









目录
3.3 Restoration-Guided Sampling
4.1 Model Training and Sampling Settings
4.2 Comparsion with Existing Methods
Restoration in the Wild 真实场景中的修复
4.3 Controlling Restoration with Textual Prompts
提出了SUPIR作为一种开创性的图像修复(IR)方法,得益于模型扩展、数据集丰富和先进的设计特性,SUPIR拓展图像修复的视野,提升感知质量,并实现对文本提示的有效控制。
扩散模型用于图像复原,自己造了一个数据集,对Controlnet进行改进并设计了一个新连接器,数据规模很大(Scale up dataset, Scale up model),用了64张A6000训了十天(AI Lab的作品),通过改进EDM采样过程(这个采样器有点冷门)来限制生成过程以保证保真度。在实验分析部分会对自己实验结果不好的limitations进行正向分析(比如参考指标效果不好、负语义引导效果有时候没那么好等),并指出合理性和给出证明,牛!连接器保证了保真度的效果,训练数据量大小决定了效果,语义引导也决定了效果,修复引导采样决定了保真度的程度。在附录补充了很多limitations和Visual Results,实验做得很充分。
Abstract
我们介绍了SUPIR(Scaling-UP Image Restoration),这是一种开创性的图像修复方法,利用生成先验和模型扩展的力量。SUPIR结合了多模态技术和先进的生成先验,标志着智能和真实图像修复的重大进展。模型扩展是SUPIR的关键催化剂,显著增强了其能力,并展示了图像修复的新潜力。
我们收集了一个包含2000万张高分辨率、高质量图像的数据集用于模型训练,每张图像都配有详细的文本注释。SUPIR能够根据文本提示修复图像,拓宽了其应用范围和潜力。此外,我们引入了负质量提示,以进一步提高感知质量。我们还开发了一种修复引导采样方法,以抑制生成式修复中遇到的保真度问题。实验结果表明,SUPIR在修复效果方面表现出色,并具有通过文本提示操控修复的新能力。
Motivation
由于计算资源、模型架构、训练数据以及生成模型与IR的协同等工程限制,扩展IR模型面临挑战。现有的适配器设计要么过于简单,无法满足IR的复杂要求,要么过于庞大,无法与SDXL共同训练。
→为了解决这个问题,我们修剪了ControlNet,并设计了一个新连接器ZeroSFT,使其能够与预训练的SDXL配合使用,旨在高效地实施IR任务,同时降低计算成本。
3.Method
3.1Model Scaling Up
Generative Prior
在大规模生成模型的选择上可选项不多,主要考虑的有Imagen、IF和SDXL,最终选择SDXL的原因如下:
- 生成方式:Imagen和IF优先考虑文本到图像的生成,并依赖分层方法,首先生成低分辨率图像,然后逐层上采样。而SDXL则符合我们的目标,能够直接生成高分辨率图像,无需分层设计,有效利用其参数提升图像质量,而不是过多关注文本理解。
- 基础-精细策略:SDXL采用基础-精细策略。在基础模型中,生成多样但质量较低的图像。随后,精细模型利用质量显著更高但多样性较低的训练图像来提升图像质量。鉴于我们采用的是大量高质量图像的数据集,SDXL的双阶段设计对于我们的目标而言显得多余。因此,我们选择基础模型,它的参数数量更多,更适合作为生成先验。
Degradation-Robust Encoder
在SDXL中,扩散生成过程是在潜在空间中进行的。图像首先通过预训练编码器映射到潜在空间。为了有效利用预训练的SDXL,我们的低质量图像 X_LQ也需要映射到同一潜在空间。然而,由于原始编码器未对低质量图像进行训练,使用它进行编码将影响模型对低质量图像内容的判断,可能将伪影误解为图像内容。
为此,我们对编码器进行微调,使其对降质具有鲁棒性,具体目标是最小化以下损失:

Large-Scale Adaptor Design.
考虑到SDXL模型作为我们选择的生成先验,我们需要一个适配器,用于根据提供的低质量(LQ)输入引导其进行图像修复。这个适配器需要识别LQ图像中的内容,并在像素级别上进行精细控制。
**现有适配器的局限性:**现有的扩散模型适配方法,如LoRA、T2I适配器和ControlNet,均未能满足我们的要求:
- LoRA:虽然能限制生成,但在LQ图像控制方面表现不佳。
- T2I:缺乏对LQ图像内容识别的能力。
- ControlNet:其直接复制方法在SDXL模型的规模上存在挑战。
**新适配器的设计:**我们设计了一个新适配器,具有两个关键特征,如图3 (a) 所示:

- 基于ControlNet的高层设计:我们保留了ControlNet的高层设计,但通过网络修剪直接修剪可训练副本中的某些模块,实现工程可行性。在SDXL的编码器模块中,每个模块主要由多个视觉变换器(ViT)块组成。我们确定了ControlNet有效性的两个关键因素:大网络容量和可训练副本的高效初始化。值得注意的是,即使是对可训练副本中的模块进行部分修剪,也能保留这些关键特性。因此,我们简单地从每个编码器模块中修剪一半的ViT块,如图3(b)所示。
- 重新设计连接器:我们重新设计了将适配器与SDXL连接的连接器。尽管SDXL的生成能力提供了出色的视觉效果,但在像素级控制方面却存在挑战。ControlNet使用零卷积进行生成指导,但仅依赖残差不足以满足IR所需的控制。为了增强LQ指导的影响,我们引入了一个ZeroSFT模块,如图3(c)所示。ZeroSFT基于零卷积,包含额外的空间特征转移(SFT)操作和组归一化(Group Normalization)。
通过这些设计,我们的适配器能够更有效地引导SDXL进行高质量的图像修复,同时增强对低质量输入的响应能力。
3.2 Scaling Up Training Data
图像收集
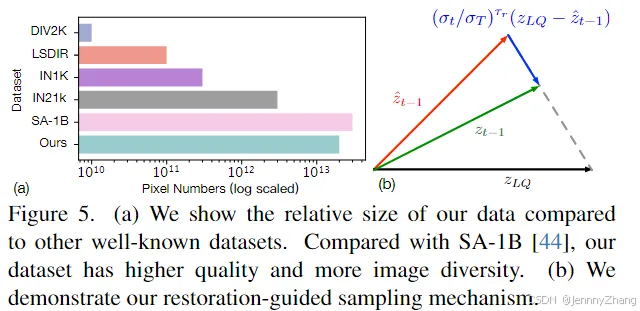
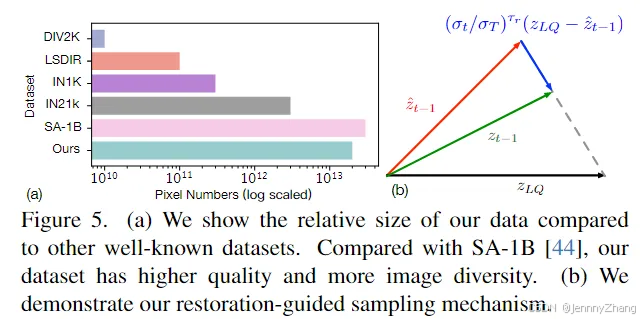
模型的扩展需要相应扩展训练数据。然而,目前尚未有大规模高质量的图像数据集可用于图像修复(IR)。尽管DIV2K和LSDIR提供了高质量的图像,但数量有限。更大的数据集,如ImageNet、LAION-5B和SA-1B,虽然包含更多图像,但其图像质量未能达到我们的高标准。为此,我们收集了一个大规模的高分辨率图像数据集,包含2000万张1024×1024的高质量、纹理丰富的图像。图3展示了我们收集的数据集规模与现有数据集的比较。此外,我们还从FFHQ-raw数据集中额外包含了7万张未对齐的高分辨率面部图像,以提升模型的面部修复性能。图5(a)展示了我们的数据集与其他知名数据集的相对规模。
多模态语言指导
扩散模型以其根据文本提示生成图像的能力而闻名。我们认为,文本提示也可以帮助图像修复:
- 理解图像内容:理解图像内容对IR至关重要。现有框架往往忽视或隐含处理这种理解。通过引入文本提示,我们可以明确传达对低质量图像的理解,促进有针对性的缺失信息修复。
- 应对严重降质:在严重降质的情况下,即使是最好的IR模型也难以完全恢复丢失的信息。在这种情况下,文本提示可以作为控制机制,根据用户的偏好有针对性地补全缺失的信息。
- 描述所需图像质量:我们还可以通过文本描述所需的图像质量,进一步提升输出的感知质量。图1(b)展示了一些示例。
为此,我们进行了两个主要修改:
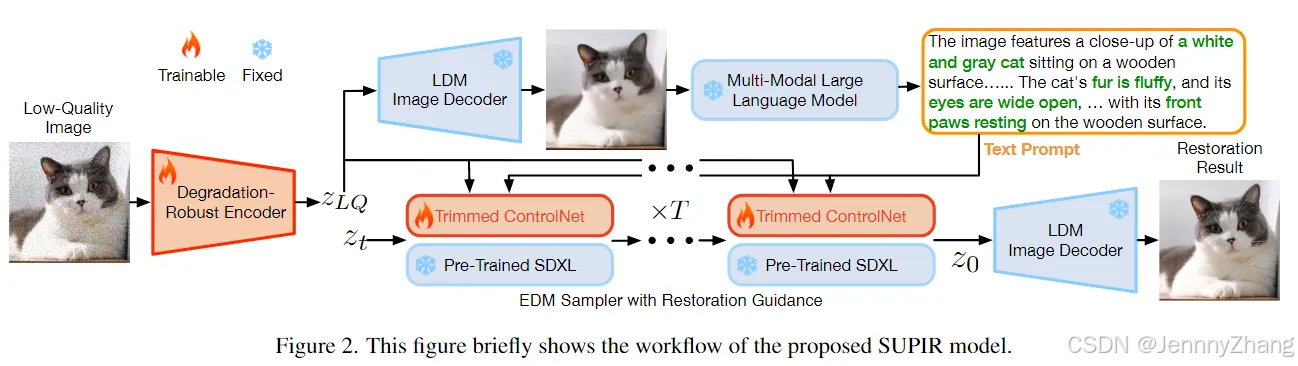
- 整体框架修订:我们将LLaVA多模态大语言模型(LLM)引入我们的工作流程,如图2所示。LLaVA以降质鲁棒处理的低质量图像 \( x'{LQ} = D(E{dr}(x_{LQ})) \) 作为输入,明确理解图像内容,并以文本描述的形式输出。这些描述随后被用作指导修复的提示。此过程可以在测试期间自动化,消除手动干预的需要。
- 收集文本注释:我们还为所有训练图像收集了文本注释,以增强文本控制在模型训练过程中的作用。通过这两项变更,SUPIR具备理解图像内容并基于文本提示进行图像修复的能力。
负质量样本与提示
无分类器引导(CFG)为控制模型提供了另一种方式,通过使用负提示来指定不希望出现的内容。我们可以利用这一特性来指定模型不生成低质量图像。具体而言,在扩散的每一步中,我们使用正提示 pos 和负提示 neg 进行两次预测,并将这两个结果的融合作为最终输出:
**准确性的重要性:**在CFG技术中,准确预测正向和负向的效果至关重要。然而,训练数据中缺乏负质量样本和提示可能导致微调后的SUPIR无法理解负提示。因此,在采样过程中使用负质量提示可能会引入伪影,示例见图4。

