







问:岭回归是在代价函数中使用了 L 1正则化项,请计算以下权重参数的 L 1正则化结果: w ={1,4.5,-1,10,0.5,-5)
答:L1正则化则是将权重参数的L1范数(绝对值之和)加入到代价函数中。
如果要计算给定权重参数w的L1范数,可以使用以下公式:
||w||_1 = |1| + |4.5| + |-1| + |10| + |0.5| + |-5| = 22
因此,该权重参数的L1正则化结果为22
岭回归基本原理
【岭回归一(Ridge Regression)】:正则化的线性模型
岭回归(RidgeQRegression))是一种用于处理线性回归问题的正则化方式。在普通的线性回归中,当特征数大于样本数时,模型会出现过拟合的问题。而岭回归通过限制参数的大小,可以有效地避免过拟合问题。
岭回归的实现方式是给损失函数添加一个正则项,这个正则项包含所有参数的平方和,并乘以一个系数alpha。
alpha的值越大,惩罚力度越大,参数越趋向于0,就越容易解决过拟合的问题。
要计算给定权重参数w的L1范数,可以使用以下公式:
||w||_1 = |w_1| + |w_2| + ... + |w_n|
L1范数是指向量中各个元素绝对值的和,可以用以下公式计算:
||w||1 = ∑|w[i]|
其中,w[i]表示向量w中的第i个元素。
例如,对于向量w = [1, -2, 3, -4, 5],其L1范数为:
||w||1 = |1| + |-2| + |3| + |-4| + |5| = 15
L1范数
L1范数表示向量中每个元素绝对值的和:
L1范数的解通常是稀疏性的,倾向于选择数目较少的一些非常大的值或者数目较多的insignificant的小值。
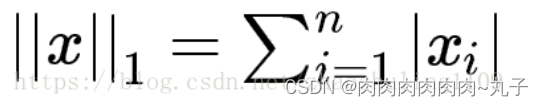
L2范数
L2范数即欧氏距离:
L2范数越小,可以使得w的每个元素都很小,接近于0,但L1范数不同的是他不会让它等于0而是接近于0.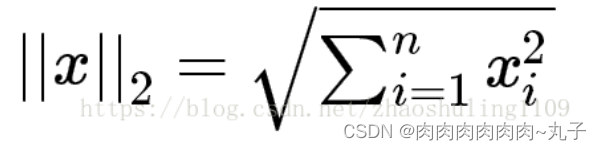
















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











