



1、环境配置
根据下述要求:

选择如下配置:

记得切换安装源:
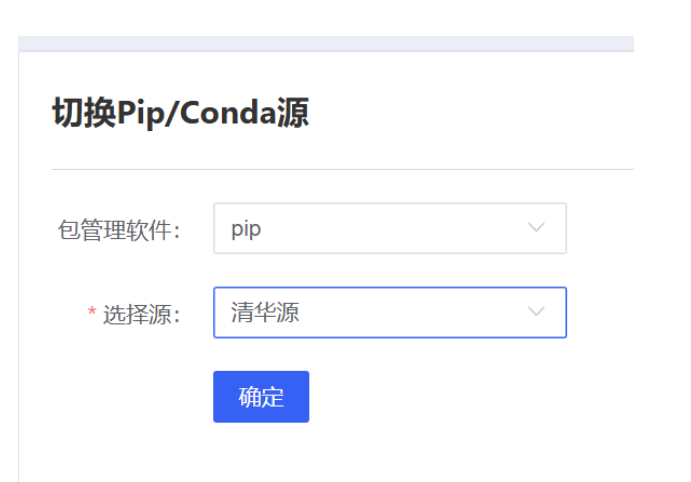
运行下述代码克隆代码库:
git clone https://github.com/hturki/suds.git
配置环境:
conda env create -f environment.yml
激活环境:
conda env create -f environment.ym
编译环境:
python setup.py install
2、数据准备(针对于KITTI数据集的0006序列进行训练)
1、从 KITTI MOT 数据集下载以下内容:
2、KITTI数据集各个文件夹解析
-
data_tracking_calib:包含了一系列相机与激光雷达的外参和内参矩阵,比如:
P2:左相机投影矩阵、P3:右相机投影矩阵、R_rect:相机矫正矩阵、Tr_velo_to_cam:激光雷达坐标系 → 相机坐标系的变换矩阵 -
data_tracking_image_0:每帧一张图片(左摄像头),用于视图合成、深度预测等。
-
data_tracking_image_03:每帧一张图片(右摄像头),主要用于立体视觉(stereo matching)任务。
-
data_tracking_oxts:GPS/IMU 测量数据,提供每帧的位置信息(经纬度)和姿态(角速度、加速度等),有助于时序建图。
-
data_tracking_velodyne:激光雷达点云数据,每帧一个
.bin文件,内含 3D 点云数据(x, y, z, 强度)。 -
kitti-step:每张RGB图像的语义标签。
3、将所有内容提取到并保持数据结构./data/kitti
4、从 Velodyne 点云生成深度图:PYTHONPATH=. python scripts/create_kitti_depth_maps.py --kitti_sequence 0006,其中PYTHONPATH=.是将告诉 Python:“请把当前目录(.)当作模块根目录来搜索 suds 包”。
5、(可选)从语义标签生成天空和静态掩码(由于suds没有提供0006序列场景的语义标签数据(kitti-step/train中没有0006序列),所以没有执行这一步,并没有生成天空和静态掩码):python scripts/create_kitti_masks.py --kitti_sequence $SEQUENCE
6、创建元数据文件:PYTHONPATH=. python scripts/create_kitti_metadata.py --config_file scripts/configs/kitti-06.yaml,生成一个autodl-tmp/suds/metadata文件夹,下面保存有kitti-06.json文件。将 KITTI 每帧图像、相机姿态、光流、深度图等信息组织成结构化 metadata,并保存成 JSON 文件,供 SUDS 在训练阶段加载。
7、Extract DINO 功能:
-
先运行
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:64,防止爆显存,在运行PYTHONPATH=. python scripts/extract_dino_features.py --metadata_path metadata/kitti-06.json或用于多 GPU 提取python -m torch.distributed.run --standalone --nnodes=1 --nproc_per_node $NUM_GPUS scripts/extract_dino_features.py --metadata_path $METADATA_PATH。 -
PYTHONPATH=. python scripts/run_pca.py --metadata_path metadata/kitti-06.json,运行这个文件,对提取出来的高维 DINO 特征进行降维(PCA),以便后续训练中减少内存开销、提高效率。(修改了对应的run_pca.py文件)
8、先运行export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:64,防止爆显存,提取 DINO 对应关系:PYTHONPATH=. python scripts/extract_dino_correspondences.py --metadata_path metadata/kitti-06.json或用于多 GPU 提取python -m torch.distributed.run --standalone --nnodes=1 --nproc_per_node $NUM_GPUS scripts/extract_dino_correspondences.py --metadata_path $METADATA_PATH,该条命令运行时间较长。
9、(可选)生成用于可视化的特征集群:python scripts/create_kitti_feature_clusters.py --metadata_path $METADATA_PATH --output_path $OUTPUT_PATH。这一步对所有图像特征做 K-Means 聚类,提取“原型中心(feature clusters)”,在某些实验中可用来引导聚类损失或原型增强。
