







 本文介绍了如何通过os.walk遍历数据,将图片读取为numpy类型,划分训练集和测试集,以及使用PaddlePaddle库进行模型训练、测试和保存。关键步骤包括数据加载、图像处理、模型训练与评估,并以ResNet152为例进行11分类任务。
本文介绍了如何通过os.walk遍历数据,将图片读取为numpy类型,划分训练集和测试集,以及使用PaddlePaddle库进行模型训练、测试和保存。关键步骤包括数据加载、图像处理、模型训练与评估,并以ResNet152为例进行11分类任务。
辣椒病虫害图像识别
一些基础
- os.walk是获取所有的目录, 产生3-元组 (dirpath, dirnames, filenames)【文件夹路径, 文件夹名字, 文件名】
- np.load()和np.save(),将图片读取成numpy类型后,可以缓存为numpy文件。这样在下次读取时,可以直接读取numpy缓存文件,减少读取时间。

- transpose()对数组转置后的变化 。应用在图片列表和标签列表里面,就是把分开的两个列表转化为,一张图片对应一个标签的形式。


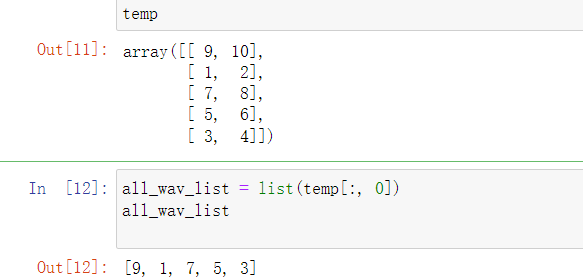
- np.random.shuffle(arr) 随机打乱顺序。使用后,效果如图:

- 取数组的第一列元素,并转化为列表。
all_wav_list = list(temp[:, 0])
- 取列表0到n的元素,以及n到最后的元素。
tra_wav = all_wav_list[0:n]
val_wav = all_wav_list[n:-1]
- model.train() 和 model.eval()分别对应训练模式和评估模式。
数据准备
引入包及解压
import os
import numpy as np
import math
import cv2
import paddle
解压:
!unzip data/data153190/辣椒病虫害图像识别挑战赛公开数据.zip
获得图片的路径及标签
# 得到每张图片的路径和标签
def get_file_list(file_path):
file_list=[]
label_list = []
for fpathe,dirs,fs in os.walk(file_path): # os.walk是获取所有的目录, 产生3-元组 (dirpath, dirnames, filenames)【文件夹路径, 文件夹名字, 文件名】
for f in fs:
filename = os.path.join(fpathe,f)
file_list.append(filename)
lable = fpathe.replace('data_path/train/d','')
lable = int(lable)-1
label_list.append(lable)
return file_list,label_list
效果:
data_list,label_list = get_file_list('data_path/train')
for i in range(5):
print(data_list[i],label_list[i])

图片读取为numpy类型
# 将图片读取成numpy数据
def data_trans_to_numpy(data_list,data_cache):
data_list1=[]
"""
得到numpy数组形式的数据集
会优先看是否有缓存文件,如果有,就直接读取缓存文件
否则会重新处理数据,并保存一份缓存文件
"""
if os.path.exists(data_cache):
# 存在缓存文件,那么直接加载缓存文件
data_list1 = np.load(data_cache)
return data_list1
for i in data_list:
data = paddle.vision.image.image_load(i, backend='cv2')/255 #归一化
data = paddle.vision.transforms.resize(data,(256,256), interpolation='bilinear') # 统一大小
data = paddle.to_tensor(data,dtype='float32') # 统一位float
data = paddle.reshape(data,(3,256,256)) # 调整形状
# data=cv2.imread(i)
# data=cv2.resize(data, (128,128), interpolation=cv2.INTER_AREA)/255
data_list1.append(data)
np.save(data_cache, data_list1) # np.save(),np.load()文件的储存与读取。
return data_list1
效果:
data_list.shape

