







前言
“概率论只不过是把常识用数学公式表达了出来。” ——拉普拉斯
1、条件概率
设
A
A
A与
B
B
B是样本空间
Ω
\Omega
Ω 中的两事件,若
P
(
B
)
>
0
P(B)>0
P(B)>0,则称
P
(
A
∣
B
)
=
P
(
A
B
)
P
(
B
)
P(A|B)=\frac{P(AB)}{P(B)}
P(A∣B)=P(B)P(AB)
为"在
B
B
B发生下
A
A
A的条件概率",简称条件概率。 即有乘法公式,
P
(
A
B
)
=
P
(
B
)
P
(
A
∣
B
)
P(AB)=P(B)P(A|B)
P(AB)=P(B)P(A∣B).
2、全概率公式
设
B
1
,
B
2
,
.
.
.
,
B
n
B_1,B_2,...,B_n
B1,B2,...,Bn 为样本空间
Ω
\Omega
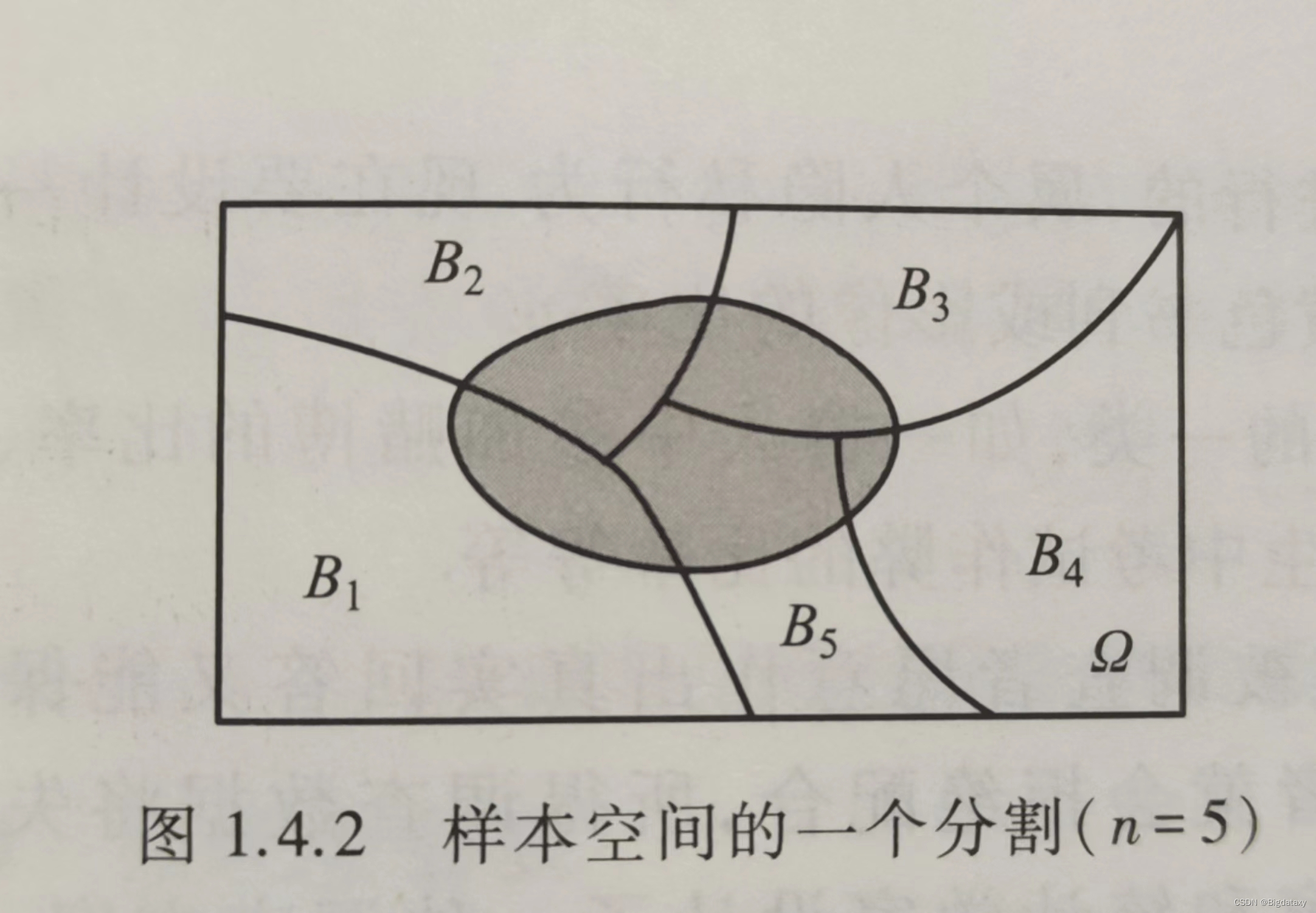
Ω 的一个分割(见下图),即
B
1
,
B
2
,
.
.
.
,
B
n
B_1,B_2,...,B_n
B1,B2,...,Bn 互不相容,且
⋃
i
=
1
n
B
i
=
Ω
\bigcup^n_{i=1}{B_i}=\Omega
⋃i=1nBi=Ω ,如果
P
(
B
i
)
>
0
,
i
=
1
,
2
,
.
.
.
,
n
P(B_i)>0,i=1,2,...,n
P(Bi)>0,i=1,2,...,n ,则对任一事件
A
A
A 有
P
(
A
)
=
∑
i
=
1
n
P
(
B
i
)
P
(
A
∣
B
i
)
P(A)=\sum^n_{i=1}P(B_i)P(A|B_i)
P(A)=i=1∑nP(Bi)P(A∣Bi)
证明:
因为
A
=
A
Ω
=
A
(
⋃
i
=
1
n
B
i
)
=
⋃
i
=
1
n
(
A
B
i
)
A=A\Omega=A(\bigcup^n_{i=1}{B_i})=\bigcup^n_{i=1}(AB_i)
A=AΩ=A(i=1⋃nBi)=i=1⋃n(ABi)
且
A
B
1
,
A
B
2
,
.
