



1、NeRF 是做什么的
通过使用稀疏的输入视图优化底层的的连续辐射体积场函数,实现复杂场景的新视角合成
2、为什么nerf叫做神经隐式的三维重建
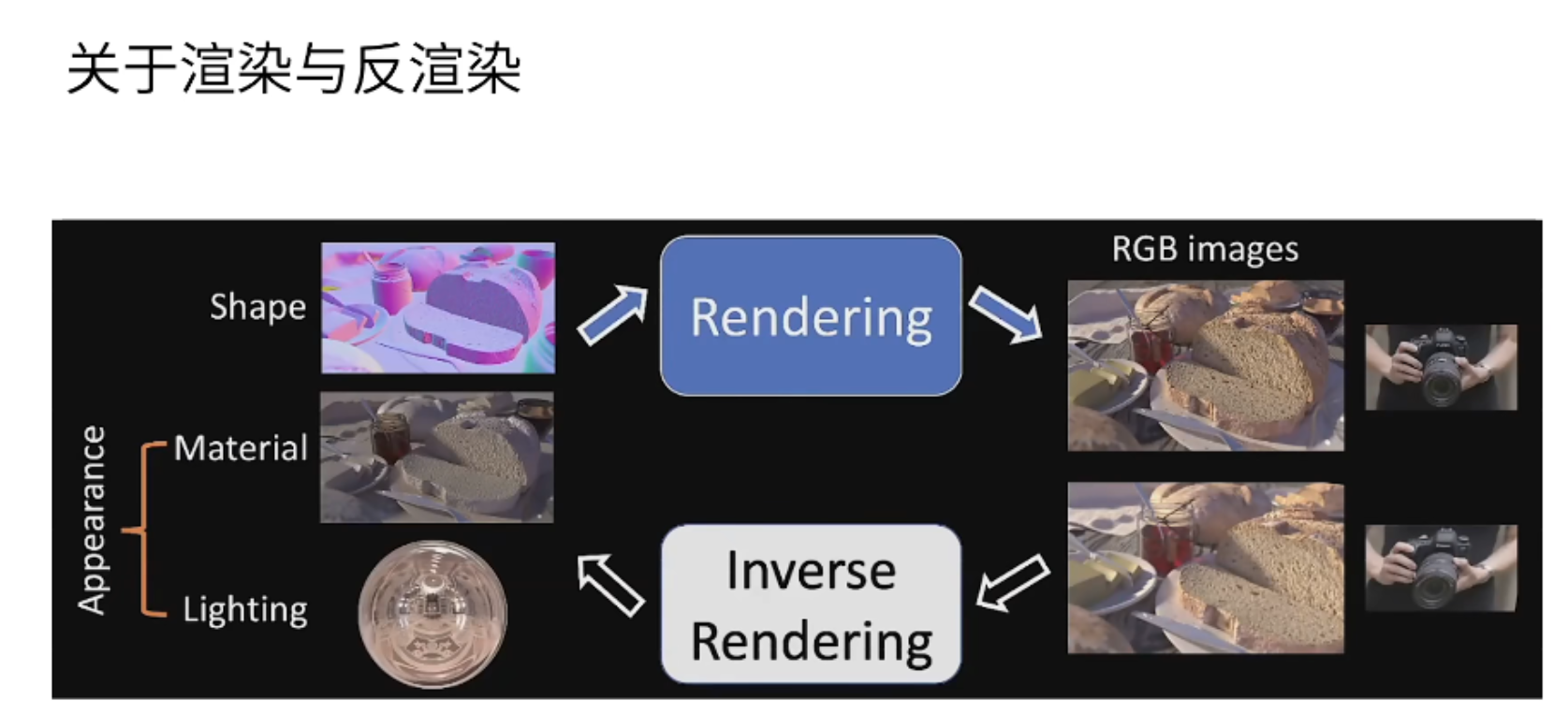
为什么Nerf叫做神经隐式的三维重建?这要从计算机图像学领域的渲染说起,渲染方式是基于三维模型的材质以及光照信息,通过一个视角将物体渲染成比较精美的画面,也就是上图的rendering内容。计算机图形学还有一个反渲染的过程,也就是上图的inverse rendering过程,也叫做三维重建,主要是通过渲染后的图片重新得到我们的三维模型,最后的三维模型是用体素、网格或者点云来表示的。Nerf也是三维重建中的一种,只不过它与以前的三维重建不同,以前都是基于多张图片,就可以恢复出点云、网格或者体素的模型,将三维模型的信息存储在点云、网格或者体素中,而Nerf是基于一种神经隐式网络去获得三维模型的,将三维模型的信息存储在隐式神经网络中。
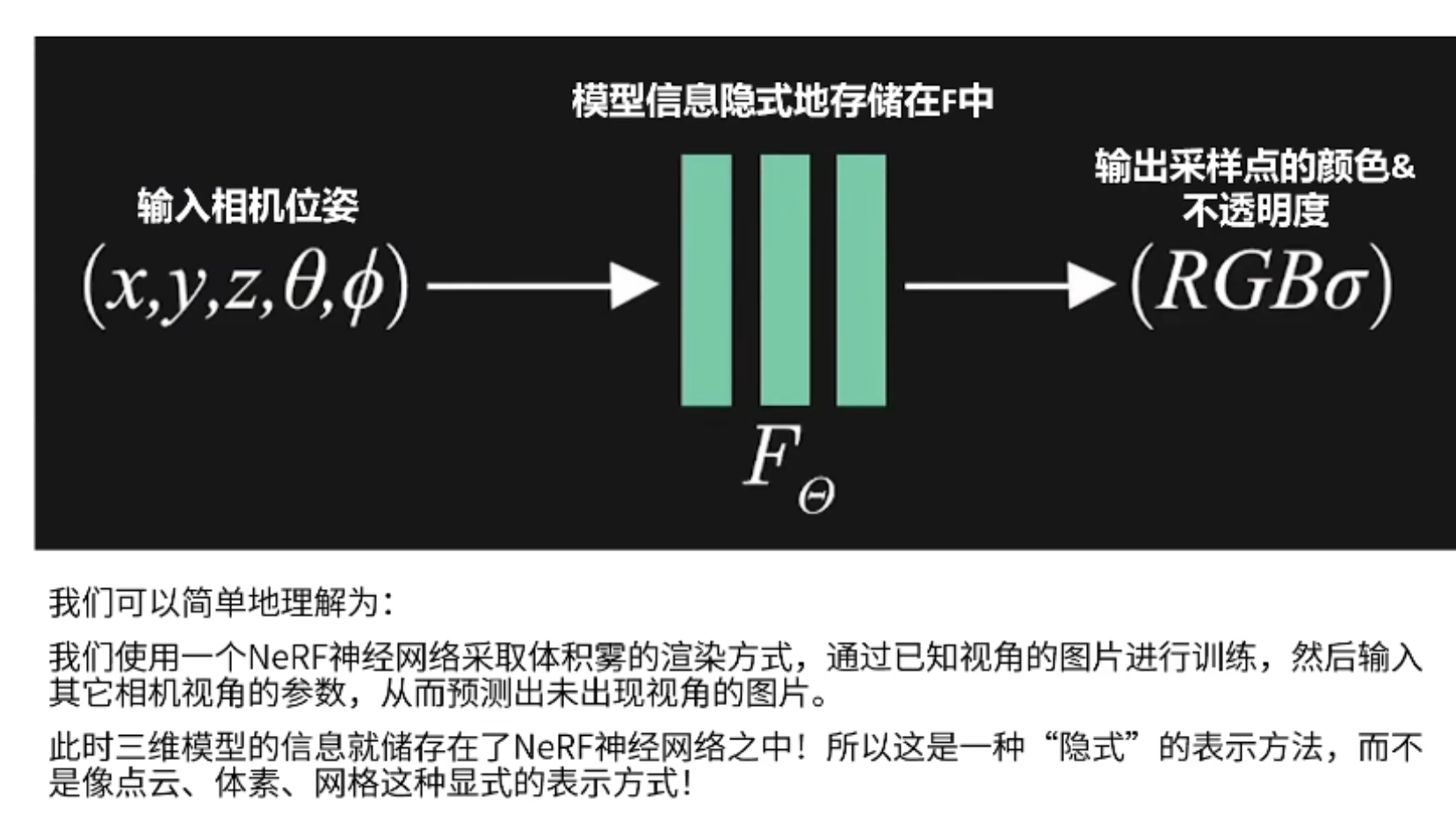
