






0 简介
1.学习目标
两大核心模块:深度学习经典算法与Tensorflow项目实战
从零开始,详细的网络模型架构与框架实现方法
2.tensorflow:核心开源库,深度学习框架,帮助开发和训练机器学习模型
3.版本2比1有哪些优势
- 2版本并不是难度增大,而是简化了建模的方法和步骤,比1.0更简单实用,难度更小;
- 终于把Keras API当作核心(简单多多多了)
- 跨平台,各种现成模型,eager mode使得调试起来不那么难受了
4.深度学习入门和进阶最好的方法
- 多练习,多试验
- 看论文复现代码和调试的过程-->提升最快的途径
1 Tensorflow2版本安装方法
1.安装anaconda:大部分都已经安装,没安装找个教程安装
2.安装tensorflow
①CPU版本 pip install tensorflow
②GPU版本pip install tensorflow-gpu,需要配置好cuda 10版本(去cuda官网中)
如果安装失败的可以手动安装,先下载.whl文件tensorflow-gpu · PyPI
进行安装 pip install xxx.whl
安装后可以简单试试
import tensorflow as tf
import numpy as np
tf.__version__
2 tf基础操作
边用边查,知道常用的就ok,不用死记很多。
矩阵
x=tf.constant([[1,9],[3,6]])机器学习中一切数据都是矩阵,所以我们是对矩阵进行操作的。
Tensor是啥,可以指定任意的维度(值,向量,矩阵),记住是可以进行GPU加速计算的矩阵就可以。
x1=np.ones([2,2])
x2=tf.multiply(x1,2)3 深度学习要解决的问题
AI(人工智能)>ML(机器学习)>DL(深度学习)

机器学习绝大多数是偏人工
深度学习:让网路深度自己去学习,最大程度是解决特征工程的问题
1.机器学习流程
数据获取------特征工程------建立模型------评估和应用
最重要的是特征工程
2.特征工程的作用
- 数据特征决定了模型的上限
- 预处理和特征提取是最核心的
- 算法和参数选择决定了如何逼近这个上限
3.特征提取方法
- 传统方法
- 深度学习:可看为一个黑盒子,自己去学习,有一个学习的过程,什么样的特征是它认为是最合适的
4 深度学习应用领域
1. 应用
图像和文本中用的比较多。
- 无人驾驶(检测和识别)
- 面部识别(关键点检测和定位)
- 医学(癌细胞检测,基因怎么组合,DNA怎么组合)
- 变脸:神经网络来做不难,直播换脸,人脸就是像素点,只需要替换相应的像素点
- 分辨率重构:老照片上色
2.问题
不太支持移动端,参数太大,速度太慢了
3.数据
ImageNet:大型数据集ImageNet (image-net.org)

1w数据---->100w数据:进行数据增强(翻转、放大、缩小)
5 计算机视觉任务
1.图像分类任务
图像表示:计算中眼中的图片。就是一个矩阵,矩阵中有一些值。一张图片被表示成三维数组的形式,每个像素的值从0-255.如300*100*3。
h=3表示颜色通道(RGB)
2.问题
- 照射角度
- 形状改变
- 部分遮蔽
- 背景混入
3.机器学习常规套路
①手机数据并给定标签
②训练一个分类器 train()
③测试,评估 predict()
6 视觉任务中遇到的问题
1.传统算法
K近邻算法
①思路

- 数据
- 绿色是属于方块还是三角?看周围什么多,就属于什么类。
- K=3和K=5得到的结果是不同的
②计算流程
- 计算已知类别数据集中的点与当前点的距离
- 按照距离依次排序
- 选取与当前点距离最小的K个点
- 确定前K个点所在类别的出现概率
- 返回前K个点出现频率最高的类别作为当前点预测分类
③k近邻可以用于一般的图像分类?
一个常用的数据集CIFAR-10。10类标签,5w训练数据,1w测试数据。大小均为32*32.
测试结果:部分可以,但是没有分类对的图像?
④K近邻分类存在的问题
效果不太好。它无法识别背景和主体。
2.神经网络
①神经网络基础
线性函数:从输入到输出的映射

线性函数也叫做得分函数。
7 得分函数
1.数学表示

b:偏置(微调)
w:权重
y=kx+b
10分类x==10,有10组权重,10组b
2.计算方法

Xi是图像分为了几个像素点。
那这个3*4的矩阵是哪里来的?随机选择,选一种优化方法,在之后的迭代中学习,得到好的参数。
3.如何评价做的好还是不好?评价分类的结果
损失函数
8 损失函数的作用
做不同的任务就是损失函数不同。


