







文章摘要:最近在参加kaggle上的一个比赛时,发现了一个非常有用的自动化参数搜索方法optuna。在本文中将搭建一个简单的pytorch神经网络,从而对野生蓝莓产量进行预测,模型使用optuna包对参数进行自动搜索,同时也以可视化的形式对参数搜索结果进行展现。
目录
前言
数据集描述
数据集可以直接在官网下载,注:(本文中还用到另一份原始数据,所以一共四份csv文件)
OPTUNA是一个自动超参数搜索的超参数优化框架,可应用于机器学习和深度学习模型;Optuna使用了采样和剪枝算法来优化超参数,所以非常快速和高效;它还可以通过直观的方式动态构建超参数搜索空间。以下是官方给出的一个使用案例:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import train_test_split
import optuna
X, y = load_iris(return_X_y=True)
X_train, X_valid, y_train, y_valid = train_test_split(X, y)
def objective(trial):
clf = SGDClassifier(random_state=0)
for step in range(100):
clf.partial_fit(X_train, y_train, np.unique(y))
intermediate_value = clf.score(X_valid, y_valid)
trial.report(intermediate_value, step=step)
if trial.should_prune():
raise optuna.TrialPruned()
return clf.score(X_valid, y_valid)
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=3)Optuna还有如下一些非常实用的特性:
1,通过将搜索结果存储到sqlite或mysql、postgresql,Optuna支持断点续搜。
2,Optuna支持剪枝策略,提前结束一些中间返回结果较差的采样点从而加快搜索进程。
3,Optuna支持手动指定一些超参采样点,也可以添加已经计算过的采样点及其结果作为初始化样本点。
4,Optuna提供ask and tell 接口模式,无需显式定义目标函数,直接在循环中调优超参。
5,Optuna封装了非常丰富的基于plotly的可视化函数,便于分析调参结果。
6,通过将搜索结果存储到mysql或postgresql,并设置分布式模式,Optuna支持多机分布式搜索,通过并行方式加快搜索进程。
以下是程序所需要的python库:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler, MaxAbsScaler, RobustScaler
from torch.utils.data import Dataset
import numpy as np
from typing import Callable, List
import optuna
import torch
from sklearn.metrics import mean_squared_error, mean_absolute_error
from torch import nn
import dataset
import warnings
warnings.filterwarnings('ignore')一、数据读取与预处理
1.读取数据
使用pandas读取csv文件并丢掉第一列
# 读取数据
path_origin='data/WildBlueberryPollinationSimulationData.csv'
path_train='data/train.csv'
path_test='data/test.csv'
#读取数据并扔掉第一列
df_train = pd.read_csv(path_train).drop(columns='id')
df_test = pd.read_csv(path_test).drop(columns='id')
df_origin = pd.read_csv(path_origin).drop(columns='Row#')
target_col = 'yield'2.数据分析
查看数据维度和是否存在缺失值:
print(f'[Info] Shapes:\n'
f'df_origin:{df_origin.shape}\n'
f'df_train:{df_train.shape}\n'
f'df_test:{df_test.shape}\n')
print(f'[Info] Are missing values?\n'
f'df_origin:{df_origin.isna().any().any()}\n'
f'df_train:{df_train.isna().any().any()}\n'
f'df_test:{df_test.isna().any().any()}\n')运行结果:

查看数据前五行:
#扩充训练集
full_train=pd.concat([df_train,df_origin],axis=0)
full_train.head()运行结果:

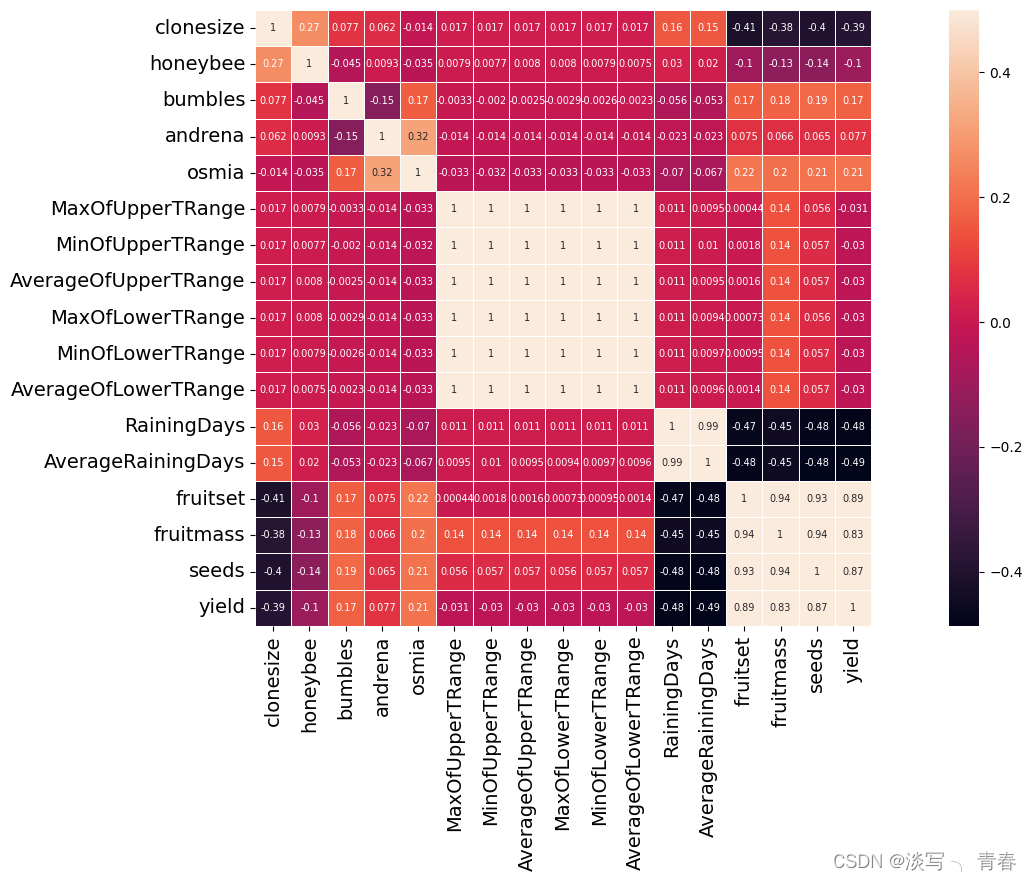
利用热力图分析特征之间的相关性:
plt.figure(figsize=(20, 8))
sns.heatmap(full_train.corr(),linewidths=0.5,vmax=0.5, square=True,linecolor='white', annot=True,annot_kws={"fontsize":7})
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()运行结果:
 3.数据处理
3.数据处理
添加特征并删除存在高相关性的特征:
def add_features(df_in):
df=df_in.copy(deep=True)
df['fruit_seed']=df['fruitset']*df['seeds']
return df
def del_features(df_in):
df = df_in.copy(deep=True)
df_in.drop(
['MinOfUpperTRange', 'AverageOfUpperTRange', 'MaxOfLowerTRange', 'MinOfLowerTRange', 'AverageOfLowerTRange',
'AverageRainingDays'], axis=1)
return df
# Add features and remove highly correlated features
df_train = add_features(df_train)
df_origin = add_features(df_origin)
df_test = add_features(df_test)
df_train = del_features(df_train)
df_origin = del_features(df_origin)
df_test = del_features(df_test)划分数据集:
target_col = 'yield'
x_train = full_train.drop([target_col], axis=1).reset_index(drop=True)
y_train = full_train[target_col].reset_index(drop=True)
x_test = df_test.reset_index(drop=True)
x_train = np.array(x_train)
y_train = np.array(y_train)
x_test = np.array(x_test)
y_test = np.zeros(len(x_test)) # Pseudo-labels
#划分训练集、验证集、测试集
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2, random_state=26)
对数据集进行归一化:
# Standardize datasets
# sc=MinMaxScaler()
# sc=MaxAbsScaler()
# sc=RobustScaler()
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_val = sc.fit_transform(x_val)
x_test = sc.fit_transform(x_test)完整代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @FileName :dataset.py
# @Time :2023/5/10 15:25
# @Author :luojiachen
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler, MaxAbsScaler, RobustScaler
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self,ds):
super(MyDataset, self).__init__()
# 读取数据和标签
X_train = ds[0]
