







| 📜个人简介 |
⭐️个人主页:摸鱼の文酱博客主页🙋♂️
🍑博客领域:java编程基础,mysql
🍅写作风格:干货,干货,还是tmd的干货
🌸精选专栏:【Java】【mysql】 【算法刷题笔记】
🎯博主的码云gitee,平常博主写的程序代码都在里面。
🚀支持博主:点赞👍、收藏⭐、留言💬
🍭作者水平很有限,如果发现错误,一定要及时告知作者哦!感谢感谢!
1.多线程的引入
你是否常常用你的电脑一边听歌,一边打游戏,又或者一边挂着网课,一边去刷剧……
那你有没有想过,你的电脑如何做到可以在你开启多个程序的时候还能兼顾
想了解操作系统是如何处理多任务的情况,我们就需要了解进程和线程
1.1 进程概念
进程是表示资源分配的基本单位,又是调度运行的基本单位。例如,用户运行自己的程序,系统就创建一个进程,并为它分配资源,包括各种表格、内存空间、磁盘空间、I/O设备等。然后,把该进程放人进程的就绪队列。进程调度程序选中它,为它分配CPU以及其它有关资源,该进程才真正运行。所以,进程是系统中的并发执行的单位。
简言之,由于进程是一个资源拥有者,因而在进程的创建、撤消和切换中,系统必须为之付出较大的时空开销。也正因为如此,在系统中所设置的进程数目不宜过多,进程切换的频率也不宜太高,但这也就限制了并发程度的进一步提高。
如何能使多个程序更好地并发执行,同时又尽量减少系统的开销,已成为近年来设计操作系统时所追求的重要目标。于是,有不少操作系统的学者们想到,可否将进 程的上述属性分开,由操作系统分开来进行处理。即对作为调度和分派的基本单位,不同时作为独立分配资源的单位,以使之轻装运行;而对拥有资源的基本单位, 又不频繁地对之进行切换。正是在这种思想的指导下,产生了线程概念。
1.2 线程概念
线程是进程中执行运算的最小单位,亦即执行处理机调度的基本单位,线程具有许多传统进程所具有的特征,故又称为轻型进程(Light—Weight Process)或进程元。如果把进程理解为在逻辑上操作系统所完成的任务,那么线程表示完成该任务的许多可能的子任务之一。
进程是包含线程的. 每个进程至少有一个线程存在,即主线程。
进程和进程之间不共享内存空间. 同一个进程的线程之间共享同一个内存空间.
进程与进程之间不会相互影响,不同进程中的线程不会相互影响,但是同一进程中的线程就有可能相互影响
例子:如果把计算机的操作系统比作一个大的工厂,那么进程就是这个工厂中的各个相互独立的车间,线程指的是车间中的流水线工人。每个车间中至少有一个工人,一个车间也也可以有多个工人,他们共享这个车间中的所有资源。也就是说,一个进程中可以有多个线程,但一个进程中至少有一个线程,他们共享这个进程下的所有资源。
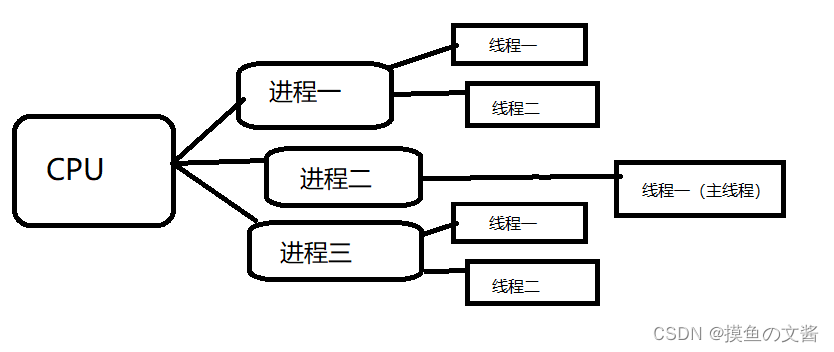
1.3 进程和线程的关系