为了解决这一问题,我们使用SDXL生成了10万张与负质量提示相对应的图像(**太逆天了,10万张!!!!!!!!)**我们反直觉地将这些低质量图像添加到训练数据中,以确保提出的SUPIR模型能够学习负质量概念。通过这一方法,SUPIR能够更好地处理负提示,从而提升其在图像修复任务中的表现。
3.3 Restoration-Guided Sampling
强大的生成先验是一把双刃剑,过强的生成能力会影响恢复图像的保真度。这突显了图像修复(IR)任务与生成任务之间的根本区别。我们需要手段来限制生成,以确保图像恢复忠实于低质量(LQ)图像。为此,我们修改了EDM采样方法,并提出了一种修复引导采样方法来解决这个问题。我们的目标是在每个扩散步骤中选择性地引导预测结果 z_{t-1}zt−1 靠近LQ图像 zLQz_{LQ}zLQ。
算法概述
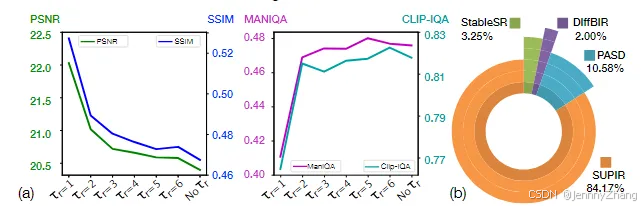
具体算法如算法1所示,其中 T是总步骤数,{σ_t}_{t=1}^T 是 T 步的噪声方差,c 是额外的文本提示条件。τr、Schurn、Snoise、Smin 和 Smax是五个超参数,其中只有 τr与修复引导相关,其余参数与原始EDM方法保持不变。

