaProp在知识图谱推理方面的巨大潜能,同时也为这一领域未来的科学研究和实际应用指明了新的研究方向。本文最后总结全文内容并对进一步工作进行展望。AdaProp的成功应用不仅在理论上,也在实践中为知识图谱推理提供了新的可能性,这进一步强调了自适应传播策略的核心地位,本次实践借助论文地址实现,内容如下图所示:
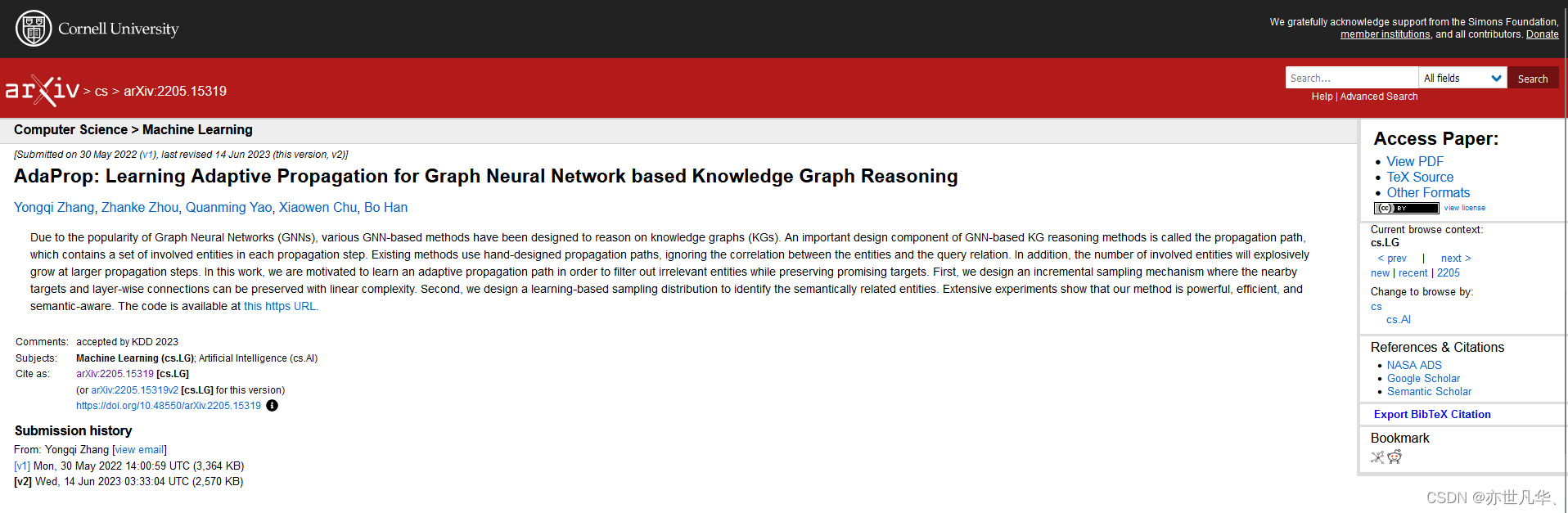
通过高效的采样技术对传播路径进行动态调整,不仅充分考虑了查询实体与查询关系之间的依赖关系,而且避免了传播时参与过多无关实体的情况,提高了推理效率,降低了计算成本。这就涉及制定新的采样策略来保证在传播路径拓展过程中能维持目标答案实体预测准确。为此,提出了一种名为AdaProp的基于GNN的方法,该算法可以根据给定的查询动态调整传播路径:
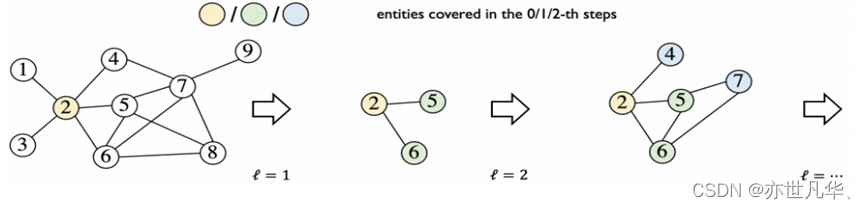
与传统方法的比较,在知识图谱推理领域,传统的方法如全传播、渐进式传播和受限传播都各自有优势和局限。提出的AdaProp方法在效率和性能上对这些传统方法进行了显著的优化:
演示效果
使用Python环境和PyTorch框架,在单个NVIDIA RTX 3070 GPU上进行,该GPU具有8GB的内存。实验的主要目的是验证AdaProp算法在传导(transductive)和归纳(inductive)设置下的有效性,并分析其各个组成部分在模型性能中的作用。这里使用family数据集,存放在./transductive/data文件夹下:
接下来配置实验环境的内容,这里先安装安装一下依赖:
torch == 1.12.1
torch_scatter == 2.0.9
numpy == 1.21.6
scipy == 1.10.1
然后这里就可以进入项目目录开始训练了,如下:
输入tensorboard指令,可视化结果,如下:
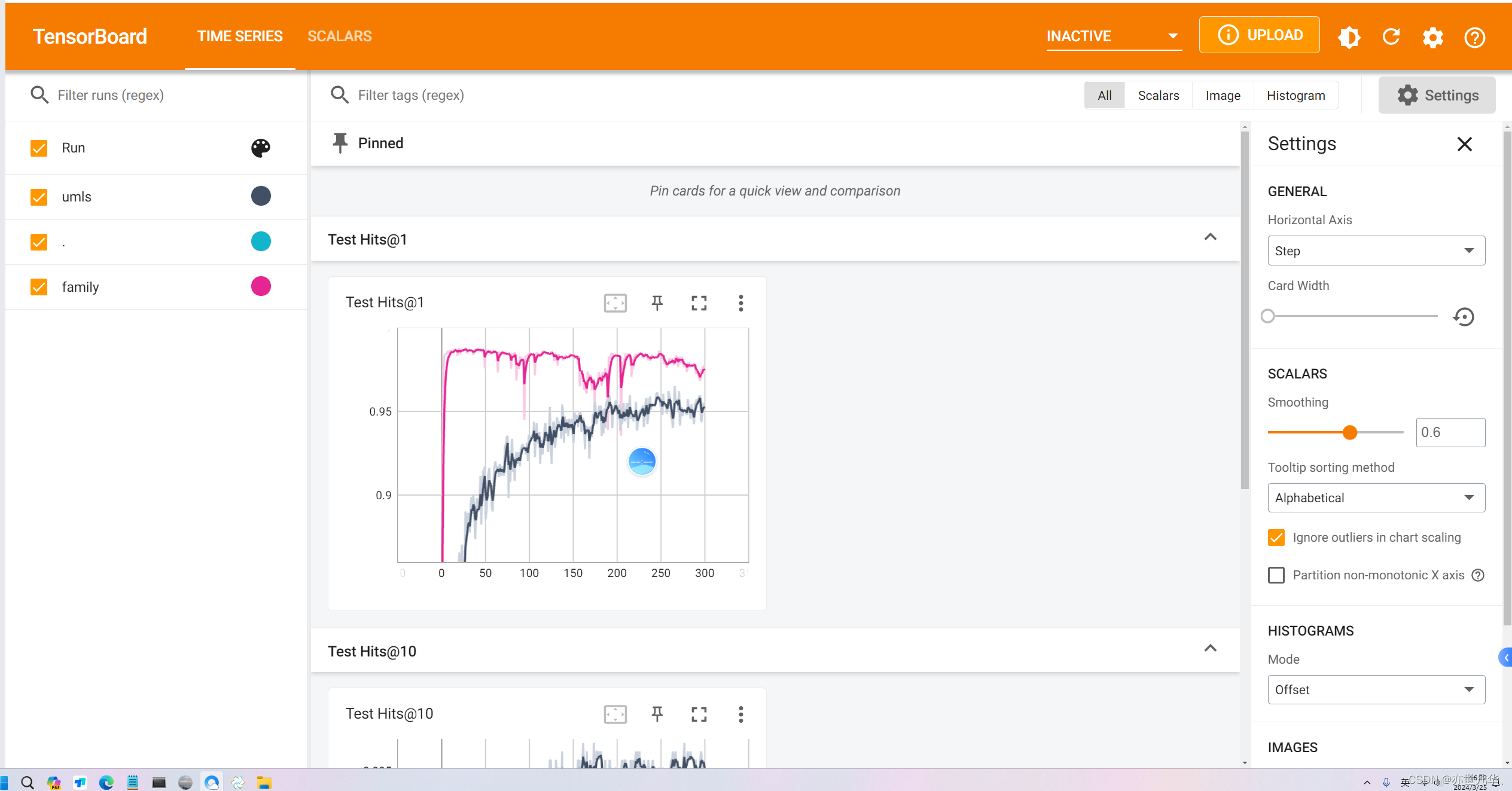
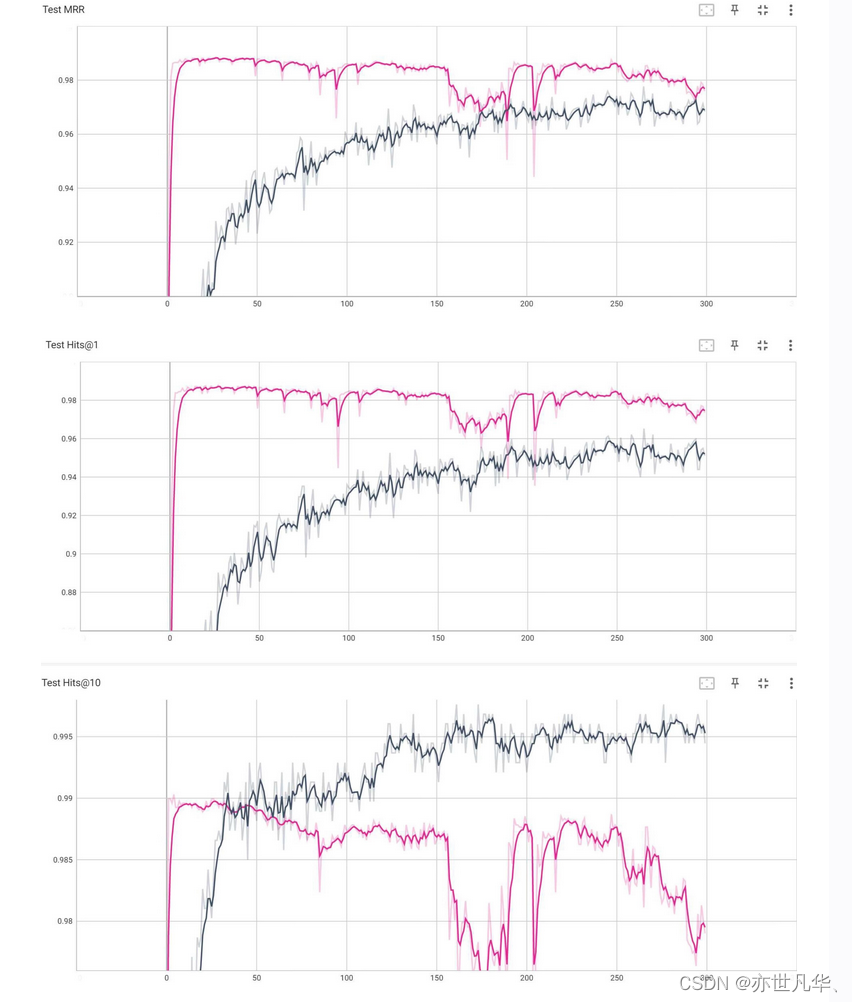
得到的实验结果如下所示:
核心代码