y_train = ds[1]
# X_train=np.expand_dims(X_train,1)
self.len = X_train.shape[0]
self.x_data = X_train
self.y_data = y_train
def __len__(self):
return self.len
def __getitem__(self, idx):
return self.x_data[idx], self.y_data[idx]
def add_features(df_in):
df=df_in.copy(deep=True)
df['fruit_seed']=df['fruitset']*df['seeds']
return df
def del_features(df_in):
df = df_in.copy(deep=True)
df_in.drop(
['MinOfUpperTRange', 'AverageOfUpperTRange', 'MaxOfLowerTRange', 'MinOfLowerTRange', 'AverageOfLowerTRange',
'AverageRainingDays'], axis=1)
return df
def processing_data(train_path,test_path,origin_path):
'''
:param train_path: type:str 训练集csv文件路径
:param test_path: type:str 测试集csv文件路径
:param origin_path: type:str 扩充训练数据集csv文件路径
:return:
'''
# Read the data and throw away the first column
df_train = pd.read_csv(train_path).drop(columns='id')
df_test = pd.read_csv(test_path).drop(columns='id')
df_origin = pd.read_csv(origin_path).drop(columns='Row#')
# Add features and remove highly correlated features
df_train = add_features(df_train)
df_origin = add_features(df_origin)
df_test = add_features(df_test)
df_train = del_features(df_train)
df_origin = del_features(df_origin)
df_test = del_features(df_test)
# Enrich the training set
full_train = pd.concat([df_train, df_origin], axis=0)
target_col = 'yield'
x_train = full_train.drop([target_col], axis=1).reset_index(drop=True)
y_train = full_train[target_col].reset_index(drop=True)
x_test = df_test.reset_index(drop=True)
x_train = np.array(x_train)
y_train = np.array(y_train)
x_test = np.array(x_test)
y_test = np.zeros(len(x_test)) # Pseudo-labels
#划分训练集、验证集、测试集
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2, random_state=26)
# Standardize datasets
# sc=MinMaxScaler()
# sc=MaxAbsScaler()
# sc=RobustScaler()
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_val = sc.fit_transform(x_val)
x_test = sc.fit_transform(x_test)
return x_train,y_train,x_val,y_val,x_test,y_test
二、模型构建
1.主函数
if __name__ == '__main__':
study = optuna.create_study(study_name = 'mlp-regressor', direction = 'minimize', sampler = optuna.samplers.TPESampler(), storage = 'sqlite:///db.sqlite3')
study.optimize(objective, n_trials=100)
print("Study statistics: ")
print(" Number of finished trials: ", len(study.trials))
print("Best trial:")
trial = study.best_trial
print(" Value: ", trial.value)
print(" Params: ")
for key, value in trial.params.items():
print("{}:{}".format(key, value))study = optuna.create_study(study_name = 'mlp-regressor', direction = 'minimize', sampler = optuna.samplers.TPESampler(), storage = 'sqlite:///db.sqlite3')
study.optimize(objective, n_trials=100)
其中,第一句中的参数说明如下:
study_name:案例的名字,注意每次运行程序时,要保证和之前的案例名不重复,若重复则另取名字或删除之前的案例
direction:表示optuna优化的方向,这个和你定义的objective函数(后面会说怎么定义)的返回值有关,可以设置为maximize或minimize,具体取决于超参数调整的最终目标。有以下两种情况:
- 如果目标是通过准确度、F1 分数、精确度或召回率等指标来提高性能,则将其设置为maximize.
- 如果目标是减少损失函数,例如 log-loss、MSE、RMSE 等,则将其设置为minimize.
sampler:Optuna 实施的采样器方法,可以选择多个采样器选项,例如:
GridSampler:根据定义的搜索空间中的每个组合选择一组超参数值。RandomSampler:从定义的搜索空间中随机选择一组超参数值。TPESampler:这是使用 Optuna时的默认设置。它基于贝叶斯超参数优化,这是一种有效的超参数调整方法。它将像随机采样器一样开始,但该采样器记录了一组超参数值的历史以及过去试验的相应目标值。然后,它将根据过去试验的有希望的目标值集为下一次试验建议一组超参数值。
storage:数据库的url,它定义了你的存储方式,这里用sqlite3,也可以用mysql等。添加该参数后会在python项目下生成一个db.sqlite3文件用于存储数据。如图:
第二句调用study.optimize()方法对你定义的objective方法进行参数搜索,试验次数设置为100。
2.MLP
对于简单的表格数据,在实验中发现RNN、LSTM等模型的效果并不好,故在神经网络的构建中,本文使用了一个简单的MLP,代码如下:
class Encoder(nn.Module):
# https://www.kaggle.com/code/eleonoraricci/ps3e14-berrylicious-predictions-with-pytorch
def __init__(self, n_hidden_layers: int,
input_dim: int,
hidden_dims: List[int],
output_dim: int,
dropout_prob: float,
activation: Callable):
"""
Parameters
----------
n_hidden_layers: int
The number of hidden layers to include between input and output
input_dim: int
Number of nodes in the input layer. It is equal to the number of
features used for modelling.
hidden_dims: List[int]
List of ints specifying the number of nodes in each hidden layer
of the network. It must contain the same number of elements as the
value of n_hidden_layers.
output_dim: int
Number of nodes in the output layer. It is equal to 1 for
this regression task.
