







前言
最近在阅读的论文过程中,有时看到论文中实验结果表格中出现p值的比较,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rj2vEZ61-1683728276133)(https://wp.recgroup.cn/wp-content/uploads/2023/03/image-1678103531070.png)]](https://i-blog.csdnimg.cn/blog_migrate/6447f474299227053b97a3f0b9bc3faa.png)
p值的计算
对于配对设计的连续性变量在两组间的差异,可以选用配对t检验或Wilcoxon signed-rank检验(Wilcoxon符号秩检验)。接下来以STCN表格中的数据为例,使用这两种方法计算p值。
t检验
-
适用条件:两组差值近似服从正态分布的数据
-
方法一:python代码
import numpy as np
from scipy import stats
A=[1,2,4,5,2]
B=[2,3,4,1,1]
A=np.array(A)
B=np.array(B)
t,p=stats.ttest_ind(A,B)
print("t:",t,"\t p:",p)
-
方法二:EXCEL公式
以STCN表格中的数据为例:依次点击 公式 -> 其他函数 -> 统计 -> T.TEST,如下图所示:
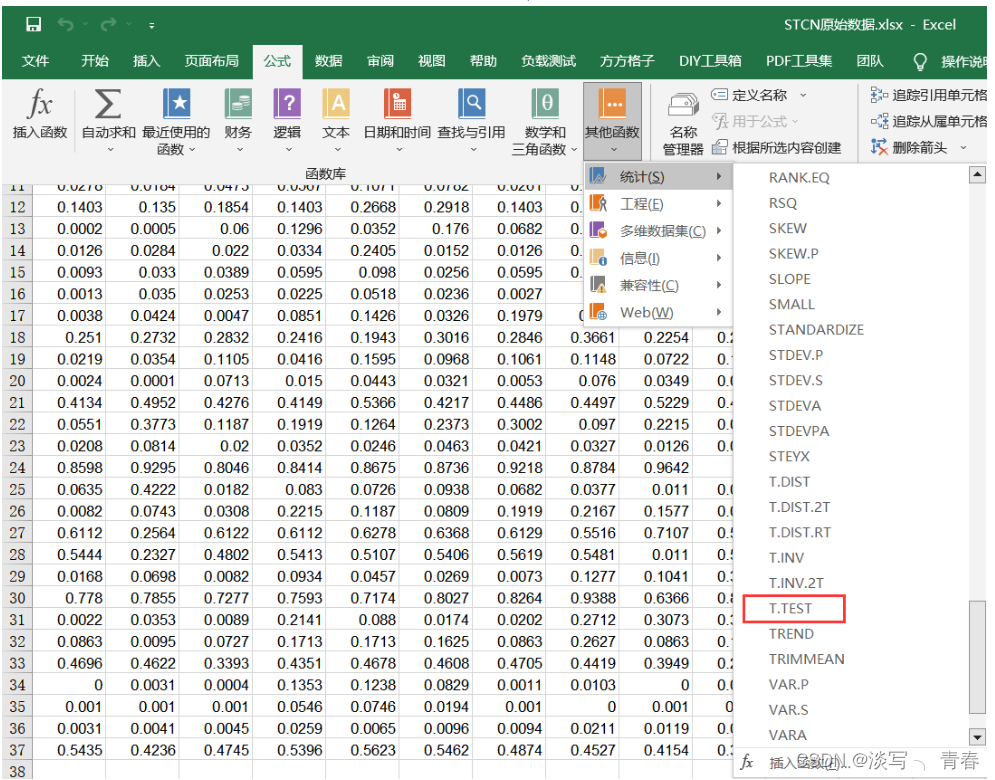
点击Array1中的输入框,再框住第一列数据(模型1的数据),点击Array2中的输入框,再框住第二列数据(模型2的数据),Tails和type都输入2(参数含义已经提示了)
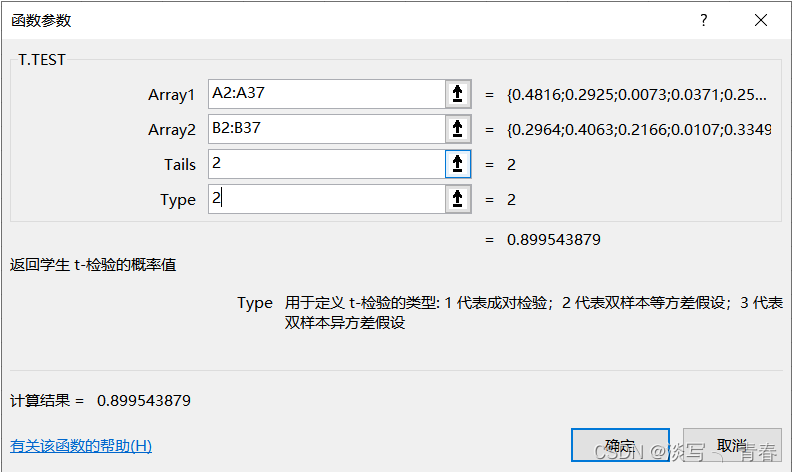
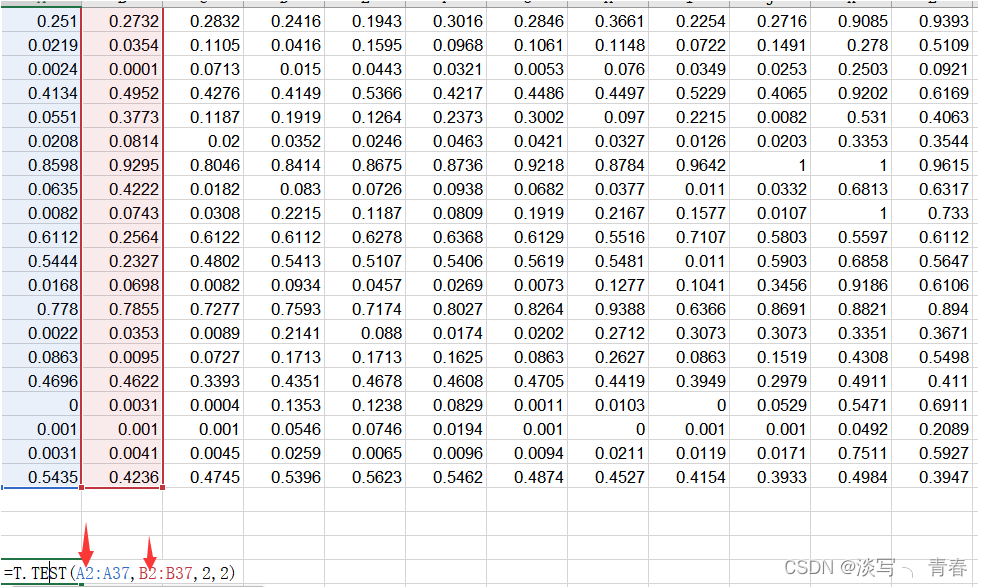
点击确定,就可以获得了t检验下的p值

