







本文仅供参考
目录
任务说明
本届微博情绪分类评测任务一共包含两个测试集:第一个为通用微博数据集,其中的微博是随机收集的包含各种话题的数据;第二个为疫情微博数据集,其中的微博数据均与本次疫情相关。
任务描述如下:
微博情绪分类任务旨在识别微博中蕴含的情绪,输入是一条微博,输出是该微博所蕴含的情绪类别。在本次评测中,我们将微博按照其蕴含的情绪分为以下六个类别之一:积极、愤怒、悲伤、恐惧、惊奇和无情绪。

本次评测训练集包含上述两类数据:通用微博训练数据和疫情微博训练数据,相对应的,测试集也分为通用微博测试集和疫情微博测试集。参赛成员可以同时使用两种训练数据集来训练模型。
每条微博被标注为以下六个类别之一:neutral(无情绪)、happy(积极)、angry(愤怒)、sad(悲伤)、fear(恐惧)、surprise(惊奇)。
一、基于 Bert 的文本表示及文本分类方法
针对该评测任务,我们可以使用基于 Bert 的文本表示及文本分类方法对通用微博训练数据和疫情微博训练数据进行分类。
二、实验原理
(1)利用Bert模型对语句进行训练,从而得到该句子的向量表示。
(tip:其实主要就是如何把这些句子变成向量的形式)
(2)构建简单的神经网络模型,将获得的文本向量进行分类
(tip:当然这一步就是把第一步得到的句子向量进行分类,可以构建不同的神经网络模型,如RNN、全连接神经网络、GRU等)
三、具体步骤
1.构建句子向量
1.1导入库
代码如下:(当然有些没用到)
由于需要用到pytorch以及gpu加速(若没有gpu,也可使用cpu,只是速度慢点),所以需要安装pytorch环境,具体安装请参考:(一定得注意python版本和pytorch版本、gpu支持之间的兼容性,要不然不能成功。另外一般的gpu都支持pytorch,比如我的mx250,虽然官网上没有显示支持,但是也还是可以)(36条消息) 深度强化学习-Pytorch1.6环境配置_indigo love的博客-CSDN博客_base环境和pytorch环境![]() https://blog.csdn.net/weixin_46133643/article/details/122657023?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1.pc_relevant_default&spm=1001.2101.3001.4242.2&utm_relevant_index=3
https://blog.csdn.net/weixin_46133643/article/details/122657023?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1.pc_relevant_default&spm=1001.2101.3001.4242.2&utm_relevant_index=3
如果你使用的python软件是jupyter(建议使用jupyter),那还涉及python解释器更换,可以参考这篇文章:
import torch
from pytorch_pretrained_bert import BertTokenizer,BertModel,BertForMaskedLM,BertConfig
from sklearn import preprocessing
import math
import pickle
import re
import numpy as np
import gensim
from gensim.models import Word2Vec, KeyedVectors
import json
import jieba
from gensim.models.tfidfmodel import TfidfModel
from gensim import corpora
from sklearn.linear_model import LogisticRegressionCV, LogisticRegression
import zhconv
from sklearn import neighbors
#分类模型
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
# from sklearn.ensemble import AdaBoostClassifier
import time
from sklearn.decomposition import PCA
from sklearn.manifold import LocallyLinearEmbedding
from sklearn import datasets,decomposition,manifold
from sklearn.cluster import KMeans
from sklearn.cluster import MeanShift
from sklearn.mixture import GaussianMixture
from sklearn.cluster import SpectralClustering
import numpy as np
# %matplotlib inline
# %matplotlib notebook
# %matplotlib
import os
# os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import matplotlib.pyplot as plt
import torch