3、训练
值得注意的是--pipeline.feature_clusters后跟的不是create_kitti_feature_clusters.py生成的文件夹。--pipeline.feature_clusters 参数它的作用是告诉 SUDS 模型是否启用预处理的 PCA 特征作为训练输入。如果你执行了 run_pca.py,每帧图像的 DINO 特征 .pt 被转换成了 .parquet,设置 --pipeline.feature_clusters true 后,训练时将 从 .parquet 文件读取 PCA 后的特征,而不是从 .pt 文件加载原始的高维 DINO 特征。
将autodl-tmp/suds/data/suds_datamanager.py中train_num_rays_per_batch: int 由4096改为 512,可以把时间从2天 ⼤⼤减⼩为 6个⼩时。
#用于优化 PyTorch GPU 显存分配策略的环境变量设置。PyTorch 默认会尽量 “预分配大块显存”,以减少频繁申请/释放造成的性能开销。下面一行命令是将 PyTorch 内存池中能“单次分配的最大内存块”限制为 64MB,这样就避免 PyTorch 去分配“过大的连续显存块”,从而 降低碎片风险、减少 OOM(Out of Memory) 错误。 export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:64 PYTHONPATH=. python suds/train.py suds --experiment-name kitti_0006 --pipeline.datamanager.dataparser.metadata_path metadata/kitti-06.json
训练过程遇到:
OSError: Could not find compatible tinycudann extension for compute capability 80.
该错误说明 tiny-cuda-nn 不能在你当前使用的 GPU 上运行,因为它缺少为该显卡“计算能力(compute capability)= 8.0” 编译的扩展。当前的 GPU 是 NVIDIA A100,它的 compute capability 是 8.0,但当前 tiny-cuda-nn 安装版本可能:
-
没有预编译支持 compute 8.0;
-
或者没有正确为你机器的 CUDA 环境编译。
解决tinycuda-nn的问题:
# 删除已安装版本(如果有) pip uninstall tinycudann -y # 重新 clone 项目 cd ~/autodl-tmp/ git clone https://github.com/NVlabs/tiny-cuda-nn.git cd tiny-cuda-nn # 重新编译,指定当前 GPU 架构(compute 80 是 A100 的架构) export TCNN_CUDA_ARCHITECTURES=80 # 安装绑定模块 cmake . -B build
进行编译时报错:
CMake Error at CMakeLists.txt:23 (cmake_minimum_required): CMake 3.18 or higher is required. You are running version 3.16.3
tiny-cuda-nn 编译要求 CMake ≥ 3.18,而当前的版本是 3.16.3。
🔗 点击下载 CMake 3.25.2 安装包(Github)然后将该 .sh 文件上传到 AutoDL的根目录~/下,然后:
#手动创建该目录 mkdir -p ~/cmake-3.25.2 #确认是否有写权限 touch ~/cmake-3.25.2/test.txt && echo "✅ 有权限" || echo "❌ 无权限" #运行安装脚本 ./cmake-3.25.2-linux-x86_64.sh --skip-license --prefix=$HOME/cmake-3.25.2 #然后设置路径 export PATH=$(pwd)/cmake-3.25.2-local/bin:$PATH #查看cmake版本是否正确,需要大于3.18版本 cmake --version
至此Cmake版本问题已被解决。
继续利用Cmake编译tiny-cuda-nn:
~/autodl-tmp/tiny-cuda-nn# cmake . -B build #报错 CMake Error at CMakeLists.txt:49 (message): Some tiny-cuda-nn dependencies are missing. If you forgot the "--recursive" flag when cloning this project, this can be fixed by calling "git submodule update --init --recursive".
