







一、方法介绍
传统方法:ARIMA模型
ARIMA模型,全称为自回归积分滑动平均模型,是时间序列分析中最经典也是最广泛使用的方法之一。其核心思想是通过对数据进行差分使其平稳,然后利用该平稳序列的滞后值和滞后预测误差来进行预测。这种方法在20世纪70年代由Box和Jenkins提出,并迅速成为经济学、金融学和环境科学中处理和预测时间序列数据的标准工具。
优势:ARIMA的主要优势在于其稳定性和解释性。它可以有效地模拟和预测具有明显线性趋势或季节性的时间序列数据。
局限性:ARIMA模型对于处理具有复杂非线性模式的数据则显得力不从心,特别是在数据存在长期依赖性时。
新型方法:LSTM网络
长短期记忆网络(LSTM)是一种先进的深度学习方法,属于循环神经网络(RNN)的一种变体,专门设计来解决传统RNN在处理长序列数据时的梯度消失问题。自1997年首次被提出以来,LSTM已经在多个领域显示出其强大的数据处理能力,尤其是在需要从时间序列中学习长期依赖关系的应用中。
优势:LSTM的优势在于其出色的灵活性和非线性建模能力。它可以通过内部的门控机制学习序列中哪些信息是重要的,从而进行长期的信息保存和短期的信息遗忘。