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。线程是操作系统可识别的最小执行和调度单位。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。 同一进程中的多个线程共享代码段(代码和常量),数据段(全局变量和静态变量),扩展段(堆存储)。但是每个线程拥有自己的栈段,栈段又叫运行时段,用来存放所有局部变量和临时变量。
(3)处理机分给线程,即真正在处理机上运行的是线程。
(4)线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。
进程是系统分配资源的最小单位,线程是系统调度的最小单位。
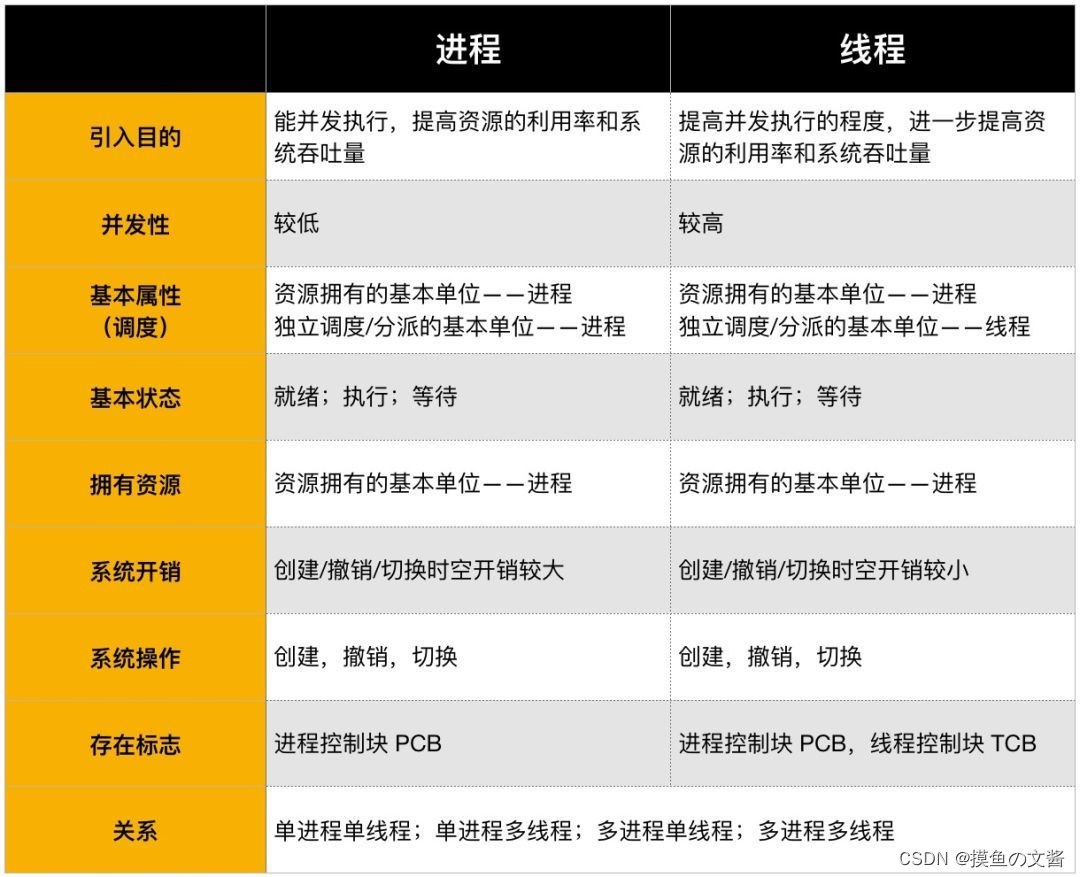
1.4 进程与线程的比较
下面,我们从调度、并发性、 系统开销、拥有资源等方面,来比较线程与进程。
(1).调度
在传统的操作系统中,拥有资源的基本单位和独立调度、分派的基本单位都是进程。而在引入线程的操作系统中,则把线程作为调度和分派的基本单位。而把进程作 为资源拥有的基本单位,使传统进程的两个属性分开,线程便能轻装运行,从而可显著地提高系统的并发程度。在同一进程中,线程的切换不会引起进程的切换,在 由一个进程中的线程切换到另一个进程中的线程时,将会引起进程的切换。
(2).并发性
在引入线程的操作系统中,不仅进程之间可以并发执行,而且在一个进程中的多个线程之间,亦可并发执行,因而使操作系统具有更好的并发性,从而能更有效地使 用系统资源和提高系统吞吐量。例如,在一个未引入线程的单CPU操作系统中,若仅设置一个文件服务进程,当它由于某种原因而被阻塞时,便没有其它的文件服 务进程来提供服务。在引入了线程的操作系统中,可以在一个文件服务进程中,设置多个服务线程,当第一个线程等待时,文件服务进程中的第二个线程可以继续运行;当第二个线程阻塞时,第三个线程可以继续执行,从而显著地提高了文件服务的质量以及系统吞吐量。
(3).拥有资源
不论是传统的操作系统,还是设有线程的操作系统,进程都是拥有资源的一个独立单位,它可以拥有自己的资源。一般地说,线程自己不拥有系统资源(也有一点必 不可少的资源),但它可以访问其隶属进程的资源。亦即,一个进程的代码段、数据段以及系统资源,如已打开的文件、I/O设备等,可供问一进程的其它所有线 程共享。
(4).系统开销
由于在创建或撤消进程时,系统都要为之分配或回收资源,如内存空间、I/o设备等。因此,操作系统所付出的开销将显著地大于在创建或撤消线程时的开销。类 似地,在进行进程切换时,涉及到整个当前进程CPU环境的保存以及新被调度运行的进程的CPU环境的设置。而线程切换只须保存和设置少量寄存器的内容,并 不涉及存储器管理方面的操作。可见,进程切换的开销也远大于线程切换的开销。此外,由于同一进程中的多个线程具有相同的地址空间,致使它们之间的同步和通信的实现,也变得比较容易。在有的系统中,线程的切换、同步和通信都无须
