







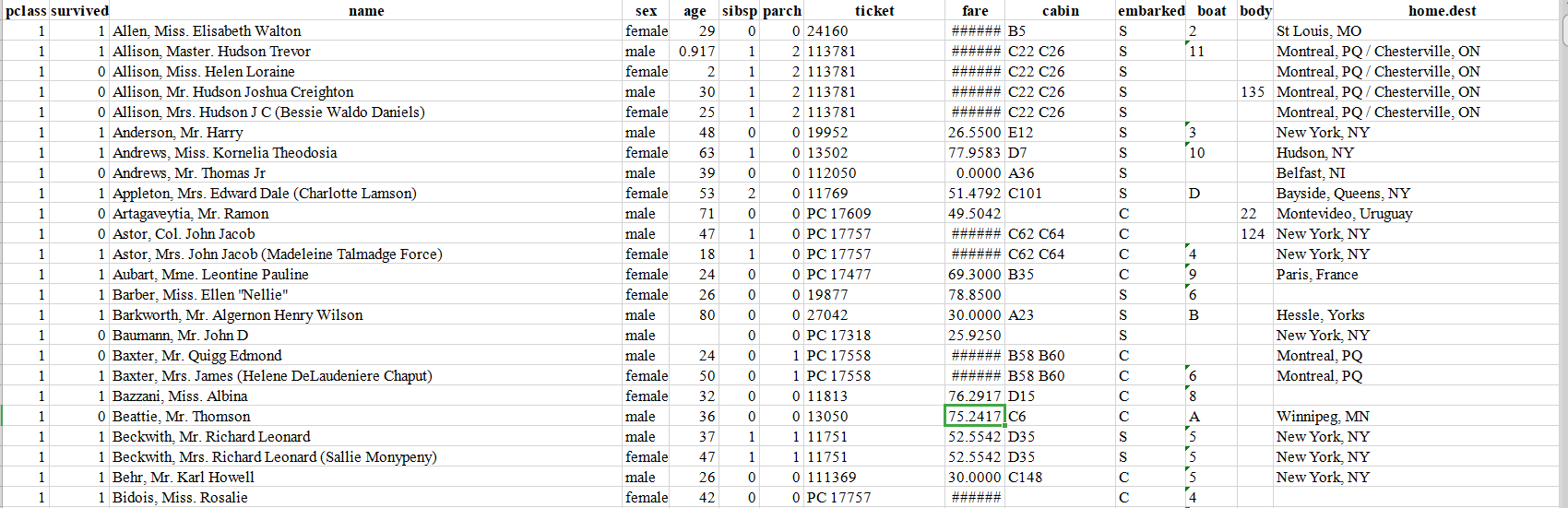
先看一眼我们拿到的数据: 在数据中有浮点数, 有字符串, 现在我们要做的就是制作满足pytorch条件的数据集。
1.先加载数据集
2.选出我们需要的行
3.将字符串类型数据转换成浮点数型
4.将数据集保存在新的excel文件中
1.使用pd.read_excel()方法读取excel表格中的数据
#读取到excel文件中的数据集
path = r'D:\数据集\泰坦尼克号\泰坦尼克号.xls'
all_df = pd.read_excel(path) 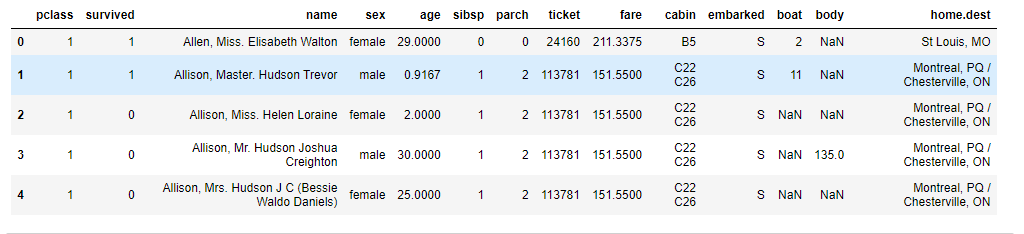
2. 选择出我们训练所需要的列
#把需要的列放进一个列表中,表示选中这些列, 拿到我们需要的数据集
cols = ['survived', 'name', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked']
data= all_df[cols].drop(['name'], axis=1)
data.head() 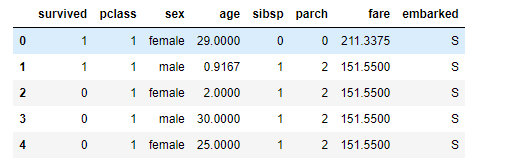
3. 将字符串数据转换成浮点数
#将性别为female用0代替, male用1代替
dict_sex = {'female':0, 'male':1}
data['sex'] = data['sex'].map(dict_sex)
#登船口也和性别处理方法一样
dict_embarked = {'S':0, 'C':1, 'Q':2}
data['embarked'] = data['embarked'].map(dict_embarked)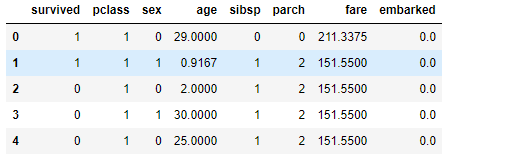
4.查看数据中分别哪些选项会有空值, 有空值的地方需要填充
#该方法可以计算数据中分别有多少个空值
print(data.isnull().sum())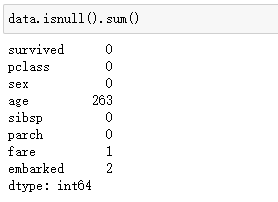
5.计算出age的平均年龄,使用Datafram.fillna()方法填充空值, 填充后age的空值个数为0
#因为有很多的年龄为空值, 所以我们用这个方法可以用年龄的平均值填充空位
age_mean = data['age'].mean()
data['age'] = data['age'].fillna(age_mean)
6.计算金额的平均 值并填充
#填充fare
fare_mean = data['fare'].mean()
data['fare'] = data['fare'].fillna(fare_mean)
7.因为登船口对生存率影响不大, 所以人为指定一个登船口
#因为哪个登船口上船对生还率影响不大, 所以用1登船口填充
data['embarked'] = data['embarked'].fillna(1)
8.产生一个true 或者false的列表, 把这个列表传递给data数据, 当某一项为true时候,那么这一项就会被选中.
msk = np.random.random(len(train_datas)) < 0.8
print(msk) ![]()
9.拿出约80%的数据作为训练集, 20%的数据做测试集
产生一个列表, 列表中每一个是一个bool类型的作为映射, 选取数据集大约80%的为True
msk = np.random.random(len(data)) < 0.8
#用80%的数据做训练集, 20%做测试集
train_datas = data[msk]
test_datas = data[~mak]
print('train_datas= ',len(train_datas))
print('test_datas=', len(test_datas))
9.将划分好的数据存储在文件中, 下次使用是直接读取两个文件即可
#指定文件路径, 把划分好的数据存储在文件中
train_path = r'D:\数据集\泰坦尼克号\train_data.xlsx'
test_path = r'D:\数据集\泰坦尼克号\test_data.xlsx'
train_datas.to_excel(train_path)
