






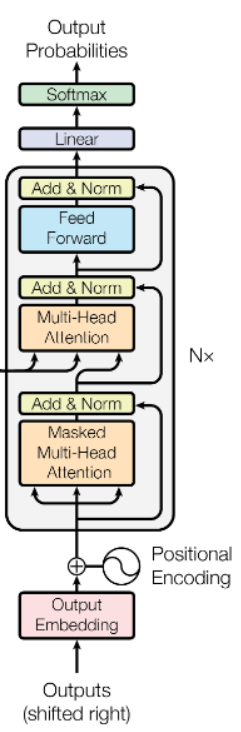
Transformer
1. Attention is all you need
- 传统的sequence trasduction models(序列传导模型)基于复杂的recurrent or convolutional(循环和卷积)神经网络,其中固定的循环模式限制了长序列的并行化和计算效率
- 这里引入注意力基础连接编码器和解码器,原始的自编码器的decoder将隐空间的z生成输出序列时会将先前的符号用作附加输入,tansformer取消递归和卷积。抛弃距离因素而选择依赖注意力机制关系来建模输入与输出之间的全局依赖关系
- 不同距离的关系只需要恒定数量的操作
- 尽管平均注意力加权对分辨率的减少利用多头注意力机制来抵消
Encoder and Decoder
Encoder
- 由N个stack(堆栈)组成,每个stack有两个sublayer,分别是橘色的多头注意力和蓝色的前馈连接层(1x1的卷积代替全连接层,两层映射关系加上中间的relu激活函数。输入和输出维度为512,中间层维度为2048。
- 每一个sublayer采用:
- 残差
- layernorm(在通道上的归一化)所有子层的输出channel都为512

Decoder:
1.改变了多头注意力的输出
2.在之前加入了mask之后的多头注意力(编码器输出的KV和解码器前面部分的Q。这允许解码器的每一个序列都参与输入序列的所有位置)
Muti-head计算过程
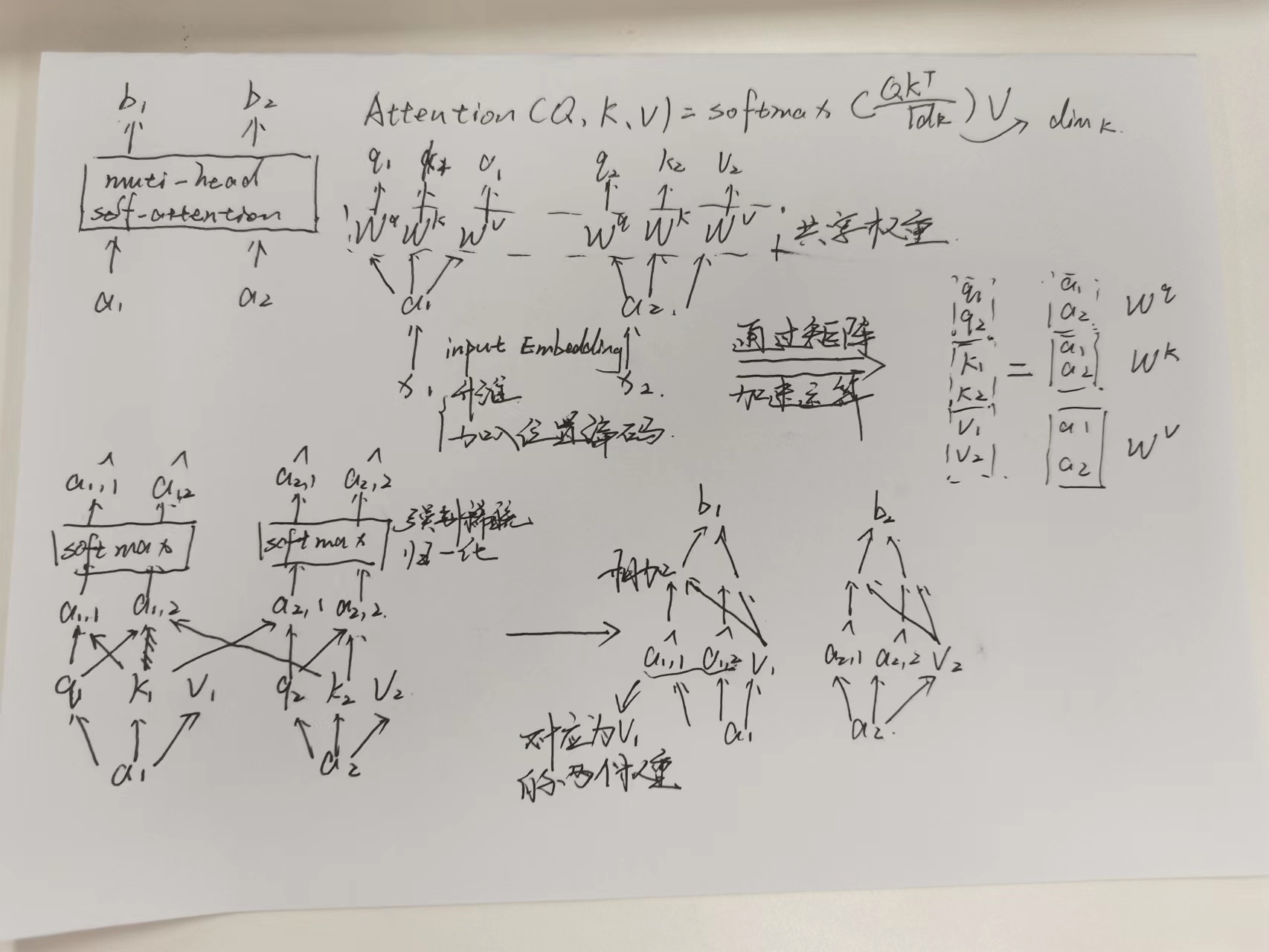
- 经过input embedding将序列数据升维并加入位置编码(这里采用固定的不频率的正余弦值)
- 利用一个全连接层输出QKV,他们共享一个权重
- 在计算的过程中利用矩阵乘法来加速
- q1分别于其他的ki相乘,最后经过softmax得到相应的注意力权重
- 注意力分数与value相乘,得到最后的输出
- 针对muti-head,将q,k,v均分,分别加权到v求和之后再concat,以保证输出维度等于输入维度
- 为什么注意力机制里面需要除以根号dk