import torchvision.datasets as dsets
import torchvision.transforms as trans
import torch.nn as nn
from torch.optim import lr_scheduler
import time
import math
import torch.nn.functional as F1.2加载bert模型
import os
bert_path = r"D:/资料/浏览器下载的资料/bert-base-chinese"
bert_config_path = os.path.join(bert_path, r"bert_config.json")
bert_vocab_path = os.path.join(bert_path, r"vocab.txt")
bert_model_path = os.path.join(bert_path, r"pytorch_model.bin")# 加载模型配置
bert_config = BertConfig.from_json_file(bert_config_path)
# 加载中文词库
bert_vocab = BertTokenizer(vocab_file= bert_vocab_path)
# 加载模型
bert_model = BertModel.from_pretrained(bert_path)这里你可以去浏览器搜索下载,或者http://链接:https://pan.baidu.com/s/15LfGEBpqoIYR4ityxYXGGw 提取码:BE2T
这篇文章对你或许有帮助:https://blog.csdn.net/sdaujz/article/details/107547503![]() https://blog.csdn.net/sdaujz/article/details/107547503
https://blog.csdn.net/sdaujz/article/details/107547503
1.3读取数据
def get_data(filename):
d_one = []
file_one = open(filename,'r',encoding='utf-8')
#对txt进行遍历
for line in file_one:
d_one.append(json.loads(line))
d_one = d_one[0]
return d_one
#virus下的数据
# virus_train_data = get_data('C:\\Users\\86182\\Desktop\\训练验证和无标注测试\\train\\virus_train.txt')
# virus_eval_data = get_data('C:\\Users\\86182\\Desktop\\训练验证和无标注测试\\eval\\virus_eval_labeled.txt')
# virus_test_data = get_data('C:\\Users\\86182\\Desktop\\训练验证和无标注测试\\test\\virus_test.txt')
# # # virus_all_data = virus_train_data
# virus_all_data = get_data('C:\\Users\\86182\\Desktop\\训练验证和无标注测试\\train\\virus_train.txt')
#usual下的数据
usual_train_data= get_data('C:\\Users\\86182\\Desktop\\训练验证和无标注测试\\train\\usual_train.txt')
usual_eval_data = get_data('C:\\Users\\86182\\Desktop\\训练验证和无标注测试\\eval\\usual_eval_labeled.txt')
usual_test_data = get_data('C:\\Users\\86182\\Desktop\\训练验证和无标注测试\\test\\usual_test.txt')
# usual_all_data = usual_train_data
usual_all_data = get_data('C:\\Users\\86182\\Desktop\\训练验证和无标注测试\\train\\usual_train.txt')1.4获得向量
参数设置:
(max_seq_lenth最大为512)若句子长度超过max_seq_lenth,我采取截断的方法
device=torch.device("cuda")
max_seq_lenth=320get_label_txt()方法用来存储文件表示向量,因为获得它需要挺长时间(我花了3个小时 ┭┮﹏┭┮),为了节省时间,把它以json格式存储起来。
def get_label_txt(test_label,filename):
id_label = []
for i in range(1,len(test_label)+1):
id = {}
id['id']=i
id['vector']=test_label[i-1]
id_label.append(id)
# print(id_label)
json_label = json.dumps(id_label)
# print(json_label)
with open(filename,'w',encoding='utf-8')as f:
f.write(json_label)
