







目录
一、简介
1.题目:
A Near Memory Computing FPGA Architecture for Neural Network Acceleration
2.时间:
2022.11
3.来源:
IEEE
4.简介:
基于NMC(近内存计算)的FPGA加速,基于深度神经网络模型参数量大,并且FPGA中的内存与处理器是分隔的,这就意味着DNN需要传输大量参数,导致巨大的能量消耗。近内存计算是最近热门的一种加快神经网络计算的方法,为了降低高功率开销,论文提出的NMC FPGA架构通过开发各种神经网络组件(CONV、FC、POOL)来构建神经网络模型,然后通过使用VTR来映射到NMC FPGA平台。提出的架构旨在降低矩阵乘法的功耗,使用NMC FPGA,矩阵计算的能源效率提高、功耗降低以及所用电路面积也有所减少。
5.论文主要贡献:
1.提出了一种基于NMC的FPGA 架构,通过在BRAM旁边增加了一个adder tree,大大提高了MAC的计算速度。
2. 计算机辅助设计(CAD)工具可以自动将神经网络模型映射到NMC FPGA,并分析其功耗和面积等。
二、相关名词
NMC:Near Memory Computing,近内存计算
CAD:Computer Aided Design,计算机辅助设计
VTR:Verilog to Routing, 一个全球合作的开源CAD项目
MAC:Multiply Accumulate,乘积累加运算
FSM:Finite State Machine,有限状态机
三、 相关背景知识
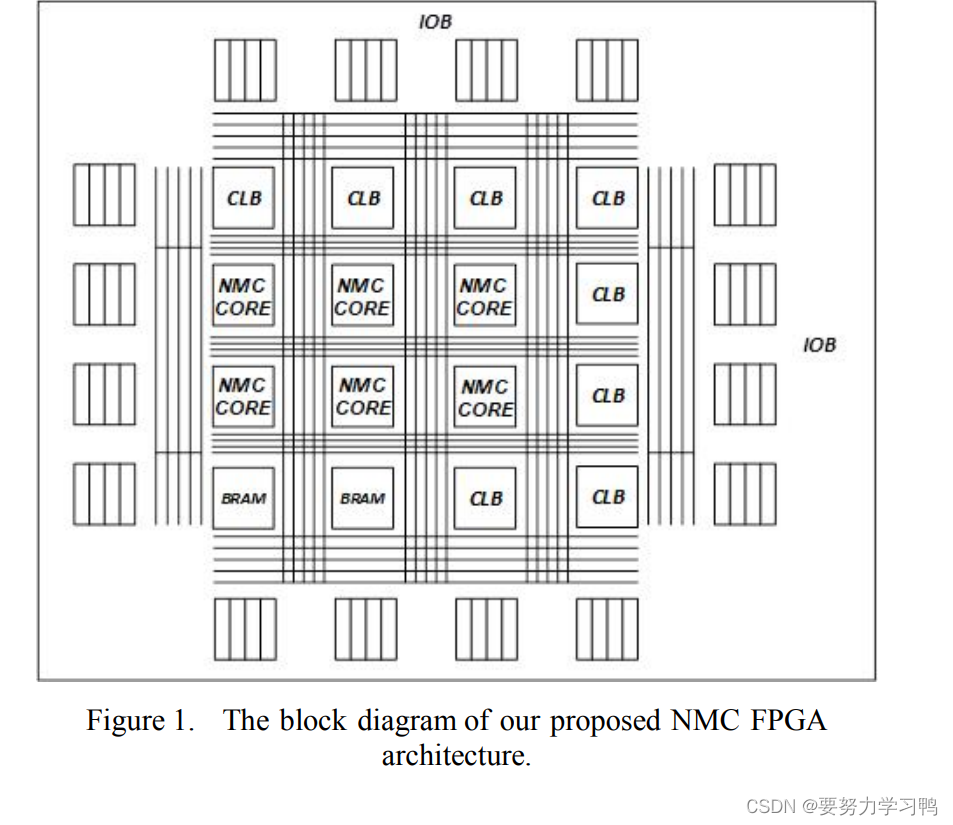
1.FPGA结构划分
当前流行的 FPGA 实现通常被称为岛式架构(island-style architecture),“岛”指的是平铺在二维阵列中的逻辑块,看上去好像海洋中漂浮的岛屿一样。
常见的FPGA架构由一组逻辑块(称为可配置逻辑块(CLB,Configurable Logic Blocks)、IO块(IOB,Input/Output Block)和路由通道组成。本文中使用的结构与岛式结构类似,基本的计算资源是CLB,BRAM是片上存储资源,用于存储中间计算结果。核心MAC计算由分布在芯片上的NMC core完成,FPGA上的逻辑块之间有丰富的路由资源进行放置和路由。
2.MAC计算
这种运算是将乘法的乘积结果和累加器的值相加,再存入累加器。实现此运算操作的硬件电路单元,被称为“乘数累加器”。
若没有使用 MAC 指令,上述的程序可能需要两条指令,但 MAC 指令可以使用一个指令完成。
而许多运算(卷积、点击、矩阵、多项式、数字滤波器运算)都可以分解为数个 MAC指令,由此可以提高运算效率。
四、处理流程概述
1.神经网络加速的关键组件
A. CONV AND FC-LAYER ACCELERATION
B. POOLING-LAYER ACCELERATION