QKV三者都是输入数据X的线性变换。为了方便表示将三者假设为相同的行向量, Q Q T QQ^{T} QQT 可以表示两个向量之间的相似度且不存在上下文关系。出入向量q和k在每一维度都具有零均值和单位方差,那么 Q Q T QQ^{T} QQT 就是会扩大方差,除以 sqrt(dk)使得运算结果仍然保持零均值和单位方差。这是因为在方差变大之后,softmax的结果只会呈现最大值和最大值附近的值,而单位化方可以使得大部分的数据分布都被保留了下来,反向传播时梯度平稳。
Optimizer
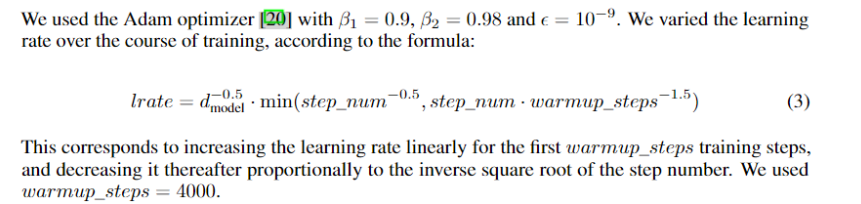
regularization
- dropout应用于输出层并添加到输入进行归一化
- label sommthing 0.1
2.Vsion transformer
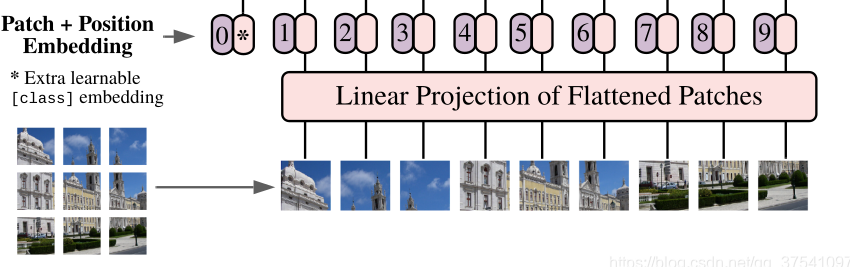
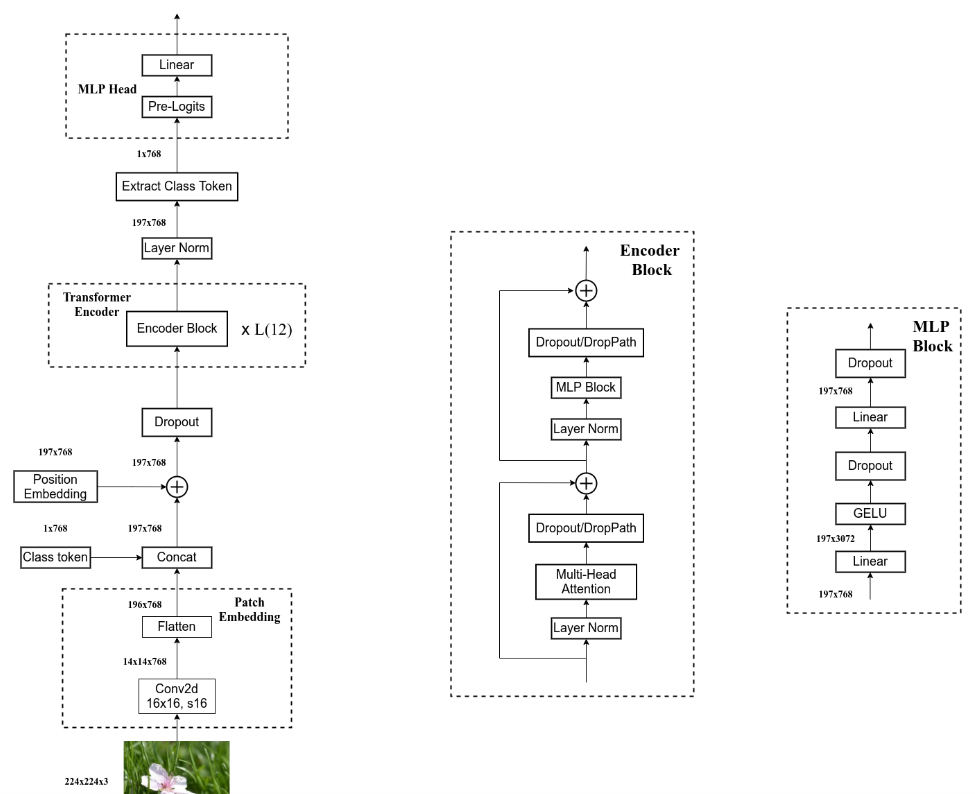
直接应用于图像序列的纯transformer的图像分类。简单而言,VIT由三个部分组成:
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder(图右侧有给出更加详细的结构)
- MLP Head(最终用于分类的层结构)
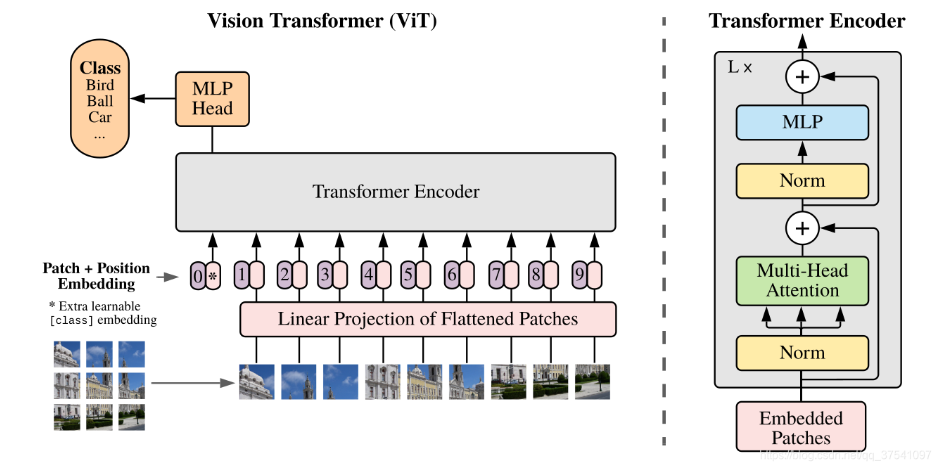
Embedding层
- 对于transformer来说,需要输入token序列 [token_num, token_dim]
- VIT中利用16x16的卷积,步距为16,卷积核为768的卷积来取不同的token。[224x224x3]->[16x16x768]->[196x768]。
- 在此基础上加入一个class token:Cat{([1,768],[196,768]) -> [197,768]}
- 每一个token加入一个可学习的位置编码 [197,768]->[197,768], 直接采用相加的操作
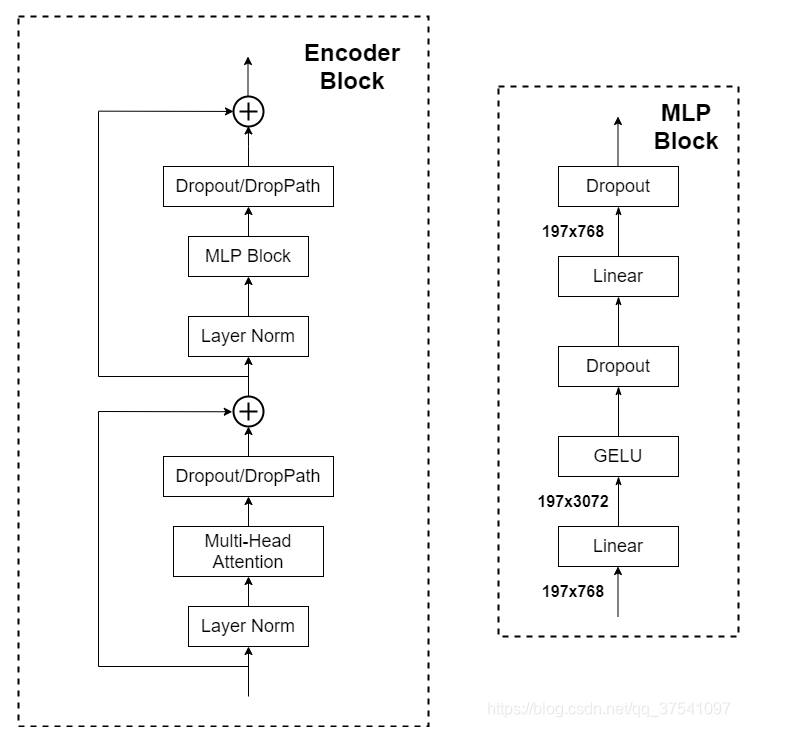
Transformer Encoder
- 重复堆叠L次的Encoder block
- layer normalization:对每个token进行norm处理,相比较与BN来说,更加关注每个token序列的子序列之间的关系,在channel维度上进行处理而不是在batch维度上进行处理
