






深度学习入门篇-推荐系统-相似度算法
B站大学学的,up主讲的很好,但是链接失效了所以手敲了一份笔记,也有一些省略和自己的理解解释。
视频链接在这里,https://www.bilibili.com/video/BV1x44y1G7kC/?spm_id_from=333.788&vd_source=e2e011da8cf8ec077bcb5e842b113eaa
学完这一part需要三个小时,我个人认为0代码基础也能看懂,不懂的地方多看几遍。建议选择连续的时间学习更高效哦,侵删。
一、能学到什么?
-
深入理解推荐系统的业务逻辑
-
掌握数据的特征提取方法
-
掌握相似度算法(余弦相似度)在实际项目中的应用
-
掌握机器学习(建模与应用)
-
掌握深度学习(建模与应用)
推荐系统可以用什么方式来实现?
-
用数学中的相似度算法实现
-
用机器学习方式实现
-
用深度学习方式实现
本季重点讲解如何使用余弦相似度算法的方式来实现
相似度算法实现推荐系统的原理
余弦相似度:通过计算两个向量的夹角余弦值来评估他们的相似度

实现原理
-
文章和用户的特征提取(栏目、地域)
-
计算所有文章与用户的夹角余弦值
-
根据夹角余弦值的大小排序
二、编码实现
工具介绍:
编程语言:python
编码工具:jupyter notebook
用到的库:sklearn-一个机器学习常用的库,这次主要用到余弦相似度
第一步:特征处理
第二步:计算用户与每一篇文章的夹角余弦值
第三步:排序,得到用户的推荐列表
with open(“wenzhang.json”)as f:
//加载文章的特征向量文档
wenzhang_list = json.loads(f.read())
//定义用户特征向量[3,3],也可以接入数据
user_list = [
[3.3]
]
wenzhang_list,user_list
//第二步,导包计算夹角余弦值
from sklearn.preprocessing import consine_similarity
//使用方法
//第一种用法,只传x,得到x内的每一个向量与其余向量的夹角余弦值
//consine_similarity(wenzhang_list)
//第二种用法,传x与y,得到x里面的每一个向量和y里面的每一个向量里面的夹角余弦值
//consine_similarity(wenzhang_list,user_list)
sim_list = consine_similarity(wenzhang_list,user_list)
user1_sim_list = sim_list[0]
//第三步,排序前预处理:新建二维数组,将文章索引与其对应夹角余弦值关联起来
wenzhang_sim_list = [(i+1,v) for i, v in enumerate(user1_sim_list)]
//排序
sorted_list = sorted(wenzhang_sim_list, key=lambda x:x[1], reverse = True)
//此时wenzhang_sim_list中已经完成了用户的推荐列表
三、特征挖掘与处理

挖掘主体的属性、行为
特征类型的类别
-
离散型特征:数值是有限的、可确定的、可一一列取的,没有实际的度量意义的。(如文章的栏目编号)
-
连续性特征:又称为度量数据,基本上都是数值型数据,其数值是有实际的度量意义的,如事物的大小、长短等。
特征处理技术
-
独热编码:One-Hot编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
-
数据缩放:将原始数据按照一定的比例进行转换,将数据缩放到一个小的特定区间内,比如0到1或者-1到1。目的是消除不同样本之间特性、数量等特征属性的差异,转化为一个无量纲的相对数值,结果的各个样本特征量数值都处于同一数量级上。
不同特征类型的预处理方式
1、离散型特征:转换成独热编码
2、连续性特征:数据缩放 或 离散化区间后 用 独热编码 处理
举例:
文章A点击量为2000,
划分点击量区间为
「100、1000、10000、20000」
则文章A独热编码为[0,0,1,0]
特征处理流程