2.将神经网络层映射到NMC FPGA的方法
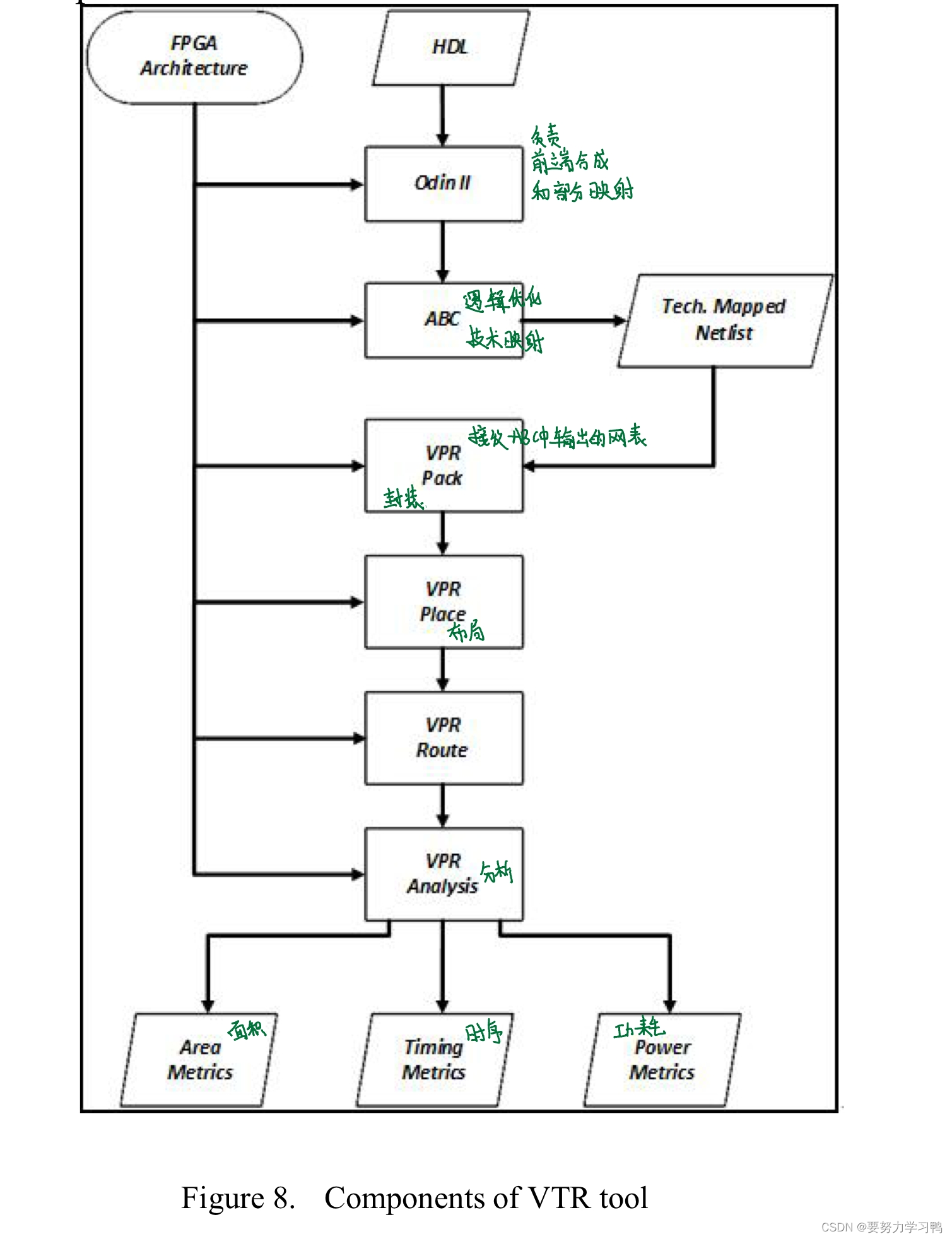















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









