







误差反向传播有什么作用
神经网络的训练目标是最小化代价函数E,为了找到使得E取得最小值时的参数值,会使用梯度下降算法,而运行梯度下降算法就需要计算出 E 关于网络中的各个参数 w 和 b 的偏导数。

误差反向传播输出层开始,逐层的向前计算 E 关于各层之间参数的偏导数,最后到达输入层,由于这个过程是从后往前的,因此被称为反向传播算法:
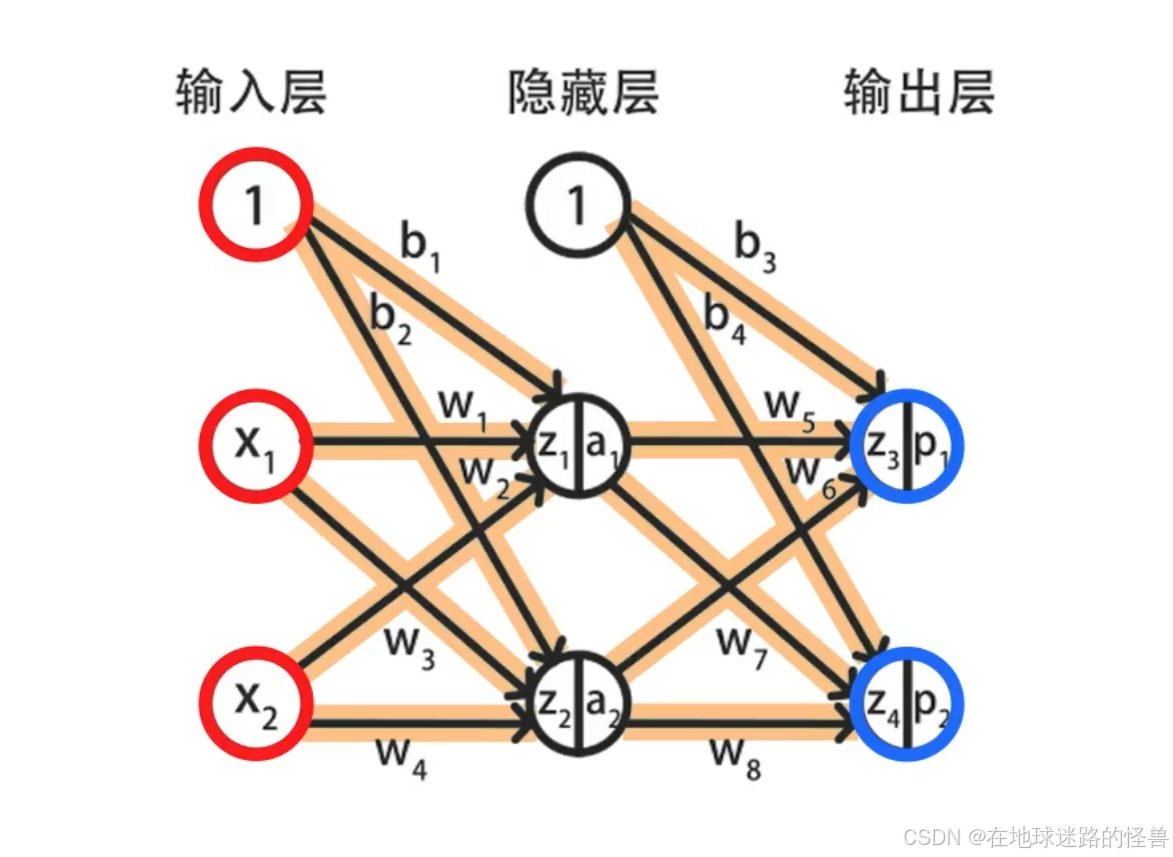
误差反向传播算法有一个通用的公式,根据这个公式可以计算出 E 关于各层之间参数的偏导数:
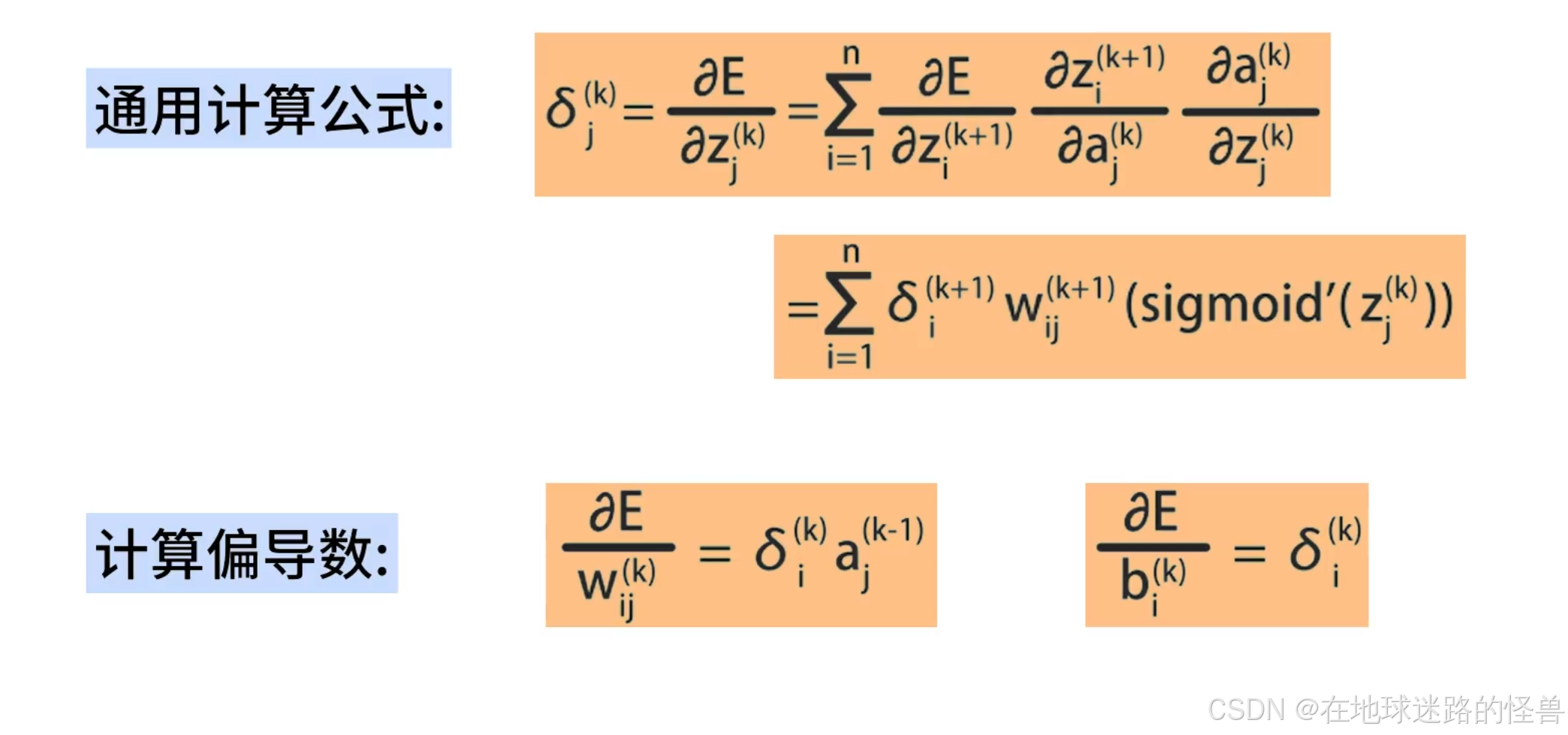
这是误差反向传播算法的核心公式。
本文不讨论这个公式的推导,而是使用一个具体的三层神经网络举例说明误差反向传播的计算过程:
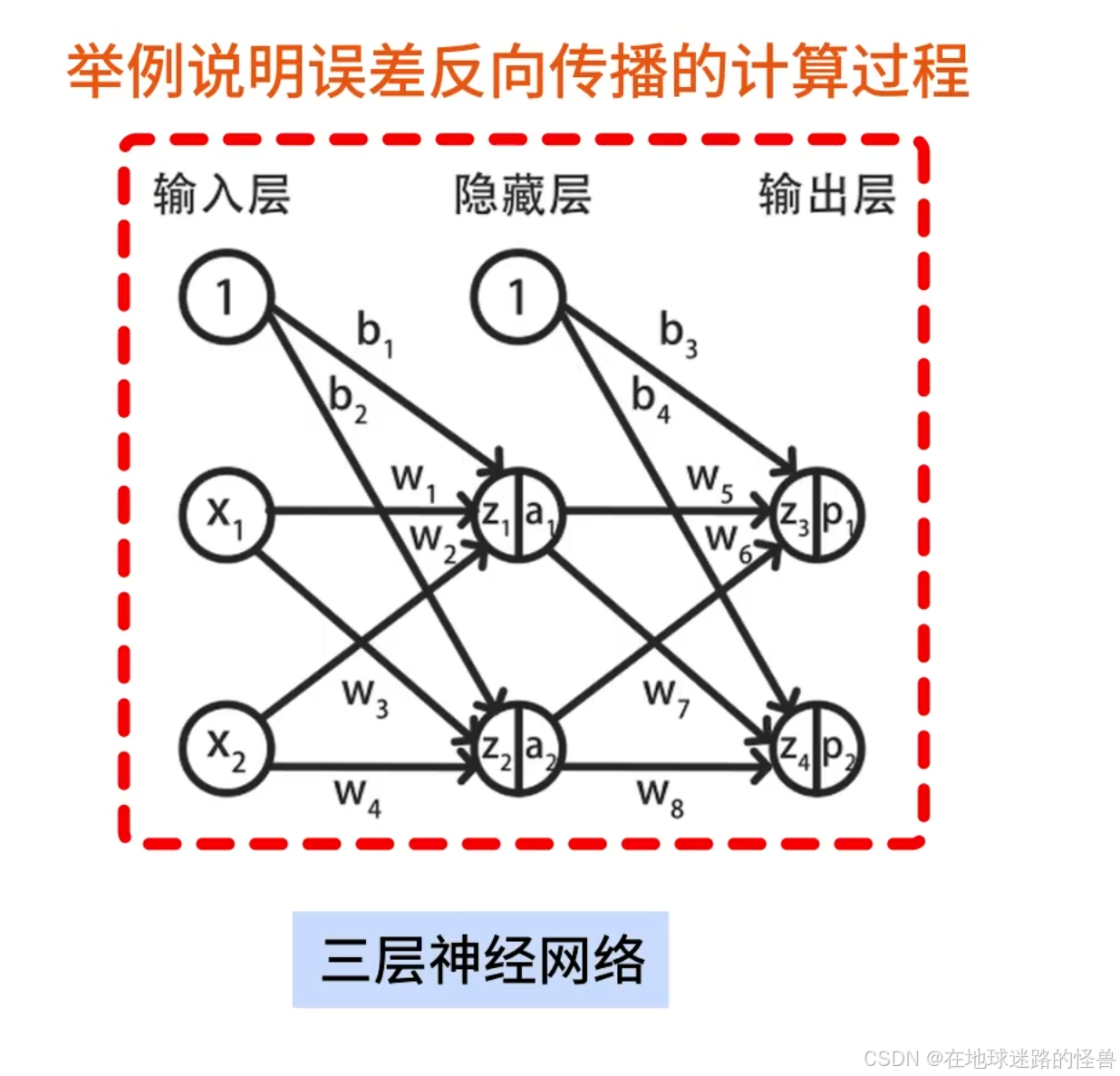
这里会具体的计算出 E 关于 w1 到 w8 ,E 关于 b1 到 b4 的偏导数,有了这些偏导数就可以对这个神经网络运行梯度下降算法了。
神经网络的前向传播
要弄明白反向传播算法,那就要先明白神经网络前向传播的计算过程,在这个过程中我们将使用下面这个计算图来详细说明这个神经网络:
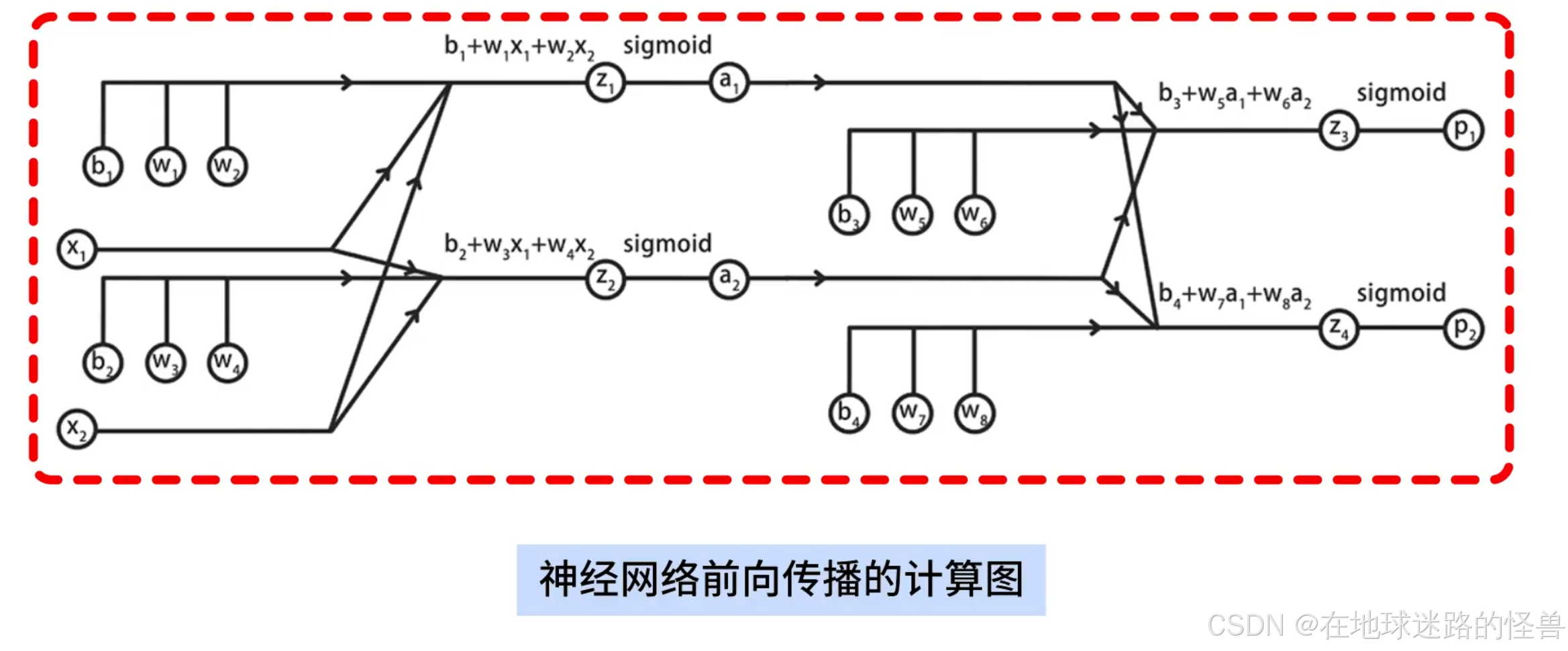
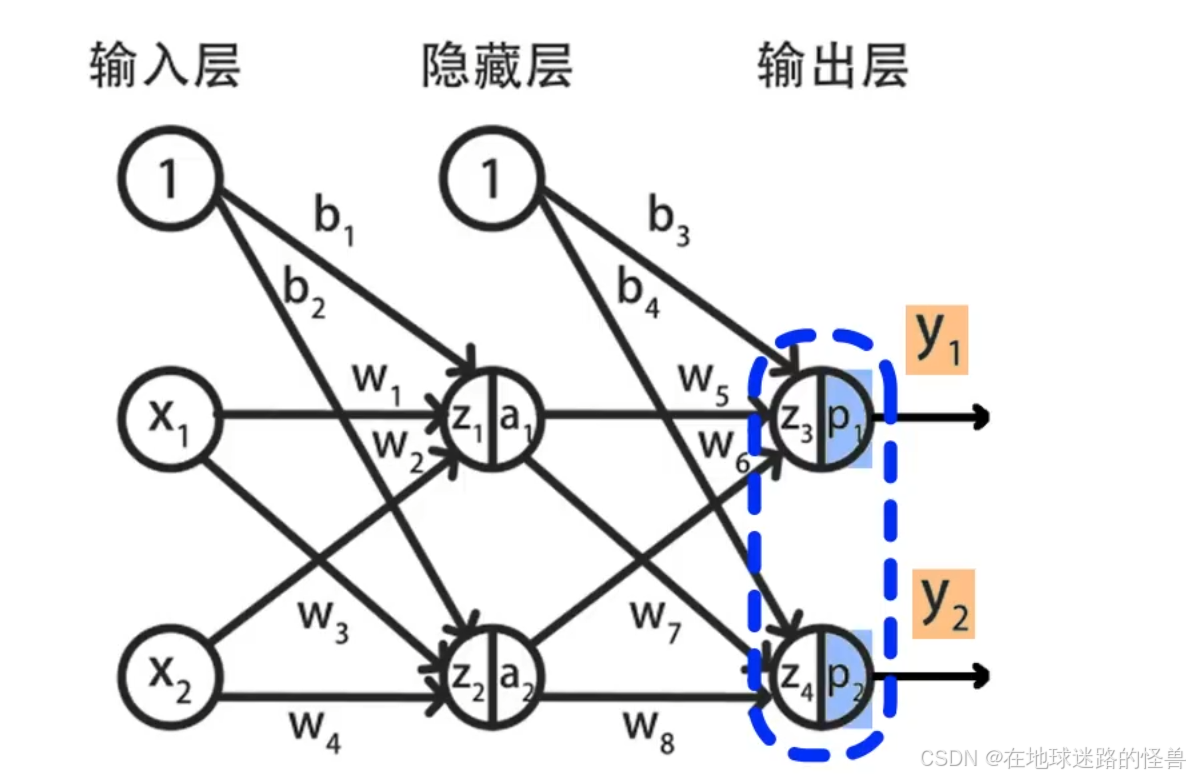
在样例神经网络当中先作如下说明:
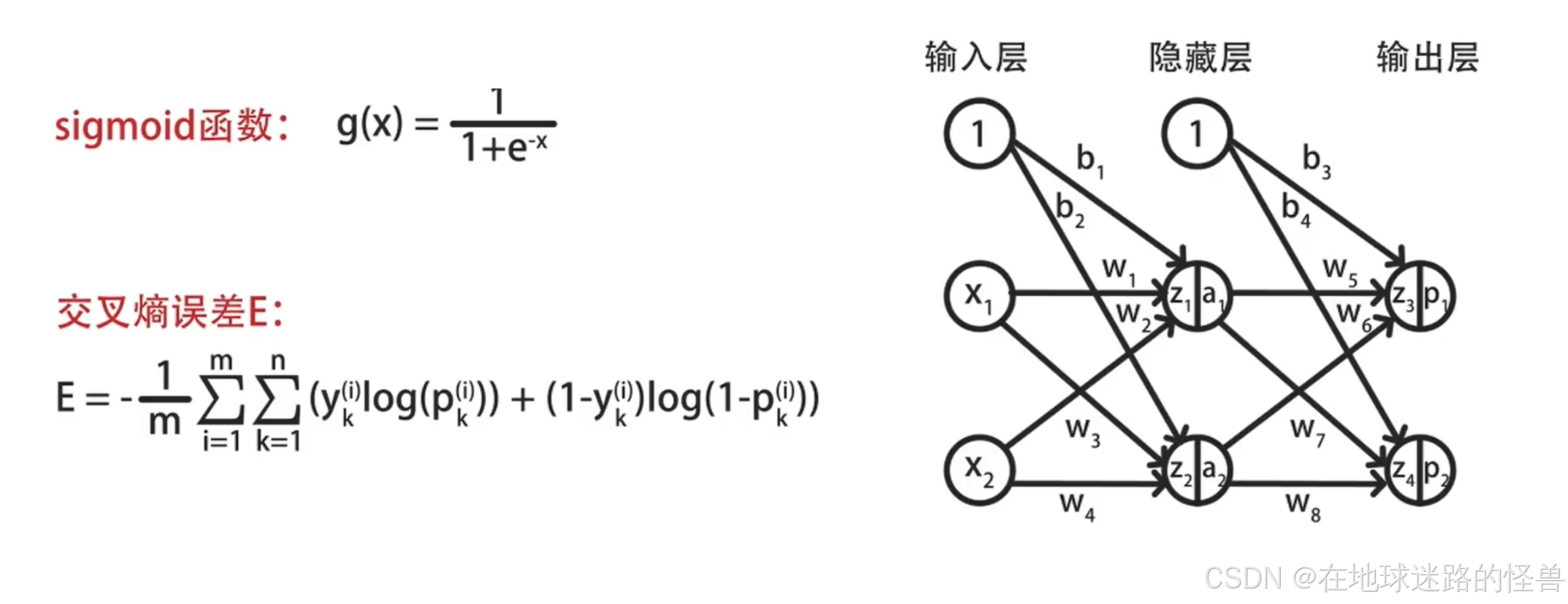
激活函数使用 sigmoid,损失函数使用交叉熵损失。
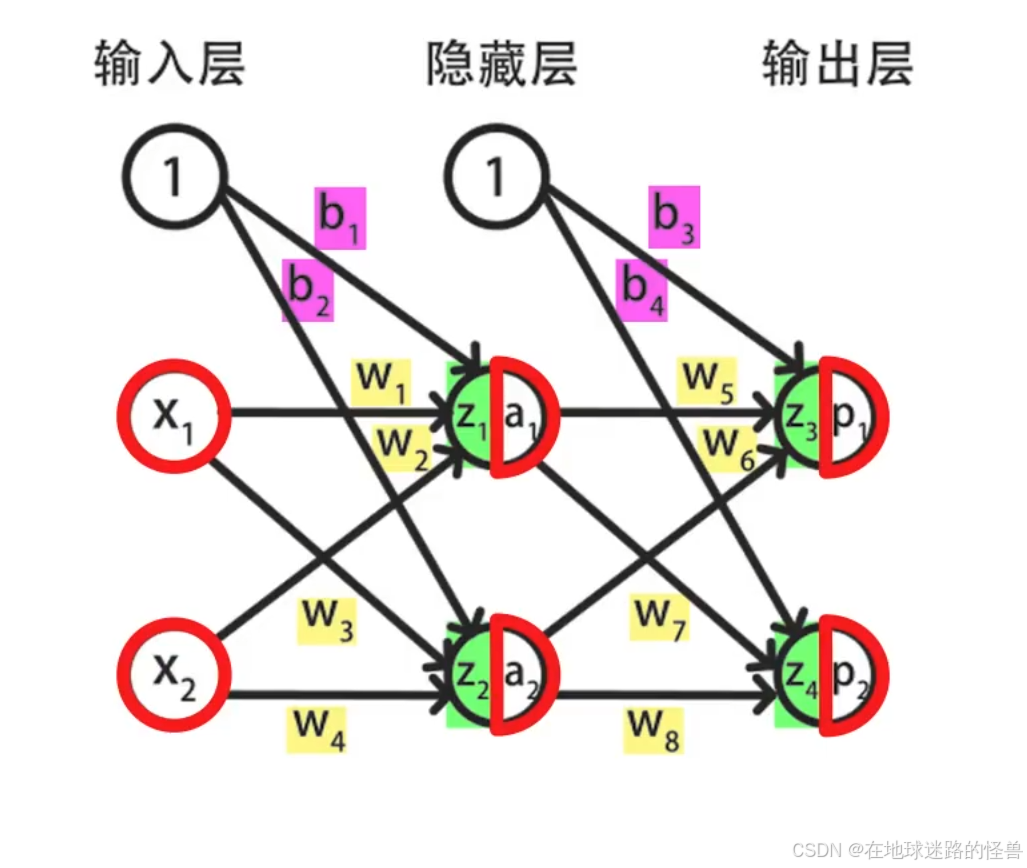
对于神经网络其中 x1、x2 是输入的特征值,a1 、a2 是第二层神经元的输出,p1 和 p2 是第三层的输出;
另外使用 w1 到 w8 表示 8 个 w 参数,b1 到 b4 表示 4 个偏置参数。
z1 到 z4 表示 4 组线性累加和的结果。
画出神经网络的计算图
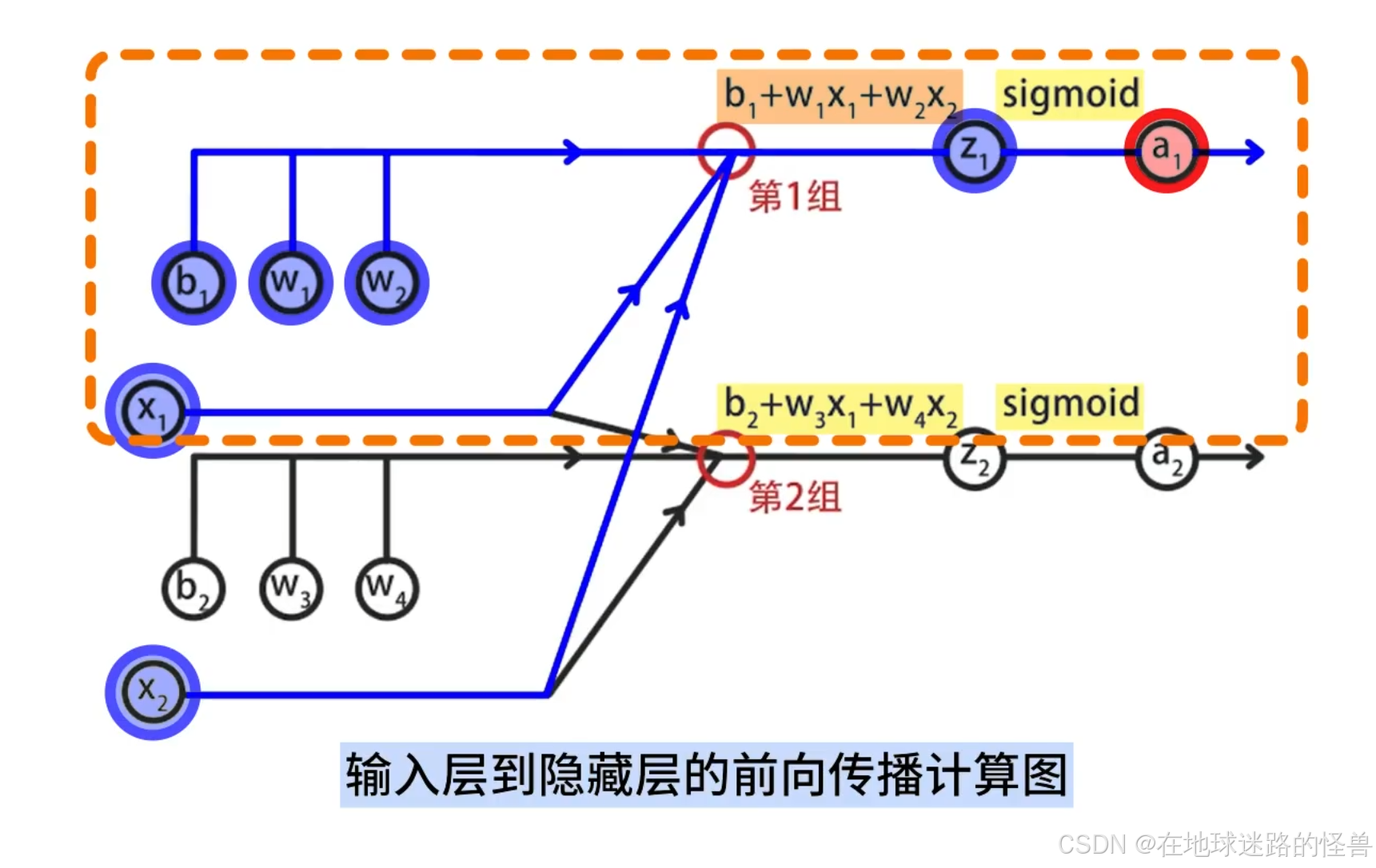
首先是输入层到隐藏层的前向传播计算图:

其中包括了两组线性方程组求和与 sigmoid 函数的计算。
具体来说,在第一组计算中,输入层的两个特征 x1 和 x2 对应参数 w1 和 w2,将它们相乘后,再加上偏置 b1 得到结果 z1,再将 z1 带入到 sigmoid 函数中得到 a1:
按照同样的方式可以得到第二组的输出 a2:
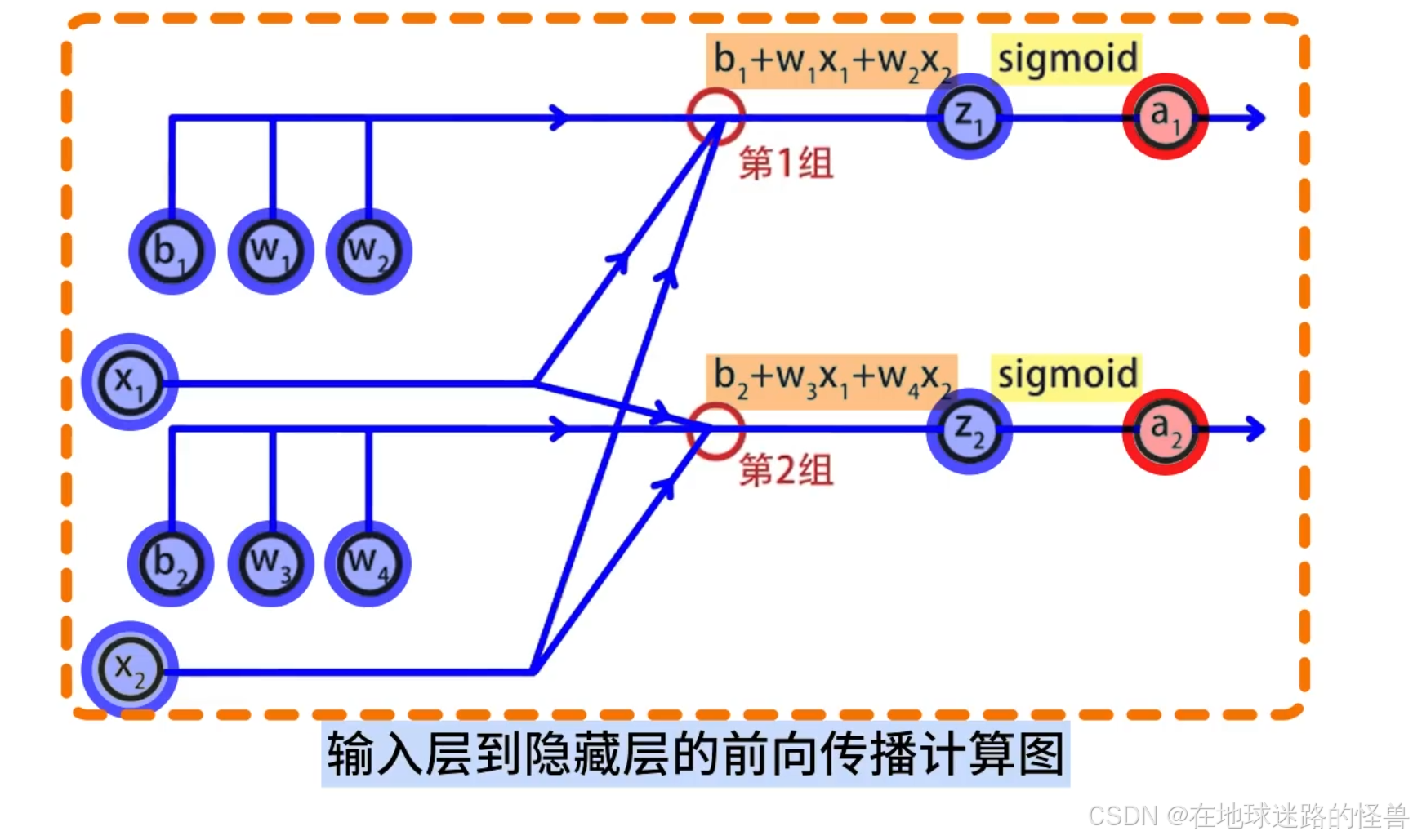
这样就完成了输入层到隐藏层的计算。
然后画出隐藏层到输出层的前向传播计算图,其中同样包括两组计算,计算方式是相同的,就不再赘述了:
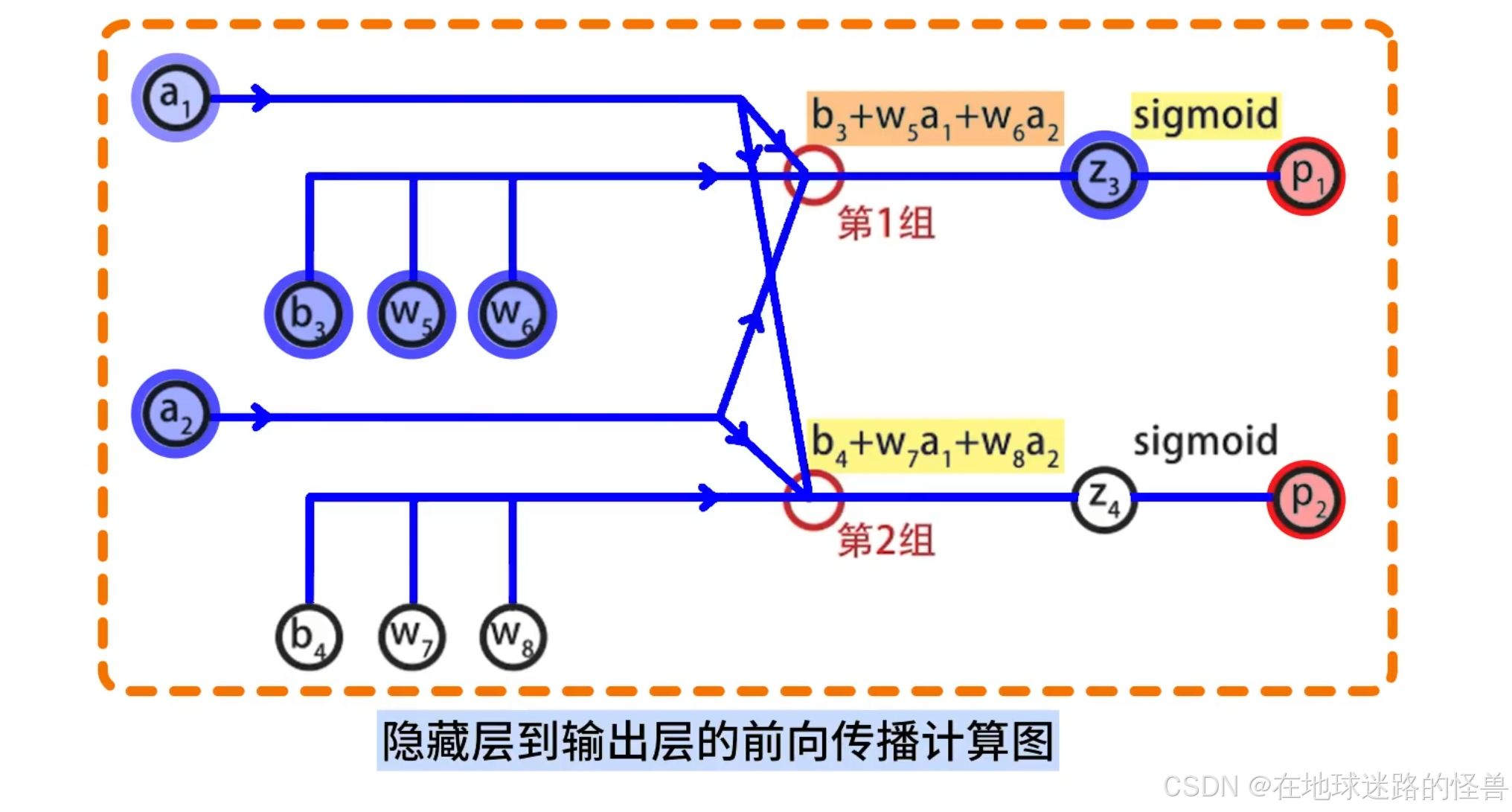
将上面两张计算图合并,就得到了神经网络前向传播的完整计算图:
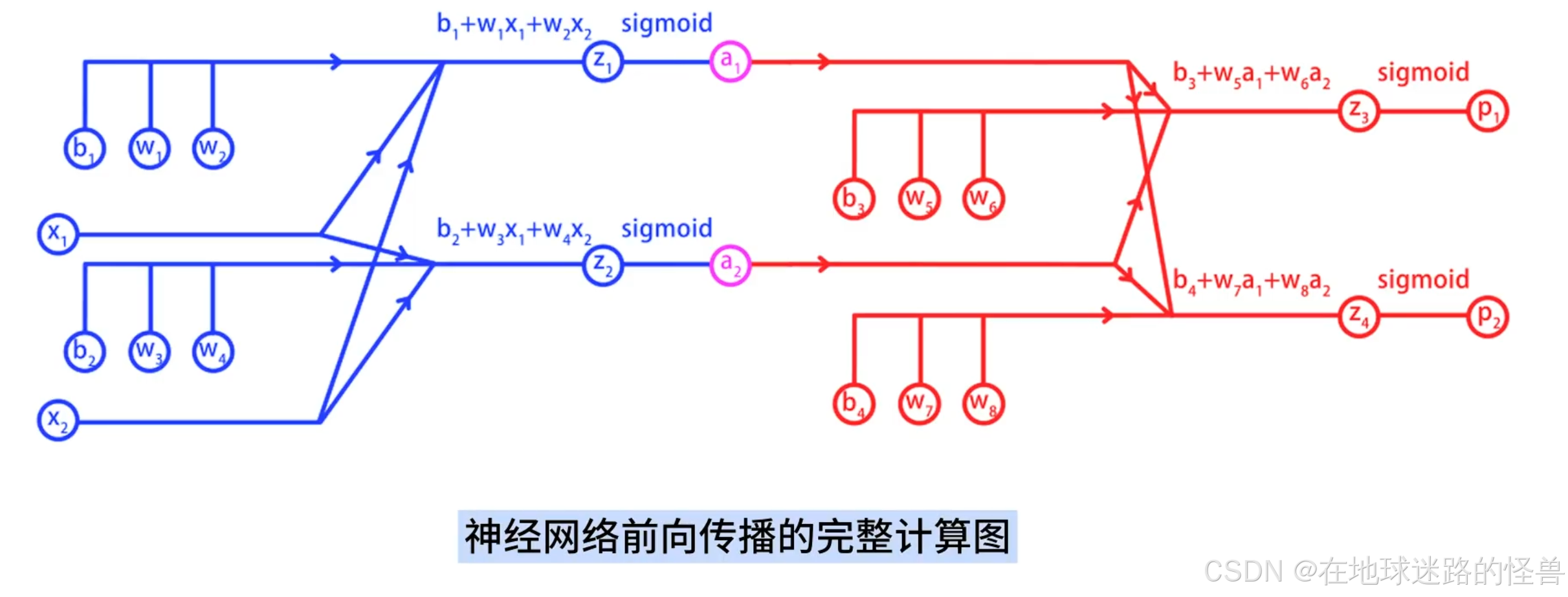
为了计算误差 E 关于参数的偏导数,还需要将 E 加入到计算图中,这里我们只关注某一个样本产生的误差 E,从而忽略掉 Σ 求和符号:
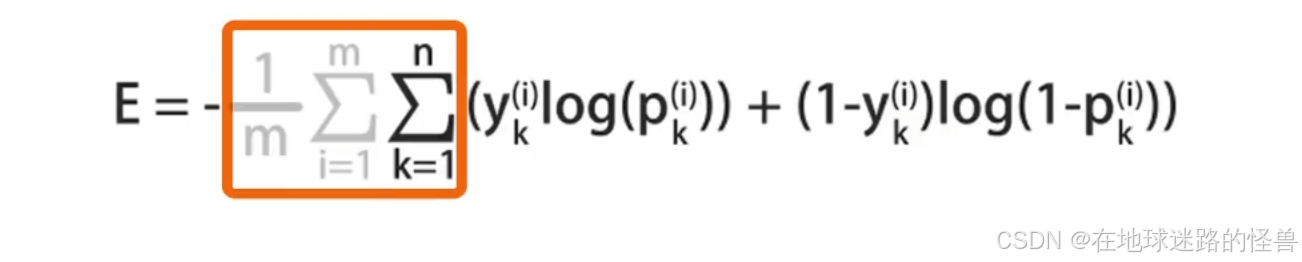
在输出层中包括两个神经元,它们的人工标记结果是 y1 和 y2,神经网络的输出结果是 p1 和 p2:
根据交叉熵误差,分别计算两个神经元的误差 E1、E2 :
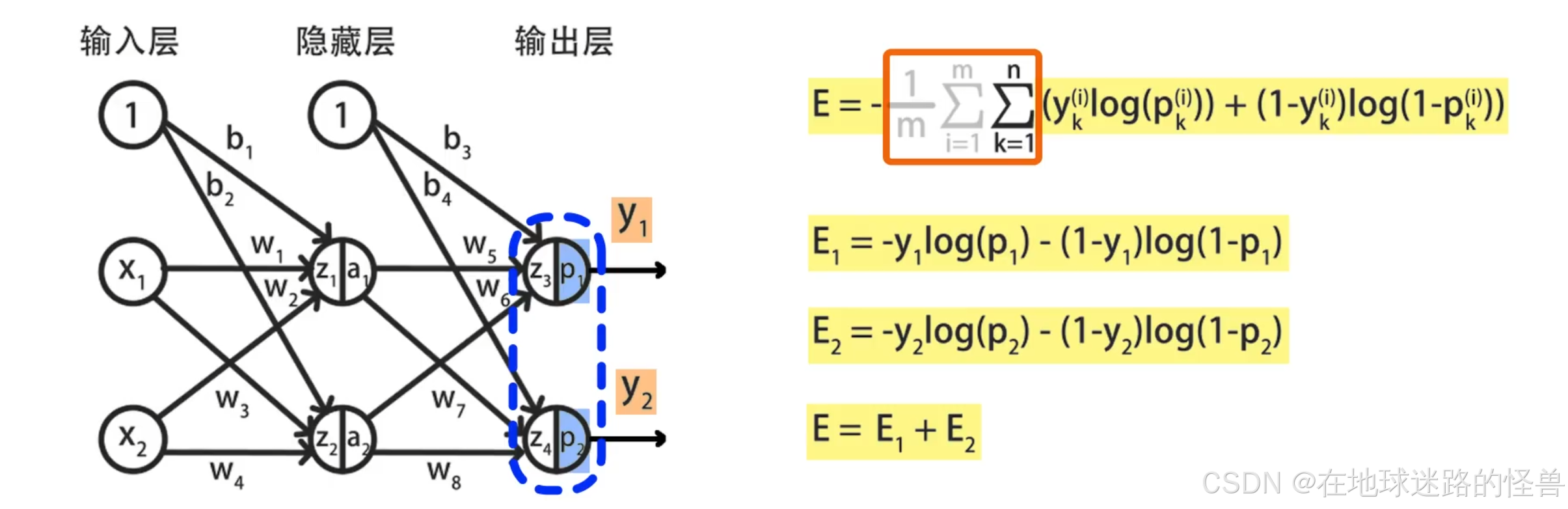
因此总误差 E = E1 + E2 。
这样就我们就得到了这个三层神经网络的完整计算图:
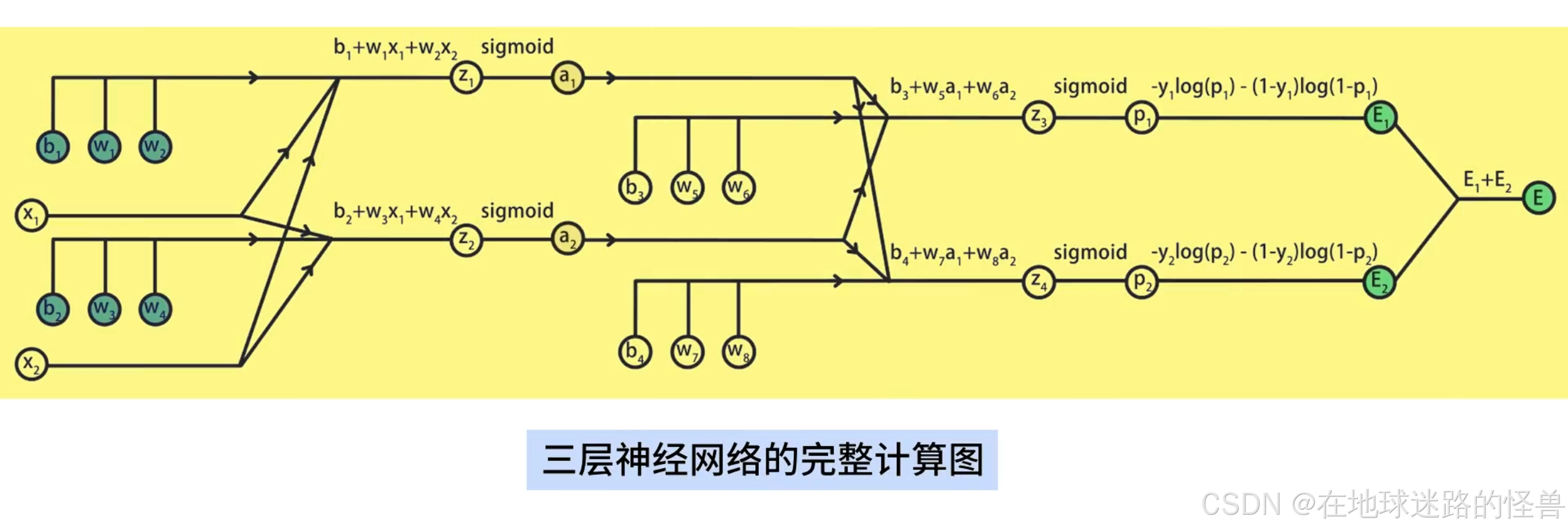
接下来我们将根据这张图使用链式法则从后向前推导代价函数 E 关于参数 w1 到 w8 、b1 到 b4 的偏导数。
这实际上就是反向传播算法的手动计算过程。
误差反向传播算法
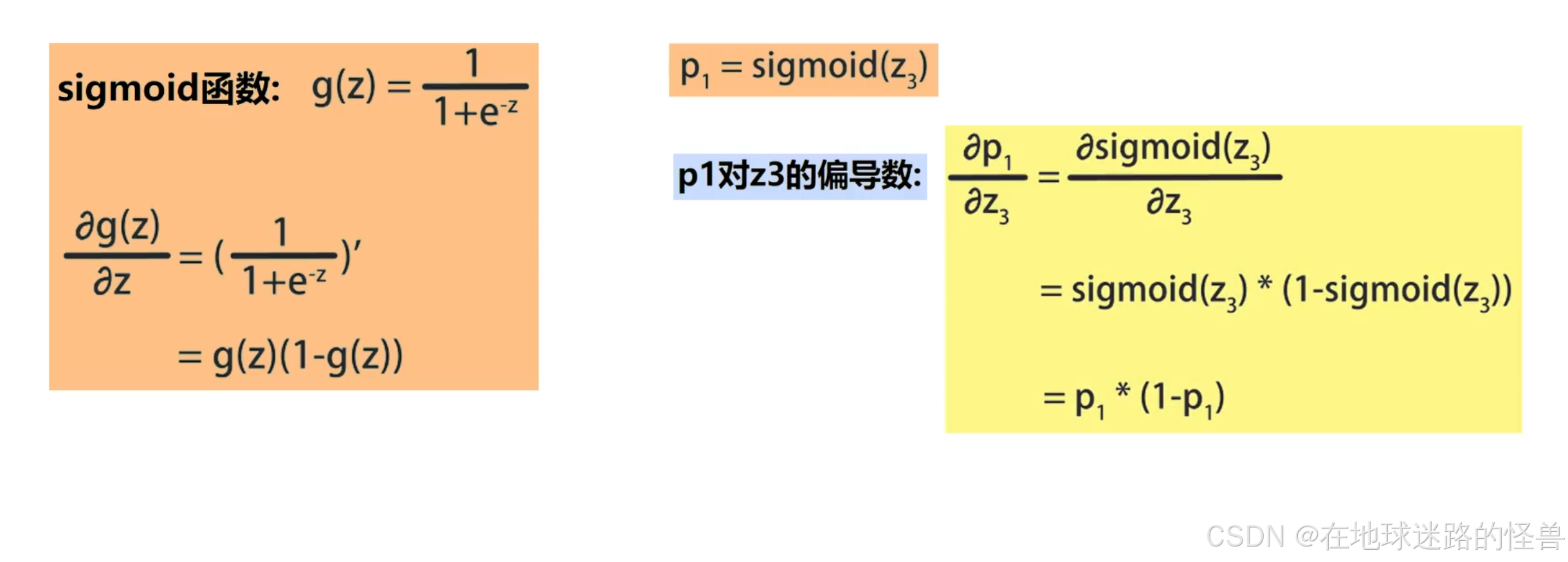
首先计算 E 对输出 p1 的偏导数,在计算时需要基于 log 函数的求导方法:

注意,其中 y1 是常数,一般是人工标注信息。
然后计算 p1 对 z3 的偏导数,在计算时,需要基于 sigmoid 函数的求导:
最后基于线性方程计算 z3 对 w5 的偏导数:
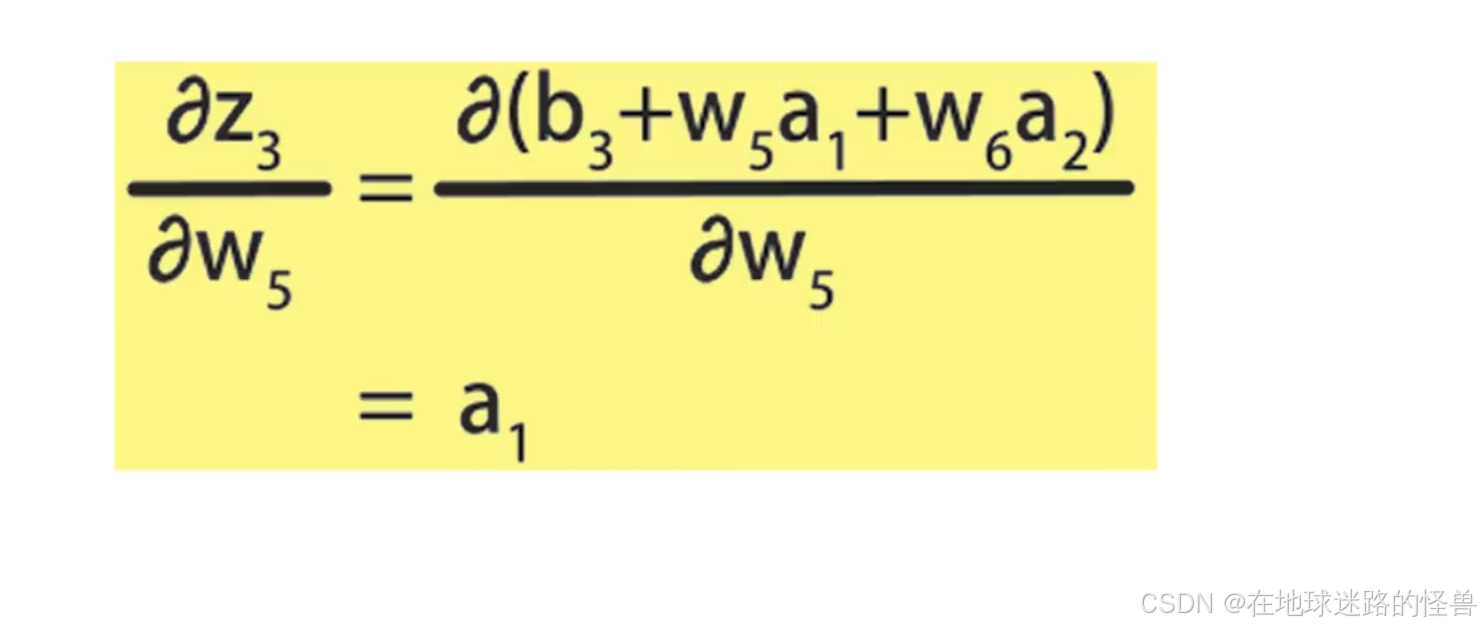
然后将三组计算结果相乘,消去重复的项,就得到了 E 对于 w5 的偏导数:

仔细观察结果可以发现,这个结果与逻辑回归中的梯度计算结果是相同的。
按照同样的方式可以计算出 E 对 w6、w7、w8 和 b3、b4 的偏导数:

这种基于链式法则从后向前计算偏导数的方式就被称为反向传播算法。
接下来我们继续推导 E 对于 w1、w4 和 b1、b2 的偏导数。
观察计算图的前半部分,可以发现蓝色部分的待求参数会经过 a1 和 a2 再传导到 E,因此如果可以先求出 E 对 a1 和 a2 的偏导数,再基于链式法则就能推导出 E 关于蓝色参数的偏导数了:
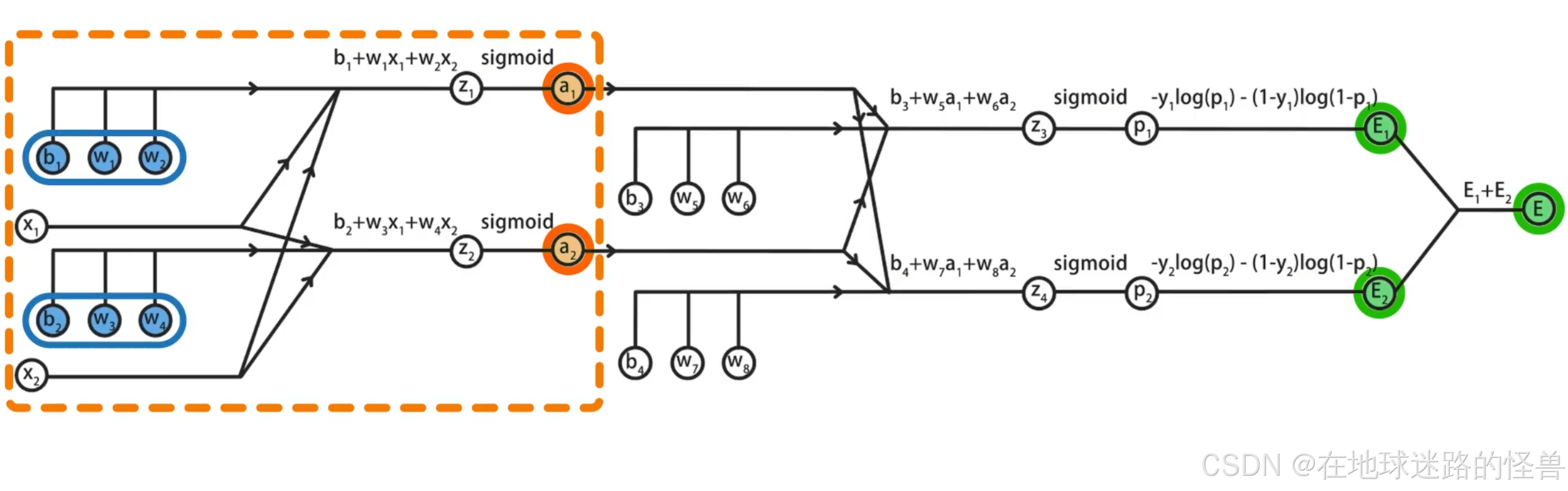
E 关于 a1 和 a2 的偏导数计算
在求 E 关于 a1 和 a2 的偏导数时,会发现 z3、z4 同时出现在 a1、a2 到 E 的路径上,这说明 a1 和 a2 与 z3、z4 都是有关系的,因此我们需要先求出 E 对 z3、z4 的偏导数,再求 z3、z4 对 a1、a2 的偏导数,最后合并到一起得到结果:
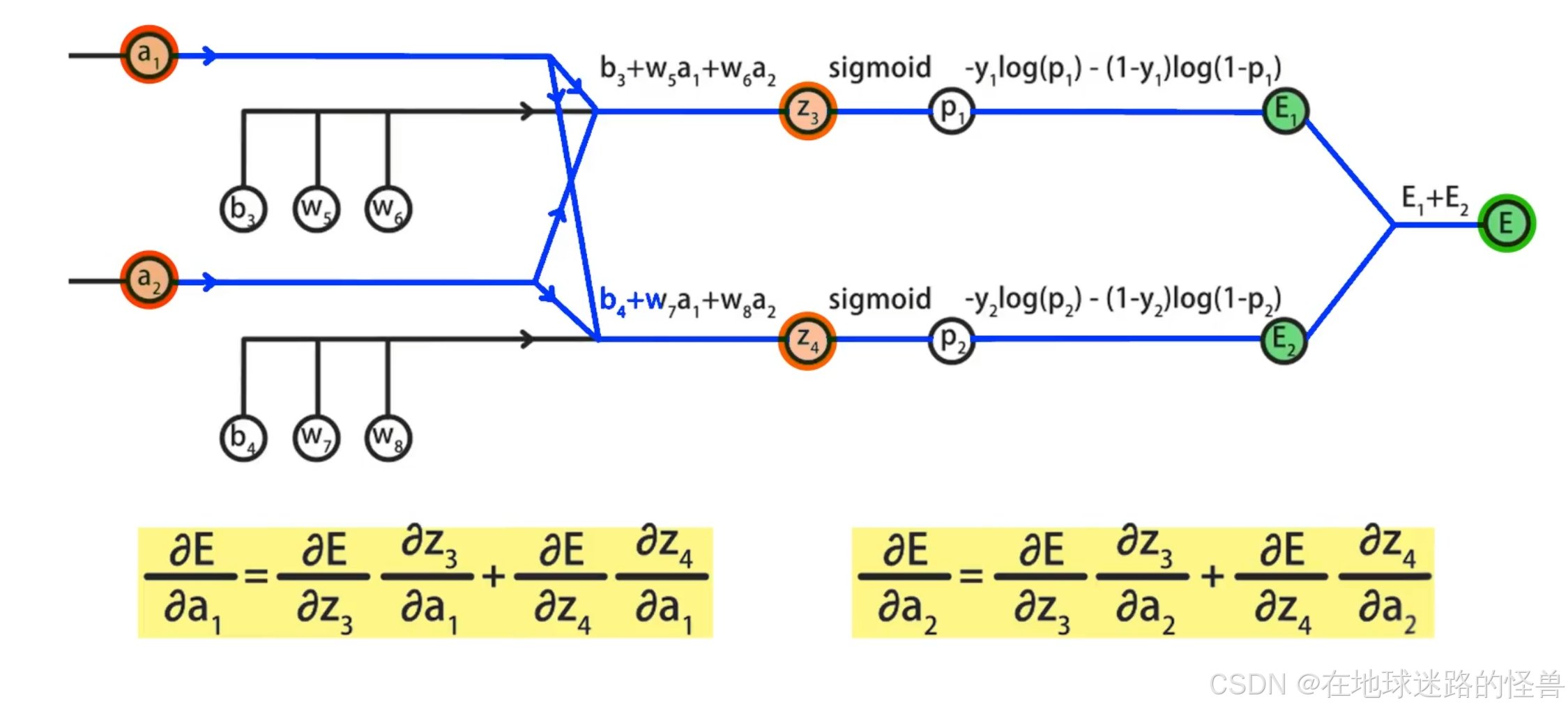
省略掉中间不相关的变量节点,得到了一个更简单的计算图,其中 E 对 a1、a2 的计算方式和路径如下图所示:
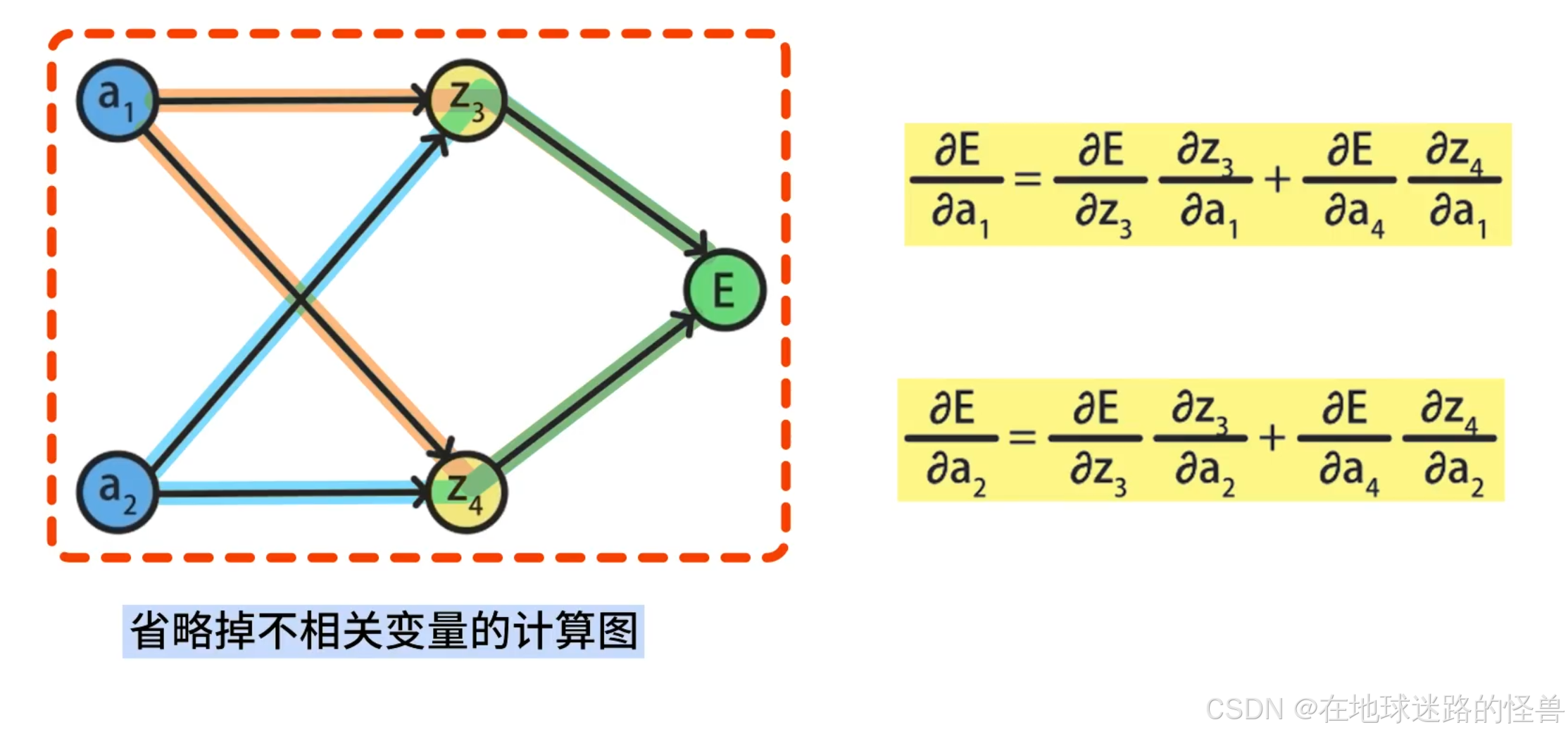
继续往下计算:
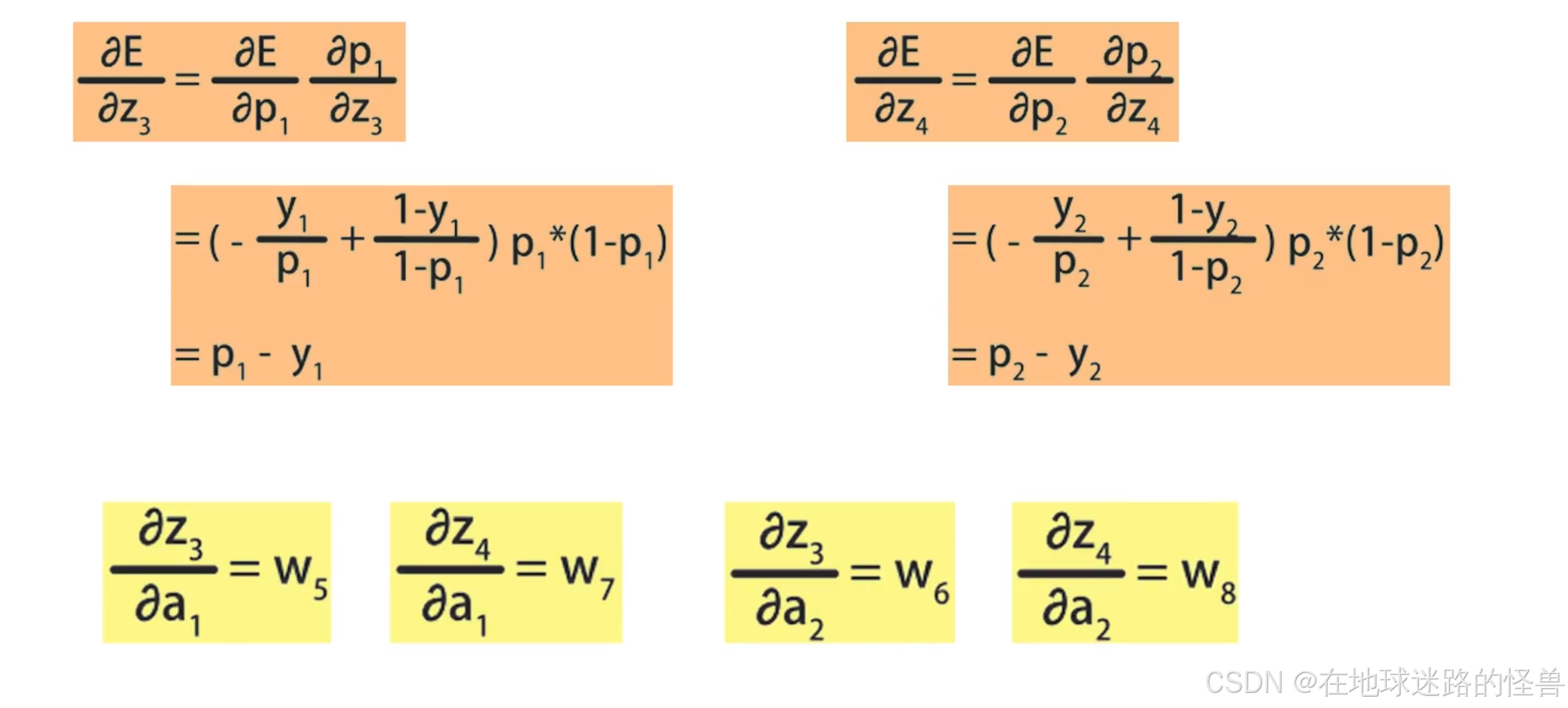
求出链式法则需要的中间结果后,将它们带入到 E 关于 a1 和 a2 的偏导数公式中,就得到了最终的结果:

有了 E 关于 a1 和 a2 的偏导数后,就可以继续通过链式法则求出 E 关于参数 w1 到 w4 、b1 和 b2的偏导数了。
我们以 E 关于参数 w1 的偏导数计算为例说明计算过程:
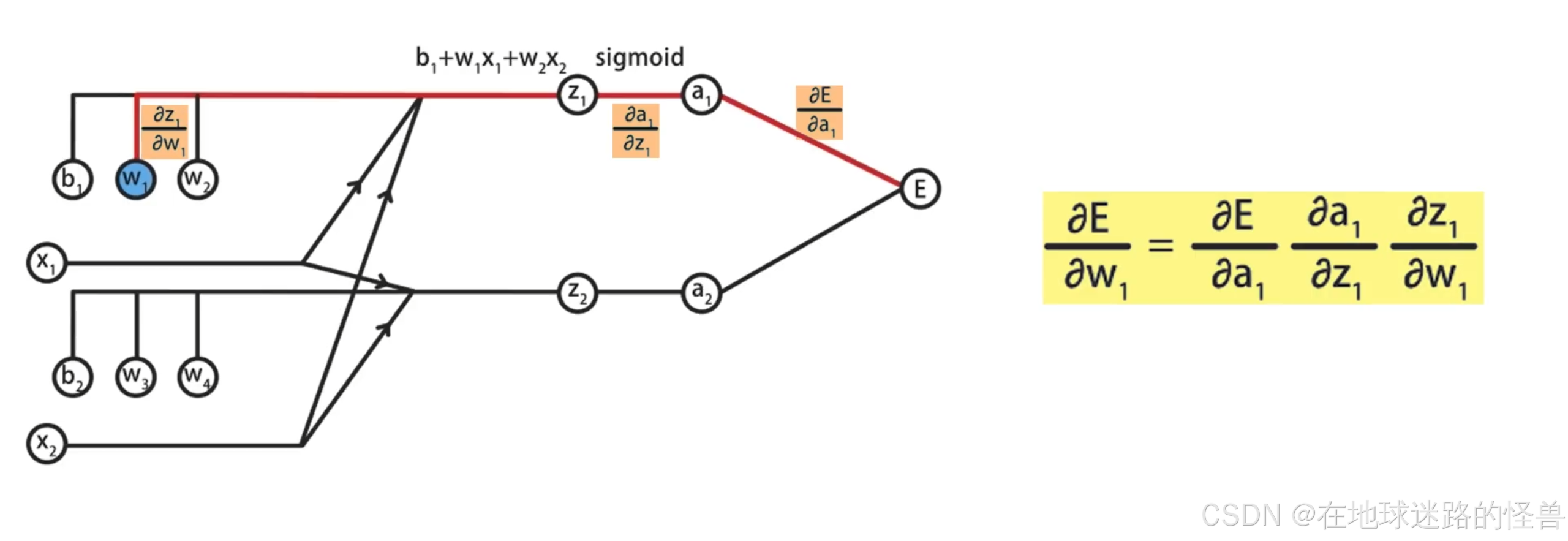
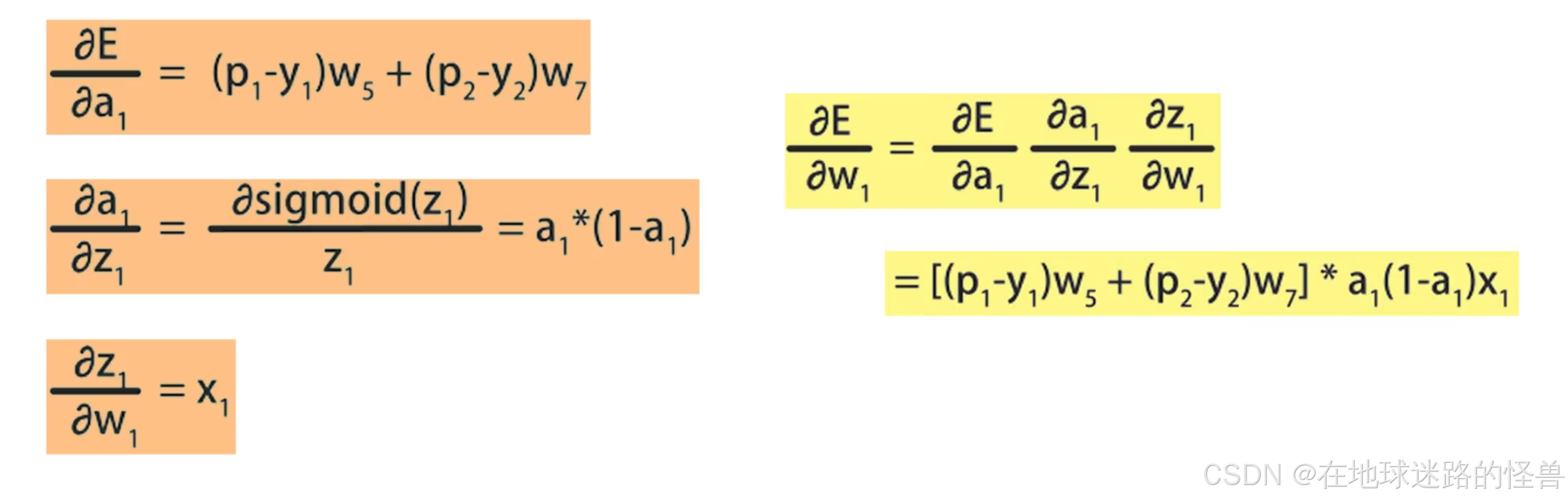
按照同样的方法,对于剩余的参数求偏导数计算是一样的方式,就不再赘述了。
通过上述流程,这样我们就使用误差反向传播算法将 E 关于神经网络当中所有参数的偏导数都求出来了,后面可以直接使用这些偏导数进行梯度下降算法的迭代,至此误差反向传播算法就讲完了。
补充:梯度下降算法
梯度下降算法的目标
我们为什么需要梯度下降算法呢?
假如现在有下面两个函数:
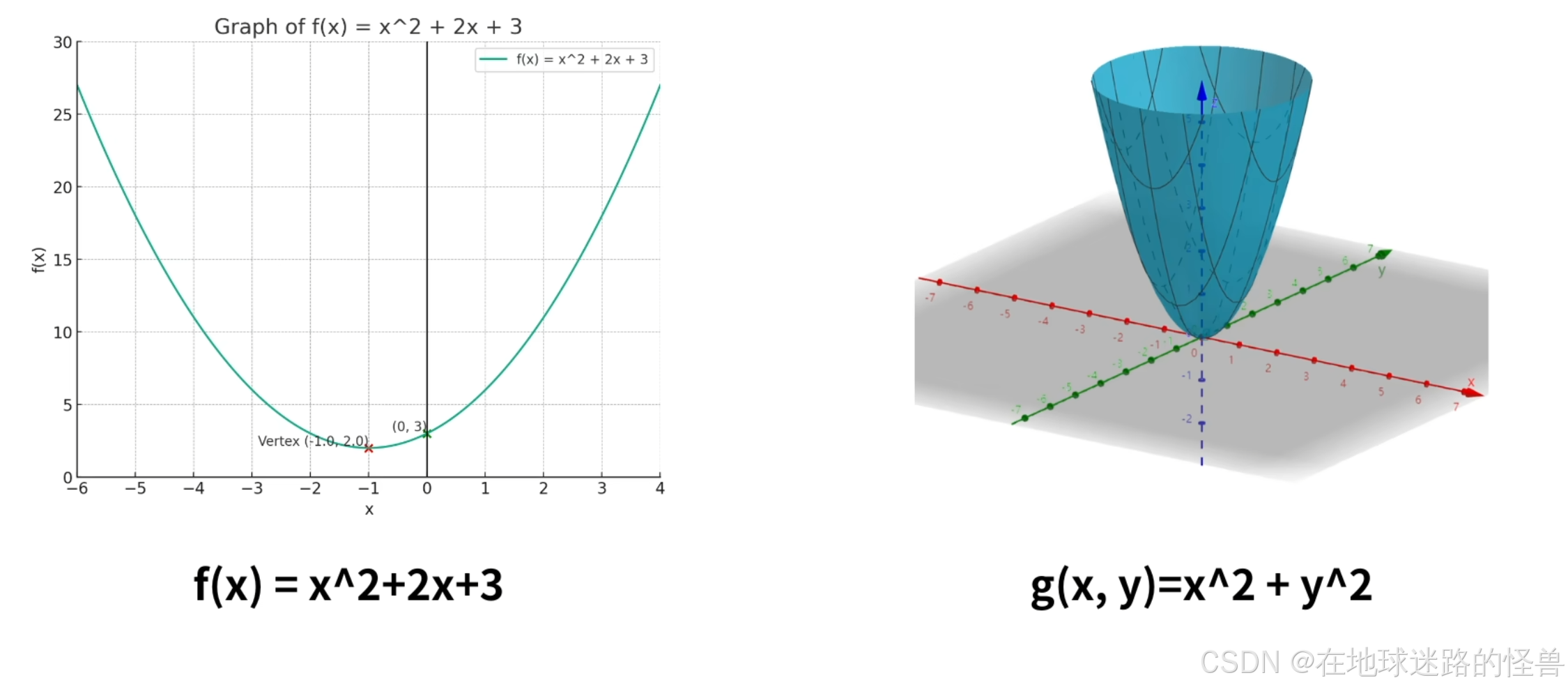
我们应该如何将它们的最小值给求出来呢?
我们不但要求出最小值,还要求函数取得最小值时函数自变量的值嗷。
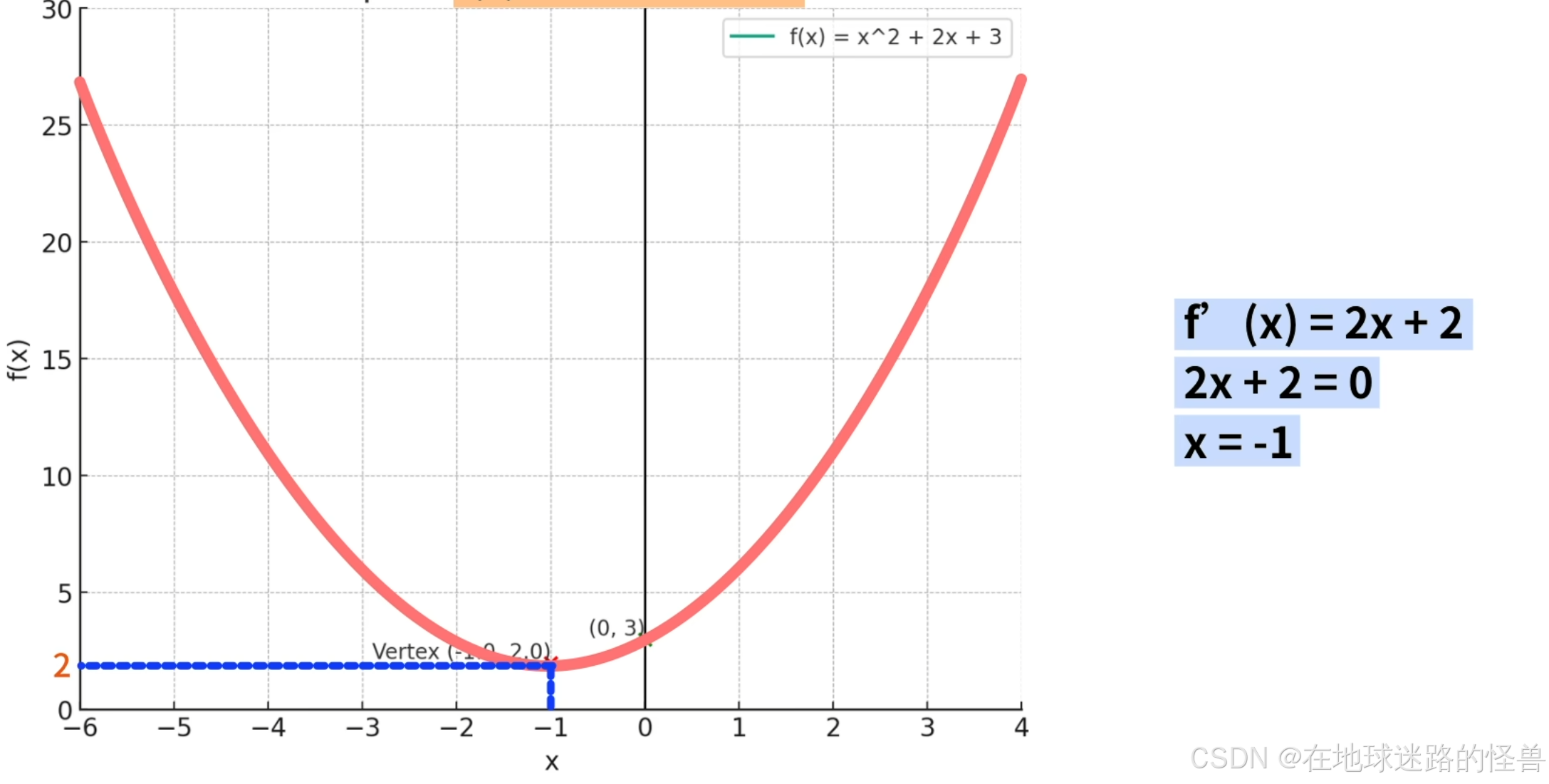
比如对于上图左侧的函数,当 x=-1 时,f(x) 取得最小值是2:
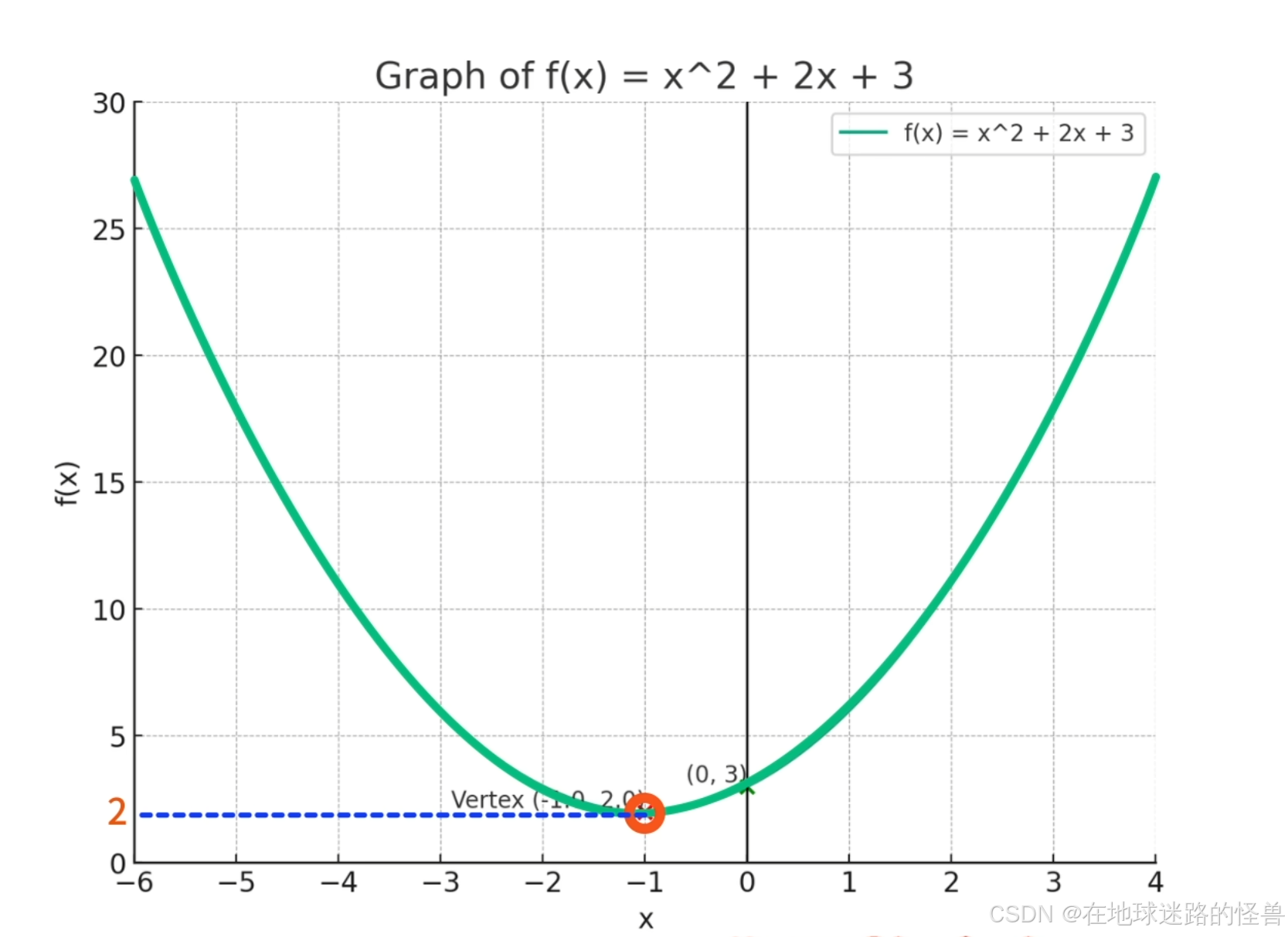
我们需要将这个 x=-1 这个值给输出出来。
实际上梯度下降算法就是用来求函数最小值的,那为什么不用数学的方法求解函数最小值呢?
比如还是上图的函数,我们只要对 f(x) 求导,然后让其导函数等于 0 ,因为抛物线的开口方向是向上的,判断出在 x=-1 的位置函数取得最小值为 2,这就可以求得最小值了呀:
然而在深度学习或者机器学习算法中,我们所要求解的问题并不都像这个例子一样这么简单,通常要求解的损失函数可能会非常复杂:
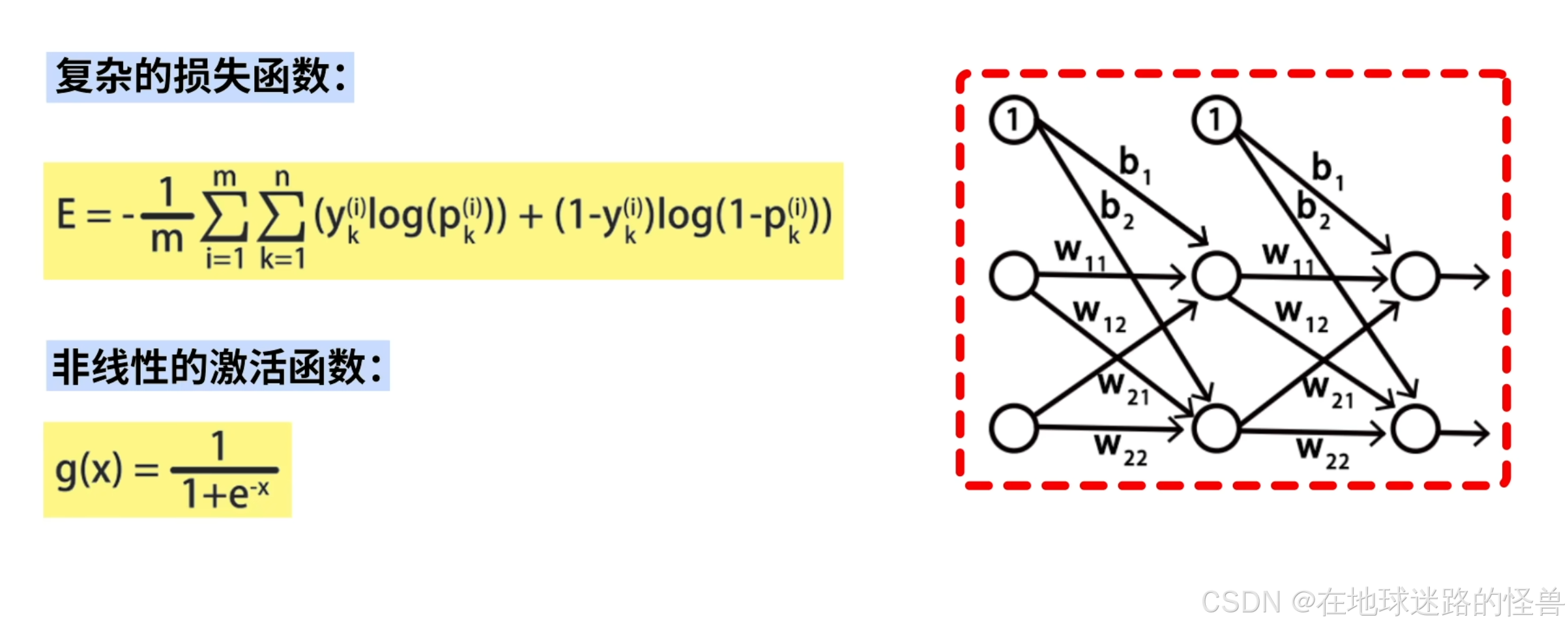
比如在神经网络中,包括了非线性的激活函数,并且有大量的待训练参数 w 和 b,因此我们很难用数学的方法求出函数的全局最小值以及对应的参数值。
而这就是为什么需要梯度下降算法的原因。
梯度下降算法的原理
接下来我们使用一元线性回归的例子来解释梯度下降算法是如何工作的。
设平面上有 3 个样本数据,分别是(1,1)、(2,2)、(3,3),求拟合这三个数据最合适的线性方程Hθ(x):
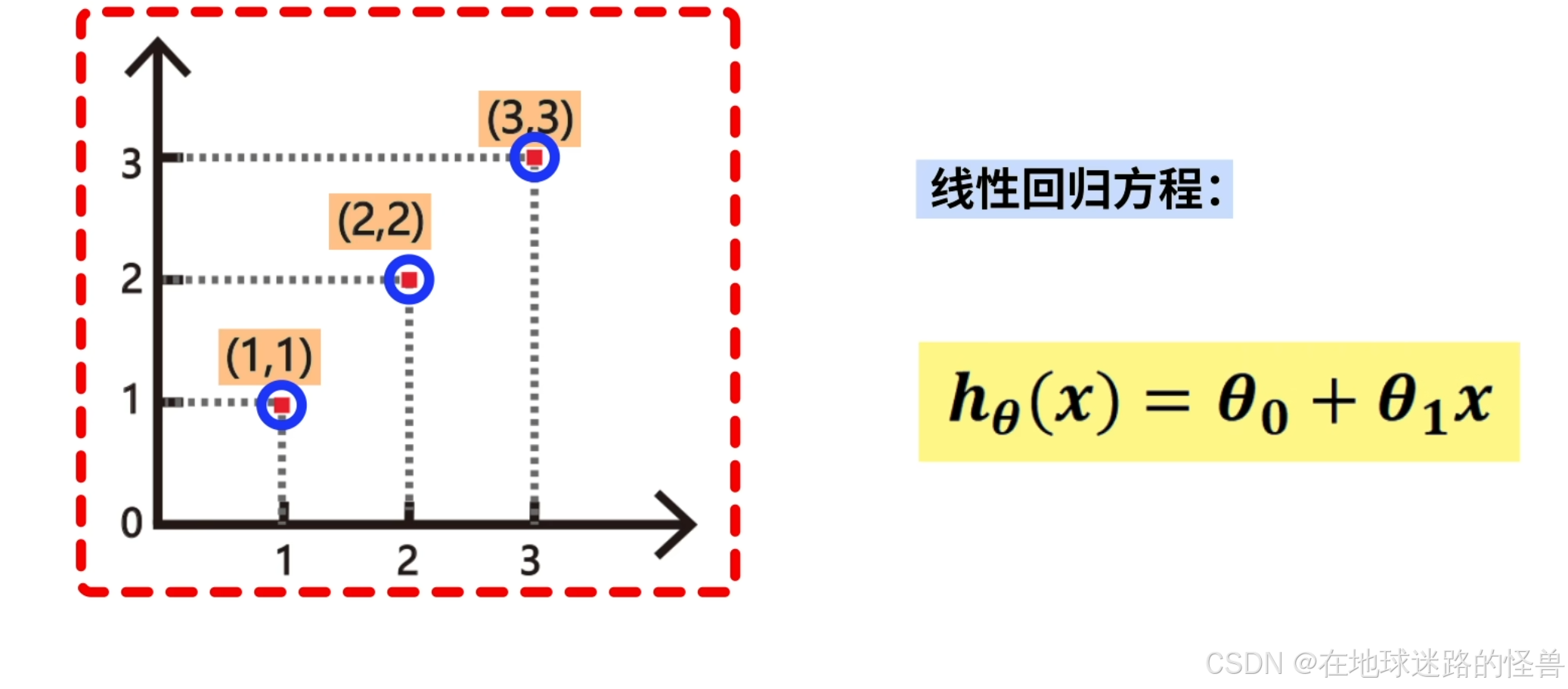
用眼睛看就能看出最合适的线性回归方程为 h(x) = x;
也就是方程中的参数 θ0 = 0,θ1 = 1 的情况:
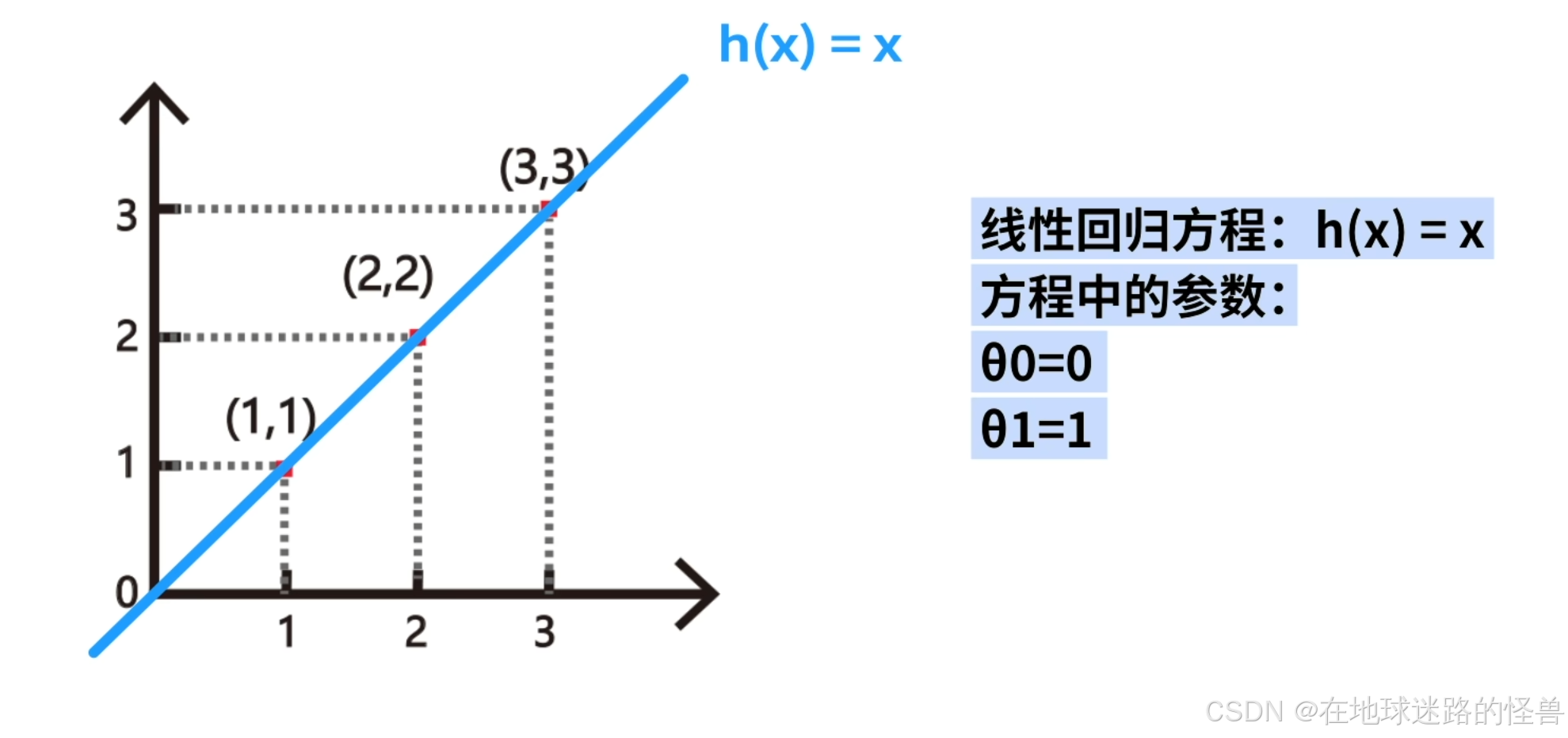
下面我们分别用数学方法和梯度下降算法具体的求出这个问题的最优解。
首先给出这个问题的损失函数定义:

然后计算 x=1、x=2、x=3的直线预测值:
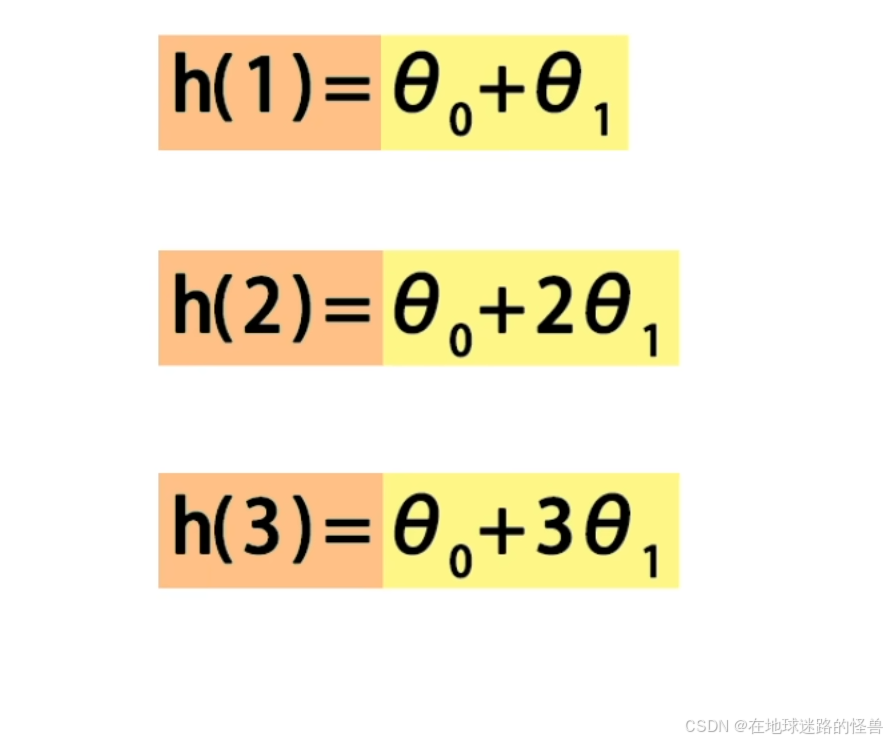
将 h1、h2、h3 与真实值 y=1、y=2、y=3 一起带入到 J(θ) 的计算公式中计算出这3个样本的预测值和真实值差的平方和:
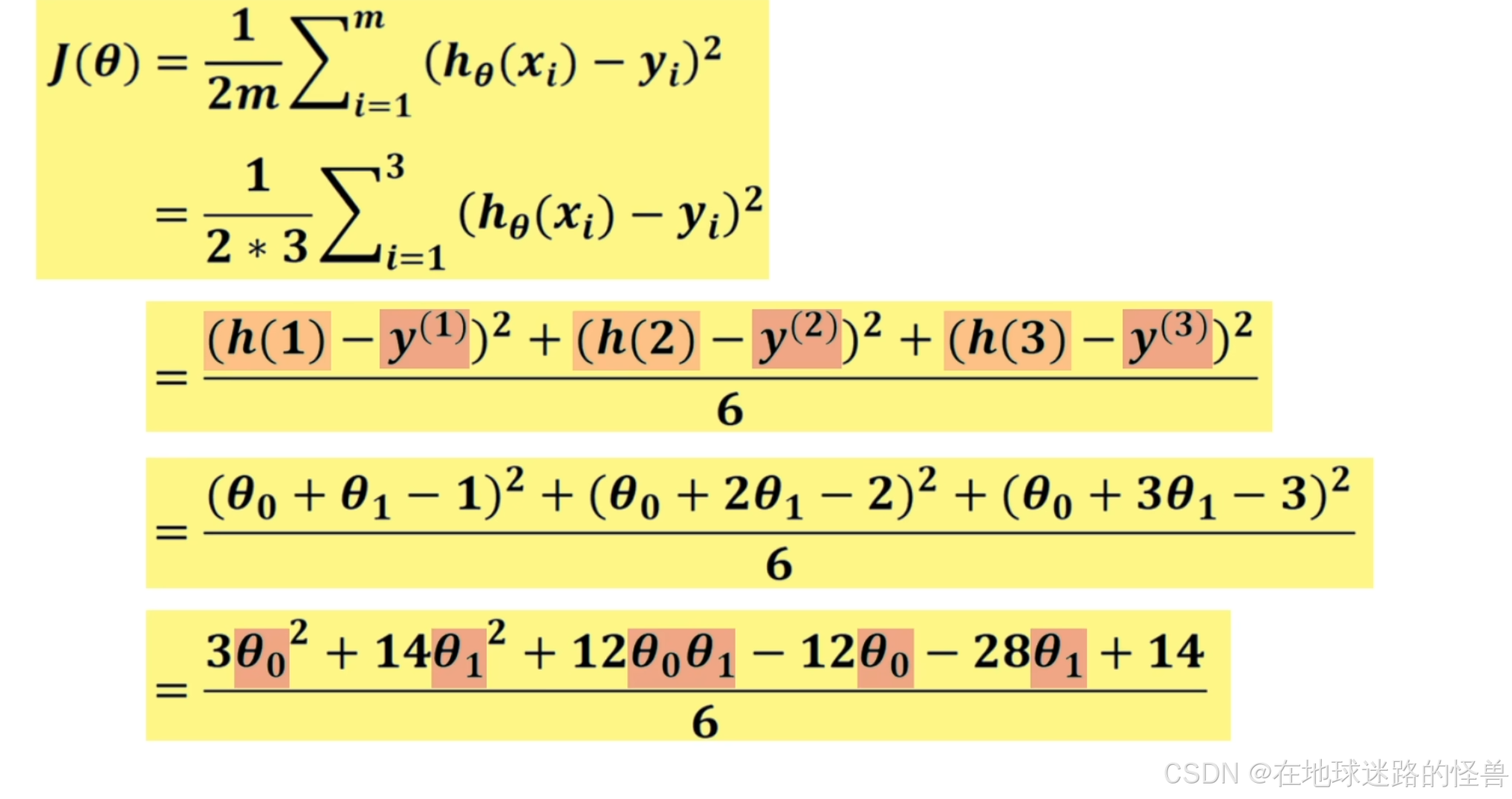
最后得到了一个关于 θ0 和 θ1 的二元函数。
我们的目的就是要求出这个二元函数取得最小值时,θ0 和 θ1 的值:

如果使用数学方法求解,需要分别求出 J(θ) 关于 θ0 和 θ1 的一阶偏导数:
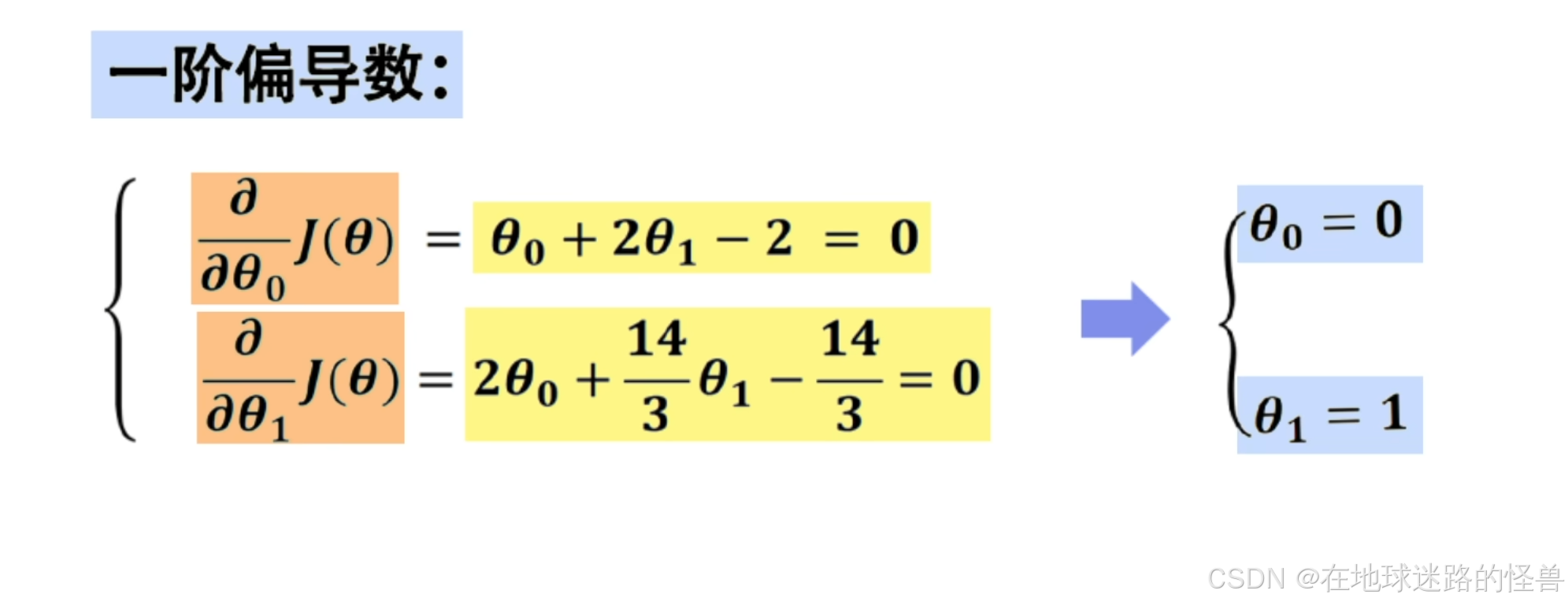
严格来说,还需要判断该驻点是函数取得极小值时的解,具体需要计算 A、B、C三个值,然后根据公式进行判断:

这里可以判断出 θ0 和 θ1 对应的位置就是函数的极小值,从而求出线性回归的方程为 h(x) = x 。
而如果使用梯度下降算法,则过程如下。
首先需要计算出 J(θ) 关于 θ0 和 θ1 的偏导数:
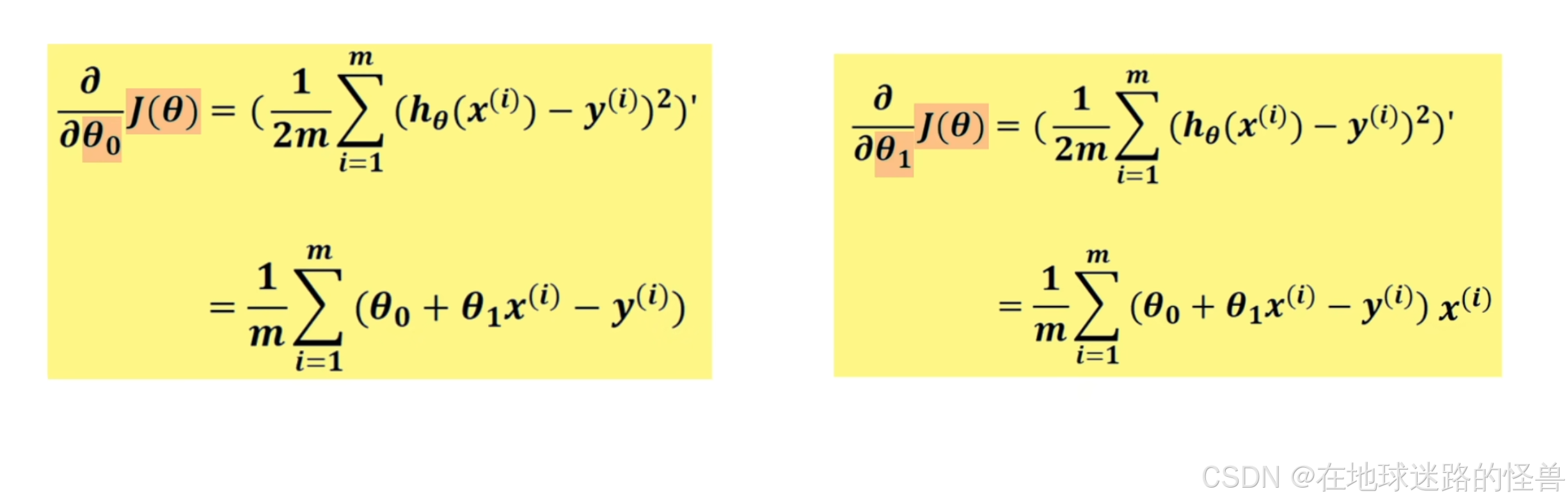
然后将它们组合在一起,得到 J(θ) 的梯度向量,再基于迭代的方式利用该梯度向量求出 θ0 和 θ1 :