1.5 引入线程的好处
(1)易于调度。
(2)提高并发性。通过线程可方便有效地实现并发性。进程可创建多个线程来执行同一程序的不同部分。
(3)开销少。创建线程比创建进程要快,所需开销很少。。
(4)利于充分发挥多处理器的功能。通过创建多线程进程(即一个进程可具有两个或更多个线程),每个线程在一个处理器上运行,从而实现应用程序的并发性,使每个处理器都得到充分运行。
1.6 Java 的线程 和 操作系统线程 的关系
线程是操作系统中的概念. 操作系统内核实现了线程这样的机制, 并且对用户层提供了一些 API 供用户使
用(例如 Linux 的 pthread 库).
Java 标准库中 Thread 类可以视为是对操作系统提供的 API 进行了进一步的抽象和封装.
2.创建线程
方法1 继承 Thread 类
- 继承 Thread 来创建一个线程类.
class MyThread extends Thread {
@Override
public void run() {
System.out.println("这里是线程运行的代码");
}
}
- 创建 MyThread 类的实例
MyThread t = new MyThread();
- 调用 start 方法启动线程
t.start(); // 线程开始运行
//多线程实现方法1
//——创建子类,继承自Thread
class MyThread1 extends Thread{
/**
* 描述了这个线程内部要执行的代码
* 重写run方法,run方法中的逻辑,是在新创建出来的线程中,被执行的代码
* (但并不是说一写run方法,线程就被创建出来)
*/
public void run(){
System.out.println("这里是线程运行的代码");
System.out.println("Hello Thread");
}
}
public class Demo1 {
public static void main(String[] args) {
Thread thread = new MyThread1();
/**
* 需要调用这里的start方法,才是真的在系统中创建了线程,
* 才开始真正执行run操作
* 在调用start之前,系统是没有创建出线程的。
*/
thread.start();
}
}
方法2 实现 Runnable 接口
- 实现 Runnable 接口
class MyThread extends Thread {
@Override
public void run() {
System.out.println("这里是线程运行的代码");
}
}
- 创建 Thread 类实例, 调用 Thread 的构造方法时将 Runnable 对象作为 target 参数.