为了更好地理解,图5(b)展示了一个简单的示意图。我们在预测输出 z^t−1_hat 和LQ潜在表示 zLQ之间进行加权插值,作为修复引导输出 zt−1。
加权插值

4.Experiment
4.1 Model Training and Sampling Settings
在训练过程中,整体训练数据包括2000万张高质量图像及其文本描述、7万张人脸图像和10万张负质量样本,以及它们各自的提示。为了实现更大的批量大小,我们在训练期间将图像裁剪为512×512的块。我们使用合成降质模型对模型进行训练,遵循Real-ESRGAN所用的设置,唯一的区别是我们将生成的低质量(LQ)图像调整为512×512进行训练。我们使用AdamW优化器,学习率为0.00001。训练过程持续了10天,使用了64个Nvidia A6000 GPU,批量大小为256。
在测试时,超参数设置为 T=100、λcfg=7.5 和 τr=4,我们的方法能够处理1024×1024大小的图像。我们将输入图像的短边调整为1024,并裁剪出一个1024×1024的子图像进行测试,然后在修复后将其调整回原始大小。除非另有说明,否则提示将不会手动提供,处理过程将完全自动化。
4.2 Comparsion with Existing Methods
我们的方法能够处理多种降质情况,并与最新的具有相同能力的方法进行比较,包括BSRGAN、Real-ESRGAN、StableSR、DiffBIR和PASD。其中一些方法限制生成图像的尺寸为512×512。在我们的比较中,我们将测试图像裁剪以满足这一要求,并对我们的结果进行下采样。我们在合成数据和真实世界数据上进行了比较。
Synathetic Data 合成数据
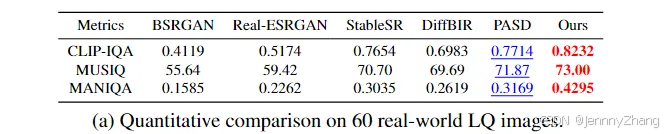
在多个代表性的降质情况下,我们进行了评估,包括单一降质和复杂混合降质。具体细节见表1。我们选择了以下指标进行定量比较:全参考指标PSNR、SSIM、LPIPS,以及非参考指标ManIQA、ClipIQA和MUSIQ。
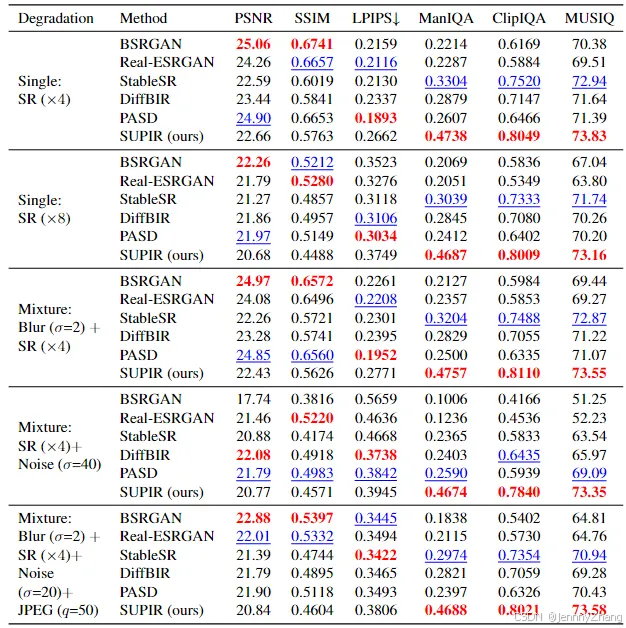
从结果可以看出,我们的方法在所有非参考指标上均取得了最佳结果,反映出我们结果的卓越图像质量。同时,我们也注意到我们的方法在全参考指标上的劣势。我们进行了一项简单实验,突显了这些全参考指标的局限性,如图7所示。尽管我们的结果在视觉效果上表现更好,但在这些指标上并没有优势。这一现象在许多研究中也有提到。

