







在信息论中,随机离散事件出现的概率存在着不确定性。为了衡量这种信息的不确定性,信息学之父香农引入了信息熵的概念,并给出了计算信息熵的数学公式:
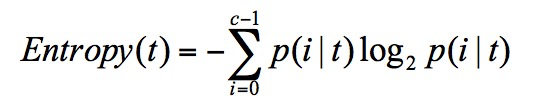
p(i|t) 代表了节点 t 为分类 i 的概率,其中 log2 为取以 2 为底的对数。这里我不是来介绍公式的,而是说存在一种度量,它能帮我们反映出来这个信息的不确定度。当不确定性越大时,它所包含的信息量也就越大,信息熵也就越高,当确定性越大时,则相反。
基尼系数,它是用来衡量一个国家收入差距的常用指标。当基尼系数大于 0.4 的时候,说明财富差异悬殊。基尼系数在 0.2-0.4 之间说明分配合理,财富差距不大。基尼系数本身反应了样本的不确定度。当基尼系数越小的时候,说明样本之间的差异性小,不确定程度低。分类的过程本身是一个不确定度降低的过程,即纯度的提升过程。
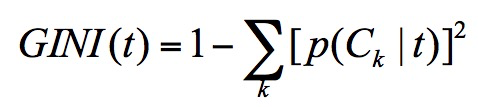
# 导入相关处理包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取候选人信息,由于原始数据没有表头,需要添加表头
candidates = pd.read_csv("weball20.txt", sep = '|',names=['CAND_ID','CAND_NAME','CAND_ICI','PTY_CD','CAND_PTY_AFFILIATION','TTL_RECEIPTS',
'TRANS_FROM_AUTH','TTL_DISB','TRANS_TO_AUTH','COH_BOP','COH_COP','CAND_CONTRIB',
'CAND_LOANS','OTHER_LOANS','CAND_LOAN_REPAY','OTHER_LOAN_REPAY','DEBTS_OWED_BY',
'TTL_INDIV_CONTRIB','CAND_OFFICE_ST','CAND_OFFICE_DISTRICT','SPEC_ELECTION','PRIM_ELECTION','RUN_ELECTION'
,'GEN_ELECTION','GEN_ELECTION_PRECENT','OTHER_POL_CMTE_CONTRIB','POL_PTY_CONTRIB',