划分训练集和测试集
def get_data_split(data_list, label_list, ration,cache_path):
"""
file_list:每一个数据的路径
cache_data_path:缓存数据路径
ration:划分比例
划分数据集,得到训练集与测试集
"""
data_list = np.load(cache_path)
data_list = list(data_list)
label_list = list(label_list)
temp = np.array([data_list, label_list]) # 合在一起,转置
temp = temp.transpose()
np.random.shuffle(temp) # 随机打乱
# 将所有的img和lab转换成list
all_wav_list = list(temp[:, 0])
all_label_list = list(temp[:, 1])
# 将所得List分为两部分,一部分用来训练tra,一部分用来测试val
# ratio是测试集的比例,看情况填入0-1的一个小数
n_sample = len(all_label_list)
n_val = int(math.ceil(n_sample * ration)) # 测试样本数
n_train = n_sample - n_val # 训练样本数
tra_wav = all_wav_list[0:n_train]
tra_labels = all_label_list[0:n_train]
val_wav = all_wav_list[n_train:-1]
val_labels = all_label_list[n_train:-1]
return tra_wav, tra_labels, val_wav, val_labels
tra_wav, tra_labels, val_wav, val_labels = get_data_split(data_list, label_list, ration=0.2,cache_path='data_cache.npy')
数据读取器
import paddle
import numpy as np
from paddle.io import Dataset
class MyDataset(Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self,mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(MyDataset, self).__init__()
if mode == 'train':
self.data = tra_wav
self.label = tra_labels
else:
self.data = val_wav
self.label = val_labels
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回 单条数据(训练数据,对应的标签)
"""
data = self.data[index]
data = paddle.to_tensor(data,dtype='float32')
label = self.label[index]
return data, label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)
设置一些参数并读取数据
这里我们使用paddle.io.DataLoader模块实现数据读取,DataLoader返回一个迭代器,该迭代器根据 batch_sampler 给定的顺序迭代一次给定的 dataset。
第一个数据参数必须是 paddle.io.Dataset 或 paddle.io.IterableDataset 的一个子类实例。
import paddle.nn.functional as F
epoch_num = 30 #训练轮数
batch_size = 32
learning_rate = 0.0001 #学习率
val_acc_history = []
val_loss_history = []
# 读取数据
train_loader = paddle.io.DataLoader(MyDataset("train"),batch_size=batch_size, shuffle=True,drop_last=True)
test_loader = paddle.io.DataLoader(MyDataset("test"), batch_size=batch_size, shuffle=True,drop_last=True)
效果 : train_loader()返回的对象啊是一个列表,包含一个batch的图片和标签。
for i in train_loader():
print(i[0])
break