- droppath:dropout随即失活神经元会导致均值偏差,而norm操作需要均值稳定,直接选择失活权重值而不是神经元
- MLP Block,如图右侧所示,就是全连接+GELU激活函数+Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]
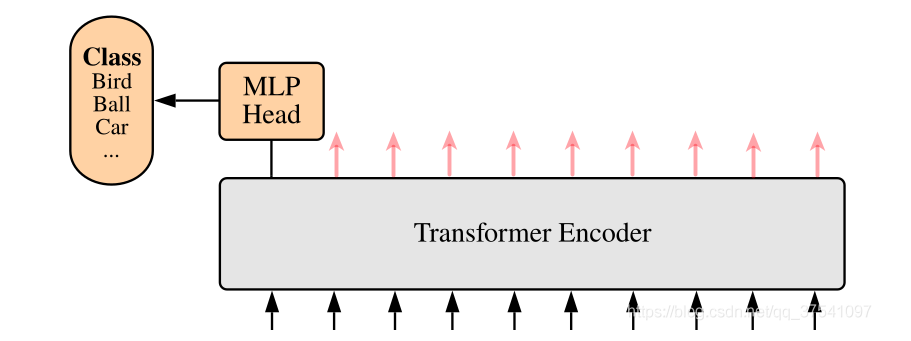
MLP Head详解
- 这里只关注分类信息,只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着通过MLP Head得到我们最终的分类结果。
代码部分
1.整体结构
def forward_features(self, x):
# [B, C, H, W] -> [B, num_patches, embed_dim]
# 首先将图片通kernel_size和步距为patch_size的卷积将其切开,再将H和W展平通过一个norm,最后将通道调整到最后一个维度
x = self.patch_embed(x) # [B, 196, 768]
# [1, 1, 768] -> [B, 1, 768]
# 将token在batch维度进行扩展更好的拼接
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
# 将token插入
if self.dist_token is None:
x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]
else:
x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)
# 加入位置编码
x = self.pos_drop(x + self.pos_embed)
x = self.blocks(x)
x = self.norm(x)
# 对应于一个Linear+tah将embed_dim变为需要的
if self.dist_token is None:
return self.pre_logits(x[:, 0])
else:
return x[:, 0], x[:, 1]
def forward(self, x):
x = self.forward_features(x)
if self.head_dist is not None:
x, x_dist = self.head(x[0]), self.head_dist(x[1])
if self.training and not torch.jit.is_scripting():
# during inference, return the average of both classifier predictions
return x, x_dist
else:
return (x + x_dist) / 2
else:
x = self.head(x)
return x
2.muti-attention
class Attention(nn.Module):
def __init__(self,
dim, # 输入token的dim
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop_ratio=0.,
proj_drop_ratio=0.):
super(Attention, self).__init__()
self.num_heads = num_heads
head_dim = dim // num_heads # 每一个head的dim
self.scale = qk_scale or head_dim ** -0.5 # 对应缩放因子根号d
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # 一次性qkv三个值来共享权重
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.proj = nn.Linear(dim, dim) # 将muti-head的结果cat拼接,这里直接通过全连接层来实现(对应于原文的W0,让输出更好的融合)
self.proj_drop = nn.Dropout(proj_drop_ratio)
def forward(self, x):
# [batch_size, num_patches + 1, total_embed_dim]
# +1是为了token
B, N, C = x.shape
# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim] # 生成所需要的qkv
# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head] # num_heads*embed_dim_per_head=total_embed_dim
# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# 将3换到第一位只是为了更好的计算
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# shape:[batch_size, num_heads, num_patches + 1, embed_dim_per_head]
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]
# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]
attn = (q @ k.transpose(-2, -1)) * self.scale
# 针对每一行的数据进行softmax处理
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]
# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]
# reshape: -> [batch_size, num_patches + 1, total_embed_dim]
# 将每个head对应位置上的结果拼接在一起
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
- 对于pytorch中的两大转置函数
torch.transpose和torch.permute两个函数都可以操作转置,前着只能进行两个维度的转置,后者需要说明所有位置进行多个位置的转置。每次在使用view()之前,该tensor只要使用了transpose()和permute()这两个函数一定要contiguous().