那么说明叫做神经隐式?上图可以很明显的看出,由于将物体的三维信息都存储在神经网络中,所以叫做神经隐式。Nerf的输入是每个采样点的位置(x,y,z),以及相机的方向参数(θ, φ),输出是采样点的颜色RGB和密度 σ。也就是或通过输入采样点的位置以及相机的相关参数,经过Nerf神经网络的一个训练,就可以得到一张未知视角的图片。这一过程也说明了Nerf的工作原理,就是利用Nerf神经网络的体积雾渲染方式,通过对已知视角的图片进行训练,然后在输入其他视角的参数,最后就可以得到未知视角的图像,此时的三维模型信息存储在神经网络中,不像点云、网格和体素那种显示的表示方式。
这里有一个很重要的问题就是一个Nerf神经网络只对应一个三维模型或者三维场景。现今很多的研究者都致力于研究多个三维模型的Nerf,但是最原始的Nerf神经网络只能与三维模型一一对应,也就是一个Nerf神经网络只能存储一个三维模型的信息,因此如果需要得到新的三维模型,就要重新进行训练。
一个图像在计算机内都是有分辨率的,例如64x64,就意味着这个图象有4096个像素值,那么从相机上每个像素点对应的位置发出一条射线,也就是这个像素点的光线,穿过世界坐标系的三维场景,形成一系列的采样点,然后再将每个采样点的位置(x,y,z),以及相机的方向参数(θ, φ)进行输入,进行Nerf神经网络的训练之后,就会得到这个采样点的颜色RGB和密度 σ,最后通过体积渲染技术,将这条光线上采样点的RGB、 σ进行合成,决定最终像素点的成像。