dropout_prob: float
value between 0 and 1: probability of zeroing out elements of the
input tensor in the Dropout layer
"""
super(Encoder, self).__init__()
# The Network is built using the ModuleList constructor
self.network = nn.ModuleList()
if n_hidden_layers == 0:
# If no hidden layers are used, go directly from input to
# output dimension
self.network.append(nn.Linear(input_dim, output_dim))
self.network.append(activation)
else:
# Append to the constructor the required layers, with dimentions specified
# in the hidden_dims list
self.network.append(nn.Linear(input_dim, hidden_dims[0]))
self.network.append(nn.LayerNorm(hidden_dims[0]))
self.network.append(activation)
if dropout_prob > 0:
self.network.append(torch.nn.Dropout(p=dropout_prob, inplace=False))
for layer in range(n_hidden_layers - 1):
self.network.append(nn.Linear(hidden_dims[layer], hidden_dims[layer + 1]))
self.network.append(nn.LayerNorm(hidden_dims[layer + 1]))
self.network.append(activation)
# self.network.append(nn.Linear(hidden_dims[-1], output_dim))
# self.network.append(nn.ReLU())
output_dim=hidden_dims[-1]
self.project=nn.Linear(output_dim,1)
self.activation=nn.ReLU()
def forward(self, x):
for layer in self.network:
x = layer(x)
return x
def forward_predict(self,x):
return self.activation(self.project(x))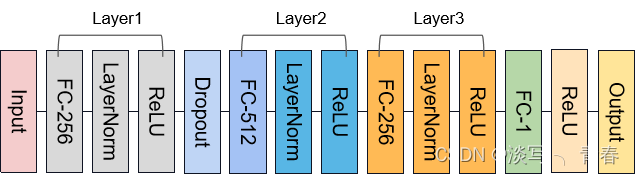
3.参数设置
注:首先定义一个函数objective,参数有且仅有trial。然后对参数进行设置,这里我将参数的类型分为了固定参数、搜索参数、计算参数,如图:
def objective(trial):
#-----------------------------参数--------------------------------------
#固定参数
device='cuda'
drop_last = False
epochs=500
patience = 15
min_change = 0.0001
beta1 = 0.9
beta2 = 0.99
hidden_dims=[256,512,256]
#需要调整的参数
batch_size=trial.suggest_categorical('batch_size',[64,128,256,512,1024])
lr=trial.suggest_float('lr', 1e-3, 1e-1)
weight_decay=trial.suggest_float('weight_decay',1e-8, 1e-3)
# compute parameters
input_size = train_ds[0].shape[1]
input_dim = input_size
n_hidden_layers=len(hidden_dims)
#-----------------------------------------------------------------------
#模型参数
params = {
'activation':nn.ReLU(),
'dropout_prob':trial.suggest_float('dropout_prob',0,0.5),
'n_hidden_layers': n_hidden_layers,
'input_dim': input_dim,
'hidden_dims': hidden_dims,
'output_dim': 1
}
# 定义模型
my_model=Encoder(**params)
my_model.to(device)其中,最关键的是搜索参数的定义,需要用到trial.suggest_*()方法,按照官方说明文档,
有以下几个扩展,具体取决于超参数的数据类型:
suggest_int:如果您的超参数接受一系列整数类型的数值。suggest_categorical:如果您的超参数接受分类值的选择。suggest_uniform:如果您的超参数接受一系列数值,并且您希望对每个值进行同样的采样。suggest_loguniform:如果您的超参数接受一系列数值,并且您希望在对数域中对每个值进行同样的采样。suggest_discrete_uniform:如果您的超参数接受特定区间内的一系列数值,并且您希望每个值都以同样的可能性进行采样。suggest_float:如果您的超参数接受一系列浮点类型的数值。这是 , 和
的suggest_uniform包装suggest_loguniform方法suggest_discrete_uniform
4.数据处理
读取数据并将其转化为data_loader
# Prepare the data
path_origin = '../data/WildBlueberryPollinationSimulationData.csv'
path_train = '../data/train.csv'
path_test = '../data/test.csv'
x_train, y_train, x_val, y_val, x_test, y_test = dataset.processing_data(path_train, path_test, path_origin)
train_ds=(x_train,y_train)
val_ds=(x_val,y_val)
train_set = dataset.MyDataset(train_ds)
val_set = dataset.MyDataset(val_ds)
train_loader = torch.utils.data.DataLoader(dataset=train_set, batch_size=batch_size, shuffle=True,drop_last=drop_last)
eval_loader = torch.utils.data.DataLoader(dataset=val_set, batch_size=batch_size, shuffle=True,drop_last=drop_last)5.其他设置
早停机制:
class EarlyStopping():
"""
Early stopping to stop the training when the loss does not improve after
certain epochs.
"""
def __init__(self, patience=5, min_delta=0.1):
"""
:param patience: how many epochs to wait before stopping when loss is
not improving
:param min_delta: minimum difference between new loss and old loss for
new loss to be considered as an improvement
"""
self.patience = patience
self.min_delta = min_delta
self.counter = 0
self.best_loss = None
self.early_stop = False
def __call__(self, val_loss):
if self.best_loss == None:
self.best_loss = val_loss
elif self.best_loss - val_loss > self.min_delta:
self.best_loss = val_loss
# reset counter if validation loss improves
self.counter = 0
elif self.best_loss - val_loss < self.min_delta:
self.counter += 1
print(f"INFO: Early stopping counter {self.counter} of {self.patience}")
if self.counter >= self.patience:
print('INFO: Early stopping')
self.early_stop = True优化器、损失函数、学习率调整器 :
# 优化器
optimizer = torch.optim.Adam(my_model.parameters(), lr=lr, betas=(beta1, beta2),weight_decay=weight_decay)
lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer=optimizer,
mode='min',
patience=10,
factor=0.1,
min_lr=1e-5,
verbose=True)
# loss function
criterion = torch.nn.L1Loss()
early_stopper = EarlyStopping(patience=patience, min_delta=min_change)训练函数:
#训练函数
def step_epoch(model, optimizer, data_loader, criterion, mode=None,device=None):
loss_epoch = 0
total_loss = []
for step, (x_data, y_data) in enumerate(data_loader):
model.eval()
if mode == 'train':
model.train()
optimizer.zero_grad()
x_data = x_data.to(torch.float32).to(device)
y_data = y_data.to(torch.float32).to(device)
h_x = model(x_data)
pred_y=model.forward_predict(h_x)
loss_mae = criterion(pred_y.squeeze(), y_data)
loss = loss_mae
# loss=loss_mae
if mode == 'train':
loss.backward()
optimizer.step()
total_loss.append(loss.item())
loss_epoch += loss.item()
# print(f'loss_mae:{loss_mae}\tloss_con:{loss_con}')
total_loss = torch.tensor(total_loss).mean()
return total_loss.item()
预测函数:
#预测函数
def predict_epoch(model, test_loader,device='cuda'):
model.eval()
feature_vector = []
labels_vector = []
for step, (x_data, y_data) in enumerate(test_loader):
x = x_data.to(torch.float32).to(device)
with torch.no_grad():
# c = self.model(x)
h_x = model(x)
c = model.forward_predict(h_x)
c = c.detach()
feature_vector.extend(c.cpu().detach().numpy())
labels_vector.extend(y_data)
feature_vector = np.array(feature_vector)
labels_vector = np.array(labels_vector)
return feature_vector, labels_vector6.模型训练
for epoch in range(1, epochs + 1):
loss_train_epoch = step_epoch(my_model,optimizer, train_loader, criterion,mode='train',device=device)
loss_eval_epoch = step_epoch(my_model,optimizer, eval_loader, criterion, mode='val',device=device)
predict_labels, true_label = predict_epoch(my_model,eval_loader,device)
MSE = mean_squared_error(true_label, predict_labels)
MAE = mean_absolute_error(true_label, predict_labels)
if MAE<min_mae:
min_mae=MAE
print(
f'Epoch:{epoch}/{epochs}\tloss_train_epoch:{loss_train_epoch}\tloss_eval_epoch:{loss_eval_epoch}\tMAE:{MAE}\tMSE:{MSE}')
# Update learning rate scheduler and check early stoopping criterun
lr_scheduler.step(loss_eval_epoch)
early_stopper(loss_eval_epoch)
if early_stopper.early_stop:
break
return min_mae(注:返回值为min_mae,objective方法必须要有返回值,这需要和optuna.create_study方法中的参数direction相适应。)
整体代码为:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @FileName :model.py
# @Time :2023/5/10 15:23
# @Author :luojiachen
import numpy as np
from typing import Callable, List
import optuna
import torch
from sklearn.metrics import mean_squared_error, mean_absolute_error
from torch import nn
import dataset
import warnings
warnings.filterwarnings('ignore')
class EarlyStopping():
"""
Early stopping to stop the training when the loss does not improve after
certain epochs.