还要关注是否过拟合。

神经网络的缺点:太强大了,越强大的模型过拟合的风险越大。
9 前向传播的整体流程

到这里,我们得到的还是一个得分。如何进行分类呢?
我希望得到一个概率值,把得分值转为概率值。

回归任务:计算一个值
分类任务:计算Loss,得到一个概率
10 反向传播计算方法
1.梯度下降

这个W,,其实就是数据怎么变,认为数据的什么部分是重要的。

链式法则:梯度是一步一步传的。
2.反向传播的几个门单位
加法门单元:均等分配
MAX门单元:给最大的,
乘法门单元:互换的感觉
3神经网络整体架构

上图只关注右边的数学模型就可以。

11 神经网络架构细节
hidden layer: 神经网络是一个黑盒子,中间进行各种变化。


神经网络的强大:神经网络层数多,参数就多。
12 神经元个数对结果的影响
神经元越多过拟合的可能性越大。

神经元数量对结果的影响,理论上越多越好,但是需要考虑过拟合的问题。

13 正则化与激活函数
1.正则化的作用
惩罚力度,当较小的时候奇形怪状的边界;较大时,边界较平滑。
(模型如何弱一点)

2.激活函数


sigmoid:一旦结果过大或者过小,就会出现梯度消失。(因为参数传统是乘法,当梯度为0,会影响后面的结果)
14 神经网路过拟合解决方案
数据标准化:中心化


参数初始化:权重参数给一个随机值。
乘0.01:得到的初始化的值都是比较小的

神经网络一直在解决一个问题,别让网络太强。过拟合?
训练阶段:舍弃其中的一部分,但不是就直接不用了,而是每一层,随机选择一部分杀死。
测试阶段:不用杀死

神经网络要做一件事:什么样的权重参数适合于当前的任务。
15 实操
相关资料获取链接:
网盘地址:https://pan.baidu.com/s/1DLaID5U_wUGY0AwiWp3BqA?pwd=v0oh
提取密码:v0oh
15.1 任务目标
15.1.1 回归问题
1 任务目标与数据集简介
气温预测数据集,根据输入的x,构建一个网络模型,输出合适的y,y是实际的气温。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import layers
import tensorflow.keras
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline#读数据
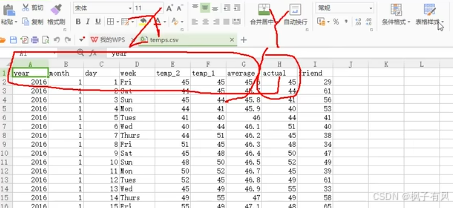
features=pd.read_csv('temps.csv')
#看看数据长什么样子
features.head()
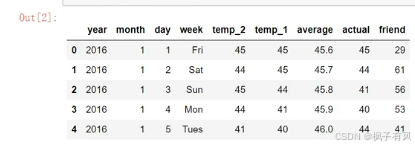
print('数据维度:',features.shape)
数据维度:(348,9)
ps:数据比较小,348条,共有9个特征
#处理时间数据
import datetime
#分别得到年月日
years=features['year']
months=features['month']
days=feartures['day']
#datetime格式
dates=[str(int(year))+'-'+str(int(month))+'-'str(int(day)) for year,month,day in zip(years,months,days)]
dates=[datetimt.datetime.strptime(data,'%Y-%m-%d') for date indates]
dates[:5]
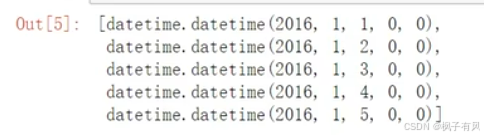

上面代码进行数据展示
建模之前把数据转成一种数值的特征。比如上面的数据周几是字符串类型,是不好处理的,需要进行coding.

#独热编码
features=pd.get_dummies(features)
features.head(5)

有了数值数据之后,需要把x和y都指定好。
labels就是actual实际值
#标签
labels=np.array(features['actual'])
#在特征中去掉标签
features=features.drop('actual',axis=1)
#名字单独保存一下,以备后患
features_list=list(features.columns)
#转换成合适的格式
features=np.array(features)对数据做预处理
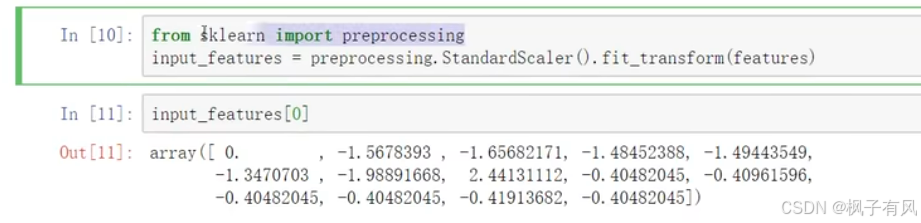
2 建模流程与API文档