注意采样点的位置(x,y,z),以及相机的方向参数(θ, φ)都是可以通过相机位姿计算获得。基于相机位姿得到的采样点就像是点云或者体素,只不过是基于相机特定角度获得的一组点,而不是散落在空间中固定的点。
3、Nerf的输入输出
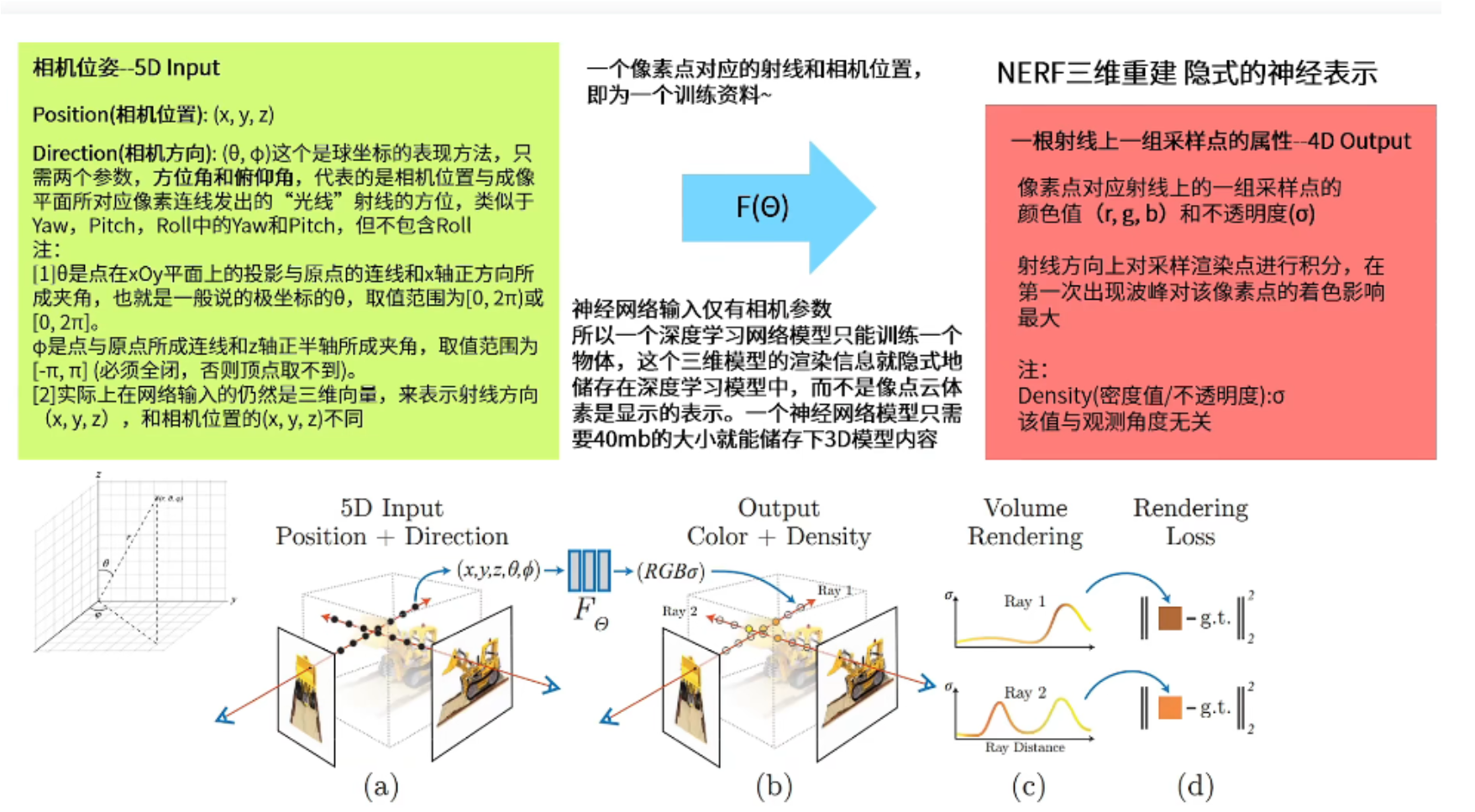
Nerf的输入是采样点的位置(x,y,z)和相机的方向(θ, φ),其中θ是相机的仰角, φ是相机的方向角,(θ, φ)是极坐标的形式,且它们虽然取值范围是角度,但是最终在代码里面的体现仍然是三维的方向向量。输入经过网络之后的目的就是将已知视角的图片的成像内容进行输出,并将三维信息存储在神经网络中,这个神经网络仅仅只有40M就可以存储一个三维模型的信息。在训练的过程当中是将一个像素点对应的一条射线,以及相机的方向作为一个训练资料,而不是以整张图片作为训练资料,所以在一个训练集中包含着多个不同地方的像素点及射线和不同地方的相机位置,所以Nerf是以像素点的层级作为训练资料,而不是图片。