'CVG_END_DT','INDIV_REFUNDS','CMTE_REFUNDS'])
# 读取候选人和委员会的联系信息
ccl = pd.read_csv("ccl.txt", sep = '|',names=['CAND_ID','CAND_ELECTION_YR','FEC_ELECTION_YR','CMTE_ID','CMTE_TP','CMTE_DSGN','LINKAGE_ID'])
# 关联两个表数据
ccl = pd.merge(ccl,candidates)
# 提取出所需要的列
ccl = pd.DataFrame(ccl, columns=[ 'CMTE_ID','CAND_ID', 'CAND_NAME','CAND_PTY_AFFILIATION'])
# 读取个人捐赠数据,由于原始数据没有表头,需要添加表头
# 提示:读取本文件大概需要5-10s
itcont = pd.read_csv('itcont_2020_20200722_20200820.txt', sep='|',names=['CMTE_ID','AMNDT_IND','RPT_TP','TRANSACTION_PGI',
'IMAGE_NUM','TRANSACTION_TP','ENTITY_TP','NAME','CITY',
'STATE','ZIP_CODE','EMPLOYER','OCCUPATION','TRANSACTION_DT',
'TRANSACTION_AMT','OTHER_ID','TRAN_ID','FILE_NUM','MEMO_CD',
'MEMO_TEXT','SUB_ID'])
# 将候选人与委员会关系表ccl和个人捐赠数据表itcont合并,通过 CMTE_ID
c_itcont = pd.merge(ccl,itcont)
# 提取需要的数据列
c_itcont = pd.DataFrame(c_itcont, columns=[ 'CAND_NAME','NAME', 'STATE','EMPLOYER','OCCUPATION',
'TRANSACTION_AMT', 'TRANSACTION_DT','CAND_PTY_AFFILIATION'])