比如有15个输入特征
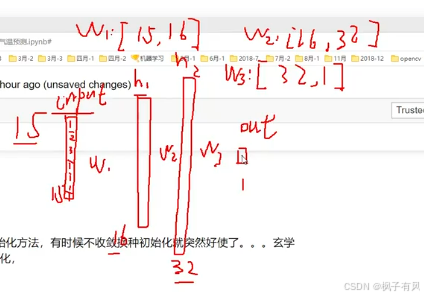
在tensorflow1中需要w1,w2,w3,但是2.0版本中不用自己指定,网络已经自己定义好了
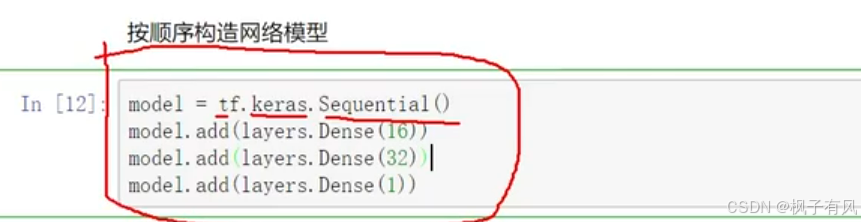
其中layer.Dense是全连接层(wx+b),具体用什么要查看官网tensorflow.google.cn中的api