"""
def __init__(self, patience=5, min_delta=0.1):
"""
:param patience: how many epochs to wait before stopping when loss is
not improving
:param min_delta: minimum difference between new loss and old loss for
new loss to be considered as an improvement
"""
self.patience = patience
self.min_delta = min_delta
self.counter = 0
self.best_loss = None
self.early_stop = False
def __call__(self, val_loss):
if self.best_loss == None:
self.best_loss = val_loss
elif self.best_loss - val_loss > self.min_delta:
self.best_loss = val_loss
# reset counter if validation loss improves
self.counter = 0
elif self.best_loss - val_loss < self.min_delta:
self.counter += 1
print(f"INFO: Early stopping counter {self.counter} of {self.patience}")
if self.counter >= self.patience:
print('INFO: Early stopping')
self.early_stop = True
class Encoder(nn.Module):
# https://www.kaggle.com/code/eleonoraricci/ps3e14-berrylicious-predictions-with-pytorch
def __init__(self, n_hidden_layers: int,
input_dim: int,
hidden_dims: List[int],
output_dim: int,
dropout_prob: float,
activation: Callable):
"""
Parameters
----------
n_hidden_layers: int
The number of hidden layers to include between input and output
input_dim: int
Number of nodes in the input layer. It is equal to the number of
features used for modelling.
hidden_dims: List[int]
List of ints specifying the number of nodes in each hidden layer
of the network. It must contain the same number of elements as the
value of n_hidden_layers.
output_dim: int
Number of nodes in the output layer. It is equal to 1 for
this regression task.
dropout_prob: float
value between 0 and 1: probability of zeroing out elements of the
input tensor in the Dropout layer