#空值处理,统一填充 NOT PROVIDED
c_itcont['STATE'].fillna('NOT PROVIDED',inplace=True)
c_itcont['EMPLOYER'].fillna('NOT PROVIDED',inplace=True)
c_itcont['OCCUPATION'].fillna('NOT PROVIDED',inplace=True)
# 对日期TRANSACTION_DT列进行处理
c_itcont['TRANSACTION_DT'] = c_itcont['TRANSACTION_DT'] .astype(str)
# 将日期格式改为年月日 7242020
c_itcont['TRANSACTION_DT'] = [i[3:7]+i[0]+i[1:3] for i in c_itcont['TRANSACTION_DT'] ]
# 从所有数据中取出支持拜的数据
biden = c_itcont[c_itcont['CAND_NAME']=='BIDEN, JOSEPH R JR']
# 统计各州对拜的捐款总数
biden_state = biden.groupby('STATE').sum().sort_values("TRANSACTION_AMT", ascending=False)
q=np.array(biden_state) #创建ndarray 对象
number_b=len(q) #支持拜州的数量
# 从所有数据中取出支持特朗的数据
trump = c_itcont[c_itcont['CAND_NAME']=='TRUMP, DONALD J.']
# 统计各州对特朗的捐款总数
trump_state = trump.groupby('STATE').sum().sort_values("TRANSACTION_AMT", ascending=False)
w=np.array(trump_state) #创建ndarray 对象
number_t=len(w) #支持特朗州的数量
#pivot_table作用是按职业和捐赠数额聚合数据,index=['STATE']取出捐赠人所在的职业,values=['TRANSACTION_AMT']取出捐赠人捐赠的数额,aggfunc='sum'计算相同州的总额