import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
# 第一步特征选取
#导文件
user_df = pd.read_csv("data/用户信息.csv")
article_df = pd.read_csv("data/文章信息.csv")
# print(article_df)
cols_df = pd.read_csv("data/栏目信息.csv")
# print(cols_df)
area_df = pd.read_csv("data/地域信息.csv")
# print(area_df)
publish_df = pd.read_csv("data/发布时间信息.csv")
# print(publish_df)
click_df = pd.read_csv("data/点击量信息.csv")
# print(click_df)
#第二步,特征预处理,独热编码
cols_vec = [0 for _ in cols_df["栏目编号"]]
# 以上语句等同于
# cols_vec = []
# for _ in cols_df["栏目编号"]:
# cols_vec.append(0)
area_vec = [0 for _ in area_df["地域编号"]]
publish_vec = [0 for _ in publish_df["发布时间编号"]]
click_vec = [0 for _ in click_df["点击量分级编号"]]
# 遍历每一篇文章,然后对其特征做处理
wenz_list = []
for i in range(len(article_df)):
# 栏目独热编码
cols_str = str(article_df["栏目编号"][i])
cols_onehot_vec = cols_vec.copy()
if cols_str == "不限":
cols_onehot_vec = [1 for _ in cols_vec]
else:
# 用于多个栏目编号以逗号分隔的情况
cols_arr = cols_str.split(",")
for j in cols_arr:
j = int(j)
cols_onehot_vec[j-1] =1
#地域独热编码
area_str = str(article_df["地域编号"][i])
area_onehot_vec = area_vec.copy()
if area_str == "不限":
area_onehot_vec = [1 for _ in area_vec]
else:
# 用于多个栏目编号以逗号分隔的情况
area_arr = area_str.split(",")
for j in area_arr:
j = int(j)
area_onehot_vec[j - 1] = 1
# 发布时间分级独热编码
publish_str = str(article_df["发布时间分级"][i])
publish_onehot_vec = publish_vec.copy()
if publish_str == "不限":
publish_onehot_vec = [1 for _ in publish_vec]
else:
# 用于多个栏目编号以逗号分隔的情况
publish_arr = publish_str.split(",")
for j in publish_arr:
j = int(j)
publish_onehot_vec[j - 1] = 1
# 点击量分级独热编码
click_str = str(article_df["点击量分级"][i])
click_onehot_vec = click_vec.copy()
if click_str == "不限":
click_onehot_vec = [1 for _ in click_vec]
else:
# 用于多个栏目编号以逗号分隔的情况
click_arr = click_str.split(",")
for j in click_arr:
j = int(j)
click_onehot_vec[j - 1] = 1
# 拼接独热编码到文章列表中
wenz_list.append(