最后输出的是颜色RGB和不透明值 σ,这里是针对于一组采样点的颜色RGB和不透明值 σ,而不是直接输出像素点的颜色RGB和不透明值 σ,Nerf会取每个像素点发出的射线上的一段范围上的采样点(代码中far和near指所能取的最远范围和最近范围),然后得到一组采样点的颜色RGB和不透明值 σ后对其积分,得到最后像素点的颜色RGB和不透明值 σ,这个过程可以看作是图中的c、d过程,也就是Nerf体积雾渲染的过程,所以最后的三维模型就有点雾状,总之就是通过对多组采样点的操作,最后才将整个物体拟合出来。
4、位置编码
注意采样点的位置=相机的出发点+距离(采样点里出发点的距离)*相机方向

位置编码是为了突出图片的高频(边缘轮廓)信息,提高图片的细节质量,使得高频信息不会因为周围像素的平滑的影响。上图可以看出加了位置编码和不加位置编码图片的明显区别,每个位置编码都是由sin和cos两项组成的,上图是sin的图,可以看到它可以进行特征的增强。其中对于空间位置,是利用20维的位置编码分别对(x,y,z)三个方向进行特征增强,那么每个方向就不是单纯的一维描述位置信息,而是21维,一共63维;对于相机方向,是利用8维的位置编码分别对相机的方向(θ, φ)的两个参数的方向向量进行特征增强,那么每个方向向量就不是单纯的一维描述位置信息,而是9维,一共27维。