by_occupation=pd.pivot_table(c_itcont,index=['STATE'],values=['TRANSACTION_AMT'],aggfunc='sum')
number=len(by_occupation) #州的数量
# 从所有数据中取出支持拜的数据
biden = c_itcont[c_itcont['CAND_NAME']=='BIDEN, JOSEPH R JR']
# 统计各职业对拜的捐款总数
biden_state = biden.groupby('OCCUPATION').sum().sort_values("TRANSACTION_AMT", ascending=False)
e=np.array(biden_state) #创建ndarray 对象
# 从所有数据中取出支持特朗的数据
biden = c_itcont[c_itcont['CAND_NAME']=='TRUMP, DONALD J.']
# 统计各职业对特朗的捐款总数
biden_state = biden.groupby('OCCUPATION').sum().sort_values("TRANSACTION_AMT", ascending=False)
r=np.array(biden_state) #创建ndarray 对象
#pivot_table作用是按职业和捐赠数额聚合数据,index=['OCCUPATION']取出捐赠人所在的职业,values=['TRANSACTION_AMT']取出捐赠人捐赠的数额,aggfunc='sum'计算相同职业的总额
by_occupation=pd.pivot_table(c_itcont,index=['OCCUPATION'],values=['TRANSACTION_AMT'],aggfunc='sum')
number_j=len(by_occupation) #职业的总数量
print('州的总数:{}'.format(number))
print('支持BIDEN, JOSEPH R JR州的数量:{}'.format(number_b))
print('支持特朗州的数量:{}'.format(number_t))