test_datas.to_excel(test_path)
数据集完整代码:
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torchvision.transforms import transforms
from torch.utils.data import Dataset,DataLoader
import torch.optim as optim
path = r'D:\数据集\泰坦尼克号\泰坦尼克号.xls'
all_df = pd.read_excel(path)
cols = ['survived', 'name', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked']
data= all_df[cols].drop(['name'], axis=1)
dict_sex = {'female':0, 'male':1}
data['sex'] = data['sex'].map(dict_sex)
dict_embarked = {'S':0, 'C':1, 'Q':2}
data['embarked'] = data['embarked'].map(dict_embarked)
age_mean = data['age'].mean()
data['age'] = data['age'].fillna(age_mean)
fare_mean = data['fare'].mean()
data['fare'] = data['fare'].fillna(fare_mean)
data['embarked'] = data['embarked'].fillna(1)
msk = np.random.random(len(data)) < 0.8
train_datas = data[msk]
test_datas = data[~msk]
print('train_datas= ',len(train_datas))
print('test_datas=', len(test_datas))
train_path = r'D:\数据集\泰坦尼克号\train_data.xlsx'
test_path = r'D:\数据集\泰坦尼克号\test_data.xlsx'
train_datas.to_excel(train_path)
test_datas.to_excel(test_path)接下来就可以使用pytorch提供的Dataset类创建和加载我们的数据集
在我们这个类中, 需要做参数是数据的路径, 我们需要做3件事情
1.将我们的数据转换成np.arrar()类型 #因为需要转换成tensor才可以使用Dataloader加载我们的批量数据,所以需要先转换成np.array()
2.拿到我们的train_data(训练数据) 和 label(标签) 并指定数据类型(pytorch的交叉熵损失需要的标签是Long类型的,但是np.int64和Long类型一致, 因为W是浮点型, 所以我们的训练数据也指定问浮点型)
3.将数据集转换成Tensor类型 并重写len 和 getitem函数
class MyDataset(nn.Module):
def __init__(self, root):
super(MyDataset, self).__init__()
self.root = root
self.df = pd.read_excel(self.root)
self.data = np.array(self.df)
self.train_data = self.data[:, 2:-1]
self.train_label = self.data[:, 1]
self.train_data = self.train_data.astype(np.float32)
self.train_label = self.train_label.astype(np.int64)
self.train_data = torch.from_numpy(self.train_data)
self.train_label = torch.from_numpy(self.train_label)
def __len__(self):
