







1 介绍
本文对手写数字识别进行分类,数据使用csv格式,版本使用pytorch版本,模型自己搭建。
2 导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from sklearn.model_selection import train_test_split
3 导入数据集
data = pd.read_csv(r"train.csv", dtype=np.float32)
4 划分特征和标签,并且数据归一化
x = data.loc[:, data.columns != "label"].values /255 # normalization
y = data.label.values
5 划分训练集-测试集
X_train, X_test, y_train, y_test = train_test_split(x, y,
train_size=0.8,
random_state=42,
shuffle=True)
6 图像展示
for i in range(20):
plt.subplot(4,5,i+1)
plt.imshow(X_train[i].reshape(28, 28))
plt.axis("off")
plt.title(str(int(y_train[i])))
plt.show()

7 数据类型转换,使用 from_numpy转换为tensor
X_train = torch.from_numpy(X_train)
y_train = torch.from_numpy(y_train).type(torch.LongTensor) # data type is long
# create feature and targets tensor for test set.
X_test = torch.from_numpy(X_test)
y_test = torch.from_numpy(y_test).type(torch.LongTensor) # data type is long
8 设置参数,构建DataLoader
batch_size, epoch and iteration
batch_size = 100
n_iters = 4000
num_epochs = n_iters / (len(X_train) / batch_size)
num_epochs = int(num_epochs)
print(num_epochs)
# Pytorch train and test sets
train = torch.utils.data.TensorDataset(X_train,y_train)
test = torch.utils.data.TensorDataset(X_test,y_test)
# data loader
train_loader = torch.utils.data.DataLoader(train, batch_size = batch_size, shuffle = False)
test_loader = torch.utils.data.DataLoader(test, batch_size = batch_size, shuffle = False)
9 搭建CNN模型
class CNNModel(nn.Module):
def __init__(self):
super(CNNModel, self).__init__()
# Convolution 1
# in_channels:输入通道数1,输入图像是单通道
# out_channels;输出通道数目
# kernel_size:5*5:(不关键) 一般是3*3
# stride:步长1:(不关键)
# padding:填充(不关键)
self.cnn1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=2, padding=0)
self.relu1 = nn.ReLU()
# Max pool 1
self.maxpool1 = nn.MaxPool2d(kernel_size=2)
# Convolution 2
self.cnn2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=0)
self.relu2 = nn.ReLU()
# Max pool 2
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
# Fully connected 1
self.fc1 = nn.Linear(32, 10)
def forward(self, x):
# Convolution 1
out = self.cnn1(x)
out = self.relu1(out)
# Max pool 1
out = self.maxpool1(out)
# Convolution 2
out = self.cnn2(out)
out = self.relu2(out)
# Max pool 2
out = self.maxpool2(out)
# flatten
out = out.view(out.size(0), -1)
# Linear function (readout)
out = self.fc1(out)
return out
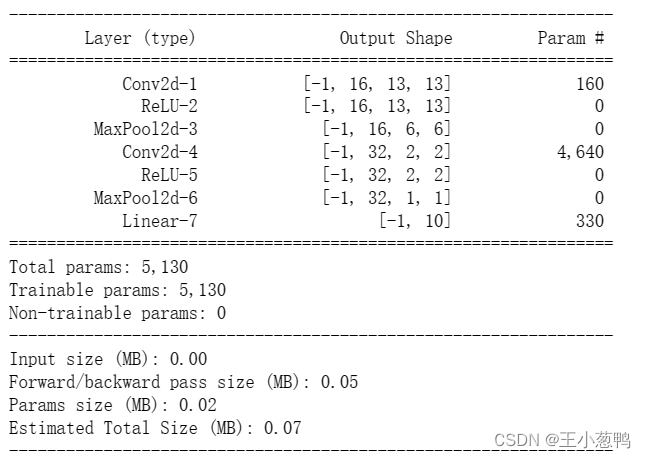
10 打印模型参数
model = CNNModel()
import torchsummary
torchsummary.summary(model, (1, 28, 28))
11 模型训练和验证
# Cross Entropy Loss
error = nn.CrossEntropyLoss()
# SGD Optimizer
learning_rate = 0.1# 学习率:0.0001,0.001,0.01,0.1,0.5
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# CNN model training
count = 0
loss_list = []
iteration_list = []
accuracy_list = []
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
train = Variable(images.view(batch_size, 1, 28, 28))
labels = Variable(labels)
# Clear gradients
optimizer.zero_grad()
# Forward propagation
outputs = model(train)
# Calculate softmax and ross entropy loss
loss = error(outputs, labels)
# Calculating gradients
loss.backward()
# Update parameters
optimizer.step()
count += 1
if count % 50 == 0:
# Calculate Accuracy
correct = 0
total = 0
# Iterate through test dataset
for images, labels in test_loader:
test = Variable(images.view(batch_size, 1, 28, 28))
# Forward propagation
outputs = model(test)
# Get predictions from the maximum value
predicted = torch.max(outputs.data, 1)[1]
# Total number of labels
total += len(labels)
correct += (predicted == labels).sum()
accuracy = 100 * correct / float(total)
# store loss and iteration
loss_list.append(loss.data)
iteration_list.append(count)
accuracy_list.append(accuracy)
if count % 500 == 0:
# Print Loss
print('Iteration: {} Loss: {} Accuracy: {} %'.format(count, loss.data, accuracy))