print('职业的总数:{}'.format(number_j))
print('支持BIDEN, JOSEPH R JR的数量:{}'.format(len(e)))
print('支持特朗的数量:{}'.format(len(r)))
得到基本数据,我们就可以根据之前提到的香农公式and基尼系数进行数据分析了。

结论: BIDEN, JOSEPH R JR战胜TRUMP, DONALD J.赢得大选的胜率为55.5%,而TRUMP, DONALD J.战胜BIDEN, JOSEPH R JR赢得大选的胜率为45%。首先我们来看BIDEN, JOSEPH R JR的情况,BIDEN, JOSEPH R JR的两组数据一个为0,一个为0.89非常极端,一个很纯,一个很不纯,出现这种情况(可能是美国的上层社会绝大部分都支持BIDEN, JOSEPH R JR,所以他们给BIDEN, JOSEPH R JR捐赠的钱非常多,而底层大众支持BIDEN, JOSEPH R JR的不多)。TRUMP, DONALD J.的两组数据比较接近,一个为0.45,一个为0.65(应该是底层大众绝大部分都支持TRUMP, DONALD J.,而美国的上层社会支持TRUMP, DONALD J.的人比较少,这应该是TRUMP, DONALD J.获得捐赠的钱少的原因)
关于基尼系数分析大家可以访问下方链接进行查看学习,还可以在原文评论和作者交流,点击直接访问。
https://tianchi.aliyun.com/forum/postDetail?postId=138414
预测BIDEN, JOSEPH R JR和TRUMP, DONALD J.各自获得的选票数:
我们知道美国大选共有538张选票,由香农公式算得BIDEN战胜TRUMP赢得大选的胜率为55.5%;而TRUMP战胜BIDEN赢得大选的胜率为45%。
BIDEN获得选票预测:[55.5%/(55.5%+45%)]x538=297张TRUMP获得选票预测:[45%/(55.5%+45%)]x538=241张

Spaceack
Spaceack带你利用Pandas,趋势图与桑基图分析美国选民候选人喜好度。
文章地址:点击直接访问
https://tianchi.aliyun.com/notebook-ai/detail?postId=140375