比如下面的。(注意:写代码就是多查多写多练)
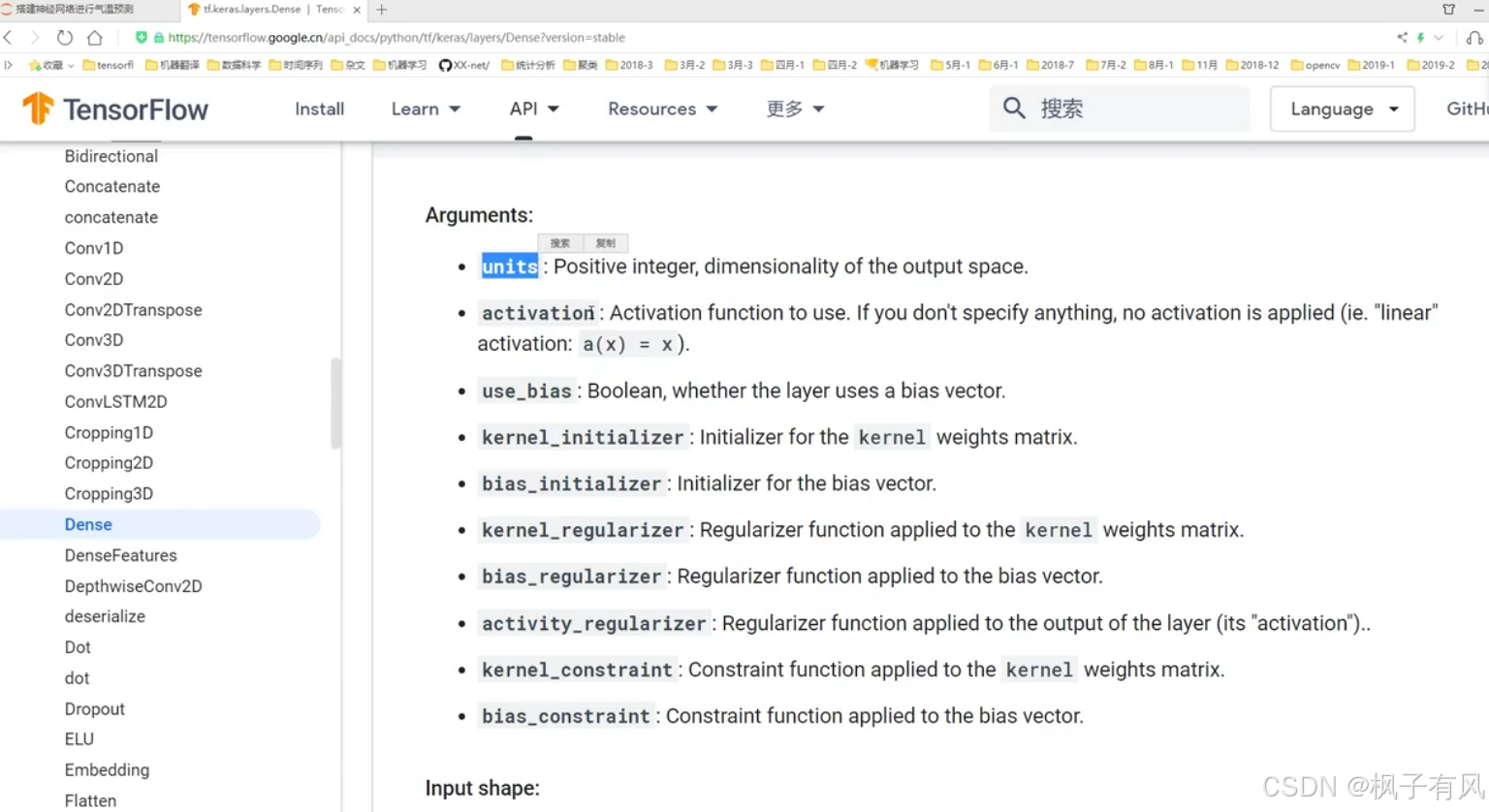
优化器有很多可以选择
3 网络模型训练
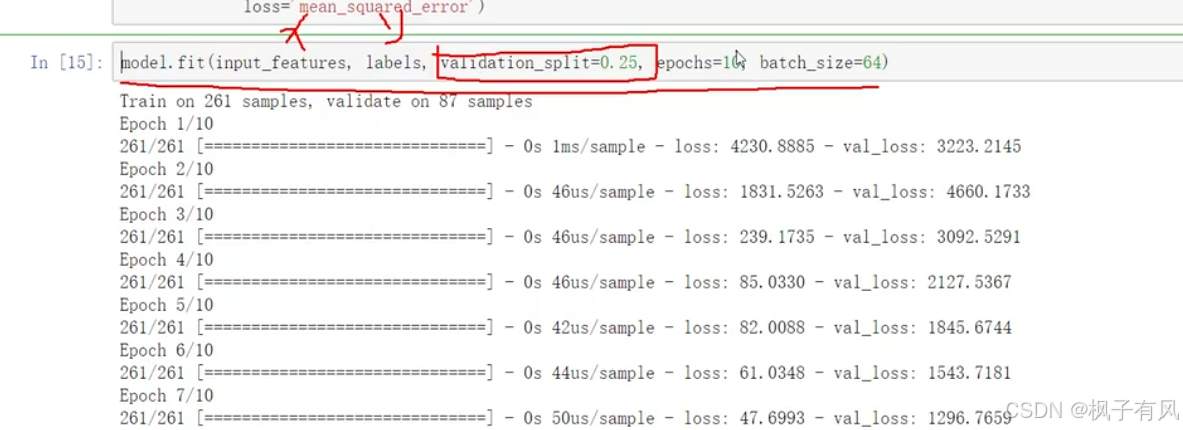
上面运行结果可以看到训练集上的loss和验证集上的差别还是较大的,说明模型过拟合了。