return len(self.train_label)
def __getitem__(self, item):
return self.train_data[item], self.train_label[item]加载我们的数据集:
train_dataset = MyDataset(root=path)
data_loader = DataLoader(train_dataset, batch_size=20, shuffle=True)
for i, data in enumerate(data_loader):
train_x, train_y = data
print(train_x.shape)
print(train_y.shape)
break
三: 定义我们的网络结构: (这里损失函数这一块我有点疑惑, 就是不知道为什么不拟合, 反正人和代码有一个能跑就行)
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.linear1 = nn.Linear(6, 64)
self.linear2 = nn.Linear(64, 128)
self.linear3 = nn.Linear(128, 32)
self.linear4 = nn.Linear(32, 2)
def forward(self, x):
x = self.linear1(x)
x = self.linear2(x)
x = self.linear3(x)
x = self.linear4(x)
return x
net = MyNet()
criterion = nn.CrossEntropyLoss() # Defined loss function
optimizer = torch.optim.SGD(net.parameters(), lr=0.01) # Defined optimizer
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(data_loader,0):
images, label = data
outputs = net(images)
loss = criterion(outputs, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if(i+1)%10==0:
print('[%d %5d] loss: %.3f'%(epoch+1, i+1, running_loss/100))
running_loss = 0.0
print('Finished Training') 
接下来就是保存模型:
#保存模型
torch.save(net, 'model_name.pth') #保存的是模型, 不止是w和b权重值
# 读取模型
model = torch.load('model_name.pth')在测试集上查看表现:
#在全部测试集上的表现
test_path = r'D:\数据集\泰坦尼克号\test_data.xlsx'
test_dataset = MyDataset(root=path)
testloader = DataLoader(train_dataset, batch_size=20, shuffle=True)
correct = 0
total = 0
with torch.no_grad(): #表示下面的计算不需要计算图和反向求导
for data in testloader:
images, label = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += label.size(0)
correct += (predicted == label).sum().item() #如果预测值和真实值相同, 则为true=1, 求和
print('Accuracy of the network on the 10000 test images: %d %%'%(100 * correct / total )) ![]()















 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