MyThread t = new MyThread();
- 调用 start 方法
t.start(); // 线程开始运行
//多线程实现方法2
//创建一个类,实现Runnable接口,再创建Runnable实例 传给Thread实例
//通过Runnable来描述任务内容
//进一步再把描述好的任务交给Thread实例
class MyRunnable implements Runnable {
public void run(){
System.out.println("这里是线程运行的代码");
System.out.println("Hello Runnable");
}
}
public class Demo2 {
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.start();
}
}

对比上面两种方法:
继承 Thread 类, 直接使用 this 就表示当前线程对象的引用.
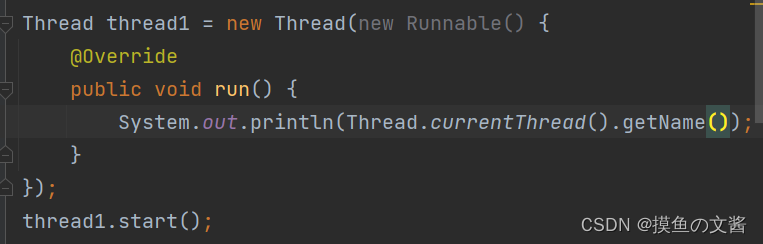
实现 Runnable 接口, this 表示的是 MyRunnable 的引用. 需要使用 Thread.currentThread()
其他变形
创建了一个匿名内部类,继承自Thread类,同时重写run方法
同时再new出这个匿名内部类的实例
// 使用匿名类创建 Thread 子类对象
Thread t1 = new Thread() {
@Override
public void run() {
System.out.println("使用匿名类创建 Thread 子类对象");
}
};
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Hello");
}
});
thread.start();
通常认为 Runnable 的写法更好一点,能够做到让线程和线程执行的任务更好的解耦
Runnable 单纯的只是描述了一个任务,至于这个任务是要通过一个进程来执行,还是通过一个线程来执行
还是线程池来执行,还是协程来执行,Runnable 本身并不关心,其内部的代码也不关心
使用lambda表达式 代替 Runnable
Thread thread = new Thread(() -> {
System.out.println("Hello thread");
});
thread.start();
3.多线程的优势-增加运行速度
在我们的认知中,多线程概念的提出就是为了提高系统的效率,那么使用多线程就一定会提高效率吗?
其实并不是,具体还要依据执行的程序而定。
- 使用 System.nanoTime() 可以记录当前系统的 纳秒 级时间戳.
- serial 串行的完成一系列运算. concurrency 使用两个线程并行的完成同样的运算.
//分别用一个线程串行自增两个变量 和 用两个线程并行自增两个变量
//观察程序执行所需时间
public class Demo6 {
private static final long count = 1000_0000_0000L;
//用一个线程 先后对两个变量自增
public static void serial(){
//记录程序执行时间
long beg = System.currentTimeMillis();//记录程序开始运行时间
long a = 0;
for (long i = 0; i < count; i++) {
a++;
}
long b = 0;
for (long i = 0; i < count; i++) {
b++;
}
long end = System.currentTimeMillis();//记录程序结束时间
System.out.println("串行消耗时间:" + (end - beg) + "ms");//计算程序消耗时间
}
//用两个线程 并行对两个变量自增