具体来说,用负梯度的方向来决定每次迭代时 θ0 和 θ1 的变化方向,从而使得每次迭代后目标 J(θ) 逐渐减小。
在每次迭代的过程中,需要同时修改 θ0 和 θ1 的值,使它们分别以 α 的学习速率沿着各自偏导数的反方向进行移动:
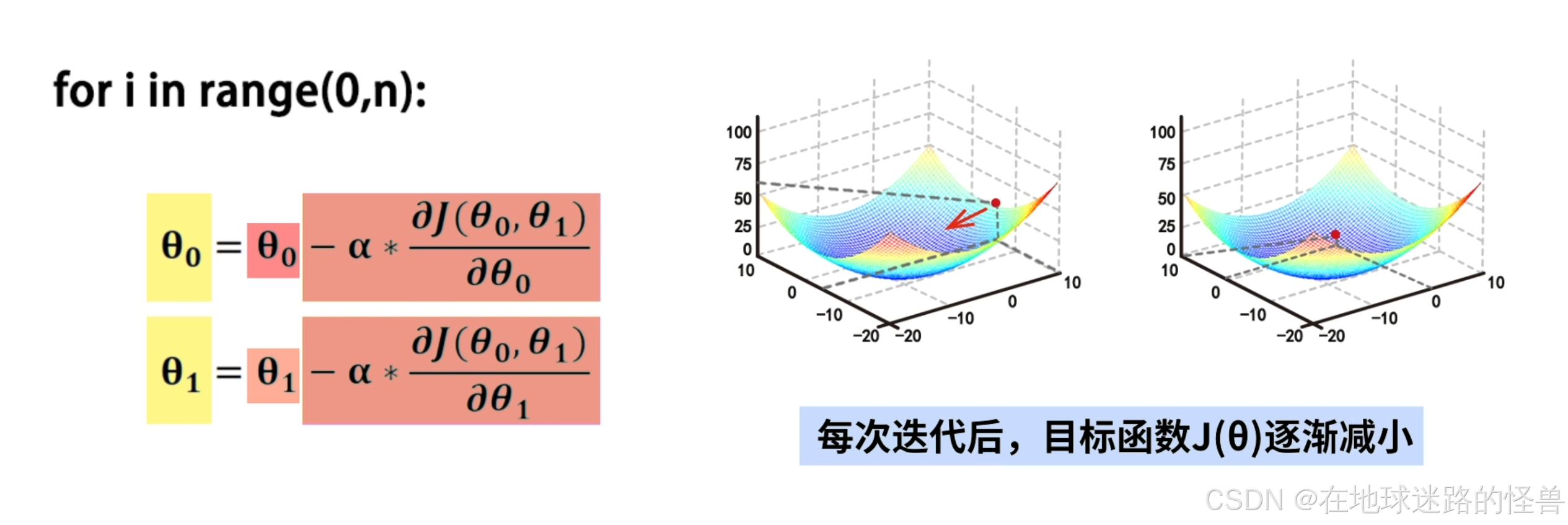
经过 n 轮迭代后,会达到 J(θ) 取得最小值的位置,在这个例子中 J(θ) 刚好等于 0,迭代结果就是: θ0=0 和 θ1=1:
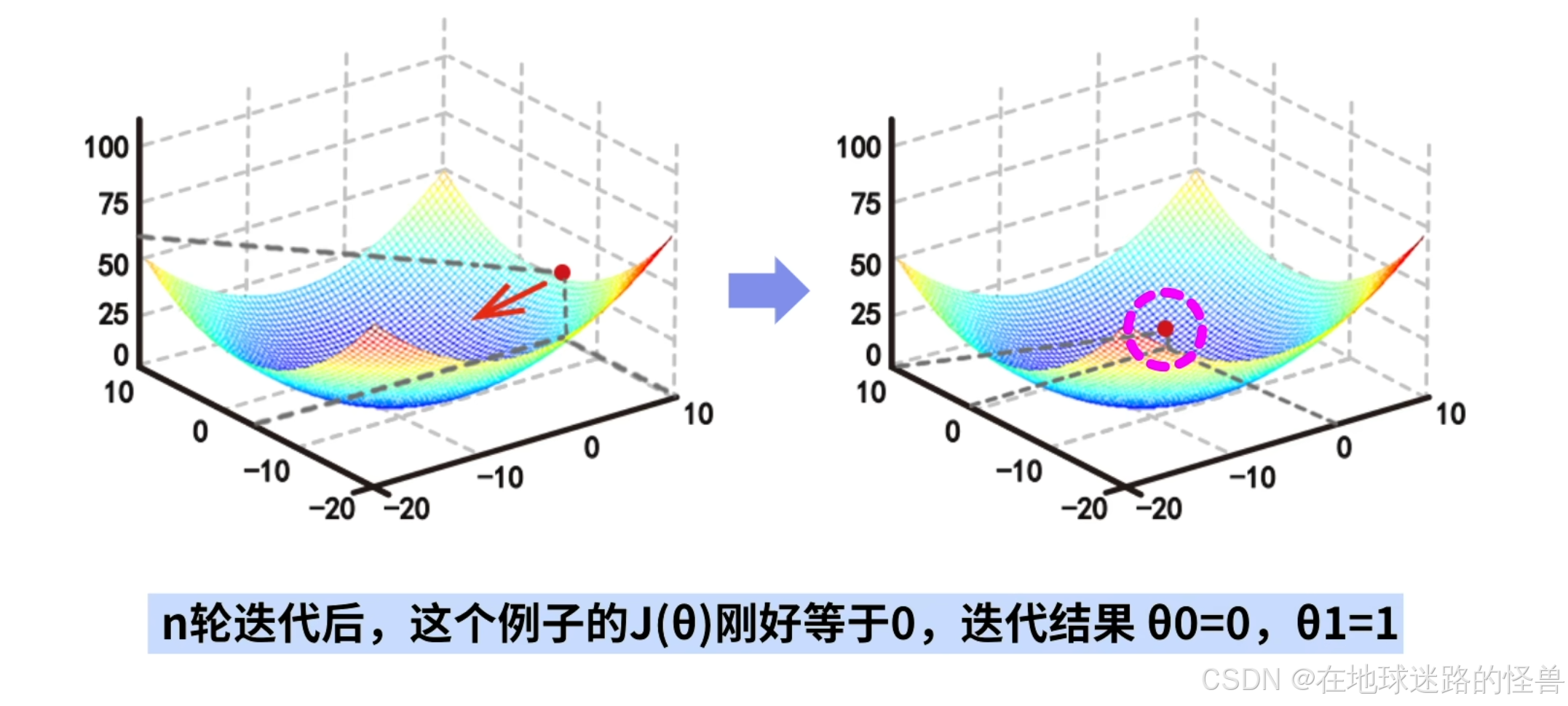
该结果与刚刚手算的结果是相同的。

梯度下降算法的代码实现
接下来我们分别使用 Numpy 和 PyTorch 实现梯度下降算法求解一元线性回归。
import matplotlib.pyplot as plt
import numpy as np
import torch
# 使用numpy实现梯度下降
# 实现损失J关于theta0偏导数的计算函数
def gradient_theta0(x, y, theta0, theta1):
# 因为x是一个数组,因此h实际上也是一个对应的数组
# 其实就是数组x中的每个元素乘以theta1再加上theta0就得到了数组h中对应位置的元素值
h = theta0 + theta1 * x
return np.sum(h - y) / len(x)
# 实现误差J关于theta1的偏导数的计算函数
def gradient_theta1(x, y, theta0, theta1):
h = theta0 + theta1 * x
return np.sum((h - y) * x) / len(x)
# 实现梯度下降算法的迭代函数
# 函数传入数据点x和y,迭代速率alpha和迭代次数n
def gradient_descent_np(x, y, alpha, n):
# 初始化参数为0
theta0 = 0.0
theta1 = 0.0
for i in range(1, n + 1): # 进入迭代的循环
# 首先计算误差J关于theta0和theta1的偏导数
# 求偏导数嘛,相当于这里就是在执行反向传播backward()函数了
g0 = gradient_theta0(x, y, theta0, theta1)
g1 = gradient_theta1(x, y, theta0, theta1)
# 使用梯度下降算法,更新theta0和theta1
# 相当于反向传播中的step()函数了
theta0 = theta0 - alpha * g0
theta1 = theta1 - alpha * g1
# 在每一轮的迭代中,打印迭代轮数、参数θ0和θ1、还有损失值loss
loss = np.mean((theta0 + theta1 * x - y) ** 2)
print(f'Epoch{i},'
f'theta0 = {theta0:.3f},'
f'theta1 = {theta1:.3f},'
f'Loss = {loss:.3f}')
return theta0, theta1 # 返回最终迭代结果
# 使用pytorch实现梯度下降
# 就不需要实现 J(θ) 关于theta0和theta1的偏导数的计算函数了
# 梯度下降算法的迭代函数
def gradient_descent_torch(x, y, alpha, n):
# 将输入的x和y转换为张量形式
x = torch.tensor(x)
y = torch.tensor(y)
# 定义张量形式θ0和θ1
theta1 = torch.tensor(0.0, requires_grad=True)
theta0 = torch.tensor(0.0, requires_grad=True)
# 定义一个优化器Adam,用来迭代参数θ
optimizer = torch.optim.Adam([theta1, theta0], lr=alpha)
for i in range(1, n + 1):
# 计算均方误差
loss = torch.mean((theta0 + theta1 * x - y) ** 2)
loss.backward() # 计算loss关于参数θ的偏导数
optimizer.step() # 梯度下降
optimizer.zero_grad() # 将梯度信息清空,为下一次迭代做准备
# 打印调试信息
print(f'Epoch{i},'
f'theta0 = {theta0:.3f},'
f'theta1 = {theta1:.3f},'
f'Loss = {loss:.3f}')
return theta0.item(), theta1.item() # 返回最终的迭代结果
# 不管使用哪种方法,main 函数的流程都是一样的
if __name__ == '__main__':
# 定义三个样本,(1,1)、(2,2)、(3,3),保存在x,y中
x = np.array([1.0, 2.0, 3.0])
y = np.array([1.0, 2.0, 3.0])
alpha = 0.01 # 迭速率,也就是学习率
n = 10000 # 迭代次数
# 迭代出直线的参数theta0 和theta1
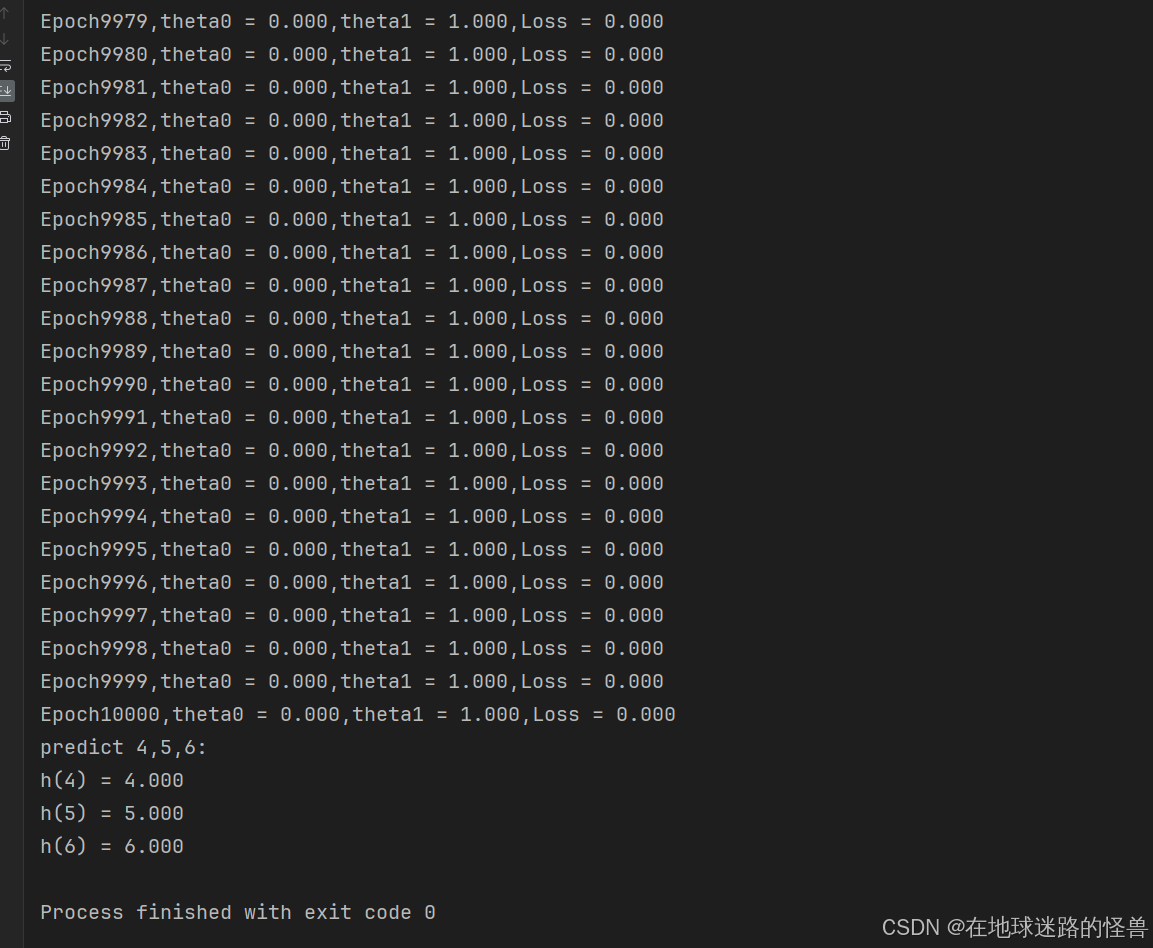
theta0, theta1 = gradient_descent_np(x, y, alpha, n)
# 打印x=4,5,6时的预测值
print("predict 4,5,6:")
print("h(4) = %.3lf" % (theta0 + theta1 * 4))
print("h(5) = %.3lf" % (theta0 + theta1 * 5))
print("h(6) = %.3lf" % (theta0 + theta1 * 6))
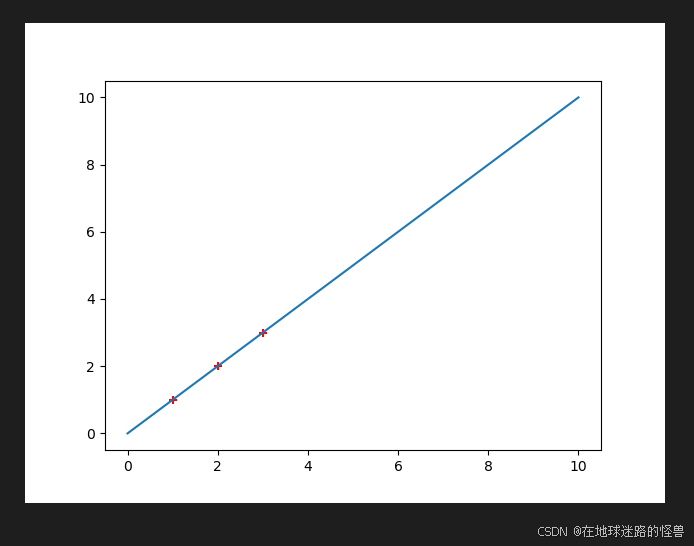
# 将这3个训练样本绘制到画板上
plt.scatter(x, y, color='red', marker='+')
# 将迭代出的直线绘制到画板上
x = np.linspace(0, 10, 100)
h = theta1 * x + theta0 # 直线的函数值
plt.plot(x, h) # 画出f1的图像
plt.show() # 调用show展示,就会得到一个空的画板
运行结果如下:
对于使用 numpy 方式的一些步骤与公式的对应图:

这个公式是怎么得出来的?下面是详细的推导过程:


在上面的代码中,我们可以发现对于使用 numpy 手动实现梯度下降和反向传播的过程和使用 PyTorch 实现的自动梯度惜艾昂和反向传播的过程其实是很相似的:
# numpy中
# 首先计算误差J关于theta0和theta1的偏导数
# 求偏导数嘛,相当于这里就是在执行反向传播backward()函数了
g0 = gradient_theta0(x, y, theta0, theta1)
g1 = gradient_theta1(x, y, theta0, theta1)
# 使用梯度下降算法,更新theta0和theta1
# 相当于反向传播中的step()函数了
theta0 = theta0 - alpha * g0
theta1 = theta1 - alpha * g1
------------------------------------------------------
# PyTorch中
loss.backward() # 计算loss关于参数θ的偏导数
optimizer.step() # 梯度下降
optimizer.zero_grad() # 将梯度信息清空,为下一次迭代做准备
可以看到貌似在手动实现的过程中并没有清零梯度这一操作,原因如下:

综上,不管使用哪种实现方式,我们会发现梯度下降算法的核心就是计算梯度,使用 numpy 就需要手动计算梯度,如果使用 PyTorch 可以直接使用 backward() 函数自动计算梯度。
补充:为什么梯度方向是函数值变化最快的方向
本补充一下梯度下降算法所依赖的数学原理,以更加深刻的理解梯度下降算法。
考虑下面这个问题:
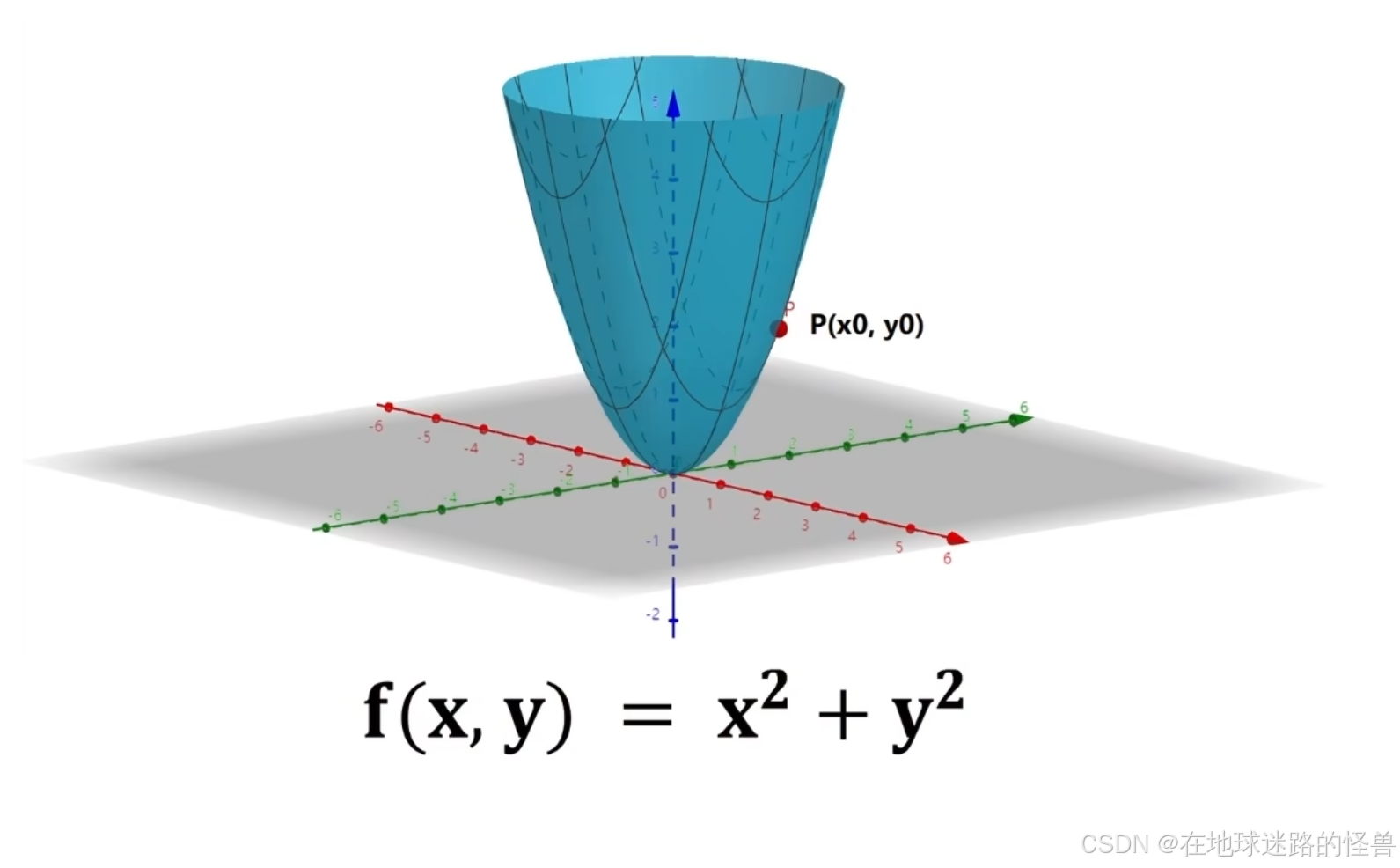
设多元函数 f(x,y) 如上,在多元函数上有一点 P(x0,y0) :
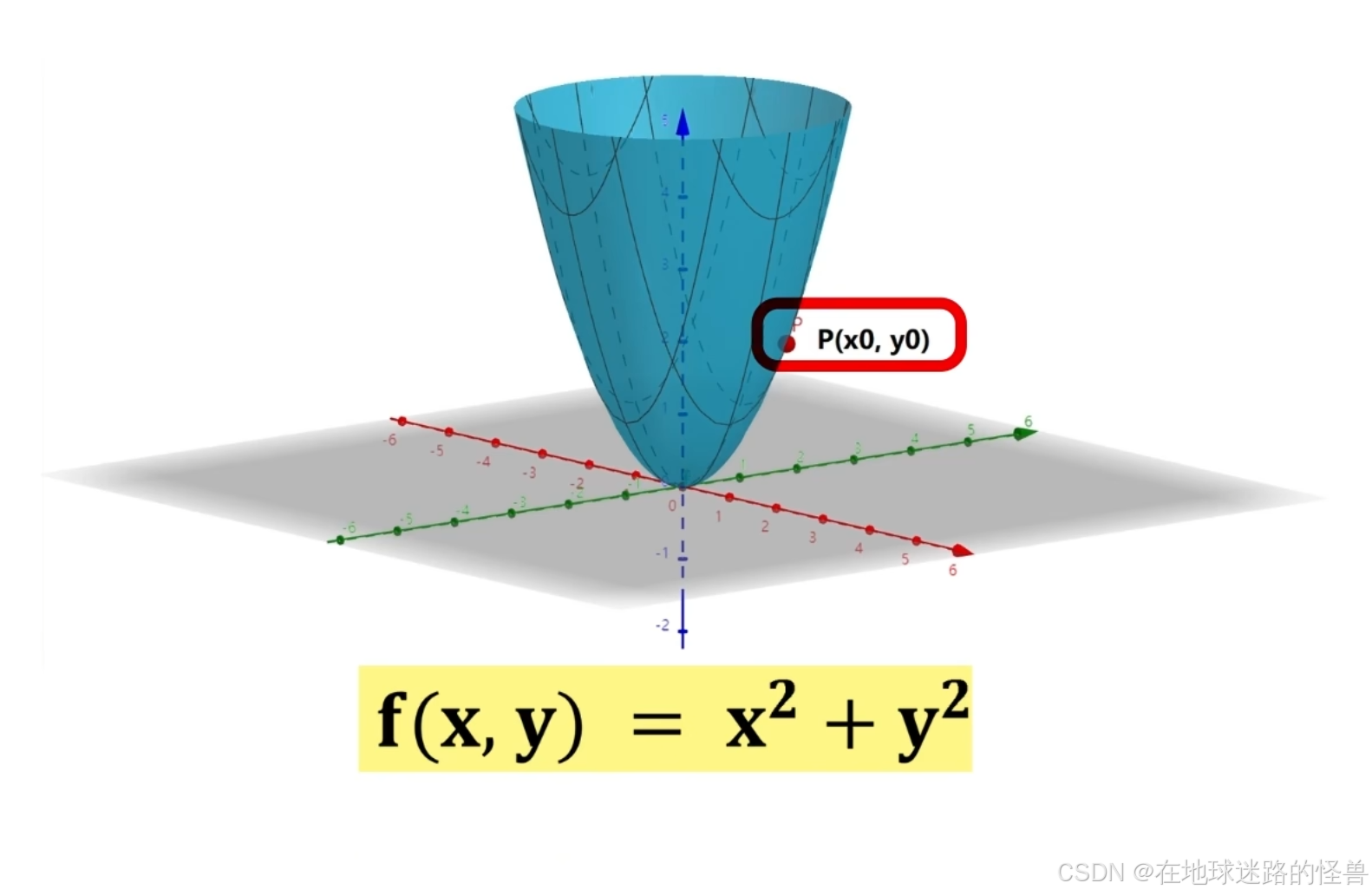
问如果我们从这一点出发,沿着哪个方向运动能使函数 f(x, y) 增大或者减小的最快呢?
先说结论:

梯度的基本概念
梯度,英文是 gradient,是微积分和向量分析中的重要概念。
可以定义为一个多元函数全部偏导数所构成的向量:
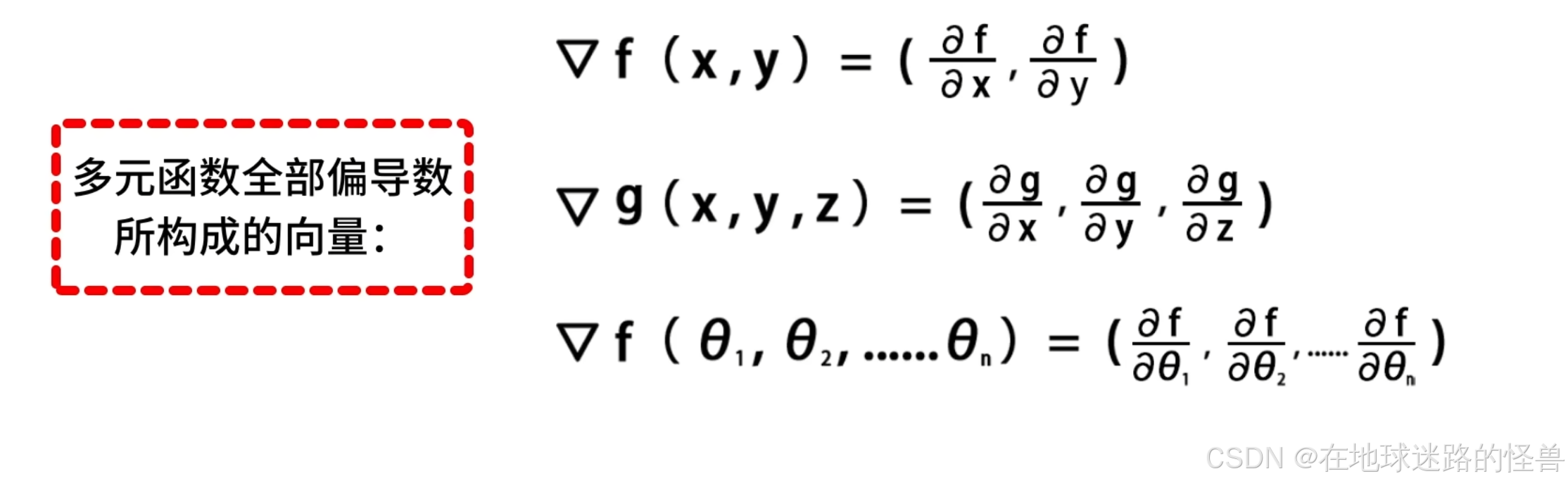
我们使用倒三角符号表示某个函数的梯度:

二元函数与函数上某点的梯度
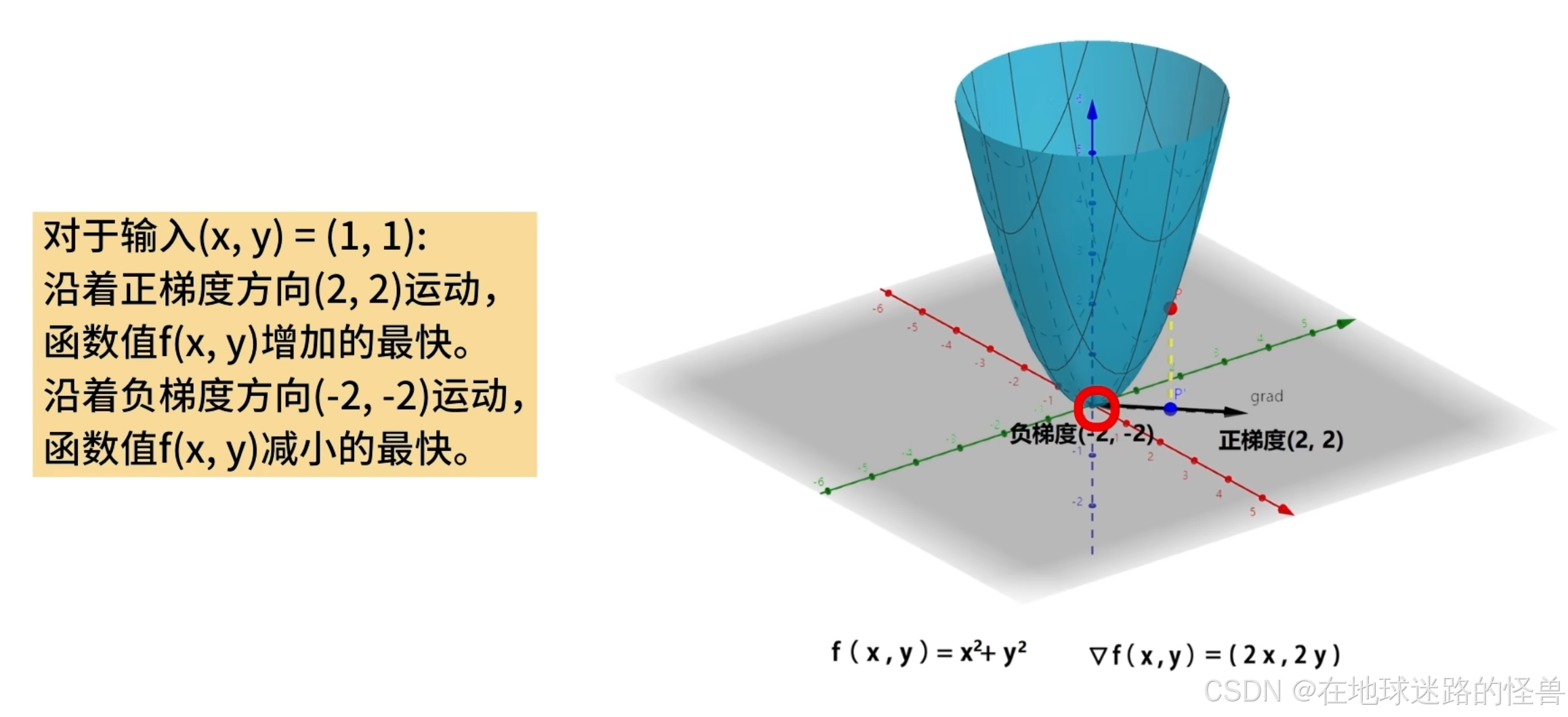
为了更加直观的说明函数与梯度的关系,我们画出上面说的二元函数 f(x, y) 在点 (1, 1) 处的梯度向量:
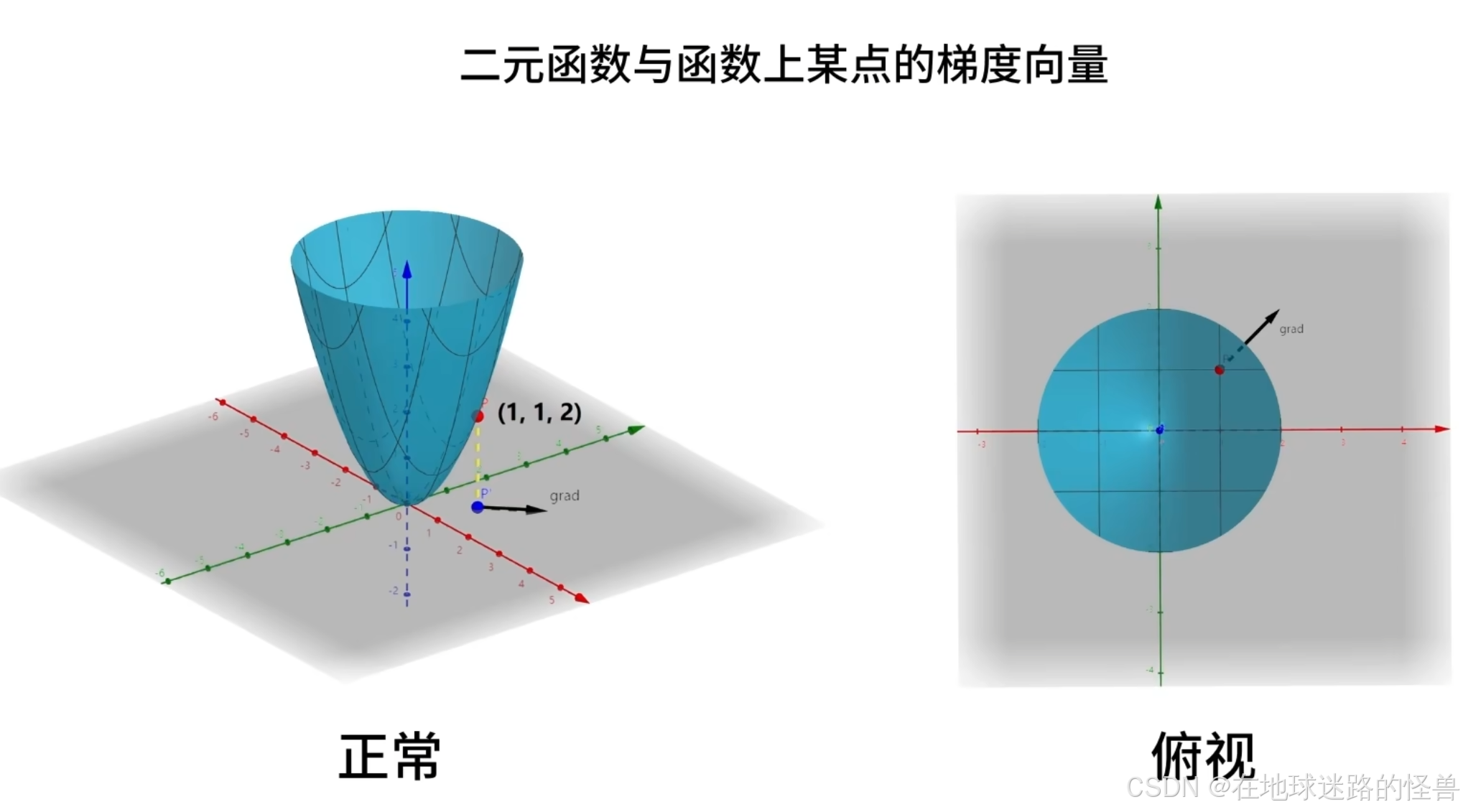
上图中将函数上的一点 P(1,1,2) 标记为了红色,将该点向 x-o-y 的平面投影,标记为蓝色:
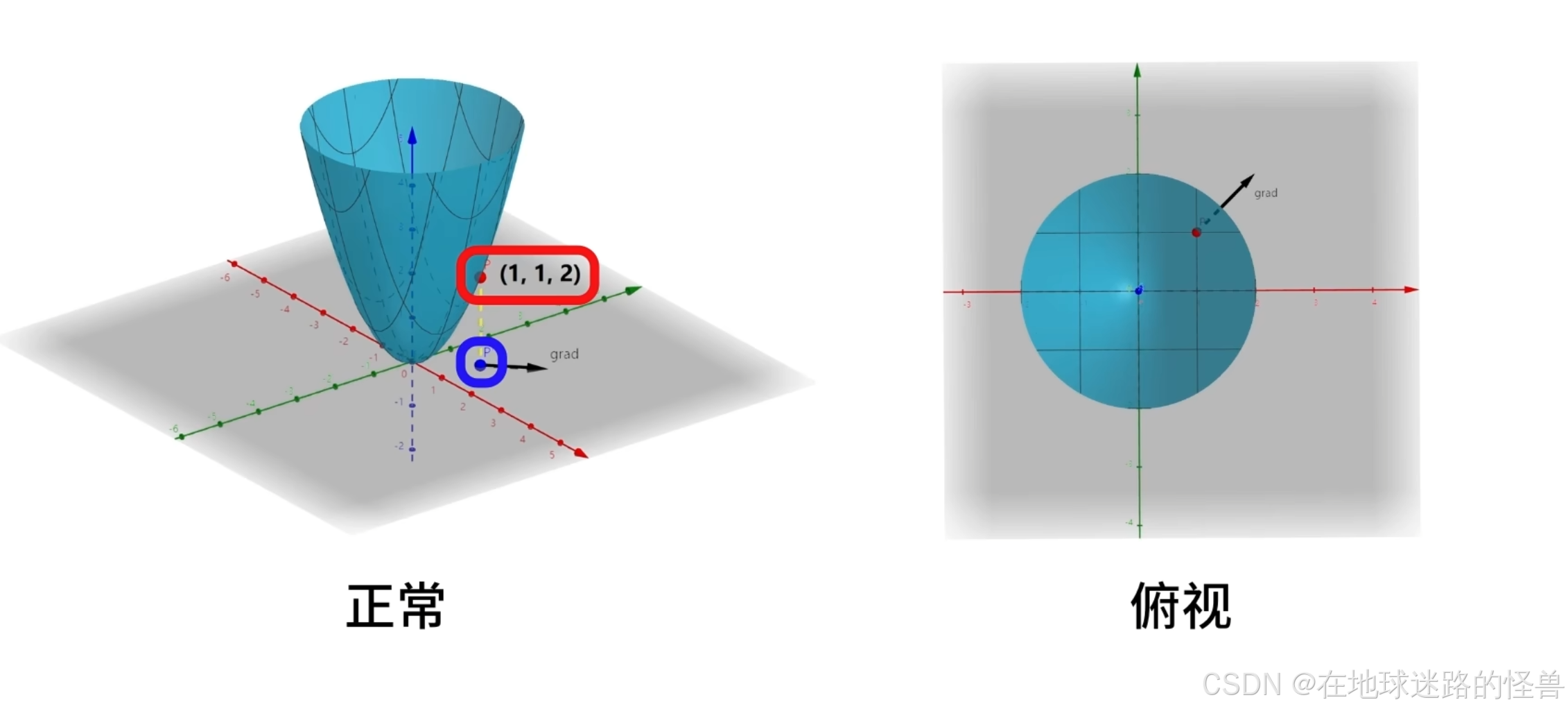
从该蓝色点出发,画出向量 (2,2),使用黑色箭头表示,它就是点 (1,1,2) 的梯度向量:
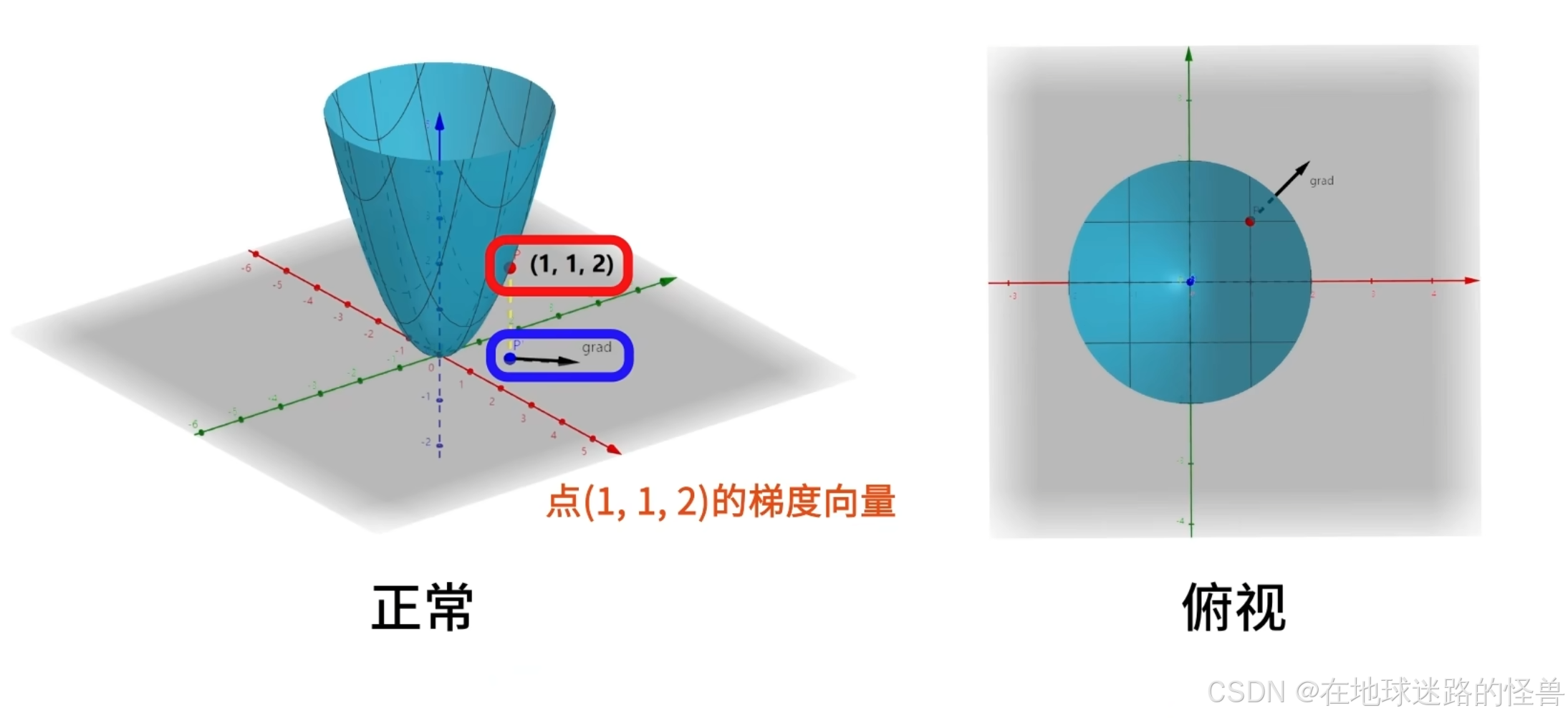
对于输入点 (1,1) ,如果它沿着 (2,2) 方向运动,函数会增加的最快。
因为梯度向量是在函数的输入空间中定义的,对应 x-o-y 这个平面,因此我们画出了蓝色的投影点,并从该点画出梯度向量。
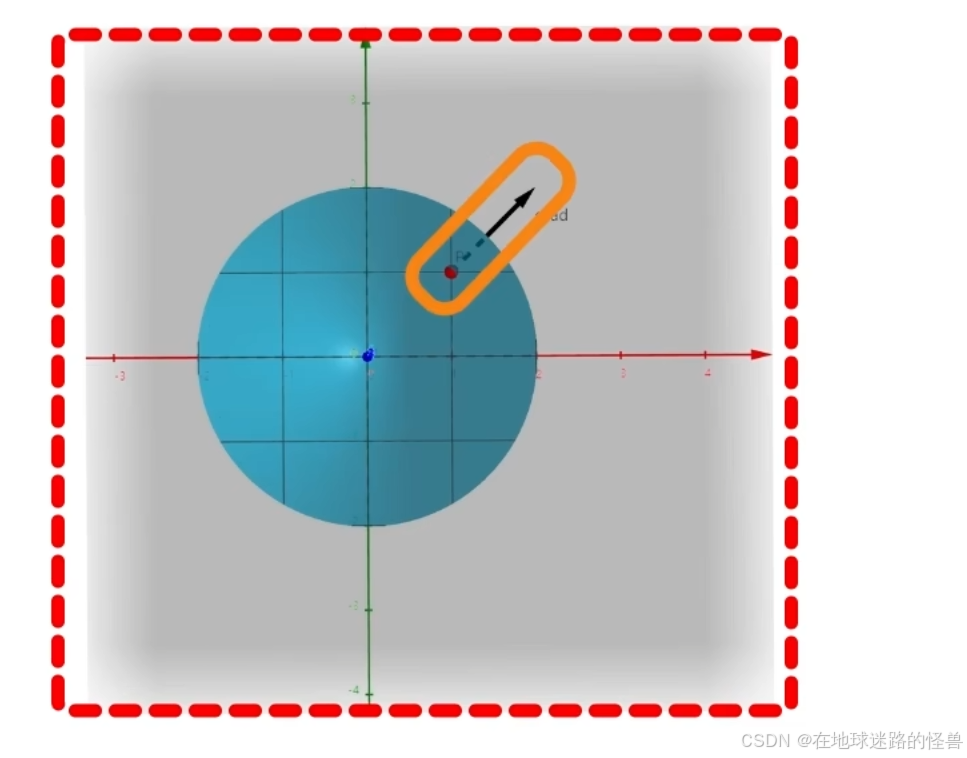
另外从俯视角度进一步观察黑色的梯度向量:
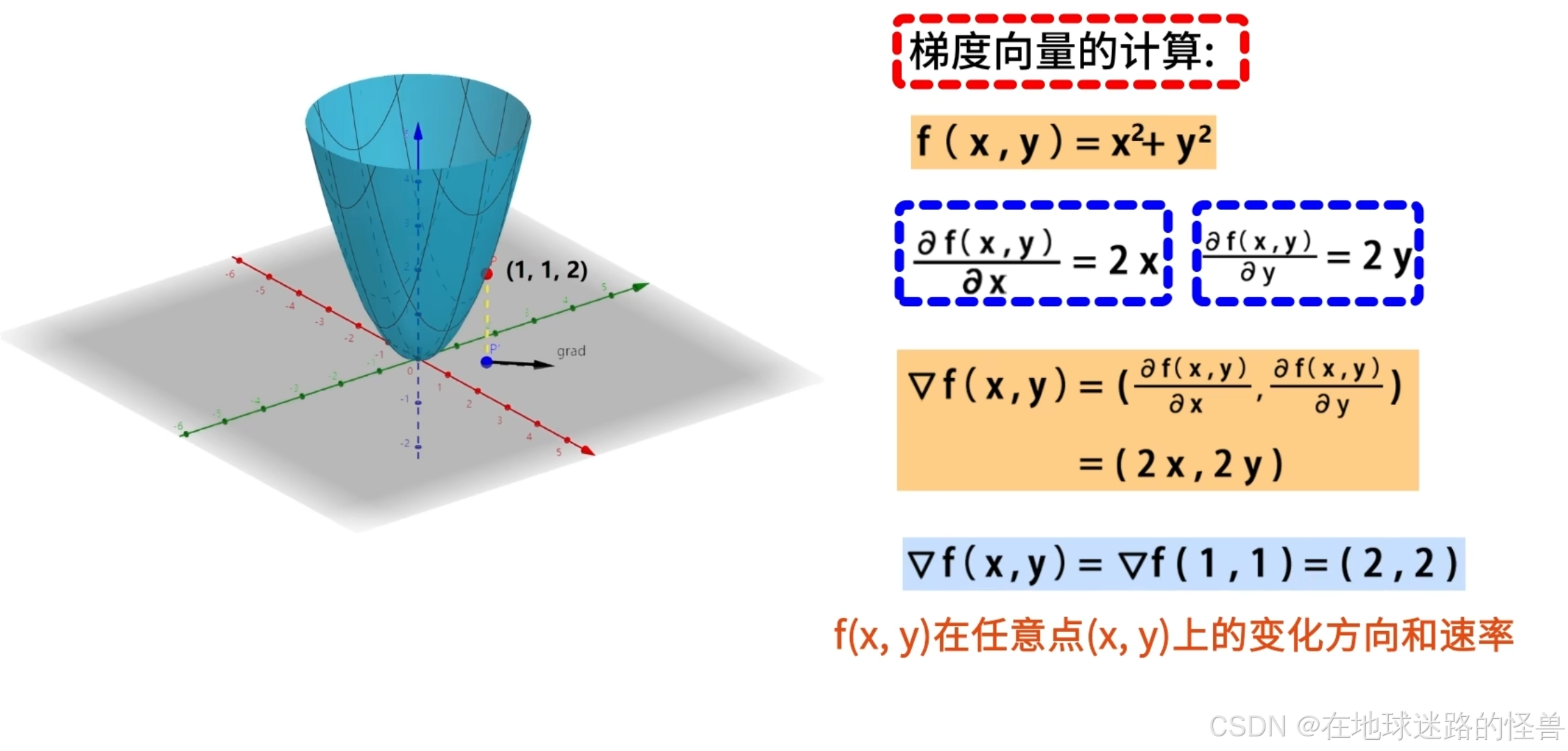
梯度向量的计算
依然是上面这个例子函数 f(x, y),说明梯度计算的方法。
首先分别求出 f(x, y) 关于 x 和 y 的偏导数 2x 和 2y,然后将这两个偏导数组合成一个梯度向量 (2x, 2y),这表示了 f(x,y) 在任意点 (x, y) 上的变化方向和速率,将坐标 (1, 1) 带入,计算点 (1, 1) 处的梯度可以得到向量 (2, 2):
梯度的性质
梯度的方向是函数值上升最快的方向。
对于函数上的某个点,如果沿河梯度方向移动,那么函数值增加的最快;如果沿着梯度的反方向移动,那么函数值减小的最快:
接下来我们举例说明这些性质:
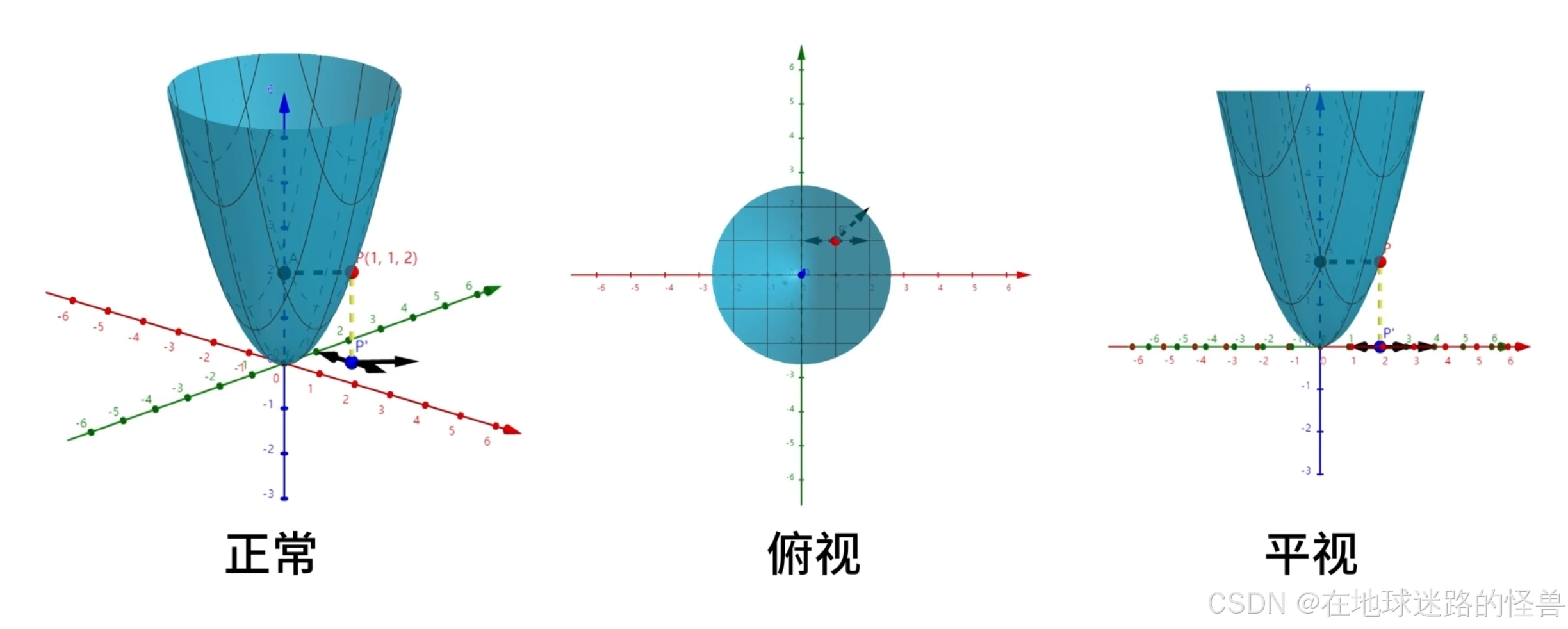
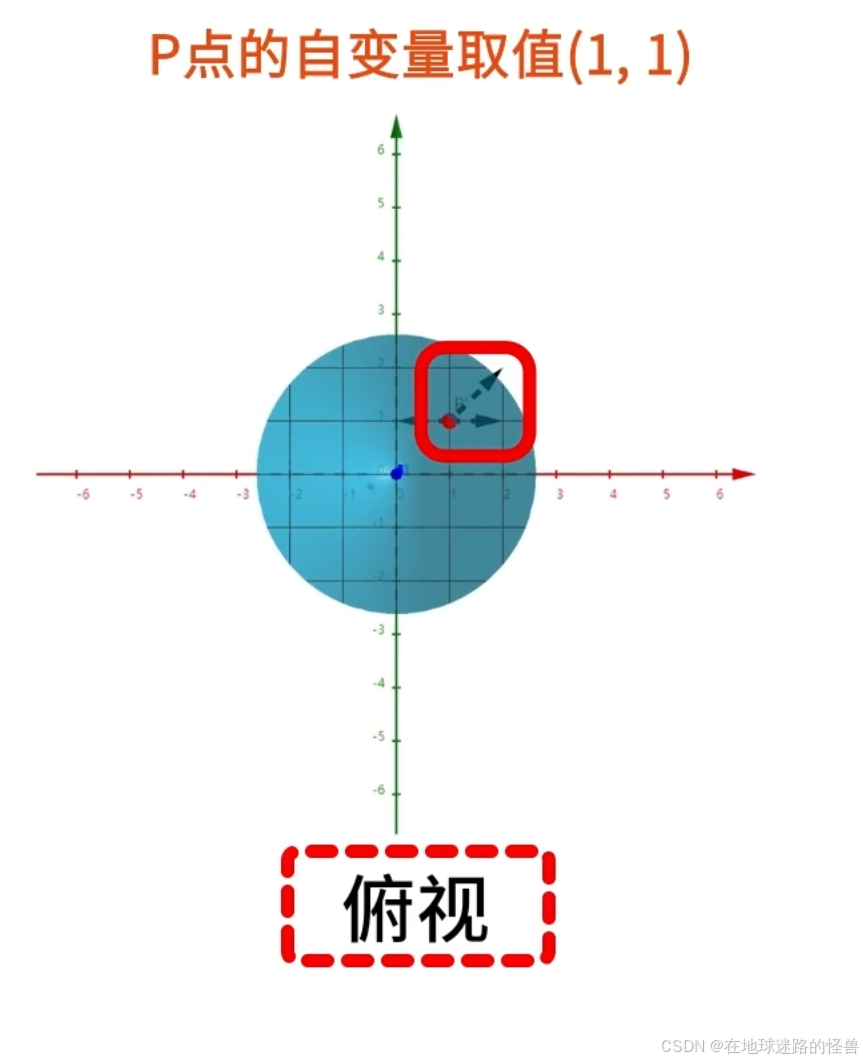
依然是讨论点 P(1, 1, 2) 的运动,将函数图像调整为俯视角度,可以观察到 P 点的自变量取值 (1, 1) 与其可能的运动方向:
调整为平视角度可以观察到函数值 f(1,1) = 2:
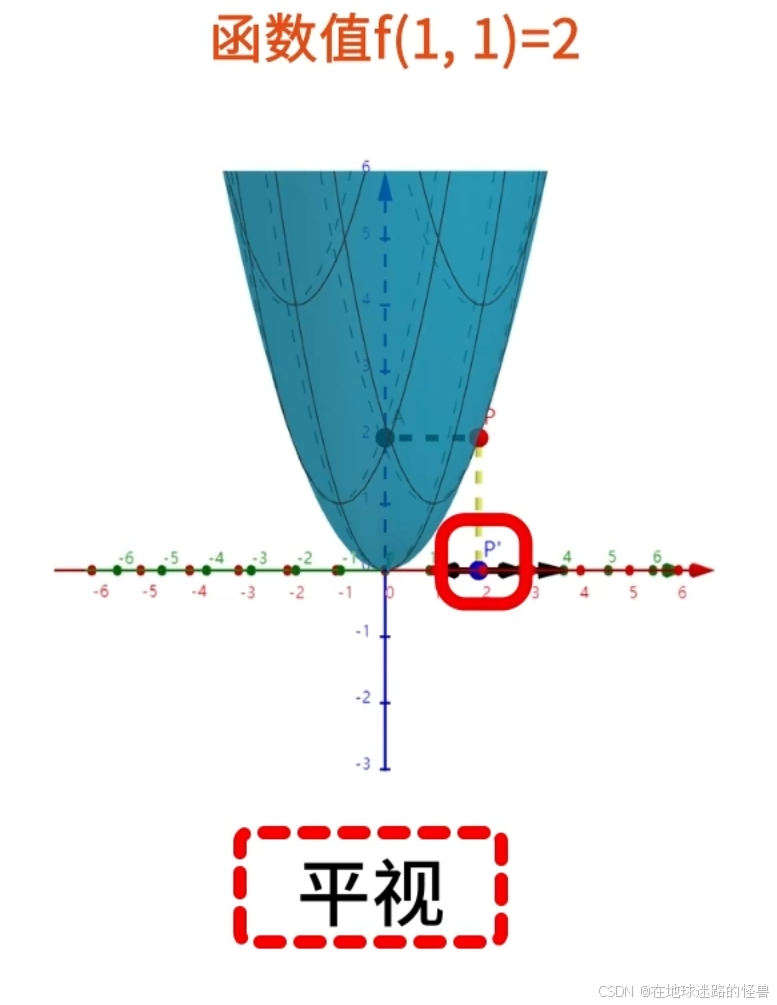
注意上图的横坐标有一点问题,P 的位置的横坐标部分应该是1的。
接下来我们会从 P 出发向不同的方向运动相同的长度,来说明沿着梯度方向运动函数值会变化的最快。
为什么沿着梯度方向运动,函数值变化的最快
基于俯视的角度观察函数:

在 xoy 平面上设置三个方向向量(-1,0)、(1,0) 和 (2,2) 分别代表接下来自变量 x 和 y 要变化的方向,分别是向左运动、向右运动和沿梯度方向运动。
然后我们要从 P 点进行上述三个方向的移动,分别移动一个单位到达 A、B、C 三个点,然后比较 A、B、C这三个点的函数值相比于 P 点函数值的变:
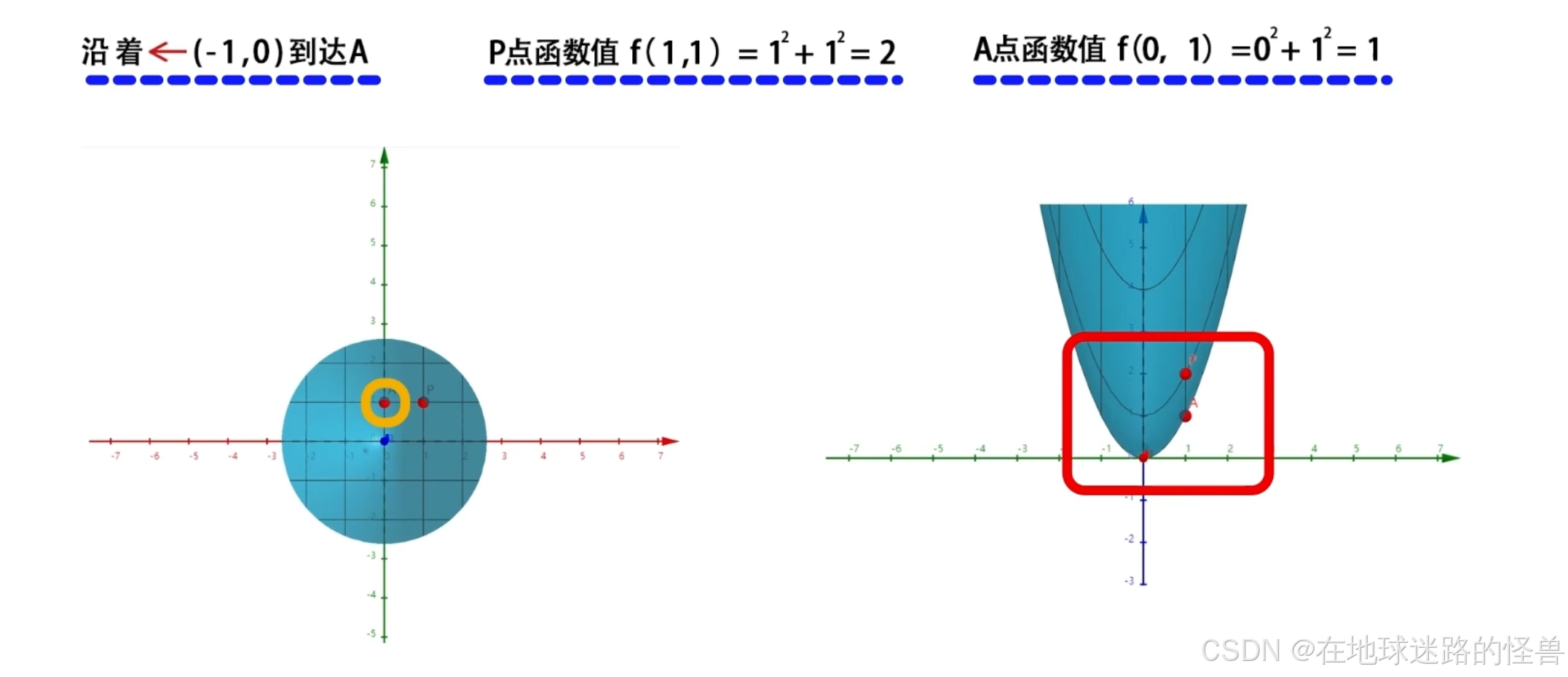
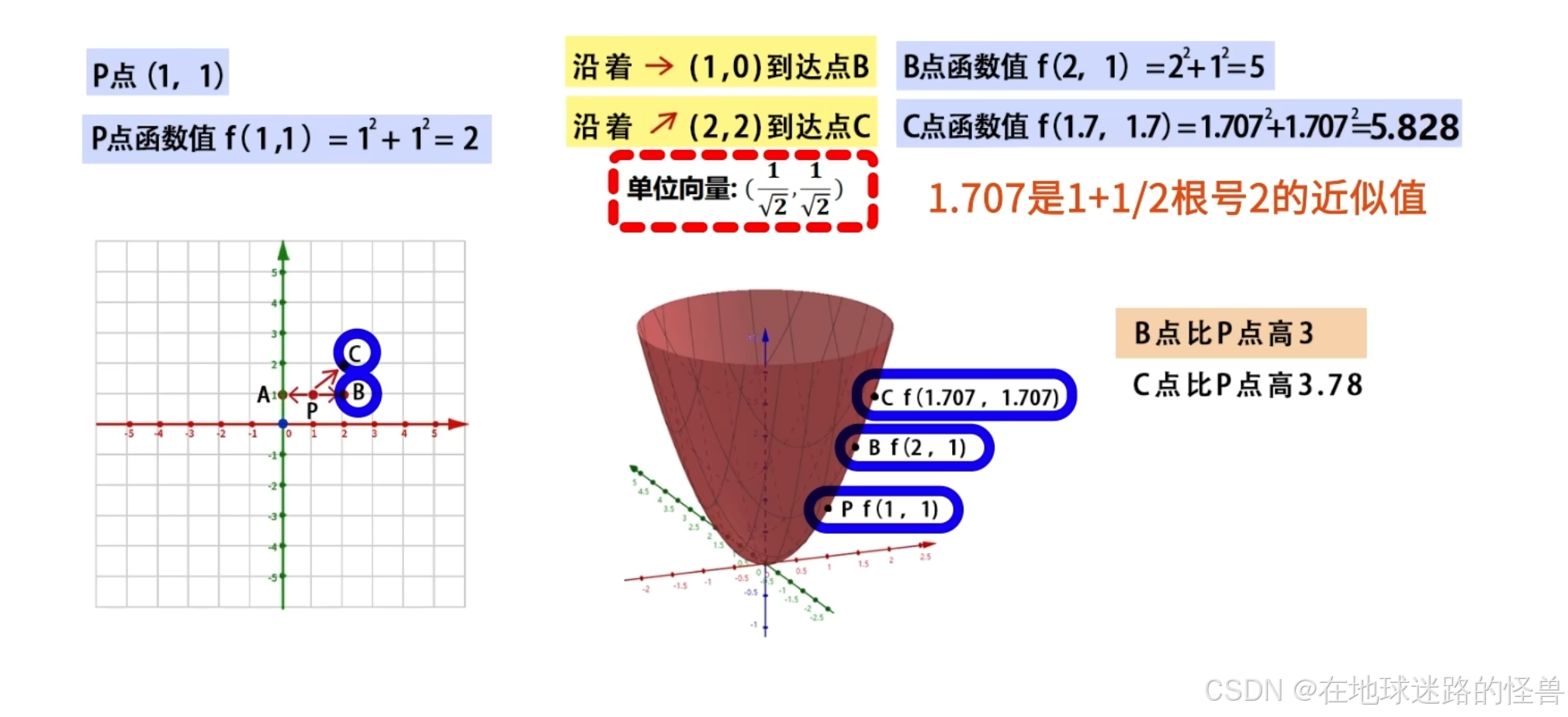
从上面的例子中可以看到,同样是移动一个单位 1 的长度,如果函数上的某个点沿着该点的梯度方向移动,函数值增长的最为迅猛,相应地,如果沿着梯度的反方向运动,那么函数的值就会减小的最快。
如果想了解严格的数学证明的话,就需要去学习《方向导数》、《梯度方向与方向导数的关系》等相关概念了。
另外在机器学习的训练算法中,我们总是需要找到目标函数的最小值,因此从函数的某一个点出发,使该点沿着梯度的反方向运动,会使得函数减小的最快,
基于这样的运动方式,就可以更快的使得函数收敛到最小,这就是梯度下降算法的理论基础。



















 3210
3210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