cols_onehot_vec + area_onehot_vec + publish_onehot_vec + click_onehot_vec
)
# 打印文章信息列表
# for v in wenz_list:
# print(v)
# 处理用户信息:用户信息中只有 栏目编号 和 所属地域编号
# 1、发布时间?最新发布的那个值 = 第1个分级
# 2、点击量?点击量最多的那个值 = 第8个分级
user_list = []
for i in range(len(user_df)):
# 用户感兴趣的栏目编号
cols_str = str(user_df["感兴趣的栏目编号"][i])
cols_onehot_vec = cols_vec.copy()
if cols_str == "不限":
cols_onehot_vec = [1 for _ in cols_vec]
else:
# 用于多个栏目编号以逗号分隔的情况
cols_arr = cols_str.split(",")
for j in cols_arr:
j = int(j)
cols_onehot_vec[j-1] =1
#地域独热编码
area_str = str(user_df["所属的地域编号"][i])
area_onehot_vec = area_vec.copy()
if area_str == "不限":
area_onehot_vec = [1 for _ in area_vec]
else:
# 用于多个栏目编号以逗号分隔的情况
area_arr = area_str.split(",")
for j in area_arr:
j = int(j)
area_onehot_vec[j - 1] = 1
# 用户隐藏的发布时间兴趣设置为最新,也就是第一级,都为[1,0,0,0,0,0,0,0]的独热编码
publish_onehot_vec = publish_vec.copy()
publish_onehot_vec[0] = 1
# 用户隐藏的点击量兴趣设置为最高,也就是最后一级,为[0,0,0,0,0,0,0,1]的独热编码
click_onehot_vec = click_vec.copy()
click_onehot_vec[-1] = 1
user_list.append(
cols_onehot_vec + area_onehot_vec + publish_onehot_vec + click_onehot_vec
)
# for v in user_list:
# print(v)
# 第三步,基于余弦相似度求每一篇文章与用户的相似度
sim_lis = cosine_similarity(user_list,wenz_list)
#第四步排序
sorted_sim_lis = []
for lis in sim_lis:
# 相似度与对应的文章编号关联起来
lis1 = [(i+1, sim_v)for i, sim_v in enumerate(lis)]
# 按第二列的值降序排序
lis1 = sorted(lis1, key=lambda row: row[1], reverse= True)
sorted_sim_lis.append(lis1)
for i,v in enumerate(sorted_sim_lis):
print(user_df["昵称"][i])
print(v)
csv文件的格式截图放下面啦,文章列表和用户列表相当于规则,其他的仅仅是商品的某一属性列表,很简单的。
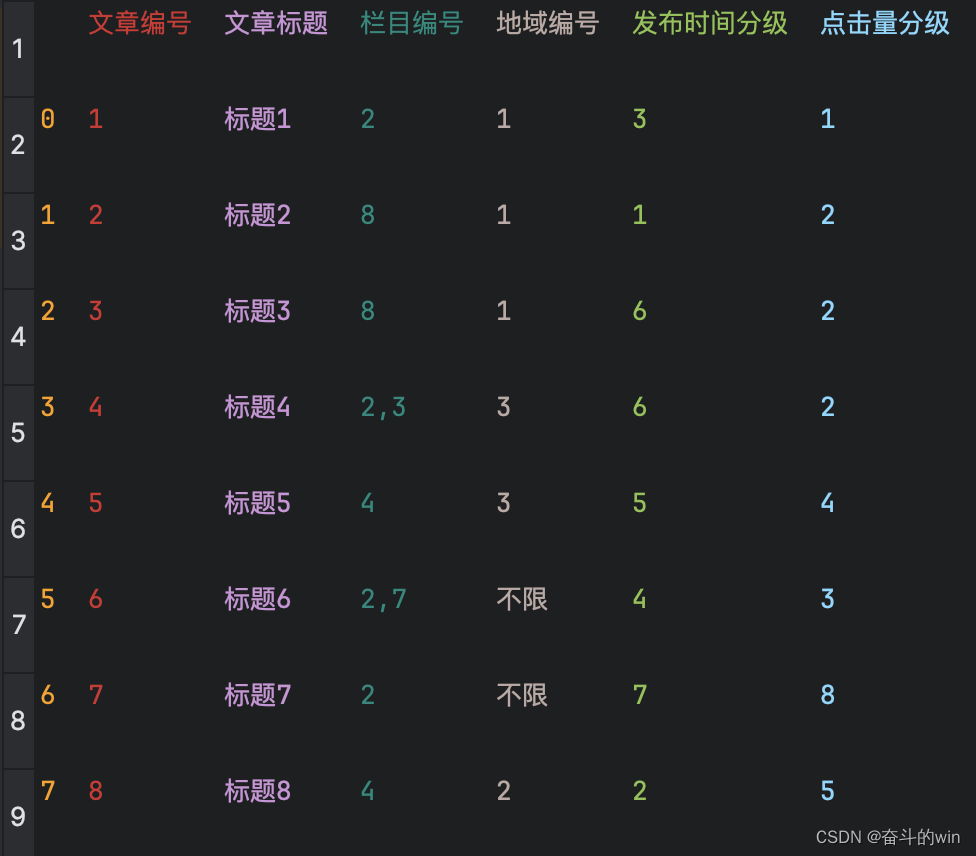
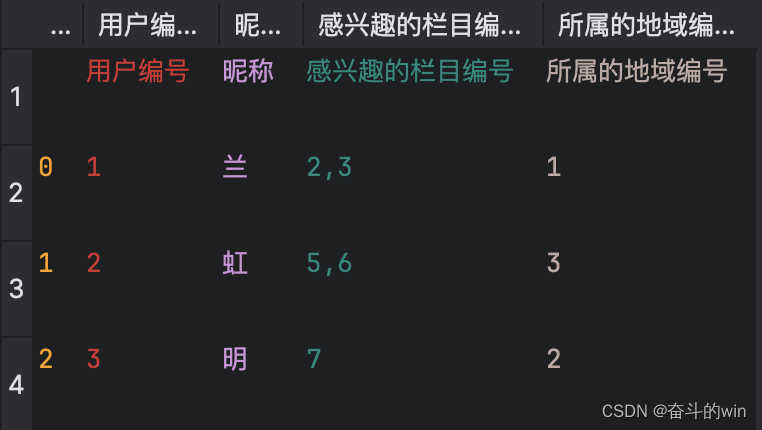

建议配合视频食用,纯手敲花了四个小学完视频,然后花两小时配套了自己的数据敲出了代码,最后花了两小时优化代码(就是写成方法,不熟python语法搞了好久),祝你学习顺利。
自己的代码已经写成方法了可以直接使用,后续再优化一下再开源。
小小余弦相似度推荐,拿下!















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