下面这段代码实现了一个训练循环,包括了模型的训练、验证和测试,并记录了训练过程中的损失和评估指标,具体如下:
1)首先代码检查输出路径,确保结果的存储目录存在,并创建它们(通过 checkPath 函数)
2)接着创建了一个模型对象 model,并设置了一些参数和路径。其中,opts 是模型的配置选项,loader 是数据加载器
3)然后代码将模型的配置参数写入一个性能文件中,这个文件记录了模型的配置信息。
4)在训练过程中,如果验证集上的 MRR(Mean Reciprocal Rank)超过了历史最佳值,则保存该模型,并记录相关信息
5)最后打印出最佳的验证集结果,并关闭记录训练过程的对象。
# start
check all output paths
checkPath('./results/')
checkPath(f'./results/{dataset}/')
checkPath(f'{loader.task_dir}/saveModel/')
model = BaseModel(opts, loader)
opts.perf_file = f'results/{dataset}/{model.modelName}_perf.txt'
print(f'==> perf_file: {opts.perf_file}')
config_str = '%.4f, %.4f, %.6f, %d, %d, %d, %d, %.4f,%s\n' % (
opts.lr, opts.decay_rate, opts.lamb, opts.hidden_dim, opts.attn_dim, opts.n_layer, opts.n_batch, opts.dropout,
opts.act)
print(config_str)
with open(opts.perf_file, 'a+') as f:
f.write(config_str)
if args.weight != None:
model.loadModel(args.weight)
model._update()
model.model.updateTopkNums(opts.n_node_topk)