3. Swin-transformer
框架结构
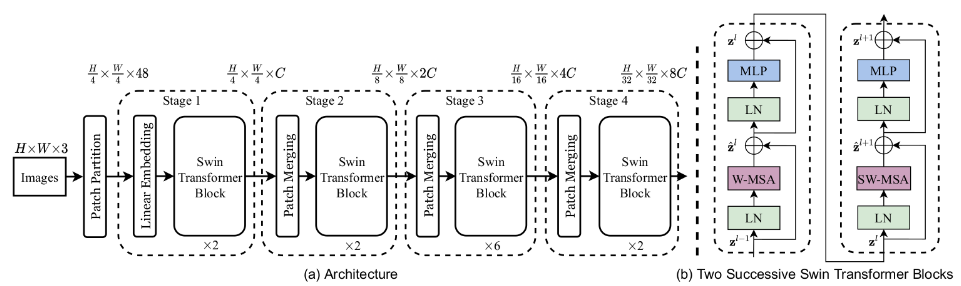
- 首先将图片输入到Patch Partition模块中分块为4X4的大小,在经过linear embedding压缩通道,源码中直接使用一行卷积实现
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)
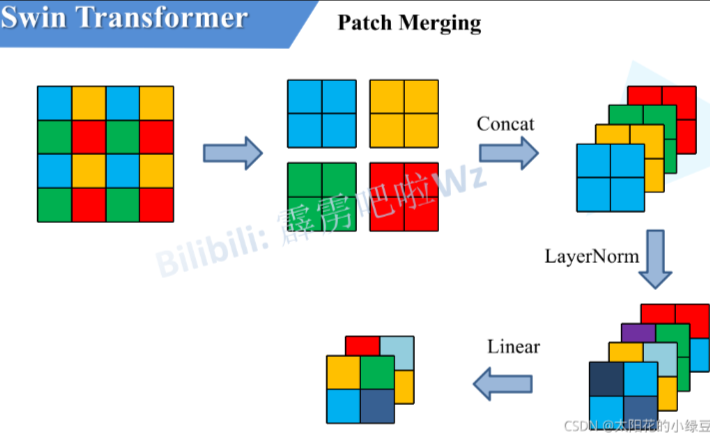
- 主题部分利用四个Stage构建不同大小的特征图来构建出有层性的整体,每层通过perch merging来压缩大小,把patch理解为像素点,224 * 224的图片分成14 * 14个16 * 16 的patch实际上就是下采样了16倍,扩大感受野,每次下采样宽度和高度将会缩减一半,但是通道增加四倍,再通过全连接层来压缩通道为上一层对两倍。
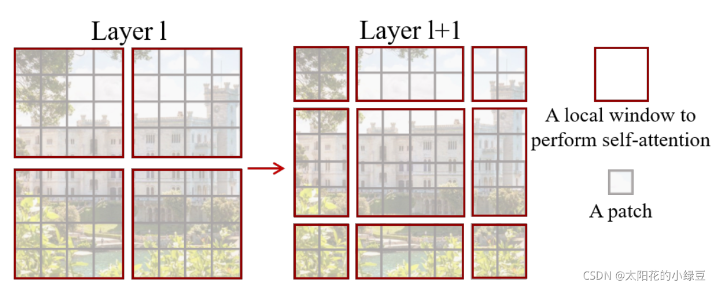
- 每次stage的数量为双数,分别对应W和SW改进的muti-head self-attention
W-MSA
传统的transformer将每一个token与其他所有token计算注意力分数,计算量巨大,将图像分割成windows减少计算量,只计算各个窗口内部的多头注意力大幅度减少计算量
SW-MSA
解决W-MSAwindows和windows之间无法进行信息传递
为了统一计算的尺度,将第一行移到最下面,左边第一行移到最左边,计算量实际上只增加了移动的部分。
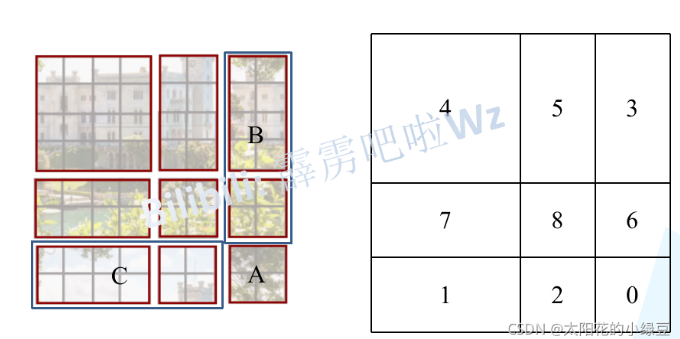
同时为老人防止不同区域的信息混淆,在计算的时候加入masked MSA,一次将不连续的地方赋值为很大的负数,那么接下来的softmax就会将这些值变为0
4.经典问题
- 多头注意力的优点
- 多头可以使参数矩阵形成多个子空间,矩阵整体的size不变,只是改变了每个head对应的维度大小,这样做使矩阵对多方面信息进行学习,但是计算量和单个head差不多。
- Transformer的并行化提现在哪个地方?
- Transformer的并行化主要体现在self-attention模块,在Encoder端Transformer可以并行处理整个序列,并得到整个输入序列经过Encoder端的输出,但是rnn只能从前到后的执行















 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