for i in train_loader():
print(i[1])
break

模型的训练
定义训练函数
loss.backward() 用于产生梯度,下面往往跟
opt.step() 执行一次优化器,并进行参数更新。
我们知道optimizer更新参数空间需要基于反向梯度,因此,当调用optimizer.step()的时候应当是loss.backward()调用的时候,这也就是经常会碰到。
def train(model):
print('start training ... ')
# turn into training mode
model.train()
opt = paddle.optimizer.Adam(learning_rate=learning_rate,
parameters=model.parameters())
for epoch in range(epoch_num):
acc_train = []
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1],dtype="int64")
y_data = paddle.unsqueeze(y_data, 1) # 返回扩展维度后的多维tensor
logits = model(x_data) # 训练输入图片
loss = F.cross_entropy(logits, y_data) # 传入标签,算损失值
acc = paddle.metric.accuracy(logits, y_data) # 计算准确率
acc_train.append(acc.numpy())
if batch_id % 20 == 0 and batch_id != 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, loss.numpy()))
avg_acc = np.mean(acc_train)
print("[train] accuracy: {}".format(avg_acc))
loss.backward() # 计算梯度,用于产生梯度
opt.step() # 执行一次优化器,并进行参数更新。我们知道optimizer更新参数空间需要基于反向梯度,因此,当调用optimizer.step()的时候应当是loss.backward()的时候),这也就是经常会碰到,
opt.clear_grad() # 清除需要优化的参数的梯度
# evaluate model after one epoch
model.eval() # 评估模式
accuracies = []
losses = []
for batch_id, data in enumerate(test_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1],dtype="int64")
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
acc = paddle.metric.accuracy(logits, y_data)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
avg_acc, avg_loss = np.mean(accuracies), np.mean(losses)
print("[test] accuracy/loss: {}/{}".format(avg_acc, avg_loss))
val_acc_history.append(avg_acc)
val_loss_history.append(avg_loss)
model.train()
开始训练
11分类问题,这里num_classes参数是11。调用了resnet152分类网络。
model = paddle.vision.models.resnet152(pretrained=True,num_classes=11)
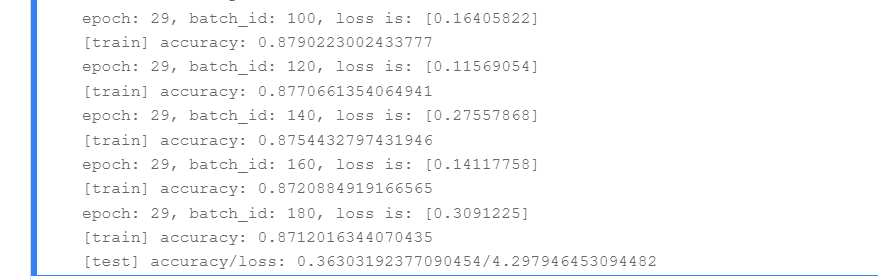
train(model)
结果如下:
保存模型
paddle.save(model.state_dict(), "my_net.pdparams")
opt = paddle.optimizer.Adam(learning_rate=learning_rate,\
parameters=model.parameters())
paddle.save(opt.state_dict(), "adam.pdopt")

测试
加载模型
model = paddle.vision.models.resnet152(pretrained=True,num_classes=11)
opt = paddle.optimizer.Adam(learning_rate=learning_rate,\
parameters=model.parameters())
#加载模型
layer_state_dict = paddle.load("my_net.pdparams")
opt_state_dict = paddle.load("adam.pdopt")
model.set_state_dict(layer_state_dict)
opt.set_state_dict(opt_state_dict)
读取测试数据集
def get_text_list(file_path):
file_list=[]
for fpathe,dirs,fs in os.walk(file_path):
for f in fs:
filename = os.path.join(fpathe,f)
file_list.append(filename)
return file_list
转成numpy
pre_data = data_trans_to_numpy(data_list,'test_data_cache.npy')
定义测试函数并测试
pre = np.argmax(logits),对于这行代码的解释,因为输出是11个元素的列表,分别对应着不同分类的概率,这里取最大值对应的索引,该索引就是它的预测出的分类值。
def test(pre_data):
print('start testing ... ')
model.train()
y_pred = []
opt = paddle.optimizer.Adam(learning_rate=learning_rate,
parameters=model.parameters()) # 优化器
model.eval()
for data in pre_data:
data = paddle.to_tensor(data)
data = paddle.reshape(data,(1,3,256,256))
x_data = data
logits = model(x_data)
pre = np.argmax(logits) # 取出概率最大值对应的索引,该索引就是它的分类
y_pred.append(pre)
return y_pred
测试
y_pred = test(pre_data)
将结果写入csv文件
pre = []
path = []
for i in y_pred:
x = 'd'+str(i+1)
pre.append(x)
for j in data_list:
img = j.replace('data_path/test/','')
path.append(img)
# 写入csv文件
import pandas as pd
out_put = pd.DataFrame({'image':path,'label':pre})
out_put.to_csv('pred.csv',index =False)
预测结果:


















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









