







基于异常价格的商品识别
案例背景
“网购”因其方便快捷、省时省力、送货上门的特点越来越受到人们的青睐。在各平台规模不断扩大、商品数不断增加的同时,一些不正当的经营行为,例如虚标价格、刷单行为也随之出现,严重违反了电商法,需要对这类商品数据进行准确识别。针对如此庞大的商品数量,如果单纯人工检查筛选,不仅工作量巨大,还会出现遗漏和错误的情况。本赛题旨在寻找一种识别方法,能够实现快速对异常商品的准确定位,减少人工干预成本和降低出错率。
数据集介绍
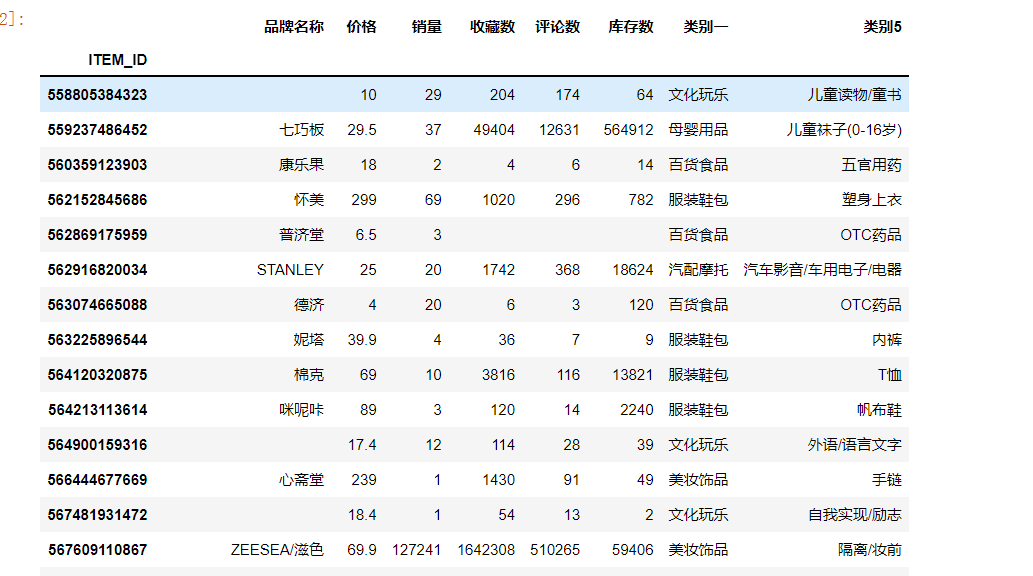
数据集含有1000多w条,关于一些商品的数据,包括品牌名称,价格,商品ID,销量,收藏数,评论数,库存数,类别等众多字段。这里,我们只选择了对服装类的T恤进行预测商品价格异常。
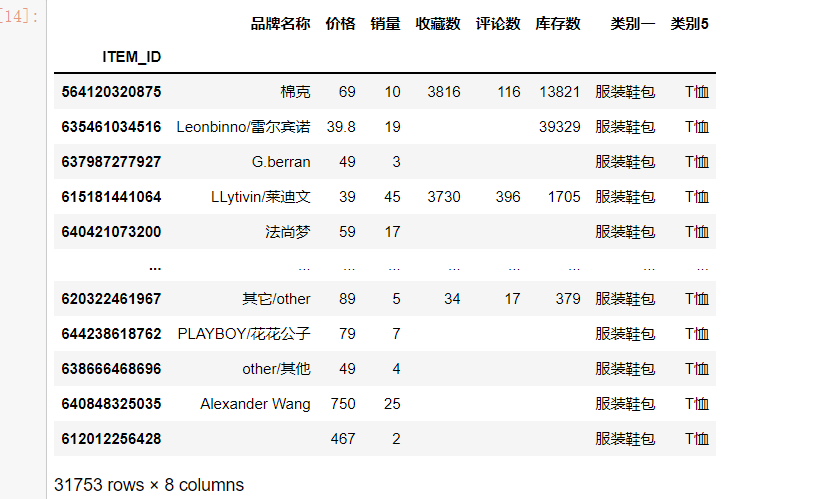
该分类中包含3w条数据
数据预处理
引入相关包
import pyod
import pandas as pd
import numpy as np
import csv
import codecs
import matplotlib.pyplot as plt
from pyecharts.charts import Scatter
filepath = 'data06.csv'
读取csv文件,并将数据转化为dataframe类型
result = []
c = 2
with codecs.open(filepath,'rb','gb18030',errors='ignore') as csvfile:
for line in csvfile:
temp = line.split('\t')
result.append(temp)
if(c==0):
break
df = pd.DataFrame(result)
list_columns = ['DATA_MONTH','ITEM_ID','ITEM_NAME','BRAND_ID','BRAND_NAME','ITEM_PRICE','ITEM_SALES_VOLUME','ITEM_SALES_AMOUNT','CATE_NAME_LV1','CATE_NAME_LV2','CATE_NAME_LV3','CATE_NAME_LV4','CATE_NAME_LV5','ITEM_FAV_NUM','TOTAL_EVAL_NUM','ITEM_STOCK','ITEM_DELIVERY_PLACE','ITEM_PROD_PLACE','ITEM_PARAM','USER_IDd',' SHOP_NAME']
df.columns = list_columns
print("go")
df.drop([0], inplace=True)
df = df.iloc[:,[1,4,5,6,13,14,15,8,10]]
df.columns
df.set_index(['ITEM_ID'],inplace=True)