5、Nerf的网络结构
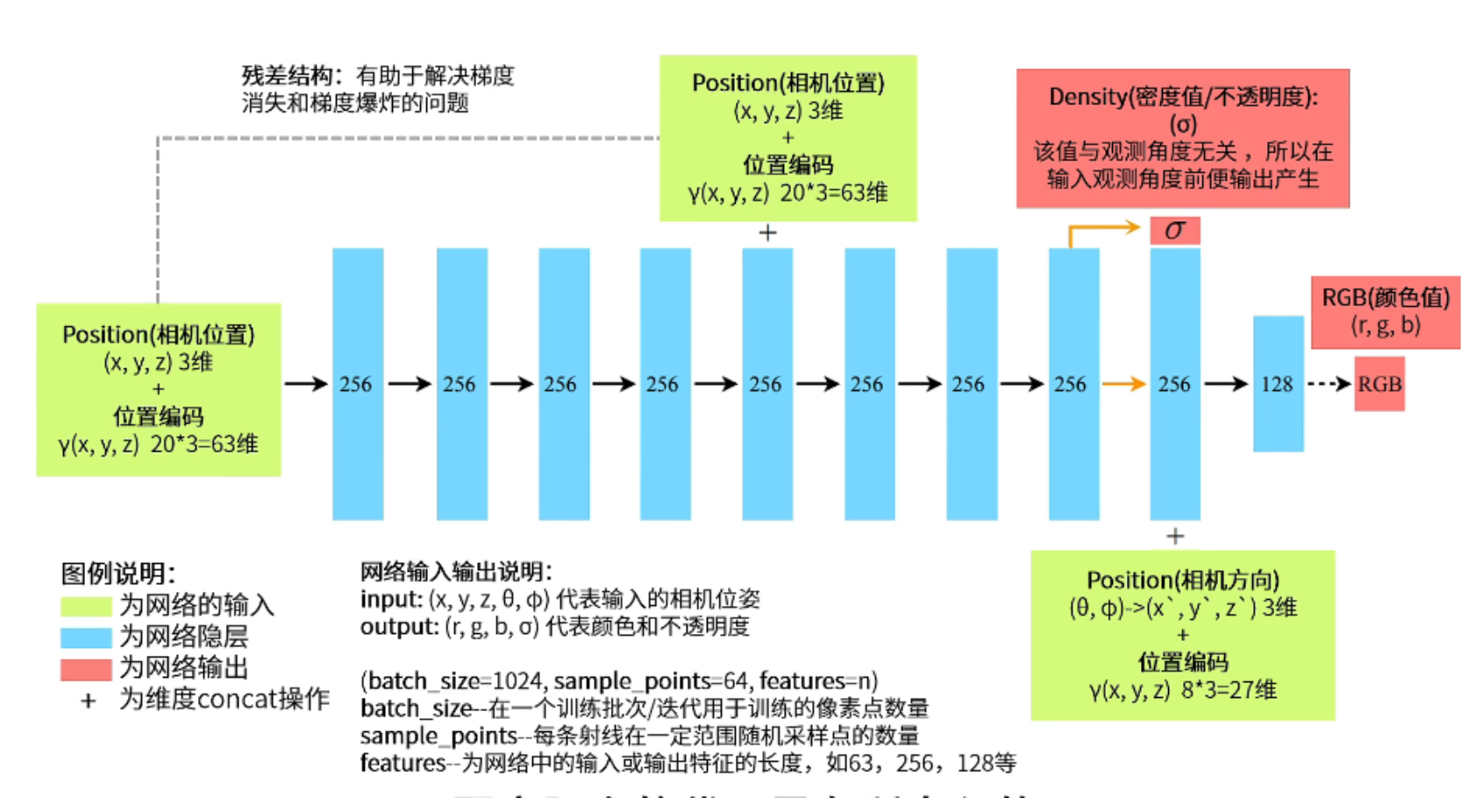
上图是Nerf的网络结构,这与原文的图有一点不一样,因为原文的图与它的代码有点出入,所以进行了细微的修改,并加入了位置编码。首先将采样点的坐标(x,y,z)以及它的位置编码作为输入(63维=20+20+20+3),这里没有相机方向参数(θ, φ),是因为Nerf会首先输出σ,而σ与相机的方向无关。然后进入Nerf的隐藏层,将63维变为256维,经过4个隐藏层之后,加入残差结构(加入63维的采样点坐标(x,y,z)以及它的位置编码),为了防止梯度消失和梯度爆炸,然后在经过4个隐藏层(319维变256维)输出不透明值σ和256维隐藏层,然后256维隐藏层再加上相机方向参数以及它的位置编码(27维=3+8+8+8),最后输出128维的隐藏层,最后转换为RGB。注意batch_size是指像素点个数,sample_points是每个像素点射线上的采样点的个数,features表示的是特征程,也就是输入部分的维度。
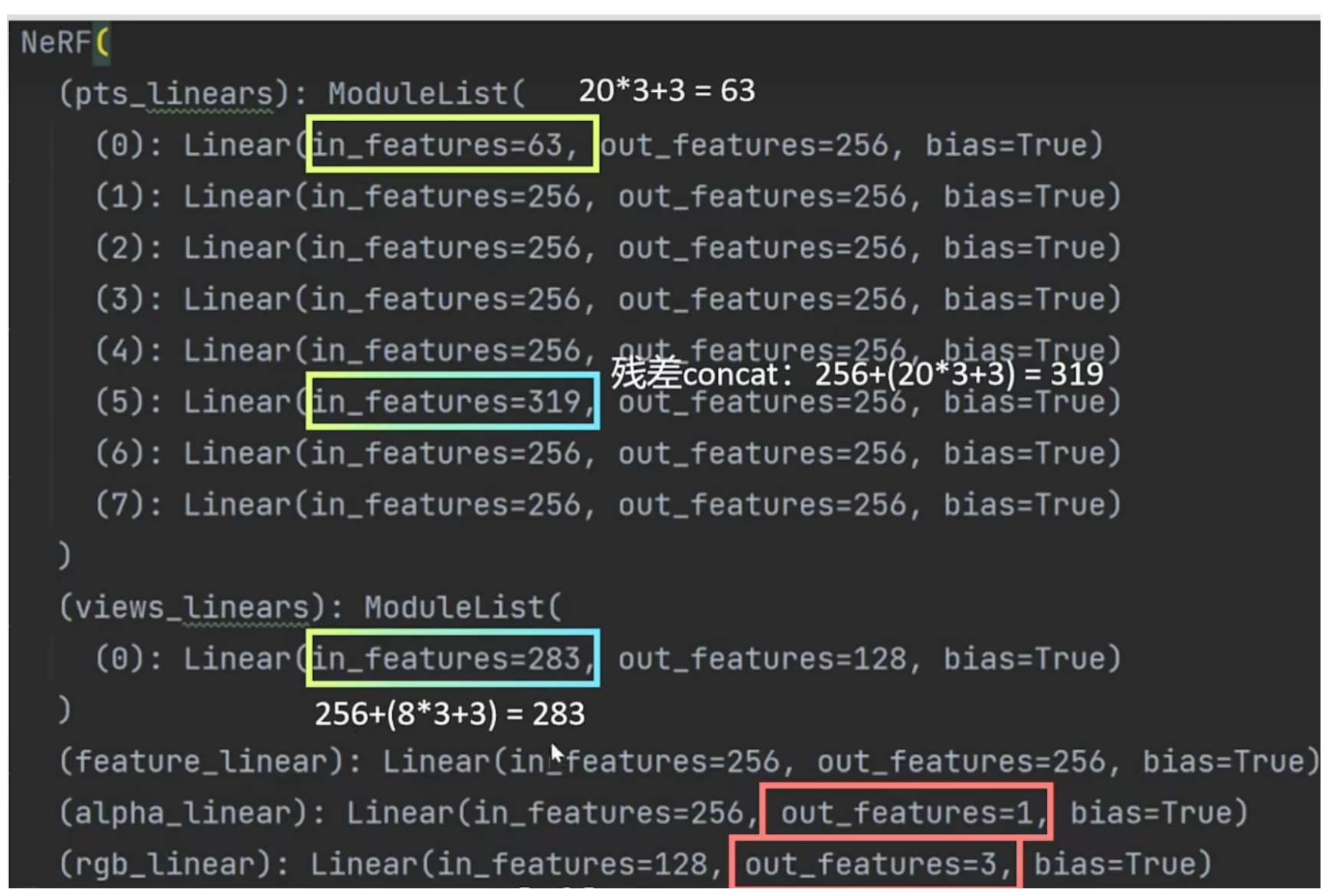