现在遇到的错误是:
❌
Some tiny-cuda-nn dependencies are missing原因是你在git clone的时候 没有加--recursive,导致子模块(尤其是cutlass等核心组件)没有被拉取
解决方案就说补全子模块,在 tiny-cuda-nn 项目目录下执行以下命令:
git submodule update --init --recursive
然后重新执行构建:
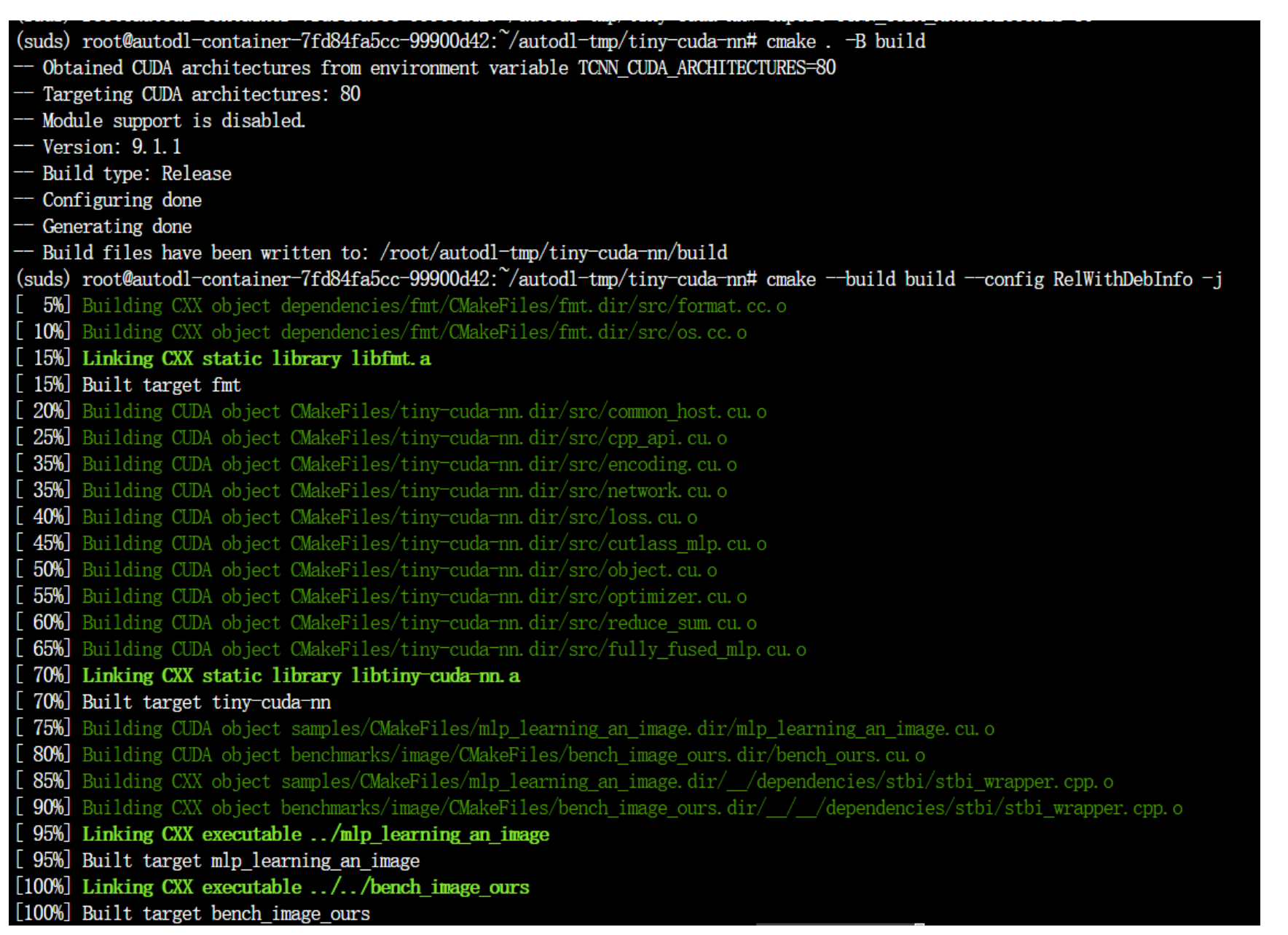
cmake . -B build cmake --build build --config RelWithDebInfo -j pip install ./bindings/torch
编译成功如下图所示:

在次运行SUDS的训练命令:
#用于优化 PyTorch GPU 显存分配策略的环境变量设置。PyTorch 默认会尽量 “预分配大块显存”,以减少频繁申请/释放造成的性能开销。下面一行命令是将 PyTorch 内存池中能“单次分配的最大内存块”限制为 64MB,这样就避免 PyTorch 去分配“过大的连续显存块”,从而 降低碎片风险、减少 OOM(Out of Memory) 错误。 export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:64 PYTHONPATH=. python suds/train.py suds --experiment-name kitti_0006 --pipeline.datamanager.dataparser.metadata_path metadata/kitti-06.json
又报错:
RuntimeError: Encoding 'SequentialGrid' not found
这表示你编译安装的 tiny-cuda-nn 版本 不包含 SequentialGrid 编码模块,而这个模块正是 SUDS 训练所依赖的。确实已经成功编译并安装了 tiny-cuda-nn,但这个版本是从 官方仓库 克隆的 main 分支,并不包含 SUDS 自定义的扩展模块。
所以你现在需要做的是:
#先卸载当前版本 pip uninstall tinycudann -y #重新 clone 正确分支,并安装 cd ~/autodl-tmp rm -rf tiny-cuda-nn # Clone 带有 SequentialGrid 的 SUDS 专用分支 git clone https://github.com/hturki/tiny-cuda-nn.git -b ht/res-grid cd tiny-cuda-nn git submodule update --init --recursive # 指定你的 GPU 架构(A100 是 80) export TCNN_CUDA_ARCHITECTURES=80 # 构建 & 安装 cmake . -B build cmake --build build --config RelWithDebInfo -j pip install ./bindings/torch
然后运行以下代码验证是否包含 SequentialGrid:
python -c "import tinycudann as tcnn; print(tcnn.network_encoding_names())"
在次运行SUDS的训练命令:
#用于优化 PyTorch GPU 显存分配策略的环境变量设置。PyTorch 默认会尽量 “预分配大块显存”,以减少频繁申请/释放造成的性能开销。下面一行命令是将 PyTorch 内存池中能“单次分配的最大内存块”限制为 64MB,这样就避免 PyTorch 去分配“过大的连续显存块”,从而 降低碎片风险、减少 OOM(Out of Memory) 错误。 export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:64 PYTHONPATH=. python suds/train.py suds --experiment-name kitti_0006 --pipeline.datamanager.dataparser.metadata_path metadata/kitti-06.json
训练完成之后运行下述命令进行评估:
#单个GPU PYTHONPATH=. python suds/eval.py --load_config outputs/kitti_0006/suds/2025-05-23_141128/config.yml --output-path outputs/kitti_0006/suds/2025-05-23_141128/eval

















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