**评估指标的思考:**随着图像修复(IR)质量的提高,现有指标的参考值需要重新考虑,并建议采用更有效的方式来评估先进的IR方法。我们还展示了一些定性比较结果,如图6所示。即使在严重降质的情况下,我们的方法也能始终产生高度合理且高质量的图像,忠实地再现低质量图像的内容。
通过这些定量和定性分析,我们强调了在评估IR方法时,需要综合考虑不同类型的指标,以更全面地反映修复效果的实际表现。
Restoration in the Wild 真实场景中的修复
我们还在真实世界的低质量(LQ)图像上测试了我们的方法。我们从RealSR、DRealSR、Real47以及在线来源收集了共计60张真实世界的LQ图像,这些图像涵盖了多样的内容,包括动物、植物、面孔、建筑和风景。

用户研究
我们还进行了用户研究,比较我们在真实世界LQ图像上的方法,共有20名参与者参与。在每组比较图像中,我们指示参与者选择在这些测试方法中质量最高的修复结果。结果如图8所示,显示我们的方案在感知质量上显著超越了最先进的方法。
4.3 Controlling Restoration with Textual Prompts
人类提示选择性修复
在经过大规模图像-文本对数据集的训练后,并利用扩散模型的特性,我们的方法能够根据人类提示选择性地修复图像。图1(b)展示了一些示例。
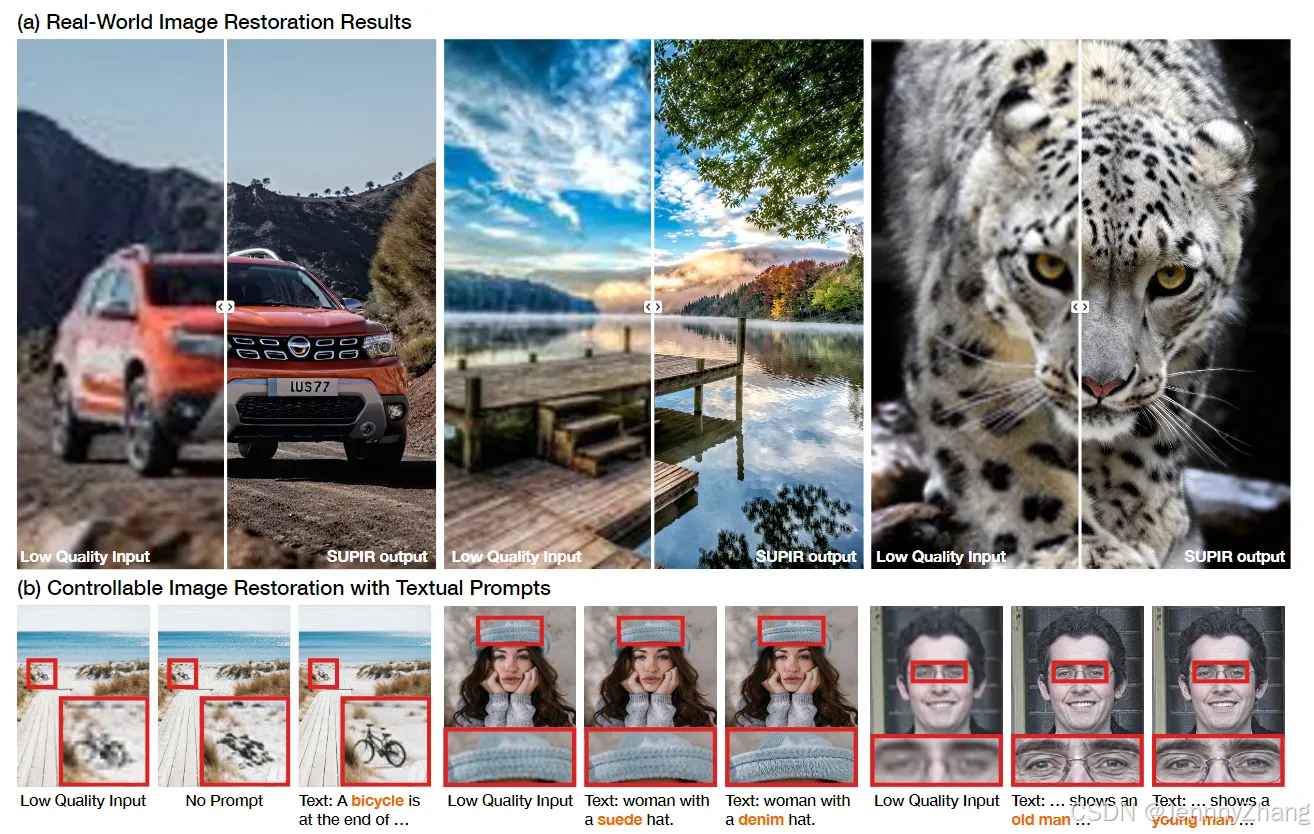
负质量提示
除了提示图像内容外,我们还可以通过负质量提示引导模型生成更高质量的图像。图11(a)展示了两个示例,表明负提示在提高输出图像整体质量方面非常有效。
提示的局限性
我们也观察到,在某些情况下,我们的方法中的提示并不总是有效。当提供的提示与低质量(LQ)图像不一致时,提示变得无效,如图11(b)所示。我们认为这是合理的,因为图像修复方法需要忠实于提供的LQ图像。这反映了与文本到图像生成模型之间的显著区别,并强调了我们方法的鲁棒性。