上述代码部分可以清晰的看到Nerf网络结构图中维度的变化,首先是输入层63维度,然后是到了第5个隐藏层,加入残差结构,形成256+63=319维度的隐藏层,然后恢复到256维度,然后是隐藏层加上相机方向参数,以及它的位置编码得到283维的隐藏层,最后是输出1维度的 σ值和3维的RGB值。
6、Nerf相关的数学公式

sample_points一般规定为64个点,那么这64个点如何处理呢?64个点其实就是体积渲染的一部分,里面有透明的部分,也就是空气,当它接触到物体就会变得不透明,其σ值就会升高,就像Ray1一样,但是当光线穿过一个物体的时候会有两个较高的σ值,因为物体有前面和背面,就如Ray2。但是在成像中,我们只希望出现前面的值,所以在计算的公式中主要是计算第一个波峰的值。所以Nerf只要输入一组图片,去训练一个网络,这个网络就可以存储这个模型的信息了,然后在输入另一个视角的参数,就可以获得另一个视角的成像了。
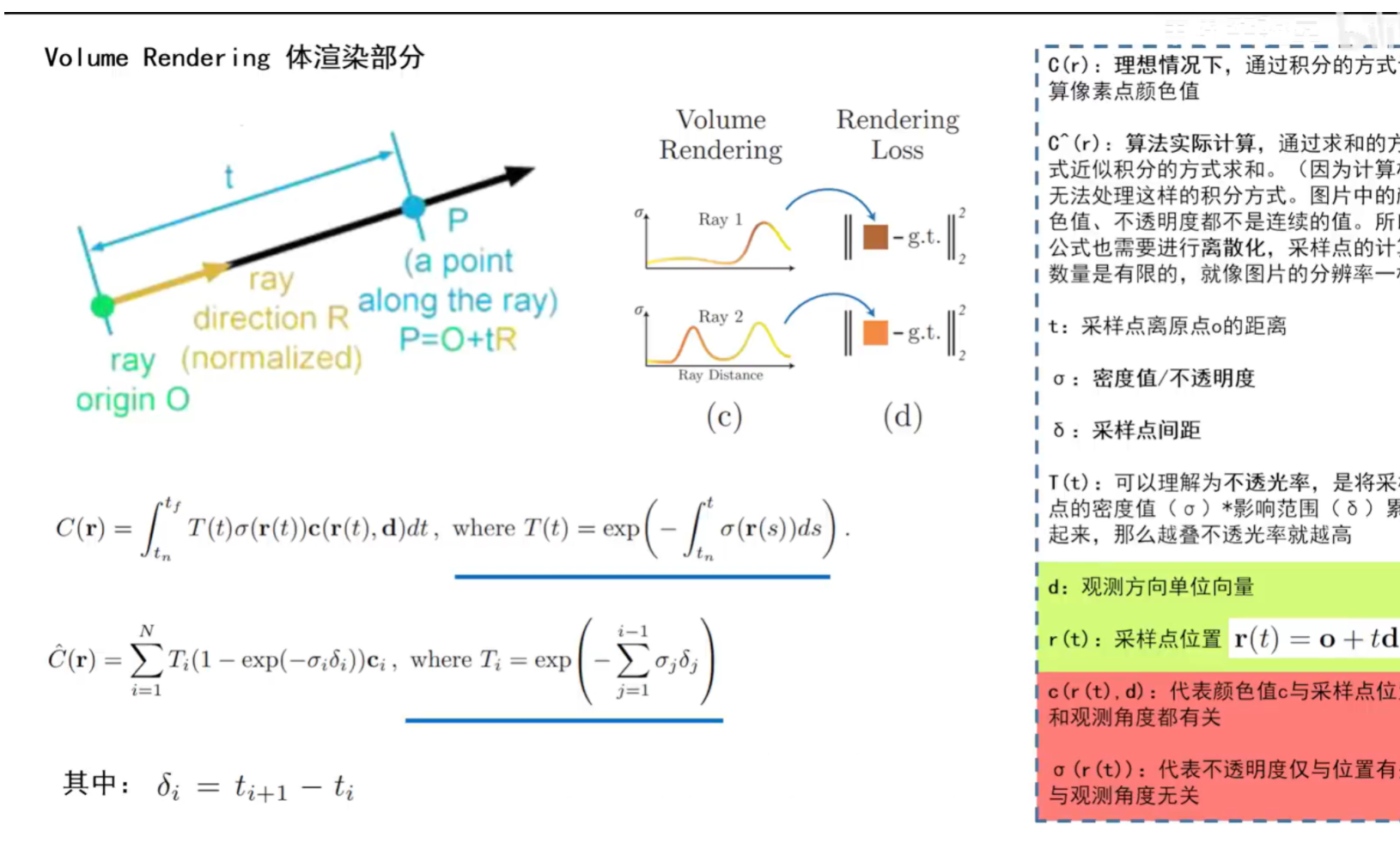