public static void concurrency() throws InterruptedException {
long beg = System.currentTimeMillis();
Thread thread1 = new Thread( () -> {
long a = 0;
for (long i = 0; i < count; i++) {
a++;
}
});
thread1.start();
Thread thread2 = new Thread( () -> {
long b = 0;
for (long i = 0; i < count; i++) {
b++;
}
});
thread2.start();
//long end = System.currentTimeMillis();
//此处不能直接这么记录结束时间,因为这个求时间戳的代码实在 main 线程中
//main 和 thread1 thread2 之间也是并发执行的关系,此处 thread1 和 thread2
//还没有执行完,时间戳就开始计时,结果显然是不准确的
//正确做法应该是让 main 线程等待 thread1 和 thread2 结束后,再来记录时间
thread1.join();
thread2.join();//join方法可以使main线程等待thread线程先结束
long end = System.currentTimeMillis();
System.out.println("并行消耗时间:" + (end - beg) + "ms");
}
/**
* 并不是两个线程 就是 一个线程 消耗时间的一半,归根结底还是不确定这两个线程在底层到底是
* 并行执行还是并发执行,只有在并行执行时,效率才会有显著提升。同时由于创建线程时也有开销
* 如果自增次数(任务量)过小,多线程反而会效率低
*
*/
public static void main(String[] args) throws InterruptedException {
serial();
concurrency();
}
}
- 当我们设置自增量为10_0000_0000 时,串行与并行执行所需时间:
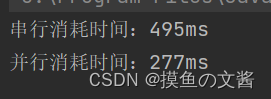
- 而当我们设置自增量为100 时,串行与并行执行所需时间:
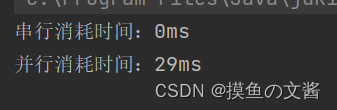
可以看到,当我们将自增量设置比较大时,串行执行所需时间较长,并行时间较短,但并不是说两个线程同时运行,就可以节省一半时间;但如果自增量较小,那么并行执行并不会节省时间,相反比起串行执行效率要低。
原因是:在创建线程时,也会有一定开销,所以当程序本身并不大时,非要使用多线程反而会消耗更多时间。
结论:1.多线程并不是万能的,不是用多线程 效率一定提高,要看具体场景;
2. 多线程一般适用于cpu密集型程序,程序要进行大量的计算,使用多线程就可以更充分的利用cpu的多核资源
4. Thread 类及常见方法
- Thread 类是 JVM 用来管理线程的一个类。
- 每个线程都有一个唯一的 Thread 对象与之关联。
4.1 Thread 的常见构造方法
| 方法 | 说明 |
|---|---|
| Thread() | 创建线程对象 |
| Thread(Runnable target) | 使用 Runnable 对象创建线程对象 |
| Thread(String name) | 创建线程对象,并命名 |
| Thread(Runnable target, String name) | 使用 Runnable 对象创建线程对象,并命名 |
| 【了解】Thread(ThreadGroup group,Runnable target) | 线程可以被用来分组管理,分好的组即为线程组,这个目前我们了解即可 |
eg:
Thread t1 = new Thread();
Thread t2 = new Thread(new MyRunnable());