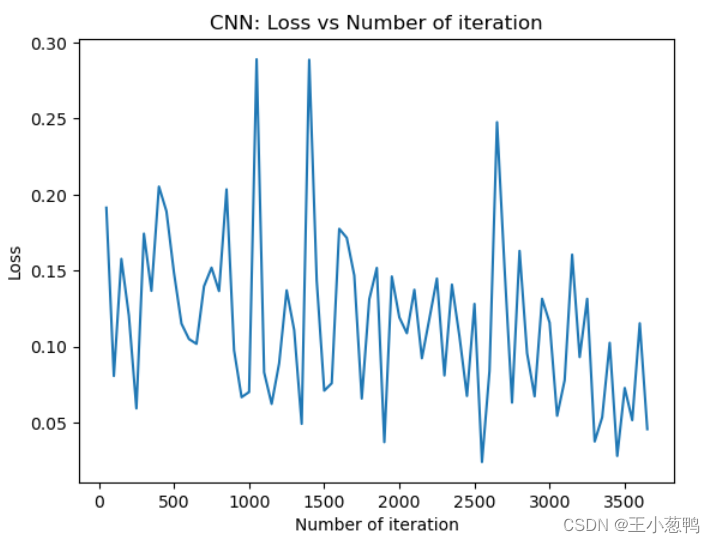
12 loss可视化
plt.plot(iteration_list,loss_list)
plt.xlabel("Number of iteration")
plt.ylabel("Loss")
plt.title("CNN: Loss vs Number of iteration")
plt.show()
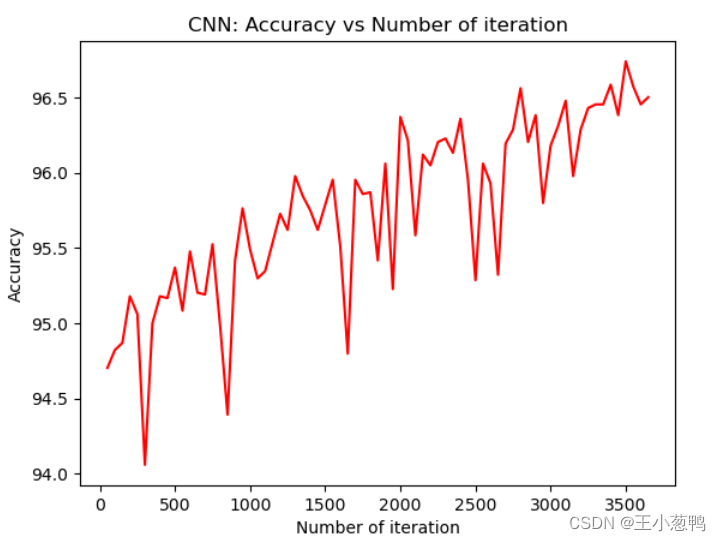
13 精度可视化
# visualization accuracy
plt.plot(iteration_list,accuracy_list,color = "red")
plt.xlabel("Number of iteration")
plt.ylabel("Accuracy")
plt.title("CNN: Accuracy vs Number of iteration")
plt.show()

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