如何将采样点的颜色和密度值应用到图片像素点的颜色当中去(Nerf最终得到的是新视角图像,而不是三维模型)。首先看采样点如何获得,它是通过相机的位姿经过简单的数学运算r(t)=o+td获得的,其中o是相机出发点,t是采样点离出发点的距离,d是相机方向。r(t)就是采样点的位置。那么有了采样点的位置以及相机方向参数之后,就可以获得采样点的颜色和密度值,那么如何将这个颜色和密度值应用到图像的像素点上面去?首先看到第一个公式C(r),该公式是理想情况下的,其中的T(t)是指不透光率,也就是不透明值(σ)*影响范围(δ),其中影响范围也是用积分表示的,然后累加,越叠加不透光率就越高,T(t)想要强调不透光物体的前面,而不是背面;σ(r(t))是指只与采样点位置有关的密度值;c(r(t),d)是指与采样点位置和相机方向都有关的颜色值,然后将这些值相乘后进行积分来求得图像像素点的颜色值。而现实情况中不可能对这些公式进行积分,因为采样点是离散的,不是连续的,因此利用一个近似积分的求和来求解C^(r),其中对应的地方进行了替换,如T发生了变换,变成两个值相乘,因为积分本来也是面积,虽然发生了变换,但是C(r)与C^(r)表示的意思是一样的。那么这个公式就可以理解为,利用近似于积分的求和操作,完成了体渲染过程,由一组采样点的输出值,得到图片像素点的颜色。
7、采样点的合理性