def clear_data(d_one,filepath): #数据清洗
usaual_result=[]
sentence = []
start_time=time.time()
print(len(d_one))
index=0
count=0
for elemnet in d_one:
text=elemnet["content"]
text = re.sub(r"(回复)?(//)?\s*@\S*?\s*(:| |$)", " ", text) # 去除正文中的@和回复/转发中的用户名
results = re.compile(r'http://[a-zA-Z0-9.?/&=:]*', re.S) #对数据进行预处理,去除url
text=results.sub("",text)
text = zhconv.convert(text,'zh-cn') #中文繁体转简体
tokenized_text = bert_vocab.tokenize(text)
tokenized_text = ["[CLS]"] + tokenized_text + ["[SEP]"]
input_ids = bert_vocab.convert_tokens_to_ids(tokenized_text) # list
# 太长了,砍掉一部分
if len(input_ids)>max_seq_lenth:
input_ids=input_ids[:max_seq_lenth]
input_mask = [1] * len(input_ids)
# segment_ids = [0] * max_seq_lenth
# define padding, 填充的地方置为0,未填充的地方是 1
padding = [0] * (max_seq_lenth - len(input_ids))
index+=1
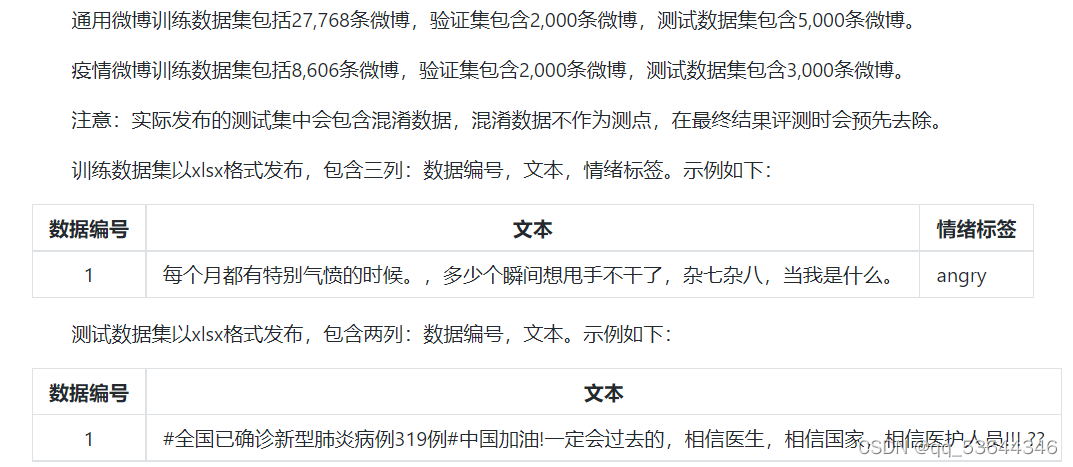
if(index%200==0):
end_time=time.time()
print(index,"/",len(d_one)," ----end---->>>time:",end_time-start_time,"seconds")
start_time=time.time()
# print(index)
# print(text,len(input_ids))
# if len(input_ids)>max_seq_lenth:
# print("false",index," ",len(input_ids))
# count+=1
# continue
input_ids += padding # 300
input_mask += padding
#转化为 torch.LongTensor 形式
input_ids = torch.tensor([input_ids], dtype = torch.long).to(device) #300
input_mask = torch.tensor([input_mask], dtype = torch.long).to(device) # 300
model = bert_model.to(device)
model.train()
with torch.no_grad():
all_encoder_layer, pooled_output = model(input_ids=input_ids,attention_mask=input_mask,)
pooled_output.to("cpu")
usaual_result.append(pooled_output[0].tolist())
sentence.append(pooled_output)
get_label_txt(usaual_result,filepath)
# print("count",count)
return sentence
这句用于截断
# 太长了,砍掉一部分
if len(input_ids)>max_seq_lenth:
input_ids=input_ids[:max_seq_lenth]这句用于测试句子最大长度
# if len(input_ids)>max_seq_lenth:
# print("false",index," ",len(input_ids))
# count+=1
# continuebert模型构建:
model = bert_model.to(device)
model.train()
with torch.no_grad():
all_encoder_layer, pooled_output = model(input_ids=input_ids,attention_mask=input_mask,)
pooled_output.to("cpu")
usaual_result.append(pooled_output[0].tolist())
sentence.append(pooled_output) with torch.no_grad():这句代码的作用参考:https://blog.csdn.net/weixin_44134757/article/details/105775027![]() https://blog.csdn.net/weixin_44134757/article/details/105775027
https://blog.csdn.net/weixin_44134757/article/details/105775027
(开始时我没有加上这句,导致cpu内存(16G)占满,电脑直接关机了!!!)