if opts.train:
writer = SummaryWriter(log_dir=f'./tensorboard_logs/{dataset}')
# training mode
best_v_mrr = 0
for epoch in range(opts.epoch):
epoch_loss = model.train_batch()
if epoch_loss is not None:
writer.add_scalar('Training Loss', epoch_loss, epoch)
else:
print("Warning: Skipping logging of Training Loss due to NoneType.")
model.train_batch()
# eval on val/test set
if (epoch + 1) % args.eval_interval == 0:
result_dict, out_str = model.evaluate(eval_val=True, eval_test=True)
v_mrr, t_mrr = result_dict['v_mrr'], result_dict['t_mrr']
writer.add_scalar('Validation MRR', result_dict['v_mrr'], epoch)
writer.add_scalar('Validation Hits@1', result_dict['v_h1'], epoch)
writer.add_scalar('Validation Hits@10', result_dict['v_h10'], epoch)
writer.add_scalar('Test MRR', result_dict['t_mrr'], epoch)
writer.add_scalar('Test Hits@1', result_dict['t_h1'], epoch)
writer.add_scalar('Test Hits@10', result_dict['t_h10'], epoch)
print(out_str)
with open(opts.perf_file, 'a+') as f:
f.write(out_str)
if v_mrr > best_v_mrr:
best_v_mrr = v_mrr
best_str = out_str
print(str(epoch) + '\t' + best_str)
BestMetricStr = f'ValMRR_{str(v_mrr)[:5]}_TestMRR_{str(t_mrr)[:5]}'
model.saveModelToFiles(BestMetricStr, deleteLastFile=False)
# show the final result
print(best_str)
writer.close()
model.writer.close()写在最后
在科研领域,知识图谱推理为研究者们提供了一个强大的工具,帮助他们从海量的数据中挖掘出有价值的信息,揭示事物之间的复杂联系,从而推动科学的进步和创新。在商业领域,知识图谱推理能够帮助企业洞察市场趋势,优化商业决策,实现更高效的资源配置和价值创造。在教育领域,它则能够为学生提供个性化的学习路径和智能辅导,帮助他们更高效地获取知识,提升学习效果。
知识图谱推理不仅是一个技术工具,更是一种思维方式和探索智慧的方法。它鼓励我们打破传统的思维框架,从全新的角度去理解和分析问题。在这个信息爆炸的时代,我们需要的不仅仅是数据和信息,更需要的是能够从中提取出有价值的知识和洞见。而知识图谱推理正是这样一种能够帮助我们实现这一目标的有力工具,让我们共同期待知识图谱推理在未来的发展和应用,相信它将为我们带来更多的惊喜和收获。让我们携手探索智慧的无尽边界,共同开创一个更加美好的未来!
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。
【传知科技】关注有礼 公众号、抖音号、视频号



















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