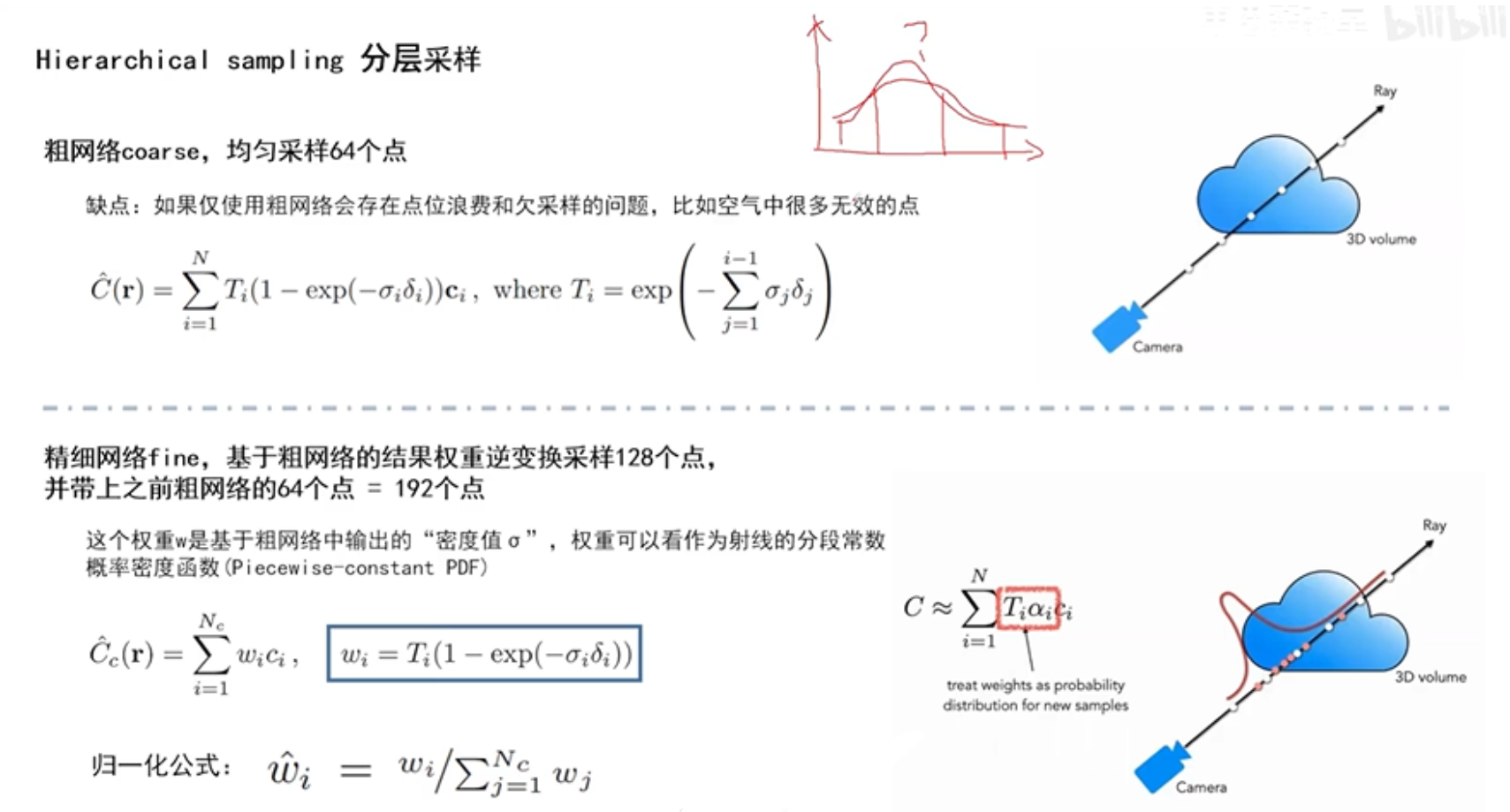
采样点如何采取才是合理的,他们的间距应该怎样分布?如右上角的图,如果是这样取采样点的话,物体的边缘部分大部分没有采集到,相反空气中却用了很多采样点,这样是很浪费的,并且最终模型效果会很差。所以Nerf在代码中提出了分层采样,分为粗网络和精细网络两步,首先在粗网络中,采用均匀采样的方式采样64个点,然后利用公式
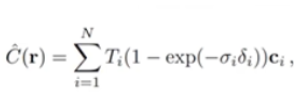
,其中的
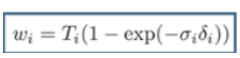
会产生权重值,也就是不透明值大的,权重也会大一点。然后精细网络会利用粗网络得到的权重值,进行逆变换采样,取128个点,权重值大的采样点就分布多一点,权重值小的就分布少一点,所以一共取了128+64=192个点
8、Nerf的损失函数

Nerf的损失函数很简单,就像素点的计算的密度值和颜色值与理想情况下像素点的计算的密度值和颜色值分别在粗网络和精细网络中的差值进行相加。

















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