df.columns = ["品牌名称","价格","销量","收藏数","评论数","库存数","类别一",'类别5']
df.head(50)
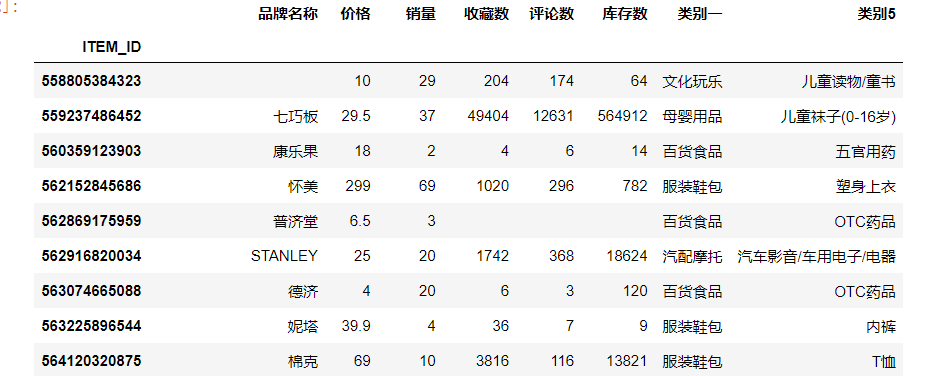
筛选出需要的类别
df_new = df[df["类别一"] == '服装鞋包']
df_new2 = df_new[df_new['类别5'] == 'T恤']
df_new2
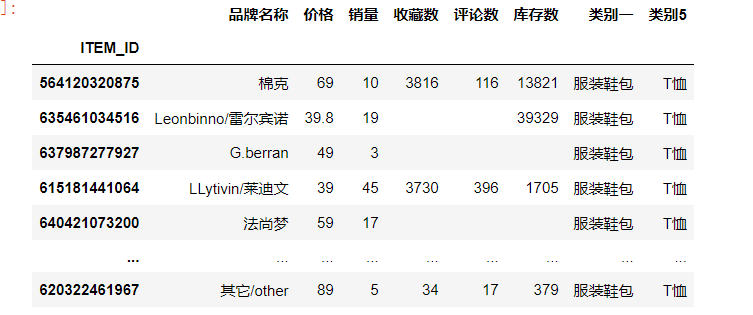
删除相关性不大的列
df_new2.drop(['收藏数','评论数','库存数','类别一','品牌名称'], axis=1,inplace=True)
df_new2
箱线法对数据进行标注
本数据集的一个缺点就是,它没有对异常的数据进行标注,没有标签。所以,这里对离群的数据进行标注一下,然后用于后面的模型训练。
df_new2.info()
df_new2['价格'] = df_new2['价格'].astype('float')
df_new2['销量'] = df_new2['销量'].astype('float')
# 箱线法
Q1 = np.percentile(df_new2['价格'], 25) # 计算1/4分位数
Q3 = np.percentile(df_new2['价格'], 75) # 计算3/4分位数
IQR = Q3 - Q1
outlier_step = 1.5 * IQR
min_limit_box = Q1 - outlier_step
max_limit_box = Q3 + outlier_step
df_new2['lable'] = 0
xx = df_new2[(df_new2['价格'] < min_limit_box) | (df_new2['价格'] > max_limit_box)]['lable']
#df_new2[df_new2['label'] == 1]
for i in range(xx.shape[0]):
df_new2.loc[xx.index[i],'lable'] = 1
得到训练集和测试集
from sklearn.model_selection import train_test_split
X = df_new2[['价格','销量']]
Y = df_new2['lable']
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.3,random_state=4)
按照3比7的比例,获得训练集和测试集。
模型的训练并预测
LogisticRegression 模型
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
model = LogisticRegression()
model.fit(X_train,Y_train) # 模型训练
prediction1 = model.predict(X_test)
prediction1