Thread t3 = new Thread("这是我的名字");
Thread t4 = new Thread(new MyRunnable(), "这是我的名字");
可以使用jconsole来观察线程的名字,在你电脑安装jdk的bin目录中就可以找到jconsole这个应用程序,他是一个jdk自带的很重要的调试工具
它可以罗列出你系统上的Java进程
选择你要查看的进程建立连接,就可以实时观测该进程的执行情况。
4.2 Thread 的常见属性
| 属性 | 获取方法 | 补充 |
|---|---|---|
| ID | getId() | 线程的唯一标识,不同线程ID不会重复 |
| 名称 | getName() | 在调试工具中会用到 |
| 状态 | getState() | 表示线程当前状态 |
| 优先级 | getPriority() | 优先级高的线程理论上更容易被调度 |
| 是否后台线程 | isDaemon() | JVM会在一个进程的所有非后台进程结束后,才结束运行 |
| 是否存活 | isAlive() | run方法是否运行结束(调用考虑点:非运行态不能执行到这行代码,如阻塞态、就绪态) |
| 是否中断 | isInterrupted() | 线程是否中断 |
ID 是线程的唯一标识,不同线程不会重复
名称是各种调试工具用到
状态表示线程当前所处的一个情况,下面我们会进一步说明
优先级高的线程理论上来说更容易被调度到
关于后台线程,需要记住一点:JVM会在一个进程的所有非后台线程结束后,才会结束运行。
是否存活,即简单的理解,为 run 方法是否运行结束了线程的中断问题,下面我们进一步说明
islive()—操作系统中对应的线程是否正在运行:
Thread t 对象的生命周期和内核中对应的线程,生命周期并不完全一致,创建出 t 对象之后,在调用 start 之前,系统中是没有对应线程的,在 run 方法执行完了以后,系统中的线程就销毁了,但是 t 这个对象可能还存在,通过 isAlive 就能判定当前系统的线程的运行情况:
如果调用 start 之后,run 执行完之前,isAlive 就返回 ture;
如果调用 start 之前,run 执行完之后,isAlive 就返回 flase。
public class Demo10 {
public static void main(String[] args) {
Thread thread = new Thread(() -> {
for (int i = 0; i < 10; i++) {
try {
System.out.println(Thread.currentThread().getName() + ": 我还活着");
Thread.sleep(5 * 100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + ": 我即将死去");
});
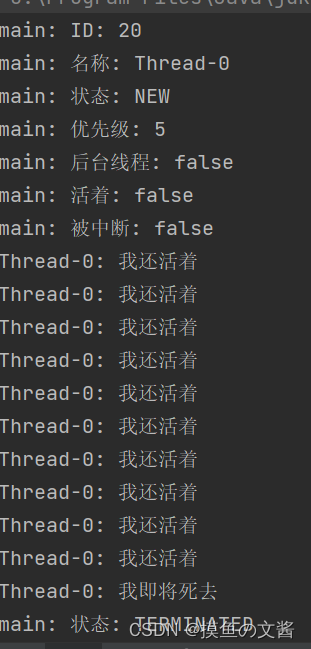
System.out.println(Thread.currentThread().getName() + ": ID: " + thread.getId());
System.out.println(Thread.currentThread().getName() + ": 名称: " + thread.getName());
System.out.println(Thread.currentThread().getName() + ": 状态: " + thread.getState());
System.out.println(Thread.currentThread().getName() + ": 优先级: " + thread.getPriority());
System.out.println(Thread.currentThread().getName() + ": 后台线程: " + thread.isDaemon());