"""
super(Encoder, self).__init__()
# The Network is built using the ModuleList constructor
self.network = nn.ModuleList()
if n_hidden_layers == 0:
# If no hidden layers are used, go directly from input to
# output dimension
self.network.append(nn.Linear(input_dim, output_dim))
self.network.append(activation)
else:
# Append to the constructor the required layers, with dimentions specified
# in the hidden_dims list
self.network.append(nn.Linear(input_dim, hidden_dims[0]))
self.network.append(nn.LayerNorm(hidden_dims[0]))
self.network.append(activation)
if dropout_prob > 0:
self.network.append(torch.nn.Dropout(p=dropout_prob, inplace=False))
for layer in range(n_hidden_layers - 1):
self.network.append(nn.Linear(hidden_dims[layer], hidden_dims[layer + 1]))
self.network.append(nn.LayerNorm(hidden_dims[layer + 1]))
self.network.append(activation)
# self.network.append(nn.Linear(hidden_dims[-1], output_dim))
# self.network.append(nn.ReLU())
output_dim=hidden_dims[-1]
self.project=nn.Linear(output_dim,1)
self.activation=nn.ReLU()
def forward(self, x):
for layer in self.network:
x = layer(x)
return x
def forward_predict(self,x):
return self.activation(self.project(x))
def step_epoch(model, optimizer, data_loader, criterion, mode=None,device=None):
loss_epoch = 0
total_loss = []
for step, (x_data, y_data) in enumerate(data_loader):
model.eval()
if mode == 'train':
model.train()
optimizer.zero_grad()
x_data = x_data.to(torch.float32).to(device)
y_data = y_data.to(torch.float32).to(device)
h_x = model(x_data)
pred_y=model.forward_predict(h_x)
loss_mae = criterion(pred_y.squeeze(), y_data)
# loss_con = contrastive_loss(h_x, y_data)
loss = loss_mae
# loss=loss_mae
if mode == 'train':