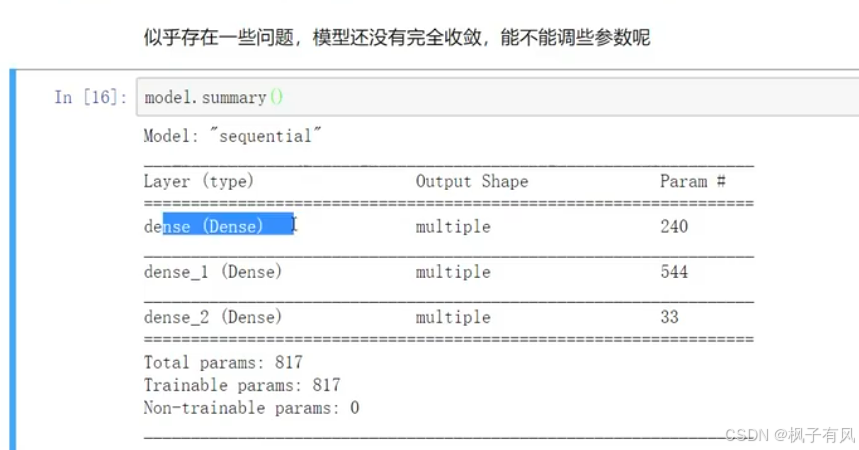
4 模型超参数与预测结果展示
对上面的模型进行改进
①改进初始化方法
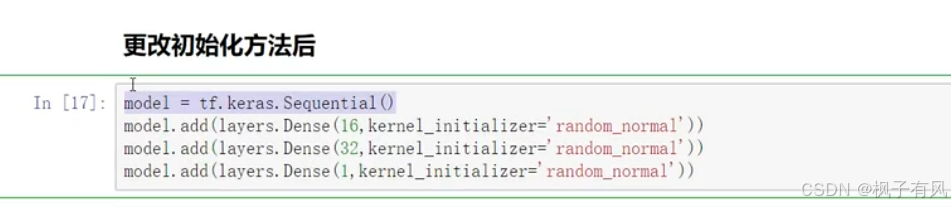
其他的代码不变,得到的训练结果如下
一般都用别人训练好的,不用大规模的调参。
②加入正则化惩罚项
最后得到的结果