获得向量文件
usual_train_sentence = clear_data(usual_train_data,'C:\\Users\\86182\\Desktop\\usual_train_vector.txt') #获得数据清理后的文本
usual_eval_sentence = clear_data(usual_eval_data,'C:\\Users\\86182\\Desktop\\usual_eval_vector.txt')
usual_test_sentence = clear_data(usual_test_data,'C:\\Users\\86182\\Desktop\\usual_test_vector.txt')1.5运行结果
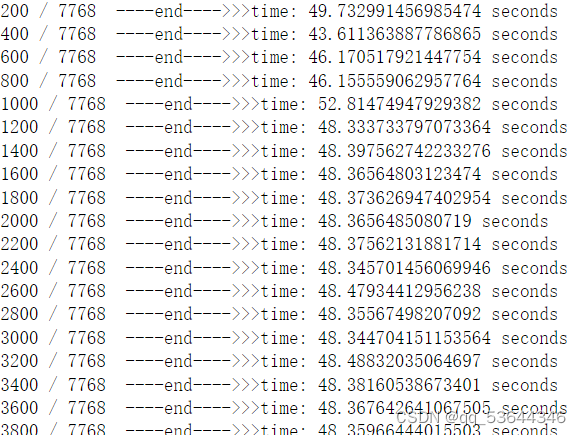
这是我运行得到的结果,有需要的可以下载:
2.读入数据
数据集格式如图:
可以看到数据集是josn格式的,所以我们可以调用json.loads()方法读取数据
代码如下(示例):
def get_data(filename):
d_one = []
file_one = open(filename,'r',encoding='utf-8')
#对txt进行遍历
for line in file_one:
d_one.append(json.loads(line))
d_one = d_one[0]
return d_one
usual_train_data= get_data('C:/Users/86182/Desktop/机器学习/EWECT/usual_train_vector.txt')
usual_eval_data = get_data('C:/Users/86182/Desktop/机器学习/EWECT/usual_eval_vector.txt')
usual_train_data_2=get_data('C:/Users/86182/Desktop/机器学习/EWECT/usual_train_vector_2.txt')
usual_train_data.extend(usual_train_data_2)
# usual_train_data.extend(usual_eval_data)
usual_test_data = get_data('C:/Users/86182/Desktop/机器学习/EWECT/usual_test_vector.txt')
# usual_train_data.extend(usual_eval_data)
注:其中usal_all_data是用来存储train、eval、test集的数据的,通过增大数据集,便于之后生成Word2Vec词向量模型,使其对词的表示更好。(当然这只是我的想法,具体还是要看结果)usual_train_data_label=get_data('C:\\Users\\86182\\Desktop\\训练验证和无标注测试\\train\\usual_train.txt')
usual_eval_data_label = get_data('C:\\Users\\86182\\Desktop\\训练验证和无标注测试\\eval\\usual_eval_labeled.txt')
获取标签
def get_label(dataset):
re=[]
for i in dataset:
re.append(i["label"])
return reusual_train_label_list=get_label(usual_train_data_label)
usual_eval_label_list=get_label(usual_eval_data_label)
# usual_train_label_list.extend(usual_eval_label_list)
# usual_train_label_list.extend(usual_test_label_list)获取向量
def get_ver(dataset):
re=[]
for i in dataset:
re.append(i["vector"])
return reusual_train_ver_list = get_ver(usual_train_data)
usual_eval_ver_list=get_ver(usual_eval_data)
usual_test_ver_list=get_ver(usual_test_data)
3.数据处理
将向量变成tensor类型
#将向量变成tensor