System.out.println(Thread.currentThread().getName() + ": 活着: " + thread.isAlive());
System.out.println(Thread.currentThread().getName() + ": 被中断: " + thread.isInterrupted());
thread.start();
while (thread.isAlive()) {}
System.out.println(Thread.currentThread().getName() + ": 状态: " + thread.getState());
}
}
4.3 Thread 的一些重要方法
4.3.1 启动一个线程-start()
start 方法决定了系统中是不是真的创建出线程。
在上面的代码中,我们发现:有时 run 方法和 start 方法的执行结果是一样的,但是事实上这两个方法有很大区别:
- run 单纯的只是一个普通的方法,它描述了任务的内容;
- start 则是一个特殊的方法,只有调用它,才会真的在操作系统的底层创建一个线程。
我们用一段代码来验证:
public class Demo11 {
public static void main(String[] args) {
Thread thread = new Thread(() -> {
while (true) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread.start();
//thread.run();
while (true) {
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
thread.start() 的执行结果如下:
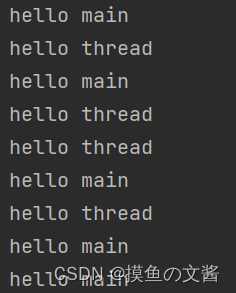
thread.run() 的执行结果如下:
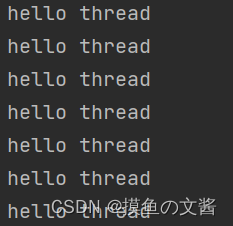
由以上结果我们可以看到:
- 当你调用 start 方法时,最后的结果就是"hello thread" 和 “hello main” 交替循环打印,说明成功在main 线程中创建了新的线程 thread ,并且两个线程并发执行。
- 而当我们调用 run 方法时,我们发现只有 “hello thread” 循环打印,说明代码是从前往后按顺序运行的,也就证明了他并没有在 main 线程中创建出新的线程,循环仍是在 main 线程中执行的。
4.3.2 中断一个线程-isInterrupted()
线程停下来的关键,是要让线程对应的run方法执行完(特别的:对于 main 线程来说,要等 main 方法执行完,线程才会结束)。
我们也可以手动控制线程中断,有下面几种方法:
- 1.手动设置标志位(自己创建的变量,比如 boolean),来控制线程是否要执行结束。
//线程的中断:
public class Demo12 {
public static boolean isQuit = false;
public static void main(String[] args) {
Thread thread = new Thread(() -> {
while (! isQuit) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread.start();
//只要把 isQuit 设置为 true ,此时循环就会退出,进一步的 run 就执行完了,然后线程也就结束了。
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
isQuit = true;
System.out.println("线程终止!");
}
}
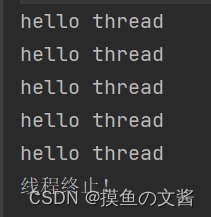
