






面试流程
1.自我介绍
2.问论文和项目经历
(问的比较细节,接近12min的问答时间,面试官感兴趣的地方都会问,主要应该还是考察逻辑表达能力)
3.深度学习底层问题
- focal loss是什么(没答上来)
- bn层的作用,batch normal和layer normal的区别
- 损失函数设计:分类交叉熵、回归mse
- 简述一下目标检测的一个框架:RCNN
- 基础评价指标:准确率、精确率、召回率的区别;论文中使用的指标(AUROC),为什么用这个
- 为什么会出现梯度消失或梯度爆炸
- 简述一下transformer的框架
对应的答案记录一下:
1.focal loss:
Focal loss是最初由何恺明提出的,最初用于图像领域解决数据不平衡造成的模型性能问题。
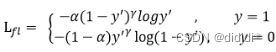
具体还是涉及到目标检测,负样本数量远大于正样本数量所导致的不平衡,最早RCNN用SVM解决的问题,后面为了改成一阶段网络,也会考虑这个问题,所以就修改了传统的交叉熵。(作者不是研究目标检测领域,后面学习了再详细解释吧)
具体论文参考:https://arxiv.org/abs/1708.02002
2.bn层的作用:约束网络中参数的规模,防止梯度过大,加快网络的收敛。
batchnormal(BN):传统卷积网络中使用的normalization形式,在数据B这个维度进行normal,相当于(B,C,H,W)的数据,在B维度上求均值方差,mu为(1,C,H,W),然后再做变换,归一化处理。
layernormal(LN):为了解决两个问题:(1)自然语言处理中,每个batch的数据长度不一样,batchnormal只能把那些缺失的维度设为0,相当于没有起到归一化的作用;(2)batch的值如果太小,效果也不好。LN相当于在网络的神经元输出进行归一化,对每一个样本的C维度上求均值方差去变换。
3.分类任务使用交叉熵函数,回归任务使用均方误差函数
4.RCNN框架(后面系统学目标检测的时候,再出笔记吧)
5.准确率、精确率、召回率
(1)准确率
(2)精确率:预测的正类里,有多少预测对了
(3)召回率:所有的正类样本里,有多少预测对了
6.梯度消失和爆炸:
需要讲到反向传播的链式法则,也可以简单提一下resnet相关的东西。
4.排序算法了解多少:
简单排序:插入排序、选择排序、冒泡排序
分治排序:快速排序、归并排序
分配排序:桶排序、基数排序
树状排序:堆排序(必学)
其他:计数排序(必学)、希尔排序
(挖个坑,后面专门学一下排序,手撕一下算法)















 102
102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