usual_train_ver=torch.Tensor(usual_train_ver_list)
usual_eval_ver=torch.Tensor(usual_eval_ver_list)
usual_test_ver=torch.Tensor(usual_test_ver_list)下面是针对标签换成数字:
# 将标签变成数字
def make_tensor(label):
label=[0 if i=='angry' else i for i in label]
label=[1 if i=='happy' else i for i in label]
label=[2 if i=='neutral' else i for i in label]
label=[3 if i=='surprise' else i for i in label]
label=[4 if i=='sad' else i for i in label]
label=[5 if i=='fear' else i for i in label]
# enc = OneHotEncoder(sparse=False)
# one_hot_train_label2 = enc.fit_transform(np.array(label).reshape(-1, 1))
return torch.Tensor(label)# 将标签变成数字
usual_train_label=make_tensor(usual_train_label_list)
usual_eval_label=make_tensor(usual_eval_label_list)
4.模型预测
这里先用LogisticRegression()测试一下分类准确率
lr_usual = LogisticRegression(max_iter=2000)
lr_usual.fit(usual_train_ver_list,usual_train_label_list)
print('usual集的分类准确率为:',lr_usual.score(usual_eval_ver_list,usual_eval_label_list))
运行结果:
![]()
5.数据划分
batch_size=100
train_set=torch.utils.data.TensorDataset(usual_train_ver,usual_train_label)
test_set=torch.utils.data.TensorDataset(usual_eval_ver,usual_eval_label)train_d1=torch.utils.data.DataLoader(train_set,batch_size=batch_size,shuffle=True,num_workers=2)
test_d1=torch.utils.data.DataLoader(test_set,batch_size=batch_size,num_workers=2)6.构建神经网络模型
6.1网络模型
注:可以自行设置网络结构,这里方便起见,网络结构设计的比较简单
模型一:全连接神经网络
# 输入层 784 隐藏层 500 隐藏层 300 输出层10
class GRU_NET(nn.Module):
def __init__(self):
super(GRU_NET,self).__init__()
self.classifier=nn.Sequential(
nn.Linear(768,320),nn.BatchNorm1d(320),nn.ReLU(),
nn.Linear(320,6)
)
def forward(self,x):
x=x.view(-1,768)
o=self.classifier(x)
return o模型二:GRU
class GRU_NET(nn.Module):
def __init__(self,input_size,hidden_size,num_layers,num_classes):
super(GRU_NET,self).__init__()
self.hidden_size=hidden_size
self.num_layers=num_layers
self.fetures=nn.GRU(input_size,hidden_size,num_layers,batch_first=True)