4.4 Ablation Study
连接器比较
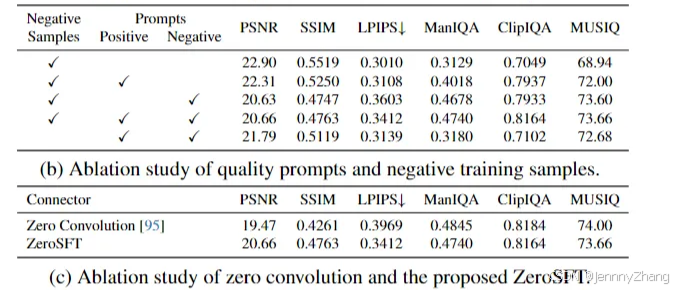
我们将提出的ZeroSFT连接器与零卷积进行了比较,定量结果见表c。与ZeroSFT相比,零卷积在非参考指标上的表现相当,但在全参考指标上的表现则显著较低。图9显示,非参考指标的下降是由于生成了低保真度的内容。因此对于图像修复(IR)任务,ZeroSFT能够确保保真度而不损失感知效果。

训练数据扩展
我们在两个较小的数据集(DIV2K和LSDIR)上训练了我们的大规模模型。图12的定性结果清楚地展示了在大规模高质量数据上训练的重要性和必要性。

负质量样本与提示
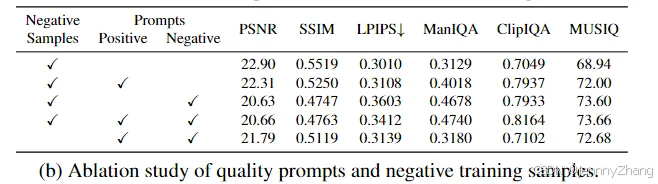
表2b展示了在不同设置下的一些定量结果。在这里,我们使用描述图像质量的积极词汇作为“积极提示”,并使用负质量词汇及第3.2节中描述的CFG方法作为负提示。可以看出,单独添加积极提示或负提示都会改善图像的感知质量。而同时使用这两者能够获得最佳的感知效果。如果在训练中未包含负样本,这两个提示将无法提升感知质量。图4和图11(a)展示了使用负提示所带来的图像质量改善。
修复引导采样方法


连接器保证了保真度的效果,训练数据量大小决定了效果,语义引导也决定了效果,修复引导采样决定了保真度的程度。
Conclusion
我们提出了SUPIR作为一种开创性的图像修复(IR)方法,得益于模型扩展、数据集丰富和先进的设计特性,SUPIR拓展了图像修复的视野,提升了感知质量,并实现了对文本提示的有效控制。


















 616
616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