1> 绘制收到捐赠额最多的两位候选人的总捐赠额变化趋势图Spaceack经过前期的数据处理后,使用 plot 方法绘制趋势图。
# c_itcont4为处理好的数据,包含三列:日期、BIDEN当日获得捐赠、TRUMP当日获得捐赠
# grid参数 用来显示后面的辅助网格线, rot 使横坐标的日期以45度排列, 不会导致产生字符过长导致叠加的问题。
c_itcont4.plot(grid=True, rot=45)
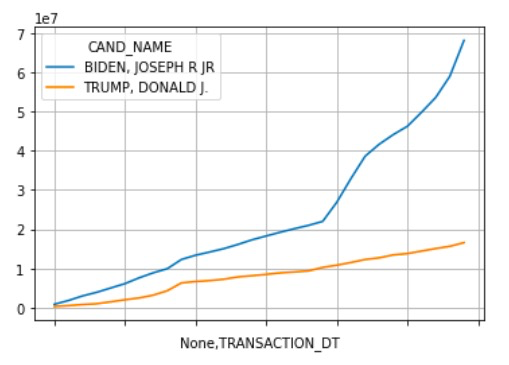
由趋势图可以看出,在7月22日至8月20日期间,拜登收到的捐款总额明显高于特朗普。且在8月份有更为显著的变化。
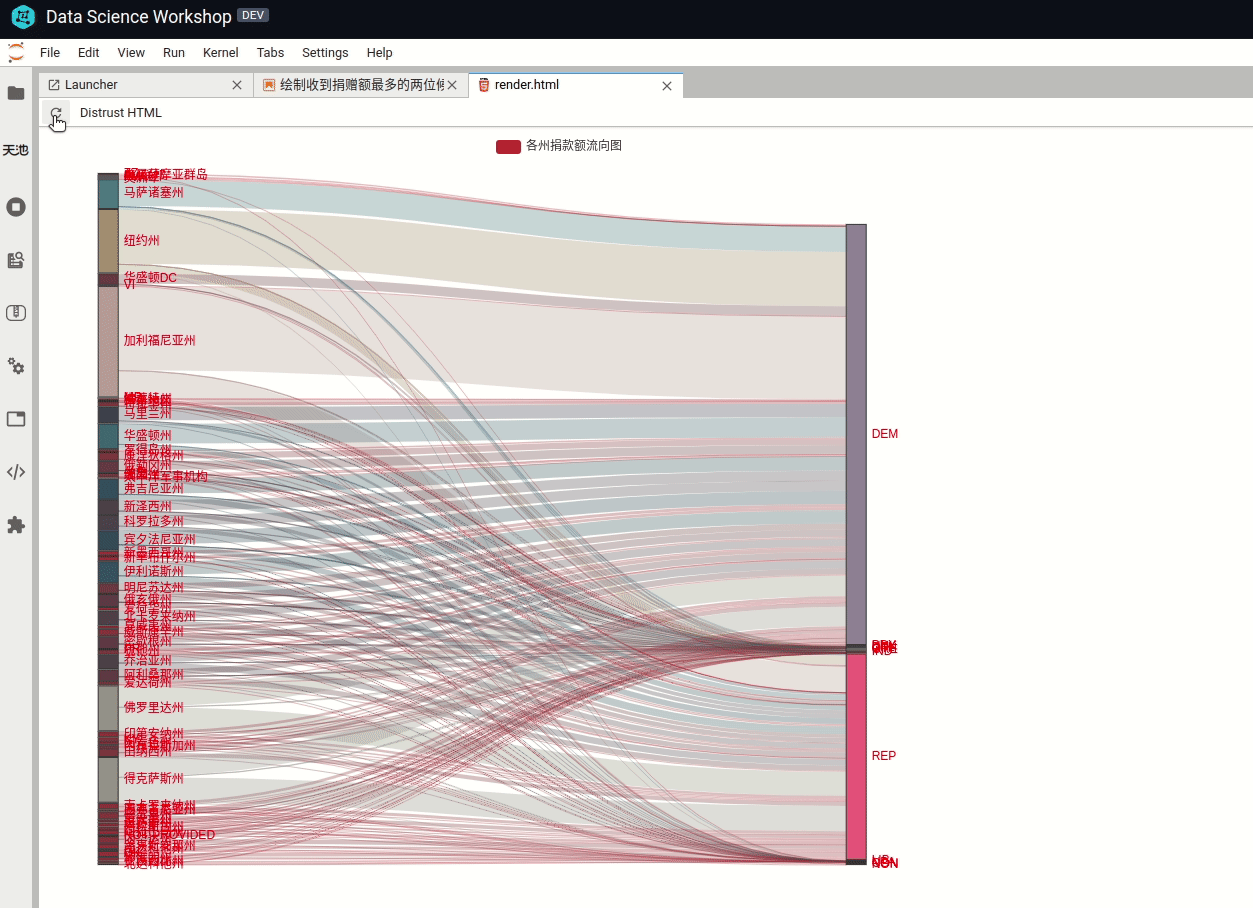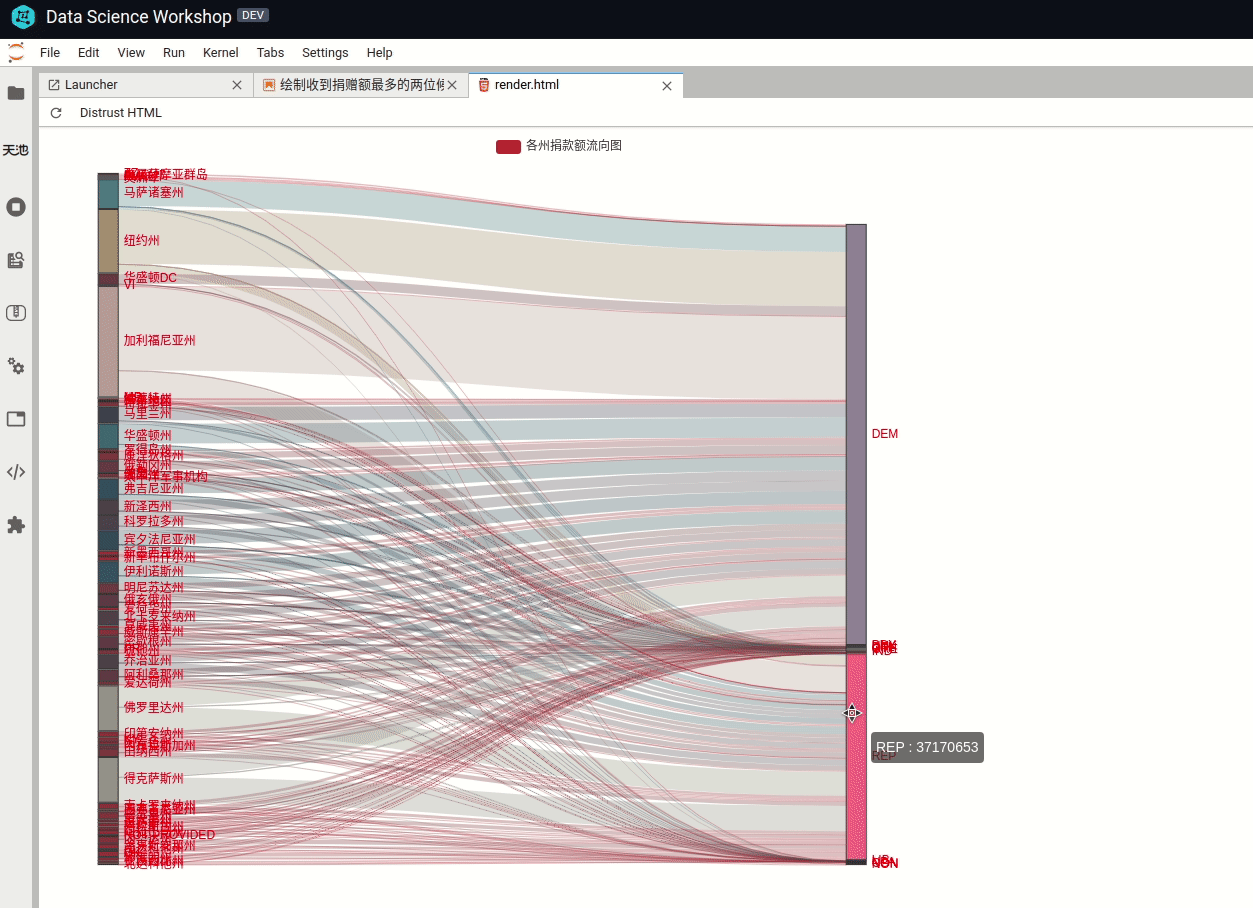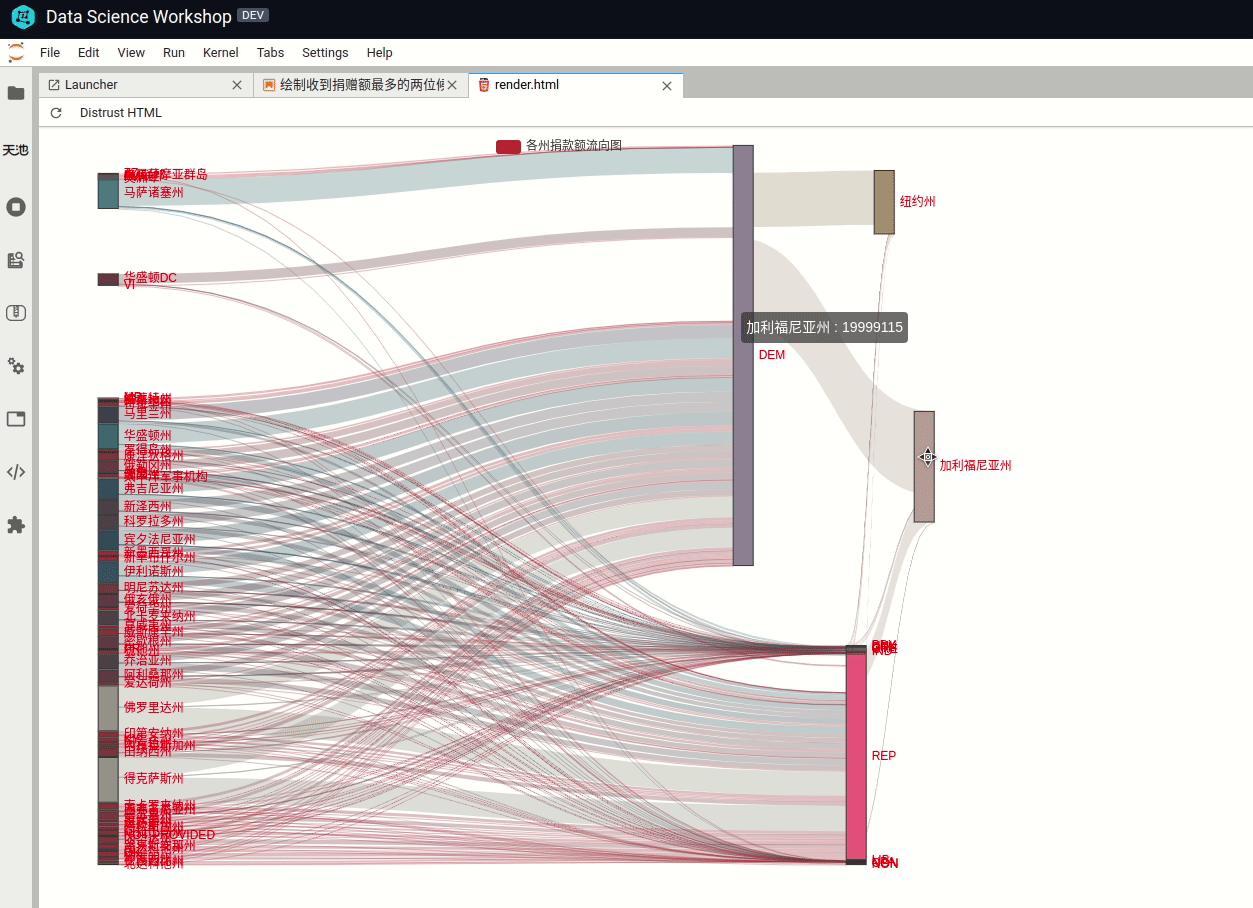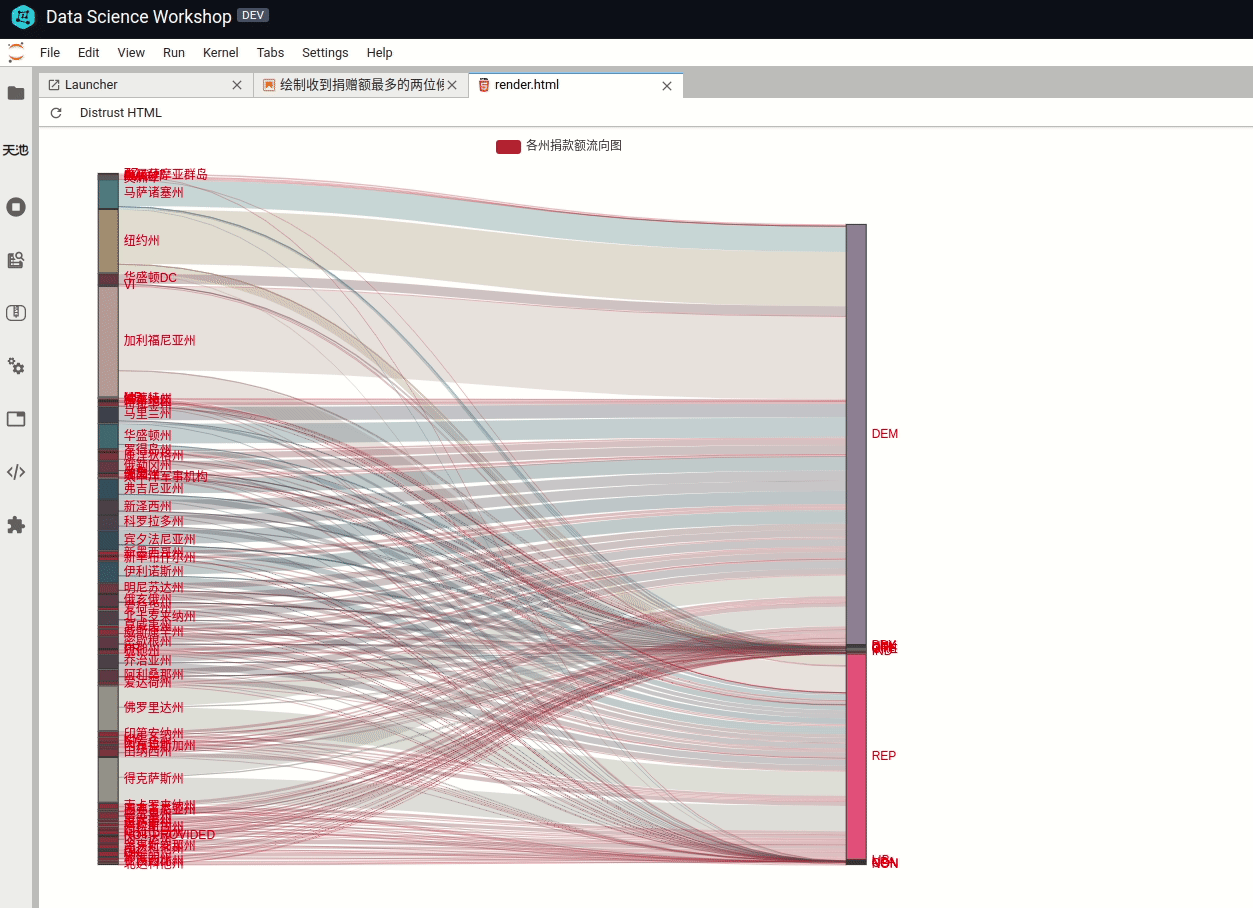
2>使用桑基图分析美国各州对党派的贡献度桑基图(Sankey),即桑基能量分流图,是一种高级可视化图形。常用于金融等数据的可视化分析。最明显的特征就是,始末端的分支宽度总和相等,即所有主支宽度的总和应与所有分出去的分支宽度的总和相等,保持能量的平衡。
一个州的捐款额可能会流向不同的党派,用桑基图表示的效果就非常好。可以很清楚看出某个党派的贡献流向。
这里要用到第三方库 pyecharts,用来画桑吉图比较方便,还支持交互式操作(鼠标悬停某条能量线高亮并显示金额数量)。
from pyecharts import options as opts
from pyecharts.charts import Page, Sankey
sankey = Sankey(init_opts=opts.InitOpts(width="1024", height="768")) #可以设置大小和图标名称
sankey.add(
'各州捐款额流向图', #名称
nodes, #输入节点,如果导入json数据,nodes=json['nodes]
links, #输入关系,nodes=json['links']