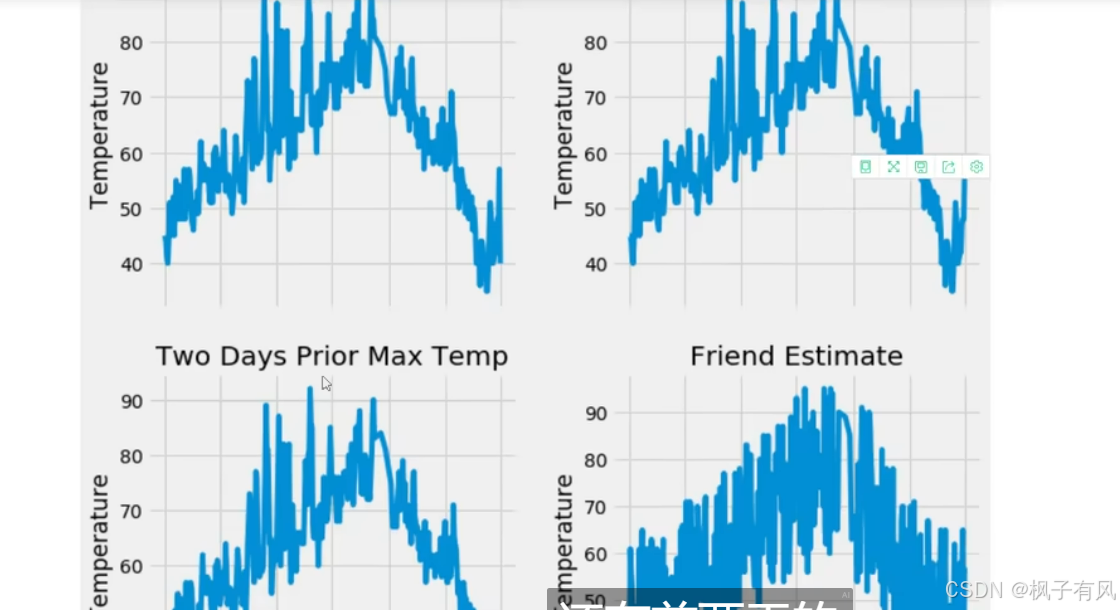
预测结果
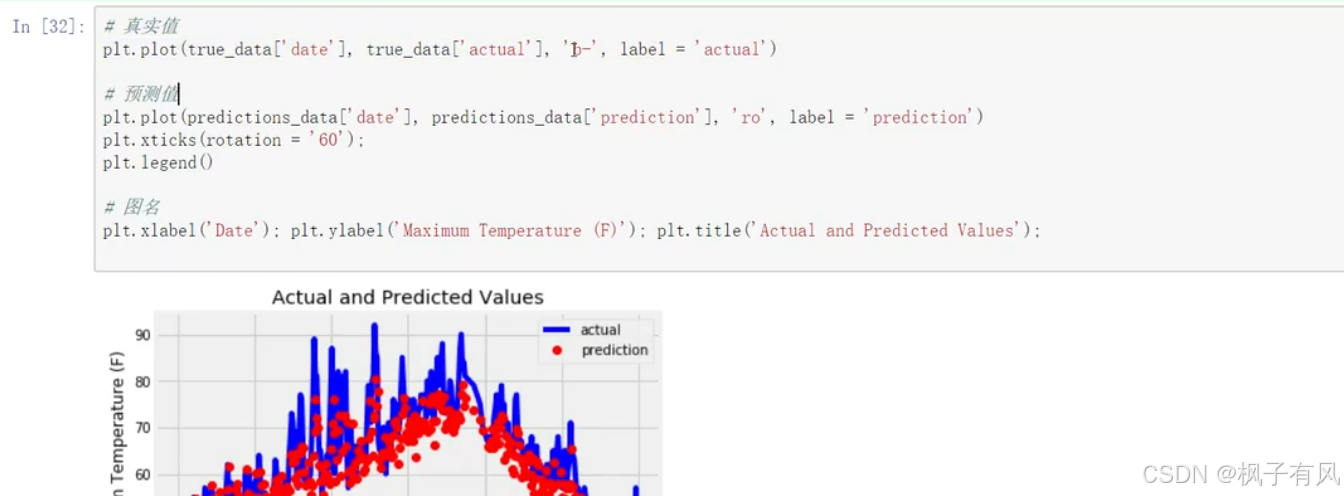
结果可视化如下:
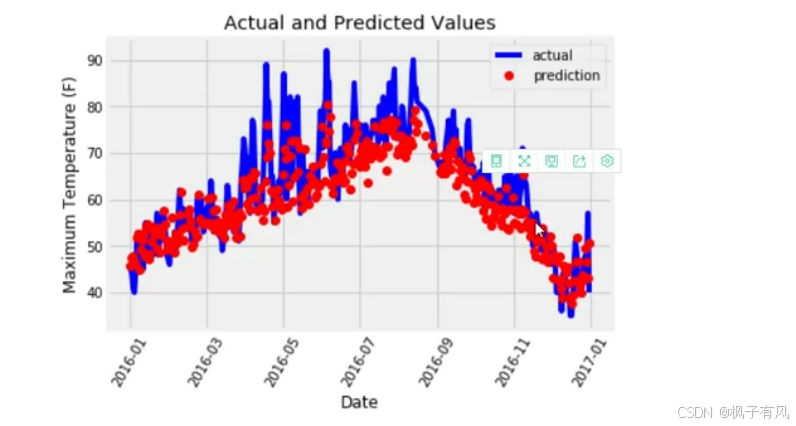
以上是一个基于tensorflow2的回归问题的预测。
15.1.2 分类问题
1. 分类模型建构