.
.
,
A
B
n
AB_1,AB_2,...,AB_n
AB1,AB2,...,ABn,互不相容,所以由可加性得
P
(
A
)
=
P
(
A
(
⋃
i
=
1
n
B
i
)
)
=
∑
i
=
1
n
P
(
A
B
i
)
P(A)=P(A(\bigcup^n_{i=1}{B_i}))=\sum^n_{i=1}P(AB_i)
P(A)=P(A(i=1⋃nBi))=i=1∑nP(ABi)
再将
P
(
A
B
i
)
=
P
(
B
i
)
P
(
A
∣
B
i
)
,
i
=
1
,
2
,
.
.
.
,
n
P(AB_i)=P(B_i)P(A|B_i),i=1,2,...,n
P(ABi)=P(Bi)P(A∣Bi),i=1,2,...,n,即可证全概率公式。
3、贝叶斯公式
在乘法公式和全概率公式的基础上立即可推得如下很著名的公式。
设
B
1
,
B
2
,
.
.
.
,
B
n
B_1,B_2,...,B_n
B1,B2,...,Bn 为样本空间
Ω
\Omega
Ω 的一个分割,即
B
1
,
B
2
,
.
.
.
,
B
n
B_1,B_2,...,B_n
B1,B2,...,Bn 互不相容,且
⋃
i
=
1
n
B
i
=
Ω
\bigcup^n_{i=1}{B_i}=\Omega
⋃i=1nBi=Ω ,如果
P
(
A
)
>
0
,
P
(
B
i
)
>
0
,
i
=
1
,
2
,
.
.
.
,
n
P(A)>0,P(B_i)>0,i=1,2,...,n
P(A)>0,P(Bi)>0,i=1,2,...,n ,则
P ( B i ∣ A ) = P ( B i ) P ( A ∣ B i ) ∑ j = 1 n P ( B j ) P ( A ∣ B j ) , i = 1 , 2 , . . . , n . P(B_i|A)=\frac{P(B_i)P(A|B_i)}{\sum^n_{j=1}P(B_j)P(A|B_j)},i=1,2,...,n. P(Bi∣A)=∑j=1nP(Bj)P(A∣Bj)P(Bi)P(A∣Bi),i=1,2,...,n.
证明:
由条件概率的定义
P
(
B
i
∣
A
)
=
P
(
A
B
i
)
P
(
A
)
P(B_i|A)=\frac{P(AB_i)}{P(A)}
P(Bi∣A)=P(A)P(ABi)
对上式的分子用乘法公式、分母用全概率公式,
P
(
A
B
i
)
=
P
(
B
i
)
P
(
A
∣
B
i
)
P
(
A
)
=
∑
j
=
1
n
P
(
B
j
)
P
(
A
∣
B
j
)
P(AB_i)=P(B_i)P(A|B_i)\\ P(A)=\sum^n_{j=1}P(B_j)P(A|B_j)
P(ABi)=P(Bi)P(A∣Bi)P(A)=j=1∑nP(Bj)P(A∣Bj)
即得
P
(
B
i
∣
A
)
=
P
(
B
i
)
P
(
A
∣
B
i
)
∑
j
=
1
n
P
(
B
j
)
P
(
A
∣
B
j
)
P(B_i|A)=\frac{P(B_i)P(A|B_i)}{\sum^n_{j=1}P(B_j)P(A|B_j)}
P(Bi∣A)=∑j=1nP(Bj)P(A∣Bj)P(Bi)P(A∣Bi)
结论得证.
Bayesain在机器学习重要地位的理解
经典的Bayesian在机器学习中如此重要,就是因为人们希望机器人能像人那样思考,而很多问题是需要计算机在已知条件下做出最佳决策的决策,而贝叶斯公式就是对人脑在已知条件下做出直觉判断的一种数学表示。
为更好的理解“贝叶斯公式就是对人脑在已知条件下做出直觉判断的一种数学表示。”
假设今天的天气情况一共有3种,雨天、晴天、雪天,今天早上天上乌云密布,你需要判断今天的天气情况为哪一种,根据以往的生活经验,一般情况下都会判断为雨天,即由贝叶斯公式有:
P
(
雨
天
∣
乌
云
密
布
)
=
P
(
雨
天
)
P
(
乌
云
密
布
∣
雨
天
)
P
(
雨
天
)
P
(
乌
云
密
布
∣
雨
天
)
+
P
(
晴
天
)
P
(
乌
云
密
布
∣
晴
天
)
+
P
(
雪
天
)
P
(
乌
云
密
布
∣
雪
天
)
=
1
P(雨天|乌云密布)=\frac{P(雨天)P(乌云密布|雨天)}{P(雨天)P(乌云密布|雨天)+P(晴天)P(乌云密布|晴天)+P(雪天)P(乌云密布|雪天)}=1
P(雨天∣乌云密布)=P(雨天)P(乌云密布∣雨天)+P(晴天)P(乌云密布∣晴天)+P(雪天)P(乌云密布∣雪天)P(雨天)P(乌云密布∣雨天)=1
在过去的生活中,雨天与乌云密布一同出现的概率极高,即对一个事件的经验判断(左式),是通过以往事件的学习得到的(右式),且这种学习所需的数据相对较易获取,机器学习就是通过右式的思想,结合已知数据来学习这种“经验判别能力”(左式)。
左式,经验判断;右式,学习过程。
















 1946
1946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