局限性:尽管LSTM在处理复杂和长序列数据方面表现优异,但它的计算成本较高,模型参数众多,需要大量数据进行训练,且对于模型的解释性较差。
二、数据集获取与预处理
数据获取
本文采用于Kaggle数据平台下载的“Daily Climate time series data”数据集作为研究对象,链接如下:https://www.kaggle.com/datasets/sumanthvrao/daily-climate-time-series-data
数据预处理
对原始训练集和测试集数据进行可视化分析,来决定下一步的预处理方式。
训练集
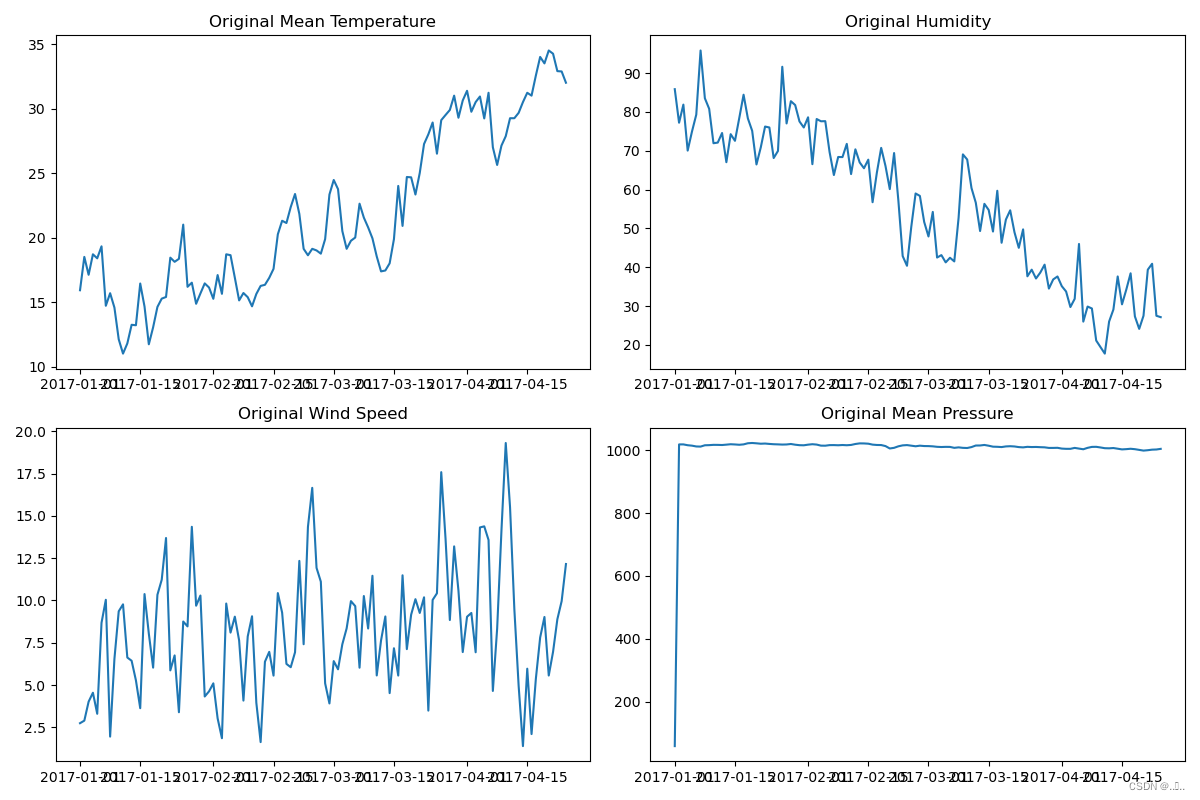
测试集
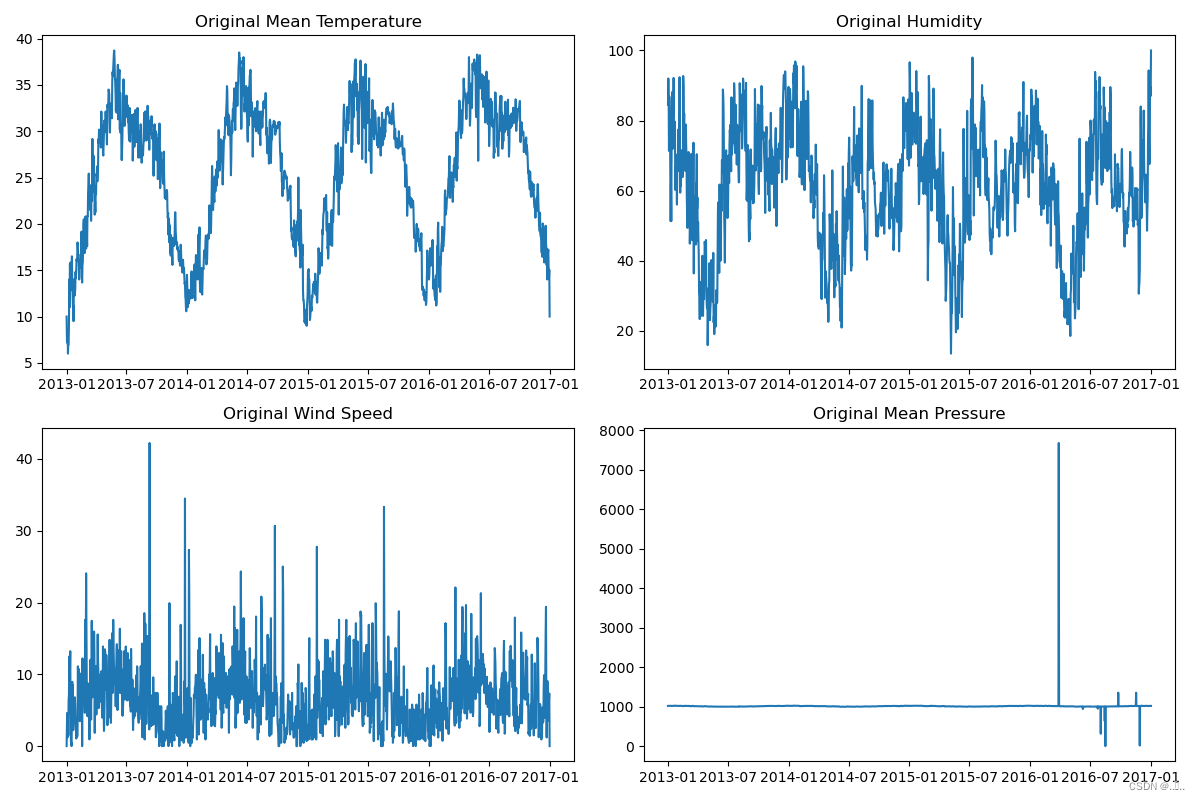
首
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2124
2124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