linestyle_opt=opts.LineStyleOpts(opacity=0.3, curve=0.5, color="source", width=10),
label_opts=opts.LabelOpts(position="right", is_show=True, color='red'),
node_gap=1
)
sankey.render()
rippercc
rippercc以美国大选捐资额数据介绍克利夫兰点图的三种形态及其应用场景。
文章地址:点击直接访问
https://tianchi.aliyun.com/notebook-ai/detail?postId=140708
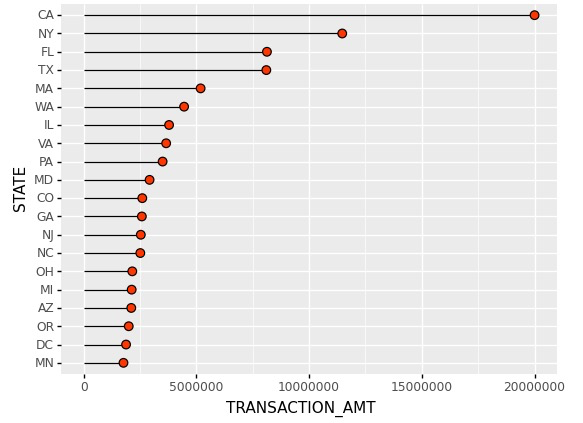
1>克利夫兰点图(Cleveland's Dot Plots)
克利夫兰点图也称滑珠散点图,重点强调数据的排序展示以及互相之间的差距。
#克利夫兰点图
base_plot=(ggplot(state_amt,aes('TRANSACTION_AMT','STATE'))+
geom_point(shape='o',size=3,color='black',fill='#FC4E07')+
xlim(0,23000000))
print(base_plot)
2>棒棒糖图(Lollipop Chart) 棒棒糖图传递了跟条形图相似的信息,只是把矩形转换成了线条,看起来更加简洁美观,相比条形图,棒棒糖图更适用数据量较多的情况。
#棒棒糖图
base_plot=(ggplot(state_amt,aes('TRANSACTION_AMT','STATE'))+
geom_segment(aes(x=0,xend='TRANSACTION_AMT',y='STATE',yend='STATE'))+
geom_point(shape='o',size=3,color='black',fill='#FC4E07')
)
print(base_plot)
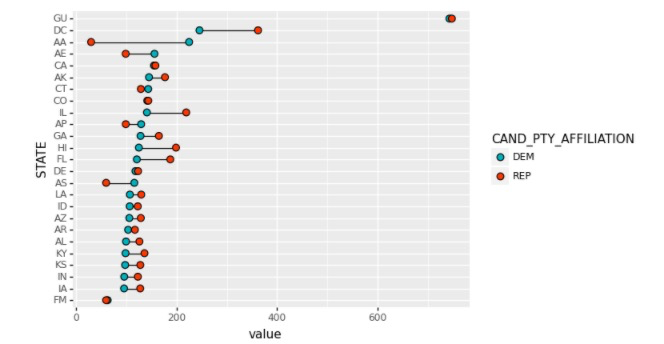
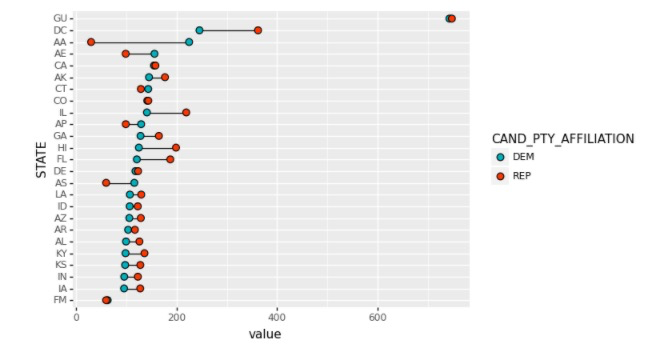