线程执行五次以后,标志位被更改为 true ,结束循环。
在别的线程中控制 isQuit 这个标志位,就能影响到这个线程的结束,这是因为 :多个线程共用一虚空地址空间!!!,所以,main 线程修改的 isQuit 和 t 线程判定的 isQuit ,是同一个值。
- 使用 Thread 中内置的一个标志位来进行判定,可以通过:
Thread.interrupted(); 这是一个静态方法 。
Thread.currentThread().isInterrupted(); 这是实例方法,其中currentThread 能够获取到当前线程的实例。

以上两种方法更推荐使用第二种 Thread.currentThread().isInterrupted(); 因为一个代码中的线程有很多个,随时哪个线程都有可能终止,我们可以使用这个方法来避免发生误判(原理如下):
- Thread.interrupted(); 这个方法判定的标志位是
Thread的static成员(一个程序中只有一个标志位)。- Thread.currentThread().isInterrupted();这个方法判定的标志位是
Thread的普通成员,每个示例都有自己的标志位
4.3.3 线程等待- join()
用途: 由于在多个线程之间,调度的顺序是不确定的,线程之间的执行是按照调度器安排的,这个过程可以视为是“无序,随机”,但这样对我们整体代码而言并不好,有些时候,我们需要能够控制线程之间的顺序。线程等待就是一种,控制线程按顺序执行的手段, 此处的线程等待,主要是控制线程结束的先后顺序
使用
join的时候,哪个线程调用的join哪个线程就会阻塞等待,等对应的线程执行完毕为止(对应线程的run方法执行完)
如果在 main 线程中创建一个 t 线程,然后调用 t. join() 方法,那么这个代码所达到的效果就是让 main 等待 t 线程 :
调用 join 之后,main 线程就会进入阻塞状态(暂时无法在cpu上执行),代码执行到 join 这一行,就暂时停下了,不继续往下执行了,等到 t 线程执行完毕(run 方法执行完),通过线程等待,我们控制l让 t 线程先结束,main后结束,一定程度上的干预了这两个线程的执行顺序。

4.3.4 获取当前线程的引用-currentThread()
哪个线程调用这个方法就能得到哪个线程的实例
public class Demo14 {
public static void main(String[] args) {
Thread thread = new Thread() {
@Override
public void run() {
//System.out.println(this.getName());
System.out.println(Thread.currentThread().getName());
}
};
thread.start();
System.out.println(Thread.currentThread().getName());
}
}
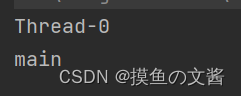
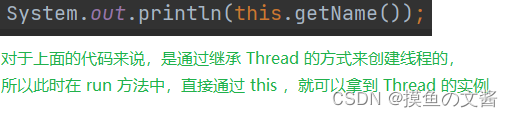
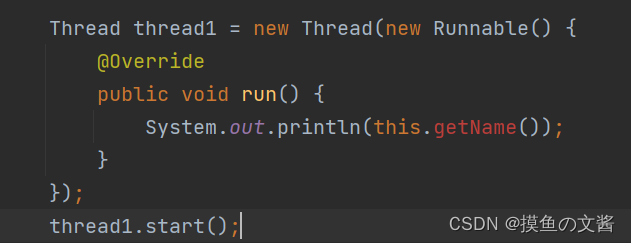
如果使用 Runnable (lambdad 效果相同) 来创建线程,此时的 this 就不是指向 Thread 类型了,而是指向 Runnable 。而 Runnable 只是一个单纯的任务,没有 name 属性,想要拿到线程的名字,只能通过 Thread.currentThread().getName()
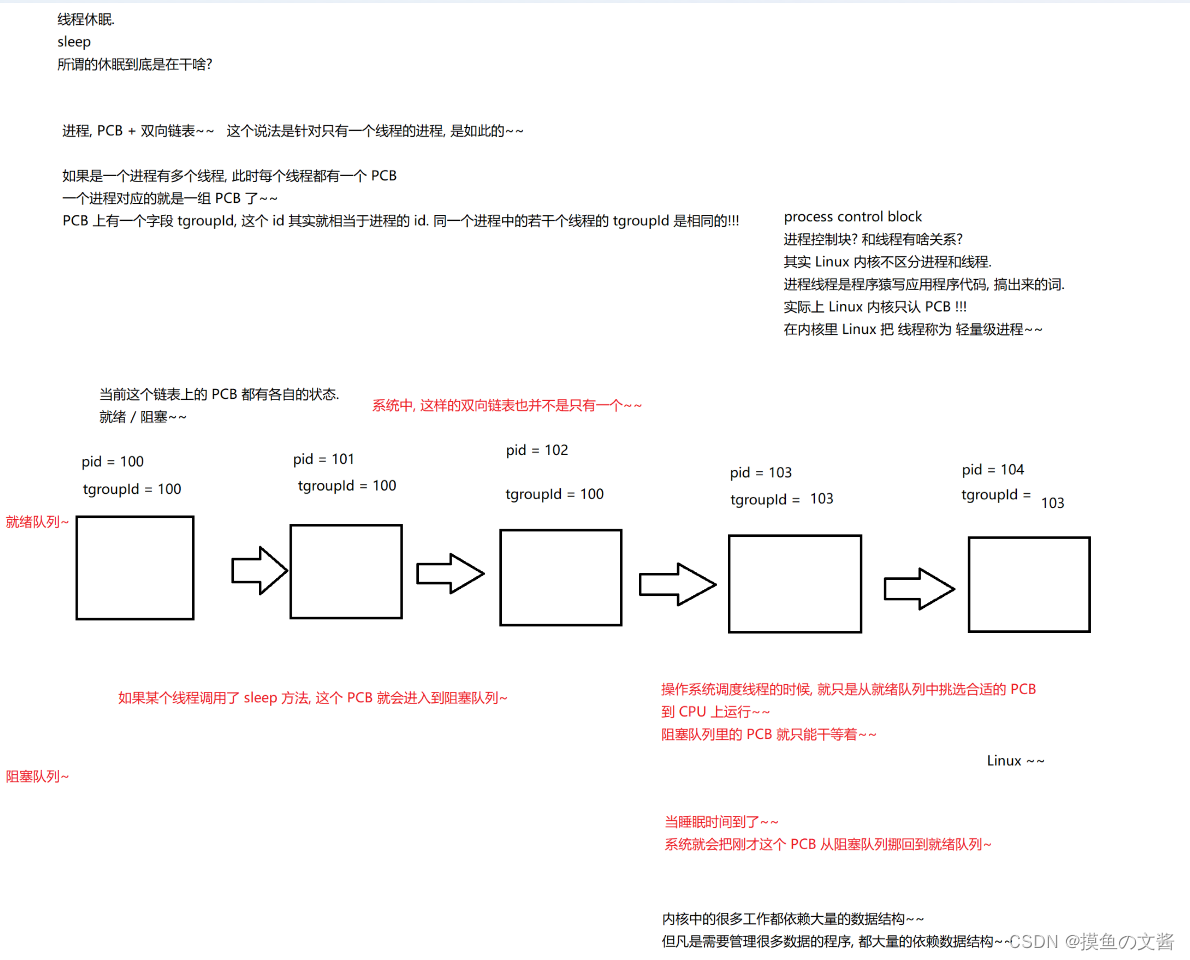
4.3.5 线程休眠-sleep()
















 1301
1301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