多组数据对比直接修改公式中的列号就行了
-
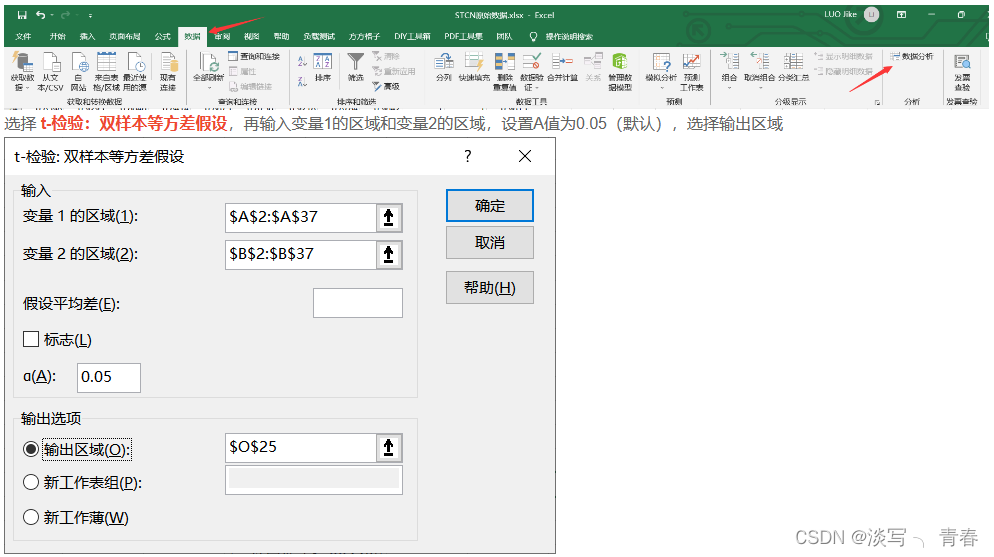
方法三:EXCEL数据分析
依次点击数据 -> 数据分析
选择 t-检验:双样本等方差假设,再输入变量1的区域和变量2的区域,设置A值为0.05(默认),选择输出区域:
确定之后即可获得一下结果可以看到单侧p值和双侧p值。同理可得到t-检验:双样本异方差假设的结果: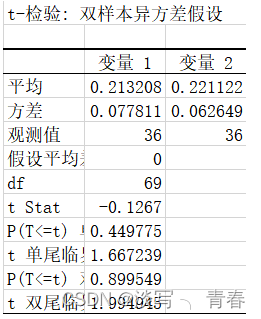
Wilcoxon符号秩检验
说明:在Self-Supervised Time Series Clustering With Model-Based Dynamics这篇论文中使用的便是Wilcoxon符号秩检验方法,具体细节他是参考论文Statistical Comparisons of Classifiers over Multiple Data Sets的,下面我就根据论文中的原始数据,实现AVG RANK 和P值的计算。
论文中的数据如图所示:
-
利用OCR工具获得原始论文中的数据,如下图所示:

-
利用rank()方法计算各方法在数据集上的排名,python程序如下:
# -*- coding: utf-8 -*-
# @Time :
# @Author :
# @Email :
# @File :
import pandas as pd
def count_avg(source_csv_file,target_csv_file):
df=pd.read_csv(source_csv_file,index_col=None)
df_head=df.columns
result_df=[]
#读取每一行数据
for i in range(len(df)):
one_row_df=df.iloc[i]
#获得每一行的排名
rank_one_row=one_row_df.rank(ascending=False, method='average')
best_result = rank_one_row.values
result_df.append(best_result)
result=pd.DataFrame(result_df,columns=df_head,index=None) result.to_csv(target_csv_file,mode='w',index=False)
source_csv_file = './file/STCN原始数据.csv'
target_csv_file='./file/STCN原始数据_RANK_NMI.csv'
count_avg(source_csv_file,target_csv_file)

运行程序,结果如图所示:

求平均值,即可获得各算法的AVG RANK

与原论文一致:

- 在原始数据上计算p值,调用stats.wilcoxon()方法即可进行Wilcoxon符号秩检验,注意使用python3.7版本,python3.10版本会有警告,且结果和python==3.7及其他版本的可能结果不一样。python程序如下:
# -*- coding: utf-8 -*-
# @Time :
# @Author :
# @Email :
# @File :
import pandas as pd
import numpy as np
from scipy import stats
source_csv_file = './file/STCN原始数据.xlsx'
def get_p_value(source_csv_file):
df = pd.read_excel(io=source_csv_file,index_col=None,header=None)
p_list=[]
# B_index默认最后一列
last_index=df.shape[1]-1
B_index=last_index
for i in range(last_index):
A=df.iloc[:,i].values
B=df.iloc[:,B_index].values
A=np.array(A)
B=np.array(B)
# Wilcoxon符号秩检验
t,p_value=stats.wilcoxon(A, B, correction=False, alternative='two-sided')
# t,p=stats.ttest_ind(A,B)
# print("t:", t, "\t p_value:", p_value)
p_list.append(p_value)
print(p_list)
get_p_value(source_csv_file)
计算结果如图所示:
python3.10的结果:

python3.7的结果:

与原论文一致:

- 绘制CD(临界差异)图,python程序如下:
# -*- coding: utf-8 -*-
# @Time :
# @Author :
# @Email :
# @File :
import Orange
import matplotlib.pyplot as plt
#算法名字
names = ['k-means', 'SC', 'UDFS', 'NDFS', 'RUFS', 'RSFS', 'KSC', 'KDBA', 'K-shape', 'u-shapelet', 'USSL', 'STCN']
#各算法的平均排名
avranks = [9.6528,7.9583,8.7778,6.8889,6.2083,6.2222,
6.4306,6.6389,7.0417,7.3333,2.5139,2.3333]
#数据集大小
datasets_num = 35
#利用Nemenyi检验计算Critical difference
CD = Orange.evaluation.scoring.compute_CD(avranks, datasets_num, alpha='0.05', test='nemenyi')
Orange.evaluation.scoring.graph_ranks(avranks, names, cd=CD, width=8, textspace=1.5, reverse=True)
plt.show()
结果如图:


















 1194
1194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