用GPU或者CPU
加载数据集Mnist
Mnist数据集的展示
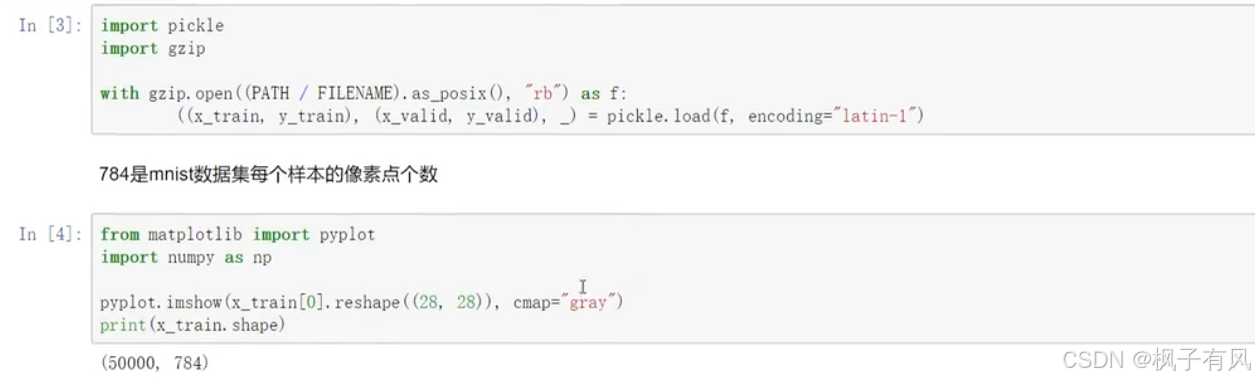
数据是28*28的灰度图片
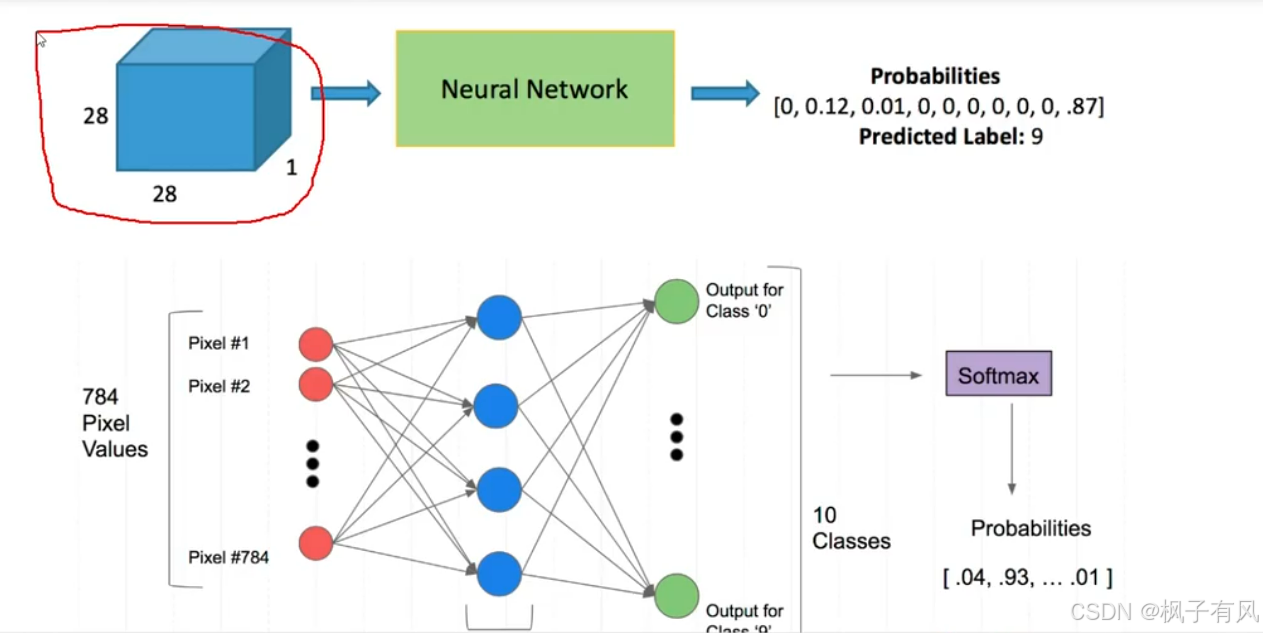
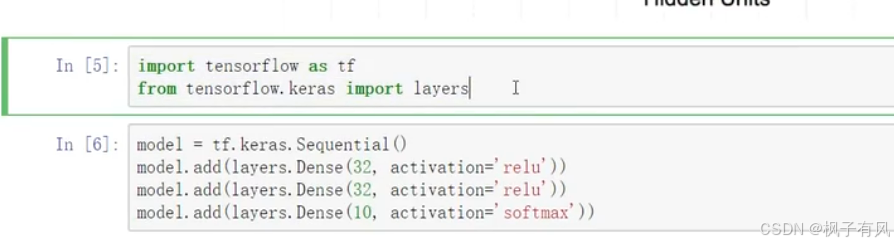
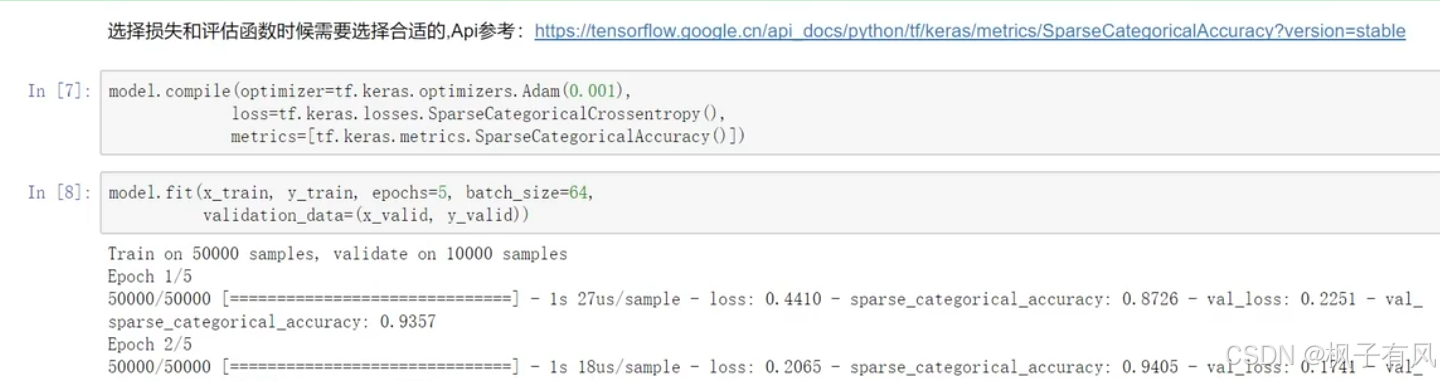
注:一定要选择合适的损失函数,针对不同的任务选择不同的损失函数。要根据输入数据的格式选择合适的损失函数。
不同任务就是损失函数和评估函数不同而已。
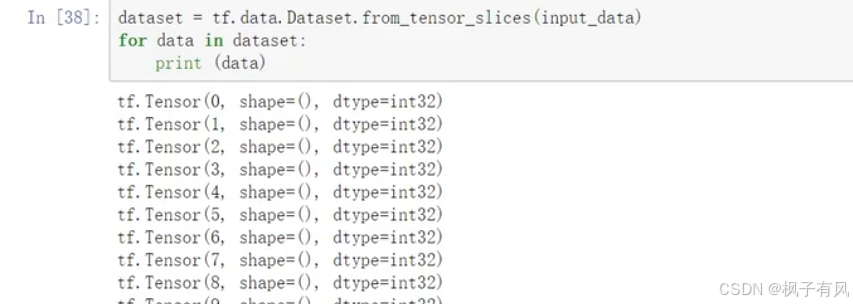
2. tf.data模块解读