self.classifier=nn.Sequential(nn.Linear(hidden_size,2*hidden_size),nn.BatchNorm1d(2*hidden_size),nn.ReLU(),nn.Linear(2*hidden_size,num_classes))
def forward(self,x):
x=x.to(device)
h0=torch.zeros(self.num_layers,x.size(0),self.hidden_size).to(device)
o,_=self.fetures(x,h0)
o=o[:,-1,:]
o=o.view(x.size(0),-1)
o=o.to(device)
o=self.classifier(o)
return o6.2参数设置
nepochs=50
device=torch.device('cuda')
criterion=nn.CrossEntropyLoss()
input_size=768
wei_du=input_size
seq_len=1
num_classes=6
num_layers=2
hidden_size=768
nepochs1=30
# lr=0.00001
# lr=0.00005
lr=0.0001
6.3模型初始化
注:1.若选择模型一,则net=GRU_NET().to(device)
若选择模型二,net=GRU_NET(input_size,hidden_size,num_layers,num_classes).to(device)
2.optimizer=torch.optim.Adam(net.parameters(),lr=lr)为优化器,这里选择Adam算法
3.criterion=nn.CrossEntropyLoss()用于计算损失loss
# net=GRU_NET(input_size,hidden_size,num_layers,num_classes).to(device)
net=GRU_NET().to(device)
net=net.to(device)criterion=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(net.parameters(),lr=lr)
scheduler=lr_scheduler.MultiStepLR(optimizer,milestones=[10,20,30],gamma=0.8)
learn_hist=[]
7.评价指标与训练函数
评价函数:
def eval(model,criterion,dataloader):
loss=0
accuracy=0
for bx,by in dataloader:
bx=bx.view(-1,seq_len,wei_du)
bx=bx.to(device)
by=by.to(device)
logit=model(bx)
error=criterion(logit,by.long())
loss+=error.item()
_,pred_y=logit.data.max(dim=1)
acc=100*(pred_y.data==by).float().sum()/bx.size(0)
accuracy+=acc
loss/=len(dataloader)
accuracy/=len(dataloader)
return loss,accuracy训练函数:
def train_epoch(net,criterion,optimizer,dataloader):
net.train()#
for bx,by in dataloader:
bx=bx.view(-1,seq_len,input_size)
bx=bx.to(device)
by=by.to(device)
optimizer.zero_grad()
logits=net(bx)
error=criterion(logits,by.long())
error.backward()
optimizer.step()获取标签:
label_list=[]
def eval_label(model,criterion,dataloader):
temp=[]
for bx,by in dataloader:
bx=bx.view(-1,seq_len,wei_du)
bx=bx.to(device)
logit=model(bx)
_,pred_y=logit.data.max(dim=1)
temp.append(pred_y)
label_list.append(temp)计算f1_score:
eval_label_pred=[]