3>哑铃图(Dumbbell Plot) 哑铃图是多数据系列的克利夫兰点图,用直线连接两个数据系列。主要用于:
1.展示在同一时间段两个数据点的相对位置(增加或者减少);
2.比较两个类别之间的数据值差别。
#哑铃图,随便选取了20个州,对比民主党和共和党在该州得到的人均捐赠额,REP有两个是空值为了美观我随意填充了一个数据。
df_party=c_itcont[['STATE','TRANSACTION_AMT','CAND_PTY_AFFILIATION']]
df_party=df_party[df_party.CAND_PTY_AFFILIATION.isin(['REP','DEM'])]
df_pivot=df_party.pivot_table(index='STATE',columns='CAND_PTY_AFFILIATION',values='TRANSACTION_AMT',aggfunc=np.mean)
re_pivot=df_pivot.reset_index(drop=False)[:25].sort_values(by='DEM',ascending=True)
re_pivot['REP'].fillna(60,inplace=True)
re_pivot['STATE']=re_pivot['STATE'].astype(pd.CategoricalDtype(categories=re_pivot['STATE'],ordered=True))
mydata=pd.melt(re_pivot,id_vars='STATE')
base_plot=(ggplot(mydata,aes('value','STATE',fill='CAND_PTY_AFFILIATION'))+
geom_line(aes(group='STATE'))+
geom_point(shape='o',size=3,color='black')+
scale_fill_manual(values=('#00AFBB','#FC4E07','#36BED9')))
print(base_plot)














 6422
6422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