利用里面的tf.data.Dateset将数据全部转为为一个tensor格式。
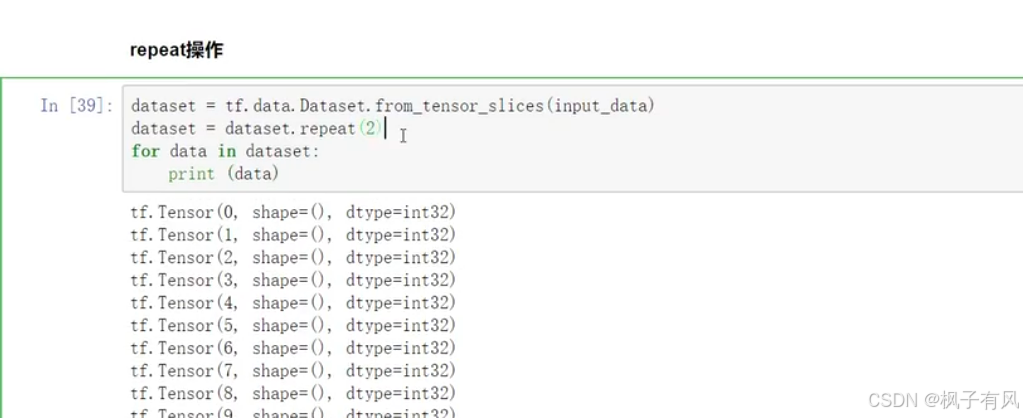
将数据集重复构建多少次,构建成我们的输入数据。
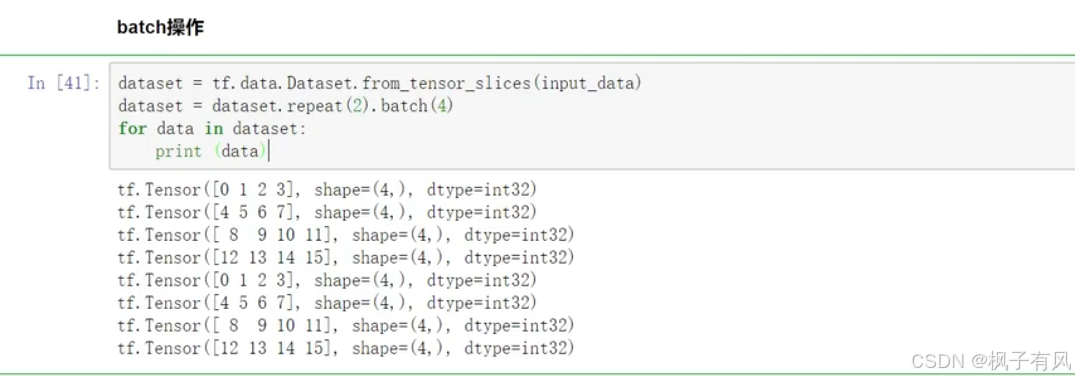
batch操作16*2=32/4=8,每次batch8个
下面进行相当于洗牌的操作
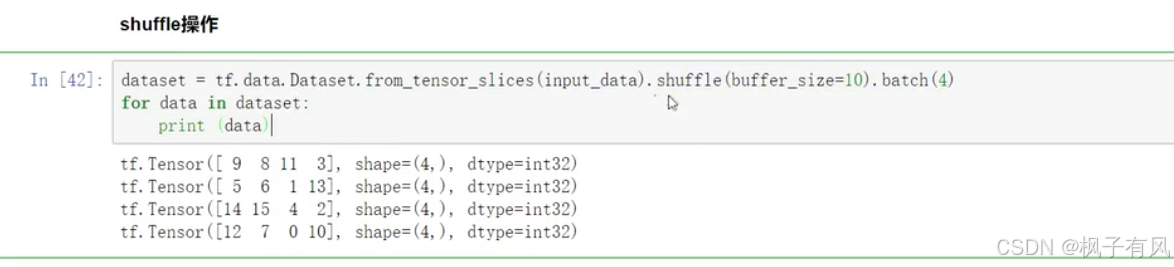
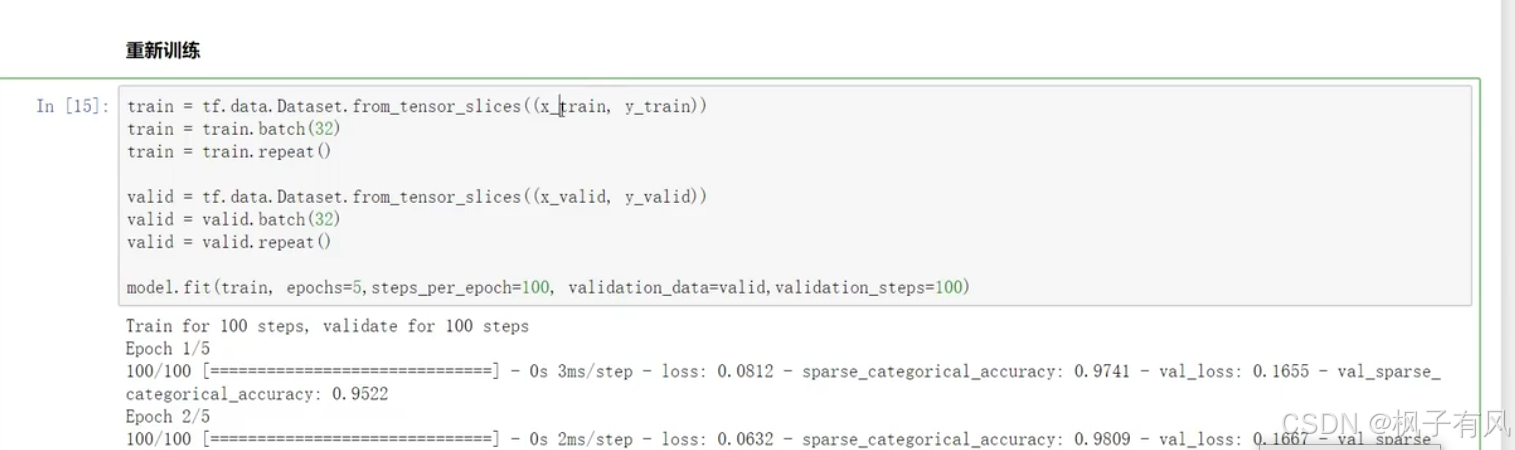
.fit操作是将你的训练集指定出来,验证集也指定出来,以及迭代多少遍,以及跑每一遍里面跑多少次。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