loss.backward()
optimizer.step()
total_loss.append(loss.item())
loss_epoch += loss.item()
# print(f'loss_mae:{loss_mae}\tloss_con:{loss_con}')
total_loss = torch.tensor(total_loss).mean()
return total_loss.item()
def predict_epoch(model, test_loader,device='cuda'):
model.eval()
feature_vector = []
labels_vector = []
for step, (x_data, y_data) in enumerate(test_loader):
x = x_data.to(torch.float32).to(device)
with torch.no_grad():
# c = self.model(x)
h_x = model(x)
c = model.forward_predict(h_x)
c = c.detach()
feature_vector.extend(c.cpu().detach().numpy())
labels_vector.extend(y_data)
feature_vector = np.array(feature_vector)
labels_vector = np.array(labels_vector)
return feature_vector, labels_vector
def objective(trial):
# 读取数据
seed = 26
# Prepare the data
path_origin = '../data/WildBlueberryPollinationSimulationData.csv'
path_train = '../data/train.csv'
path_test = '../data/test.csv'
x_train, y_train, x_val, y_val, x_test, y_test = dataset.processing_data(path_train, path_test, path_origin)
train_ds=(x_train,y_train)
val_ds=(x_val,y_val)
#-----------------------------参数--------------------------------------
#固定参数
device='cuda'
drop_last = False
epochs=500
patience = 15
min_change = 0.0001
beta1 = 0.9
beta2 = 0.99
hidden_dims=[256,512,256]
#需要调整的参数
batch_size=trial.suggest_categorical('batch_size',[64,128,256,512,1024])
lr=trial.suggest_float('lr', 1e-3, 1e-1)
weight_decay=trial.suggest_float('weight_decay',1e-8, 1e-3)
# compute parameters
input_size = train_ds[0].shape[1]
input_dim = input_size
n_hidden_layers=len(hidden_dims)
#-----------------------------------------------------------------------
train_set = dataset.MyDataset(train_ds)