随机森林
from sklearn.ensemble import RandomForestClassifier
model2 = RandomForestClassifier(n_estimators=500, criterion='entropy', max_depth=5, min_samples_split=1.0,
min_samples_leaf=1, max_features='auto', bootstrap=False, oob_score=False, n_jobs=1, random_state=0,
verbose=0)
model2.fit(X_train, Y_train)
prediction2 = model2.predict(X_test) # 模型预测
prediction2

决策树模型
from sklearn.tree import DecisionTreeClassifier
model3 = DecisionTreeClassifier(criterion='entropy', max_depth=7, min_impurity_decrease=0.0)
model3.fit(X_train, Y_train)
prediction3 = model3.predict(X_test)
prediction3

投票法,集成
为了提高模型的准确率,对训练好的三个模型,使用投票法进行集成。
prediciton_vote = pd.DataFrame({
'Vote': prediction1.astype(int)+prediction2.astype(int)+prediction3.astype(int)})
vote = { 0:0,1:0,2:1,3:1}
prediciton_vote['异常否']=prediciton_vote['Vote'].map(vote) # 该操作将0,1,2,3映射到False和True上。
prediciton_vote

返回异常商品ID号
X_test['异常'] = list(prediciton_vote['异常否'].values)
xx = X_test[X_test['异常'] == 1].index
xx
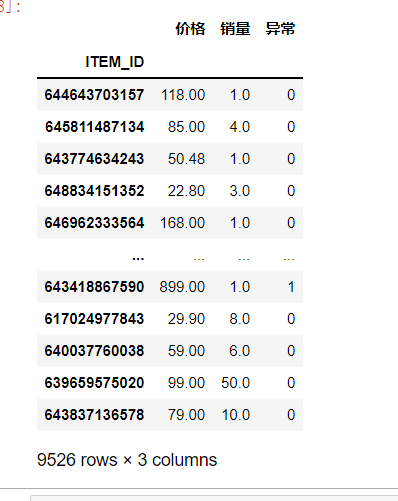
筛选出的异常商品
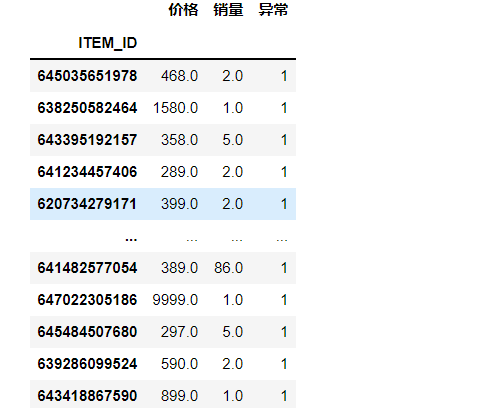
异常商品的ID号


















 1779
1779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