def eval_label_f1(model,criterion,dataloader):
pred=[]
real=[]
for bx,by in dataloader:
bx=bx.view(-1,seq_len,wei_du)
bx=bx.to(device)
logit=model(bx)
_,pred_y=logit.data.max(dim=1)
pred.extend(pred_y.tolist())
real.extend([int(e) for e in by])
sc=f1_score(real,pred,average='macro')
eval_label_pred.append(sc)
print("eval :f1_score=======>>>",sc)
训练模型:
train_list=[]
eval_list=[]
nepochs1=50
for epoch in range(nepochs1):
time_start=time.time()
scheduler.step()
train_epoch(net,criterion,optimizer,train_d1)
tr_err,tr_acc=eval(net,criterion,train_d1)
te_err,te_acc=eval(net,criterion,test_d1)
eval_label_f1(net,criterion,test_d1)
# te_err,te_acc=eval(net,criterion,test_d1)
# learn_hist.append((tr_err,tr_acc,te_err,te_acc))
train_list.append((tr_err,tr_acc))
eval_list.append((te_err,te_acc))
time_end=time.time()
print('[%d/%d, time:%.1f seconds], \t tr_e:%.1e |\ttr_a:%.2f'%(epoch+1,nepochs1,time_end-time_start,tr_err,tr_acc))
print('[%d/%d, time:%.1f seconds], \t te_e:%.1e |\tte_a:%.2f'%(epoch+1,nepochs1,time_end-time_start,te_err,te_acc))
print("--------------------------------------------------------=")若用测试集获得结果,则模型训练代码改为: (就是调用一下eval_label函数)
train_list=[]
eval_list=[]
nepochs1=100
for epoch in range(nepochs1):
time_start=time.time()
scheduler.step()
train_epoch(net,criterion,optimizer,train_d1)
tr_err,tr_acc=eval(net,criterion,train_d1)
te_err,te_acc=eval(net,criterion,test_d1)
eval_label(net,criterion,test_d2)
eval_label_f1(net,criterion,test_d1)
# te_err,te_acc=eval(net,criterion,test_d1)
# learn_hist.append((tr_err,tr_acc,te_err,te_acc))
train_list.append((tr_err,tr_acc))
eval_list.append((te_err,te_acc))
time_end=time.time()
print('[%d/%d, time:%.1f seconds], \t tr_e:%.1e |\ttr_a:%.2f'%(epoch+1,nepochs1,time_end-time_start,tr_err,tr_acc))
print('[%d/%d, time:%.1f seconds], \t te_e:%.1e |\tte_a:%.2f'%(epoch+1,nepochs1,time_end-time_start,te_err,te_acc))
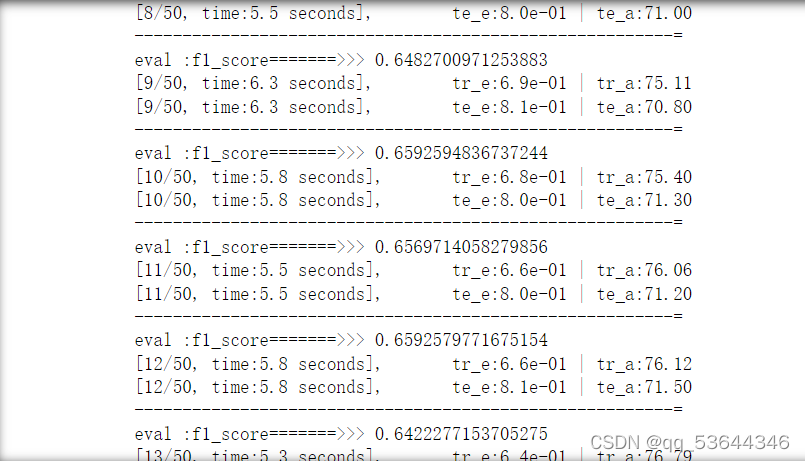
print("--------------------------------------------------------=")训练结果:
画图:
plt.plot([t[1] for t in train_list],'r',label='train_acc')
plt.plot([t[1] for t in eval_list],'b',label='test_acc')
plt.plot([100*t for t in eval_label_pred],'black',label='test_f1')
plt.xlabel('Epoch')
plt.ylabel('accuracy')
plt.legend() 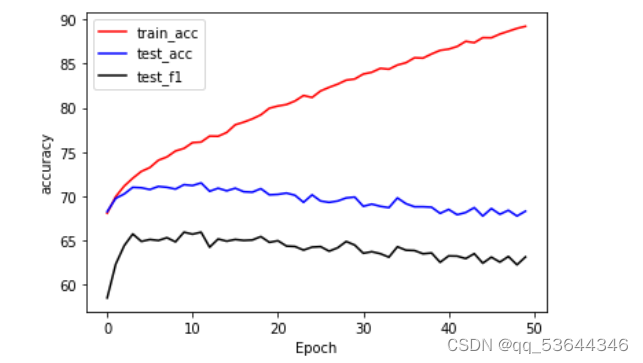
可以看到准确率比LogisticRegression高,当然也并没有高很多,这主要是由于神经网络模型过于简单,同时参数的选择也直接影响准确率。
另外,随着训练次数的增加,出现了过拟合,即随着训练次数的增加,精确率在不断下降。
四、优化
1.模型选择
采用模型一的结果:
采用模型二的结果:
可以看到,训练结果和模型一差不多,但是每个epoch的训练时间变长了。而其在训练集上的结果接近100%来
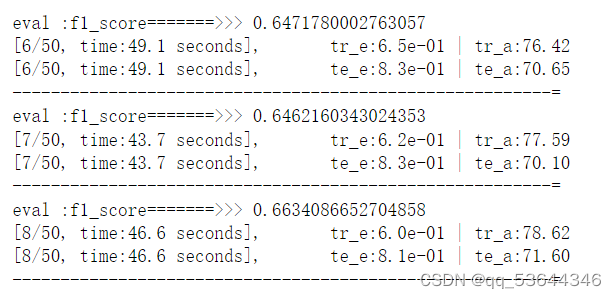
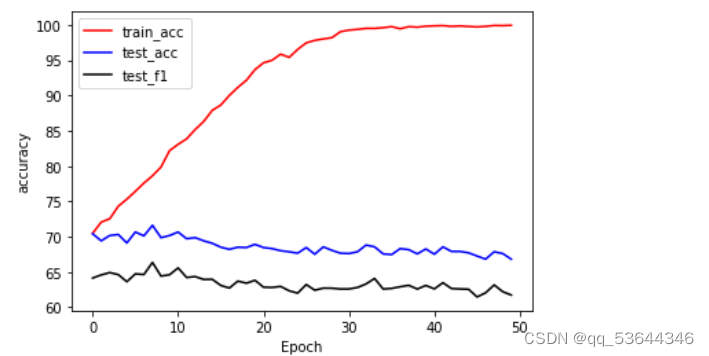
注:温度对训练时间的影响是十分巨大的,由于笔记本电脑散热性不是很好,于是我加了电风扇降低显卡温度,以下是其训练时长的变化:
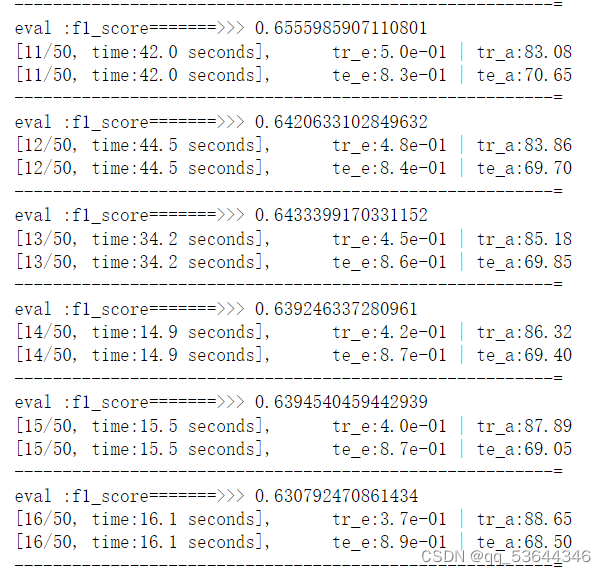
2.参数优化
训练的过程中有许多的参数,选择不同的参数会得到不同的结果。以下是我认为主要的参数:
1:维度 wei_du,这里我选取的是200
2:隐藏层数量num_layers,这里我选取2
3:隐藏层张量大小:hidden_size=768
4:学习率lr,这个对训练结果的影响是巨大的,过高或过低都会导致模型不收敛或过拟合,这里我选取0.0001
五、分类结果
1.获得预测结果
25表示为第25次训练获得的label
result=[]
for i in range(50):
for j in range(100):
result.append(int(label_list[25][i][j]))2.将标签数字转换成文字
代码如下:
# 将数字变成标签
def make_label(label):
label=['angry' if i==0 else i for i in label]
label=['happy' if i==1 else i for i in label]
label=['neutral' if i==2 else i for i in label]
label=['surprise' if i==3 else i for i in label]
label=['sad' if i==4 else i for i in label]
label=['fear'if i==5 else i for i in label]
return label
usaual_result=make_label(result)3.保存结果
def get_label_txt(test_label,filename):
id_label = []
for i in range(1,len(test_label)+1):
id = {}
id['id']=i
id['label']=test_label[i-1]
id_label.append(id)
# print(id_label)
json_label = json.dumps(id_label)
# print(json_label)
with open(filename,'w',encoding='utf-8')as f:
f.write(json_label)
get_label_txt(usaual_result,'C:\\Users\\86182\\Desktop\\usual_result.txt')最终评分:

传统基于 Word2Vec 的文本表示及文本分类方法+LogisticRegression分类方法

基于bert模型的词向量表示+简单的全连接神经网络:

可以看到,无论在通用微博数据集和疫情微博数据集上都有不小的提升。
总结:
当然方法仅供参考,如有不足,还忘不吝赐教!!!同时也欢迎更多的nlp爱好者参与评测
评测地址:















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