val_set = dataset.MyDataset(val_ds)
train_loader = torch.utils.data.DataLoader(dataset=train_set, batch_size=batch_size, shuffle=True,drop_last=drop_last)
eval_loader = torch.utils.data.DataLoader(dataset=val_set, batch_size=batch_size, shuffle=True,drop_last=drop_last)
# 模型参数
params = {
'activation':nn.ReLU(),
'dropout_prob':0,
'n_hidden_layers': n_hidden_layers,
'input_dim': input_dim,
'hidden_dims': hidden_dims,
'output_dim': 1
}
# 定义模型
my_model=Encoder(**params)
my_model.to(device)
# 优化器
optimizer = torch.optim.Adam(my_model.parameters(), lr=lr, betas=(beta1, beta2),weight_decay=weight_decay)
lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer=optimizer,
mode='min',
patience=10,
factor=0.1,
min_lr=1e-5,
verbose=True)
# loss function
criterion = torch.nn.L1Loss()
early_stopper = EarlyStopping(patience=patience, min_delta=min_change)
min_mae=np.inf
for epoch in range(1, epochs + 1):
loss_train_epoch = step_epoch(my_model,optimizer, train_loader, criterion,mode='train',device=device)
loss_eval_epoch = step_epoch(my_model,optimizer, eval_loader, criterion, mode='val',device=device)
predict_labels, true_label = predict_epoch(my_model,eval_loader,device)
MSE = mean_squared_error(true_label, predict_labels)
MAE = mean_absolute_error(true_label, predict_labels)
if MAE<min_mae:
min_mae=MAE
print(
f'Epoch:{epoch}/{epochs}\tloss_train_epoch:{loss_train_epoch}\tloss_eval_epoch:{loss_eval_epoch}\tMAE:{MAE}\tMSE:{MSE}')
# Update learning rate scheduler and check early stoopping criterun
lr_scheduler.step(loss_eval_epoch)
early_stopper(loss_eval_epoch)
if early_stopper.early_stop:
break
return min_mae
if __name__ == '__main__':
# study = optuna.create_study(storage='path', study_name='first', pruner=optuna.pruners.MedianPruner())
study = optuna.create_study(study_name = 'mlp-rgb2', direction = 'minimize', sampler = optuna.samplers.TPESampler(), storage = 'sqlite:///db.sqlite3')
study.optimize(objective, n_trials=100)
print("Study statistics: ")
print(" Number of finished trials: ", len(study.trials))
print("Best trial:")
trial = study.best_trial
print(" Value: ", trial.value)
print(" Params: ")
for key, value in trial.params.items():
print("{}:{}".format(key, value))
7.训练结果:

三、optuna dashboard可视化
程序运行完成之后可以在项目中看到生成了一个db.sqlite的文件
1.安装optuna-dashboard
pip install optuna-dashboard2.打开anaconda-prompt,切换到当前目录下(即db.sqlite目录下),激活解释器环境,输入以下命令启动dashboard:
![]()


optuna-dashboard sqlite:///db.sqlite3
3.浏览器输入
http://127.0.0.1:8080/dashboard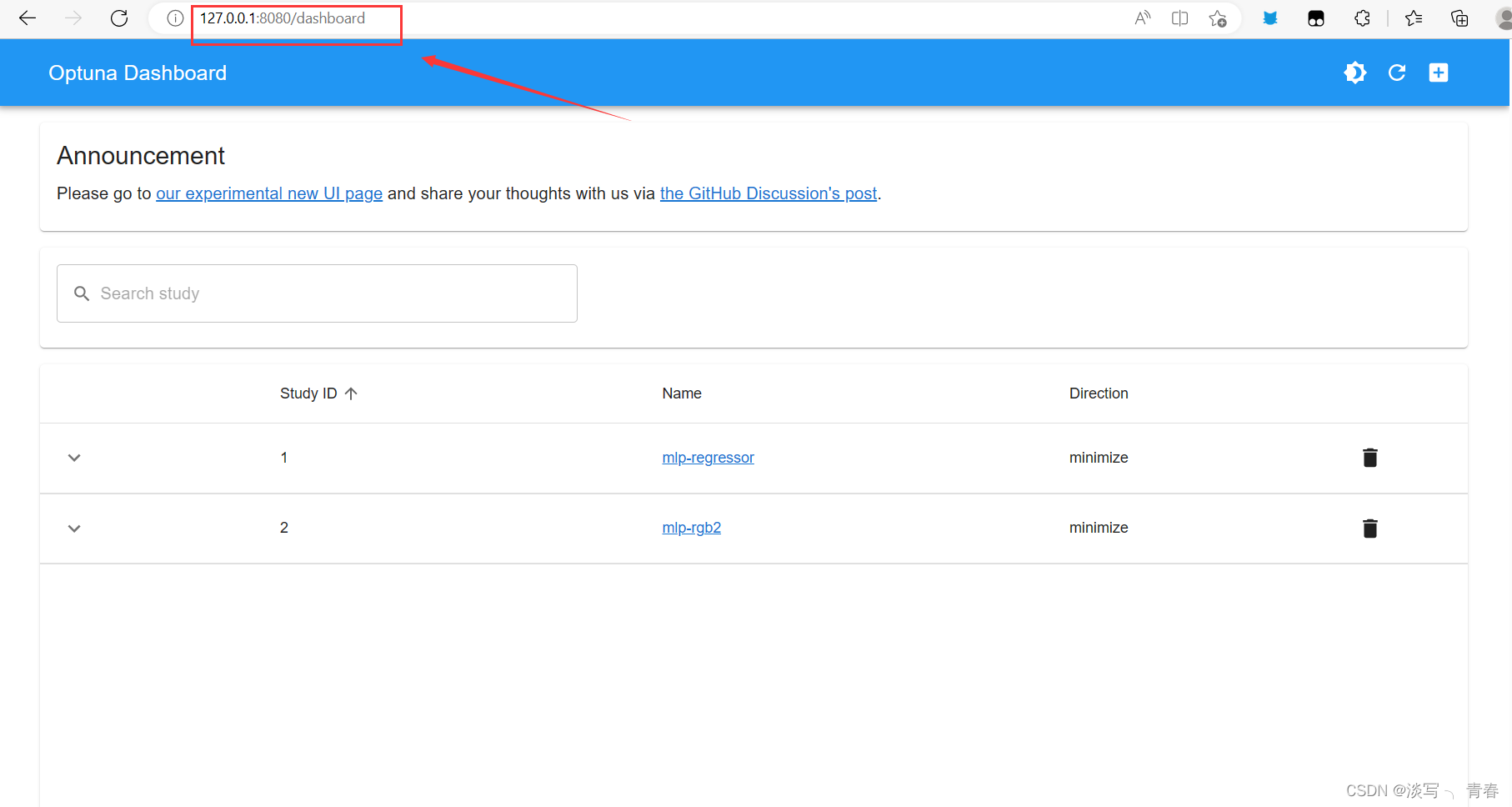
4.点开mlp-regressor可以看到以下内容:(这个和tensorboard是类似的)
4.1损失与试验次数的关系

4.2参数组合
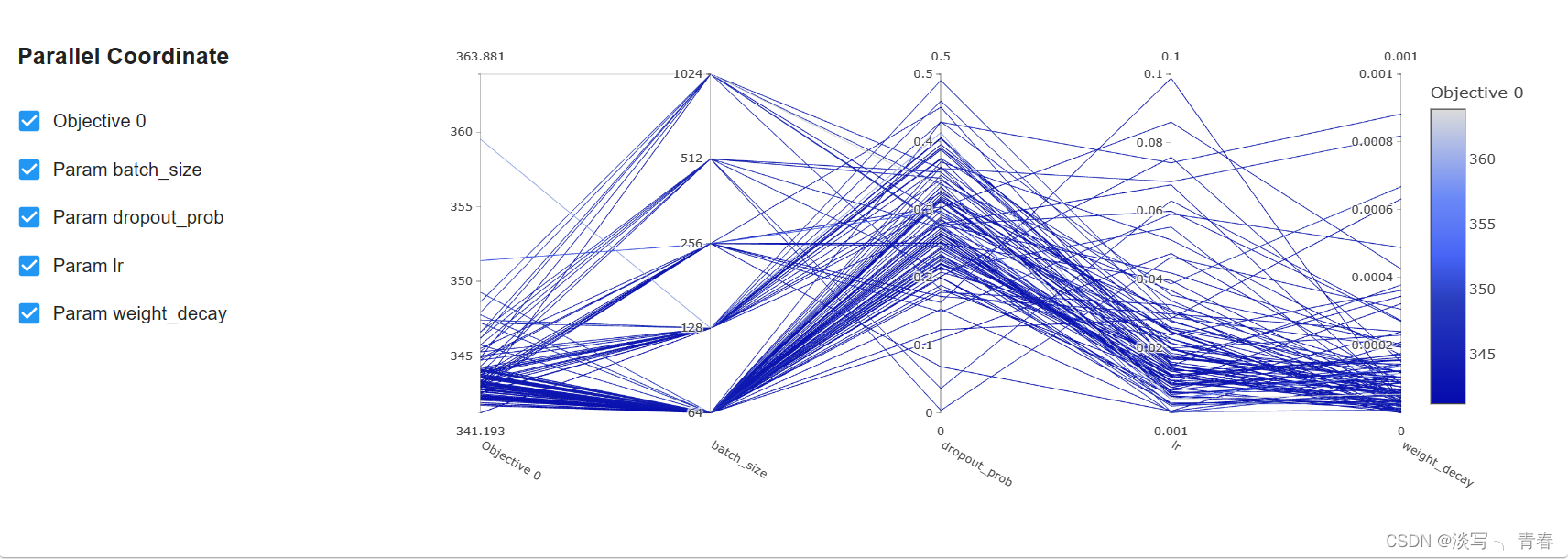

4.3累积概率图
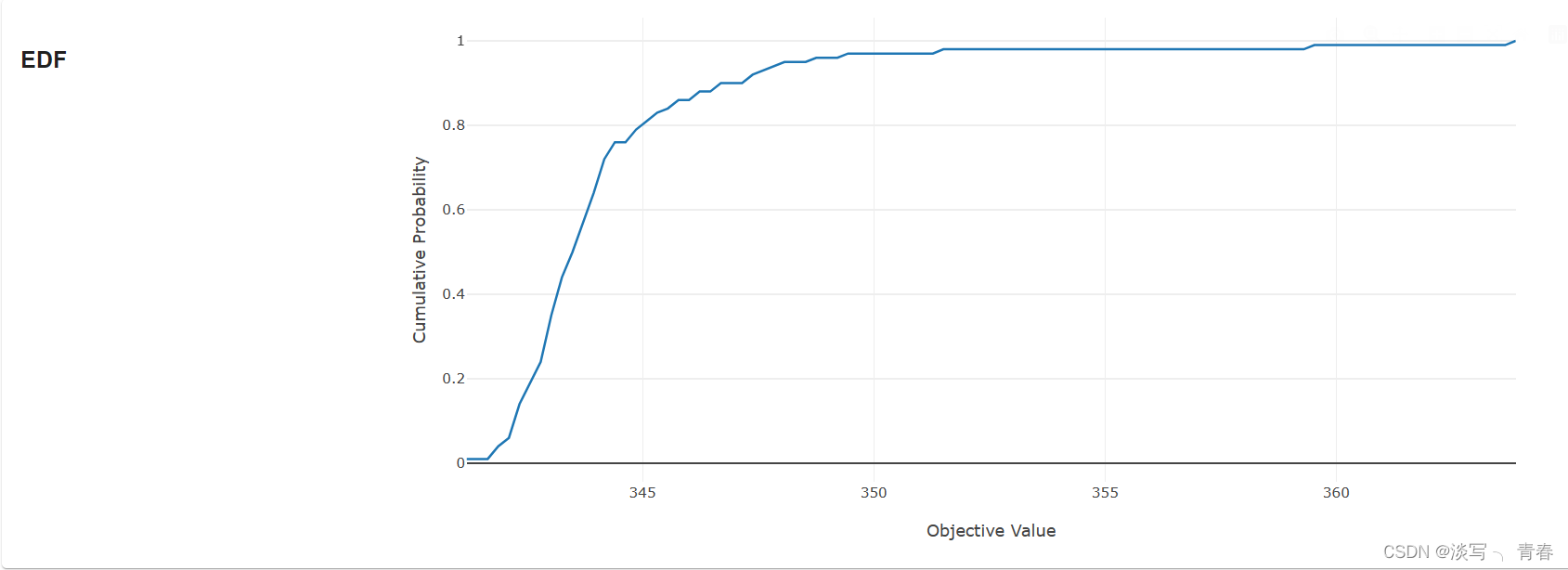
4.4等高线图
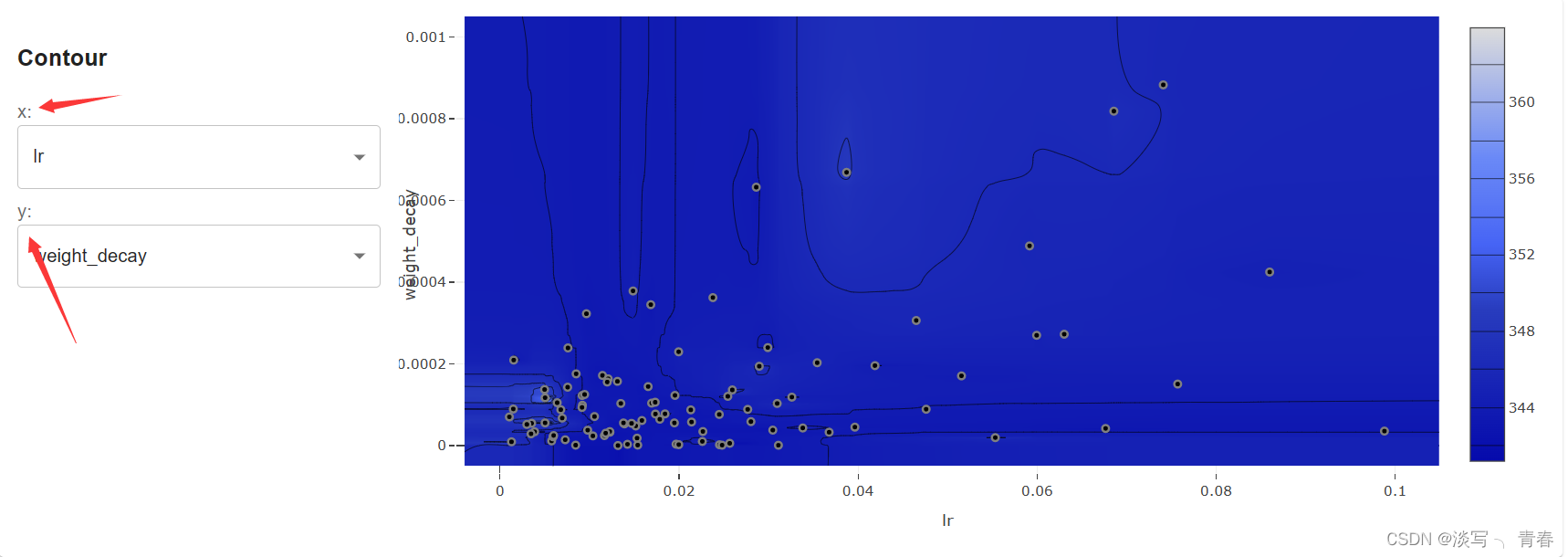
当然也可以手动调用,在 study.optimize 执行结束以后,通过调用 optuna.visualization.plot_contour,并将 study 和需要可视化的参数传入该方法,Optuna 将返回一张等高线图。如果要查看参数 x 和 y 的关系以及它们对于函数值贡献的话,只需要执行下面的语句即可:
optuna.visualization.plot_contour(study, params=['x', 'y'])
# 如果不指定 params 也是可以的,optuna 将画出所有的参数之间的关系,在这里两者等价。
optuna.visualization.plot_contour(study)4.5参数重要性图
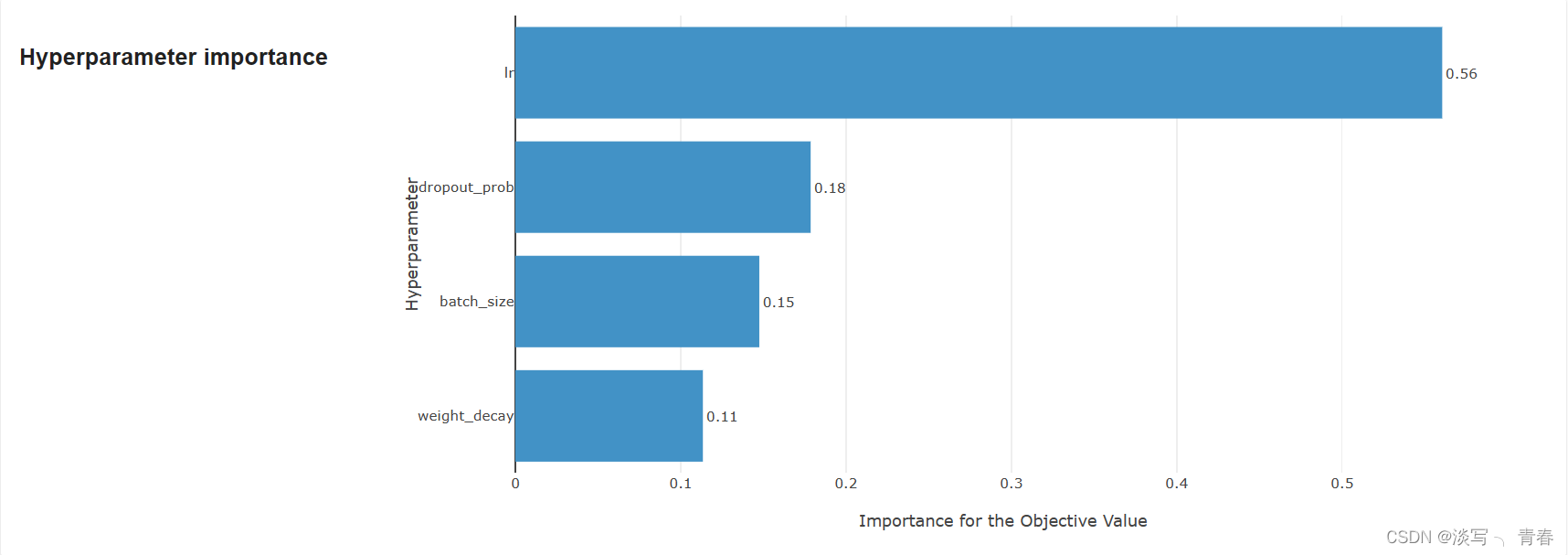
这是这些图中非常重要的一个了,通过该图我们可以知道哪些参数对模型性能的影响较大,对于那些不重要的参数就没必要调整了。
4.6参数采样图
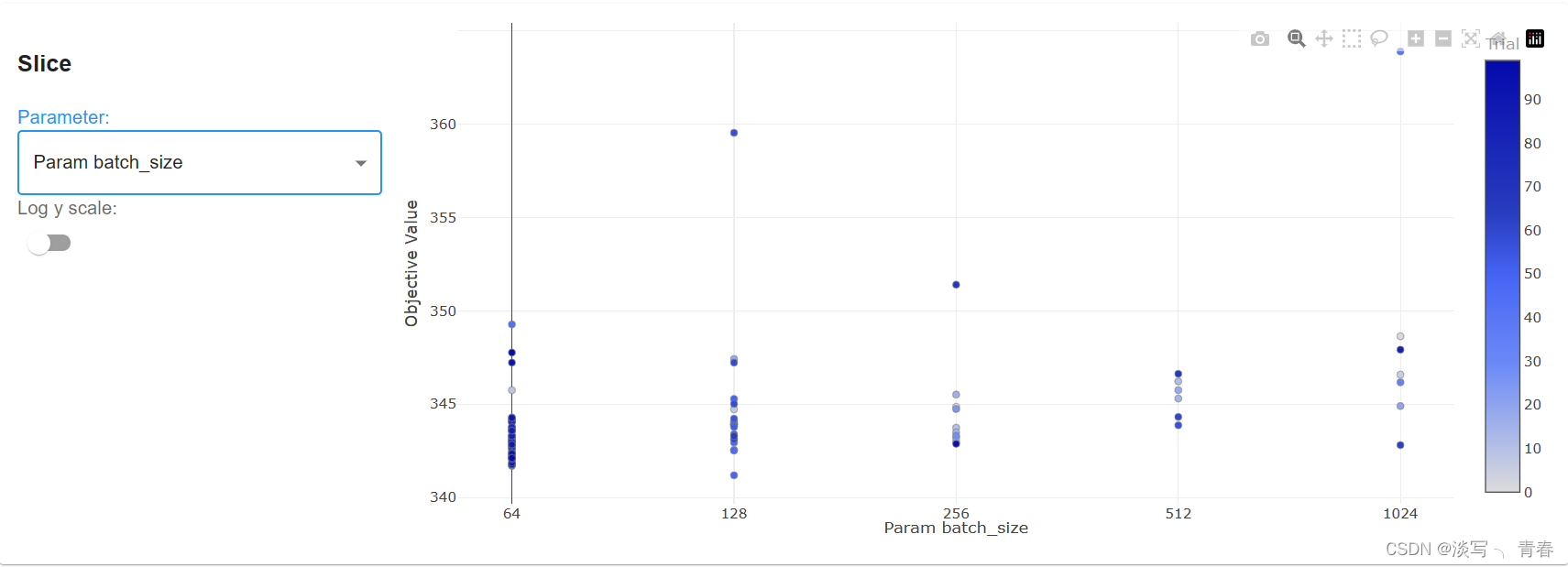
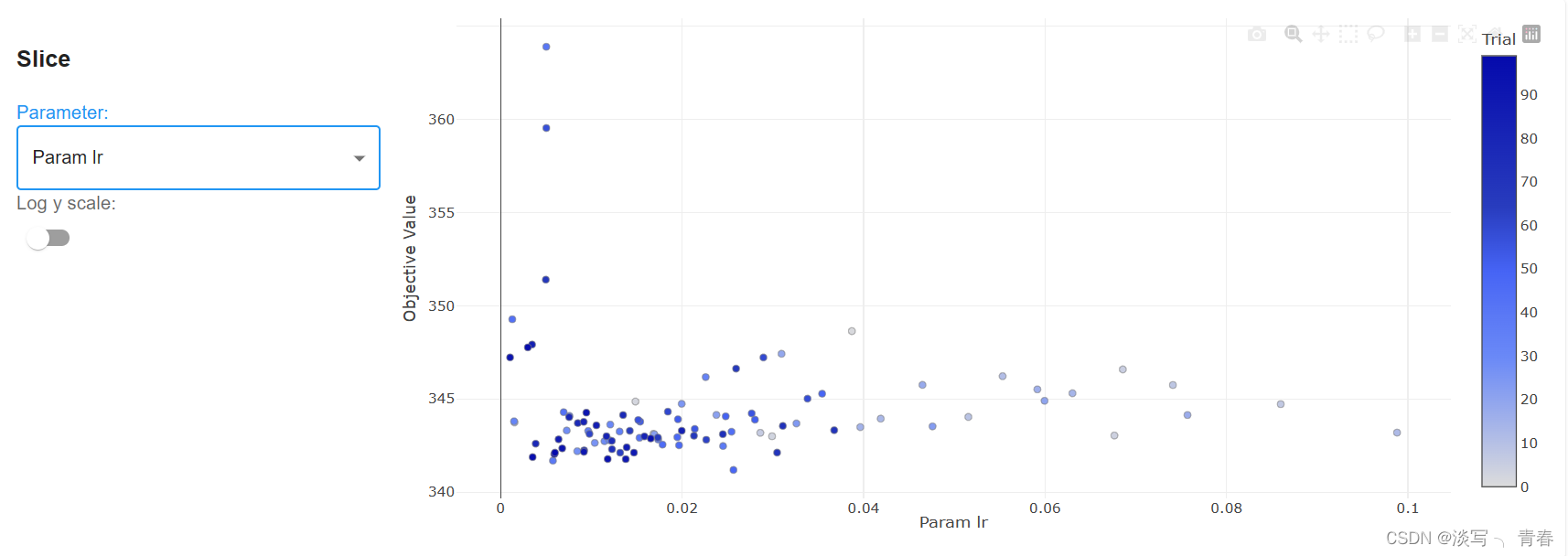
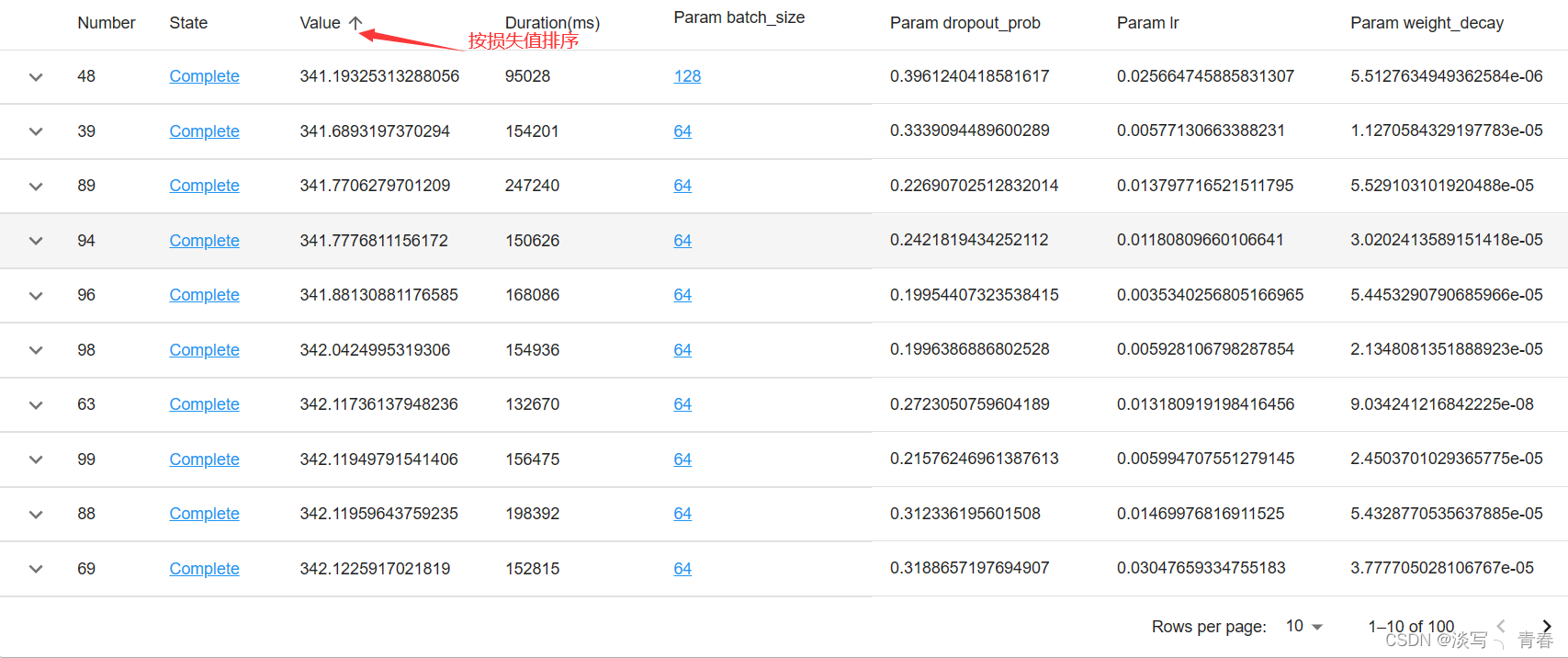
4.7参数组合结果表
总结
不足之处还望及时批评指正呀!















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









